3 库的操作
3.1 创建库
sql
CREATE DATABASE [IF NOT EXISTS] db_name [create_specification [, create_specification] ...]
create_specification:
[DEFAULT] CHARACTER SET charset_name
[DEFAULT] COLLATE collation_name-
[IF NOT EXISTS]在脚本中很有用,如果数据库名字重复了,那么一般来说会报错,脚本中老是因为名字问题而报错是一个不太方便的事情,所以带上这个可选项之后,可以实现"如果存在同名数据库就不创建,否则创建", -
create_specification是配置选项,可以用来自定义一些内容,否则就会采用默认配置 -
具体可以使用的配置是
CHARACTER SET和COLLATE:CHARACTER SET: 字符集,用于规范数据存储的字符COLLATE: 校验规则,规范了字符如何进行排序和比大小
-
值得一提的是,固定的字符集必须使用对应适配的校验规则,一个字符集如果试图采用一个八竿子打不着的校验规则,
MySQL会直接提示命令错误
sql
mysql> CREATE DATABASE broken_db CHARACTER SET utf8mb4 COLLATE latin1_swedish_ci;
ERROR 1253 (42000): COLLATION 'latin1_swedish_ci' is not valid for CHARACTER SET 'utf8mb4'- 这个命令可以显示所有兼容的字符集极其默认校验规则
SQL
SHOW CHARACTER SET;- 这个命令可以显示所有兼容的校验规则极其匹配的字符集,一般有几百个校验规则
SQL
show collation;
sql
mysql> create database test_db1 character set utf8mb4 collate utf8mb4_0900_ai_ci;
Query OK, 1 row affected (0.00 sec)
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| hello |
| information_schema |
| mysql |
| performance_schema |
| sys |
| test_db |
| test_db1 |
+--------------------+
7 rows in set (0.00 sec)- 另一种写法
sql
mysql> create database test_db2 charset=utf8mb4 collate utf8mb4_0900_ai_ci;
Query OK, 1 row affected (0.01 sec)
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| hello |
| information_schema |
| mysql |
| performance_schema |
| sys |
| test_db |
| test_db1 |
| test_db2 |
+--------------------+
8 rows in set (0.00 sec)3.2 校验规则与层级继承机制(扩展)
-
我们知道,我们可以在创建数据库的时候指定校验规则,也可以不指定校验规则,如果不指定校验规则,那么这个数据库就会使用操作系统中默认配置的校验规则
-
事实上,从表结构(
table)来看,我们创建数据库时手动指明的校验规则也是某种意义上的默认校验规则,这意味着即便我们在创建库时手动指明了校验规则,我也可以单独为该库中的表结构单独指定校验规则 -
甚至说,我甚至可以为一个表结构的列单独指明校验规则
-
上面说得有点复杂,我们换个简单的说法,
MySQL有点像是excel提供了这样的功能(我没怎么用过excel,不太熟,只是为了举例子而已) -
假设
excel提供了排序功能,并且可以按照我们选中的区域为数据个性化排序
| 选中区域 | 生效范围 | 类比MySQL操作 |
|---|---|---|
| 不选中任何东西 | 全局所有的excel表格全部按照默认设置排序 |
按照默认配置的校验规则 |
| 选中一个目录下的所有表格 | 该目录下所有excel表格全部按照当前设置的排序方式排序 |
创建库时手动指明了校验规则 |
| 选中一个目录下的一个表格 | 该excel表格按照当前设置的排序方式排序 |
创建表格时手动指明了校验规则 |
| 选中一个表格下的某一列 | 该列按照当前设置的排序方式排序 | 创建列时手动指明了校验规则 |
- 所以你会发现,如果你不指定,关于校验规则的设置就会继承上一层的设置,最终落实到每一列的设置
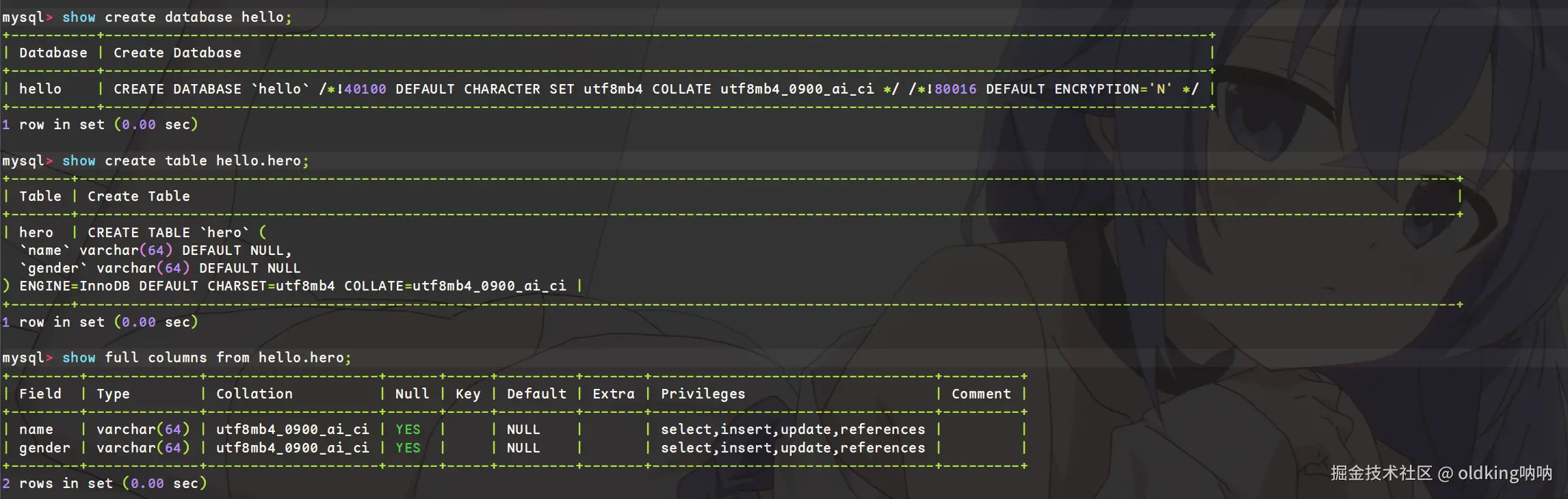
3.3 校验规则带来的影响
- 这里我在
hello里再创建两个表,一个大小写敏感,另一个大小写不敏感
sql
mysql> create table test_ci (content varchar(64)) collate utf8mb4_0900_ai_ci;
Query OK, 0 rows affected (0.03 sec)
mysql> create table test_bin (content varchar(64)) collate utf8mb4_bin;
Query OK, 0 rows affected (0.02 sec)
mysql> INSERT INTO test_ci VALUES ('Apple'), ('apple'), ('APPLE');
Query OK, 3 rows affected (0.00 sec)
Records: 3 Duplicates: 0 Warnings: 0
mysql> INSERT INTO test_bin VALUES ('Apple'), ('apple'), ('APPLE');
Query OK, 3 rows affected (0.00 sec)
Records: 3 Duplicates: 0 Warnings: 0
mysql> SELECT * FROM test_ci WHERE content = 'apple';
+---------+
| content |
+---------+
| Apple |
| apple |
| APPLE |
+---------+
3 rows in set (0.00 sec)
mysql> SELECT * FROM test_bin WHERE content = 'apple';
+---------+
| content |
+---------+
| apple |
+---------+
1 row in set (0.00 sec)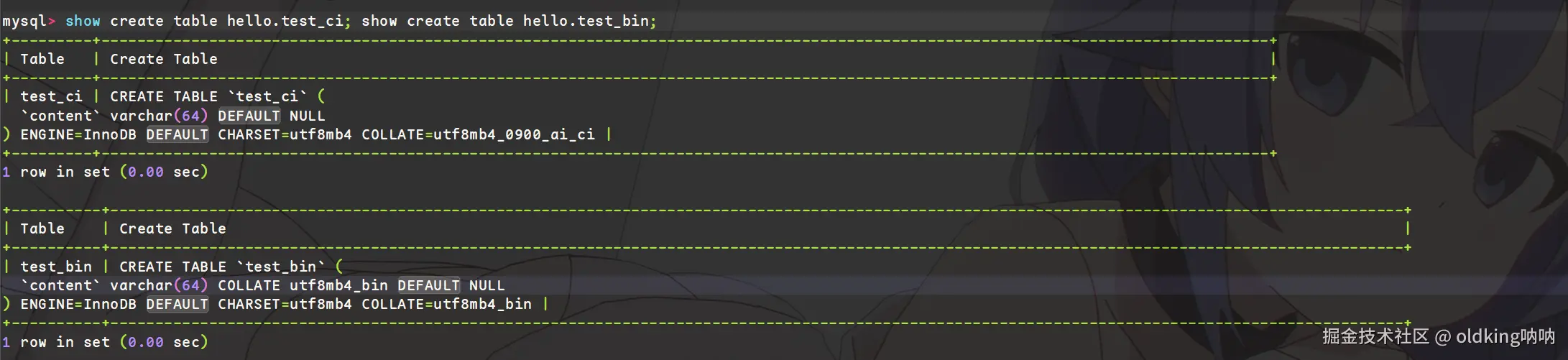
3.4 查找数据库
- 显示数据库
SQL
show databases;- 查找创建数据库时使用的命令
SQL
show create database db_name;
-
值得一提的是,这串命令是经过还原的,以显示一些默认参数,比方说字符集什么的
-
另外,
/**/不是注释,这个符号其实表示如果MySQL版本大于某个固定版本(比方说!40100就表示在4.01.00版本及之后的所有版本都会执行,!80016同理) ,就执行这个命令,同样是方便脚本使用的设计,比方说你把这个命令丢给其他数据库,他就不会执行或者储存/**/里的内容,但如果你丢给MySQL,他就会执行或者储存 -
老实说我觉得这是一个很妙的设计,有点像是
CPP的条件编译,根据当前环境来选择性的过滤/新增一些代码或者指令 -
当然,你也可以查找创建表时使用的命令
SQL
show create table table_name;
- 另外,如果你看过其他人写
MySQL指令的话,你可能会觉得他们为什么要用部分大写去写指令? - 因为
MySQL在设计的时候考虑到了权重问题,我们把关键字和非关键字(也就是库名,表名什么的)分开看,如果所有的关键字全部用大写,非关键字用小写或者首字母大写其他小写的这种形式,会使得可读性更好,不过这是非强制的,你依旧可以用小写,MySQL仍旧可以做解析
3.5 数据库修改
- 修改数据库的字符集和校验规则
SQL
alter database db_name [character set charset_name] [collate collation_name];- 值得一提的是,因为继承机制仅存在于创建时,或者说只有创建时当前对象会继承上层的属性,如果后续修改了上层的属性,下层是不会继承的
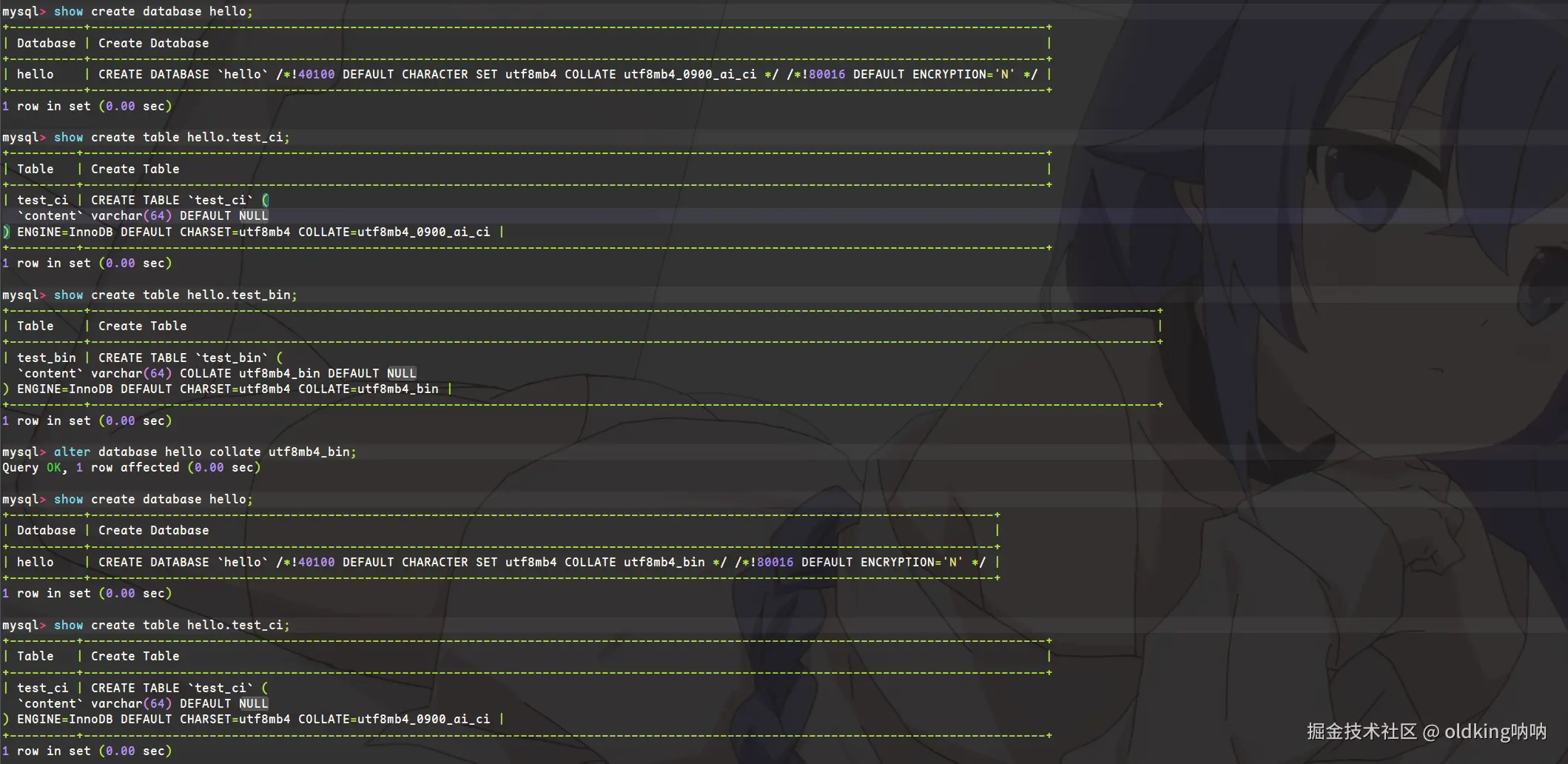
- 关于修改数据库的名字,其实
MySQL没有提供能够直接修改数据库的命令,因为数据库一般不会经常动,一般改名字很容易牵一发而动全身,所以不如改,如果一定要改的话,就需要手动备份数据库,然后手动创建新数据库然后把文件恢复回去
3.6 数据库删除
- 删除数据库请一定要慎重
SQL
drop database [if exists] db_name;
sql
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| hello |
| information_schema |
| mysql |
| performance_schema |
| sys |
| test_db |
| test_db1 |
| test_db2 |
+--------------------+
8 rows in set (0.00 sec)
mysql> drop database test_db;
Query OK, 0 rows affected (0.01 sec)
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| hello |
| information_schema |
| mysql |
| performance_schema |
| sys |
| test_db1 |
| test_db2 |
+--------------------+
7 rows in set (0.00 sec)3.7 备份
- 这个命令可以用于备份一个数据库
bash
mysqldump -u user_name -p -B database_name > path- 比方说这里我就备份了
hello到一个文件
ini
root@iZwz9b2bj2gor4d8h3rlx0Z:~# mysqldump -u root -p -B hello > ./sqlcp.sql
Enter password:
root@iZwz9b2bj2gor4d8h3rlx0Z:~# cat sqlcp.sql
-- MySQL dump 10.13 Distrib 8.0.45, for Linux (x86_64)
--
-- Host: localhost Database: hello
-- ------------------------------------------------------
-- Server version 8.0.45-0ubuntu0.24.04.1
/*!40101 SET @OLD_CHARACTER_SET_CLIENT=@@CHARACTER_SET_CLIENT */;
/*!40101 SET @OLD_CHARACTER_SET_RESULTS=@@CHARACTER_SET_RESULTS */;
/*!40101 SET @OLD_COLLATION_CONNECTION=@@COLLATION_CONNECTION */;
/*!50503 SET NAMES utf8mb4 */;
/*!40103 SET @OLD_TIME_ZONE=@@TIME_ZONE */;
/*!40103 SET TIME_ZONE='+00:00' */;
/*!40014 SET @OLD_UNIQUE_CHECKS=@@UNIQUE_CHECKS, UNIQUE_CHECKS=0 */;
/*!40014 SET @OLD_FOREIGN_KEY_CHECKS=@@FOREIGN_KEY_CHECKS, FOREIGN_KEY_CHECKS=0 */;
/*!40101 SET @OLD_SQL_MODE=@@SQL_MODE, SQL_MODE='NO_AUTO_VALUE_ON_ZERO' */;
/*!40111 SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0 */;
--
-- Current Database: `hello`
--
CREATE DATABASE /*!32312 IF NOT EXISTS*/ `hello` /*!40100 DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_bin */ /*!80016 DEFAULT ENCRYPTION='N' */;
USE `hello`;
--
-- Table structure for table `hero`
--
DROP TABLE IF EXISTS `hero`;
/*!40101 SET @saved_cs_client = @@character_set_client */;
/*!50503 SET character_set_client = utf8mb4 */;
CREATE TABLE `hero` (
`name` varchar(64) DEFAULT NULL,
`gender` varchar(64) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
/*!40101 SET character_set_client = @saved_cs_client */;
...
-- Dump completed on 2026-04-26 22:50:33- 如果你仔细看这个文件,这个文件里根本就没有存数据库本身,而是一堆脚本,这是为了方便数据跨版本或者跨平台恢复,直接拷贝数据库文件的话可能会导致不同平台之间无法兼容,导致数据永远丢失(数据真的很金贵,小时候老爸的电脑硬盘被修电脑的小哥格式化了,导致丢失了超多照片,数据火葬场了属于是),所以为了跨平台实现数据恢复,
MySQL被设计成了用脚本恢复数据
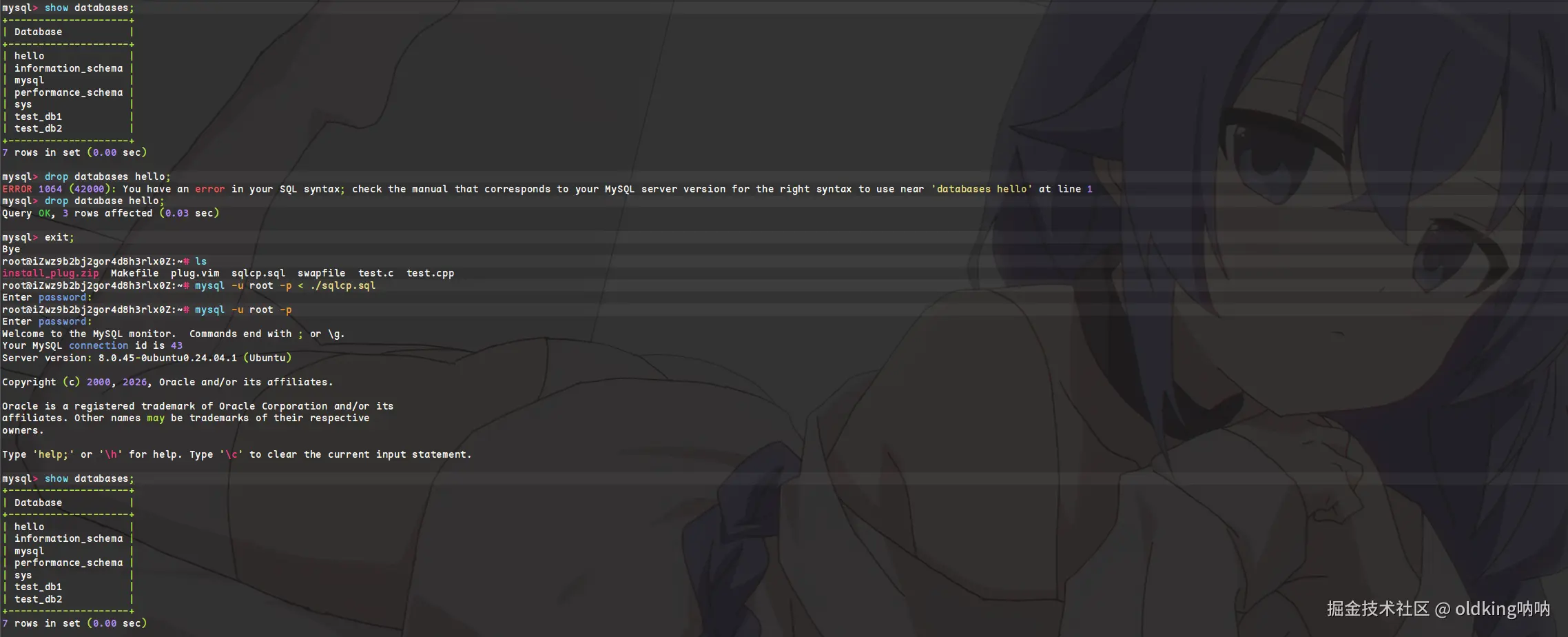
- 可以看到,这里我删除了
hello库,然后把./sqlcp.sql喂给MySQL,然后数据库就恢复了
3.8 视奸(查看谁连接上了)
- 这个指令可以视奸其他用户
SQL
show processlist;
- 这里的
event_scheduler其实不是一个用户,而是MySQL内核中的事件调度器,是一个守护进程,负责在一个固定时间执行某些命令