基于YOLO+Flask+FastAdmin打造通用目标检测系统
一套代码,适配所有YOLO检测项目------图片、视频、摄像头全覆盖,还带完整后台管理。
前言
目标检测是计算机视觉领域的热门方向,但许多开发者都会遇到同一个痛点:训练好的YOLO模型如何快速落地成一个可用的系统?如何让非技术人员也能方便地使用、管理和查看检测记录?
本文介绍的系统正是为了解决这些问题而设计。基于 YOLO + Flask + FastAdmin 技术栈,实现了一个通用性极强的目标检测平台。你只需要在后端配置好不同的模型权重,前端改个名字,就能瞬间将"车辆检测系统"变成"水果检测系统"或"缺陷检测系统"。
下面我们一起来看看这个系统的完整功能。
一、系统架构概览
系统的技术选型非常清晰:
- 前端:FastAdmin ------ 基于ThinkPHP+Bootstrap的后台管理框架,快速搭建美观的管理界面。
- 后端:Flask ------ 提供RESTful API接口,负责调用YOLO模型进行推理。
- 检测核心:YOLO系列(YOLOv5/v8/v9等均可适配)。
用户通过前端上传图片/视频,Flask接口接收后调用YOLO处理,再将结果返回前端展示。所有检测记录、用户管理、统计分析都集成在FastAdmin后台中。
插图:系统登录界面

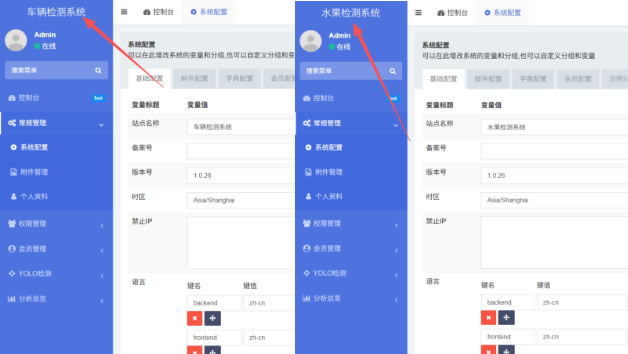
二、通用性设计:一套系统,N种场景
这套系统最大的亮点在于通用性。
当你训练好一个新的YOLO模型(比如用于检测苹果、香蕉、橙子),只需要:
- 将模型权重文件放入Flask后端指定目录。
- 在前端后台修改系统名称,例如将"车辆检测系统"改为"水果检测系统"。
- 刷新页面 ------ 整个界面标题、图标、描述都会同步更新,检测逻辑自动适配新模型。
不需要修改任何前端代码,不需要重启服务。真正做到了"一次开发,到处复用"。
插图:系统名称修改前后对比图
(左侧为车辆检测系统界面,右侧为水果检测系统界面)
三、用户与权限管理
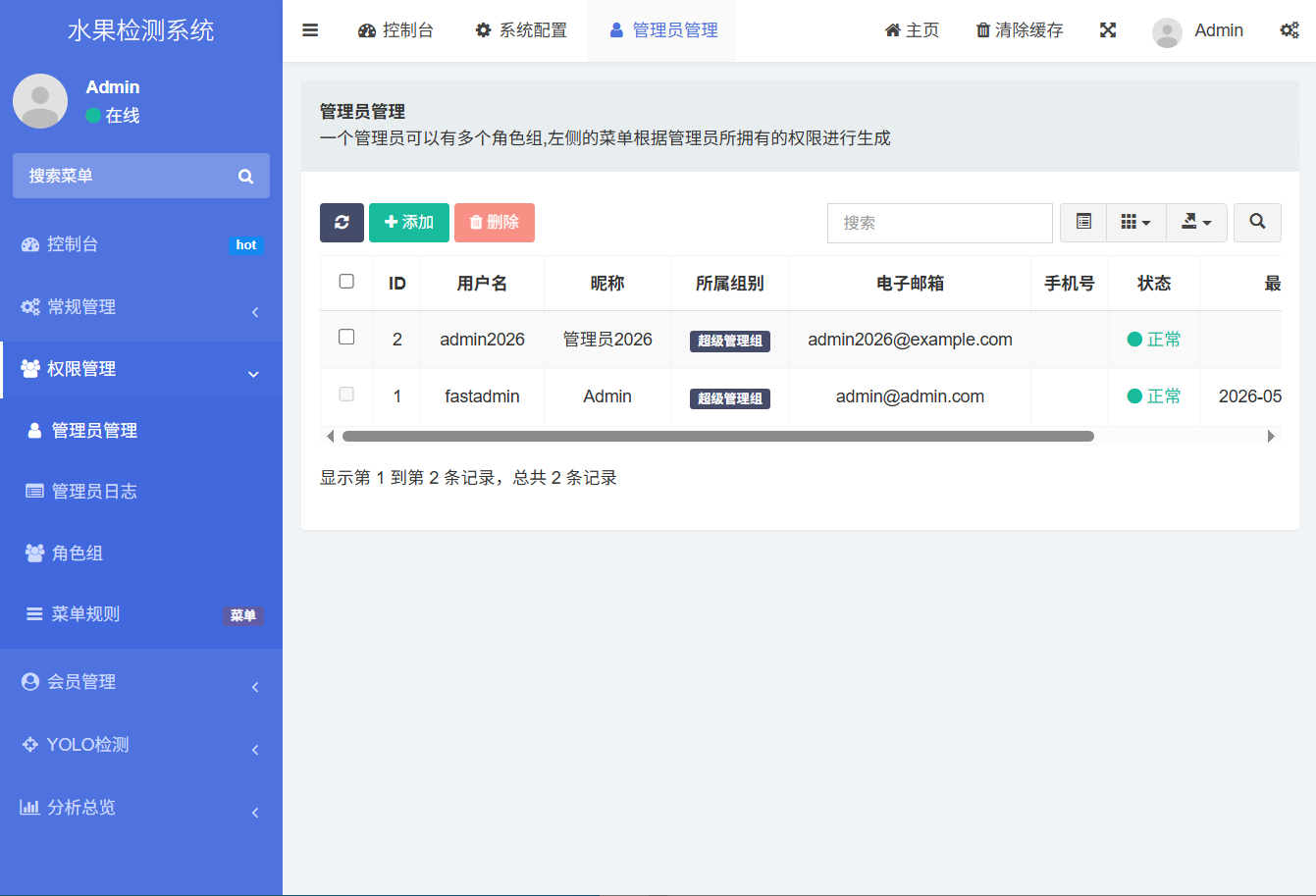
系统内置了完善的管理员账户体系。管理员可以:
- 创建、删除用户账号
- 设置不同用户的权限(如只能检测,不能查看记录等)
- 其他用户使用自己的账号登录后,同样可以使用全部检测功能,各自的检测记录相互隔离(或按需求共享)。
插图:用户管理页面截图
四、检测模块详解
检测模块是整个系统的核心,支持三种输入方式:图片检测 、视频检测 、摄像头实时检测。
1. 图片检测
操作流程非常简单:
- 点击上传按钮,选择一张本地图片。
- 点击"开始检测"。
- 图片通过HTTP请求发送到Flask后端,YOLO模型进行推理。
- 检测结果(带边界框和标签的图片)返回前端并显示。
右侧面板会同步展示检测到的目标类别、数量、置信度等信息。
插图:图片检测界面
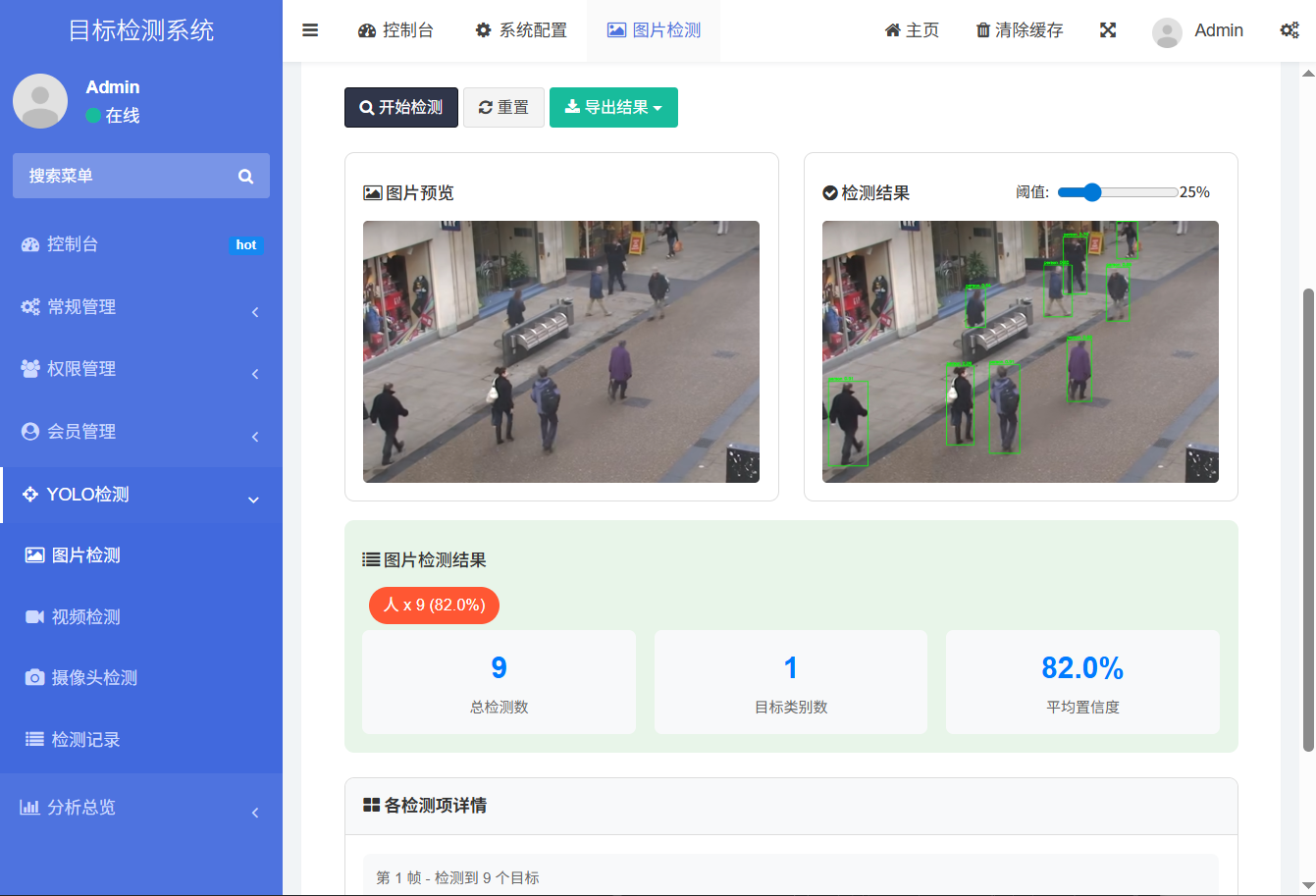
实际测试中,上传一张包含多个物体的图片,系统能快速准确地框出所有目标,效果令人满意。
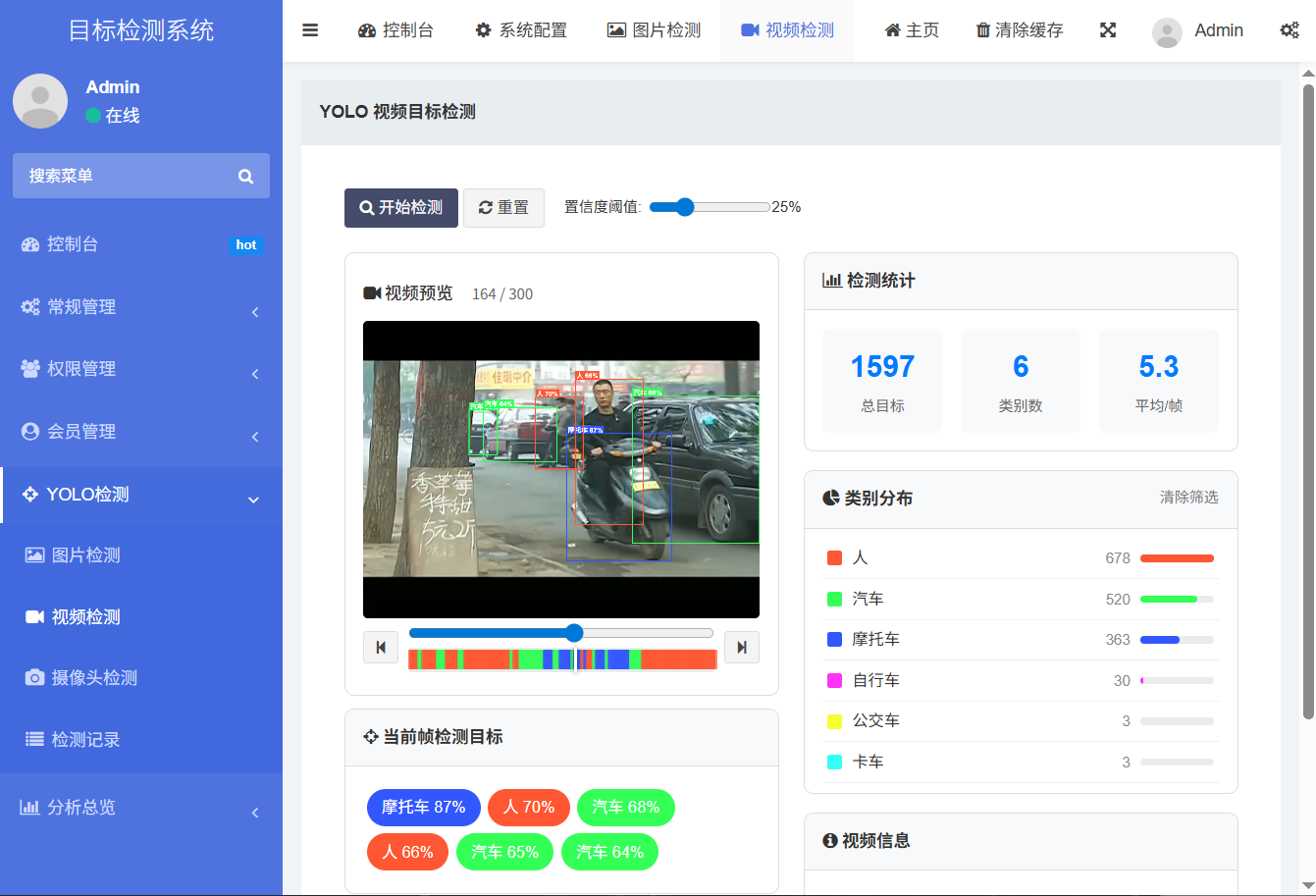
2. 视频检测
视频检测功能更为强大。上传一个MP4/AVI等格式的视频文件后,后端会逐帧处理,并将带有检测框的结果视频返回前端。
视频播放器支持进度条拖拽,你可以随意拖动查看每一帧的检测情况。更智能的是,右侧的"类别分布"面板会统计视频中出现的所有目标类别及其数量。
你可以点击任意类别进行筛选 ------ 比如只勾选"person",那么拖动进度条时,视频画面上只会显示"person"的检测框,其他类别框会被隐藏。这对于分析特定目标的出现规律非常实用。
插图:视频检测界面 + 类别筛选面板
3. 摄像头实时检测
系统会自动检测电脑上可用的摄像头设备,你可以在下拉菜单中选择想要使用的摄像头(例如内置摄像头或外接USB摄像头)。
点击"开启检测"后,实时视频流会逐帧送入YOLO模型进行推理,画面中实时显示检测框。检测过程中,点击"保存快照"按钮,当前帧的检测结果图片会被保存到系统记录中。
五、检测记录与详情管理
所有检测操作(图片、视频、摄像头快照)都会被自动记录下来,存放在"检测记录"模块中。
每条记录包含:
- 检测时间
- 检测类型(图片/视频/摄像头)
- 检测到的所有目标统计
- 原始文件缩略图
- 操作按钮(查看详情、删除等)
点击"查看详情"可以进入一个专门的详情页,里面展示检测结果大图/视频,以及该次检测的完整JSON数据(边界框坐标、类别、置信度等)。
插图:检测记录列表页
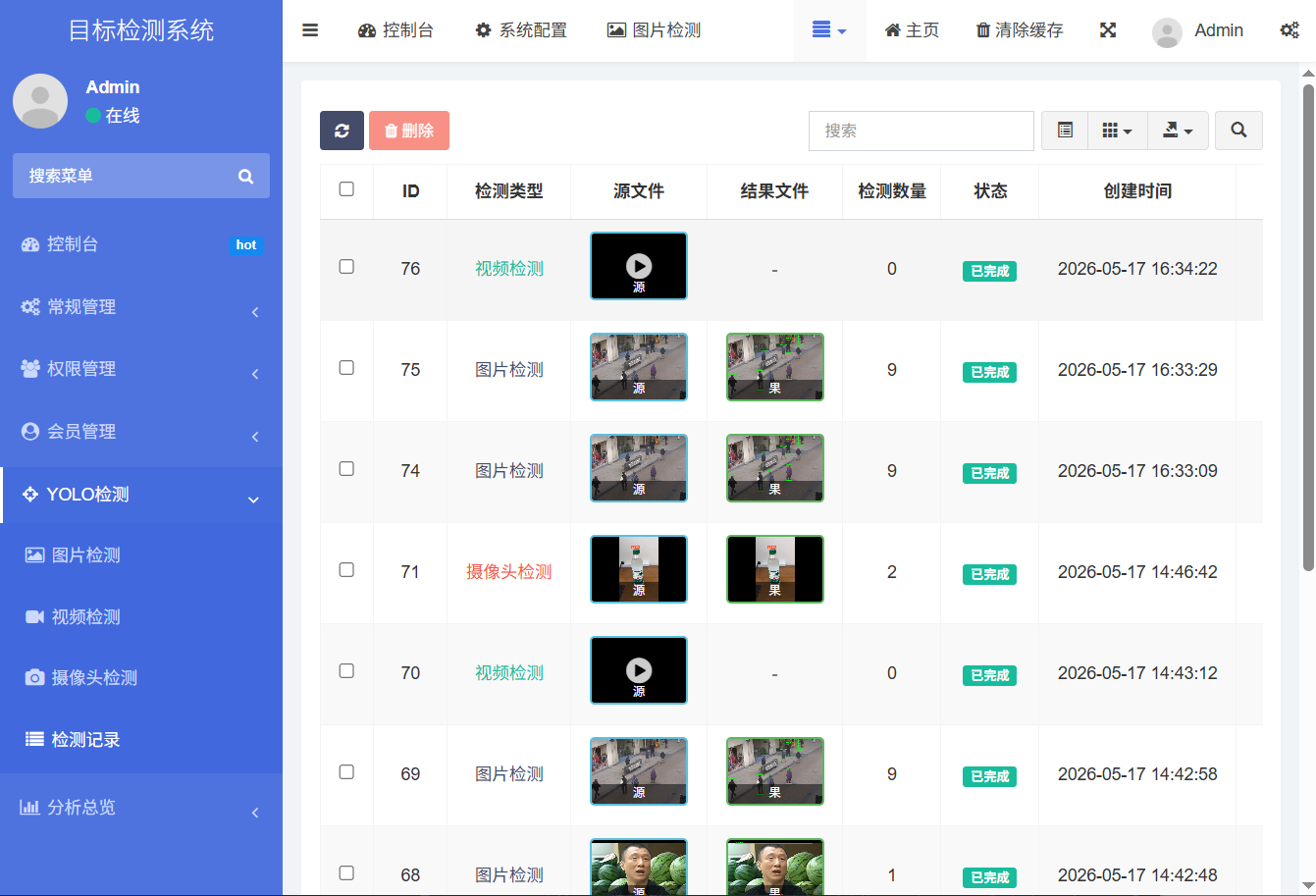
之前通过图片检测和摄像头快照保存的图片,都会整齐地列在这里,方便回溯。
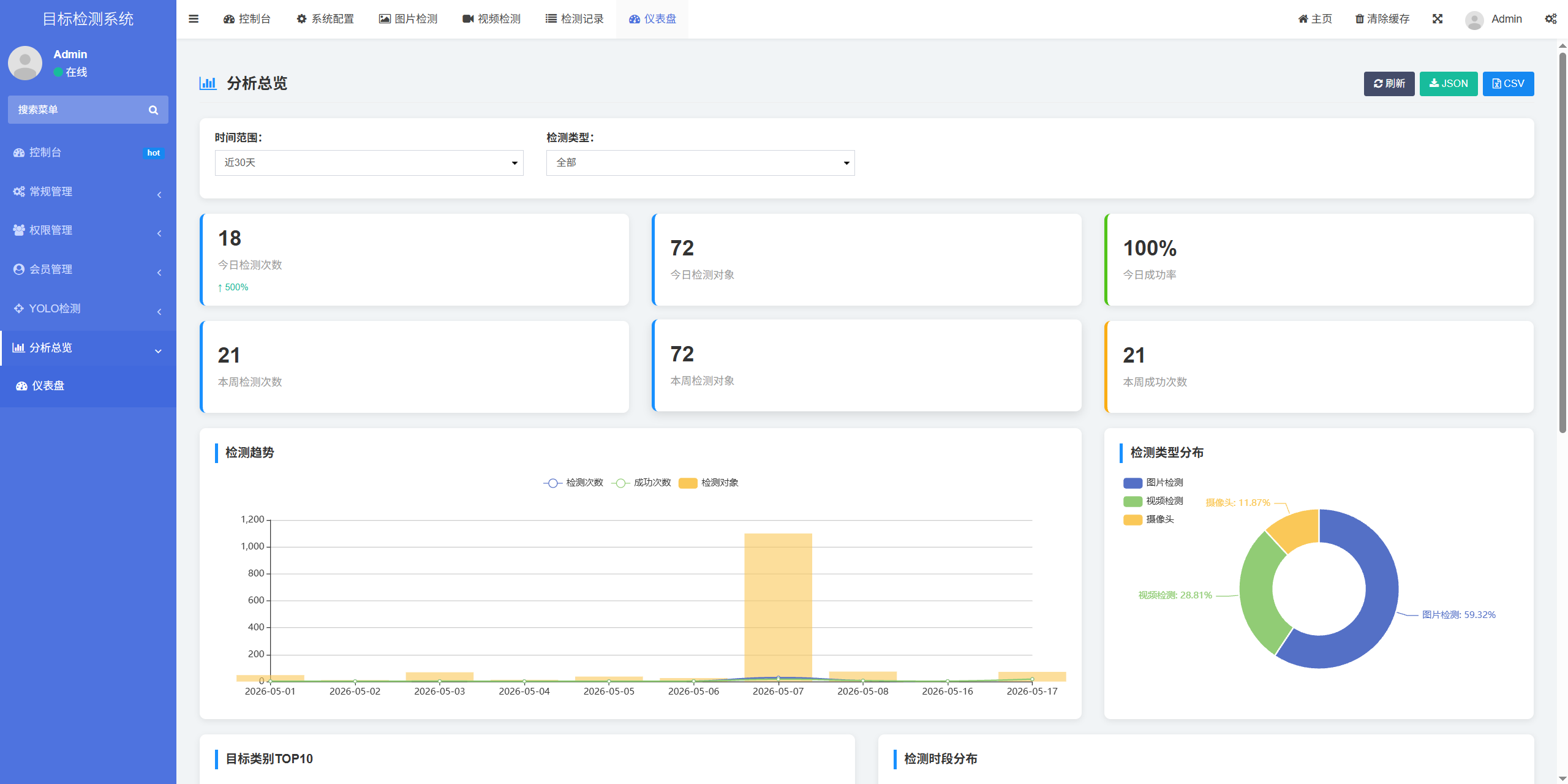
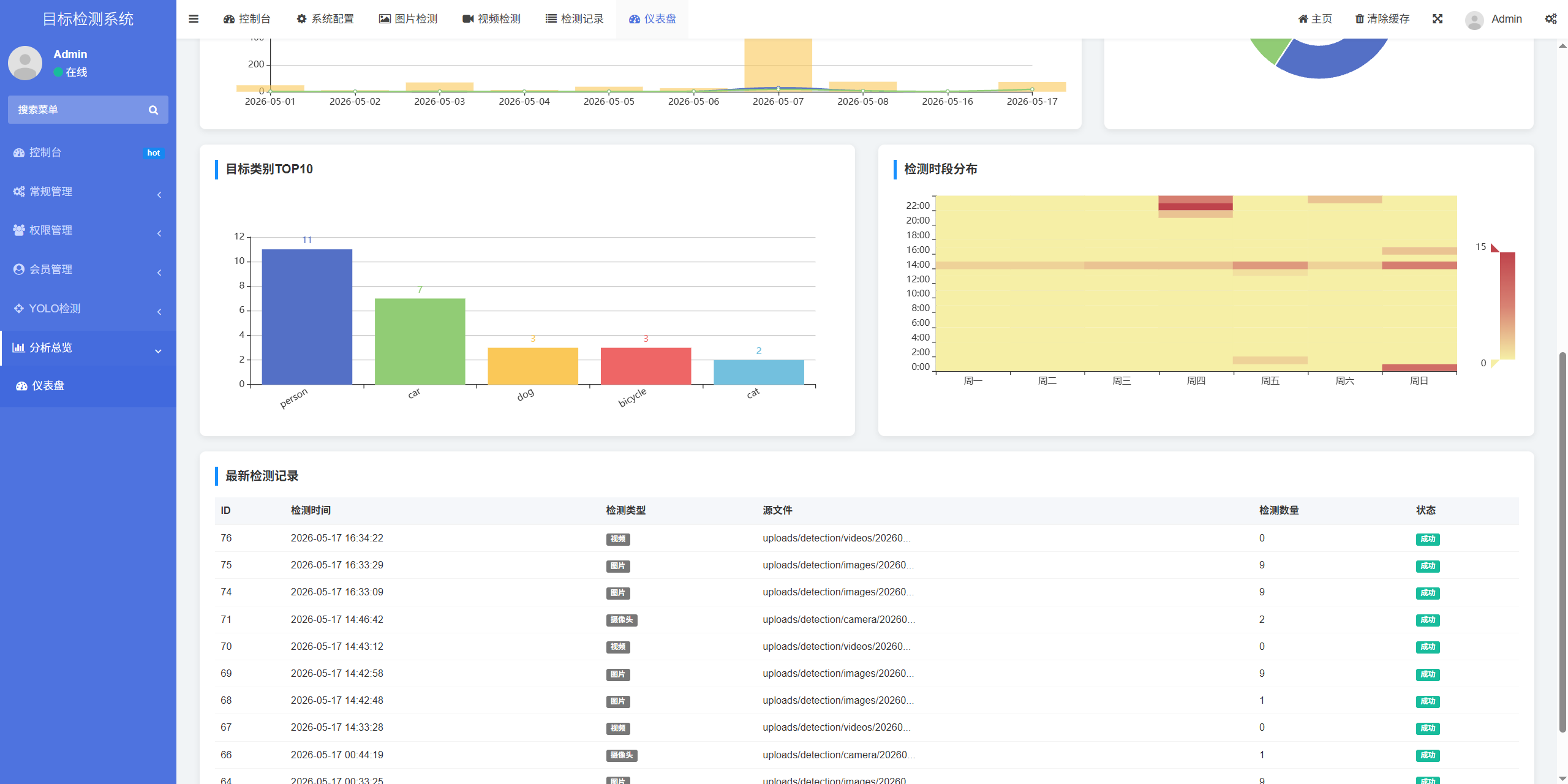
六、分析总览:系统运行仪表盘
"分析总览"模块是给管理员看的全局统计面板。这里展示了整个系统的使用情况:
- 时间趋势图:按日/周/月统计检测次数,可以看出系统在什么时间段最活跃。
- 目标检测排行榜:所有检测中,各类目标被识别到的总次数(例如"car"出现了1200次,"person"出现了800次)。
- 检测记录汇总:总检测次数、涉及用户数、模型调用成功率等指标。
通过这些数据,管理员可以了解系统的使用热度,也可以为后续模型优化提供方向(比如某种目标频繁被误检,说明该类别需要增加训练样本)。
插图:分析总览仪表盘
八、如何获取与部署
博客简介可以找到我
或
点我!找我到
Flask后端接口代码
python
import os
import uuid
import time
import threading
from flask import Flask, request, jsonify, Response
import cv2
import numpy as np
from detector import YOLODetector
from utils import save_uploaded_file, draw_bboxes
from tasks import process_video_async, task_status
from config import Config
app = Flask(__name__)
app.config.from_object(Config)
detector = YOLODetector() # 全局单例
# 创建所需文件夹
os.makedirs(Config.UPLOAD_FOLDER, exist_ok=True)
os.makedirs(Config.STATIC_FOLDER, exist_ok=True)
# ---------- 图片识别 ----------
@app.route('/api/detect/image', methods=['POST'])
def detect_image():
if 'file' not in request.files:
return jsonify({"success": False, "message": "No file part"}), 400
file = request.files['file']
if file.filename == '':
return jsonify({"success": False, "message": "No selected file"}), 400
ext = file.filename.rsplit('.', 1)[1].lower()
if ext not in app.config['ALLOWED_EXTENSIONS']:
return jsonify({"success": False, "message": "Invalid image format"}), 400
# 保存原始图片
src_path = save_uploaded_file(file, Config.UPLOAD_FOLDER, prefix="img_")
img = cv2.imread(src_path)
if img is None:
os.remove(src_path)
return jsonify({"success": False, "message": "Cannot read image"}), 400
# 检测
detections = detector.detect(img)
# 画框并保存
annotated = draw_bboxes(img, detections)
out_filename = f"annotated_{uuid.uuid4().hex}.jpg"
out_path = os.path.join("uploads/detection/results", out_filename)
cv2.imwrite(out_path, annotated)
# 清理临时文件
os.remove(src_path)
print({
"success": True,
"data": {
"detections": [{"frame_id": 0, "objects": detections}],
"image_url": out_path
}
})
return jsonify({
"success": True,
"data": {
"detections": [{"frame_id": 0, "objects": detections}],
"image_url": out_path
}
})
# ---------- 摄像头帧检测 ----------
@app.route('/detection/api/camera_frame', methods=['POST'])
def detect_camera_frame():
timestamp = int(time.time())
if 'frame' not in request.files:
return jsonify({
"code": 0,
"msg": "请上传帧图片文件",
"time": timestamp,
"data": {}
})
frame_file = request.files['frame']
if frame_file.filename == '':
return jsonify({
"code": 0,
"msg": "请上传帧图片文件",
"time": timestamp,
"data": {}
})
# 解析 confidence 参数
confidence_str = request.form.get('confidence', '0.25')
try:
confidence_threshold = float(confidence_str)
if not (0.0 <= confidence_threshold <= 1.0):
raise ValueError()
except (ValueError, TypeError):
return jsonify({
"code": 0,
"msg": "confidence 参数格式错误,应为0~1之间的浮点数",
"time": timestamp,
"data": {}
})
# 读取图片
img_bytes = np.frombuffer(frame_file.read(), dtype=np.uint8)
img = cv2.imdecode(img_bytes, cv2.IMREAD_COLOR)
if img is None:
return jsonify({
"code": 0,
"msg": "无法解析图片,请确认上传的是有效的JPEG图片",
"time": timestamp,
"data": {}
})
# 检测
start_time = time.time()
all_detections = detector.detect(img)
inference_time = time.time() - start_time
# 按 confidence 阈值过滤
filtered_objects = [
{
"label": d["label"],
"confidence": round(d["confidence"], 4),
"bbox": d["bbox"]
}
for d in all_detections
if d["confidence"] >= confidence_threshold
]
return jsonify({
"code": 1,
"msg": "检测完成",
"time": timestamp,
"data": {
"objects": filtered_objects,
"count": len(filtered_objects),
"inference_time": round(inference_time, 3)
}
})
# ---------- 视频识别(异步)----------
@app.route('/detection/api/video', methods=['POST'])
def detect_video():
if 'file' not in request.files:
return jsonify({"code": 0, "message": "No file part"}), 400
file = request.files['file']
if file.filename == '':
return jsonify({"code": 0, "message": "No selected file"}), 400
ext = file.filename.rsplit('.', 1)[1].lower()
if ext not in ['mp4', 'avi', 'mov']:
return jsonify({"code": 0, "message": "Invalid video format"}), 400
task_id = uuid.uuid1().hex
video_path = save_uploaded_file(file, Config.UPLOAD_FOLDER, prefix=f"video_{task_id}_")
# 启动后台线程处理视频
thread = threading.Thread(target=process_video_async, args=(task_id, video_path))
thread.daemon = True
thread.start()
return jsonify({
"code": 1,
"data": {
"task_id": task_id,
"log_id": 1
}
})
@app.route('/detection/api/task', methods=['GET'])
def get_task_status():
task_id = request.args.get('task_id')
if not task_id:
return jsonify({"code": 0, "message": "Missing task_id"}), 400
result = task_status(task_id)
return jsonify({"code": 1, "data": result})
# ---------- 监控流(MJPEG 方式)----------
@app.route('/api/monitor/stream')
def monitor_stream():
stream_url = request.args.get('url', '0')
def generate():
cap = cv2.VideoCapture(stream_url)
while True:
success, frame = cap.read()
if not success:
break
detections = detector.detect(frame)
annotated = draw_bboxes(frame, detections)
ret, jpeg = cv2.imencode('.jpg', annotated)
yield (b'--frame\r\n'
b'Content-Type: image/jpeg\r\n\r\n' + jpeg.tobytes() + b'\r\n')
cap.release()
return Response(generate(), mimetype='multipart/x-mixed-replace; boundary=frame')
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000, debug=True)FastAdmin + YOLO 目标检测系统
系统简介
本系统是一套基于 FastAdmin 前端框架与 Flask + YOLO 深度学习模型构建的智能目标检测平台。系统集成图片检测、视频检测、摄像头实时检测等多种识别能力,适用于安防监控、工业质检、智能零售、车辆识别等多种应用场景。用户可通过 FastAdmin 管理后台轻松上传图片或视频,获取可视化检测结果。
技术栈
后端
| 技术 | 说明 |
|---|---|
| Flask | 轻量级 Python Web 框架,提供 RESTful API 接口 |
| YOLOv8/v11/v26 | Ultralytics 开源的目标检测模型,支持多种场景下的物体识别 |
| OpenCV | 计算机视觉库,用于图像/视频处理及检测结果可视化 |
| NumPy | 数值计算库,处理图像数据 |
| Threading | Python 多线程,支持视频异步处理 |
前端
| 技术 | 说明 |
|---|---|
| FastAdmin | 基于 ThinkPHP + Bootstrap 的后台管理框架 |
| HTML5 + JavaScript | 页面交互与 AJAX 请求 |
| jQuery | 简化 DOM 操作与异步通信 |
部署
| 技术 | 说明 |
|---|---|
| Python 3.x | 后端运行环境 |
| FFmpeg | 视频处理(可选) |
系统功能
1. 图片检测
- 支持上传 JPG、PNG、JPEG 格式图片
- 自动识别图中物体并返回类别、置信度、位置坐标
- 返回标注后的图片,可视化展示检测框
2. 视频检测(异步处理)
- 支持 MP4、AVI、MOV 格式视频上传
- 后台异步逐帧检测,不阻塞前端操作
- 支持进度查询,实时反馈处理状态
- 生成带检测框的标注视频
3. 摄像头实时检测
- 支持本地摄像头及 RTSP 网络摄像头
- 单帧图片快速检测,适合与前端视频流配合使用
- 可调节置信度阈值,过滤低质量检测结果
- 返回推理耗时,便于性能评估
4. 监控流识别
- MJPEG 实时视频流输出
- 每帧自动检测并绘制边界框
- 前端通过 img 标签直接展示,无需额外插件
系统特点
高精度目标检测
- 采用 YOLO 系列深度学习模型,支持 80+ 类物体识别
- 可配置置信度阈值(默认 0.5)和 IOU 阈值(默认 0.45)
- 支持模型热切换,可根据场景选择不同精度的模型
异步处理机制
- 视频检测采用后台线程处理,不占用 HTTP 请求周期
- 支持多任务并发处理,用户可同时提交多个视频检测任务
- 进度实时查询,便于用户了解处理状态
灵活的部署方式
- 前后端分离架构,Flask API 可独立部署
- 支持 CPU/GPU 切换部署,适配不同硬件环境
- 提供 MJPEG 流接口,支持与第三方监控系统集成
简单易用的管理界面
- 集成于 FastAdmin 后台,无需单独开发管理界面
- 支持文件上传、进度查看、结果展示一体化操作
- 检测结果以表格和可视化图片/视频形式呈现
目录结构
flask-detection/
├── app.py # Flask 主应用,定义所有 API 接口
├── detector.py # YOLO 检测器封装(单例模式)
├── tasks.py # 视频异步处理任务
├── utils.py # 工具函数(文件保存、绘制边框)
├── config.py # 配置文件
├── uploads/ # 上传文件目录
├── static/ # 静态资源目录
└── yolo*.pt # YOLO 模型文件