本文作者:多年微服务架构实战经验,深耕分布式事务落地,从双 11 核心链路踩坑沉淀而来,全文无废话、全干货,从原理到源码级拆解,从环境搭建到生产落地,从单模式使用到混合模式实战,再到 90% 开发者都会踩的坑,一篇带你吃透 Seata 分布式事务,看完即可直接落地到项目中。本文适合人群 :Java 初中级开发工程师、微服务架构师、需要落地分布式事务的技术负责人、准备面试的求职者。
原创不易,点赞、收藏、关注三连,后续持续更新 Seata 高可用、性能优化、混沌工程验证系列内容。
一、开篇:微服务架构下,分布式事务为什么是绕不开的坎?
1.1 从单体到微服务,事务的本质发生了什么变化?
在单体架构中,我们所有的业务都在一个服务里,操作的是同一个数据库,一个@Transactional注解就能搞定事务的 ACID 特性,保证 "要么全成功,要么全回滚"。
但当我们做了微服务拆分,情况完全变了:
- 一个下单流程,会拆分出订单服务、库存服务、账户服务、支付服务,每个服务都是独立部署的节点
- 每个服务都对应自己的数据库,甚至是不同类型的数据库(MySQL、Redis、MongoDB)
- 服务之间通过 HTTP/RPC 远程调用,网络抖动、服务宕机随时可能发生
这时候,单体的本地事务完全失效了 ------ 订单创建成功了,库存扣减了,结果账户余额扣减失败了,数据就出现了不一致,这就是分布式事务要解决的核心问题。
1.2 分布式事务的核心痛点:一致性 vs 性能
分布式事务的本质,是在不可靠的分布式环境下,保证多个独立资源操作的原子性,而它天生就面临 CAP 定理的约束:
- 一致性 (Consistency):所有节点在同一时间看到的数据是一致的
- 可用性 (Availability):服务一直可用,正常请求能在合理时间内返回结果
- 分区容错性 (Partition Tolerance):网络分区故障发生时,系统依然能正常运行
在微服务架构中,P 是必须满足的,我们只能在 C 和 A 之间做权衡,而分布式事务的所有方案,本质上都是在 C 和 A 之间找一个适合业务的平衡点。
而传统的分布式事务方案,都有无法回避的硬伤:
| 方案 | 核心原理 | 硬伤 |
|---|---|---|
| 原生 2PC/3PC | 数据库原生两阶段提交,强一致 | 性能极差,长事务占用数据库连接,容易出现阻塞和死锁,不适合高并发场景 |
| 本地消息表 | 本地事务 + 消息队列实现最终一致 | 代码侵入性强,表结构与业务强耦合,运维成本高,不支持复杂事务场景 |
| SAGA 模式 | 长事务拆分,正向执行 + 反向补偿 | 无隔离性,脏写问题难以解决,补偿逻辑开发量巨大,出问题难以排查 |
| 最大努力通知 | 基于消息队列的定时重试通知 | 一致性最弱,只适合非核心场景(如短信通知、站内信) |
1.3 为什么说 Seata 是分布式事务的终极解决方案?
Seata 是阿里开源的分布式事务框架,历经双 11 万亿级流量的考验,目前已经成为 Apache 顶级项目,也是国内微服务架构下分布式事务的事实标准。
它的核心优势,完美解决了传统方案的痛点:
- 多模式适配全场景:支持 AT、TCC、SAGA、XA 四大模式,覆盖 99% 的业务场景,简单场景用 AT 零侵入,高并发复杂场景用 TCC 高性能
- 极低的业务侵入性 :AT 模式下,业务代码几乎零改造,一个
@GlobalTransactional注解就能开启全局事务,开发成本极低 - 高性能低延迟:AT 模式一阶段直接提交本地事务,释放锁资源,二阶段异步化处理,性能远超原生 2PC,完全适配高并发场景
- 完善的生态兼容:完美适配 SpringCloud、SpringCloud Alibaba、Dubbo 等主流微服务框架,支持 MySQL、Oracle、PostgreSQL 等主流数据库
- 生产级高可用:支持 TC 集群部署、注册中心 / 配置中心对接、全链路监控告警,经过互联网大厂多年生产环境验证
接下来,我们就从核心原理入手,一步步带你落地 Seata 的 AT/TCC 模式,吃透分布式事务。
二、Seata 核心基石:架构与核心概念全解
2.1 Seata 是什么?
Seata (Simple Extensible Autonomous Transaction Architecture) 是一款高性能的开源分布式事务中间件,致力于在微服务架构下提供简单易用、高性能的分布式事务服务。
从开源至今,Seata 已经迭代到 2.x 稳定版本,在阿里内部支撑了双 11 的核心交易链路,在金融、电商、物流等多个行业有大规模的生产落地,是目前国内最成熟的分布式事务解决方案。
2.2 Seata 三大核心组件:分布式事务的 "三剑客"
Seata 的分布式事务,本质上是由三大核心组件协同完成的,这三个组件的职责分工,是理解 Seata 所有模式的基础。
这里先给大家配上 Seata 核心架构图,一眼看懂组件间的协同关系:
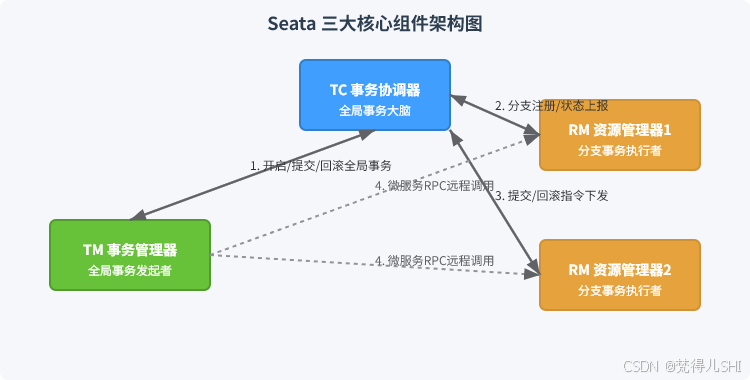
三个组件的核心职责,我用最直白的话给大家讲清楚:
-
TC (Transaction Coordinator) - 事务协调器
- 全局事务的 "大脑",独立部署的 Seata Server 服务
- 负责维护全局事务的状态,接收 TM 的请求,创建全局事务并生成唯一的 XID(全局事务 ID)
- 协调所有分支事务的执行,根据分支事务的执行结果,决定全局事务是提交还是回滚
- 管理全局锁的分配与释放,保证事务的隔离性
-
TM (Transaction Manager) - 事务管理器
- 全局事务的 "发起者",一般在业务的入口服务(比如订单服务的下单接口)
- 通过
@GlobalTransactional注解标记全局事务的边界,负责向 TC 申请开启、提交、回滚全局事务 - 负责将 XID 通过服务调用链路传递给下游的 RM,保证整个分布式事务链路的 XID 统一
-
RM (Resource Manager) - 资源管理器
- 分布式事务的 "执行者",部署在每个微服务节点中,负责管理分支事务
- 负责分支事务的本地执行,向 TC 注册分支事务,上报分支事务的执行状态
- 接收 TC 的提交 / 回滚指令,执行对应的本地事务提交或回滚操作
- AT 模式下,负责生成 undo_log 回滚日志,TCC 模式下,负责调用自定义的 Confirm/Cancel 逻辑
2.3 Seata 四大模式核心对比:AT/TCC/SAGA/XA 怎么选?
Seata 提供了四种事务模式,分别适配不同的业务场景,这里给大家做一个全维度的对比,看完就知道什么场景该用什么模式:
| 模式 | 核心原理 | 侵入性 | 性能 | 一致性 | 适用场景 |
|---|---|---|---|---|---|
| AT 模式 | 基于本地关系型数据库,通过数据源代理自动生成 undo_log,两阶段自动化提交 / 回滚 | 极低,几乎零侵入 | 极高 | 最终一致 | 90% 的常规业务场景,基于 MySQL 等支持本地 ACID 的关系型数据库,希望业务代码零改造 |
| TCC 模式 | 手动实现 Try-Confirm-Cancel 三个阶段,资源预留 + 确认提交 / 取消释放,完全由业务代码控制 | 高,需手动实现三个阶段逻辑 | 极高 | 最终一致 | 高并发核心链路(如秒杀、库存扣减)、跨异构数据库(MySQL+Redis)、非关系型数据库操作、AT 模式无法覆盖的复杂业务 |
| SAGA 模式 | 长事务拆分为多个正向操作,每个正向操作对应一个反向补偿操作,失败时按顺序反向补偿 | 高,需手动实现正向 + 反向逻辑 | 中 | 最终一致 | 超长事务流程(如金融审批、物流全链路)、无法改造的老系统接入、事务参与者多且流程长的场景 |
| XA 模式 | 基于数据库原生 XA 协议实现的强一致两阶段提交,一阶段 prepare,二阶段 commit/rollback | 低,零侵入 | 低 | 强一致 | 金融、银行等对数据强一致要求极高的场景,并发量不高,对性能要求不苛刻 |
我们重点讲解AT 模式和 TCC 模式,这两个模式覆盖了 99% 的生产业务场景,也是大家面试和工作中最常用的。
三、Seata AT 模式:零侵入的分布式事务方案,从原理到源码级拆解
AT 模式是 Seata 最核心、最常用的模式,也是大家入门 Seata 的首选模式,它最大的优势就是业务代码零侵入,完全自动化实现分布式事务的提交和回滚,开发成本极低。
3.1 AT 模式的核心设计理念
AT 模式的本质,是对传统 2PC 的革命性优化,它解决了传统 2PC 的性能痛点:
- 传统 2PC:一阶段执行 SQL 不提交,持有数据库锁,等待所有分支完成,二阶段才提交 / 回滚,锁持有时间长,性能极差
- Seata AT 模式:一阶段就提交本地事务,释放本地锁,二阶段如果是提交,异步删除 undo_log 即可;如果是回滚,通过 undo_log 自动生成反向 SQL 补偿,锁持有时间极短,性能大幅提升
而支撑这个设计的,就是 AT 模式的两大核心机制:基于数据源代理的 undo_log 自动生成机制 + 全局锁机制。
3.2 AT 模式两阶段提交全流程详解
这里我用最经典的电商下单场景(订单创建 + 库存扣减),给大家拆解 AT 模式的完整执行流程,同时配上 AT 模式两阶段执行流程图,一眼看懂整个过程。
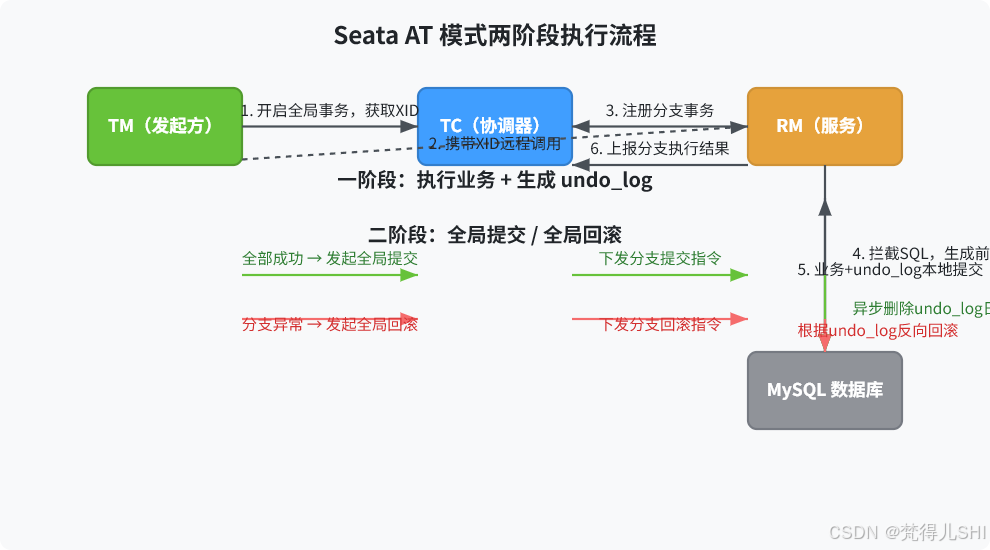
3.2.1 一阶段:业务执行 + 快照数据保存
一阶段是 AT 模式的核心,也是它性能远超传统 2PC 的关键,整个过程分为 6 个核心步骤:
- 开启全局事务 :TM(订单服务)执行被
@GlobalTransactional标记的方法,向 TC 发起请求,开启全局事务,TC 生成唯一的全局事务 XID,并返回给 TM - XID 链路传递:TM 通过 RPC/HTTP 调用下游的库存服务,将 XID 传递到下游服务,保证整个链路的 XID 统一
- 分支事务注册:RM(库存服务)接收到请求,发现请求头中包含 XID,说明当前处于全局事务中,向 TC 注册分支事务,生成分支事务 ID(Branch ID),并关联到当前的 XID
- SQL 拦截与镜像生成 :RM 通过数据源代理(DataSourceProxy)拦截业务 SQL(比如库存扣减的 UPDATE 语句),解析 SQL 类型、表名、条件、更新字段,先查询更新前的数据,生成前镜像(Before Image) ;然后执行业务 SQL,再查询更新后的数据,生成后镜像(After Image)
- 生成 undo_log 并本地提交 :根据前后镜像,生成 undo_log 回滚日志,将业务数据的更新和 undo_log 的写入,放在同一个本地事务中提交,提交完成后,立即释放本地数据库锁
- 上报执行结果:RM 向 TC 上报当前分支事务的执行结果(成功 / 失败)
这里要划重点:AT 模式一阶段就提交了本地事务,释放了本地锁,这是它性能高的核心原因。
3.2.2 二阶段:提交 / 回滚,自动化处理
TC 会收集所有分支事务的执行结果,根据结果决定全局事务是提交还是回滚,两个场景的处理逻辑完全不同:
场景 1:全部分支执行成功,全局提交
- TC 向所有 RM 下发分支提交的指令
- RM 接收到提交指令后,不需要做任何数据操作,只需要异步删除对应的 undo_log 日志即可,整个过程非常快,完全不影响业务性能
场景 2:有分支执行失败,全局回滚
- TC 向所有 RM 下发分支回滚的指令
- RM 接收到回滚指令后,根据 XID 和 Branch ID 查询对应的 undo_log 日志
- 脏写校验:对比当前数据库中的数据和 undo_log 中的后镜像,判断数据是否被其他事务修改,如果出现脏写,会触发告警和人工处理
- 校验通过后,根据前镜像生成反向 SQL,执行反向 SQL 完成数据回滚
- 回滚完成后,删除对应的 undo_log 日志,向 TC 上报回滚结果
3.3 AT 模式的核心保障:全局锁 + 本地锁 + undo_log 机制
很多人会问:AT 模式一阶段就提交了本地事务,释放了本地锁,那如果有其他事务修改了同一条数据,回滚的时候不就出问题了吗?
这就是 Seata AT 模式的核心设计:本地锁保证本地事务的 ACID,全局锁保证分布式事务的隔离性。
全局锁机制详解
全局锁是由 TC 管理的,记录的是 "哪个全局事务,锁住了哪个表的哪条数据",它的核心规则是:
- 分支事务在一阶段提交本地事务之前,必须先拿到这条数据的全局锁,拿不到全局锁,就不能提交本地事务,必须回滚本地事务并释放本地锁
- 全局锁只有在全局事务完成(提交 / 回滚)之后,才会被释放
- 非 Seata 管理的事务,因为不会申请全局锁,所以能修改数据,这就是我们后面要讲的脏写坑
我用一个经典的并发场景,给大家讲清楚全局锁是如何避免脏写和超卖的:
- 全局事务 TX1,要扣减商品 A 的库存,一阶段执行 UPDATE 语句,拿到本地锁,执行业务 SQL,然后向 TC 申请商品 A 这条数据的全局锁,拿到全局锁后,提交本地事务,释放本地锁,全局锁不释放
- 此时,全局事务 TX2 也要扣减商品 A 的库存,执行 UPDATE 语句,拿到本地锁,执行业务 SQL,然后向 TC 申请全局锁,发现全局锁被 TX1 持有,申请失败,不断重试
- 如果 TX1 执行成功,TC 发起全局提交,提交完成后释放全局锁,TX2 就能拿到全局锁,完成自己的事务
- 如果 TX1 有分支执行失败,TC 发起全局回滚,TX1 拿到本地锁,根据 undo_log 回滚数据,回滚完成后释放全局锁和本地锁,TX2 继续执行
这样就保证了:在全局事务完成之前,其他分布式事务无法修改同一条数据,避免了并发场景下的脏写和数据不一致。
undo_log 表核心设计
undo_log 是 AT 模式回滚的基础,每个业务库都必须创建 undo_log 表,它的核心字段如下:
sql
CREATE TABLE IF NOT EXISTS `undo_log`
(
`branch_id` BIGINT NOT NULL COMMENT 'branch transaction id',
`xid` VARCHAR(100) NOT NULL COMMENT 'global transaction id',
`context` VARCHAR(128) NOT NULL COMMENT 'undo_log context, such as serialization',
`rollback_info` LONGBLOB NOT NULL COMMENT 'rollback info',
`log_status` INT NOT NULL COMMENT '0:normal status, 1:defense status',
`log_created` DATETIME(6) NOT NULL COMMENT 'create datetime',
`log_modified` DATETIME(6) NOT NULL COMMENT 'modify datetime',
UNIQUE KEY `ux_undo_log` (`xid`, `branch_id`),
KEY `ix_log_created` (`log_created`)
) ENGINE = InnoDB
AUTO_INCREMENT = 1
DEFAULT CHARSET = utf8mb4 COMMENT ='AT transaction mode undo table';核心字段说明:
xid+branch_id:唯一索引,定位到具体的分支事务回滚日志rollback_info:存储了前后镜像的二进制数据,是回滚的核心依据log_status:日志状态,0 是正常状态,1 是防御状态(用于脏写校验)
3.4 AT 模式的适用场景与局限性
适用场景
- 基于支持本地 ACID 特性的关系型数据库(MySQL、Oracle、PostgreSQL 等)
- 常规的 CRUD 业务场景,希望业务代码零改造,开发成本低
- 并发量较高,对性能有要求,能接受最终一致性的业务场景
- 微服务架构下,多服务跨库操作的常规业务场景(如电商下单、支付、退款等)
局限性
- 只支持关系型数据库,不支持 Redis、MongoDB 等非关系型数据库
- 不支持跨异构数据源的复杂事务场景
- 高并发热点数据场景下,全局锁竞争会导致性能下降(比如秒杀场景的商品库存)
- 不能通过非 Seata 代理的数据源修改业务表,否则会绕过全局锁检查,导致脏写,回滚失败
四、Seata TCC 模式:高性能高灵活的分布式事务方案,原理与核心问题解决
如果说 AT 模式是 Seata 的 "普惠方案",那 TCC 模式就是 Seata 的 "高阶方案",它完全由业务代码控制,灵活性极高,性能极强,能解决 AT 模式无法覆盖的所有复杂场景,也是大厂高并发核心链路的首选方案。
4.1 TCC 模式的核心设计理念
TCC(Try-Confirm-Cancel)模式,本质上是一种侵入式的、完全由业务代码实现的两阶段提交方案,它把一个分布式事务拆分为三个阶段,每个阶段的逻辑都由开发者手动实现:
- Try 阶段:尝试执行,完成所有业务检查,预留必须的业务资源(比如冻结库存、冻结账户余额)
- Confirm 阶段 :确认执行,真正执行业务操作,只使用 Try 阶段预留的资源,必须保证幂等性
- Cancel 阶段 :取消执行,释放 Try 阶段预留的资源,必须保证幂等性,同时处理空回滚和悬挂问题
TCC 模式的核心优势,就是完全摆脱了数据库的限制,不管是关系型数据库、非关系型数据库、还是第三方接口调用,只要能实现这三个阶段,就能纳入分布式事务的管理,同时它没有全局锁的竞争,性能远超 AT 模式,完美适配高并发热点场景。
4.2 TCC 模式的三个阶段:Try-Confirm-Cancel 全流程
同样用电商库存扣减的场景,给大家拆解 TCC 模式的三个阶段的核心职责,同时配上 TCC 模式执行流程图:
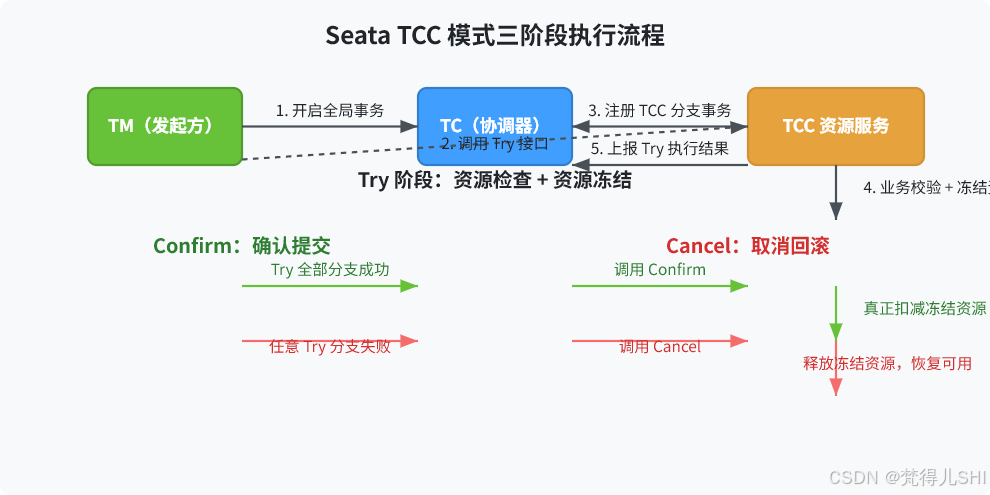
三个阶段的核心职责,我给大家讲透,这是 TCC 模式落地的关键:
-
Try 阶段:检查 + 预留
- 这是 TCC 的一阶段,核心是所有业务的前置检查 和资源预留
- 必须完成所有的业务合法性校验:比如账户是否存在、余额是否充足、库存是否足够
- 必须完成资源的预留,而不是直接扣减:比如冻结账户余额、冻结库存,而不是直接扣减可用余额 / 库存
- 举个例子:库存扣减的 Try 阶段,不是直接把可用库存从 100 减到 90,而是把可用库存减 10,冻结库存加 10,总库存不变,这就是资源预留
-
Confirm 阶段:确认提交
- 这是 TCC 的二阶段提交,只有所有分支的 Try 阶段都执行成功,TC 才会下发 Confirm 指令
- 核心是真正执行业务提交,只能使用 Try 阶段预留的资源,不能做任何业务检查
- 必须保证幂等性:因为 TC 会重复下发 Confirm 指令,所以 Confirm 接口必须支持重复调用不重复执行
- 接上面的例子:Confirm 阶段,把冻结的 10 个库存,真正扣减掉,冻结库存减 10,总库存减 10
-
Cancel 阶段:取消回滚
- 这是 TCC 的二阶段回滚,只要有一个分支的 Try 阶段执行失败,TC 就会给所有已经执行成功 Try 的分支下发 Cancel 指令
- 核心是释放 Try 阶段预留的资源,回滚到初始状态
- 必须保证幂等性 ,同时必须处理空回滚 和悬挂问题
- 接上面的例子:Cancel 阶段,把冻结的 10 个库存恢复到可用库存,冻结库存减 10,可用库存加 10,回到初始状态
4.3 TCC 模式三大经典问题:空回滚、幂等、悬挂,根本原因与终极解决方案
TCC 模式虽然灵活高性能,但它有三个绕不开的经典问题,90% 的开发者在落地 TCC 的时候都会踩坑,这也是面试的高频考点,今天我给大家讲透根本原因和终极解决方案。
先给大家配上 TCC 三大问题场景图,一眼看懂问题发生的过程:

问题 1:幂等性问题
根本原因:TC 在下发 Confirm/Cancel 指令后,会等待 RM 的返回结果,如果因为网络抖动、服务宕机,导致 TC 没有收到返回结果,TC 会重复下发指令,导致 Confirm/Cancel 方法被多次调用,如果不做幂等处理,就会出现重复扣减、重复回滚的问题。
解决方案:
- 基于 TCC 事务控制表,记录每个分支事务的执行状态,Confirm/Cancel 执行前,先查询状态,如果已经是 committed/rollbacked 状态,直接返回成功,不执行业务逻辑
- Seata 1.5.1 + 版本已经内置了 TCC Fence 能力,只需要在
@TwoPhaseBusinessAction注解中设置useTCCFence = true,就能自动实现幂等性,无需手动开发
问题 2:空回滚问题
根本原因:分支事务的 Try 阶段因为网络问题,请求没有到达 RM,或者 RM 在执行 Try 之前就宕机了,导致 Try 方法没有执行,但是 TC 因为超时,认为 Try 失败,下发了 Cancel 指令,RM 需要执行 Cancel 方法,但是此时没有预留任何资源,Cancel 无法回滚,这就是空回滚。
解决方案:
- Cancel 执行时,先检查 TCC 事务控制表中是否有对应的 trying 状态记录,如果没有,说明 Try 方法没有执行,属于空回滚,直接返回成功,不执行业务回滚逻辑,同时插入一条 suspended 状态的记录,防止后续的悬挂问题
- 同样,TCC Fence 已经内置了空回滚的处理逻辑,无需手动开发
问题 3:悬挂问题
根本原因:这是空回滚的后续问题,Cancel 指令比 Try 指令先到达 RM,RM 执行了空回滚,返回成功,TC 认为全局事务已经结束,此时延迟的 Try 请求才到达 RM,执行了资源预留,但是全局事务已经结束了,不会再有 Confirm/Cancel 指令下发,导致预留的资源永远被冻结,这就是悬挂。
解决方案:
- Cancel 执行空回滚时,插入一条 suspended 状态的记录,标记这个 xid+branch_id 的事务已经执行过 Cancel 了
- Try 方法执行时,先检查 TCC 事务控制表中是否有对应的记录,如果有 suspended 状态的记录,说明已经执行过 Cancel 了,直接拒绝执行 Try 方法,防止悬挂
- TCC Fence 同样内置了防悬挂的处理逻辑,一键开启即可
4.4 TCC 模式的适用场景与局限性
适用场景
- 高并发热点数据场景:比如秒杀、库存扣减,没有全局锁竞争,性能远超 AT 模式
- 跨异构数据源的事务场景:比如同时操作 MySQL 和 Redis,AT 模式不支持,TCC 可以完美适配
- 非关系型数据库的事务场景:比如 MongoDB、Elasticsearch 等,AT 模式不支持
- 调用第三方接口的事务场景:比如调用支付、退款接口,需要保证接口调用的一致性
- AT 模式无法覆盖的复杂业务场景
局限性
- 代码侵入性极强,每个分支事务都需要手动实现 Try/Confirm/Cancel 三个方法,开发成本是 AT 模式的 3 倍以上
- 对开发者的要求极高,需要充分理解 TCC 的三个阶段,处理好幂等、空回滚、悬挂三大问题
- 业务逻辑和事务逻辑强耦合,后期维护成本高
五、环境前置准备:Seata Server + SpringCloud 项目整合全流程(含版本兼容避坑)
讲完了原理,接下来我们进入实战环节,第一步就是环境搭建,这也是 90% 的开发者踩坑的重灾区,我会给大家讲清楚每一个步骤,以及对应的避坑点。
5.1 版本选型终极指南(生产级必看)
Seata 最常见的坑,就是版本不兼容,客户端和服务端版本不一致、SpringCloud Alibaba 和 Seata 版本不匹配,都会导致事务不生效、回滚失败、甚至服务启动失败。
这里我给大家整理了 2026 年最新的生产级稳定版本对应关系,大家直接照着选,绝对不会踩坑:
| SpringCloud Alibaba 版本 | SpringCloud 版本 | SpringBoot 版本 | Seata Server 版本 | JDK 版本 | 生产推荐 |
|---|---|---|---|---|---|
| 2025.1.0.0 | 2025.1.1 | 4.0.2+ | 2.2.0 | 21+ | 最新稳定推荐 |
| 2023.0.3.0 | 2023.0.2 | 3.2.x | 2.1.0 | 17+ | 主流稳定推荐 |
| 2022.0.0.0-RC2 | 2022.0.0 | 3.0.x | 1.7.1 | 17+ | 老项目兼容 |
| 2.2.10.RELEASE | Hoxton.SR12 | 2.3.x | 1.6.1 | 8+ | 老项目维护 |
版本避坑铁则(生产环境必须遵守):
- Seata 客户端和服务端的大版本必须一致,比如服务端用 2.1.0,客户端必须用 2.1.x,严禁跨大版本混用,否则会出现协议不兼容、事务状态异常
- SpringCloud Alibaba 2.2.0.RELEASE 是分界点,之前的版本依赖
seata-all,之后的版本依赖seata-spring-boot-starter,严禁混用 - 生产环境严禁使用 SNAPSHOT 版本,必须使用 RELEASE 稳定版
- JDK 版本必须和 SpringBoot 版本匹配,SpringBoot 3.0 + 必须用 JDK17+,SpringBoot 4.0 + 必须用 JDK21+
本文我们使用生产主流稳定版本进行实战:
- SpringCloud Alibaba:2023.0.3.0
- SpringCloud:2023.0.2
- SpringBoot:3.2.5
- Seata Server:2.1.0
- Nacos:2.3.2(注册中心 + 配置中心)
- MySQL:8.0
- JDK:17
5.2 Seata Server(TC) 集群部署实战(基于 Nacos 注册 + 配置中心 + MySQL 存储)
Seata Server 就是我们说的 TC 事务协调器,生产环境必须部署集群,保证高可用,我们使用 Nacos 作为注册中心和配置中心,MySQL 作为存储介质,实现 TC 的集群部署。
5.2.1 数据库初始化
首先,我们需要在 MySQL 中创建 Seata 的数据库,初始化对应的表结构,Seata 的存储模式有 file、db、redis 三种,生产环境推荐使用 db 模式。
- 创建数据库
sql
CREATE DATABASE seata DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
USE seata;- 初始化表结构,SQL 脚本可以从 Seata 官网获取,核心表如下:
sql
-- 全局事务表,记录所有全局事务的状态
CREATE TABLE IF NOT EXISTS `global_table`
(
`xid` VARCHAR(128) NOT NULL,
`transaction_id` BIGINT,
`status` TINYINT NOT NULL,
`application_id` VARCHAR(32),
`transaction_service_group` VARCHAR(32),
`transaction_name` VARCHAR(128),
`timeout` INT,
`begin_time` BIGINT,
`application_data` VARCHAR(2000),
`gmt_create` DATETIME,
`gmt_modified` DATETIME,
PRIMARY KEY (`xid`),
KEY `idx_status_gmt_modified` (`status`, `gmt_modified`),
KEY `idx_transaction_id` (`transaction_id`)
) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4;
-- 分支事务表,记录所有分支事务
CREATE TABLE IF NOT EXISTS `branch_table`
(
`branch_id` BIGINT NOT NULL,
`xid` VARCHAR(128) NOT NULL,
`transaction_id` BIGINT,
`resource_group_id` VARCHAR(32),
`resource_id` VARCHAR(256),
`branch_type` VARCHAR(8),
`status` TINYINT,
`client_id` VARCHAR(64),
`application_data` VARCHAR(2000),
`gmt_create` DATETIME(6),
`gmt_modified` DATETIME(6),
PRIMARY KEY (`branch_id`),
KEY `idx_xid` (`xid`)
) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4;
-- 全局锁表,管理AT模式的全局锁
CREATE TABLE IF NOT EXISTS `lock_table`
(
`row_key` VARCHAR(128) NOT NULL,
`xid` VARCHAR(128),
`transaction_id` BIGINT,
`branch_id` BIGINT NOT NULL,
`resource_id` VARCHAR(256),
`table_name` VARCHAR(32),
`pk` VARCHAR(36),
`status` TINYINT NOT NULL DEFAULT 0 COMMENT '0:locked ,1:rollbacking',
`gmt_create` DATETIME,
`gmt_modified` DATETIME,
PRIMARY KEY (`row_key`),
KEY `idx_status` (`status`),
KEY `idx_branch_id` (`branch_id`),
KEY `idx_xid_and_branch_id` (`xid`, `branch_id`)
) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4;
-- TCC Fence表,用于TCC模式的三大问题处理
CREATE TABLE IF NOT EXISTS `tcc_fence_log`
(
`xid` VARCHAR(128) NOT NULL COMMENT 'global id',
`branch_id` BIGINT NOT NULL COMMENT 'branch id',
`action_name` VARCHAR(64) NOT NULL COMMENT 'action name',
`status` TINYINT NOT NULL COMMENT 'status(tried:1;committed:2;rollbacked:3;suspended:4)',
`gmt_create` DATETIME(3) NOT NULL COMMENT 'create time',
`gmt_modified` DATETIME(3) NOT NULL COMMENT 'update time',
PRIMARY KEY (`xid`, `branch_id`),
KEY `idx_gmt_modified` (`gmt_modified`),
KEY `idx_status` (`status`)
) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4;5.2.2 Nacos 配置同步
我们将 Seata Server 的配置同步到 Nacos 配置中心,方便集群节点统一管理,步骤如下:
- 从 Seata 官网下载 2.1.0 版本的安装包,解压后找到
/script/config-center/config.txt文件,这是 Seata 的核心配置文件 - 修改核心配置:
bash
# 存储模式,使用db
store.mode=db
# 数据库类型
store.db.dbType=mysql
# 驱动类
store.db.driverClassName=com.mysql.cj.jdbc.Driver
# 数据库连接地址
store.db.url=jdbc:mysql://你的MySQL地址:3306/seata?useUnicode=true&characterEncoding=utf8&rewriteBatchedStatements=true&useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true
# 数据库用户名
store.db.user=你的数据库用户名
# 数据库密码
store.db.password=你的数据库密码
# 最小连接数
store.db.minConn=5
# 最大连接数
store.db.maxConn=30
# 全局事务查询次数
store.db.globalTable=global_table
store.db.branchTable=branch_table
store.db.lockTable=lock_table
store.db.queryLimit=100
store.db.maxWait=5000
# 服务配置,事务分组,必须和客户端的tx-service-group对应
service.vgroupMapping.my_test_tx_group=default
# 注册中心配置
registry.type=nacos
registry.nacos.application=seata-server
registry.nacos.serverAddr=你的Nacos地址:8848
registry.nacos.group=SEATA_GROUP
registry.nacos.namespace=public
registry.nacos.username=nacos用户名
registry.nacos.password=nacos密码
# 配置中心配置
config.type=nacos
config.nacos.serverAddr=你的Nacos地址:8848
config.nacos.group=SEATA_GROUP
config.nacos.namespace=public
config.nacos.username=nacos用户名
config.nacos.password=nacos密码- 执行
/script/config-center/nacos/nacos-config.sh脚本,将配置同步到 Nacos 配置中心
5.2.3 Seata Server 配置与启动
- 解压 Seata Server 安装包,修改
/conf/application.yml文件,核心配置如下:
bash
server:
port: 8091
spring:
application:
name: seata-server
logging:
config: classpath:logback-spring.xml
file:
path: ${user.home}/logs/seata
console:
user:
username: seata
password: seata
seata:
registry:
type: nacos
nacos:
application: seata-server
server-addr: 你的Nacos地址:8848
group: SEATA_GROUP
namespace: public
username: nacos用户名
password: nacos密码
config:
type: nacos
nacos:
server-addr: 你的Nacos地址:8848
group: SEATA_GROUP
namespace: public
username: nacos用户名
password: nacos密码
store:
mode: db- 启动 Seata Server:
- Linux/Mac:执行
/bin/seata-server.sh - Windows:执行
/bin/seata-server.bat
- Linux/Mac:执行
- 启动成功后,访问
http://你的服务器地址:8091,使用 seata/seata 登录控制台,能看到服务信息,说明启动成功
5.2.4 集群高可用配置
生产环境需要部署至少 3 个 TC 节点,实现集群高可用,步骤非常简单:
- 在另外两台服务器上,部署相同的 Seata Server,修改端口为 8092、8093
- 配置文件完全一样,都指向同一个 Nacos 和同一个 MySQL 数据库
- 启动三个节点,三个节点会自动注册到 Nacos,形成集群
- 客户端只需要配置 Nacos 地址,会自动发现 TC 集群节点,无需手动配置多个 TC 地址
5.3 SpringCloud 微服务项目整合 Seata 全步骤
接下来,我们将 SpringCloud 微服务项目整合 Seata 客户端,这里我会给大家讲清楚每一个步骤,以及对应的避坑点。
5.3.1 核心依赖引入(避坑:依赖冲突解决)
首先,在父工程的 pom.xml 中统一管理版本,然后在每个微服务子工程中引入核心依赖:
父工程 pom.xml 版本管理:
XML
<properties>
<java.version>17</java.version>
<spring-boot.version>3.2.5</spring-boot.version>
<spring-cloud.version>2023.0.2</spring-cloud.version>
<spring-cloud-alibaba.version>2023.0.3.0</spring-cloud-alibaba.version>
<seata.version>2.1.0</seata.version>
<mysql.version>8.0.33</mysql.version>
<mybatis-plus.version>3.5.7</mybatis-plus.version>
</properties>
<dependencyManagement>
<dependencies>
<!-- SpringBoot 依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>${spring-boot.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<!-- SpringCloud 依赖 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${spring-cloud.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<!-- SpringCloud Alibaba 依赖 -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-dependencies</artifactId>
<version>${spring-cloud-alibaba.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<!-- Seata 依赖 -->
<dependency>
<groupId>io.seata</groupId>
<artifactId>seata-spring-boot-starter</artifactId>
<version>${seata.version}</version>
</dependency>
<!-- MySQL 驱动 -->
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
<version>${mysql.version}</version>
</dependency>
<!-- MyBatis-Plus 依赖 -->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>${mybatis-plus.version}</version>
</dependency>
</dependencies>
</dependencyManagement>子工程核心依赖引入:
XML
<dependencies>
<!-- SpringBoot Web -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- Nacos 服务注册发现 -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
<!-- OpenFeign 远程调用 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
<!-- Seata 客户端核心依赖 -->
<dependency>
<groupId>io.seata</groupId>
<artifactId>seata-spring-boot-starter</artifactId>
</dependency>
<!-- 排除SpringCloud Alibaba内置的Seata,避免版本冲突 -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-seata</artifactId>
<exclusions>
<exclusion>
<groupId>io.seata</groupId>
<artifactId>seata-spring-boot-starter</artifactId>
</exclusion>
</exclusions>
</dependency>
<!-- MySQL 驱动 -->
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
</dependency>
<!-- MyBatis-Plus -->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
</dependency>
<!-- Lombok -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
</dependencies>依赖避坑重点:
- 必须排除
spring-cloud-starter-alibaba-seata内置的seata-spring-boot-starter,否则会出现版本冲突,导致服务启动失败 - 严禁同时引入
seata-all和seata-spring-boot-starter,否则会出现类冲突 - 所有微服务的 Seata 客户端版本必须和 Seata Server 版本一致,否则会出现协议不兼容
5.3.2 客户端配置详解
在每个微服务的application.yml中,添加 Seata 的核心配置:
bash
spring:
application:
name: order-service # 服务名称,每个服务不一样
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://你的MySQL地址:3306/order_db?useUnicode=true&characterEncoding=utf8&useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true
username: 数据库用户名
password: 数据库密码
cloud:
nacos:
discovery:
server-addr: 你的Nacos地址:8848
namespace: public
username: nacos用户名
password: nacos密码
# Seata核心配置
seata:
# 事务分组,必须和Seata Server中配置的vgroupMapping对应
tx-service-group: my_test_tx_group
service:
# 事务分组映射,key是上面的tx-service-group,value是集群名称
vgroup-mapping:
my_test_tx_group: default
registry:
# 注册中心类型,和Seata Server保持一致
type: nacos
nacos:
server-addr: 你的Nacos地址:8848
group: SEATA_GROUP
namespace: public
username: nacos用户名
password: nacos密码
config:
# 配置中心类型,和Seata Server保持一致
type: nacos
nacos:
server-addr: 你的Nacos地址:8848
group: SEATA_GROUP
namespace: public
username: nacos用户名
password: nacos密码
# AT模式配置
client:
rm:
# 全局锁重试次数
lock-retry-times: 30
# 全局锁重试间隔
lock-retry-interval: 100
# 异步提交,提升性能
async-commit-buffer-limit: 1000
tm:
# 全局事务默认超时时间,单位毫秒
default-global-transaction-timeout: 60000
# MyBatis-Plus配置
mybatis-plus:
mapper-locations: classpath:mapper/*.xml
configuration:
map-underscore-to-camel-case: true
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
# 日志配置
logging:
level:
io.seata: debug配置避坑重点:
tx-service-group必须和 Seata Server 中配置的service.vgroupMapping.xxx=default中的 xxx 完全一致,否则会出现can not get cluster name in registry config报错,服务无法注册到 TC- 注册中心和配置中心的配置,必须和 Seata Server 完全一致,包括 group、namespace、用户名密码,否则无法发现 TC 服务
- 生产环境必须调整全局锁的重试次数和间隔,避免高并发下锁等待超时
5.3.3 数据源代理配置(AT 模式核心,90% 的人在这里踩坑)
AT 模式的核心是数据源代理,Seata 需要代理业务的数据源,才能拦截 SQL,生成 undo_log,实现自动回滚。
SpringBoot 3.0 + 版本,Seata 已经自动实现了数据源代理,无需手动配置,但是有几个必须遵守的规则,否则会导致数据源代理失效,AT 模式不回滚:
- 严禁手动配置
DataSourceProxy,否则会出现双重代理,导致代理失效 - 严禁使用其他的数据源代理框架,比如动态数据源,必须将动态数据源交给 Seata 代理
- 所有操作业务表的 SQL,必须通过 Seata 代理的数据源执行,严禁通过原生数据源、JDBC 直连等方式操作业务表
- 每个业务库,必须创建 undo_log 表,否则 AT 模式会报错
多数据源 / 动态数据源避坑配置:如果你的项目使用了多数据源 / 动态数据源,必须手动配置 Seata 的数据源代理,核心配置如下:
java
@Configuration
public class SeataDataSourceConfig {
@Bean
@ConfigurationProperties("spring.datasource.dynamic.master")
public DataSource masterDataSource() {
return DruidDataSourceBuilder.create().build();
}
@Bean
@ConfigurationProperties("spring.datasource.dynamic.slave")
public DataSource slaveDataSource() {
return DruidDataSourceBuilder.create().build();
}
@Bean
public DataSource dynamicDataSource() {
DynamicRoutingDataSource dynamicDataSource = new DynamicRoutingDataSource();
Map<Object, Object> dataSourceMap = new HashMap<>();
dataSourceMap.put("master", masterDataSource());
dataSourceMap.put("slave", slaveDataSource());
dynamicDataSource.setTargetDataSources(dataSourceMap);
dynamicDataSource.setDefaultTargetDataSource(masterDataSource());
// 交给Seata代理数据源
return new DataSourceProxy(dynamicDataSource);
}
@Bean
public SqlSessionFactory sqlSessionFactory(DataSource dataSource) throws Exception {
MybatisSqlSessionFactoryBean factoryBean = new MybatisSqlSessionFactoryBean();
factoryBean.setDataSource(dataSource);
factoryBean.setMapperLocations(new PathMatchingResourcePatternResolver().getResources("classpath:mapper/*.xml"));
return factoryBean.getObject();
}
}六、AT 模式实战:经典电商场景(订单 - 库存 - 账户)全流程落地
环境搭建完成后,我们进入 AT 模式的实战环节,用最经典的电商下单场景,带大家完整落地 AT 模式,实现订单创建、库存扣减、账户余额扣减的分布式事务,保证要么全成功,要么全回滚。
6.1 业务场景与表结构设计
6.1.1 业务流程说明
我们的业务流程是:用户下单,创建订单 → 扣减商品库存 → 扣减用户账户余额,三个操作分属三个不同的微服务,三个不同的数据库,需要通过 Seata AT 模式保证分布式事务的一致性。
服务模块划分:
- order-service:订单服务,负责创建订单,是全局事务的发起者(TM)
- storage-service:库存服务,负责扣减商品库存,是分支事务的执行者(RM)
- account-service:账户服务,负责扣减用户账户余额,是分支事务的执行者(RM)
6.1.2 数据库表设计
- 订单库 order_db:订单表 + undo_log 表
sql
-- 订单表
CREATE TABLE `t_order` (
`id` bigint NOT NULL AUTO_INCREMENT COMMENT '订单ID',
`order_no` varchar(64) NOT NULL COMMENT '订单编号',
`user_id` bigint NOT NULL COMMENT '用户ID',
`product_id` bigint NOT NULL COMMENT '商品ID',
`count` int NOT NULL COMMENT '购买数量',
`amount` decimal(10,2) NOT NULL COMMENT '订单金额',
`status` tinyint NOT NULL DEFAULT '0' COMMENT '订单状态:0-创建,1-已支付,2-已取消',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_order_no` (`order_no`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='订单表';
-- undo_log表,必须创建
CREATE TABLE IF NOT EXISTS `undo_log`
(
`branch_id` BIGINT NOT NULL COMMENT 'branch transaction id',
`xid` VARCHAR(100) NOT NULL COMMENT 'global transaction id',
`context` VARCHAR(128) NOT NULL COMMENT 'undo_log context, such as serialization',
`rollback_info` LONGBLOB NOT NULL COMMENT 'rollback info',
`log_status` INT NOT NULL COMMENT '0:normal status, 1:defense status',
`log_created` DATETIME(6) NOT NULL COMMENT 'create datetime',
`log_modified` DATETIME(6) NOT NULL COMMENT 'modify datetime',
UNIQUE KEY `ux_undo_log` (`xid`, `branch_id`),
KEY `ix_log_created` (`log_created`)
) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4 COMMENT ='AT transaction mode undo table';- 库存库 storage_db:库存表 + undo_log 表
sql
-- 库存表
CREATE TABLE `t_storage` (
`id` bigint NOT NULL AUTO_INCREMENT COMMENT '库存ID',
`product_id` bigint NOT NULL COMMENT '商品ID',
`total_count` int NOT NULL DEFAULT '0' COMMENT '总库存',
`available_count` int NOT NULL DEFAULT '0' COMMENT '可用库存',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_product_id` (`product_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='库存表';
-- 初始化测试数据
INSERT INTO `t_storage` (`product_id`, `total_count`, `available_count`) VALUES (1, 100, 100);
-- undo_log表,必须创建
CREATE TABLE IF NOT EXISTS `undo_log`
(
`branch_id` BIGINT NOT NULL COMMENT 'branch transaction id',
`xid` VARCHAR(100) NOT NULL COMMENT 'global transaction id',
`context` VARCHAR(128) NOT NULL COMMENT 'undo_log context, such as serialization',
`rollback_info` LONGBLOB NOT NULL COMMENT 'rollback info',
`log_status` INT NOT NULL COMMENT '0:normal status, 1:defense status',
`log_created` DATETIME(6) NOT NULL COMMENT 'create datetime',
`log_modified` DATETIME(6) NOT NULL COMMENT 'modify datetime',
UNIQUE KEY `ux_undo_log` (`xid`, `branch_id`),
KEY `ix_log_created` (`log_created`)
) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4 COMMENT ='AT transaction mode undo table';- 账户库 account_db:账户表 + undo_log 表
sql
-- 账户表
CREATE TABLE `t_account` (
`id` bigint NOT NULL AUTO_INCREMENT COMMENT '账户ID',
`user_id` bigint NOT NULL COMMENT '用户ID',
`balance` decimal(10,2) NOT NULL DEFAULT '0.00' COMMENT '账户余额',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_user_id` (`user_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='账户表';
-- 初始化测试数据
INSERT INTO `t_account` (`user_id`, `balance`) VALUES (1, 1000.00);
-- undo_log表,必须创建
CREATE TABLE IF NOT EXISTS `undo_log`
(
`branch_id` BIGINT NOT NULL COMMENT 'branch transaction id',
`xid` VARCHAR(100) NOT NULL COMMENT 'global transaction id',
`context` VARCHAR(128) NOT NULL COMMENT 'undo_log context, such as serialization',
`rollback_info` LONGBLOB NOT NULL COMMENT 'rollback info',
`log_status` INT NOT NULL COMMENT '0:normal status, 1:defense status',
`log_created` DATETIME(6) NOT NULL COMMENT 'create datetime',
`log_modified` DATETIME(6) NOT NULL COMMENT 'modify datetime',
UNIQUE KEY `ux_undo_log` (`xid`, `branch_id`),
KEY `ix_log_created` (`log_created`)
) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4 COMMENT ='AT transaction mode undo table';6.2 微服务模块划分
我们创建三个微服务模块,分别是 order-service、storage-service、account-service,每个模块的结构如下:
bash
├── order-service # 订单服务(TM)
│ ├── src/main/java
│ │ ├── controller # 控制器
│ │ ├── service # 业务服务
│ │ ├── mapper # 数据访问层
│ │ ├── entity # 实体类
│ │ ├── feign # 远程调用接口
│ │ └── OrderServiceApplication.java # 启动类
│ └── src/main/resources
│ └── application.yml # 配置文件
├── storage-service # 库存服务(RM)
│ └── 结构同上
└── account-service # 账户服务(RM)
└── 结构同上6.3 核心代码实现
6.3.1 账户服务(Account Service)
- 实体类 Account
java
@Data
@TableName("t_account")
public class Account implements Serializable {
private static final long serialVersionUID = 1L;
@TableId(type = IdType.AUTO)
private Long id;
private Long userId;
private BigDecimal balance;
private LocalDateTime createTime;
private LocalDateTime updateTime;
}- Mapper 接口 AccountMapper
java
@Mapper
public interface AccountMapper extends BaseMapper<Account> {
/**
* 扣减账户余额
*/
@Update("UPDATE t_account SET balance = balance - #{amount} WHERE user_id = #{userId} AND balance >= #{amount}")
int deductBalance(@Param("userId") Long userId, @Param("amount") BigDecimal amount);
}- 服务接口与实现
java
public interface AccountService extends IService<Account> {
/**
* 扣减账户余额
*/
boolean deduct(Long userId, BigDecimal amount);
}
@Service
public class AccountServiceImpl extends ServiceImpl<AccountMapper, Account> implements AccountService {
@Override
public boolean deduct(Long userId, BigDecimal amount) {
int rows = baseMapper.deductBalance(userId, amount);
return rows > 0;
}
}- 控制器 AccountController
java
@RestController
@RequestMapping("/account")
public class AccountController {
@Resource
private AccountService accountService;
@PostMapping("/deduct")
public ResponseEntity<Boolean> deduct(@RequestParam Long userId, @RequestParam BigDecimal amount) {
boolean result = accountService.deduct(userId, amount);
return ResponseEntity.ok(result);
}
}- Feign 接口 AccountFeignClient,供订单服务调用
java
@FeignClient(value = "account-service", fallbackFactory = AccountFeignFallbackFactory.class)
public interface AccountFeignClient {
@PostMapping("/account/deduct")
Boolean deduct(@RequestParam("userId") Long userId, @RequestParam("amount") BigDecimal amount);
}
// 降级工厂:必须抛出异常,不能静默返回,否则Seata无法感知分支失败
@Component
public class AccountFeignFallbackFactory implements FallbackFactory<AccountFeignClient> {
@Override
public AccountFeignClient create(Throwable cause) {
return (userId, amount) -> {
throw new RuntimeException("账户服务调用异常:" + cause.getMessage(), cause);
};
}
}避坑前置提醒:Feign 降级逻辑必须抛出 RuntimeException,严禁返回 null/false 等默认值,否则 Seata 会判定分支事务执行成功,不会触发全局回滚,这是 AT 模式 90% 回滚失效的核心原因。
6.3.2 库存服务(Storage Service)
- 实体类 Storage
java
@Data
@TableName("t_storage")
public class Storage implements Serializable {
private static final long serialVersionUID = 1L;
@TableId(type = IdType.AUTO)
private Long id;
private Long productId;
private Integer totalCount;
private Integer availableCount;
private LocalDateTime createTime;
private LocalDateTime updateTime;
}- Mapper 接口 StorageMapper
java
@Mapper
public interface StorageMapper extends BaseMapper<Storage> {
/**
* 扣减可用库存
*/
@Update("UPDATE t_storage SET available_count = available_count - #{count} WHERE product_id = #{productId} AND available_count >= #{count}")
int deductStorage(@Param("productId") Long productId, @Param("count") Integer count);
}- 服务接口与实现
java
public interface StorageService extends IService<Storage> {
boolean deduct(Long productId, Integer count);
}
@Service
public class StorageServiceImpl extends ServiceImpl<StorageMapper, Storage> implements StorageService {
@Override
public boolean deduct(Long productId, Integer count) {
int rows = baseMapper.deductStorage(productId, count);
return rows > 0;
}
}- 控制器 StorageController
java
@RestController
@RequestMapping("/storage")
public class StorageController {
@Resource
private StorageService storageService;
@PostMapping("/deduct")
public ResponseEntity<Boolean> deduct(@RequestParam Long productId, @RequestParam Integer count) {
boolean result = storageService.deduct(productId, count);
return ResponseEntity.ok(result);
}
}- Feign 接口 StorageFeignClient,供订单服务调用
java
@FeignClient(value = "storage-service", fallbackFactory = StorageFeignFallbackFactory.class)
public interface StorageFeignClient {
@PostMapping("/storage/deduct")
Boolean deduct(@RequestParam("productId") Long productId, @RequestParam("count") Integer count);
}
@Component
public class StorageFeignFallbackFactory implements FallbackFactory<StorageFeignClient> {
@Override
public StorageFeignClient create(Throwable cause) {
return (productId, count) -> {
throw new RuntimeException("库存服务调用异常:" + cause.getMessage(), cause);
};
}
}6.3.3 订单服务(Order Service,全局事务发起者 TM)
- 实体类 Order
java
@Data
@TableName("t_order")
public class Order implements Serializable {
private static final long serialVersionUID = 1L;
@TableId(type = IdType.AUTO)
private Long id;
private String orderNo;
private Long userId;
private Long productId;
private Integer count;
private BigDecimal amount;
private Integer status;
private LocalDateTime createTime;
private LocalDateTime updateTime;
}- Mapper 接口 OrderMapper
java
@Mapper
public interface OrderMapper extends BaseMapper<Order> {
}- 核心业务实现(AT 模式核心入口)
java
public interface OrderService extends IService<Order> {
String createOrder(Long userId, Long productId, Integer count, BigDecimal unitPrice);
}
@Slf4j
@Service
public class OrderServiceImpl extends ServiceImpl<OrderMapper, Order> implements OrderService {
@Resource
private OrderMapper orderMapper;
@Resource
private StorageFeignClient storageFeignClient;
@Resource
private AccountFeignClient accountFeignClient;
/**
* AT模式分布式事务核心入口
* @GlobalTransactional 开启全局分布式事务
* name:全局事务唯一名称,建议按业务场景命名
* rollbackFor = Exception.class:所有异常均触发回滚(必加!)
*/
@Override
@GlobalTransactional(name = "order-create-tx", rollbackFor = Exception.class)
public String createOrder(Long userId, Long productId, Integer count, BigDecimal unitPrice) {
// 1. 获取全局事务XID,生产环境必须打印,用于问题排查
String xid = RootContext.getXID();
log.info("【全局事务开启】XID:{}", xid);
// 2. 生成订单编号
String orderNo = "ORDER_" + System.currentTimeMillis() + "_" + userId;
// 3. 计算订单总金额
BigDecimal totalAmount = unitPrice.multiply(new BigDecimal(count));
// 4. 本地事务:创建订单
Order order = new Order();
order.setOrderNo(orderNo);
order.setUserId(userId);
order.setProductId(productId);
order.setCount(count);
order.setAmount(totalAmount);
order.setStatus(0);
orderMapper.insert(order);
log.info("【订单创建成功】订单号:{}", orderNo);
// 5. 远程调用:扣减商品库存(分支事务1)
Boolean storageResult = storageFeignClient.deduct(productId, count);
if (!storageResult) {
throw new RuntimeException("库存扣减失败:商品可用库存不足");
}
log.info("【库存扣减成功】商品ID:{}, 扣减数量:{}", productId, count);
// 【回滚测试点】放开注释,手动触发异常,验证分布式事务回滚
// if (true) {
// throw new RuntimeException("手动触发异常,测试分布式事务回滚");
// }
// 6. 远程调用:扣减用户账户余额(分支事务2)
Boolean accountResult = accountFeignClient.deduct(userId, totalAmount);
if (!accountResult) {
throw new RuntimeException("余额扣减失败:用户账户余额不足");
}
log.info("【余额扣减成功】用户ID:{}, 扣减金额:{}", userId, totalAmount);
// 7. 本地事务:更新订单状态为已支付
order.setStatus(1);
orderMapper.updateById(order);
log.info("【订单状态更新完成】订单号:{}", orderNo);
log.info("【全局事务执行完成】XID:{}", xid);
return orderNo;
}
}核心注解必知必会:
@GlobalTransactional(rollbackFor = Exception.class)必须加rollbackFor,Spring 默认仅对 RuntimeException 和 Error 回滚,加此配置可覆盖所有异常,避免回滚失效。RootContext.getXID()可获取当前全局事务唯一 ID,生产环境必须打印到日志中,出问题时可通过 XID 在 Seata 控制台、服务日志中全链路追踪。- 分支执行失败必须抛出 RuntimeException,不能静默返回,否则 Seata 无法感知异常,不会触发全局回滚。
- 控制器 OrderController
java
@RestController
@RequestMapping("/order")
public class OrderController {
@Resource
private OrderService orderService;
@PostMapping("/create")
public ResponseEntity<String> createOrder(
@RequestParam Long userId,
@RequestParam Long productId,
@RequestParam Integer count,
@RequestParam BigDecimal unitPrice) {
try {
String orderNo = orderService.createOrder(userId, productId, count, unitPrice);
return ResponseEntity.ok("订单创建成功,订单号:" + orderNo);
} catch (Exception e) {
log.error("订单创建失败", e);
return ResponseEntity.internalServerError().body("订单创建失败:" + e.getMessage());
}
}
}- 启动类 OrderServiceApplication
java
@SpringBootApplication
@EnableDiscoveryClient
@EnableFeignClients
@MapperScan("com.example.order.mapper")
public class OrderServiceApplication {
public static void main(String[] args) {
SpringApplication.run(OrderServiceApplication.class, args);
}
}6.4 AT 模式实战测试:一致性验证
6.4.1 环境启动顺序
- 启动 Nacos 服务,确认服务正常
- 启动 Seata Server 集群,确认已注册到 Nacos
- 依次启动 account-service、storage-service、order-service,确认所有服务均注册到 Nacos,且与 Seata Server 成功建立连接
启动成功后,可通过 Seata 控制台(http://TC 节点 IP:8091)查看注册的服务实例与事务分组。
6.4.2 正常流程测试
调用订单创建接口,传入正常参数:
bash
POST http://localhost:8080/order/create
Content-Type: application/x-www-form-urlencoded
userId=1&productId=1&count=2&unitPrice=100正常返回结果:
bash
订单创建成功,订单号:ORDER_1712345678901_1数据一致性校验:
- 订单库:生成订单记录,status=1(已支付)
- 库存库:商品 1 可用库存从 100→98,扣减 2 个
- 账户库:用户 1 余额从 1000→800,扣减 200
- 三个库的 undo_log 表:全局事务提交后,undo_log 已被异步删除,无残留记录
6.4.3 异常回滚测试(核心验证)
放开订单服务中手动抛出异常的代码,模拟库存扣减成功后、余额扣减前出现异常,重启订单服务,再次调用相同接口。
异常返回结果:
bash
订单创建失败:手动触发异常,测试分布式事务回滚回滚效果校验(AT 模式核心能力验证):
- 订单库:无新增订单记录,本地事务回滚成功
- 库存库:商品 1 可用库存仍为 100,扣减操作已通过 undo_log 反向回滚
- 账户库:用户 1 余额仍为 1000,无扣减操作
- 三个库的 undo_log 表:回滚完成后,undo_log 已被清理
通过日志可完整看到回滚流程:异常触发后,TC 向所有已执行的分支下发回滚指令,RM 通过 undo_log 自动生成反向 SQL,完成数据回滚,全程无需业务代码介入,完美实现了分布式事务的原子性。
七、TCC 模式实战:高并发库存扣减场景全流程落地
AT 模式虽零侵入、开发成本低,但在高并发热点数据场景(如秒杀库存、金融账户)中,全局锁竞争会导致性能瓶颈,且无法支持 Redis、MongoDB 等非关系型数据库。而 TCC 模式完全由业务代码控制,无全局锁竞争,性能极强,可覆盖所有复杂业务场景,是大厂高并发核心链路的首选方案。
本次实战我们将库存扣减改造为 TCC 模式,实现AT+TCC 混合模式分布式事务(生产环境最常用方案:常规业务用 AT,热点核心链路用 TCC,兼顾开发效率与性能)。
7.1 前置准备:表结构改造
TCC 模式的核心是资源预留,我们需要改造库存表,新增冻结库存字段,用于 Try 阶段的资源锁定:
sql
-- 库存表新增冻结库存字段
ALTER TABLE `t_storage`
ADD COLUMN `frozen_count` int NOT NULL DEFAULT 0 COMMENT '冻结库存' AFTER `available_count`;
-- 重置测试数据
UPDATE `t_storage` SET available_count=100, frozen_count=0 WHERE product_id=1;三个核心字段的职责划分:
available_count:可用库存,用户可下单的库存,Try 阶段扣减frozen_count:冻结库存,Try 阶段锁定的资源,Confirm 阶段真正扣减、Cancel 阶段释放total_count:总库存,Confirm 阶段最终扣减
同时,在库存库中创建tcc_fence_log表,用于 Seata 内置的 TCC Fence 能力,一键解决幂等、空回滚、悬挂三大问题:
sql
CREATE TABLE IF NOT EXISTS `tcc_fence_log`
(
`xid` VARCHAR(128) NOT NULL COMMENT '全局事务ID',
`branch_id` BIGINT NOT NULL COMMENT '分支事务ID',
`action_name` VARCHAR(64) NOT NULL COMMENT 'TCC接口名称',
`status` TINYINT NOT NULL COMMENT '状态:1=trying,2=committed,3=rollbacked,4=suspended',
`gmt_create` DATETIME(3) NOT NULL COMMENT '创建时间',
`gmt_modified` DATETIME(3) NOT NULL COMMENT '更新时间',
PRIMARY KEY (`xid`, `branch_id`),
KEY `idx_gmt_modified` (`gmt_modified`),
KEY `idx_status` (`status`)
) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4 COMMENT='TCC事务防护表';7.2 TCC 核心接口定义与实现
7.2.1 TCC 接口定义
java
/**
* 库存扣减TCC接口
* 接口需保证全局唯一,二阶段方法名必须与注解中配置完全一致
*/
public interface StorageTccService {
/**
* Try阶段:资源检查与预留
* @TwoPhaseBusinessAction 标记TCC两阶段接口
* name:TCC接口全局唯一名称,不可重复
* commitMethod:二阶段确认方法名,必须与实际方法名完全一致
* rollbackMethod:二阶段回滚方法名,必须与实际方法名完全一致
* useTCCFence=true:开启TCC防护,自动解决幂等、空回滚、悬挂三大问题(生产必开)
* @BusinessActionContextParameter:标记参数,自动传递到二阶段上下文
*/
@TwoPhaseBusinessAction(
name = "storageTccService",
commitMethod = "confirm",
rollbackMethod = "cancel",
useTCCFence = true
)
boolean tryFreezeStorage(BusinessActionContext context,
@BusinessActionContextParameter(paramName = "productId") Long productId,
@BusinessActionContextParameter(paramName = "count") Integer count);
/**
* Confirm阶段:确认提交,真正扣减冻结资源
* 方法名必须与commitMethod一致,入参只能是BusinessActionContext
*/
boolean confirm(BusinessActionContext context);
/**
* Cancel阶段:取消回滚,释放冻结资源
* 方法名必须与rollbackMethod一致,入参只能是BusinessActionContext
*/
boolean cancel(BusinessActionContext context);
}7.2.2 TCC 接口实现
严格遵循 TCC 三阶段职责划分,严禁越界操作:
java
@Slf4j
@Service
public class StorageTccServiceImpl implements StorageTccService {
@Resource
private StorageMapper storageMapper;
/**
* Try阶段:仅做资源检查+预留,不做真正的业务扣减
* 核心:扣减可用库存,增加冻结库存,完成资源锁定
*/
@Override
@Transactional(rollbackFor = Exception.class)
public boolean tryFreezeStorage(BusinessActionContext context, Long productId, Integer count) {
String xid = context.getXid();
log.info("【TCC Try阶段开始】XID:{}, 商品ID:{}, 冻结数量:{}", xid, productId, count);
// 1. 参数校验
if (productId == null || count == null || count <= 0) {
throw new IllegalArgumentException("库存冻结参数异常");
}
// 2. 检查可用库存,执行资源冻结
int rows = storageMapper.freezeStorage(productId, count);
if (rows <= 0) {
log.error("【TCC Try阶段失败】商品库存不足,XID:{}", xid);
throw new RuntimeException("商品可用库存不足");
}
log.info("【TCC Try阶段完成】库存冻结成功,XID:{}", xid);
return true;
}
/**
* Confirm阶段:仅做确认提交,使用Try阶段预留的资源
* 核心:扣减冻结库存,完成真正的业务扣减,必须保证幂等
*/
@Override
@Transactional(rollbackFor = Exception.class)
public boolean confirm(BusinessActionContext context) {
String xid = context.getXid();
log.info("【TCC Confirm阶段开始】XID:{}", xid);
// 从上下文获取Try阶段传递的参数
Long productId = context.getActionContext("productId", Long.class);
Integer count = context.getActionContext("count", Integer.class);
// 确认扣减冻结库存
int rows = storageMapper.confirmDeduct(productId, count);
if (rows <= 0) {
log.warn("【TCC Confirm阶段无数据更新】可能为重复执行,XID:{}", xid);
return true; // 幂等处理,直接返回成功
}
log.info("【TCC Confirm阶段完成】库存扣减成功,XID:{}", xid);
return true;
}
/**
* Cancel阶段:仅做资源释放,回滚Try阶段的操作
* 核心:释放冻结库存,恢复可用库存,必须处理空回滚、幂等、悬挂
*/
@Override
@Transactional(rollbackFor = Exception.class)
public boolean cancel(BusinessActionContext context) {
String xid = context.getXid();
log.info("【TCC Cancel阶段开始】XID:{}", xid);
// 从上下文获取Try阶段传递的参数
Long productId = context.getActionContext("productId", Long.class);
Integer count = context.getActionContext("count", Integer.class);
// 释放冻结库存,恢复可用库存
int rows = storageMapper.unfreezeStorage(productId, count);
if (rows <= 0) {
log.warn("【TCC Cancel阶段无数据更新】可能为空回滚或重复执行,XID:{}", xid);
return true; // TCC Fence已处理空回滚和悬挂,直接返回成功
}
log.info("【TCC Cancel阶段完成】库存冻结已释放,XID:{}", xid);
return true;
}
}7.2.3 Mapper 接口新增 SQL
java
@Mapper
public interface StorageMapper extends BaseMapper<Storage> {
// 原有扣减方法略...
/**
* Try阶段:冻结库存
*/
@Update("UPDATE t_storage SET available_count = available_count - #{count}, frozen_count = frozen_count + #{count} " +
"WHERE product_id = #{productId} AND available_count >= #{count}")
int freezeStorage(@Param("productId") Long productId, @Param("count") Integer count);
/**
* Confirm阶段:确认扣减冻结库存
*/
@Update("UPDATE t_storage SET frozen_count = frozen_count - #{count}, total_count = total_count - #{count} " +
"WHERE product_id = #{productId} AND frozen_count >= #{count}")
int confirmDeduct(@Param("productId") Long productId, @Param("count") Integer count);
/**
* Cancel阶段:释放冻结库存
*/
@Update("UPDATE t_storage SET available_count = available_count + #{count}, frozen_count = frozen_count - #{count} " +
"WHERE product_id = #{productId} AND frozen_count >= #{count}")
int unfreezeStorage(@Param("productId") Long productId, @Param("count") Integer count);
}7.2.4 控制器与 Feign 接口改造
- 库存服务 TCC 控制器
java
@RestController
@RequestMapping("/storage/tcc")
public class StorageTccController {
@Resource
private StorageTccService storageTccService;
@PostMapping("/try")
public ResponseEntity<Boolean> tryFreeze(BusinessActionContext context,
@RequestParam Long productId,
@RequestParam Integer count) {
boolean result = storageTccService.tryFreezeStorage(context, productId, count);
return ResponseEntity.ok(result);
}
}- 订单服务 TCC Feign 接口
java
@FeignClient(value = "storage-service", fallbackFactory = StorageTccFeignFallbackFactory.class)
public interface StorageTccFeignClient {
@PostMapping("/storage/tcc/try")
Boolean tryFreezeStorage(@RequestBody BusinessActionContext context,
@RequestParam("productId") Long productId,
@RequestParam("count") Integer count);
}
@Component
public class StorageTccFeignFallbackFactory implements FallbackFactory<StorageTccFeignClient> {
@Override
public StorageTccFeignClient create(Throwable cause) {
return (context, productId, count) -> {
throw new RuntimeException("库存TCC服务调用异常:" + cause.getMessage(), cause);
};
}
}7.2.5 订单服务改造:AT+TCC 混合模式
java
@Slf4j
@Service
public class OrderServiceImpl extends ServiceImpl<OrderMapper, Order> implements OrderService {
@Resource
private OrderMapper orderMapper;
@Resource
private StorageTccFeignClient storageTccFeignClient;
@Resource
private AccountFeignClient accountFeignClient;
@Override
@GlobalTransactional(name = "order-create-tcc-tx", rollbackFor = Exception.class)
public String createOrder(Long userId, Long productId, Integer count, BigDecimal unitPrice) {
String xid = RootContext.getXID();
log.info("【混合模式全局事务开启】XID:{}", xid);
String orderNo = "ORDER_TCC_" + System.currentTimeMillis() + "_" + userId;
BigDecimal totalAmount = unitPrice.multiply(new BigDecimal(count));
// AT模式:本地创建订单
Order order = new Order();
order.setOrderNo(orderNo);
order.setUserId(userId);
order.setProductId(productId);
order.setCount(count);
order.setAmount(totalAmount);
order.setStatus(0);
orderMapper.insert(order);
log.info("【订单创建成功】订单号:{}", orderNo);
// TCC模式:冻结库存(热点链路)
BusinessActionContext context = new BusinessActionContext();
context.setXid(xid); // 传递全局XID
Boolean tryResult = storageTccFeignClient.tryFreezeStorage(context, productId, count);
if (!tryResult) {
throw new RuntimeException("库存冻结失败:商品库存不足");
}
log.info("【TCC Try阶段完成】库存冻结成功");
// 回滚测试点
// if (true) {
// throw new RuntimeException("手动触发异常,测试TCC混合模式回滚");
// }
// AT模式:扣减账户余额
Boolean accountResult = accountFeignClient.deduct(userId, totalAmount);
if (!accountResult) {
throw new RuntimeException("余额扣减失败:账户余额不足");
}
log.info("【余额扣减成功】用户ID:{}", userId);
// 更新订单状态
order.setStatus(1);
orderMapper.updateById(order);
log.info("【订单状态更新完成】订单号:{}", orderNo);
log.info("【混合模式全局事务完成】XID:{}", xid);
return orderNo;
}
}核心优势:Seata 完美支持 AT+TCC 混合模式,同一个全局事务中,常规业务用 AT 零侵入开发,热点核心链路用 TCC 高性能实现,兼顾开发效率与并发性能,是生产环境的首选方案。
7.3 TCC 模式实战测试
7.3.1 正常流程测试
调用订单接口,正常参数执行后,数据校验结果:
- 订单库:订单创建成功,status=1
- 库存库:可用库存 98,冻结库存 0,总库存 98(Try 冻结的库存已在 Confirm 阶段真正扣减)
- 账户库:余额 800,扣减成功
- tcc_fence_log 表:生成 status=2(committed)的记录,标记 TCC 事务已提交
7.3.2 异常回滚测试
放开手动异常代码,触发全局回滚后,数据校验结果:
- 订单库:无新增订单,AT 分支回滚成功
- 库存库:可用库存 100,冻结库存 0,总库存 100(Try 冻结的库存已在 Cancel 阶段释放)
- 账户库:余额 1000,无扣减
- tcc_fence_log 表:生成 status=3(rollbacked)的记录,标记 TCC 事务已回滚
TCC 模式回滚完美生效,且 Seata 的 TCC Fence 自动解决了幂等、空回滚、悬挂三大问题,无需手动开发复杂的防护逻辑。
八、生产级避坑指南:90% 开发者都会踩的 Seata 坑,全解全破
这部分是本文的核心价值所在,是我 5 年微服务架构、双 11 核心链路踩坑沉淀的生产经验,覆盖 AT/TCC 模式、环境部署、性能优化的全场景坑点,每一个都有可落地的解决方案,帮你避开 90% 的生产事故。
8.1 AT 模式专属避坑指南
坑 1:AT 模式不回滚,90% 开发者都踩过的终极坑
根本原因:
- 数据源未被 Seata 代理,无法拦截 SQL 生成 undo_log
@GlobalTransactional未加rollbackFor = Exception.class,非 RuntimeException 异常不触发回滚- 业务代码捕获异常后未重新抛出,Seata 感知不到异常
- Feign 降级返回默认值,未抛出异常,Seata 判定分支执行成功
- 业务库未创建 undo_log 表,或表结构与官方不一致
- 客户端
tx-service-group与服务端vgroupMapping配置不匹配,无法连接 TC
解决方案:
- SpringBoot 3.0 + 严禁手动配置 DataSourceProxy,避免双重代理导致代理失效;多数据源场景必须将动态数据源交给 Seata 代理
- 必须给
@GlobalTransactional加上rollbackFor = Exception.class,覆盖所有异常场景 - 业务捕获异常后,必须抛出 RuntimeException,严禁静默处理
- Feign 降级逻辑必须抛出异常,不能返回 null/false
- 所有业务库必须创建官方标准的 undo_log 表,不可修改核心字段
- 客户端
tx-service-group必须与服务端service.vgroupMapping.xxx=default中的 xxx 完全一致
坑 2:AT 模式脏写,生产致命数据不一致事故
根本原因:非 Seata 代理的数据源(如 Navicat、DMS、原生 JDBC)修改了业务表,绕过了全局锁检查,导致 Seata 回滚时前后镜像不一致,回滚失败,出现脏写。
解决方案:
- 生产环境严格管控业务表的修改权限,所有操作必须通过 Seata 代理的数据源执行,严禁手动修改业务表数据
- 开启脏写校验:
seata.client.rm.undo.log.validation.enable=true,回滚时自动校验数据是否被篡改 - 核心业务表增加乐观锁 version 字段,避免并发修改
- 配置脏写告警,校验失败时立即触发人工介入
坑 3:热点数据场景全局锁竞争激烈,TPS 上不去
根本原因:AT 模式下,热点数据的全局锁被持有期间,其他事务必须等待,高并发下出现大量锁等待超时,TPS 瓶颈明显。
解决方案:
- 热点数据场景优先切换为 TCC 模式,无全局锁竞争,性能提升 10 倍以上
- 优化锁参数:
seata.client.rm.lock-retry-times=30、seata.client.rm.lock-retry-interval=100,根据业务调整重试策略 - 拆分热点数据,如将单个商品库存拆分为多个分片,减少锁竞争
- 缩短全局事务执行时长,非事务操作放到全局事务之外,减少锁持有时间
坑 4:undo_log 表持续膨胀,数据库性能下降
根本原因:TC / 服务宕机导致 undo_log 未被异步清理,日积月累表数据量过大,影响数据库性能。
解决方案:
- 开启自动清理:
seata.client.rm.undo.log.clean-period=86400000,每天自动清理 7 天前的历史数据 - 手动创建定时任务,定期清理
log_status=0且log_created超过 7 天的记录 - 生产环境对 undo_log 表按时间做分区表,方便历史数据清理
8.2 TCC 模式专属避坑指南
坑 1:幂等、空回滚、悬挂三大问题处理不当,数据不一致
根本原因:网络抖动、服务超时导致 Cancel 比 Try 先执行,或二阶段方法被重复调用,未做防护导致数据重复扣减、资源永久冻结。
解决方案:
- 生产环境必须开启
useTCCFence = true,Seata 自动解决三大问题,无需手动开发 - 低版本 Seata 必须手动实现 TCC 事务控制表,记录分支事务执行状态,执行前先校验状态
- Try/Confirm/Cancel 三个方法必须保证幂等性,严禁重复执行导致数据异常
坑 2:二阶段方法找不到,事务超时回滚失败
根本原因 :@TwoPhaseBusinessAction中的commitMethod/rollbackMethod与实际方法名不一致,或方法参数不符合规范,Seata 无法调用二阶段方法。
解决方案:
- 二阶段方法名必须与注解配置完全一致,包括大小写
- Confirm/Cancel 方法的入参只能是
BusinessActionContext,不能有其他参数 - Try 方法的参数必须加
@BusinessActionContextParameter注解,否则二阶段无法获取参数 - TCC 接口的 name 必须全局唯一,不可与其他接口重名
坑 3:Try 阶段直接执行业务扣减,未做资源预留,回滚失效
根本原因:开发者在 Try 阶段直接扣减可用资源,未做冻结预留,导致 Cancel 阶段无法回滚,数据不一致。
解决方案:
- 严格遵循 TCC 设计原则:Try 仅做资源检查 + 预留,Confirm 才做真正的业务扣减,Cancel 释放预留资源
- 必须通过冻结字段实现资源预留,严禁直接扣减可用资源
坑 4:二阶段执行失败,事务悬挂数据永久不一致
根本原因:Confirm/Cancel 执行失败,Seata 重试多次仍失败,导致事务悬挂,资源永久冻结。
解决方案:
- 配置二阶段重试次数:
seata.client.tm.commit-retry-count=5、seata.client.tm.rollback-retry-count=5 - 生产环境配置事务悬挂告警,二阶段重试失败立即人工介入
- Confirm/Cancel 方法必须保证幂等性,支持重复执行
- 核心业务开发人工补偿接口,自动重试失败时可手动干预
8.3 通用避坑指南(AT/TCC 通用)
坑 1:版本不兼容,服务启动失败、事务不生效
根本原因:Seata 客户端与服务端大版本不一致,SpringCloud Alibaba 与 Seata 版本不匹配,导致类冲突、协议不兼容。
解决方案:
- 严格遵守版本对应关系,客户端与服务端大版本必须完全一致
- 排除 SpringCloud Alibaba 内置的 Seata 依赖,手动引入与服务端版本一致的依赖
- 生产环境严禁使用 SNAPSHOT 版本,必须使用 RELEASE 稳定版
坑 2:TC 单点故障,全系统分布式事务瘫痪
根本原因:生产环境仅部署单节点 TC,节点宕机后所有分布式事务无法执行,系统瘫痪。
解决方案:
- 生产环境必须部署 TC 集群,至少 3 个节点,跨机房部署
- 使用 Nacos 等注册中心实现 TC 服务发现,客户端自动感知节点上下线
- TC 存储使用 MySQL 主从 / MGR 集群,避免数据库单点
- 配置 TC 节点健康检查与宕机告警
坑 3:XID 传递失败,分支事务无法加入全局事务
根本原因:服务间远程调用未传递 XID,下游分支事务无法加入全局事务,导致回滚失效。
解决方案:
- Seata 已内置 Feign/Dubbo 等主流 RPC 框架的 XID 自动传递机制,无需手动处理
- 自定义 HTTP 调用需手动将 XID 放入请求头,下游通过拦截器设置到
RootContext中 - 生产环境打印每个分支的 XID,排查传递失败问题
九、生产级性能优化与高可用最佳实践
9.1 核心性能优化手段
- 模式选型优化:热点链路用 TCC,常规业务用 AT,避免 AT 模式全局锁竞争
- 事务时长优化:缩短全局事务执行时间,非事务操作放到全局事务之外,减少锁持有时间
- 参数调优 :
- 客户端线程池调优:
seata.client.rm.thread-pool.core-pool-size=20、max-pool-size=100 - 开启异步提交:
seata.client.rm.async-commit-buffer-limit=1000,提升 AT 模式提交性能 - 调整全局锁重试参数,减少无效重试的 CPU 消耗
- 客户端线程池调优:
- 数据库优化 :
- undo_log、tcc_fence_log 表必须创建正确的索引,避免慢 SQL
- 大表按时间分区,定期清理历史数据
- 数据库采用主从架构、读写分离,提升性能
- 批量操作优化:避免全局事务中循环执行单条 SQL,优先使用批量操作,减少数据库交互次数
9.2 高可用最佳实践
- TC 集群高可用:至少 3 节点跨机房部署,避免单机房故障
- 注册 / 配置中心高可用:Nacos 集群至少 3 节点,保证服务发现能力稳定
- 存储高可用:TC 数据库采用 MySQL MGR 集群,避免存储单点故障
- 全链路监控告警 :
- 监控 TC 集群节点健康状态、CPU、内存、磁盘 IO
- 监控全局事务成功率、回滚率、平均执行时长
- 监控二阶段重试失败、悬挂事务,立即触发告警
- 监控 undo_log、tcc_fence_log 表数据量
- 容灾降级方案 :
- 核心业务开发降级开关,Seata 集群故障时可降级为本地事务 + 最终一致性方案
- 制定应急预案,TC 集群全宕机时的快速恢复流程
- 定期开展混沌工程演练,模拟 TC 宕机、网络分区等故障,验证系统容灾能力
十、总结
本文从分布式事务的核心痛点出发,深入拆解了 Seata 的核心架构、AT/TCC 模式的底层原理,从环境搭建、全流程实战到生产级避坑指南、高可用最佳实践,完整覆盖了 Seata 从入门到生产落地的全链路内容。
核心要点总结:
- Seata 三大核心组件 TC/TM/RM 是所有模式的基础,TC 是全局事务大脑,TM 是事务发起者,RM 是分支执行者
- AT 模式零侵入、开发成本低,适合 90% 的常规业务场景,核心是 undo_log 自动回滚机制 + 全局锁隔离机制
- TCC 模式高性能、高灵活,适合高并发热点场景与异构数据源场景,核心是 Try-Confirm-Cancel 三阶段设计,必须处理好三大经典问题
- AT+TCC 混合模式是生产环境首选,兼顾开发效率与并发性能
- 生产环境必须严格遵守避坑指南,避免数据不一致的致命事故
- 生产环境必须部署 TC 集群,建立完善的监控告警与容灾方案
结语
如果本文对你有帮助,欢迎点赞、收藏、关注三连,有任何关于 Seata 分布式事务的问题,欢迎在评论区留言,我会一一回复。
如果你在生产环境落地 Seata 的过程中遇到了疑难问题,也可以私信我,我会提供针对性的解决方案。
原创不易,转载请注明出处,感谢大家的支持!