AI写测试用例这件事,模型是必须,人机协同的流程设计更是关键
做测试的同学都知道,写测试用例是个"又累又必要"的活儿。需求文档动辄好几页,功能点密密麻麻,写完用例还要反复核对是否有遗漏------一个大型需求光梳理需求+用例编写就能耗掉不止一周的时间。
随着AI的发展,我们开始琢磨:AI能不能帮我们把这事干漂亮点?
让AI直接生成,要么对内部文档格式水土不服,要么没法灵活切换模型、自定义Prompt,生成内容参差不同。于是我们干脆撸起袖子自己干,在测试小伙伴和基架构组小伙伴多次开会讨论研究落地方案后,自研了一个AI辅助生成测试用例平台 。真实数据是:简单需求AI节点采纳率90%+,复杂或有历史包袱的需求也能到50%左右。
今天我们就聊聊这个平台怎么设计的、踩过哪些坑、以及对"AI+测试"这件事的真实体感。
一、重写文档:让AI重写成易于AI理解的文档
最早我们试过最简单粗暴的办法:把需求文档扔给AI,让它直接吐用例。
结果惨不忍睹。要么AI理解跑偏,把A模块的功能写到B模块去了;要么生成的用例浮在表面;更头疼的是越聊越多,AI就忘了前文说了啥------上下文一长,智商直接掉线。
于是我们做的第一件事,不是让AI写用例,而是让AI先把需求文档"翻译"成AI容易理解的结构。
在平台上,你上传一份原始需求文档,AI会做四件事:
- 梳理文档结构------把散落各处的描述归拢成树状层级
- 整理模块归属------识别功能模块、子功能的包含关系
- 删除冗余信息------删除重复信息
- 自动转换图片------把文档中的链接转换成图片
AI重写完,会吐出一份"结构化需求说明"。这时候人工可以介入修改或补充------AI不理解业务黑话?没关系,人把黑话翻译成逻辑就行;AI漏了什么?人补上去。
这一步做完,后续所有环节的准确率直接上了一个台阶。磨刀不误砍柴工,先把输入质量控住,输出才不会翻车。
二、功能点拆解:让AI把"大块需求"切成"可测试的小块"
有了结构化需求,下一步是功能点拆解。
这一步的目标是把需求文档拆成功能模块 → 子功能 → 子子功能 → 测试点的树状结构。比如:
- 登录模块(功能模块)
- 账号密码登录(子功能)
- 正确账号密码登录成功(测试点)
- 错误密码提示并限制尝试次数(测试点)
- 空账号/空密码校验(测试点)
- 账号密码登录(子功能)
AI生成完初版后,平台支持三种人工协作模式:
- AI补充测试点:让AI基于当前功能点,继续挖掘可能遗漏的测试场景
- AI拆分测试点:把一个笼统的测试点细化成多个独立验证项
- 人工编辑测试点:手动添加一些AI挖掘不到的功能点
这里有个关键设计:AI负责广度发散,人负责深度决策。 AI会想到"密码错误限制尝试次数"这种边界条件,但它不知道你们系统具体是限3次还是5次、锁定多久------这些细节由测试同学根据业务知识补上去。
拆解完的功能点树,既是一份测试范围清单,也是下一步生成用例的"精确输入"。
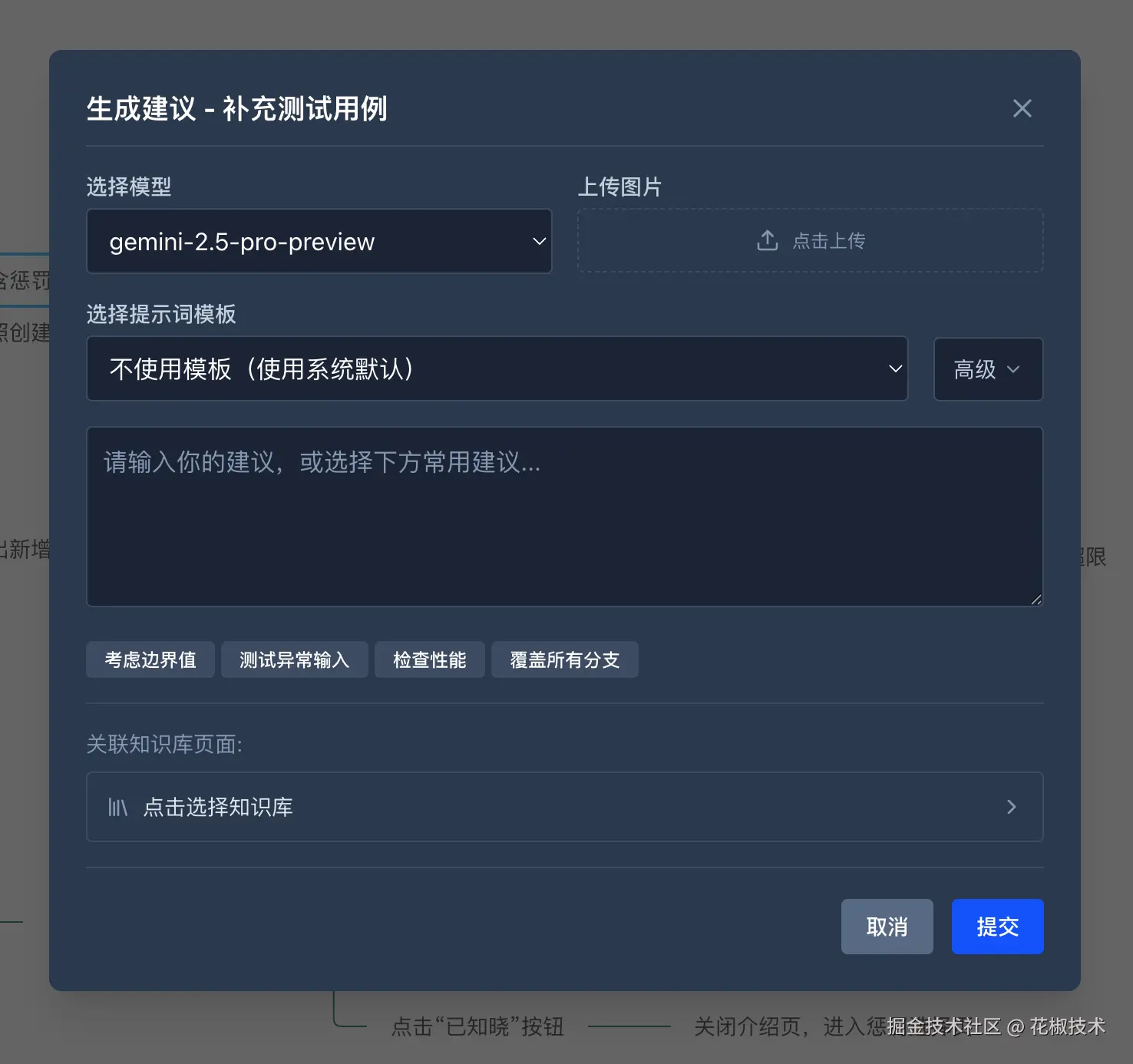
三、生成用例:模型随便换,上下文不再爆
到生成用例这一步,我们遇到了另一个典型问题:AI生成用例时,上下文又爆了。
一个功能模块可能拆出几十个测试点,每个测试点要生成完整的用例(前置条件、步骤、预期结果),一次性全扔给AI,输出质量明显下降。
对于一些简单的小需求,我们可以直接选择一键生成所有用例,但对于大且复杂或历史包袱重的需求,我们做了几件事来解决:
1. 按粒度灵活生成 你可以选择按"整个功能模块"生成,也可以按"单个子功能"生成,甚至可以按"单个测试点"生成。上下文越小,AI越专注,输出越精准。
2. 支持并行多任务 平台可以同时启动多个生成任务。比如登录模块和支付模块各开一个任务并行跑,互不干扰,效率直接翻倍。
3. 模型自由切换 平台目前接入了豆包、Gemini、ChatGPT中的三个模型,生成时可以任选。三个模型生成的内容风格确实有差异------有的偏简洁,有的发散性强适合探索性测试。没有绝对的"最好",只有"哪个更符合你当下的需求"。 我们一般建议同一个需求用不同模型各跑一遍,对比后选满意的版本。
4. 挂载"花椒知识库" 这是内部沉淀的一个花椒所有功能页面的知识库,生成时勾选关联页面,AI会参考知识库里的页面内容,生成结果更接近花椒功能,而不是"AI味很重"的那种。
5.自定义prompt 针对不同的业务需求,选择或输入合适的prompt,生成更符合预期的内容。
6. 支持上传图片 需求文档里的UI稿、流程图可以直接上传,AI会结合图文信息理解交互细节,对用例的准确率提升尤其明显。
生成完后,同样需要人工干预------AI写了个大概,人把业务细节补精准,最终入库的就是可以直接执行的、带测试人员专业判断的用例。
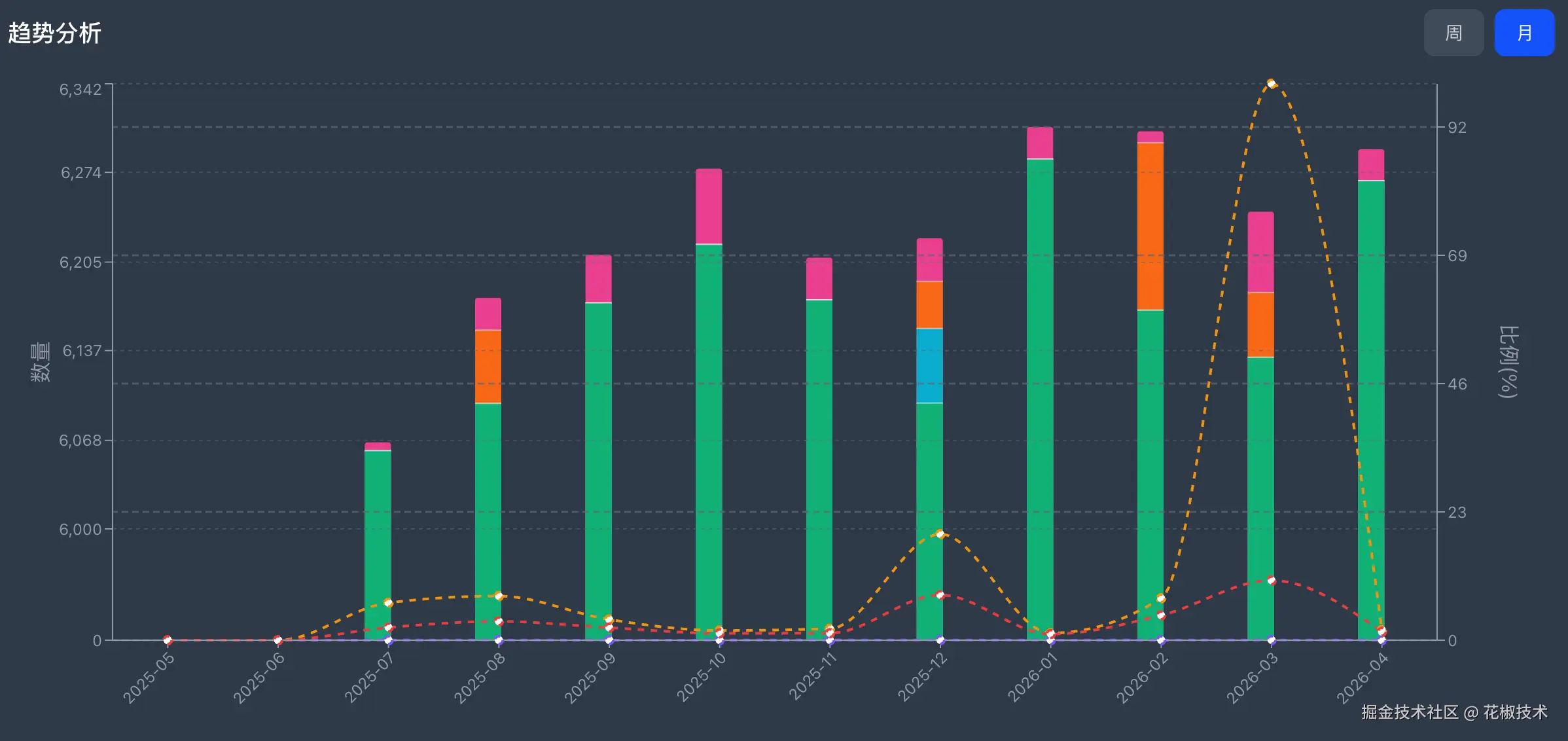
四、看板:AI到底帮了多少忙,用数据说话
工具用了一段时间,自然会问:AI到底帮了多少忙?
所以平台里专门做了一个看板,追踪每个需求AI生成用例节点及占比,所有AI生成用例节点,平台采用统计,人员使用统计等:
- 直接采纳------AI写出来,人看一眼,没问题,直接用
- 修改后采纳------AI搭了骨架,人改了步骤细节或补充了预期结果
- 删除/弃用------AI写偏了或者用不上
这个看板能实时看到各模块的AI节点占比和采纳情况。
- 简单需求 :AI节点采纳率稳定在80%-90%。
- 复杂需求或有历史包袱的需求 :采纳率50%左右。
- AI能把通用部分写好,但那些藏在代码里的历史bug和业务特例,还是得人工补。
这个数据本身也在迭代------随着花椒知识库越来越厚,人工使用的熟练度增加,prompt持续优化,采纳率在逐步爬升。
更重要的是,看板让AI帮了多少忙这件事可视化 了。数据会说明:AI生成了XX条用例,AI节点占比XX%,采纳率XX%。
五、真实体感:AI是辅助,是增强
最大的体会是:AI替代的是"打字"和"回忆"。
以前写用例,脑子里知道要测什么,但得一条条敲出来------敲步骤、敲预期结果、敲前置条件。现在AI把这些体力活干了,测试人员的时间释放出来去思考更重要的事:这个需求的业务价值到底是什么?测试场景设计合不合理?哪些场景有没有遗漏?和历史功能会不会冲突?如何保障质量?
人机协同的边界也变得清晰:
- AI擅长:结构化信息处理、模式识别、发散列举、避免低级遗漏
- 人擅长:业务判断、历史背景理解、价值优先级排序、最终质量兜底
平台设计的每一步都留了人工干预的口子,不是因为我们不信任AI,而是因为我们清楚:测试用例是要执行、要维护、要担责任的。 最终签字画押的必须是人。
如果你也在做AI辅助测试的探索,或者对类似平台感兴趣,欢迎留言交流。
毕竟,能把测试人员从重复劳动里解放出来的工具,永远值得投入。
(本文数据基于团队内部实际使用统计,不代表行业通用水平,供参考)
以上是本期分享。如果你想和我们进一步交流技术问题、获取独家干货,欢迎扫码加入花椒技术交流群。
