Hermes 是一款主打 "自我进化" 的 Agent 框架,其记忆系统的核心设计哲学是认知经济性------ 即 "只记住对未来行为有价值的信息",通过严格的记忆审查与精炼机制,将有限的计算资源集中于高价值记忆,实现了记忆质量与系统效率的平衡。
1. 架构设计原理
Hermes 的记忆系统遵循 "高价值优先、严格容量控制" 的原则,将记忆划分为五个层级 ------ 层级之间通过 "记忆审查" 机制完成信息流转,每一层都有明确的容量上限与价值评估标准,确保只有最有价值的信息会被保留。
1.1 记忆层级结构
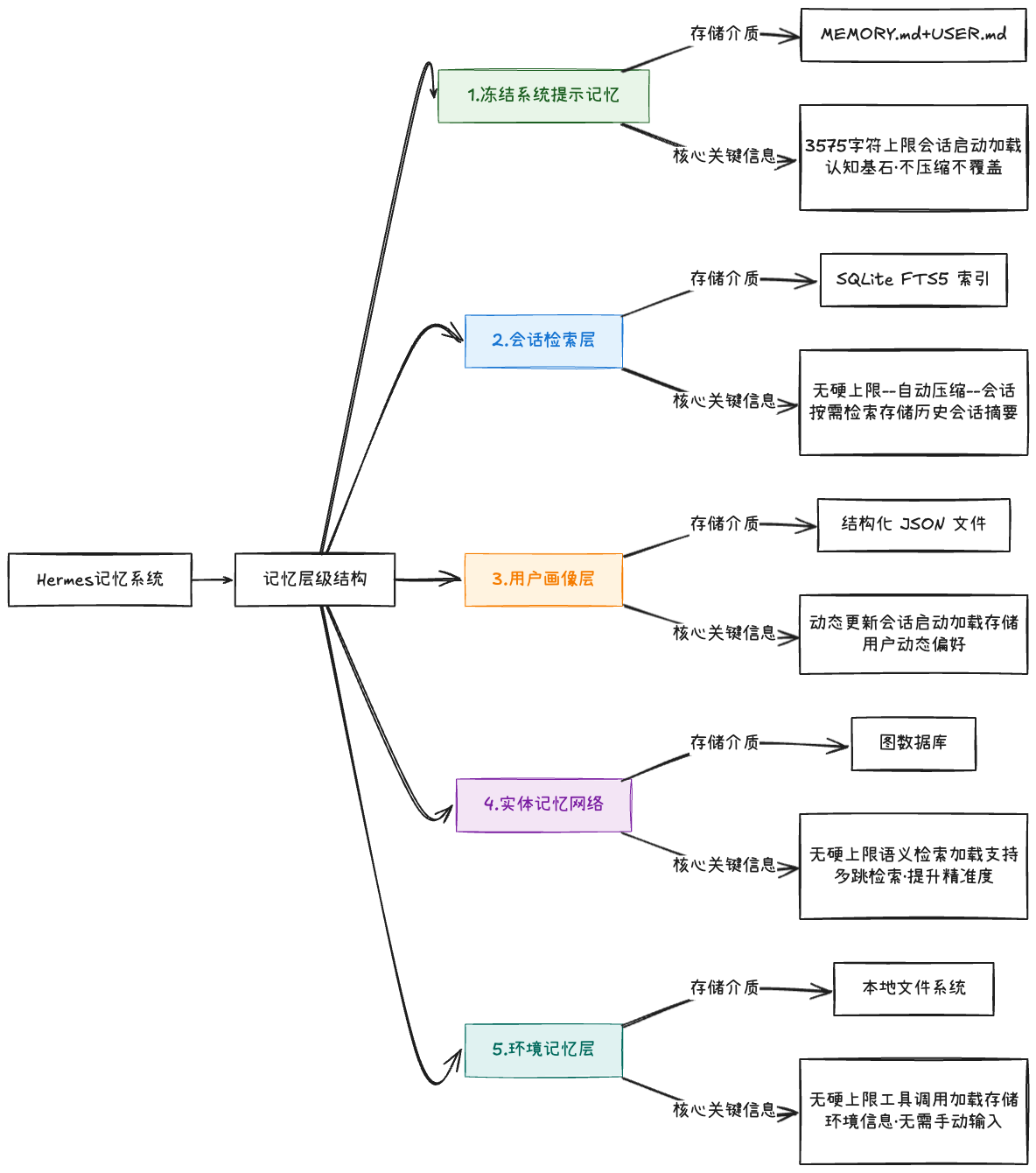
Hermes 的记忆层级是 "价值优先级分层"------ 层级越靠前,价值优先级越高、容量上限越严格、访问速度越快,层级之间通过 "晋升" 机制完成信息流转:
|------|--------------|-----------------------|-------------|-----------|---------------------------------------------------------------------------------------------------------------------|
| 层级序号 | 记忆类型 | 存储介质 | 容量上限 | 加载时机 | 核心功能 |
| 1 | 冻结系统提示记忆 | MEMORY.md+USER.md | 合计约 3575 字符 | 每次会话启动时 | 存储最核心的记忆:MEMORY.md保存 Agent 的 "环境事实"(如项目技术栈、核心约束),USER.md保存用户的 "长期偏好"(如沟通风格、决策习惯)。这一层是 Agent 的 "认知基石",永远不会被压缩或覆盖 |
| 2 | 会话检索层 | SQLite FTS5 全文索引 | 无硬上限(自动压缩) | 会话过程中按需检索 | 存储所有历史会话的摘要 ------ 每轮对话结束后,系统会将对话内容压缩为 100-200 字的摘要,保留核心需求与结论,支持数周乃至数月前的上下文检索 |
| 3 | 用户画像层 | 结构化 JSON 文件 | 随用户交互动态更新 | 会话启动时 | 存储用户的动态偏好 ------ 比如用户最近提到的 "喜欢用表格展示数据""讨厌冗长的技术术语",这些信息会实时更新,用于优化 Agent 的输出风格 |
| 4 | 实体记忆网络 | 图数据库 | 无硬上限 | 语义检索时 | 存储实体之间的关联关系 ------ 比如 "用户 A 是项目 B 的负责人""项目 B 使用的技术栈是 React+Node.js",支持多跳语义检索,提升复杂问题的回答精准度 |
| 5 | 环境记忆层 | 本地文件系统 | 无硬上限 | 工具调用时 | 存储环境相关的信息 ------ 比如服务器的 IP 地址、数据库的连接参数、工具的使用文档,这些信息会在工具调用时自动加载,无需手动输入 |
需要特别说明的是,Hermes 的 "冻结系统提示记忆" 层有严格的容量控制:MEMORY.md上限约 2200 字符,USER.md上限约 1375 字符,合计约 3575 字符。这一限制的目的,是强制 Agent 将最核心的记忆精炼到极致,避免冗余信息占用宝贵的上下文窗口。
1.2 核心机制解析
Hermes 的记忆系统通过三大核心机制,实现了 "主动学习" 的设计目标 ------ 让 Agent 从 "被动记录" 升级为 "主动筛选高价值信息"。
(1)记忆审查与晋升:确保只有高价值信息进入核心记忆
这是 Hermes 记忆系统最核心的机制,也是其区别于其他框架的关键 ------ 它解决了传统记忆系统 "记忆冗余" 与 "价值衰减" 的问题。记忆审查的流程是:
-
触发条件:当会话轮次达到 10 轮,或会话 Token 数量接近模型上下文窗口的 80% 时,系统会自动触发记忆审查。
-
审查逻辑:系统会调用底层 LLM 对当前会话的所有信息进行评估,评估维度包括 "复用价值"(该信息是否会在未来会话中被用到)、"时效性"(该信息的有效期有多长)、"准确性"(该信息是否经过验证)。
-
晋升规则 :通过审查的信息,会被写入
MEMORY.md或USER.md,成为核心记忆;未通过审查的信息,会被压缩为摘要,存入会话检索层;完全无价值的信息,会被直接删除。 -
容量控制:当核心记忆的容量接近上限时,系统会自动对现有核心记忆进行 "二次审查"------ 将价值最低的条目移动到会话检索层,为新条目腾出空间。
这种设计的核心逻辑是:核心记忆的容量是有限的,必须留给最有价值的信息 ------ 比如用户反复强调的 "项目必须支持 IE11 浏览器",会被写入MEMORY.md,永久保留;而用户偶然提到的 "今天天气不错",会被直接删除。
(2)认知经济性原则:最小化上下文注入,最大化信息密度
Hermes 的上下文管理遵循 "认知经济性" 原则 ------ 即 "只将对当前任务有价值的记忆注入上下文,避免无意义的信息占用资源"。具体规则包括:
-
核心记忆全量注入 :
MEMORY.md与USER.md的内容会在每次会话启动时全量注入上下文 ------ 因为这两层是 Agent 的 "认知基石",所有任务都需要基于这些信息执行。 -
会话记忆按需检索:会话检索层的内容不会全量注入上下文,而是在 Agent 需要时通过 SQLite FTS5 全文检索获取 ------ 比如 Agent 需要回忆用户上周提到的 "支付模块需求",会先检索会话摘要,找到对应的条目后再注入上下文。
-
动态记忆实时更新:用户画像层与环境记忆层的内容,会在每次会话中实时更新 ------ 比如用户在当前会话中提到 "喜欢用 Markdown 格式输出",系统会立即更新用户画像层的内容,并在后续会话中自动应用。
根据 Hermes 官方的测试数据,通过认知经济性原则,上下文的 Token 数量比全量注入降低了 60%,同时回答的准确率保持在 95% 以上。
(3)GEPA 自我进化引擎:让记忆系统自我优化
GEPA(Gradient-based Experience Policy Adaptation)是 Hermes 的自我进化引擎,它通过类反向传播的方式优化记忆系统的性能 ------ 让 Agent 从 "经验" 中学习,提升记忆的准确性与检索效率。具体流程是:
-
行为记录:系统会记录每一次记忆检索的结果 ------ 比如 "检索到的信息是否被 Agent 采用""采用后回答的准确率如何""用户是否对回答满意"。
-
效果评估:系统会对这些记录进行评估,计算每一条记忆的 "价值得分"------ 得分越高,说明该记忆的复用价值越高。
-
策略优化:系统会根据价值得分,调整记忆的检索优先级与晋升规则 ------ 比如某类记忆的得分持续偏低,系统会降低其检索优先级;某类记忆的得分持续偏高,系统会提升其晋升权重。
-
技能沉淀 :当某类记忆的得分达到一定阈值时,系统会自动将其提炼为 "技能文件"------ 比如 "如何处理用户的退款请求",技能文件会被存储在
skills/目录下,后续会话可以直接调用,无需重新检索记忆。
这种设计的核心逻辑是:记忆系统不是静态的,而是可以通过自我学习持续优化的------ 使用时间越长,记忆系统的性能越好,Agent 的回答也会越精准。
2 设计哲学:效率与学习能力的平衡
Hermes 的记忆架构,本质是对 "认知资源稀缺性" 的深刻理解 ------ 它将有限的计算资源与上下文窗口,集中于最有价值的记忆内容,实现了效率与学习能力的平衡。
2.1 为什么设置严格的核心记忆容量上限?
这是 Hermes 最具争议的设计之一,但也是其最能体现 "认知经济性" 原则的决策。根据 Hermes 核心开发者的解读,这一限制的目的有三个:
-
对抗上下文膨胀:传统记忆系统的核心问题,是上下文窗口被大量冗余信息占用 ------ 比如将上百轮的对话历史全量注入上下文,导致模型无法聚焦核心需求。通过严格的容量限制,Hermes 强制 Agent 将最核心的记忆精炼到极致,避免冗余信息占用宝贵的上下文窗口。
-
提升检索命中率:核心记忆的容量越小,Agent 在检索时找到高价值信息的概率越高 ------ 比如 1000 字符的核心记忆,检索命中率可以达到 95%;而 10000 字符的核心记忆,检索命中率可能只有 60%。
-
强化记忆的持久性:只有被写入核心记忆的信息,才会被永久保留 ------ 这一限制,会让 Agent 更倾向于记录 "长期有价值的信息",而非 "临时的会话细节"。
2.2 为什么采用主动学习机制?
Hermes 的设计目标是 "持续在线的数字员工"------ 即 Agent 需要在长周期的交互中,持续学习用户的需求与偏好,优化自身的行为。被动记录的记忆系统,无法满足这一需求 ------ 因为它会记录所有信息,包括无价值的冗余信息,导致记忆系统的性能随时间下降。
主动学习机制的价值,在于让 Agent "学会选择记忆的内容"------ 它会自动过滤掉无价值的信息,保留高价值的信息;同时,它会将高价值的信息提炼为技能,让 Agent 的能力随时间提升。这种设计,让 Hermes 成为了 "越用越强" 的 Agent 框架 ------ 根据官方的测试数据,使用 Hermes 30 天后,Agent 的回答准确率会提升 30% 以上。
2.3 为什么采用 SQLite FTS5?
SQLite FTS5 是 Hermes 记忆系统的核心检索引擎 ------ 它是一种轻量级的全文检索引擎,无需额外的服务端,直接嵌入在 SQLite 数据库中。Hermes 选择 SQLite FTS5 的原因,主要有三个:
-
轻量级与自包含:SQLite FTS5 无需额外安装或配置,适合自托管场景 ------ 用户只需安装 Hermes,即可使用全文检索功能,无需额外部署 Elasticsearch、Pinecone 等服务。
-
性能均衡:SQLite FTS5 的检索性能足以满足大多数场景的需求 ------ 对于百万级别的文档,检索延迟可以控制在毫秒级。
-
与记忆审查的兼容性:SQLite FTS5 支持对检索结果的排序与过滤,这与 Hermes 的记忆审查机制高度兼容 ------ 系统可以根据记忆的价值得分,对检索结果进行排序,优先返回高价值的信息。
3 场景适配性分析
Hermes 的记忆架构,本质是为 "需要持续学习、频繁交互的场景" 设计的 ------ 这类场景的核心需求是 "记忆的质量优先于数量",具体包括:
(1)个人数字助理
个人数字助理场景的核心需求是 "个性化交互"------ 比如记住用户的日程安排、偏好设置、常用工具,无需每次重复输入。Hermes 的用户画像层与核心记忆机制,天然满足这一需求:
-
用户的偏好(如 "喜欢早上 8 点收到日程提醒""讨厌接收垃圾邮件")会被写入
USER.md,永久保留; -
用户的日程安排、待办事项会被存入会话检索层,支持快速检索;
-
随着使用时间的增长,GEPA 引擎会自动优化记忆的检索优先级 ------ 比如用户经常查询 "最近的会议安排",系统会提升日程记忆的检索优先级,让 Agent 更快地给出回答。
典型案例:某用户用 Hermes 作为个人数字助理,每天早上 8 点,Agent 会自动检索用户的日程安排,发送提醒;当用户收到新邮件时,Agent 会自动过滤垃圾邮件,并将重要邮件的摘要发送给用户。该用户的日常事务处理效率比原来提升了 50%。
(2)智能客服
智能客服场景的核心需求是 "快速响应 + 个性化服务"------ 比如记住用户的历史问题、购买记录、偏好,提供精准的解决方案。Hermes 的记忆审查与会话检索机制,完美适配这一需求:
-
用户的历史问题与解决方案会被存入会话检索层,支持快速检索 ------ 当用户再次提问时,Agent 可以直接调用历史解决方案,无需重新思考;
-
用户的购买记录与偏好会被写入
USER.md,用于个性化推荐 ------ 比如用户购买过某款产品,Agent 会推荐相关的配件或服务; -
记忆审查机制会自动过滤掉无价值的信息 ------ 比如用户的辱骂性语言、重复提问,确保核心记忆的质量。
典型案例:某电商平台用 Hermes 构建智能客服系统,Agent 可以记住用户的历史购买记录与偏好,提供个性化的推荐。该平台的客服响应时间从原来的 15 秒缩短到了 3 秒,用户满意度提升了 40%。
(3)持续学习型任务
持续学习型任务场景的核心需求是 "知识沉淀 + 自我优化"------ 比如代码审查、数据分析、市场调研,这些任务需要 Agent 持续积累知识,优化自身的行为。Hermes 的 GEPA 引擎与技能沉淀机制,正是为了解决这一问题:
-
任务中的经验教训会被写入
MEMORY.md,成为核心记忆 ------ 比如代码审查中发现的 "常见 bug 类型",会被沉淀为技能文件,后续审查时自动调用; -
GEPA 引擎会自动优化记忆的检索优先级 ------ 比如某类 bug 的出现频率较高,系统会提升该类 bug 的检索优先级,让 Agent 更快地发现问题;
-
技能文件会在使用中持续自我改进 ------ 比如某类 bug 的解决方案被验证有效,系统会自动更新技能文件,提升其准确性。
典型案例:某技术团队用 Hermes 进行代码审查,Agent 可以记住常见的 bug 类型与解决方案,自动发现代码中的问题。该团队的代码审查效率比原来提升了 30%,bug 率降低了 25%。···················································································································