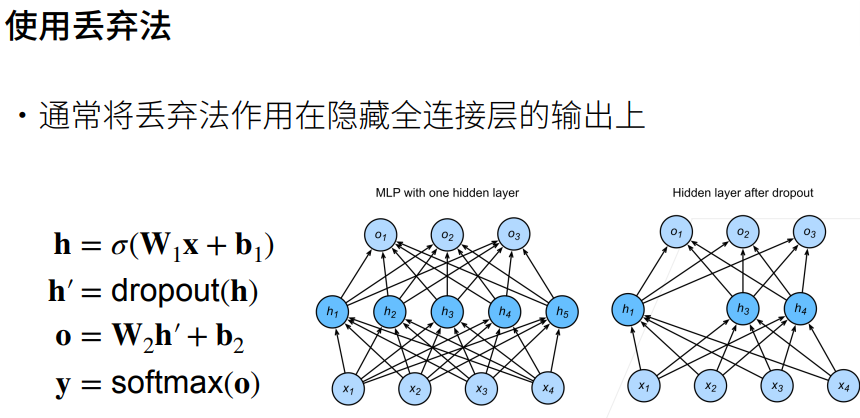
1. 丢弃法


① 这里除以1-p是为了与原来的的期望相同。



2. 丢弃法(使用自定义)
python
# 实现dropout_layer函数,该函数以dropout的概率丢弃张量输入x中的元素
import torch
from torch import nn
from d2l import torch as d2l
def dropout_layer(X, dropout):
assert 0 <= dropout <= 1 # dropout大于等于0,小于等于1,否则报错
if dropout == 1:
return torch.zeros_like(X) # 如果dropout为1,则X返回为全0
if dropout == 0:
return X # 如果dropout为1,则X返回为全原值
mask = (torch.randn(X.shape)>dropout).float() # 取X.shape里面0到1之间的均匀分布,如果值大于dropout,则把它选出来
#print((torch.randn(X.shape)>dropout)) # 返回的是布尔值,然后转布尔值为0、1
return mask * X / (1.0 - dropout)
X = torch.arange(16,dtype=torch.float32).reshape((2,8))
print(X)
print(dropout_layer(X, 0.))
print(dropout_layer(X, 0.5)) # 有百分之50的概率变为0
print(dropout_layer(X, 1.))tensor([[ 0., 1., 2., 3., 4., 5., 6., 7.],
[ 8., 9., 10., 11., 12., 13., 14., 15.]])
tensor([[ 0., 1., 2., 3., 4., 5., 6., 7.],
[ 8., 9., 10., 11., 12., 13., 14., 15.]])
tensor([[ 0., 0., 4., 6., 0., 0., 0., 14.],
[16., 0., 0., 0., 0., 0., 0., 30.]])
tensor([[0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0.]])一、Dropout在干嘛?
一句话理解:
👉 以一定概率把输入张量中的元素"随机置为0",其余元素做缩放
比如:
原始: [1, 2, 3, 4] dropout=0.5 可能变成: [0, 2, 0, 4](随机丢掉一半二、函数整体结构
def dropout_layer(X, dropout):
X:输入张量(tensor:多维数组,比如矩阵)
dropout:丢弃概率(比如0.5表示丢一半)三、逐行解释
1️⃣ 参数检查
assert 0 <= dropout <= 1👉 确保概率合法(0~1之间) 2️⃣ 极端情况 if dropout == 1: return torch.zeros_like(X)👉 全丢弃(100%),输出全0 if dropout == 0: return X👉 不丢弃,原样返回 3️⃣ 核心:生成 mask(掩码) mask = (torch.rand(X.shape) > dropout).float() torch.rand() 👉 均匀分布(uniform distribution:0~1之间均匀) mask 是什么? 假设:dropout = 0.5 那么:torch.rand(X.shape) 可能是:[0.2, 0.8, 0.3, 0.9] 然后:> 0.5 → [0, 1, 0, 1] 再 .float():[0., 1., 0., 1.] 👉 这就是 mask(掩码:控制哪些保留,哪些丢弃)4️⃣ 应用 dropout
return mask * X / (1.0 - dropout) 分两步理解: ✔ 第一步:mask * X👉 把被丢弃的位置变0 ✔ 第二步:除以 (1 - dropout)👉 缩放(scaling:调整数值大小) 为什么? 因为丢掉一部分后,整体数值变小了,需要补回来。 举例: 原均值:10 丢一半后:5 → 除以0.5 → 变回10👉 这样训练和测试时分布一致四、测试代码解释
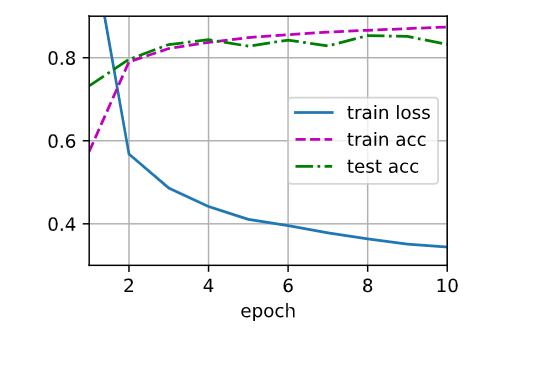
X = torch.arange(16).reshape((2,8))生成: [[ 0, 1, 2, ..., 7] [ 8, 9, 10,...15]] 1️⃣ dropout=0 print(dropout_layer(X, 0.))👉 原样输出 2️⃣ dropout=0.5 print(dropout_layer(X, 0.5))👉 大约一半变0,另一半变: 原值 / 0.5 = 原值 * 2 3️⃣ dropout=1 print(dropout_layer(X, 1.))👉 全0五、总结一句话
👉 这段代码在做:
随机生成一个0/1掩码,把输入的一部分变0,并对剩余部分做缩放
python
# 定义具有两个隐藏层的多层感知机,每个隐藏层包含256个单元
num_inputs, num_outputs, num_hiddens1, num_hiddens2 = 784, 10 ,256, 256
dropout1, dropout2 = 0.2, 0.5
class Net(nn.Module):
def __init__(self, num_inputs, num_outputs, num_hiddens1, num_hiddens2,is_training=True):
super(Net, self).__init__()
self.num_inputs = num_inputs
self.training = is_training
self.lin1 = nn.Linear(num_inputs, num_hiddens1)
self.lin2 = nn.Linear(num_hiddens1, num_hiddens2)
self.lin3 = nn.Linear(num_hiddens2, num_outputs)
self.relu = nn.ReLU()
def forward(self, X):
H1 = self.relu(self.lin1(X.reshape((-1,self.num_inputs))))
if self.training == True: # 如果是在训练,则作用dropout,否则则不作用
H1 = dropout_layer(H1, dropout1)
H2 = self.relu(self.lin2(H1))
if self.training == True:
H2 = dropout_layer(H2,dropout2)
out = self.lin3(H2) # 输出层不作用dropout
return out
net = Net(num_inputs, num_outputs, num_hiddens1, num_hiddens2)
# 训练和测试
num_epochs, lr, batch_size = 10, 0.5, 256
loss = nn.CrossEntropyLoss()
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
trainer = torch.optim.SGD(net.parameters(),lr=lr)
d2l.train_ch3(net,train_iter,test_iter,loss,num_epochs,trainer)
这段代码的整体目的:
用 PyTorch 定义一个带 Dropout 的多层感知机(MLP),然后在 Fashion-MNIST 数据集上训练分类模型。
可以按 4 步理解。
1. 定义网络规模
num_inputs, num_outputs, num_hiddens1, num_hiddens2 = 784, 10, 256, 256 含义:num_inputs = 784输入特征数。Fashion-MNIST 图片是 28 × 28,展开后就是:28 * 28 = 784
num_outputs = 10输出类别数。Fashion-MNIST 有 10 类衣服。
num_hiddens1 = 256第一个隐藏层有 256 个神经元。
num_hiddens2 = 256第二个隐藏层也有 256 个神经元。
网络结构大概是:
输入层 784 ↓ 隐藏层1 256 ↓ 隐藏层2 256 ↓ 输出层 102. 设置 Dropout 比例
dropout1, dropout2 = 0.2, 0.5 Dropout(随机失活):训练时随机丢掉一部分神经元,防止模型过拟合。
dropout1 = 0.2:第一隐藏层随机丢掉 20%
dropout2 = 0.5:第二隐藏层随机丢掉 50%注意:Dropout 只在训练时使用,测试时不用。
3. 定义网络类
Netclass Net(nn.Module):
这表示你在定义一个神经网络模型。
nn.Module是 PyTorch 里所有神经网络模型的基类。3.1 初始化函数
__init__
def __init__(self, num_inputs, num_outputs, num_hiddens1, num_hiddens2, is_training=True): 这个函数负责创建网络里的层。 super(Net, self).__init__()调用父类初始化,固定写法。 self.num_inputs = num_inputs self.training = is_training保存输入维度,并设置当前是否为训练模式。 不过这里有一点要注意: PyTorch 本身已经有 self.training这个属性,通常不建议自己手动这样写。更推荐后面用:net.train() net.eval()来切换训练和测试模式。 3.2 三个全连接层 self.lin1 = nn.Linear(num_inputs, num_hiddens1) self.lin2 = nn.Linear(num_hiddens1, num_hiddens2) self.lin3 = nn.Linear(num_hiddens2, num_outputs)nn.Linear 是全连接层。对应关系是: lin1: 784 → 256 lin2: 256 → 256 lin3: 256 → 10也就是:输入图片 → 第一隐藏层 → 第二隐藏层 → 分类结果3.3 激活函数 ReLU
self.relu = nn.ReLU()ReLU(修正线性单元):一种激活函数。它的作用是给模型增加非线性能力。 简单理解:ReLU(x) = max(0, x)也就是:负数变成 0,正数保持不变4. 前向传播
forward
def forward(self, X):这里定义数据怎么从输入走到输出。4.1 先把图片拉平成一维
X.reshape((-1, self.num_inputs))Fashion-MNIST 每张图原本形状通常是: batch_size × 1 × 28 × 28如:256 × 1 × 28 × 28经过 reshape 后变成:256 × 784 其中:
-1:让 PyTorch 自动计算这一维
self.num_inputs = 784:每张图片展开成 784 个特征
4.2 第一层
H1 = self.relu(self.lin1(X.reshape((-1,self.num_inputs))))流程是: 输入 X → 拉平成 784 → 经过 lin1,全连接层 → 经过 ReLU → 得到 H1 此时 H1 的形状大概是:batch_size × 2564.3 对第一隐藏层使用 Dropout
if self.training == True: H1 = dropout_layer(H1, dropout1) 如果是训练阶段,就对 H1使用 dropout。 也就是随机让一部分隐藏单元变成 0。4.4 第二层
H2 = self.relu(self.lin2(H1))流程是:H1 → lin2 → ReLU → H2 此时 H2形状仍然是:batch_size × 2564.5 对第二隐藏层使用 Dropout
if self.training == True: H2 = dropout_layer(H2,dropout2)训练时,对第二隐藏层随机丢掉 50% 的神经元。
4.6 输出层
out = self.lin3(H2) return out 输出层把 256 维变成 10 维。也就是每张图片输出 10 个分数: batch_size × 10这 10 个分数分别代表模型认为图片属于 10 个类别的倾向。 注意:这里没有加 softmax,因为:loss = nn.CrossEntropyLoss()CrossEntropyLoss内部已经包含了 softmax 相关计算,所以不需要手动加。5. 创建模型
net = Net(num_inputs, num_outputs, num_hiddens1, num_hiddens2) 这一步是真正创建一个网络对象。6. 设置训练参数
num_epochs, lr, batch_size = 10, 0.5, 256 含义:
num_epochs = 10:训练 10 轮
lr = 0.5:学习率是 0.5
batch_size = 256:每次用 256 张图片训练一次
7. 定义损失函数
loss = nn.CrossEntropyLoss()这是多分类常用损失函数。它会比较:模型预测的 10 个类别分数和真实标签然后告诉模型错得有多离谱。8. 加载数据
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
加载 Fashion-MNIST 数据集。
返回:
train_iter:训练集迭代器
test_iter:测试集迭代器
9. 定义优化器
trainer = torch.optim.SGD(net.parameters(), lr=lr)
这里使用的是 SGD(随机梯度下降)。
作用是:根据损失函数计算出来的梯度,更新模型参数。
net.parameters()表示把网络里所有需要训练的参数交给优化器。
10. 开始训练
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
这句会执行完整训练过程,大概包括:
取一批训练数据
前向传播,得到预测结果
计算损失
反向传播,计算梯度
用 SGD 更新参数
在测试集上评估准确率
重复 10 轮
最核心的思路
这段代码就是在做:
图片 28×28 → 展平成 784 个数字 → 全连接层 784→256 → ReLU → Dropout → 全连接层 256→256 → ReLU → Dropout → 全连接层 256→10 → 得到 10 类分类分数 → 用 CrossEntropyLoss 训练
3. 丢弃法(使用框架)
python
import torch
from torch import nn
from d2l import torch as d2l
# 简洁实现
num_epochs, lr, batch_size = 10, 0.5, 256
dropout1, dropout2 = 0.2, 0.5
loss = nn.CrossEntropyLoss()
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
#nn.Sequential = 按顺序堆叠网络
net = nn.Sequential(nn.Flatten(),nn.Linear(784,256),nn.ReLU(),
nn.Dropout(dropout1),nn.Linear(256,256),nn.ReLU(),
nn.Dropout(dropout2),nn.Linear(256,10))
#初始化权重;如果是 Linear层;就用正态分布初始化权重
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight,std=0.01)
net.apply(init_weights)
trainer = torch.optim.SGD(net.parameters(),lr=lr)
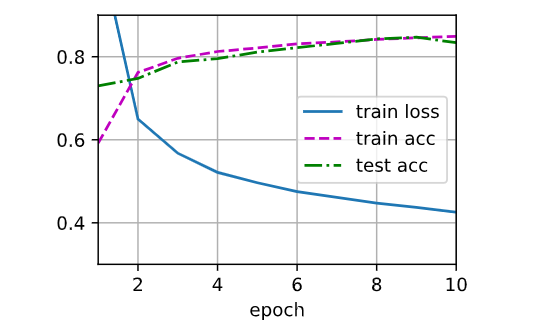
d2l.train_ch3(net,train_iter, test_iter, loss, num_epochs,trainer)最后一行做了:
for epoch:
for batch:
前向传播
计算 loss
反向传播
更新参数
计算测试集准确率