RAG 知识库质检:三级 Gate 如何拦截垃圾知识
从自动检查到人工确认,我们怎么防止"垃圾知识"混进生产环境。自动通过率 73%,拒绝率 5%。
📖 系列阅读地图
| 序号 | 文章 | 内容 | 状态 |
|---|---|---|---|
| ① | 《企业级 Agent 自研复盘》 | 技术选型决策:10 个关键决策与真实成本 | 已发布 |
| ② | 本文 | 知识入库前的质量 Gate:三级审核机制 | 新发布 |
| ③ | 《ReAct Agent 从零实现》 | Java 构建企业级 Agent 的完整架构 | 已发布 |
| ④ | 《RAG 准确率三级跳》 | 检索优化:30%→87% 的完整过程 | 已发布 |
本文是系列第二篇,讲知识进入向量库之前的"质量关卡"。建议先读系列第四篇《RAG 准确率三级跳》,了解数据清洗流水线。
引言:清洗之后,为什么还要审核?
这个系列的前两篇文章讲了 Agent 怎么"长脑子"(ReAct 推理循环)和怎么"记东西"(RAG 检索优化,准召率 70%→87%)。但有一个问题一直没回答:知识是怎么进入向量库的?
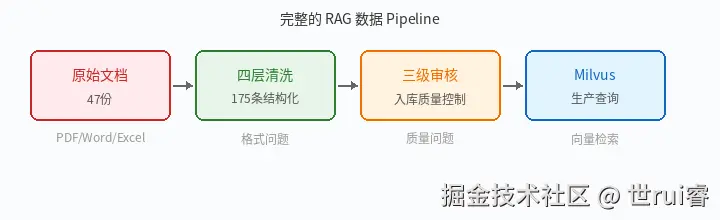
答案是:先经过四层清洗流水线,再经过三级审核机制。
- 四层清洗(系列第四篇已讲):47 份原始文档 → 175 条结构化知识。解决的是"格式问题"------PDF 怎么解析、Excel 表头怎么探测、Word 怎么按标题切分。
- 三级审核(本文):175 条知识 → 过滤掉矛盾、错误、低质量内容。解决的是"质量问题"------文档 A 说"默认值为 true",文档 B 说"默认值为 false",清洗不会发现这个矛盾,但审核会。
完整的 RAG 数据 pipeline:
一、问题:为什么需要质检?
三个真实场景。
场景 1:知识矛盾
arduino
文档A(旧版手册):"参数默认值为 true"
文档B(新版手册):"参数默认值为 false"
用户问:"参数默认值是什么?"
AI 可能引用任意一个,给出错误答案。场景 2:过时知识
arduino
文档:"系统 V1.0 操作步骤"
实际:已升级到 V2.0
AI 按 V1.0 回答,用户操作后出错。场景 3:低质量入库
arduino
录入内容:"这个问题很好"
实际:没有具体问题,没有可检索价值
这种内容无法被有效检索,纯占存储空间。核心洞察 :RAG 有个前提假设------召回的文档是准确、相关、无矛盾的。但现实中这个假设经常不成立。质检不是可选功能,是企业级 RAG 的刚需。
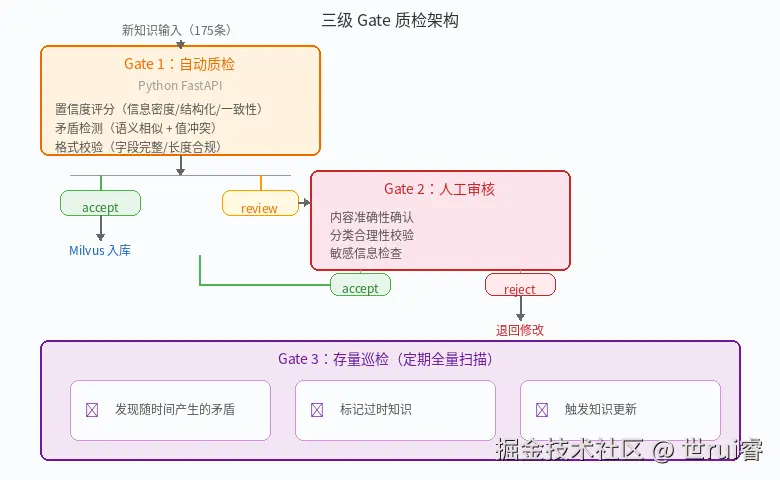
二、方案:三级 Gate 架构
我们的质检系统叫 Knowledge Gate,分为三个阶段:
三、技术实现
Gate 1:自动质检(Python FastAPI)
3.1 置信度评分
多维度评分体系:
python
def calculate_confidence(text: str) -> float:
"""
多维度评分
- 信息密度(40%):有效内容占比
- 结构化程度(30%):是否有明确 Q/A 或步骤
- 语义完整性(30%):上下文是否自洽
"""
density = calculate_info_density(text) # 0~1
structure = check_structure(text) # 0~1
consistency = check_consistency(text) # 0~1
return 0.4 * density + 0.3 * structure + 0.3 * consistency3.2 矛盾检测
python
def detect_conflicts(new_knowledge: str, existing: List[str]) -> List[Conflict]:
conflicts = []
for exist in existing:
similarity = semantic_similarity(new_knowledge, exist)
if similarity > 0.8: # 语义高度相似
if has_value_conflict(new_knowledge, exist):
conflicts.append(Conflict(
type="value_mismatch",
existing=exist,
confidence=similarity
))
return conflicts阈值设定 :相似度 0.8 是经过调优的经验值。太高会漏掉冲突,太低会误报太多。我们采用动态阈值 + 人工复核机制,持续优化。
3.3 审核决策
python
from enum import Enum, auto
from dataclasses import dataclass
from typing import Callable
class GateDecision(Enum):
"""用枚举替代魔法字符串,类型安全"""
ACCEPT = auto()
REVIEW = auto()
REJECT = auto()
@dataclass(frozen=True)
class DecisionRule:
"""决策规则:条件 + 结果,可组合"""
condition: Callable[[float, list], bool]
decision: GateDecision
class QualityGate:
"""质检门:规则链模式,按优先级匹配"""
_rules: list[DecisionRule] = [
DecisionRule(
lambda c, conf: c < 0.5 or len(conf) > 0,
GateDecision.REJECT
),
DecisionRule(
lambda c, conf: c < 0.8,
GateDecision.REVIEW
),
DecisionRule(
lambda c, conf: True, # 默认规则
GateDecision.ACCEPT
),
]
def decide(self, confidence: float, conflicts: list) -> GateDecision:
return next(
rule.decision for rule in self._rules
if rule.condition(confidence, conflicts)
)3.4 FastAPI 服务
python
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class KnowledgePayload(BaseModel):
question: str
answer: str
category: str
source_path: str
@app.post("/api/knowledge/validate")
def validate(payload: KnowledgePayload):
confidence = calculate_confidence(payload.answer)
conflicts = detect_conflicts(payload.answer, existing_knowledge)
recommendation = make_decision(confidence, conflicts)
return {
"recommendation": recommendation, # accept / review / reject
"confidence": confidence,
"conflicts": [c.dict() for c in conflicts]
}Gate 2:Java 侧集成与降级
4.1 入库流程
java
/** 知识入库:策略模式替代 switch,每个决策对应一个处理器 */
@Component
@RequiredArgsConstructor
public class KnowledgeSyncService {
private final ValidateClient validateClient;
private final MilvusRepository milvus;
private final Map<GateDecision, KnowledgePostProcessor> processors;
public void syncUpsert(KnowledgeRecord record) {
validateClient.validate(record)
.map(ValidationResult::decision)
.flatMap(decision -> processors.get(decision).process(record))
.ifSuccess(milvus::upsert)
.ifFailure(this::handleSyncError);
}
}
/** 决策处理器接口 */
public interface KnowledgePostProcessor {
Result<KnowledgeRecord> process(KnowledgeRecord record);
}
@Component
public class AcceptProcessor implements KnowledgePostProcessor {
public Result<KnowledgeRecord> process(KnowledgeRecord record) {
record.markAs(VectorStatus.SYNCED);
return Result.success(record);
}
}
@Component
public class ReviewProcessor implements KnowledgePostProcessor {
public Result<KnowledgeRecord> process(KnowledgeRecord record) {
record.markAs(VectorStatus.PENDING_REVIEW);
return Result.success(record); // 入库但标记待审核
}
}
@Component
public class RejectProcessor implements KnowledgePostProcessor {
public Result<KnowledgeRecord> process(KnowledgeRecord record) {
record.markAs(VectorStatus.REJECTED);
return Result.failure(new QualityCheckFailedException("质量未通过"));
}
}
/** 质检客户端:函数式降级,超时自动放行 */
@Component
public class ValidateClient {
private final RestTemplate restTemplate;
private final DegradePolicy degradePolicy = DegradePolicy.allowPass();
public Optional<ValidationResult> validate(KnowledgeRecord record) {
return DegradeExecutor.withPolicy(degradePolicy)
.timeout(Duration.ofSeconds(3))
.execute(() -> restTemplate.postForObject(
VALIDATE_URL, record, ValidationResult.class
));
}
}核心约束 :质检服务超时必须降级放行,不能因为 Python 服务挂了阻断入库。这是生产环境的铁律。
4.2 Nacos 配置
yaml
agent.rag.validate-url: http://localhost:8000/api/knowledge/validate4.3 表结构(已扩展 gate 字段)
java
/** 知识库实体:用 JPA 枚举替代魔法数字 */
@Entity
@Table(name = "agent_knowledge_base")
public class KnowledgeRecord {
@Id
private UUID id;
@Enumerated(EnumType.STRING)
@Column(name = "gate_recommendation", length = 20)
private GateDecision gateDecision; // ACCEPT / REVIEW / REJECT
@Column(name = "gate_confidence", precision = 4, scale = 3)
private BigDecimal gateConfidence; // 置信度 0.000 ~ 1.000
@Enumerated(EnumType.STRING)
@Column(name = "vector_status")
private VectorStatus vectorStatus; // 类型安全,非裸 int
@Column(name = "source_path")
private SourcePath sourcePath; // 值对象,封装路径校验
}
public enum VectorStatus {
UNSYNCED, // 未同步
SYNCED, // 已入向量库
REJECTED, // 质检拒绝
PENDING_REVIEW // 待人工审核
}Gate 3:人工审核与存量巡检
人工审核工作流:
vector_status=4(review)的知识进入审核队列- 运营人员在管理后台确认内容准确性、分类合理性、敏感信息
- 审核通过 → 状态不变(已在库),审核拒绝 →
vector_status=3
存量巡检(规划中):
- 定期全量扫描,发现随时间产生的矛盾
- 新版本文档上线后,自动检测与旧版本的冲突
- 标记过时知识,触发更新流程
四、6 个关键实现决策
决策 1:为什么用 Python FastAPI 做质检?
Java 是我们的主技术栈,但质检服务选择了 Python。
原因:
- 语义相似度计算、NLP 处理在 Python 生态更成熟(sentence-transformers、scikit-learn)
- 质检服务是独立边界,不影响主服务的 Java 技术栈统一性
- FastAPI 异步性能足够,启动速度快
决策 2:为什么 DTO 禁止 @Data?
Java 侧 DTO 手写 getter/setter + @JsonIgnoreProperties,不用 Lombok @Data。
原因:Jackson 反序列化时,@Data 生成的构造函数可能与新字段不兼容,导致旧数据反序列化失败。手写控制更稳定。
决策 3:为什么 source_path 存相对路径?
source_path 存相对路径(相对 ~/CompanyWiki),不存绝对路径。
原因:开发环境、测试环境、生产环境的绝对路径不同,相对路径保证跨环境一致性。
决策 4:为什么批量同步用 @Async?
CompanyWiki 批量同步标记为 @Async,避免阻塞 HTTP 请求。
原因:批量同步可能涉及数百条知识的质检和入库,同步执行会导致前端请求超时。异步执行 + 进度回调是更合理的方案。
决策 5:相似度阈值 0.8 怎么来的?
不是拍脑袋定的,是调出来的。
- 初期设 0.9 → 漏掉很多实际冲突(太严格)
- 降到 0.7 → 误报太多,人工审核压力大(太宽松)
- 最终 0.8 + 人工复核机制,持续收集反馈优化
决策 6:降级放行会不会放进垃圾数据?
会,但概率极低,且是可用性与准确性的权衡。
- Python 服务正常时:自动质检拦截 5% 的明显垃圾
- Python 服务异常时:降级放行,依赖存量知识的质量基线
- 事后补偿:存量巡检定期扫描,发现漏网之鱼
核心原则:宁可偶尔放进一条低质量知识,也不能让整个入库流程瘫痪。
五、效果验证
运行数据
| 指标 | 数值 | 说明 |
|---|---|---|
| 自动通过率 | ~73% | 高质量知识,无需人工干预 |
| 人工审核率 | ~27% | 置信度中等或潜在冲突 |
| 拒绝率 | ~5% | 明显低质量或严重冲突 |
避免的坑
- 拦截了多处知识矛盾(新旧版本参数默认值冲突)
- 发现了文档格式问题(表头探测失败、内容过短)
- 低质量 FAQ(如"这个问题很好"类无效内容)未进入生产环境
可视化
质检仪表盘基于 D3.js 实现,展示知识图谱和冲突关系。我们 175 条知识产生了 582 个可视化节点,知识间的关联和冲突一目了然。
六、踩坑实录
坑 1:质检服务超时导致入库阻塞
现象:Python 服务偶发慢,Java 侧等待,前端用户体验差。
解决:3 秒连接超时 + 15 秒读取超时,超时则降级放行,并记录告警日志。
java
/** 质检客户端配置:用 Builder 模式替代魔法数字 */
@Configuration
public class ValidateClientConfig {
@Bean
public ValidateClient validateClient(RestTemplateBuilder builder) {
return new ValidateClient(
builder
.setConnectTimeout(Duration.ofSeconds(3))
.setReadTimeout(Duration.ofSeconds(15))
.errorHandler(new DegradeOnTimeoutHandler())
.build()
);
}
}
/** 超时降级处理器:RestTemplate 的 ErrorHandler 扩展点 */
public class DegradeOnTimeoutHandler extends DefaultResponseErrorHandler {
@Override
public void handleError(ClientHttpResponse response) {
log.warn("质检服务超时,触发降级放行");
// 不抛异常,让上游 Optional.empty() 走降级逻辑
}
}坑 2:矛盾检测把"相似问题不同答案"当成冲突
现象:FAQ 中常见"相似问题、不同场景的不同答案"被误判为冲突。
例子 : 
这两个答案语义相似,但不是冲突------是不同场景的合理回答。
解决 :矛盾检测加入场景标签判断。相同场景 + 语义相似 + 答案不同 → 才是冲突。
坑 3:审核队列堆积
现象:人工审核速度跟不上入库速度,review 状态的记录越积越多。
解决:
- 批量审核:一次处理多条相似记录
- 优先级队列:P0 知识(核心业务流程)优先审核
- 审核模板:常见问题的审核标准模板化,减少判断时间
坑 4:质检服务自己也需要监控
现象:某天发现质检服务的响应时间从 200ms 涨到 3s,原因是依赖的 Embedding 模型加载变慢。
解决:给质检服务本身加监控(响应时间、成功率、降级次数),发现异常及时告警。
七、实施路线图
如果你想在自己的系统上这套方案,建议分阶段实施:
| 阶段 | 时间 | 内容 | 目标 |
|---|---|---|---|
| Phase 1 | 1 周 | 自动质检上线(仅拒绝明显低质量) | 拦截 80% 的明显垃圾 |
| Phase 2 | 2 周 | 矛盾检测上线(相似度阈值从保守开始) | 发现知识冲突 |
| Phase 3 | 1 周 | 人工审核工作流(钉钉/飞书审批) | 处理边界情况 |
| Phase 4 | 持续 | 存量巡检机制 | 知识保鲜,防止"知识腐烂" |
建议:Phase 1 可以先不做矛盾检测,只做"格式校验 + 置信度评分 + 明显低质量拦截",一周内就能上线看到效果。
总结
质检不是可选功能,是企业级 RAG 的刚需。
三级 Gate 的分工:
- Gate 1 自动质检:过滤 73% 的常规问题,机器做机器擅长的事
- Gate 2 人工审核:处理 27% 的边界情况,人做人擅长的事
- Gate 3 存量巡检:持续监控,防止"知识腐烂"
核心原则:宁可严进,不可滥入。
175 条知识通过这套机制进入生产环境后,我们的 RAG 准召率从 70% 提升到 87%。检索优化解决的是"找得到",质检机制解决的是"找得准"。 两者缺一不可。
标签 :#RAG #知识库 #质检 #后端开发 #企业落地 #Java #Python
如果这个系列对你有帮助,欢迎 👍 点赞 | 🔖 收藏 | 💬 评论。四部曲的完整阅读地图在文章顶部,建议按顺序阅读。