以下是为您整理的 LiveTalking Windows 部署复盘教程,编译部分已按您的要求精简并指向您的系列文章。
LiveTalking 数字人项目 Windows 部署完全指南(EPGF 架构)
一、项目简介
LiveTalking (GitHub: lipku/LiveTalking)是一个开源实时数字人对话系统,支持 Wav2Lip、MuseTalk、ErNeRF 等多种驱动方案,可通过 WebRTC 在浏览器中实现低延迟的数字人视频通话与语音播报。

本文基于 EPGF(Environment Path Governance Framework)架构 在 Windows 上完成部署,使用 Python 3.12 + PyTorch 2.9.1 + CUDA 13.1,并成功在 RTX 3090 上运行 Wav2Lip 模型。
关于 EPGF 路径治理架构的详细原理,请参考:
二、环境准备
2.1 硬件与驱动
- GPU: NVIDIA GeForce RTX 3090 (24GB)
- 驱动: NVIDIA-SMI 596.49,最高支持 CUDA Version: 13.2
- CUDA Toolkit: 实机安装的最高版本 13.1 (nvcc)
- cuDNN: 9.17
多版本 CUDA 共存与切换策略请参考:
2.2 父级 Python
使用 Anaconda 创建的 py312 环境作为父级 Python(D:\A\envs\py312\python.exe),后续通过 EPGF 创建项目级隔离虚拟环境。
三、EPGF 虚拟环境创建
在项目目录下创建完全解耦的本地 .venv:
bash
:: 克隆项目
git clone https://github.com/lipku/LiveTalking.git
:: 进入项目目录
cd LiveTalking
cmd
:: 激活父级 Python
conda activate py312
:: 创建本地虚拟环境(--copies 确保完全独立)
python -m venv --copies .venv
:: 激活本地环境
.venv\Scripts\Activate
:: 退出父级 conda,避免 PATH 污染
conda deactivate
:: 验证解耦成功
where python
:: 应优先显示 .venv\Scripts\python.exe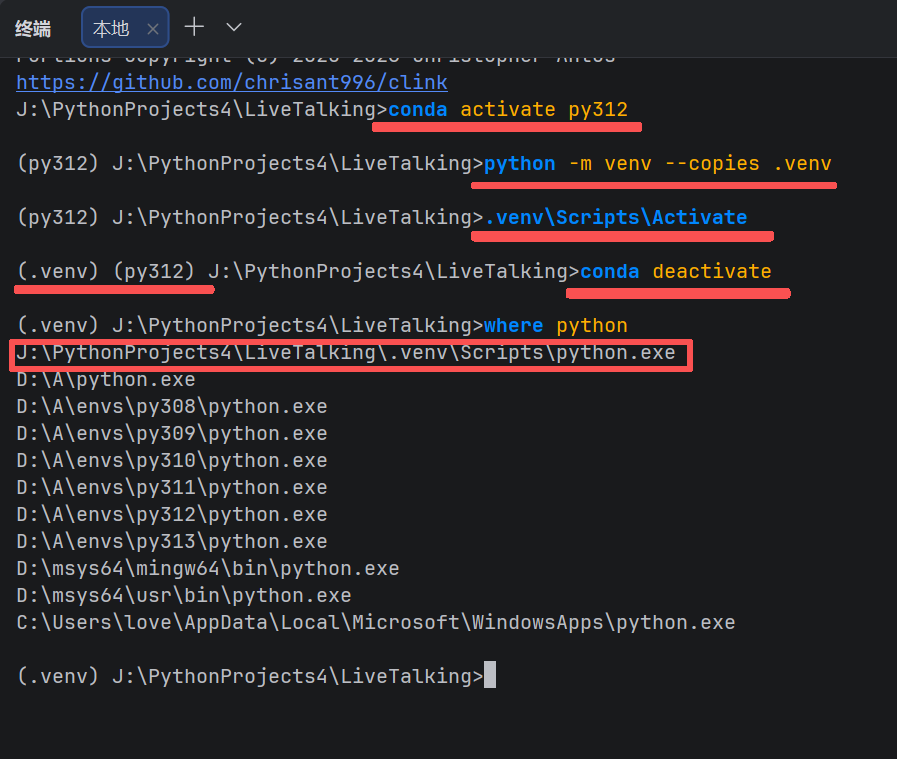
四、核心依赖安装
4.1 PyTorch (CUDA 13.0)
当前 PyTorch 官方最高提供 cu130 版本,与 CUDA 13.1/13.2 驱动兼容:
cmd
pip install torch==2.9.1 torchvision==0.24.1 torchaudio==2.9.1 --index-url https://download.pytorch.org/whl/cu130
验证:
python
import torch # 导入 PyTorch 库
print("PyTorch 版本:", torch.__version__) # 打印 PyTorch 的版本号
# 检查 CUDA 是否可用,并设置设备("cuda:0" 或 "cpu")
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("设备:", device) # 打印当前使用的设备
print("CUDA 可用:", torch.cuda.is_available()) # 打印 CUDA 是否可用
print("cuDNN 已启用:", torch.backends.cudnn.enabled) # 打印 cuDNN 是否已启用
# 打印 PyTorch 支持的 CUDA 和 cuDNN 版本
print("支持的 CUDA 版本:", torch.version.cuda)
print("cuDNN 版本:", torch.backends.cudnn.version())
# 创建两个随机张量(默认在 CPU 上)
x = torch.rand(5, 3)
y = torch.rand(5, 3)
# 将张量移动到指定设备(CPU 或 GPU)
x = x.to(device)
y = y.to(device)
# 对张量进行逐元素相加
z = x + y
# 打印结果
print("张量 z 的值:")
print(z) # 输出张量 z 的内容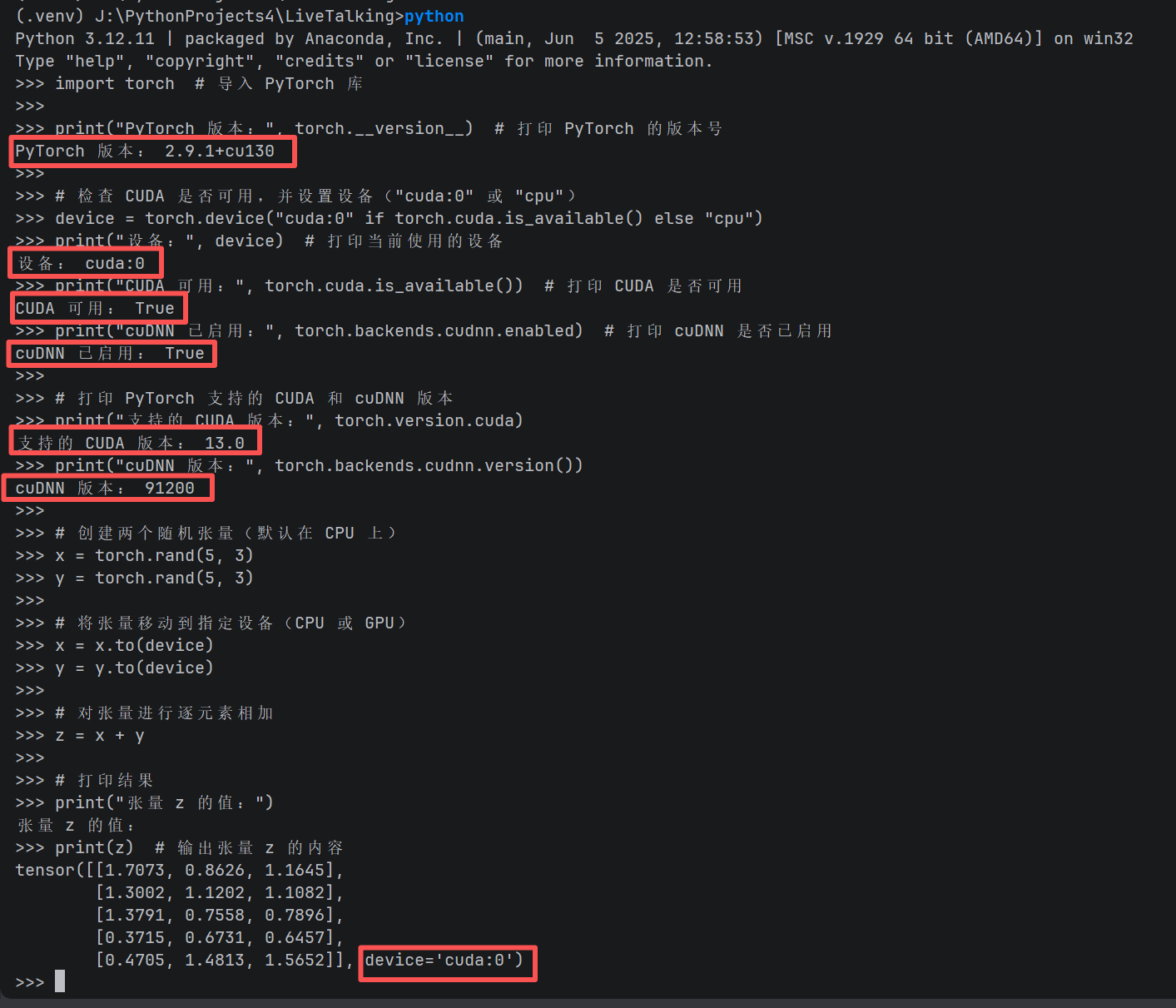
4.2 项目基础依赖
cmd
pip install -r requirements.txt
requirements.txt 中注释掉的行(如 tensorboardX、numba、opencv-python 等)为 ernerf 训练专用或已被替代 的依赖,运行 wav2lip/musetalk 时无需安装。
4.3 ONNXRuntime GPU
cmd
pip install onnxruntime-gpu --extra-index-url https://aiinfra.pkgs.visualstudio.com/PublicPackages/_packaging/onnxruntime-cuda-13/pypi/simple/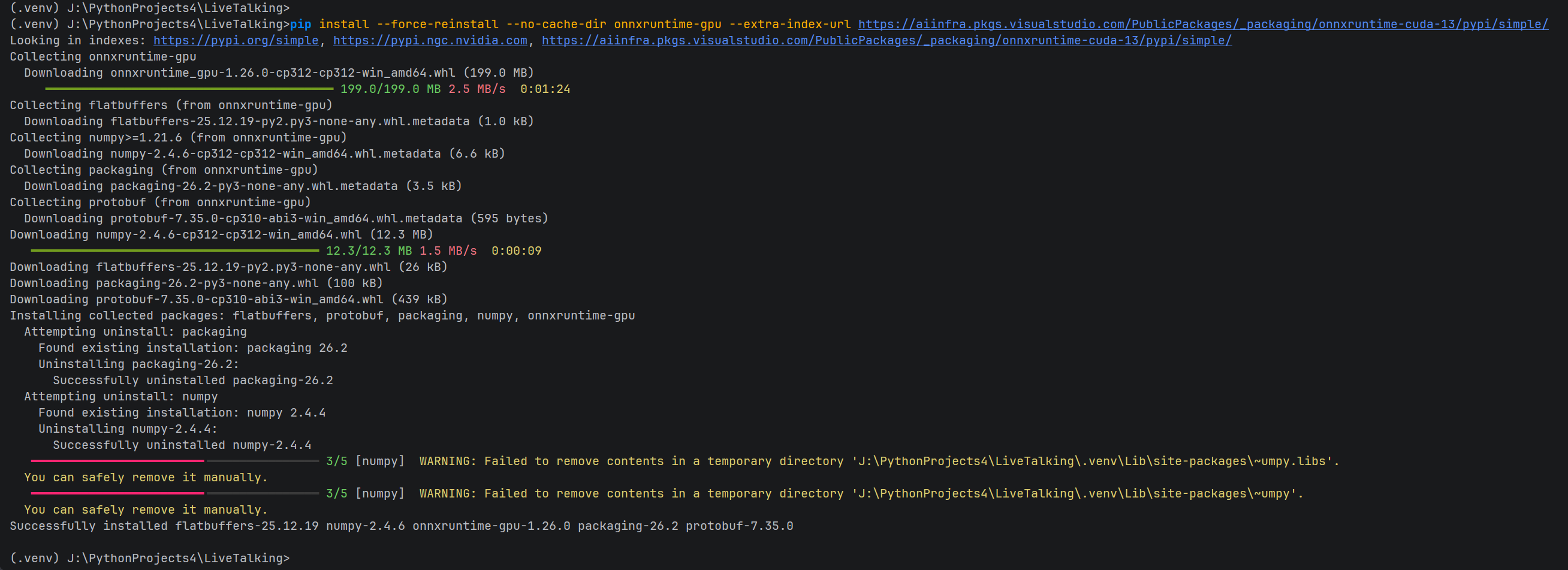
清理安装残留
python
rmdir /s /q "J:\PythonProjects4\LiveTalking\.venv\Lib\site-packages\~umpy.libs"
rmdir /s /q "J:\PythonProjects4\LiveTalking\.venv\Lib\site-packages\~umpy"
安装验证方法一:
python
# 导入 onnxruntime 模块,不使用别名
import onnxruntime
# 打印 onnxruntime 的版本号,确保已正确安装
print(onnxruntime.__version__)
# 导入 onnxruntime 模块,并使用别名 'ort',方便后续调用
import onnxruntime as ort
# 检查设备
print("Device:", ort.get_device()) # 应输出 'GPU'
# 检查可用的执行提供程序
providers = ort.get_available_providers()
print("Available providers:", providers) # 应包含 'CUDAExecutionProvider'
# 如果 GPU 支持正常,可以进一步测试推理
if 'CUDAExecutionProvider' in providers:
print("GPU support is enabled.")
else:
print("GPU support is not enabled. Please check your CUDA and cuDNN installation.")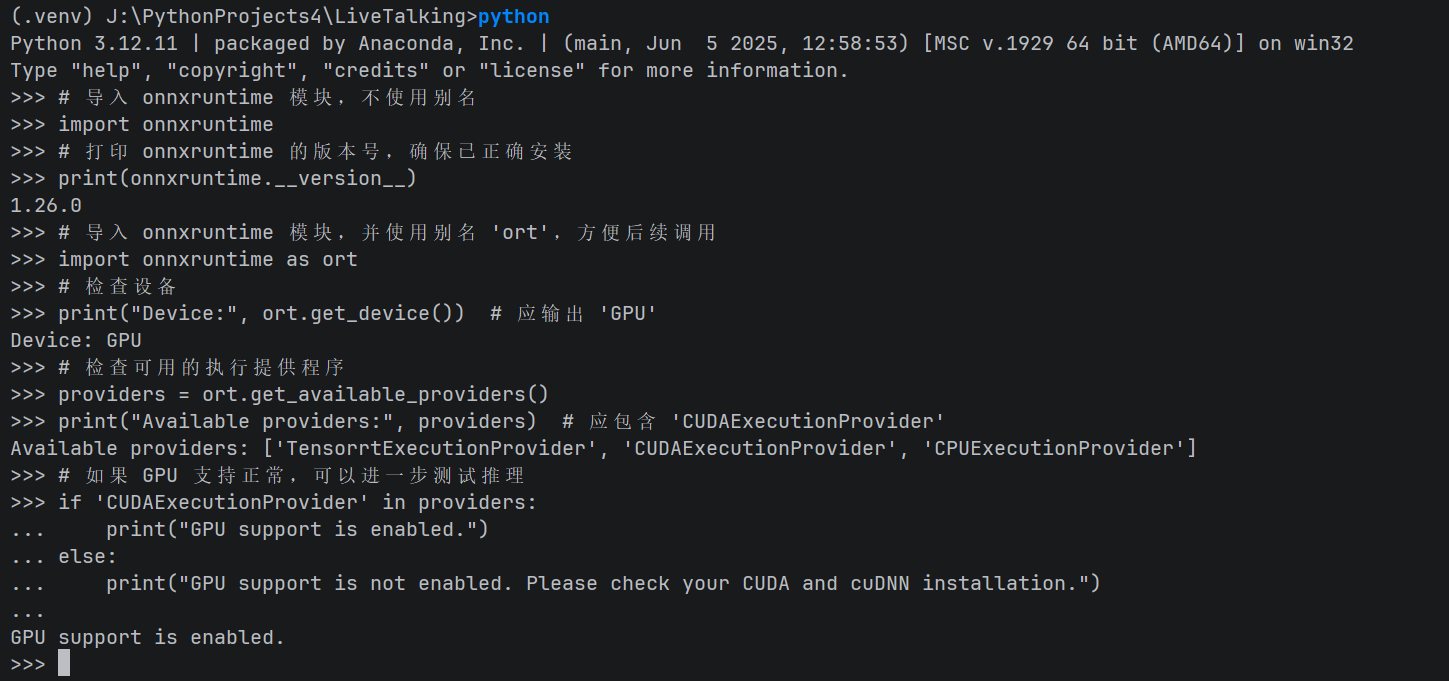
安装验证方法二:
python
python -c "import onnxruntime as ort; print(ort.get_device()); print(ort.get_available_providers())"
五、MMLab 工具链安装(关键步骤)
LiveTalking 的 MuseTalk 模型依赖 OpenMMLab 生态(mmcv、mmdet、mmpose)。Windows 下 mmcv 的 CUDA 算子编译是最大难点。
5.1 安装策略
方案 A:本地编译(推荐,性能最优)
从源码编译 MMCV 2.2.0,适配 PyTorch 2.9.1 + CUDA 13.1。编译过程涉及 MSVC 预处理器兼容性、短路径策略、CUDA 算子编译等细节。
详细编译步骤与踩坑复盘请参考以下文章,本文不再赘述:
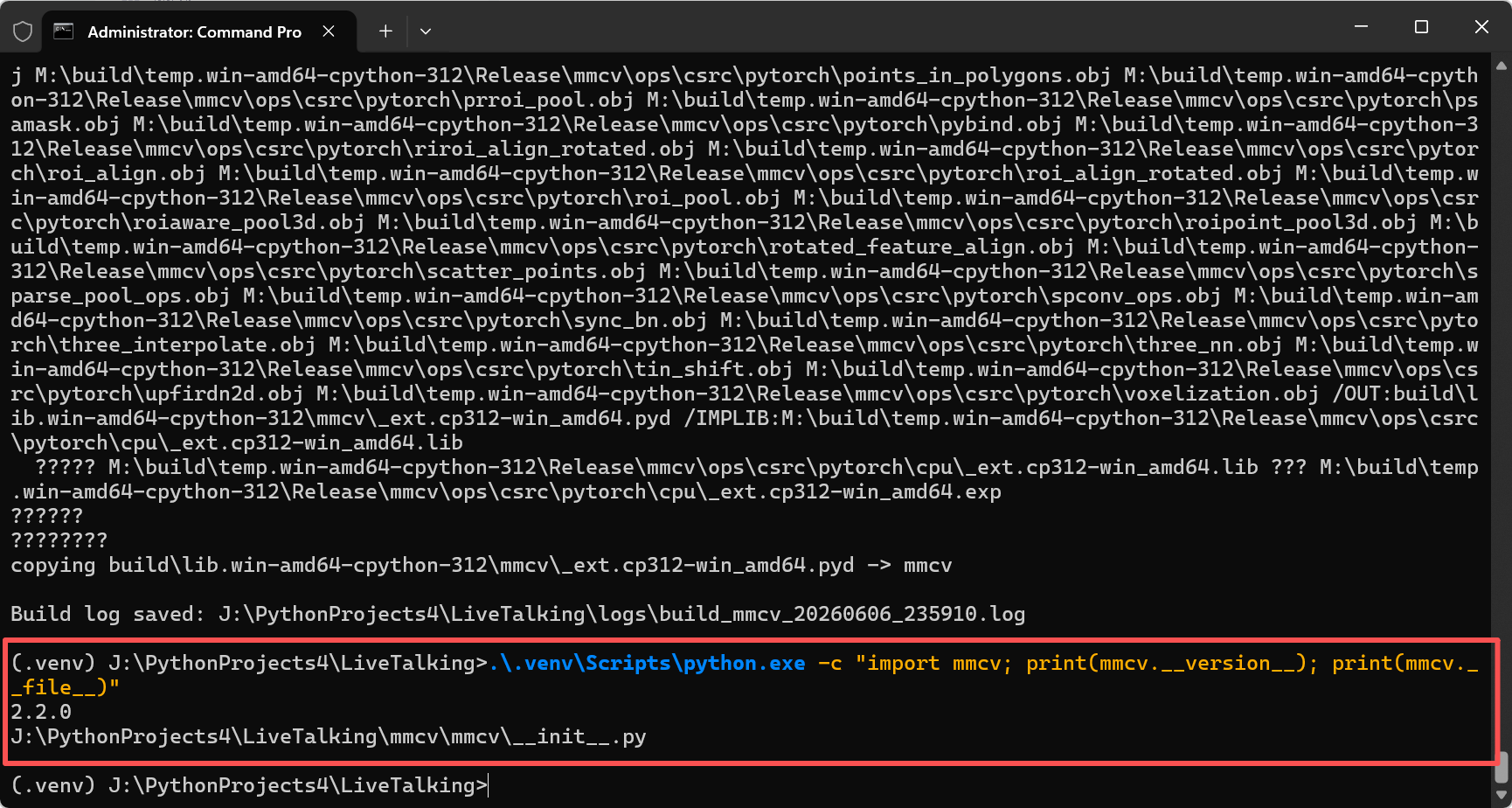
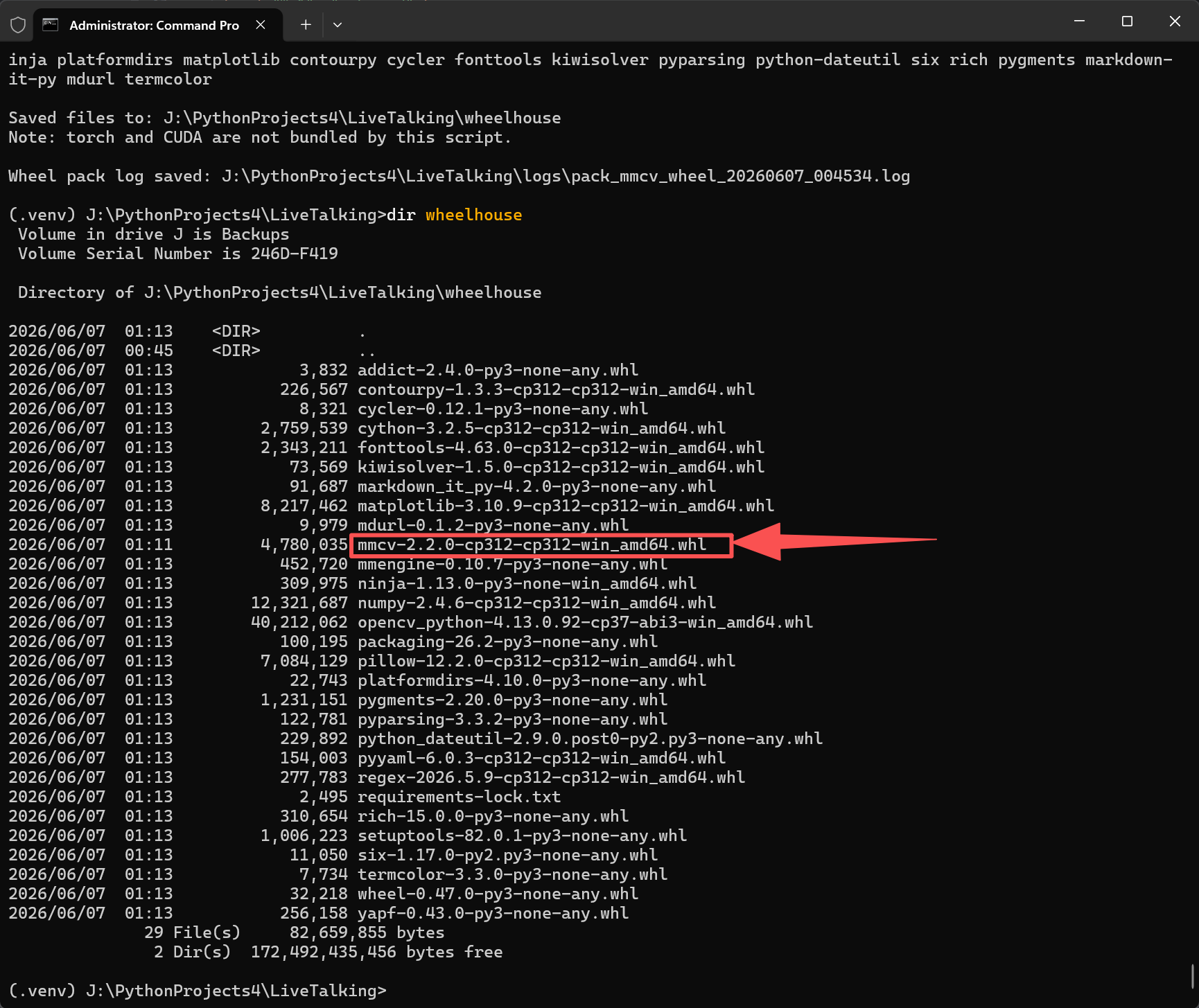
在旧版组件下编译
[torch 2.7.1+cu126]的参考:
方案 B:纯 Python/CPU 安装(备选)
如果无法完成 CUDA 编译,可使用 mmcv-lite 作为降级方案。MuseTalk 推理阶段 mmcv 仅用于 CPU 端图像预处理,不影响核心功能。
纯 Python 安装记录请参考:
5.2 安装 mmdet 与 mmpose
mmcv 就绪后,安装检测与姿态库:
cmd
pip install "mmdet>=3.1.0" -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install mmpose --no-deps -i https://pypi.tuna.tsinghua.edu.cn/simple注意:mmdet 3.3.0 默认限制
mmcv<2.2.0,需手动修改.venv\Lib\site-packages\mmdet\__init__.py中的mmcv_maximum_version为'2.3.0'以兼容已编译的 mmcv 2.2.0。

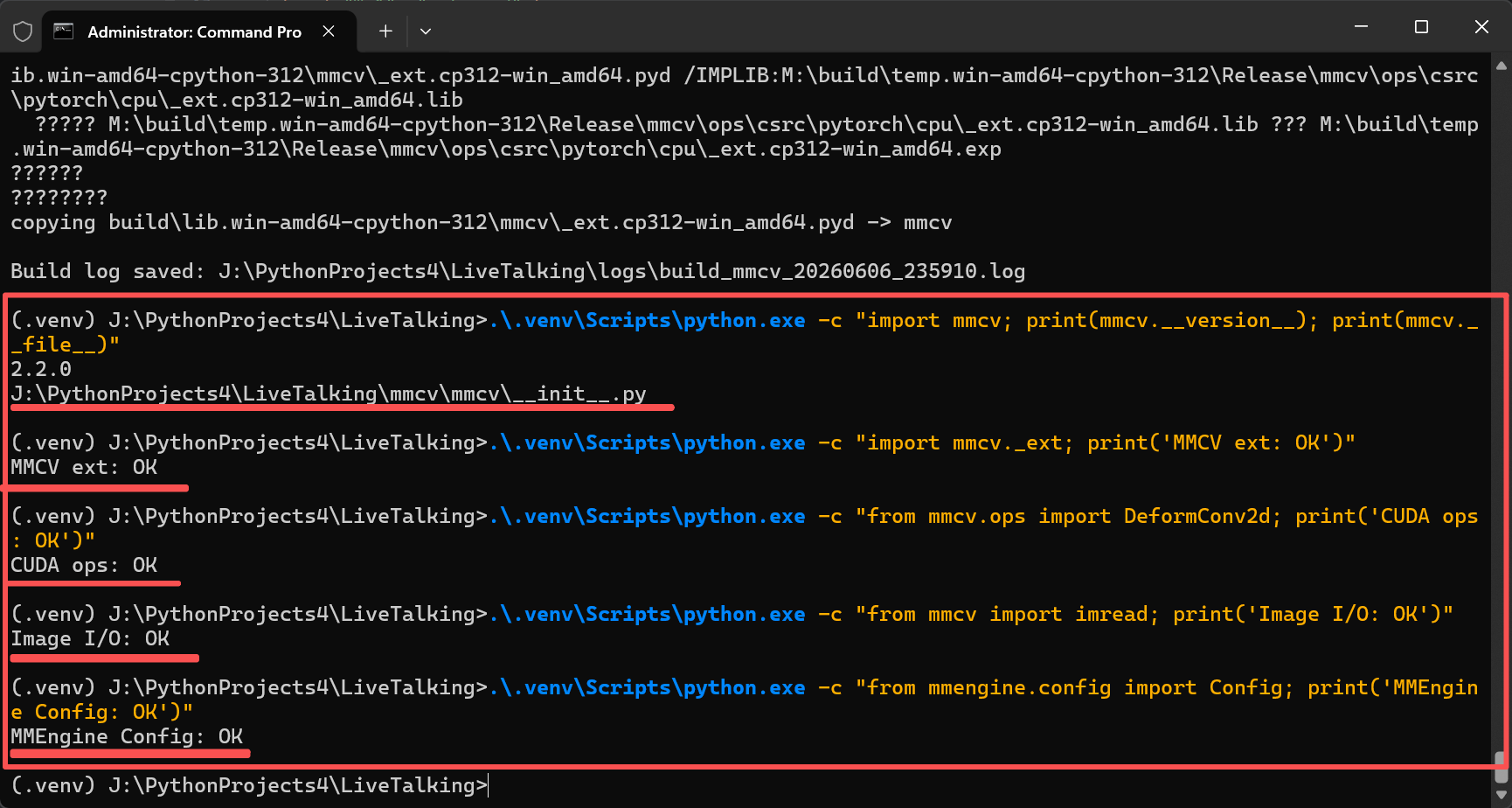
验证:
python
import mmcv; import mmdet; import mmpose
print(mmcv.__version__) # 2.2.0
print(mmdet.__version__) # 3.3.0
print(mmpose.__version__) # 1.3.2
六、FFmpeg 配置
LiveTalking 依赖 FFmpeg 进行视频处理。如果系统已安装 FFmpeg(如通过 Scoop),无需额外配置:
cmd
where ffmpeg
:: D:\Scoop\apps\ffmpeg-shared\current\bin\ffmpeg.exe七、模型下载与部署
7.1 下载地址
- 夸克云盘: https://pan.quark.cn/s/83a750323ef0
- Google Drive : https://drive.google.com/drive/folders/1FOC_MD6wdogyyX_7V1d4NDIO7P9NlSAJ
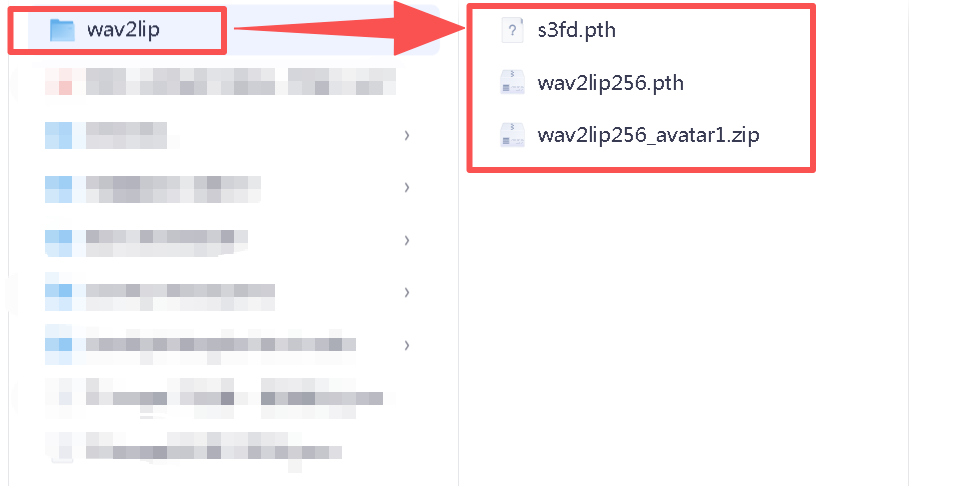
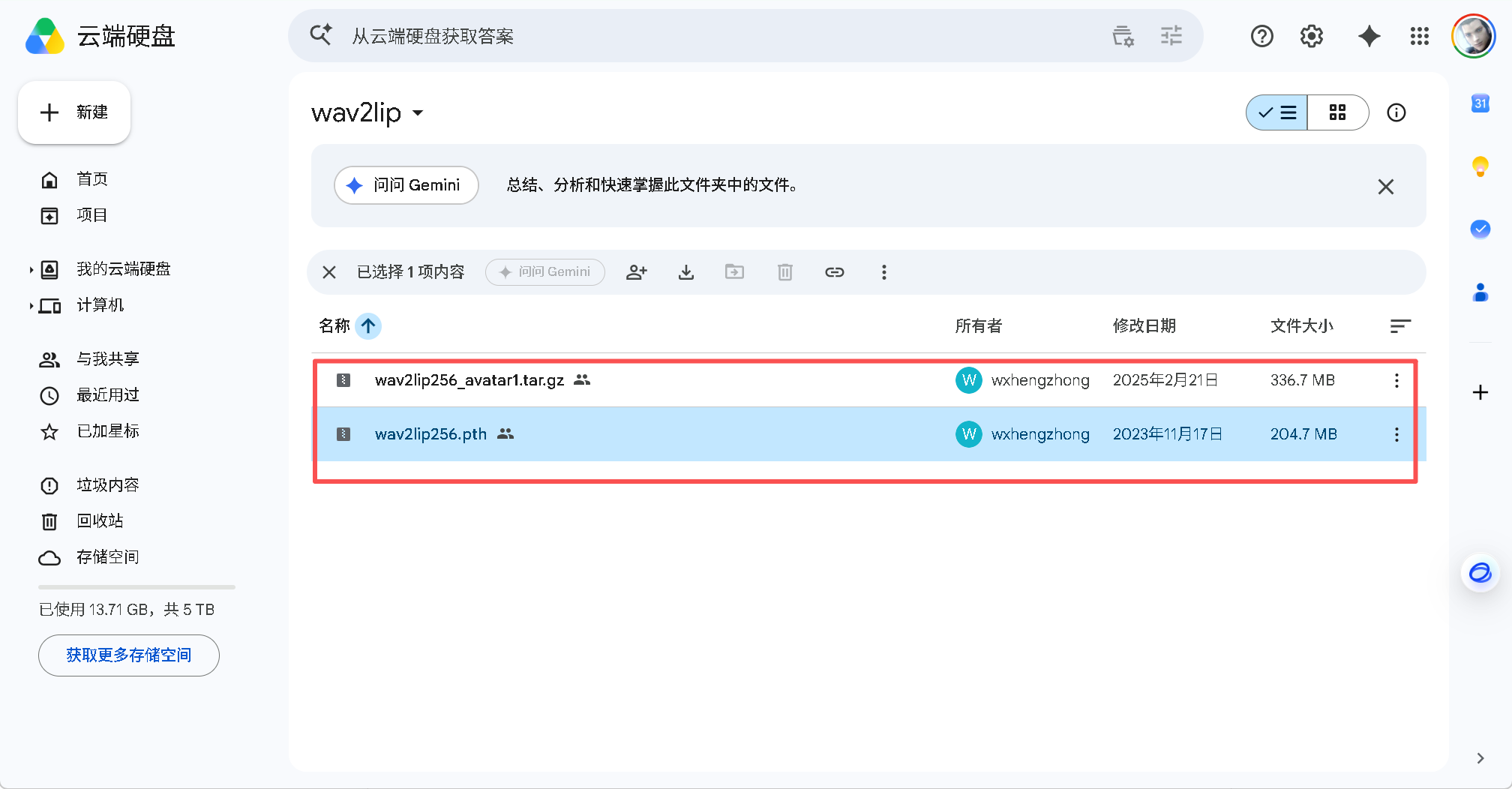
7.2 模型放置(以 Wav2Lip 为例)
| 文件 | 来源 | 放置位置 |
|---|---|---|
wav2lip256.pth |
夸克网盘 | models/wav2lip.pth(需重命名) |
s3fd.pth |
夸克网盘 | models/s3fd.pth |
wav2lip256_avatar1.zip |
夸克网盘 | 解压至 data/avatars/wav2lip256_avatar1/ |
目录结构:
LiveTalking/
├── models/
│ ├── wav2lip.pth
│ └── s3fd.pth
└── data/
└── avatars/
└── wav2lip256_avatar1/
└── ...八、启动服务
8.1 Wav2Lip 模式(轻量快速)
cmd
python app.py --transport webrtc --model wav2lip --avatar_id wav2lip256_avatar1RTX 3090 可加大 batch size 提升 GPU 利用率:
cmd
python app.py --transport webrtc --model wav2lip --avatar_id wav2lip256_avatar1 --batch_size 32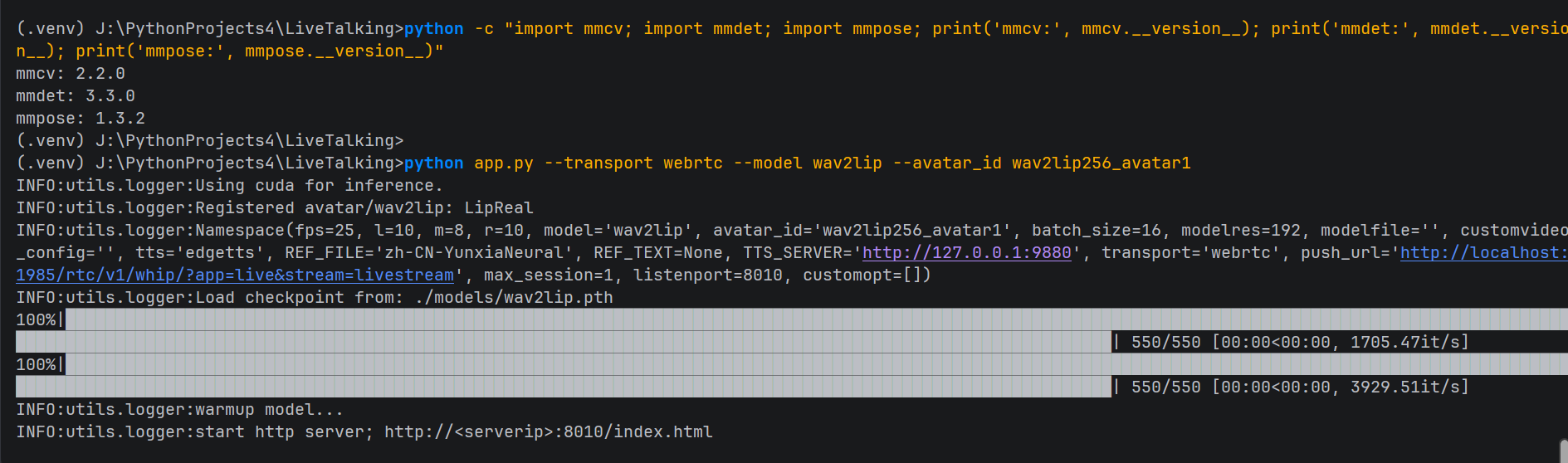
8.2 MuseTalk 模式(口型更精准,需下载对应模型)
cmd
python app.py --transport webrtc --model musetalk --avatar_id musetalk_avatar1 --batch_size 248.3 访问验证
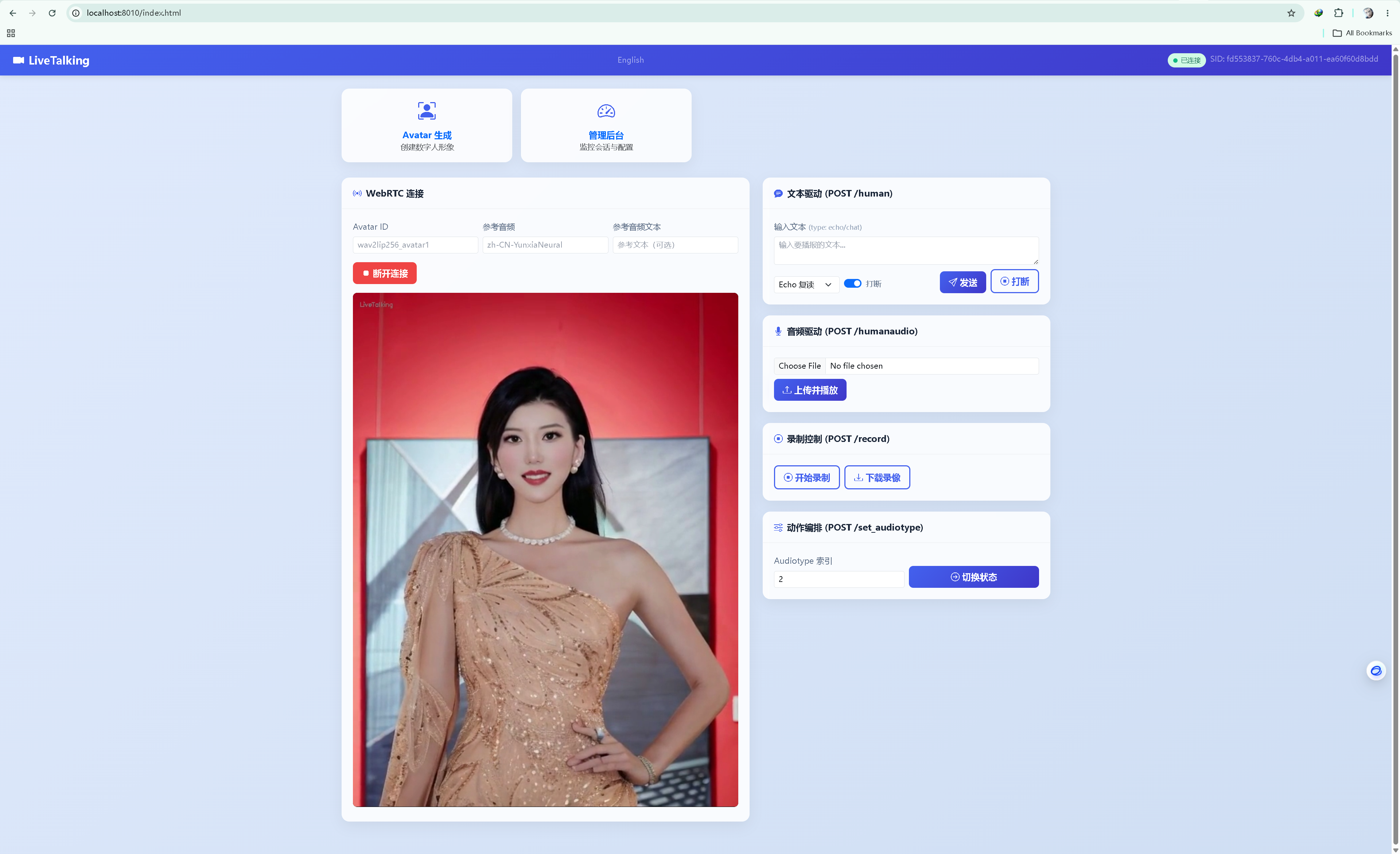
浏览器打开:
http://localhost:8010/index.html- 点击 "开始连接" → 加载数字人视频
- 在文本框输入文字 → 点击 发送
- 数字人实时播报输入内容
九、部署成功验证
最终验证环境:
| 组件 | 版本/状态 |
|---|---|
| Python | 3.12.11 |
| PyTorch | 2.9.1+cu130 |
| CUDA | 13.1 (Driver 13.2) |
| GPU | RTX 3090 |
| MMCV | 2.2.0 (CUDA ops OK) |
| MMDet | 3.3.0 |
| MMPose | 1.3.2 |
| ONNXRuntime | 1.26.0 (GPU enabled) |
| 模型 | Wav2Lip |
| 服务 | WebRTC @ :8010 |
十、总结
本项目在 Windows 上的部署核心难点在于 MMLab 工具链的 CUDA 编译 与 PyTorch 2.9.1 新版本的兼容性。通过 EPGF 架构实现 Python 环境隔离,结合短路径编译策略与防御性构建方案,成功在 RTX 3090 上完成了全功能部署。
对于后续希望使用 MuseTalk 获得更精准口型效果的用户,可从 Google Drive 下载对应模型替换,3090 的 24GB 显存完全胜任。
本文编译部分详细技术细节已收录于系列博客,请参阅上文引用链接。