前言
上一篇教程已完成 YOLOv5 v2.0 口罩检测模型训练(mAP@.5 86.5%),彻底解决了环境兼容、版本报错、训练闪退等问题。本文聚焦 全场景口罩检测实操,一次性讲解三种核心用法 ------ 本地图片检测、本地视频检测、摄像头实时识别,全程纯 CPU 运行,无需额外配置,所有命令 / 代码可直接复制,衔接训练成果,快速完成课设、毕设全流程演示,新手零踩坑、零冗余操作。
本文适配 Windows 系统、PyCharm 环境,严格衔接上一篇训练好的口罩模型,不新增任何复杂依赖,手把手教你从 "模型训练完成" 到 "全场景检测落地",实现口罩检测项目闭环。
一、前置准备(必看,确保一次成功)
启动检测前,先确认 3 个核心条件(已完成模型训练的同学可直接跳过):
- 模型就绪:已训练好口罩二分类模型(戴口罩 / 未戴口罩),模型路径固定为:
yolov5\runs\exp13_mask_train_exp\weights\best_mask_train_exp.pt(全程复用,无需重新训练); - 环境正常:已安装 YOLOv5 所有依赖(终端运行
pip install -r requirements.txt),无 numpy、torch 版本报错,之前的np.int兼容问题已修复; - 文件就绪:提前准备好待检测的口罩图片、视频(可选),确保电脑摄像头可用(无遮挡、未被其他软件占用)。
二、全场景检测实现(三种方式,任选其一 / 全部尝试)
方式一:本地图片检测
适合快速验证模型效果,批量检测本地口罩图片,操作最简单,无需复杂设置。
方法 1:命令行运行(无需改代码,零风险)
1.放置图片:将需要检测的口罩图片(格式不限,jpg/png 均可),放入 YOLOv5 目录下的 inference\images 文件夹(原代码默认路径,不用新建);
2.打开终端:PyCharm 底部「Terminal」,确保当前路径为 D:\software\Pycharm\yolov5(yolov5 根目录);
3.复制命令,回车运行(直接运行就行):
python
python detect.py --weights runs/exp13_mask_train_exp/weights/best_mask_train_exp.pt --source inference/images --device cpu --view-img --conf-thres 0.4方法 2:修改代码,一键运行
若想后续点击 "运行" 就检测图片,可修改 detect.py 默认参数,永久生效:
- 打开 detect.py,拉到文件最底部,找到参数定义部分,替换以下 4 行代码:
python
# 1. 权重路径:改为训练好的口罩模型
parser.add_argument('--weights', nargs='+', type=str, default='runs/exp13_mask_train_exp/weights/best_mask_train_exp.pt', help='model.pt path(s)')
# 2. 检测来源:默认检测 inference/images 文件夹下的所有图片
parser.add_argument('--source', type=str, default='inference/images', help='source')
# 3. 运行设备:强制CPU,避免显卡报错
parser.add_argument('--device', default='cpu', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
# 4. 弹窗显示检测结果,方便查看
parser.add_argument('--view-img', action='store_true', help='display results')2.保存代码(Ctrl+S),点击 PyCharm 右上角「运行」,自动检测图片并弹窗显示结果。
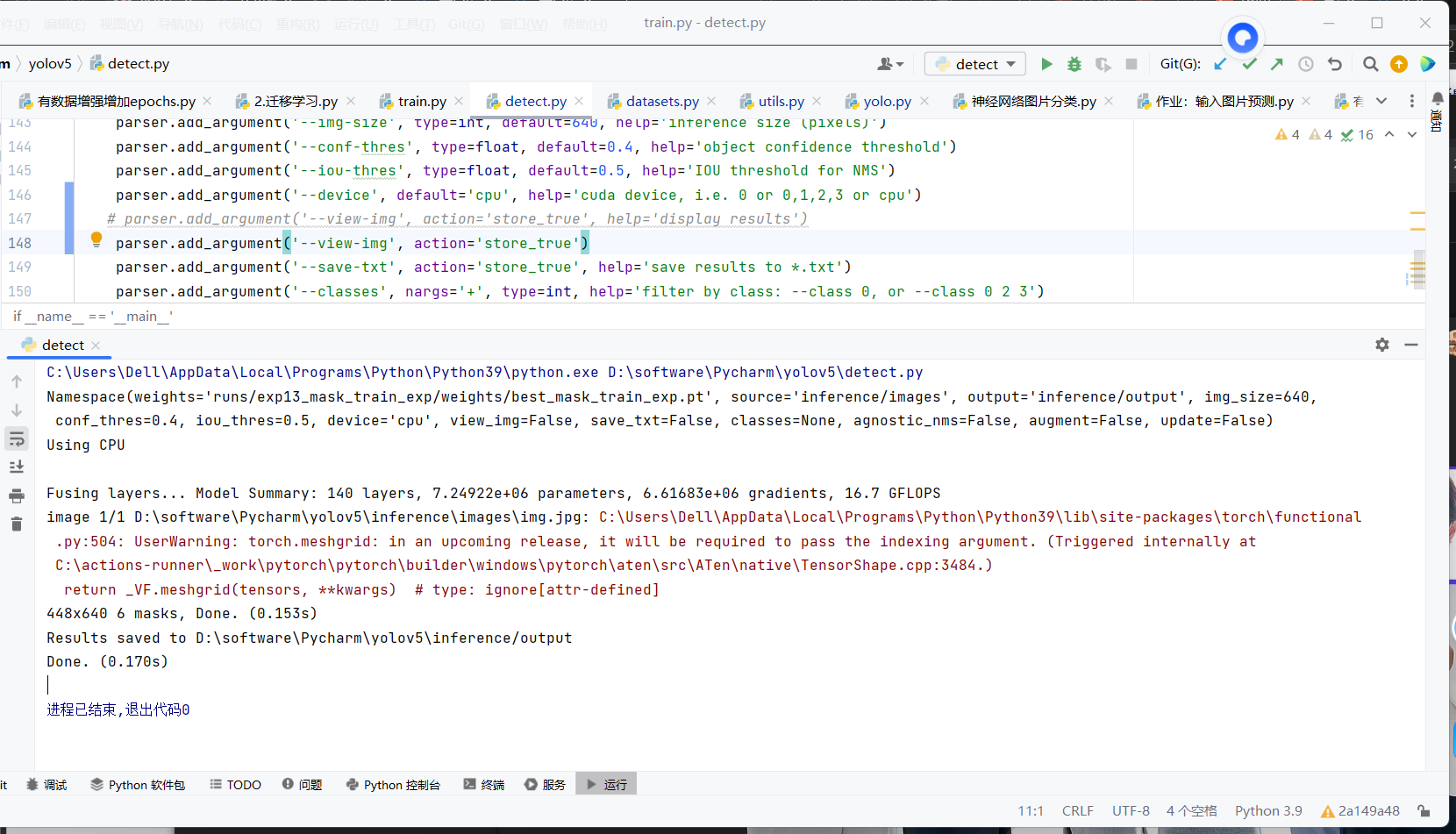
图片检测补充说明
• 检测结果保存:所有画好框、标好类别的图片,自动保存到 yolov5\inference\output 文件夹;
• 批量检测:只需将所有图片放入 inference\images,命令 / 代码无需修改,会自动批量处理;
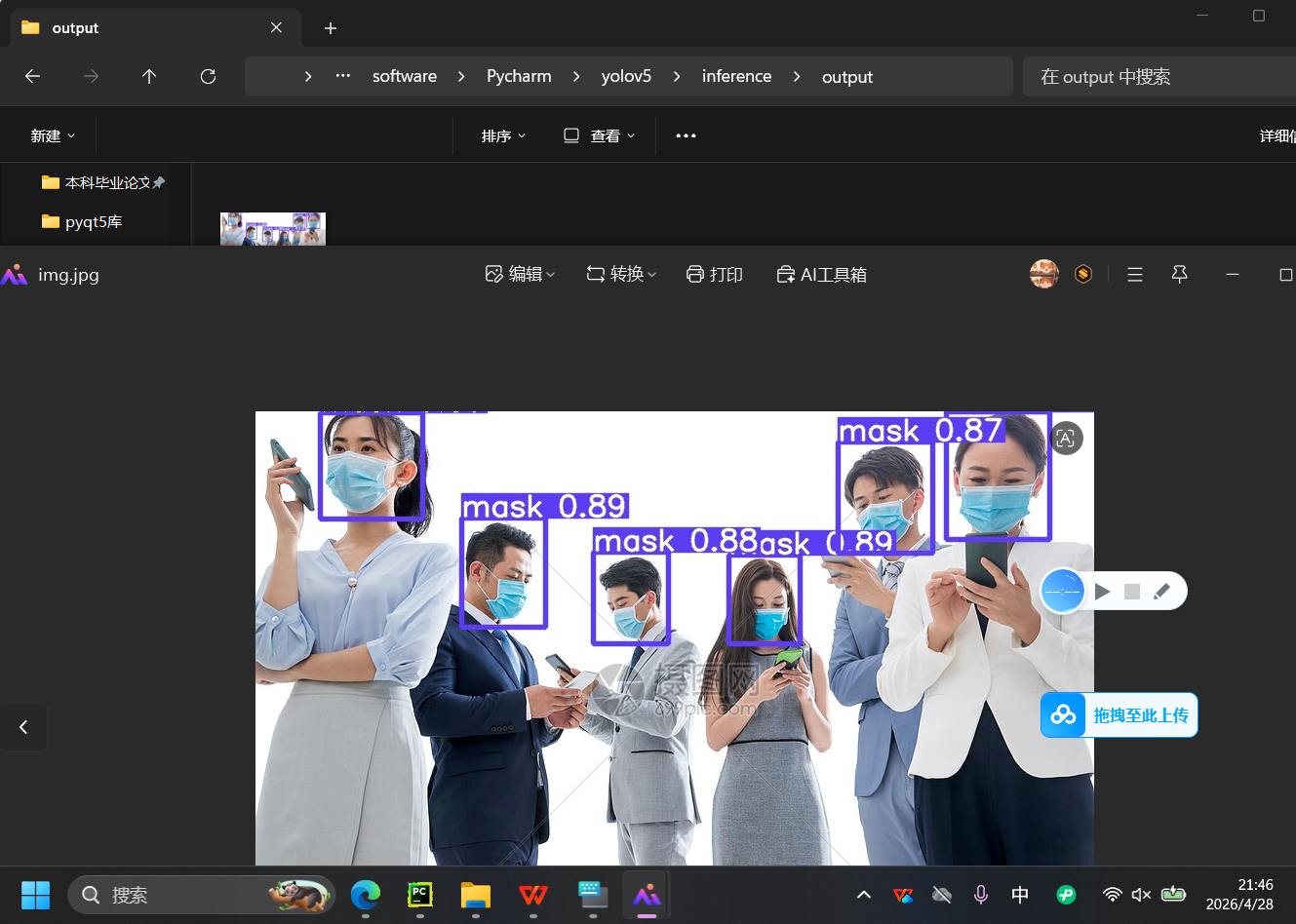
• 识别效果:戴口罩标注 mask + 置信度,未戴口罩标注 no-mask + 置信度,置信度越高,识别越准确。
方式二:本地视频检测
可检测本地口罩相关视频,自动识别视频中每一帧的口罩佩戴情况,生成带检测框的视频文件,适合课设汇报演示。
方法 1:命令行运行(无需改代码)
-
放置视频:将待检测的视频(推荐 mp4 格式),放入 YOLOv5 根目录(与 detect.py 同级);
-
终端输入命令(替换 口罩视频.mp4 为你的视频文件名)
python
python detect.py --weights runs/exp13_mask_train_exp/weights/best_mask_train_exp.pt --source 口罩视频.mp4 --device cpu --view-img --conf-thres 0.4 --save-video方法 2:修改代码,一键检测视频
- 打开 detect.py,修改底部参数(仅改 --source 和 --save-video):
python
# 其他参数不变,仅修改以下2行
parser.add_argument('--source', type=str, default='口罩视频.mp4', help='source') # 替换为你的视频文件名
parser.add_argument('--save-video', action='store_true', help='save video results') # 新增,用于保存检测后的视频保存代码,点击运行,自动启动视频检测。
视频检测补充说明
• 参数 --save-video:核心参数,用于保存检测后的视频(带口罩检测框),不添加则只弹窗显示,不保存;
• 视频保存路径:检测后的视频自动保存到 yolov5\inference\output 文件夹,文件名与原视频一致;
• 格式兼容:优先使用 mp4 格式,其他格式(如 avi、mov)可能出现无法检测的情况,可提前转换格式;
• 运行速度:CPU 运行视频检测会轻微卡顿,属于正常现象,耐心等待即可。
方式三:摄像头实时口罩识别
调用电脑本地摄像头,实时识别画面中人脸的口罩佩戴情况,弹窗显示实时画面,适合现场演示、小型场景部署,是课设 / 毕设的核心展示环节。
方法 1:命令行运行(推荐,无需改代码)
终端复制以下命令,回车直接启动摄像头,无需修改任何代码:
python
python detect.py --weights runs/exp13_mask_train_exp/weights/best_mask_train_exp.pt --source 0 --device cpu --view-img --conf-thres 0.4方法 2:修改代码,一键启动摄像头
- 打开 detect.py,修改底部 3 个核心参数:
python
# 1. 权重路径:训练好的口罩模型
parser.add_argument('--weights', nargs='+', type=str, default='runs/exp13_mask_train_exp/weights/best_mask_train_exp.pt', help='model.pt path(s)')
# 2. 检测来源:0 = 本地默认摄像头(外接摄像头可改为1)
parser.add_argument('--source', type=str, default='0', help='source') # 0 for webcam
# 3. 强制CPU,弹窗显示实时画面
parser.add_argument('--device', default='cpu', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--view-img', action='store_true', help='display results')- 保存代码,点击运行,自动弹出摄像头实时窗口,开始口罩识别。
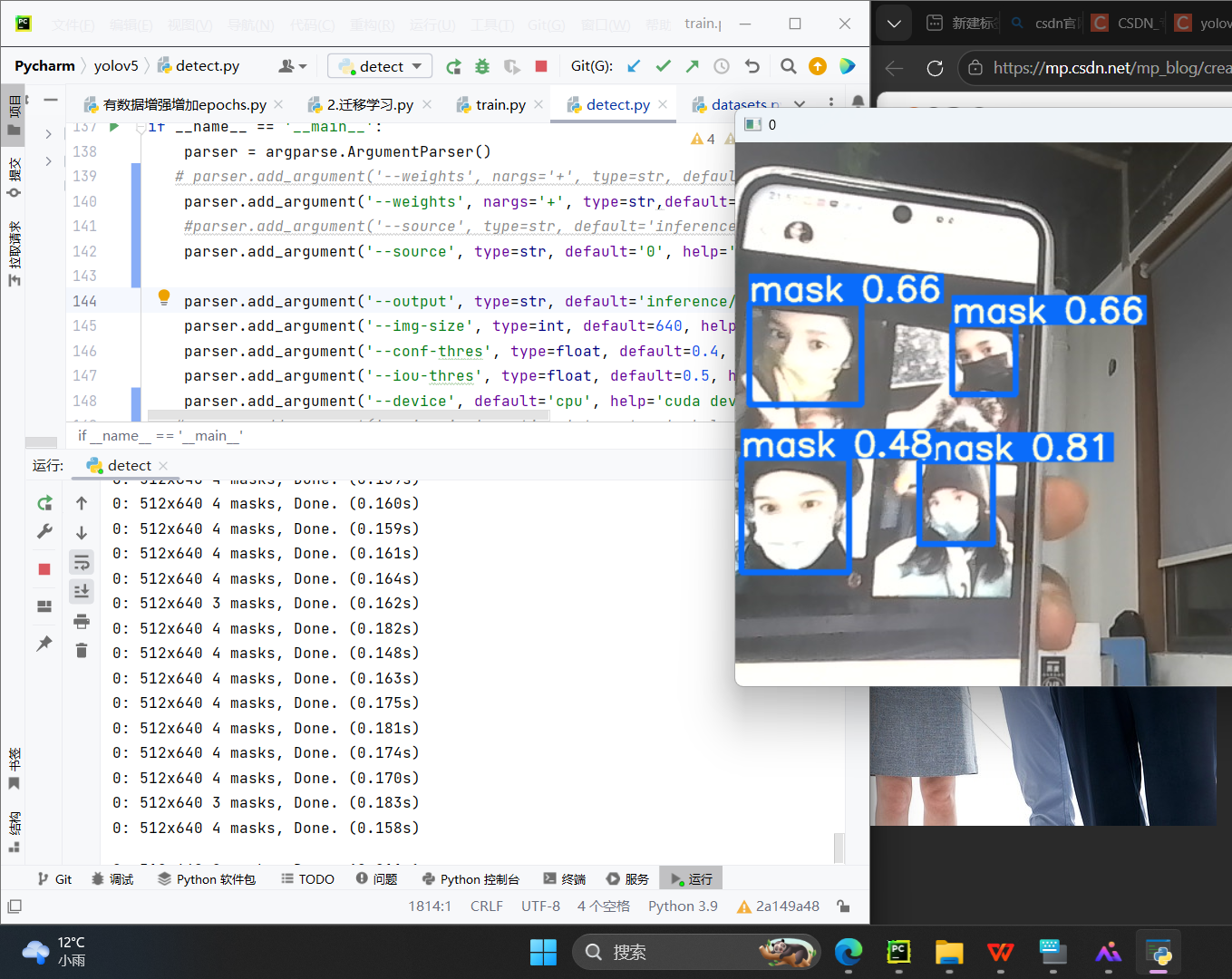
摄像头实时检测使用说明
-
启动后,弹窗显示摄像头画面,人脸进入画面后,自动框选并标注:
- 戴口罩:彩色框 +
mask + 置信度(如 mask 0.92,代表 92% 概率戴口罩); - 未戴口罩:彩色框 +
no-mask + 置信度;
- 戴口罩:彩色框 +
-
退出方式:在摄像头窗口处于激活状态时,按键盘
q键(一定要点击弹窗再按 q,否则无效) -
画面卡顿解决:CPU 算力有限,轻微卡顿正常,可添加参数
--img-size 480降低画面尺寸,提升速度(命令如下)pythonpython detect.py --weights runs/exp13_mask_train_exp/weights/best_mask_train_exp.pt --source 0 --device cpu --view-img --conf-thres 0.4 --img-size 480 -
外接摄像头:若使用 USB 外接摄像头,将 --source 0 改为 --source 1 尝试,若仍无法识别,关闭其他占用摄像头的软件。
三、三种检测方式核心参数统一说明
| 参数 | 作用 | 推荐设置 |
|---|---|---|
--weights |
指定训练好的口罩模型 | 固定为 runs/exp13_mask_train_exp/weights/best_mask_train_exp.pt |
--source |
检测来源 | 图片:inference/images;视频:视频文件名;摄像头:0 |
--device cpu |
运行设备 | 无独立显卡必加,避免报错 |
--view-img |
弹窗显示检测结果 | 建议开启,方便实时查看效果 |
--conf-thres 0.4 |
置信度阈值 | 低于 40% 的检测结果会被过滤,减少误识别 |
--save-video |
保存视频检测结果 | 视频检测必加,图片检测无需添加 |
--img-size 480 |
检测画面尺寸 | 卡顿严重时添加,降低尺寸提升速度 |
四、常见问题排查(新手必看,避坑指南)
1. 检测失败,提示 "模型路径错误"
- 原因:
--weights参数路径写错,或模型文件best_mask_train_exp.pt不存在; - 解决:核对模型路径,确保路径为
runs/exp13_mask_train_exp/weights/best_mask_train_exp.pt,若路径不一致,修改命令 / 代码中的路径。
2. 图片 / 视频无法检测,提示 "no images/video found"
- 原因:图片 / 视频放置路径错误,或文件名包含中文、特殊字符;
- 解决:图片放入
inference/images,视频放入 yolov5 根目录,文件名改为英文(如mask_video.mp4),避免空格、中文。
3. 摄像头黑屏 / 打不开
- 原因 1:摄像头被微信、浏览器、钉钉等软件占用;
- 解决 1:关闭所有占用摄像头的软件,重新运行命令 / 代码;
- 原因 2:电脑未允许应用访问摄像头;
- 解决 2:Windows 设置 → 隐私和安全性 → 摄像头 → 开启 "允许应用访问你的摄像头",并允许 PyCharm 访问。
4. 误识别严重(将其他物体识别为口罩)
- 原因:置信度阈值太低,或训练数据集有限;
- 解决:将
--conf-thres 0.4改为0.5,过滤低概率误识别结果;若仍有问题,可补充口罩训练数据,重新训练模型。
5. 运行报错 "no module named xxx"
- 原因:依赖库未安装完整,或环境冲突;
- 解决:终端运行
pip install -r requirements.txt,重新安装所有依赖,确保 Python 版本为 3.9(兼容性最佳)。
五、项目完整闭环总结
到本文为止,我们的 YOLOv5 口罩检测项目已实现全流程闭环,从基础准备到全场景落地,全程纯 CPU 运行,新手可 1:1 复刻:
- 前期准备:数据集制作(口罩图片 + 标签)→ YOLOv5 v2.0 环境搭建 → 模型训练(mAP@.5 86.5%);
- 全场景检测:本地图片检测 → 本地视频检测 → 摄像头实时识别;
- 核心优势:操作简单、无需独立显卡、所有命令 / 代码可直接复制、报错可快速排查,完美适配课程设计、毕业设计、小型场景演示。
六、拓展建议
- 录制实时检测视频:摄像头检测时,添加
--save-video参数,可录制实时检测画面,保存到inference/output,方便汇报演示; - 批量处理图片 / 视频:图片检测时,将所有图片放入
inference/images;视频检测时,可批量修改--source参数,一次性处理多个视频; - 提升检测速度:若有独立显卡,删除命令 / 代码中的
--device cpu,自动调用 GPU 运行,检测速度提升 5-10 倍; - 优化识别精度:补充更多不同场景的口罩图片(如不同光线、不同角度),重新训练模型,进一步提升识别准确率。
结尾
本文详细讲解了 YOLOv5 口罩检测的三种核心场景,衔接上一篇模型训练教程,实现从 "训练" 到 "落地" 的完整闭环。所有操作均经过实操验证,新手跟着步骤走,无需复杂调试,就能快速完成全场景口罩检测。若遇到其他报错或疑问,可在评论区留言,及时排查解决,助力大家顺利完成课设、毕设!