( Owed by: 春夜喜雨 http://blog.csdn.net/chunyexiyu )
0. 摘要
std::unordered_map 是 C++ STL 中的哈希表(Hash Table)实现,也常被称作 hash_map,底层实现比较清晰。
哈希桶布局与核心计算规则
-
桶数量与负载因子约束
根据容器内元素数量动态确定哈希桶数量,默认最大负载因子为 0.75 ,满足公式:
元素个数 / 桶个数 ≤ 0.75,等价于桶个数 ≥ 元素个数 / 0.75 ≈ 1.33 倍元素个数。通过预留充足的桶空间,保证哈希散列均匀时,每个桶仅存放单个元素。
-
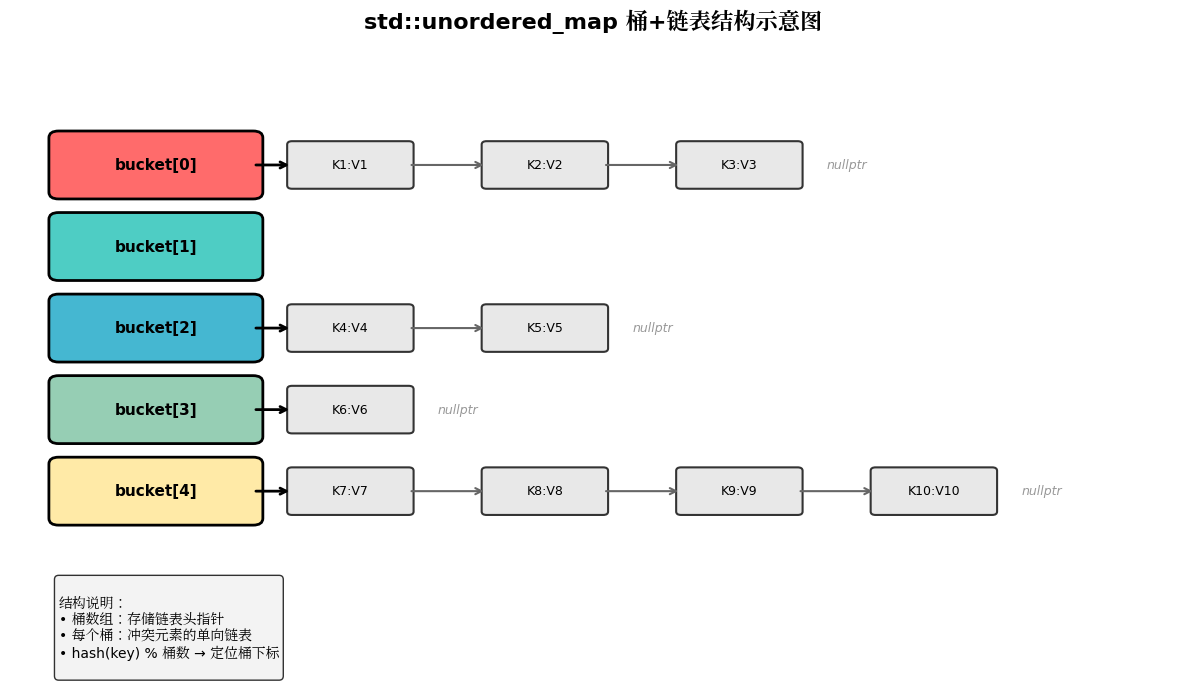
哈希冲突解决方案
每个桶对应一个单向链表,当不同元素的哈希值映射到同一个桶时,所有冲突元素会挂载到该链表中。
-
桶定位算法
通过哈希计算将元素散列到对应桶:
桶下标 = hash(元素key) % 桶个数MSVC 实现中桶个数为 2 的整数次幂,可使用位运算优化:
_Bucket_index = _Hashval & (_Bucket_count - 1),性能高于取模运算。
核心数据结构总结
- 内存浪费主要来源于桶数组长度不会主动收缩
- 底层是指针数组,自身内存占用极小
- 桶数组大小仅与历史最大元素数量相关
- 数组大小与 value 数据类型大小无关
- 键值对存储在同一个节点中,key 与 value 不分离存储
标准哈希函数实现
| 数据类型 | std::hash 实现逻辑 | 性能 |
|---|---|---|
| uint64_t/整型 | 直接返回 key 原值 | 极快 |
| 指针类型 | 转换为整数返回 | 极快 |
| std::string | 循环计算:hash = hash*31 + 字符 | 正常 |
| 浮点型 | 比特转换为整数 | 极快 |
| 自定义结构体 | 需手动实现哈希函数 | 不可用 |
核心哈希代码示例
c++
// 64位整型:直接返回原值
template<> struct hash<uint64_t> {
size_t operator()(uint64_t x) const noexcept { return x; }
};
// 字符串:经典31倍哈希算法
size_t operator()(const string& s) const {
size_t hash = 0;
for (char c : s) hash = hash * 31 + c;
return hash;
}
// 指针:强转整数
return (size_t)ptr;
// 浮点型:比特位转换
return bit_cast<size_t>(val);1、定义
std::unordered_map 是 C++ 标准库提供的哈希表容器 ,是 hash_map 的标准实现。
核心特性:平均 O(1) 时间复杂度,支持键值对的快速查找、插入、删除操作。
2. 整体设计思想
2.1 负载因子与桶数量控制
负载因子是哈希表性能与内存的核心平衡指标:
- 默认阈值:0.75
- 计算公式:
负载因子 = 元素个数 / 桶个数 - 扩容触发条件:
负载因子 > 0.75
2.2 冲突解决:链式哈希(拉链法)
unordered_map 采用拉链法解决哈希冲突,这是最主流的哈希表实现方案。
哈希桶数组
Bucket 0
Bucket 1
Bucket 2
Bucket 3
Node
key:4, val:A
Node
key:8, val:B
nullptr
Node
key:2, val:C
nullptr
2.3 桶定位算法
- GCC/Clang :桶数量为质数,使用取模运算
桶下标 = hash(key) % 桶个数 - MSVC :桶数量为 2ⁿ,使用位运算
桶下标 = hash(key) & (桶个数 - 1)
3. 核心执行流程
3.1 查找元素(find)流程
平均时间复杂度 O(1),最差 O(n)(冲突严重时)
匹配
不匹配
否
是
传入查找key
计算hash-key
计算桶下标
定位对应哈希桶
遍历桶内链表
key是否匹配?
返回元素迭代器
遍历结束?
返回end
3.2 插入元素(insert)流程
包含**自动扩容(rehash)**机制
是
否
否
是
插入key-value
查找key是否已存在
key存在?
覆盖value/终止插入
新建节点, 插入对应桶链表
检查负载因子
>0.75? 插入完成
执行扩容rehash
创建2倍大小的新桶数组
所有元素重新哈希
释放旧桶数组
4. 关键性能结论
- 查找性能与数据量无关
10万 ~ 1000万 数据量下,查找速度保持一致,均为纳秒级。 - 64位无符号整型是最优 key
哈希无计算开销、冲突概率极低、key 比较为单指令。 - value 大小不影响查找性能
find操作仅读取 key,不会访问 value 数据。 - 大数据量必须提前调用
reserve()
避免频繁自动扩容,这是unordered_map唯一的性能瓶颈。
5、总结
unordered_map
底层结构
哈希桶数组
单向链表拉链法
核心机制
负载因子 0.75
Rehash 扩容重排
性能优化
reserve 预分配
整型 Key 最优实践
常见问题
迭代器失效
内存不释放
- 底层结构:桶数组 + 单向链表(拉链法哈希表)
- 核心公式:
桶下标 = hash(key) % 桶个数 - 负载因子 0.75:桶个数为约1.33倍元素个数,平衡性能与内存
- 平均 O(1) 查找效率,整型 key 接近理论最优
- 大数据场景下,提前
reserve()可规避扩容性能损耗