当你用 LangChain 构建 AI 应用时,有没有想过------LLM 的每一次推理调用、每一个 Token 的流式吐出、工具的每一次执行、甚至整个 Chain 的开始与结束,这些事件你能不能「插一脚」?Callback 就是干这个的。
一、引言:为什么需要 Callback?
LangChain 是一个强大的 LLM 应用开发框架,它把复杂的 AI 工作流抽象成 Chain、Agent、Tool、LLM 等组件。但光有组件不够------你需要观察它们、干预它们、为它们添加副作用。
比如你正在构建一个 AI 客服系统:
- 你想记录每次用户提问和 LLM 的回复(日志)
- 你想在 LLM 回答时流式推送 Token 到前端(流式输出)
- 你想统计每次 Chain 的执行时间(性能监控)
- 你想在工具执行出错时自动重试或通知管理员(异常处理)
这些需求如果写在业务代码里,会搅得一团乱。Callback 模式 就是来解决这个问题的------它让你监听 LLM 应用运行过程中的关键事件,并钩入自定义逻辑,而业务逻辑本身完全不用改。
Callback 的本质
Callback(回调)是一种事件驱动的钩子机制。你可以把它想象成在 LLM 应用这条「流水线」的各个节点上安装了监听器:
OnLLMStart → OnLLMNewToken → OnLLMEnd
OnChainStart → OnChainEnd → OnToolStart → OnToolEnd当流水线运行时,这些事件会自动触发,你的回调函数就会执行。
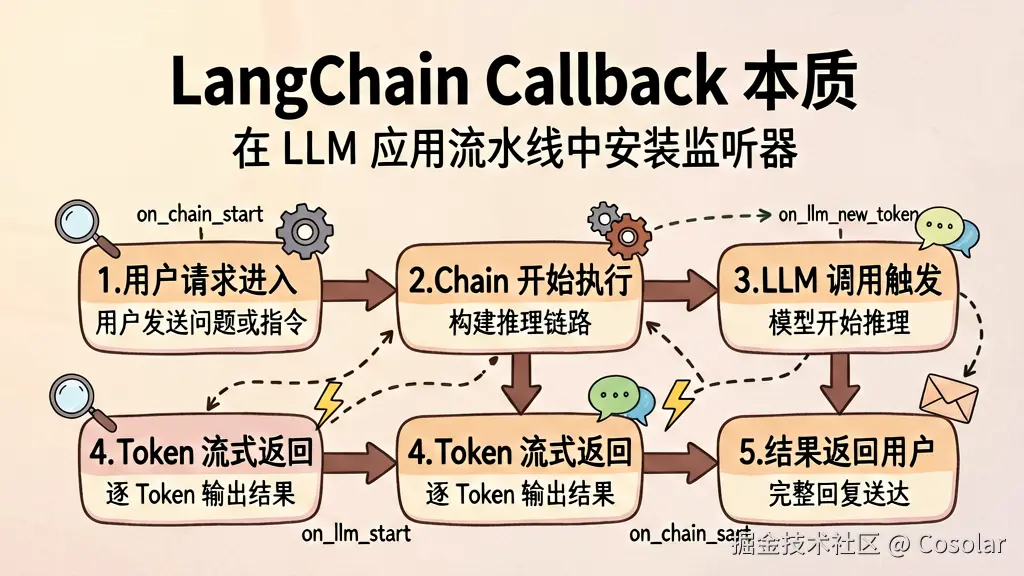 ▲ Callback 本质:在 LLM 应用流水线的每个节点安装监听器
▲ Callback 本质:在 LLM 应用流水线的每个节点安装监听器
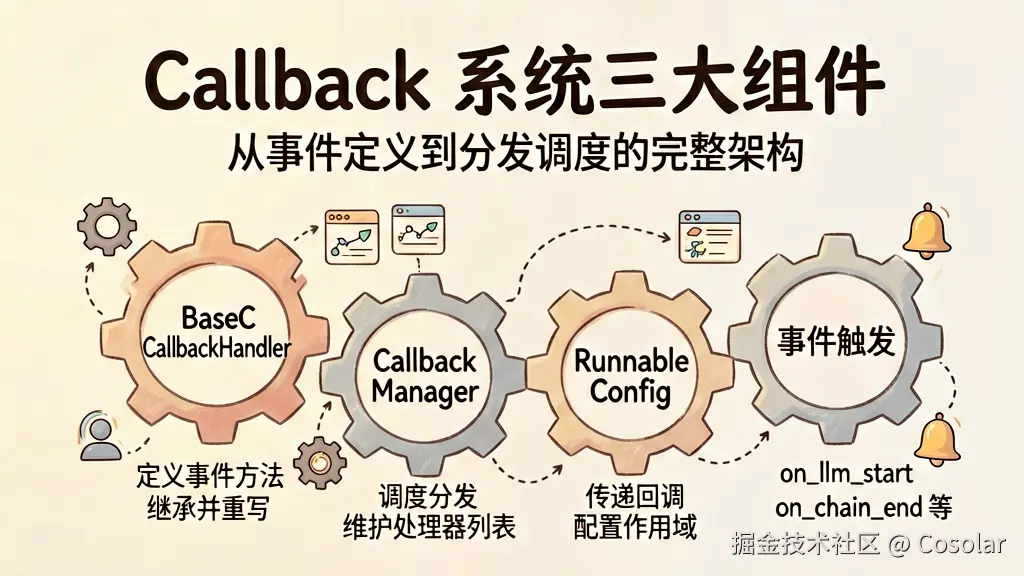 ▲ Callback 系统三大组件:定义 → 调度 → 传递,完整架构一目了然
▲ Callback 系统三大组件:定义 → 调度 → 传递,完整架构一目了然
二、核心概念:Callback 的设计哲学
LangChain 的 Callback 系统由三个核心组件构成:
2.1 BaseCallbackHandler
所有回调处理器的基类。它定义了一系列事件方法,你只需继承它并重写你需要的方法:
python
from langchain.callbacks.base import BaseCallbackHandler
class MyCallbackHandler(BaseCallbackHandler):
def on_llm_start(self, serialized, prompts, **kwargs):
print(f"LLM 开始调用,prompts: {prompts}")
def on_llm_end(self, response, **kwargs):
print(f"LLM 调用完成,response: {response}")
def on_chain_start(self, serialized, inputs, **kwargs):
print(f"Chain 开始执行")2.2 CallbackManager
回调的管理器,负责调度 和分发事件。它维护了一个回调处理器列表,当事件发生时依次通知所有注册的处理器。
2.3 RunnableConfig
在 LangChain 新版本(langchain>=0.1.0)中,通过 RunnableConfig 将回调传递给每个可运行组件:
python
from langchain_core.runnables import RunnableConfig
config = RunnableConfig(callbacks=[MyCallbackHandler()])
chain.invoke({"input": "你好"}, config=config)设计亮点
| 特性 | 说明 |
|---|---|
| 松耦合 | 业务逻辑与监控逻辑完全分离 |
| 可组合 | 多个 Callback Handler 可以叠加使用 |
| 层级化 | 支持全局、Chain 级、组件级三级作用域 |
| 异步友好 | 原生支持 async 回调 |
| 链式传递 | 父组件的回调自动传递给子组件 |
三、核心事件:完整的生命周期
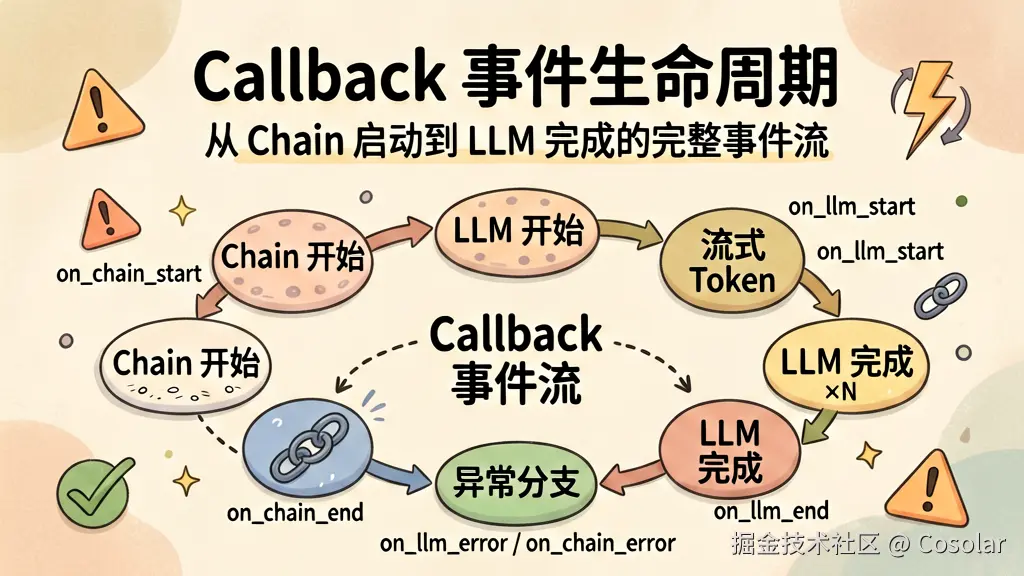 ▲ 从 Chain 启动到 LLM 调用完成,完整的事件流与嵌套关系
▲ 从 Chain 启动到 LLM 调用完成,完整的事件流与嵌套关系
Callback 系统覆盖了 LangChain 所有主要组件的生命周期。以下是核心事件:
LLM 事件
| 事件方法 | 触发时机 | 典型用途 |
|---|---|---|
on_llm_start |
LLM 开始调用前 | 记录请求日志、开始计时 |
on_llm_new_token |
流式生成每个 Token | 实时推送 Token 到前端 |
on_llm_end |
LLM 调用成功完成 | 记录响应、结束计时、计算 Token 用量 |
on_llm_error |
LLM 调用失败 | 记录错误、告警通知 |
on_chat_model_start |
Chat Model 开始调用 | 同上,适用于 Chat Model |
Chain 事件
| 事件方法 | 触发时机 | 典型用途 |
|---|---|---|
on_chain_start |
Chain 开始执行 | 记录链路追踪的开始 |
on_chain_end |
Chain 执行成功 | 输出执行结果 |
on_chain_error |
Chain 执行失败 | 异常捕获和处理 |
Tool 事件
| 事件方法 | 触发时机 | 典型用途 |
|---|---|---|
on_tool_start |
Tool 开始执行 | 记录工具调用参数 |
on_tool_end |
Tool 执行完成 | 记录工具返回结果 |
on_tool_error |
Tool 执行出错 | 重试或回滚 |
Retriever 事件
| 事件方法 | 触发时机 | 典型用途 |
|---|---|---|
on_retriever_start |
检索开始 | 记录查询语句 |
on_retriever_end |
检索完成 | 记录检索到的文档 |
on_retriever_error |
检索失败 | 备用检索策略 |
文本与流事件
| 事件方法 | 触发时机 | 典型用途 |
|---|---|---|
on_text |
任意文本输出 | 日志记录、调试输出 |
四、使用场景:什么时候用 Callback?
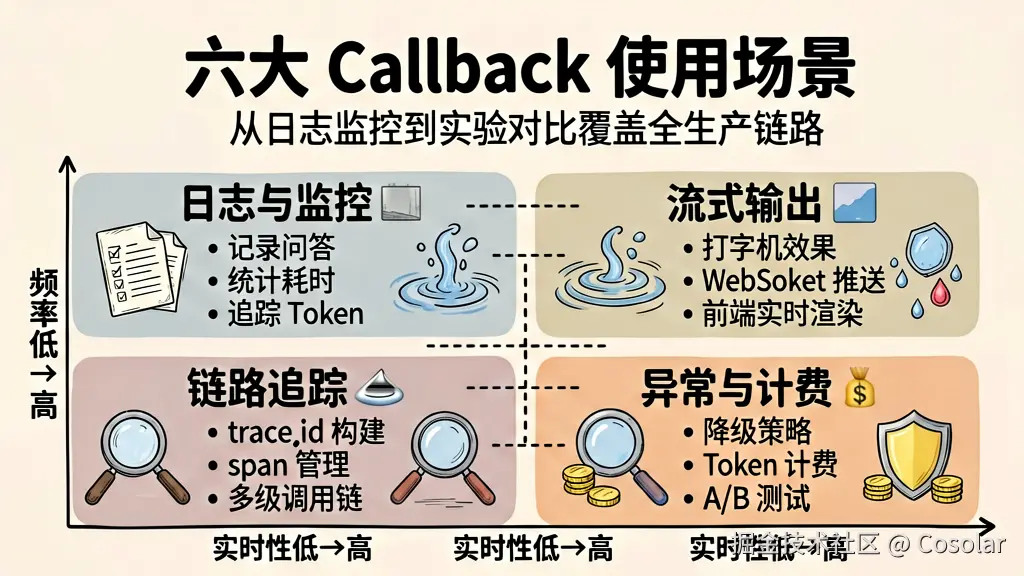 ▲ 从日志监控到实验对比,六大场景覆盖生产环境所有需求
▲ 从日志监控到实验对比,六大场景覆盖生产环境所有需求
场景 1:日志与监控 📊
最简单的场景 ------ 记录谁、在什么时候、问了什么问题、得到了什么回答、花了多长时间。
python
class LoggingCallbackHandler(BaseCallbackHandler):
def on_llm_start(self, serialized, prompts, **kwargs):
start_time = time.time()
kwargs.get("run_id")
# 写入日志系统或数据库
def on_llm_end(self, response, **kwargs):
elapsed = time.time() - start_time
tokens = response.llm_output.get("token_usage", {})
# 保存耗时和 Token 消耗场景 2:流式输出到前端 🌊
RAG 应用中,用户不想等全部生成完毕才看到结果------他们想要打字机效果:
python
class StreamingCallbackHandler(BaseCallbackHandler):
def __init__(self, websocket):
self.ws = websocket
def on_llm_new_token(self, token, **kwargs):
self.ws.send(json.dumps({"type": "token", "content": token}))
def on_llm_end(self, response, **kwargs):
self.ws.send(json.dumps({"type": "done"}))场景 3:Token 用量追踪与计费 💰
在 SaaS 产品中,你需要精确追踪每个用户消耗了多少 Token:
python
class TokenUsageCallback(BaseCallbackHandler):
def __init__(self, user_id):
self.user_id = user_id
def on_llm_end(self, response, **kwargs):
usage = response.llm_output.get("token_usage", {})
prompt_tokens = usage.get("prompt_tokens", 0)
completion_tokens = usage.get("completion_tokens", 0)
total = prompt_tokens + completion_tokens
# 记录到计费系统
BillingService.record(self.user_id, total, model_name)场景 4:链路追踪与可观测性 🔍
复杂应用中,一个请求可能经过 Chain → LLM → Tool → Retriever 多个环节。Callback 可以构建完整的调用链路:
python
class TracingCallback(BaseCallbackHandler):
def __init__(self):
self.trace_id = str(uuid.uuid4())
self.spans = []
def on_chain_start(self, serialized, inputs, **kwargs):
self.spans.append({
"trace_id": self.trace_id,
"span_id": str(uuid.uuid4()),
"parent_id": kwargs.get("parent_run_id"),
"type": "chain",
"start_time": time.time(),
})
def on_chain_end(self, outputs, **kwargs):
# 结束 span
...场景 5:异常处理与降级 🛡️
当 Tool 或 LLM 调用失败时,自动执行降级策略:
python
class FallbackCallback(BaseCallbackHandler):
def __init__(self, fallback_llm="gpt-3.5-turbo"):
self.fallback_llm = fallback_llm
def on_llm_error(self, error, **kwargs):
logger.error(f"LLM 调用失败: {error}")
# 自动切换到备用模型
if "rate_limit" in str(error).lower():
notify_ops_team("API 限流,请检查配额")场景 6:A/B 测试与实验 🧪
对比不同 Prompt 或模型的效果:
python
class ABTestCallback(BaseCallbackHandler):
def on_llm_end(self, response, **kwargs):
test_group = self._get_test_group()
metrics = {
"group": test_group,
"latency": response.llm_output.get("latency"),
"tokens": response.llm_output.get("token_usage"),
}
ExperimentService.record(metrics)五、实战:构建一个完整的日志 & 监控系统
让我们把前面学的串起来,构建一个完整的回调系统:
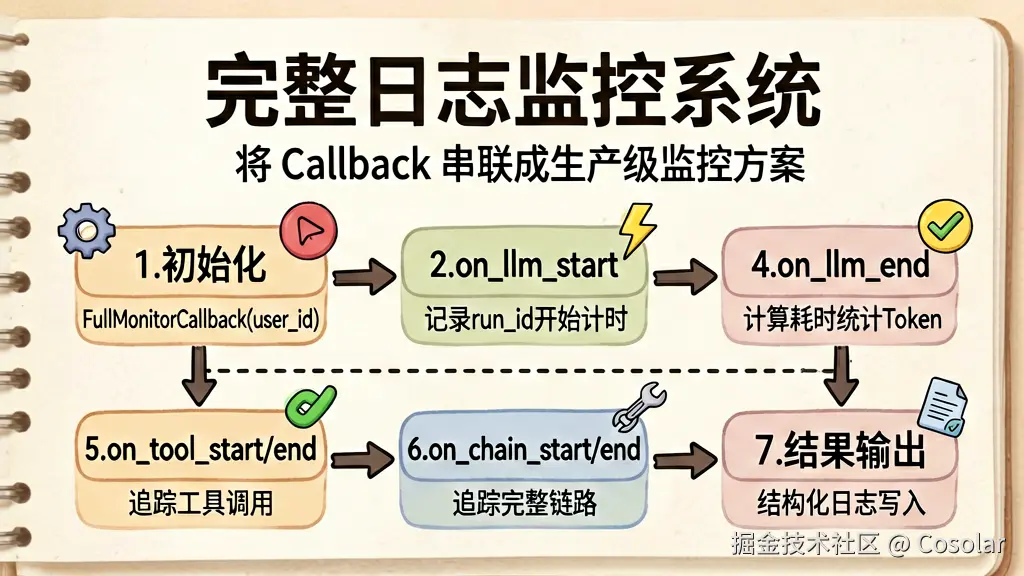 ▲ 从初始化到结果输出,完整串联 Callback 事件构建生产级监控
▲ 从初始化到结果输出,完整串联 Callback 事件构建生产级监控
python
import time
import logging
from typing import Any, Dict, List, Optional
from langchain.callbacks.base import BaseCallbackHandler
from langchain_core.messages import BaseMessage
from langchain.schema import LLMResult
logger = logging.getLogger(__name__)
class FullMonitorCallback(BaseCallbackHandler):
"""综合监控回调:日志 + 性能 + Token 用量"""
def __init__(self, user_id: str = "anonymous"):
self.user_id = user_id
self.starts: Dict[str, float] = {}
self.token_totals: Dict[str, int] = {"prompt": 0, "completion": 0}
def on_llm_start(
self, serialized: Dict[str, Any],
prompts: List[str], **kwargs
) -> None:
run_id = str(kwargs.get("run_id", ""))
self.starts[run_id] = time.time()
logger.info(
f"[{self.user_id}] LLM 开始 | prompts: {prompts[:1]}..."
)
def on_llm_new_token(self, token: str, **kwargs) -> None:
# 可以在这里做实时处理
pass
def on_llm_end(
self, response: LLMResult, **kwargs
) -> None:
run_id = str(kwargs.get("run_id", ""))
elapsed = time.time() - self.starts.pop(run_id, time.time())
usage = response.llm_output.get("token_usage", {}) if response.llm_output else {}
prompt_tokens = usage.get("prompt_tokens", 0)
completion_tokens = usage.get("completion_tokens", 0)
self.token_totals["prompt"] += prompt_tokens
self.token_totals["completion"] += completion_tokens
logger.info(
f"[{self.user_id}] LLM 完成 | "
f"耗时: {elapsed:.2f}s | "
f"Token: 输入={prompt_tokens}, 输出={completion_tokens}"
)
def on_llm_error(
self, error: BaseException, **kwargs
) -> None:
logger.error(
f"[{self.user_id}] LLM 错误: {error}"
)
def on_tool_start(
self, serialized: Dict[str, Any],
input_str: str, **kwargs
) -> None:
logger.info(
f"[{self.user_id}] Tool 调用: {serialized.get('name', 'unknown')} | "
f"输入: {input_str[:100]}"
)
def on_tool_end(self, output: str, **kwargs) -> None:
logger.info(
f"[{self.user_id}] Tool 完成 | "
f"输出长度: {len(output)}"
)
def on_chain_start(
self, serialized: Dict[str, Any],
inputs: Dict[str, Any], **kwargs
) -> None:
logger.info(
f"[{self.user_id}] Chain 开始: "
f"{serialized.get('name', 'unnamed')}"
)
def on_chain_end(
self, outputs: Dict[str, Any], **kwargs
) -> None:
logger.info(f"[{self.user_id}] Chain 完成")
# ===== 使用示例 =====
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnableConfig
# 配置回调
monitor = FullMonitorCallback(user_id="user_123")
config = RunnableConfig(callbacks=[monitor])
# 创建 Chain
llm = ChatOpenAI(model="gpt-4")
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个 AI 助手"),
("human", "{input}")
])
chain = prompt | llm
# 执行
result = chain.invoke(
{"input": "请用简单的语言解释什么是机器学习"},
config=config
)六、高级技巧:Callback 的三种作用域
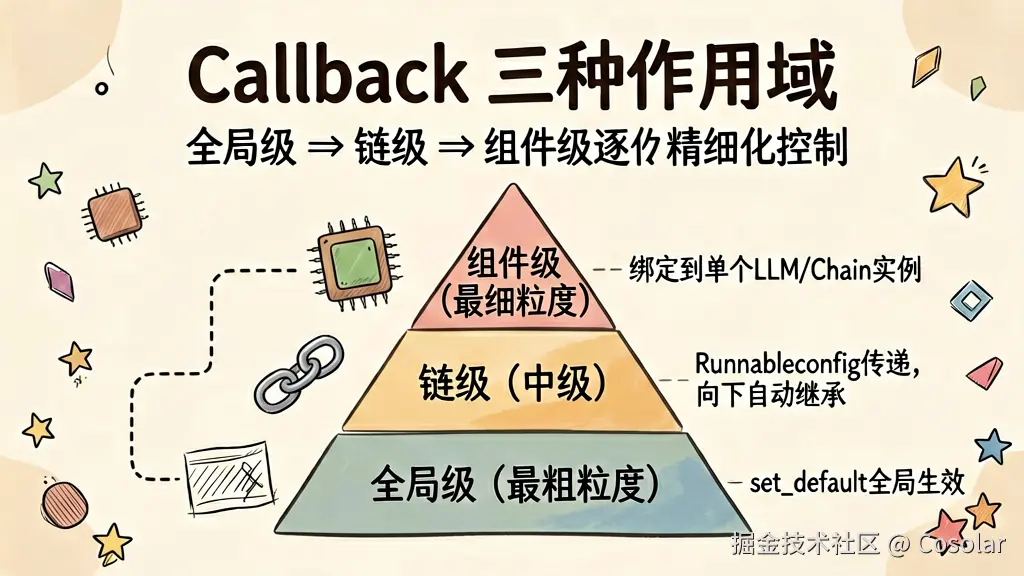 ▲ 全局级 → 链级 → 组件级,逐层精细化控制回调范围
▲ 全局级 → 链级 → 组件级,逐层精细化控制回调范围
6.1 全局级
通过 langchain.callbacks.set_default_callback() 设置后,对所有 Chain 生效:
python
from langchain.callbacks import set_default_callback
set_default_callback(GlobalLoggingHandler())6.2 链级
通过 RunnableConfig 传入,只对当前 Chain 及其子组件生效(自动向下传递):
python
config = RunnableConfig(callbacks=[ChainLevelHandler()])
chain.invoke(inputs, config=config)6.3 组件级
直接绑定到某个组件,只对该组件生效:
python
llm = ChatOpenAI(model="gpt-4", callbacks=[LLMOnlyHandler()])6.4 继承与覆盖规则
markdown
如果全局、链级、组件级都定义了回调:
1. 子组件**默认继承**父组件的回调
2. 如果子组件也指定了回调,则**合并**(不覆盖)
3. 相同的 Handler 不会重复调用(去重)七、最佳实践与注意事项
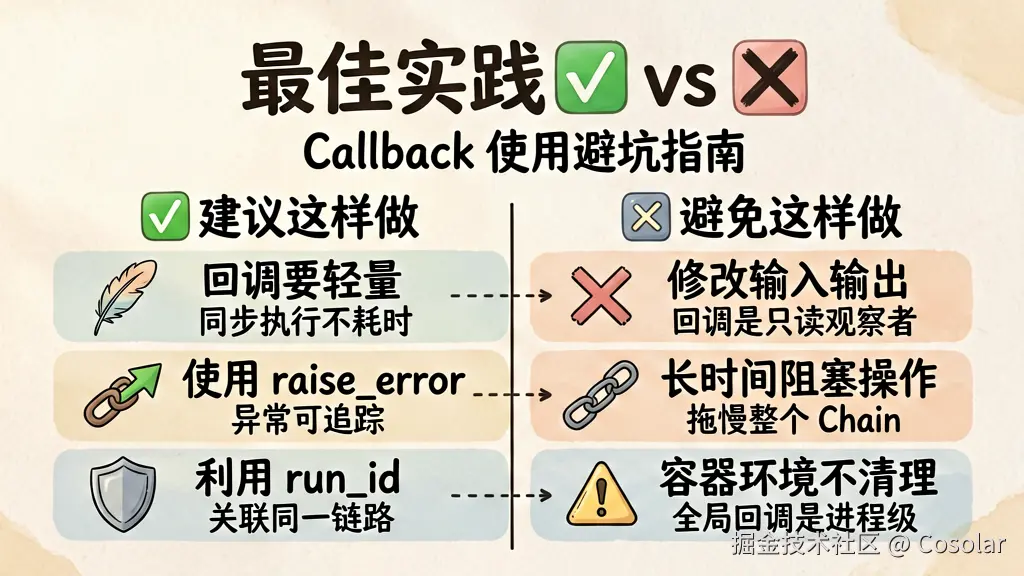 ▲ 建议这样做 vs 避免这样做,生产环境避坑指南
▲ 建议这样做 vs 避免这样做,生产环境避坑指南
✅ 建议这样做
- 回调要轻量 --- 回调是同步执行的,不要在回调里做耗时操作。需要的话用
asyncio或消息队列异步处理 - 使用
raise_error参数 ---BaseCallbackHandler(raise_error=True)可以让回调中的异常传播,便于调试 - 充分利用
run_id--- 每个事件都携带run_id,可以用来关联同一链路中的多个事件 - 配置
verbose=False--- 线上环境关闭 LangChain 默认的控制台输出,避免日志爆炸
❌ 避免这样做
- 不要在回调里修改输入/输出 --- Callback 是只读的观察者模式,不要尝试修改事件参数
- 不要做长时间阻塞操作 --- 会拖慢整个 Chain 的执行
- 不要在容器环境忘记清理 --- 全局回调是进程级别的,容器重启时注意清理
性能对比
| 回调复杂度 | 100次调用耗时 | 建议 |
|---|---|---|
| 无回调 | ~2.1s | 生产环境最小配置 |
| 简单日志回调 | ~2.2s (+5%) | ✅ 推荐 |
| 带 DB 写入的回调 | ~3.5s (+67%) | ⚠️ 建议异步 |
| 带外部 HTTP 的回调 | ~5.8s (+176%) | ❌ 必须异步 |
八、总结
 ▲ 继承 → 配置 → 异步化,掌握 Callback 让应用真正上线
▲ 继承 → 配置 → 异步化,掌握 Callback 让应用真正上线
LangChain 的 Callback 机制是构建生产级 LLM 应用的必备技能。它不是"锦上添花"的特性,而是刚需:
- 日志与监控 --- 没有回调,你就无法知道应用在做什么
- 流式输出 --- 面向用户的体验需求
- Token 计费 --- SaaS 产品的商业基石
- 链路追踪 --- 排查复杂问题的必备能力
核心要记住三句话:
- 继承
BaseCallbackHandler,重写你需要的事件方法 - 通过
RunnableConfig传入回调 - 回调要轻量,数据库和 HTTP 走异步
掌握 Callback,你的 LangChain 应用才算真正"上线"了。
觉得有用?欢迎分享给更多同学!🚀
📋 附录:快速参考表
| 事件 | 父类方法 | 何时触发 | 常用参数 |
|---|---|---|---|
| LLM 开始 | on_llm_start |
调用 LLM 前 | serialized, prompts, run_id |
| LLM Token | on_llm_new_token |
每个 Token 生成 | token, run_id |
| LLM 完成 | on_llm_end |
LLM 返回 | response(LLMResult), run_id |
| LLM 错误 | on_llm_error |
LLM 异常 | error, run_id |
| Chat 开始 | on_chat_model_start |
Chat 调用前 | serialized, messages, run_id |
| Chain 开始 | on_chain_start |
Chain 开始 | serialized, inputs, run_id |
| Chain 完成 | on_chain_end |
Chain 结束 | outputs, run_id |
| Chain 错误 | on_chain_error |
Chain 异常 | error, run_id |
| Tool 开始 | on_tool_start |
Tool 执行前 | serialized, input_str, run_id |
| Tool 完成 | on_tool_end |
Tool 结束 | output, run_id |
| Tool 错误 | on_tool_error |
Tool 异常 | error, run_id |
| 检索开始 | on_retriever_start |
检索前 | serialized, query, run_id |
| 检索完成 | on_retriever_end |
检索后 | documents, run_id |
| 文本输出 | on_text |
任意文本 | text, run_id |