
🔥承渊政道: 个人主页
❄️个人专栏: 《C语言基础语法知识》 《数据结构与算法》
✨逆境不吐心中苦,顺境不忘来时路! 🎬 博主简介:

引言:前篇文章,小编已经介绍了关于unordered_map和unordered_set的使⽤以及哈希表的实现!相信大家应该有所收获!接下来我将带领大家继续深入学习C++的相关内容!本篇文章着重介绍关于⽤哈希表封装myunordered_map和myunordered_set以及位图和布隆过滤器介绍!本文将系统梳理哈希表的核心设计思路:完成myunordered_map与myunordered_set的封装实现,并延伸介绍位图和布隆过滤器的原理、应用场景及实现要点,帮助读者构建"哈希表-自定义哈希容器-位图-布隆过滤器"的完整知识体系,理解不同场景下数据结构的选择逻辑与设计思想.那么这里面到底有哪些知识需要我们去学习的呢?废话不多说,带着这些疑问,下面跟着小编的节奏🎵一起去疯狂的学习吧!
目录
- 1.源码及框架分析
- 2.模拟实现unordered_map和unordered_set
- 3.位图(哈希扩展学习)
- 4.布隆过滤器(哈希扩展学习)
- 5.海量数据处理问题
-
- 5.1给两个⽂件,分别有100亿个query,我们只有1G内存,如何找到两个⽂件交集?
- [5.2给⼀个超过100G⼤⼩的log file,log中存着ip地址,设计算法找到出现次数最多的ip地址?查找出现次数前10的ip地址](#5.2给⼀个超过100G⼤⼩的log file,log中存着ip地址,设计算法找到出现次数最多的ip地址?查找出现次数前10的ip地址)
1.源码及框架分析
SGI-STL30版本源代码中没有unordered_map和unordered_set,SGI-STL30版本是C++11之前的STL版本,这两个容器是C++11之后才更新的.但是SGI-STL30实现了哈希表,只容器的名字hash_map和hash_set,他是作为⾮标准的容器出现的,⾮标准是指⾮C++标准规定必须实现的,源代码在hash_map/hash_set/stl_hash_map/stl_hash_set/stl_hashtable.h中hash_map和hash_set的实现结构框架核⼼部分截取出来如下:
cpp
// stl_hash_set
template <class Value, class HashFcn = hash<Value>,
class EqualKey = equal_to<Value>,
class Alloc = alloc>
class hash_set
{
private:
typedef hashtable<Value, Value, HashFcn, identity<Value>,
EqualKey, Alloc> ht;
ht rep;
public:
typedef typename ht::key_type key_type;
typedef typename ht::value_type value_type;
typedef typename ht::hasher hasher;
typedef typename ht::key_equal key_equal;
typedef typename ht::const_iterator iterator;
typedef typename ht::const_iterator const_iterator;
hasher hash_funct() const { return rep.hash_funct(); }
key_equal key_eq() const { return rep.key_eq(); }
};
// stl_hash_map
template <class Key, class T, class HashFcn = hash<Key>,
class EqualKey = equal_to<Key>,
class Alloc = alloc>
class hash_map
{
private:
typedef hashtable<pair<const Key, T>, Key, HashFcn,
select1st<pair<const Key, T> >, EqualKey, Alloc> ht;
ht rep;
public:
typedef typename ht::key_type key_type;
typedef T data_type;
typedef T mapped_type;
typedef typename ht::value_type value_type;
typedef typename ht::hasher hasher;
typedef typename ht::key_equal key_equal;
typedef typename ht::iterator iterator;
typedef typename ht::const_iterator const_iterator;
};
// stl_hashtable.h
template <class Value, class Key, class HashFcn,
class ExtractKey, class EqualKey,
class Alloc>
class hashtable {
public:
typedef Key key_type;
typedef Value value_type;
typedef HashFcn hasher;
typedef EqualKey key_equal;
private:
hasher hash;
key_equal equals;
ExtractKey get_key;
typedef __hashtable_node<Value> node;
vector<node*,Alloc> buckets;
size_type num_elements;
public:
typedef __hashtable_iterator<Value, Key, HashFcn, ExtractKey, EqualKey,Alloc>iterator;
pair<iterator, bool> insert_unique(const value_type& obj);
const_iterator find(const key_type& key) const;
};
template <class Value>
struct __hashtable_node
{
__hashtable_node* next;
Value val;
};1️⃣哈希节点结构:__hashtable_node
①作用:哈希表的最小存储单元,是开散列(链地址法)的核心载体;
②核心设计:每个节点包含next指针,当多个元素哈希到同一个桶时,通过链表串联这些节点,解决哈希冲突;
③模板参数Value:节点存储的值类型(可适配hash_set的单一值、hash_map的键值对).
2️⃣核心底层:hashtable类
①模板参数(核心设计):
Value:节点存储的完整值类型(如hash_map的pair<const Key, T>、hash_set的Value);
Key:键类型(用于哈希计算和相等判断);
HashFcn:哈希函数类型(自定义哈希规则,默认hash<Key>);
ExtractKey:从Value中提取Key的策略(如hash_set用identity、hash_map用select1st);
EqualKey:键相等判断规则(默认equal_to<Key>);
Alloc:内存分配器(STL标准分配器,统一内存管理).
②核心成员:
buckets:桶数组(vector存储链表头指针),哈希表的"桶"本质是数组,每个桶对应一个哈希值区间,元素通过哈希值映射到对应桶的链表中;
get_key:解耦Value和Key的关键---比如hash_map的Value是pair<const Key, T>,需要通过select1st提取第一个元素(Key);hash_set的Value就是Key,用identity直接返回自身;
③核心接口:
insert_unique:插入元素且保证Key唯一(符合set/map的"无重复键"特性),返回pair<迭代器,布尔值>(布尔值表示是否插入成功);
find:根据Key查找元素,返回常量迭代器.
3️⃣上层封装:hash_set类
①模板参数简化:hash_set的Value就是Key(集合存储的元素本身就是键),因此省略了独立的Key参数;
②hashtable适配:
hashtable的前两个参数都是Value(因为 set 的键 = 值);
ExtractKey用identity(直接返回 Value 本身作为 Key);
③迭代器设计:iterator被定义为const_iterator---这是因为hash_set的元素是唯一且不可修改的(修改元素会改变 Key,破坏哈希表的映射关系);
④组合复用:hash_set仅封装一个ht(hashtable实例),自身无核心逻辑,所有增删查改都通过rep调用底层接口.
4️⃣上层封装:hash_map类
①模板参数适配:hash_map需要区分Key(键)和T(值),因此模板参数显式声明Key和T;
②hashtable适配:
Value是pair<const Key, T>(map 存储键值对,且Key不可修改,因此加const);
ExtractKey用select1st<pair<const Key, T>>(从键值对中提取第一个元素作为Key);
③类型别名:新增data_type/mapped_type(均为T),适配map的语义(用户关注"键对应的值");
④迭代器设计:暴露iterator(可变迭代器)---允许修改键值对中的T(值),但Key是const的,无法修改(避免破坏哈希映射).
这⾥就不再画图分析了,通过源码可以看到,结构上hash_map和hash_set跟map和set的完全类似,复⽤同⼀个hashtable实现key和key/value结构,hash_set传给hash_table的是两个key,hash_map传给hash_table的是pair<const key, value>
需要注意的是源码⾥⾯跟map/set源码类似,命名⻛格⽐较乱,这⾥⽐map和set还乱,hash_set模板参数居然⽤的Value命名,hash_map⽤的是Key和T命名,可⻅⼤佬有时写代码也不规范.下⾯我们模拟⼀份⾃⼰的出来,就按⾃⼰的⻛格⾛了.




2.模拟实现unordered_map和unordered_set
2.1实现出复⽤哈希表的框架,并⽀持insert
①参考源码框架,unordered_map和unordered_set复⽤之前我们实现的哈希表.
②我们这⾥相⽐源码调整⼀下,key参数就⽤K,value参数就⽤V,哈希表中的数据类型,我们使⽤T.
③其次跟map和set相⽐⽽⾔unordered_map和unordered_set的模拟实现类结构更复杂⼀点,但是⼤框架和思路是完全类似的.因为HashTable实现了泛型不知道T参数导致是K,还是pair<K, V>,那么insert内部进⾏插⼊时要⽤K对象转换成整形取模和K⽐较相等,因为pair的value不参与计算取模,且默认⽀持的是key和value⼀起⽐较相等,我们需要时的任何时候只需要⽐较K对象,所以我们在unordered_map和unordered_set层分别实现⼀个MapKeyOfT和SetKeyOfT的仿函数传给HashTable的KeyOfT,然后HashTable中通过KeyOfT仿函数取出T类型对象中的K对象,再转换成整形取模和K⽐较相等,具体细节参考如下代码实现.
cpp
// MyUnorderedSet.h
namespace lcz
{
template<class K, class Hash = HashFunc<K>>
class unordered_set
{
struct SetKeyOfT
{
const K& operator()(const K& key)
{
return key;
}
};
public:
bool insert(const K& key)
{
return _ht.Insert(key);
}
private:
hash_bucket::HashTable<K, K, SetKeyOfT, Hash> _ht;
};
}
// MyUnorderedMap.h
namespace lcz
{
template<class K, class V, class Hash = HashFunc<K>>
class unordered_map
{
struct MapKeyOfT
{
const K& operator()(const pair<K, V>& kv)
{
return kv.first;
}
};
public:
bool insert(const pair<K, V>& kv)
{
return _ht.Insert(kv);
}
private:
hash_bucket::HashTable<K, pair<K, V>, MapKeyOfT, Hash> _ht;
};
}
// HashTable.h
template<class K>
struct HashFunc
{
size_t operator()(const K& key)
{
return (size_t)key;
}
};
namespace hash_bucket
{
template<class T>
struct HashNode
{
T _data;
HashNode<T>* _next;
HashNode(const T& data)
:_data(data)
,_next(nullptr)
{}
};
// 实现步骤:
// 1、实现哈希表
// 2、封装unordered_map和unordered_set的框架 解决KeyOfT
// 3、iterator
// 4、const_iterator
// 5、key不⽀持修改的问题
// 6、operator[]
template<class K, class T, class KeyOfT, class Hash>
class HashTable
{
typedef HashNode<T> Node;
inline unsigned long __stl_next_prime(unsigned long n)
{
static const int __stl_num_primes = 28;
static const unsigned long __stl_prime_list[__stl_num_primes] =
{
53, 97, 193, 389, 769,
1543, 3079, 6151, 12289, 24593,
49157, 98317, 196613, 393241, 786433,
1572869, 3145739, 6291469, 12582917, 25165843,
50331653, 100663319, 201326611, 402653189, 805306457,
1610612741, 3221225473, 4294967291
};
const unsigned long* first = __stl_prime_list;
const unsigned long* last = __stl_prime_list + __stl_num_primes;
const unsigned long* pos = lower_bound(first, last, n);
return pos == last ? *(last - 1) : *pos;
}
public:
HashTable()
{
_tables.resize(__stl_next_prime(_tables.size()), nullptr);
}
~HashTable()
{
// 依次把每个桶释放
for (size_t i = 0; i < _tables.size(); i++)
{
Node* cur = _tables[i];
while (cur)
{
Node* next = cur->_next;
delete cur;
cur = next;
}
_tables[i] = nullptr;
}
}
bool Insert(const T& data)
{
KeyOfT kot;
if (Find(kot(data)))
return false;
Hash hs;
size_t hashi = hs(kot(data)) % _tables.size();
// 负载因⼦==1扩容
if (_n == _tables.size())
{
vector<Node*> newtables(__stl_next_prime(_tables.size()),nullptr);
for (size_t i = 0; i < _tables.size(); i++)
{
Node* cur = _tables[i];
while (cur)
{
Node* next = cur->_next;
// 旧表中结点,挪动新表重新映射的位置
size_t hashi = hs(kot(cur->_data)) % newtables.size();
// 头插到新表
cur->_next = newtables[hashi];
newtables[hashi] = cur;
cur = next;
}
_tables[i] = nullptr;
}
_tables.swap(newtables);
}
// 头插
Node* newnode = new Node(data);
newnode->_next = _tables[hashi];
_tables[hashi] = newnode;
++_n;
return true;
}
private:
vector<Node*> _tables; // 指针数组
size_t _n = 0; // 表中存储数据个数
};
}2.2⽀持iterator的实现
cpp
//iterator核⼼源代码
template <class Value, class Key, class HashFcn,
class ExtractKey, class EqualKey, class Alloc>
struct __hashtable_iterator {
typedef hashtable<Value, Key, HashFcn, ExtractKey, EqualKey, Alloc>
hashtable;
typedef __hashtable_iterator<Value, Key, HashFcn,
ExtractKey, EqualKey, Alloc>
iterator;
typedef __hashtable_const_iterator<Value, Key, HashFcn,
ExtractKey, EqualKey, Alloc>
const_iterator;
typedef __hashtable_node<Value> node;
typedef forward_iterator_tag iterator_category;
typedef Value value_type;
node* cur;
hashtable* ht;
__hashtable_iterator(node* n, hashtable* tab) : cur(n), ht(tab) {}
__hashtable_iterator() {}
reference operator*() const { return cur->val; }
#ifndef __SGI_STL_NO_ARROW_OPERATOR
pointer operator->() const { return &(operator*()); }
#endif /* __SGI_STL_NO_ARROW_OPERATOR */
iterator& operator++();
iterator operator++(int);
bool operator==(const iterator& it) const { return cur == it.cur; }
bool operator!=(const iterator& it) const { return cur != it.cur; }
};
template <class V, class K, class HF, class ExK, class EqK, class A>
__hashtable_iterator<V, K, HF, ExK, EqK, A>&
__hashtable_iterator<V, K, HF, ExK, EqK, A>::operator++()
{
const node* old = cur;
cur = cur->next;
if (!cur) {
size_type bucket = ht->bkt_num(old->val);
while (!cur && ++bucket < ht->buckets.size())
cur = ht->buckets[bucket];
}
return *this;
}iterator实现思路分析
①iterator实现的⼤框架跟list的iterator思路是⼀致的,⽤⼀个类型封装结点的指针,再通过重载运算符实现,迭代器像指针⼀样访问的⾏为,要注意的是哈希表的迭代器是单向迭代器.
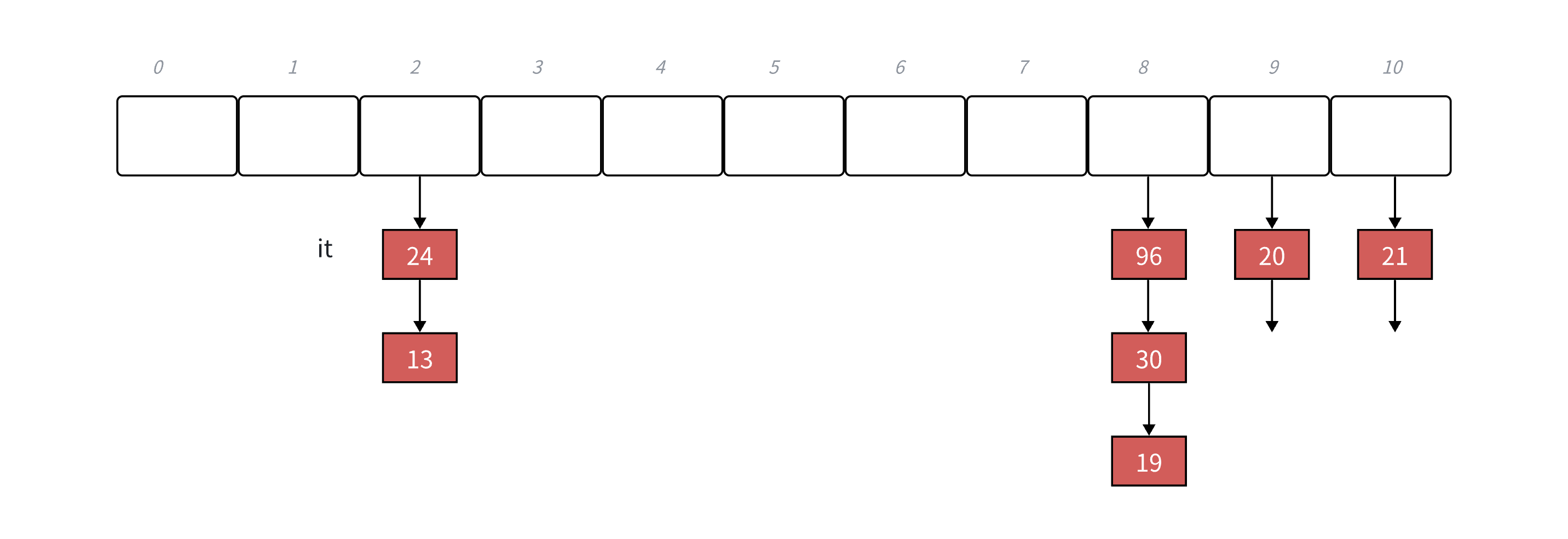
②这⾥的难点是operator++的实现.iterator中有⼀个指向结点的指针,如果当前桶下⾯还有结点,则结点的指针指向下⼀个结点即可.如果当前桶⾛完了,则需要想办法计算找到下⼀个桶.这⾥的难点是结构设计的问题,参考上⾯的源码,我们可以看到iterator中除了有结点的指针,还有哈希表对象的指针,这样当前桶⾛完了,要计算下⼀个桶就相对容易多了,⽤key值计算出当前桶位置,依次往后找下⼀个不为空的桶即可.
③begin()返回第⼀个桶中第⼀个节点指针构造的迭代器,这⾥end()返回迭代器可以⽤空表示.
④unordered_set的iterator也不⽀持修改,我们把unordered_set的第⼆个模板参数改成const K即可,HashTable<K, const K, SetKeyOfT, Hash> _ht;
⑤unordered_map的iterator不⽀持修改key但是可以修改value,我们把unordered_map的第⼆个模板参数pair的第⼀个参数改成const K即可,HashTable<K, pair<const K, V>,MapKeyOfT, Hash> _ht;
⑤⽀持完整的迭代器还有很多细节需要修改,接着往下看.
2.3map⽀持\[\]
unordered_map要⽀持\[\]主要需要修改insert返回值⽀持,
修改HashTable中的insert返回值为:pair<Iterator, bool> Insert(const T& data)
有了insert⽀持\[\]实现就很简单了,具体参考下⾯代码实现.
2.4unordered_map和unordered_set代码实现
cpp
// MyUnorderedSet.h
namespace lcz
{
template<class K, class Hash = HashFunc<K>>
class unordered_set
{
struct SetKeyOfT
{
const K& operator()(const K& key)
{
return key;
}
};
public:
typedef typename hash_bucket::HashTable<K, const K, SetKeyOfT,Hash>::Iterator iterator;
typedef typename hash_bucket::HashTable<K, const K, SetKeyOfT,Hash>::ConstIterator const_iterator;
iterator begin()
{
return _ht.Begin();
}
iterator end()
{
return _ht.End();
}
const_iterator begin() const
{
return _ht.Begin();
}
const_iterator end() const
{
return _ht.End();
}
pair<iterator, bool> insert(const K& key)
{
return _ht.Insert(key);
}
iterator Find(const K& key)
{
return _ht.Find(key);
}
bool Erase(const K& key)
{
return _ht.Erase(key);
}
private:
hash_bucket::HashTable<K, const K, SetKeyOfT, Hash> _ht;
};
void test_set()
{
unordered_set<int> s;
int a[] = { 4, 2, 6, 1, 3, 5, 15, 7, 16, 14, 3,3,15 };
for (auto e : a)
{
s.insert(e);
}
for (auto e : s)
{
cout << e << " ";
}
cout << endl;
unordered_set<int>::iterator it = s.begin();
while (it != s.end())
{
// 不⽀持修改
//*it += 1;
cout << *it << " ";
++it;
}
cout << endl;
}
}
// MyUnorderedMap.h
namespace lcz
{
template<class K, class V, class Hash = HashFunc<K>>
class unordered_map
{
struct MapKeyOfT
{
const K& operator()(const pair<K, V>& kv)
{
return kv.first;
}
};
public:
typedef typename hash_bucket::HashTable<K, pair<const K, V>,
MapKeyOfT, Hash>::Iterator iterator;
typedef typename hash_bucket::HashTable<K, pair<const K, V>,
MapKeyOfT, Hash>::ConstIterator const_iterator;
iterator begin()
{
return _ht.Begin();
}
iterator end()
{
return _ht.End();
}
const_iterator begin() const
{
return _ht.Begin();
}
const_iterator end() const
{
return _ht.End();
}
pair<iterator, bool> insert(const pair<K, V>& kv)
{
return _ht.Insert(kv);
}
V& operator[](const K& key)
{
pair<iterator, bool> ret = _ht.Insert(make_pair(key, V()));
return ret.first->second;
}
iterator Find(const K& key)
{
return _ht.Find(key);
}
bool Erase(const K& key)
{
return _ht.Erase(key);
}
private:
hash_bucket::HashTable<K, pair<const K, V>, MapKeyOfT, Hash> _ht;
};
void test_map()
{
unordered_map<string, string> dict;
dict.insert({ "sort", "排序" });
dict.insert({ "left", "左边" });
dict.insert({ "right", "右边" });
dict["left"] = "左边,剩余";
dict["insert"] = "插⼊";
dict["string"];
unordered_map<string, string>::iterator it = dict.begin();
while (it != dict.end())
{
// 不能修改first,可以修改second
//it->first += 'x';
it->second += 'x';
cout << it->first << ":" << it->second << endl;
++it;
}
cout << endl;
}
}
// HashTable.h
template<class K>
struct HashFunc
{
size_t operator()(const K& key)
{
return (size_t)key;
}
};
// 特化
template<>
struct HashFunc<string>
{
size_t operator()(const string& key)
{
size_t hash = 0;
for (auto e : key)
{
hash *= 131;
hash += e;
}
return hash;
}
};
namespace hash_bucket
{
template<class T>
struct HashNode
{
T _data;
HashNode<T>* _next;
HashNode(const T& data)
:_data(data)
,_next(nullptr)
{}
};
// 前置声明
template<class K, class T, class KeyOfT, class Hash>
class HashTable;
template<class K, class T, class Ptr, class Ref, class KeyOfT, class Hash>
struct HTIterator
{
typedef HashNode<T> Node;
typedef HTIterator<K, T, Ptr, Ref, KeyOfT, Hash> Self;
Node* _node;
const HashTable<K, T, KeyOfT, Hash>* _pht;
HTIterator(Node* node, const HashTable<K, T, KeyOfT, Hash>* pht)
:_node(node)
,_pht(pht)
{}
Ref operator*()
{
return _node->_data;
}
Ptr operator->()
{
return &_node->_data;
}
bool operator!=(const Self& s)
{
return _node != s._node;
}
Self& operator++()
{
if (_node->_next)
{
// 当前桶还有节点
_node = _node->_next;
}
else
{
// 当前桶⾛完了,找下⼀个不为空的桶
KeyOfT kot;
Hash hs;
size_t hashi = hs(kot(_node->_data)) % _pht->_tables.size();
++hashi;
while (hashi < _pht->_tables.size())
{
if (_pht->_tables[hashi])
{
break;
}
++hashi;
}
if (hashi == _pht->_tables.size())
{
_node = nullptr; // end()
}
else
{
_node = _pht->_tables[hashi];
}
}
return *this;
}
};
template<class K, class T, class KeyOfT, class Hash>
class HashTable
{
// 友元声明
template<class K, class T, class Ptr, class Ref, class KeyOfT, class Hash>
friend struct HTIterator;
typedef HashNode<T> Node;
public:
typedef HTIterator<K, T, T*, T&, KeyOfT, Hash> Iterator;
typedef HTIterator<K, T, const T*, const T&, KeyOfT, Hash> ConstIterator;
Iterator Begin()
{
if (_n == 0)
return End();
for (size_t i = 0; i < _tables.size(); i++)
{
Node* cur = _tables[i];
if (cur)
{
return Iterator(cur, this);
}
}
return End();
}
Iterator End()
{
return Iterator(nullptr, this);
}
ConstIterator Begin() const
{
if (_n == 0)
return End();
for (size_t i = 0; i < _tables.size(); i++)
{
Node* cur = _tables[i];
if (cur)
{
return ConstIterator(cur, this);
}
}
return End();
}
ConstIterator End() const
{
return ConstIterator(nullptr, this);
}
inline unsigned long __stl_next_prime(unsigned long n)
{
static const int __stl_num_primes = 28;
static const unsigned long __stl_prime_list[__stl_num_primes] =
{
53, 97, 193, 389, 769,
1543, 3079, 6151, 12289, 24593,
49157, 98317, 196613, 393241, 786433,
1572869, 3145739, 6291469, 12582917, 25165843,
50331653, 100663319, 201326611, 402653189, 805306457,
1610612741, 3221225473, 4294967291
};
const unsigned long* first = __stl_prime_list;
const unsigned long* last = __stl_prime_list +__stl_num_primes;
const unsigned long* pos = lower_bound(first, last, n);
return pos == last ? *(last - 1) : *pos;
}
HashTable()
{
_tables.resize(__stl_next_prime(_tables.size()), nullptr);
}
~HashTable()
{
// 依次把每个桶释放
for (size_t i = 0; i < _tables.size(); i++)
{
Node* cur = _tables[i];
while (cur)
{
Node* next = cur->_next;
delete cur;
cur = next;
}
_tables[i] = nullptr;
}
}
pair<Iterator, bool> Insert(const T& data)
{
KeyOfT kot;
Iterator it = Find(kot(data));
if (it != End())
return make_pair(it, false);
Hash hs;
size_t hashi = hs(kot(data)) % _tables.size();
// 负载因⼦==1扩容
if (_n == _tables.size())
{
vector<Node*>
newtables(__stl_next_prime(_tables.size()+1), nullptr);
for (size_t i = 0; i < _tables.size(); i++)
{
Node* cur = _tables[i];
while (cur)
{
Node* next = cur->_next;
// 旧表中节点,挪动新表重新映射的位置
size_t hashi = hs(kot(cur->_data)) %
newtables.size();
// 头插到新表
cur->_next = newtables[hashi];
newtables[hashi] = cur;
cur = next;
}
_tables[i] = nullptr;
}
_tables.swap(newtables);
}
// 头插
Node* newnode = new Node(data);
newnode->_next = _tables[hashi];
_tables[hashi] = newnode;
++_n;
return make_pair(Iterator(newnode, this), true);
}
Iterator Find(const K& key)
{
KeyOfT kot;
Hash hs;
size_t hashi = hs(key) % _tables.size();
Node* cur = _tables[hashi];
while (cur)
{
if (kot(cur->_data) == key)
{
return Iterator(cur, this);
}
cur = cur->_next;
}
return End();
}
bool Erase(const K& key)
{
KeyOfT kot;
Hash hs;
size_t hashi = hs(key) % _tables .size();
Node* prev = nullptr;
Node* cur = _tables[hashi];
while (cur)
{
if (kot(cur->_data) == key)
{
if (prev == nullptr)
{
_tables[hashi] = cur->_next;
}
else
{
prev->_next = cur->_next;
}
delete cur;
--_n;
return true;
}
prev = cur;
cur = cur->_next;
}
return false;
}
private:
vector<Node*> _tables; // 指针数组
size_t _n = 0; // 表中存储数据个数
};
}3.位图(哈希扩展学习)
哈希中的位图(Bitmap)是一种基于哈希思想的空间高效型数据结构,用单个二进制位(bit)标记数据的存在状态(1=存在,0=不存在),本质是直接定址法哈希表的变形实现.它与图像中的位图完全不同,核心用于高效处理海量整数的存在性判断.
3.1位图的⾯试题
给40亿个不重复的⽆符号整数,没排过序.给⼀个⽆符号整数,如何快速判断⼀个数是否在这40亿个数中.(本题为腾讯/百度等公司出过的⼀个⾯试题)
①解题思路1:暴⼒遍历,时间复杂度O(N),太慢.
②解题思路2:排序+⼆分查找.时间复杂度消耗O(NlogN)+O(logN).
深⼊分析:解题思路2是否可⾏,我们先算算40亿个数据⼤概需要多少内存?
1G=1024MB=1024 1024KB=10241024 1024Byte 约等于10亿多Byte.那么40亿个整数约等于16G,说明40亿个数是⽆法直接放到内存中的,只能放到硬盘⽂件中.⽽⼆分查找只能对内存数组中的有序数据进⾏查找.
③解题思路3:数据是否在给定的整形数据中,结果是在或者不在,刚好是两种状态,那么可以使⽤⼀个⼆进制⽐特位来代表数据是否存在的信息,如果⼆进制⽐特位为1,代表存在,为0代表不存在.那么我们设计⼀个⽤位表示数据是否存在的数据结构,这个数据结构就叫位图.
3.2位图的设计及实现
位图本质是⼀个直接定址法的哈希表,每个整型值映射⼀个bit位,位图提供控制这个bit的相关接⼝.
实现中需要注意的是,C/C++没有对应位的类型,只能看int/char这样整形类型,我们再通过位运算去控制对应的⽐特位.⽐如我们数据存到vector<int>中,相当于每个int值映射对应的32个值,⽐如第⼀个整形映射0-31对应的位,第⼆个整形映射32-63对应的位,后⾯的以此类推,那么来了⼀个整形值x,i = x/32;j = x%32;计算出x映射的值在vector的第i个整形数据的第j位.
解决给40亿个不重复的⽆符号整数,查找⼀个数据的问题,我们要给位图开232个位,注意不能开40亿个位,因为映射是按⼤⼩映射的,我们要按数据⼤⼩范围开空间,范围是是0~232-1,所以需要开232个位.然后从⽂件中依次读取每个set到位图中,然后就可以快速判断⼀个值是否在这40亿个数中了.
cpp
#include<iostream>
#include<vector>
using namespace std;
namespace bit
{
// N是需要多少⽐特位
template<size_t N>
class bitset
{
public:
bitset()
{
//_bits.resize(N/32+1, 0);
_bits.resize((N >> 5) + 1, 0);
}
// 把x映射的位标记成1
void set(size_t x)
{
size_t i = x / 32;
size_t j = x % 32;
_bits[i] |= (1 << j);//左移不是方向,是地位往高位移
}
// 把x映射的位标记成0
void reset(size_t x)
{
size_t i = x / 32;
size_t j = x % 32;
_bits[i] &= ~(1 << j);
}
//x映射的位是1返回真;x映射的位是0返回假
bool test(size_t x)
{
size_t i = x / 32;
size_t j = x % 32;
return _bits[i] & (1 << j);
}
private:
vector<int> _bits;
};
}
int main()
{
bit::bitset<100> bs1;
bs1.set(50);
bs1.set(30);
bs1.set(90);
for (size_t i = 0; i < 100; i++)
{
if (bs1.test(i))
{
cout << i << "->" << "在" << endl;
}
else
{
cout << i << "->" << "不在" << endl;
}
}
bs1.reset(90);
bs1.set(91);
cout << endl << endl;
for (size_t i = 0; i < 100; i++)
{
if (bs1.test(i))
{
cout << i << "->" << "在" << endl;
}
else
{
cout << i << "->" << "不在" << endl;
}
}
// 开2^32^个位的位图
//bit::bitset<-1> bs2;
//bit::bitset<UINT_MAX> bs3;
//bit::bitset<0xffffffff> bs4;
return 0;
}3.3C++库中的位图bitset
C++库中的位图bitset
可以看到核⼼接⼝还是set/reset/和test,当然后⾯还实现了⼀些其他接⼝,如to_string将位图按位转成01字符串,再包括operator\[\]等⽀持像数组⼀样控制⼀个位的实现.这里我就不一一细讲了.有感兴趣的可以自己去官方文档里面看看.
3.4位图的优缺点
✅优势:
①空间利用率极高
只用1个bit表示一个数是否存在,比普通int数组省32倍空间,比哈希表省得更多.
②速度极快
插入、查询、删除都是O(1),本质就是简单位运算,CPU 效率非常高.
③天然去重
同一个数字无论存多少次,最终只占1位,自动去重.
④可以用来快速排序
数据范围已知时,遍历一遍位图就能得到有序结果,时间接近O(n).
❌缺点:
①只能处理整数(或能映射成整数的数据)
字符串、浮点数等必须先做哈希,会引入冲突.
②严重依赖数据范围
如果数据范围很大(比如0~2⁶⁴),位图根本开不出来,极度不适合稀疏数据.
③只能表示"存在/不存在"
不能存额外信息,也不能直接统计出现次数(普通1bit位图不行).
④无法处理重复计数
想记"出现几次"必须改成多比特位图(如2bit 计数),空间会变大.
⑤哈希映射后会有冲突
非整数用哈希函数转成下标,可能出现不同数据映射到同一位,造成误判.
一句话总结:位图省空间、速度快、但只适合范围不大的整数,只记存在不记内容.
3.5位图相关考察题⽬
1️⃣给定100亿个整数,设计算法找到只出现⼀次的整数?
①核心思路:使用2位位图(计数位图)来统计每个整数的出现次数.
②原理:将每个整数映射到2个二进制位,用不同的位组合表示出现次数:
00:出现 0 次
01:出现 1 次
10:出现 2 次及以上
③步骤:
初始化一个大小为2232位的位图(覆盖32位无符号整数范围).
遍历所有100亿个整数,对每个整数x:
若对应位为00,则更新为01(首次出现).
若对应位为01,则更新为10(再次出现).
若对应位为10,则保持不变(已超过1次).
遍历位图,所有状态为01的整数即为只出现一次的数.
④内存计算:2 * 232位 = 233位 =1GB,符合常见内存限制.
2️⃣给两个⽂件,分别有100亿个整数,我们只有1G内存,如何找到两个⽂件交集?
①核心思路:使用两个独立的位图,分别标记两个文件中存在的整数,再通过位运算求交集.
②原理:位图的位运算(与运算)可以高效地找到同时存在于两个集合中的元素.
③步骤:
初始化两个大小为232位(512MB)的位图A和B,总占用 1GB 内存.
遍历第一个文件,将所有存在的整数在位图 A 中标记为1.
遍历第二个文件,将所有存在的整数在位图 B 中标记为1.
遍历所有整数x,若 A.test(x) && B.test(x) 为真,则x是两个文件的交集.
④内存验证:单个位图占用232/8=512MB,两个位图共1GB,刚好满足内存限制.
3️⃣⼀个⽂件有100亿个整数,1G内存,设计算法找到出现次数不超过2次的所有整数?
①原理:用两位二进制位的四种组合表示不同的出现次数:
00:出现 0 次
01:出现 1 次
10:出现 2 次
11:出现 3 次及以上
②步骤:
初始化一个大小为2 232位(1GB)的位图.
遍历文件中的所有整数,对每个整数x:
若当前状态为00→更新为01(+1次).
若当前状态为01→更新为10(+1次).
若当前状态为10→更新为11(+1次,超过2次).
若当前状态为11→保持不变.
遍历位图,所有状态为01(1次)和10(2次)的整数,即为出现次数不超过2次的数.
cpp
template<size_t N>
class twobitset
{
public:
void set(size_t x)
{
bool bit1 = _bs1.test(x);
bool bit2 = _bs2.test(x);
if (!bit1 && !bit2) // 00->01
{
_bs2.set(x);
}
else if (!bit1 && bit2) // 01->10
{
_bs1.set(x);
_bs2.reset(x);
}
else if (bit1 && !bit2) // 10->11
{
_bs1.set(x);
_bs2.set(x);
}
}
// 返回0 出现0次数
// 返回1 出现1次数
// 返回2 出现2次数
// 返回3 出现2次及以上
int get_count(size_t x)
{
bool bit1 = _bs1.test(x);
bool bit2 = _bs2.test(x);
if (!bit1 && !bit2)
{
return 0;
}
else if (!bit1 && bit2)
{
return 1;
}
else if (bit1 && !bit2)
{
return 2;
}
else
{
return 3;
}
}
private:
bitset<N> _bs1;
bitset<N> _bs2;
};
};
void test_bitset2()
{
bit::twobitset<100> tbs;
int a[] = { 5,7,9,2,5,99,5,5,7,5,3,9,2,55,1,5,6,6,6,6,7,9 };
for (auto e : a)
{
tbs.set(e);
}
for (size_t i = 0; i < 100; ++i)
{
//cout << i << "->" << tbs.get_count(i) << endl;
if (tbs.get_count(i) == 1 || tbs.get_count(i) == 2)
{
cout << i << endl;
}
}
}
// 模拟位图找交集
void test_bitset1()
{
int a1[] = { 5,7,9,2,5,99,5,5,7,5,3,9,2,55,1,5,6 };
int a2[] = { 5,3,5,99,6,99,33,66};
bitset<100> bs1;
bitset<100> bs2;
for (auto e : a1)
{
bs1.set(e);
}
for (auto e : a2)
{
bs2.set(e);
}
for (size_t i = 0; i < 100; i++)
{
if (bs1.test(i) && bs2.test(i))
{
cout << i << endl;
}
}
}
void test_bitset1()
{
int a1[] = { 5,7,9,2,5,99,5,5,7,5,3,9,2,55,1,5,6 };
int a2[] = { 5,3,5,99,6,99,33,66 };
bitset<100> bs1;
bitset<100> bs2;
for (auto e : a1)
{
bs1.set(e);
}
for (auto e : a2)
{
bs2.set(e);
}
for (size_t i = 0; i < 100; i++)
{
if (bs1.test(i) && bs2.test(i))
{
cout << i << endl;
}
}
}4.布隆过滤器(哈希扩展学习)
4.1什么是布隆过滤器?
布隆过滤器是基于位图扩展的概率型数据结构,核心用于高效判断一个元素是否存在于海量集合中.它牺牲了"绝对准确性",换取了极致的空间效率和查询速度---特点是:不存在的元素一定能准确判断,存在的元素可能误判.可以通俗理解为:布隆过滤器是位图的"升级版",用多个哈希函数+位图解决了普通位图"只能处理整数、数据范围受限"的问题,同时保持了位图的空间优势.
有⼀些场景下⾯,有⼤量数据需要判断是否存在,⽽这些数据不是整形,那么位图就不能使⽤了,使⽤红⿊树/哈希表等内存空间可能不够.这些场景就需要布隆过滤器来解决.
布隆过滤器是由布隆(Burton Howard Bloom)在1970年提出的⼀种紧凑型的、⽐较巧妙的概率型数据结构,特点是⾼效地插⼊和查询,可以⽤来告诉你"某样东西⼀定不存在或者可能存在",它是⽤多个哈希函数,将⼀个数据映射到位图结构中.此种⽅式不仅可以提升查询效率,也可以节省⼤量的内存空间.
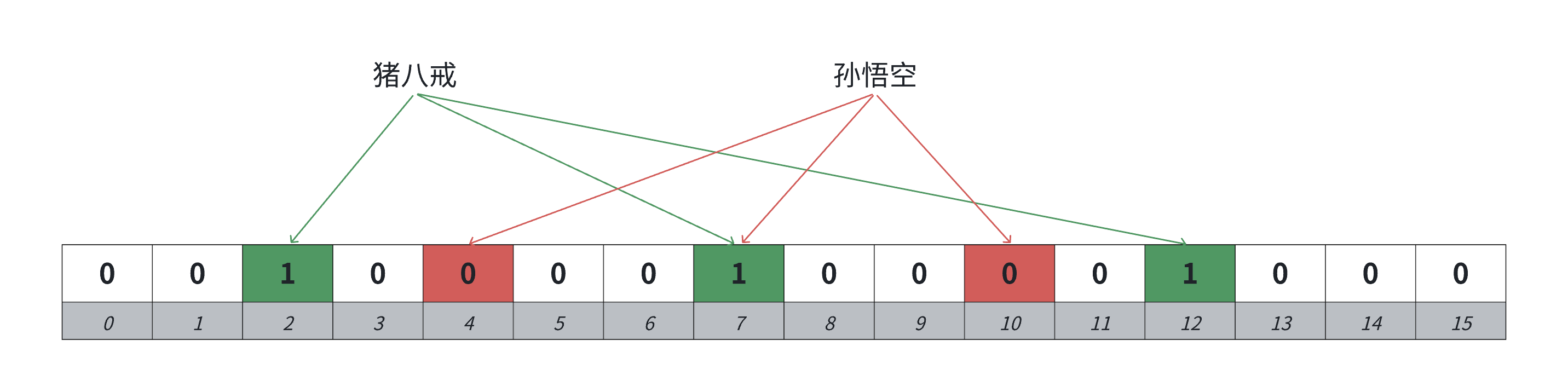
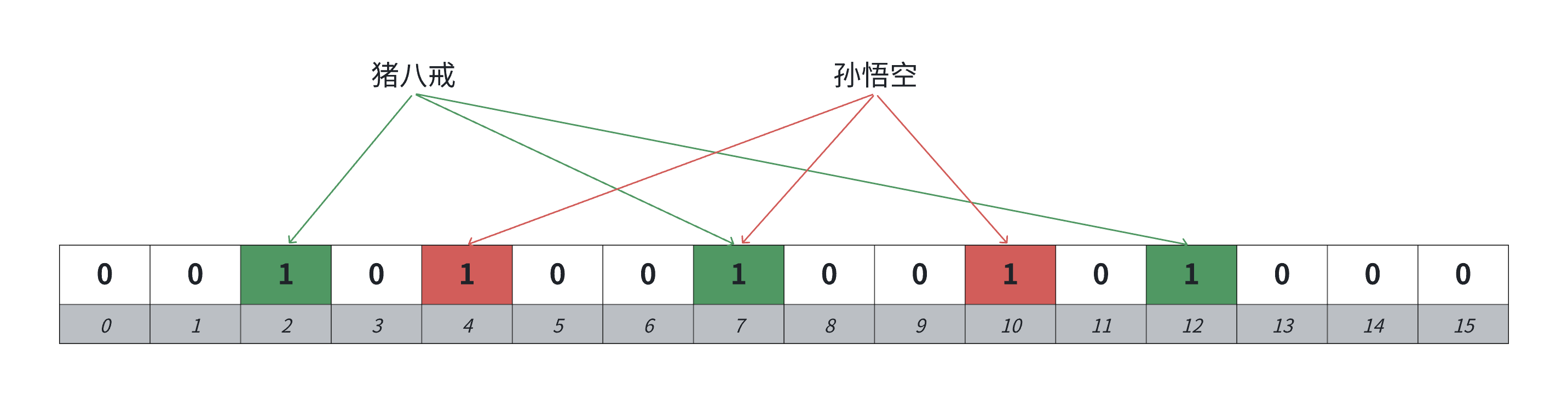
布隆过滤器的思路就是把key先映射转成哈希整型值,再映射⼀个位,如果只映射⼀个位的话,冲突率会⽐较多,所以可以通过多个哈希函数映射多个位,降低冲突率.布隆过滤器这⾥跟哈希表不⼀样,它⽆法解决哈希冲突的,因为它压根就不存储这个值,只标记映射的位.它的思路是尽可能降低哈希冲突.判断⼀个值key在是不准确的,判断⼀个值key不在是准确的.下面用猪八戒形象的表示在,孙悟空形象的表示不在(误判).
4.2布隆过滤器的核心原理
1️⃣底层结构
基础:一个长度为m的位图(bit数组),初始所有位都是0;
核心:k个独立的哈希函数(如 MD5、SHA1 或自定义哈希),每个函数能将任意元素(字符串/整数/对象)映射到位图的一个索引位置.
2️⃣核心流程(插入+查询)
(1)插入元素(如字符串"apple")
用k个哈希函数分别对"apple"计算,得到k个不同的位图索引(比如:2、5、7);
将位图中这k个索引位置的位全部置为1.
(2)查询元素(判断"apple"是否存在)
用同样的k个哈希函数对"apple"计算,得到相同的k个索引(2、5、7);
检查位图中这k个位置:
只要有一个位置是0:元素一定不存在;
所有位置都是1:元素可能存在(因为其他元素可能恰好把这些位置都置1).
3️⃣直观示例
假设位图长度m=8,哈希函数数量k=3:
插入"apple"→哈希得到索引 2、5、7→位图变为:0 0 1 0 0 1 0 1;
查询"apple"→检查 2、5、7 全为1→判定"可能存在";
查询"banana"→哈希得到索引 3、5、7→检查到索引3是0→判定"一定不存在";
查询"orange"→哈希得到索引 2、5、7→检查全为1→误判"可能存在"(假阳性).
4.3布隆过滤器误判率推导
推导过程
说明:这个⽐较复杂,涉及概率论、极限、对数运算,求导函数等知识,有兴趣且数学功底⽐较好的人可以看细看⼀下,其他人记⼀下结论即可!
假设定义
m m m:布隆过滤器的bit长度.
n n n:插入过滤器的元素个数.
k k k:哈希函数的个数.
①单个哈希函数下,某位置被置为1的概率: 1 m \frac{1}{m} m1
②单个哈希函数下,某位置不被置为1的概率: 1 − 1 m 1 - \frac{1}{m} 1−m1
③经过k次哈希后,某位置依旧不被置为1的概率: ( 1 − 1 m ) k \left(1 - \frac{1}{m}\right)^k (1−m1)k
④利用极限公式 lim m → ∞ ( 1 − 1 m ) − m = e \lim_{m \to \infty} \left(1 - \frac{1}{m}\right)^{-m} = e limm→∞(1−m1)−m=e,近似化简: ( 1 − 1 m ) k = ( ( 1 − 1 m ) m ) k m ≈ e − k m \left(1 - \frac{1}{m}\right)^k = \left(\left(1 - \frac{1}{m}\right)^m\right)^{\frac{k}{m}} \approx e^{\frac{-k}{m}} (1−m1)k=((1−m1)m)mk≈em−k
⑤插入n个元素后,某位置依旧不被置为1的概率: ( 1 − 1 m ) k n ≈ e − k n m \left(1 - \frac{1}{m}\right)^{kn} \approx e^{\frac{-kn}{m}} (1−m1)kn≈em−kn
⑥插入n个元素后,某位置被置为1的概率: 1 − ( 1 − 1 m ) k n ≈ 1 − e − k n m 1 - \left(1 - \frac{1}{m}\right)^{kn} \approx 1 - e^{\frac{-kn}{m}} 1−(1−m1)kn≈1−em−kn
⑦查询一个元素时,k次哈希后所有位置都命中1(即误判存在)的概率(误判率):
( 1 − ( 1 − 1 m ) k n ) k ≈ ( 1 − e − k n m ) k \left(1 - \left(1 - \frac{1}{m}\right)^{kn}\right)^k \approx \left(1 - e^{\frac{-kn}{m}}\right)^k (1−(1−m1)kn)k≈(1−em−kn)k
结论
布隆过滤器的误判率为 : f ( k ) = ( 1 − e − k n m ) k f(k) = \left(1 - e^{\frac{-kn}{m}}\right)^k f(k)=(1−em−kn)k
等价形式 : f ( k ) = ( 1 − 1 e k n m ) k f(k) = \left(1 - \frac{1}{e^{\frac{kn}{m}}}\right)^k f(k)=(1−emkn1)k
误判率趋势 :在k固定时,n增加→误判率升高;m增加→误判率降低.
最优哈希函数个数 :当m、n固定时,对误判率公式求导取最小值,得到最优哈希函数数量: k = m n ln 2 k = \frac{m}{n} \ln 2 k=nmln2
根据期望误判率求bit长度 :若已知期望误判率p和插入元素数n,代入最优k公式后,可推导出所需bit长度:
m = − n ⋅ ln p ( ln 2 ) 2 m = -\frac{n \cdot \ln p}{(\ln 2)^2} m=−(ln2)2n⋅lnp(这个是怎么推导来的?请看下面)
设: b = e n m b = e^{\frac{n}{m}} b=emn
则简化为: f ( k ) = ( 1 − b − k ) k f(k) = (1 - b^{-k})^k f(k)=(1−b−k)k
两边取对数: ln f ( k ) = k ⋅ ln ( 1 − b − k ) \ln f(k) = k \cdot \ln(1 - b^{-k}) lnf(k)=k⋅ln(1−b−k)
两边对 k k k求导:
1 f ( k ) ⋅ f ′ ( k ) = ln ( 1 − b − k ) + k ⋅ 1 1 − b − k ⋅ ( − b − k ) ⋅ ln b ⋅ ( − 1 ) = ln ( 1 − b − k ) + k ⋅ b − k ⋅ ln b 1 − b − k \begin{align*} \frac{1}{f(k)} \cdot f'(k) &= \ln(1 - b^{-k}) + k \cdot \frac{1}{1 - b^{-k}} \cdot (-b^{-k}) \cdot \ln b \cdot (-1) \\ &= \ln(1 - b^{-k}) + k \cdot \frac{b^{-k} \cdot \ln b}{1 - b^{-k}} \end{align*} f(k)1⋅f′(k)=ln(1−b−k)+k⋅1−b−k1⋅(−b−k)⋅lnb⋅(−1)=ln(1−b−k)+k⋅1−b−kb−k⋅lnb
下面求最值:
ln ( 1 − b − k ) + k ⋅ b − k ⋅ ln b 1 − b − k = 0 ( 1 − b − k ) ⋅ ln ( 1 − b − k ) = − k ⋅ b − k ⋅ ln b ( 1 − b − k ) ⋅ ln ( 1 − b − k ) = b − k ⋅ ln b − k 1 − b − k = b − k b − k = 1 2 e − k n m = 1 2 \begin{align*} \ln(1 - b^{-k}) + k \cdot \frac{b^{-k} \cdot \ln b}{1 - b^{-k}} &= 0 \\ (1 - b^{-k}) \cdot \ln(1 - b^{-k}) &= -k \cdot b^{-k} \cdot \ln b \\ (1 - b^{-k}) \cdot \ln(1 - b^{-k}) &= b^{-k} \cdot \ln b^{-k} \\ 1 - b^{-k} &= b^{-k} \\ b^{-k} &= \frac{1}{2} \\ e^{-\frac{kn}{m}} &= \frac{1}{2} \end{align*} ln(1−b−k)+k⋅1−b−kb−k⋅lnb(1−b−k)⋅ln(1−b−k)(1−b−k)⋅ln(1−b−k)1−b−kb−ke−mkn=0=−k⋅b−k⋅lnb=b−k⋅lnb−k=b−k=21=21
则误判率最低时,得出 k k k值: k = ln 2 ⋅ m n k = \ln2 \cdot \frac{m}{n} k=ln2⋅nm
把 k k k代入误判率公式,得出: P ( error ) = ( 1 − 1 2 ) k = 2 − k = 2 − ln 2 ⋅ m n P(\text{error}) = \left(1 - \frac{1}{2}\right)^k = 2^{-k} = 2^{-\ln2 \cdot \frac{m}{n}} P(error)=(1−21)k=2−k=2−ln2⋅nm
把 k k k代入误判率公式,得出 m m m值: P = 2 − ln 2 ⋅ m n ⇒ ln p = ln 2 ⋅ ( − ln 2 ) ⋅ m n ⇒ m = − n ⋅ ln p ( ln 2 ) 2 P = 2^{-\ln2 \cdot \frac{m}{n}} \Rightarrow \ln p = \ln2 \cdot (-\ln2) \cdot \frac{m}{n} \Rightarrow m = -\frac{n \cdot \ln p}{(\ln2)^2} P=2−ln2⋅nm⇒lnp=ln2⋅(−ln2)⋅nm⇒m=−(ln2)2n⋅lnp
4.4布隆过滤器代码实现
cpp
#include <iostream>
#include <string>
#include <vector>
using namespace std;
// 自定义bitset(基于vector<char>,堆上存储,避免std::bitset静态数组溢出问题)
namespace bit {
template<size_t N>
class bitset {
public:
// 构造函数:计算需要的字节数(N位 / 8)
bitset() {
_bits.resize(N / 8 + 1, 0); // 多开1字节避免越界
}
// 将第pos位设置为1
void set(size_t pos) {
if (pos >= N) { // 防止越界
return;
}
size_t byte_idx = pos / 8; // 计算字节下标
size_t bit_idx = pos % 8; // 计算字节内的位下标
_bits[byte_idx] |= (1 << bit_idx);
}
// 检查第pos位是否为1
bool test(size_t pos) const {
if (pos >= N) { // 越界则返回false
return false;
}
size_t byte_idx = pos / 8;
size_t bit_idx = pos % 8;
return (_bits[byte_idx] & (1 << bit_idx)) != 0;
}
// 可选:将第pos位重置为0
void reset(size_t pos) {
if (pos >= N) {
return;
}
size_t byte_idx = pos / 8;
size_t bit_idx = pos % 8;
_bits[byte_idx] &= ~(1 << bit_idx);
}
private:
vector<char> _bits; // 底层存储:1字节=8位
};
}
// BKDR哈希函数(Java字符串哈希算法)
struct HashFuncBKDR {
/// @detail 本算法由Brian Kernighan与Dennis Ritchie提出,累乘因子为31
size_t operator()(const string& s) {
size_t hash = 0;
for (auto ch : s) {
hash *= 31;
hash += ch; // 累加字符的ASCII值
}
return hash;
}
};
// AP哈希函数(Arash Partow发明)
struct HashFuncAP {
size_t operator()(const string& s) {
size_t hash = 0;
for (size_t i = 0; i < s.size(); i++) {
if ((i & 1) == 0) { // 偶数位字符
hash ^= ((hash << 7) ^ (s[i]) ^ (hash >> 3));
}
else { // 奇数位字符
hash ^= (~((hash << 11) ^ (s[i]) ^ (hash >> 5)));
}
}
return hash;
}
};
// DJB哈希函数(Daniel J. Bernstein教授发明)
struct HashFuncDJB {
size_t operator()(const string& s) {
size_t hash = 5381; // 初始值固定为5381
for (auto ch : s) {
hash = hash * 33 ^ ch; // 33是DJB的核心因子
}
return hash;
}
};
// 布隆过滤器模板类
template<size_t N,
size_t X = 6,
class K = string,
class Hash1 = HashFuncBKDR,
class Hash2 = HashFuncAP,
class Hash3 = HashFuncDJB>
class BloomFilter {
public:
// 插入元素到布隆过滤器
void Set(const K& key) {
// 计算3个哈希值并取模(M是总位数)
size_t hash1 = Hash1()(key) % M;
size_t hash2 = Hash2()(key) % M;
size_t hash3 = Hash3()(key) % M;
// 标记对应位为1
_bs.set(hash1);
_bs.set(hash2);
_bs.set(hash3);
}
// 测试元素是否存在
bool Test(const K& key) {
size_t hash1 = Hash1()(key) % M;
if (_bs.test(hash1) == false)
return false;
size_t hash2 = Hash2()(key) % M;
if (_bs.test(hash2) == false)
return false;
size_t hash3 = Hash3()(key) % M;
if (_bs.test(hash3) == false)
return false;
return true; // 可能误判
}
// 公式计算理论误判率
double getFalseProbability() {
// 误判率公式:(1 - e^(-k*n/m))^k 这里k=3, m=X*N, n=N(简化版)
double p = pow((1.0 - pow(2.71828, -3.0 / X)), 3.0); // e取2.71828更精准
return p;
}
private:
static const size_t M = X * N; // 布隆过滤器总位数(X倍的元素数量)
bit::bitset<M> _bs; // 自定义bitset存储位状态
};
// 测试用例1:简单字符串测试
void TestBloomFilter1() {
string strs[] = { "百度","字节","腾讯" };
BloomFilter<10> bf; // 元素数量N=10,X=6(默认)
// 插入元素
for (auto& s : strs) {
bf.Set(s);
}
// 测试存在的元素(应返回true)
cout << "测试存在的元素:" << endl;
for (auto& s : strs) {
cout << s << " : " << boolalpha << bf.Test(s) << endl;
}
// 测试不存在的元素(理论应返回false,可能误判)
cout << "\n测试不存在的元素:" << endl;
for (auto& s : strs) {
cout << s + "a" << " : " << boolalpha << bf.Test(s + "a") << endl;
}
cout << "摆渡 : " << boolalpha << bf.Test("摆渡") << endl;
cout << "百渡 : " << boolalpha << bf.Test("百渡") << endl;
}
// 测试用例2:海量数据误判率测试
void TestBloomFilter2() {
srand(time(0)); // 初始化随机数种子
const size_t N = 100000; // 元素数量(建议先小量测试,100万需稍等)
BloomFilter<N> bf; // N=10万,X=6(默认)
std::vector<std::string> v1;
std::string url = "猪八戒";
// 第一步:插入10万个不同的URL
cout << "开始插入" << N << "个URL..." << endl;
for (size_t i = 0; i < N; ++i) {
v1.push_back(url + to_string(i));
}
for (auto& str : v1) {
bf.Set(str);
}
// 第二步:测试相似字符串(前缀相同,后缀不同)的误判率
v1.clear();
cout << "测试相似字符串误判率..." << endl;
for (size_t i = 0; i < N; ++i) {
string urlstr = url + to_string(999999 + i); // 后缀不同
v1.push_back(urlstr);
}
size_t n2 = 0;
for (auto& str : v1) {
if (bf.Test(str)) { // 误判(实际未插入)
++n2;
}
}
cout << "相似字符串误判率: " << (double)n2 / N << endl;
// 第三步:测试不相似字符串的误判率
v1.clear();
cout << "测试不相似字符串误判率..." << endl;
for (size_t i = 0; i < N; ++i) {
string url = "孙悟空";
url += std::to_string(i + rand());
v1.push_back(url);
}
size_t n3 = 0;
for (auto& str : v1) {
if (bf.Test(str)) {
++n3;
}
}
cout << "不相似字符串误判率: " << (double)n3 / N << endl;
cout << "公式计算的理论误判率: " << bf.getFalseProbability() << endl;
}
int main() {
// 可选:先运行简单测试
TestBloomFilter1();
// 运行海量数据误判率测试
TestBloomFilter2();
return 0;
}4.5布隆过滤器删除问题
布隆过滤器默认是不⽀持删除的,因为⽐如"猪⼋戒"和"孙悟空"都映射在布隆过滤器中,它们映射的位有⼀个位是共同映射的(冲突的),如果我们把孙悟空删掉,那么再去查找"猪⼋戒"会查找不到,因为那么"猪⼋戒"间接被删掉了.解决⽅案:可以考虑计数标记的⽅式,⼀个位置⽤多个位标记,记录映射这个位的计数值,删除时,仅仅减减计数,那么就可以某种程度⽀持删除.但是这个⽅案也有缺陷,如果⼀个值不在布隆过滤器中,我们去删除,减减了映射位的计数,那么会影响已存在的值,也就是说,⼀个确定存在的值,可能会变成不存在,这⾥就很坑.当然也有⼈提出,我们可以考虑计数⽅式⽀持删除,但是定期重建⼀下布隆过滤器,这样也是⼀种思路.
4.6布隆过滤器的优缺点
✅优点
空间效率极致:比哈希表节省10~100 倍空间,1GB 内存可处理百亿级元素;
速度极快:插入/查询都是O(k)(k是哈希函数数量,通常取3~8),接近常数时间;
无数据存储:只存位图的位状态,不存储元素本身,保护隐私;
支持海量数据:不受元素类型限制(整数/字符串/对象均可),弥补位图只能处理整数的缺陷;
无假阴性:判断"不存在"时100%准确.
❌ 缺点
存在假阳性:无法100%确定元素存在(但假阳性概率可通过参数控制);
不支持删除:普通布隆过滤器无法删除元素(删除会导致其他元素的判断出错,需用"计数布隆过滤器"扩展);
参数敏感:位图长度m、哈希函数数量k需根据元素数量n提前计算,否则假阳性概率会飙升;
哈希函数要求高:需保证哈希函数独立、均匀分布,否则会增加假阳性概率.
4.7布隆过滤器的应⽤
1️⃣爬⾍系统中URL去重
在爬⾍系统中,为了避免重复爬取相同的URL,可以使⽤布隆过滤器来进⾏URL去重.爬取到的URL可
以通过布隆过滤器进⾏判断,已经存在的URL则可以直接忽略,避免重复的⽹络请求和数据处理.
2️⃣垃圾邮件过滤
在垃圾邮件过滤系统中,布隆过滤器可以⽤来判断邮件是否是垃圾邮件.系统可以将已知的垃圾邮件的特征信息存储在布隆过滤器中,当新邮件到达时,可以通过布隆过滤器快速判断是否为垃圾邮件,从⽽提⾼过滤的效率.
3️⃣预防缓存穿透
在分布式缓存系统中,布隆过滤器可以⽤来解决缓存穿透的问题.缓存穿透是指恶意⽤⼾请求⼀个不存在的数据,导致请求直接访问数据库,造成数据库压⼒过⼤.布隆过滤器可以先判断请求的数据是否存在于布隆过滤器中,如果不存在,直接返回不存在,避免对数据库的⽆效查询.
4️⃣对数据库查询提效
在数据库中,布隆过滤器可以⽤来加速查询操作.例如:⼀个app要快速判断⼀个电话号码是否注册过,可以使⽤布隆过滤器来判断⼀个⽤⼾电话号码是否存在于表中,如果不存在,可以直接返回不存在,避免对数据库进⾏⽆⽤的查询操作.如果在,再去数据库查询进⾏⼆次确认.
5.海量数据处理问题
5.1给两个⽂件,分别有100亿个query,我们只有1G内存,如何找到两个⽂件交集?
分析:假设平均每个query字符串50byte,100亿个query就是5000亿byte,约等于500G(1G约等于10亿多Byte)哈希表/红⿊树等数据结构肯定是⽆能为⼒的.
解决⽅案1:这个⾸先可以⽤布隆过滤器解决,⼀个⽂件中的query放进布隆过滤器,另⼀个⽂件依次查找,在的就是交集,问题就是找到交集不够准确,因为在的值可能是误判的,但是交集⼀定被找到了.
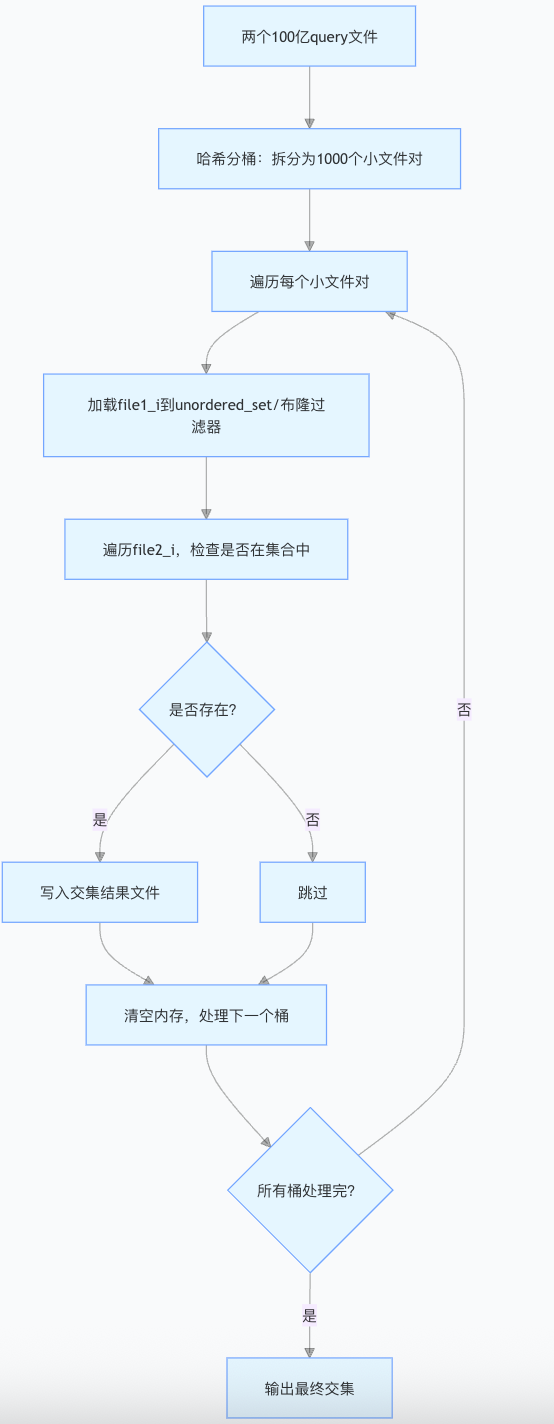
解决⽅案2:哈希切分,⾸先内存的访问速度远⼤于硬盘,⼤⽂件放到内存搞不定,那么我们可以考虑切分为⼩⽂件,再放进内存处理.但是不要平均切分,因为平均切分以后,每个⼩⽂件都需要依次暴⼒处理,效率还是太低了.可以利⽤哈希切分,依次读取⽂件中query,i = HashFunc(query)%N,N为准备切分多少分⼩⽂件,N取决于切成多少份,内存能放下,query放进第i号⼩⽂件,这样A和B中相同的query算出的hash值i是⼀样的,相同的query就进⼊的编号相同的⼩⽂件就可以编号相同的⽂件直接找交集,不⽤交叉找,效率就提升了.本质是相同的query在哈希切分过程中,⼀定进⼊的同⼀个⼩⽂件Ai和Bi,不可能出现A中的的query进⼊Ai,但是B中的相同query进⼊了和Bj的情况,所以对Ai和Bi进⾏求交集即可,不需要Ai和Bj求交集.(本段表述中i和j是不同的整数)哈希切分的问题就是每个⼩⽂件不是均匀切分的,可能会导致某个⼩⽂件很⼤内存放不下.我们细细分析⼀下某个⼩⽂件很⼤有两种情况:①这个⼩⽂件中⼤部分是同⼀个query.②这个⼩⽂件是有很多的不同query构成,本质是这些query冲突了.针对情况1,其实放到内存的set中是可以放下的,因为set是去重的.针对情况2,需要换个哈希函数继续⼆次哈希切分.所以本体我们遇到⼤于1G⼩⽂件,可以继续读到set中找交集,若set insert时抛出了异常(set插⼊数据抛异常只可能是申请内存失败了,不会有其他情况),那么就说明内存放不下是情况2,换个哈希函数进⾏⼆次哈希切分后再对应找交集.
接下来我将详细拆分解决方案
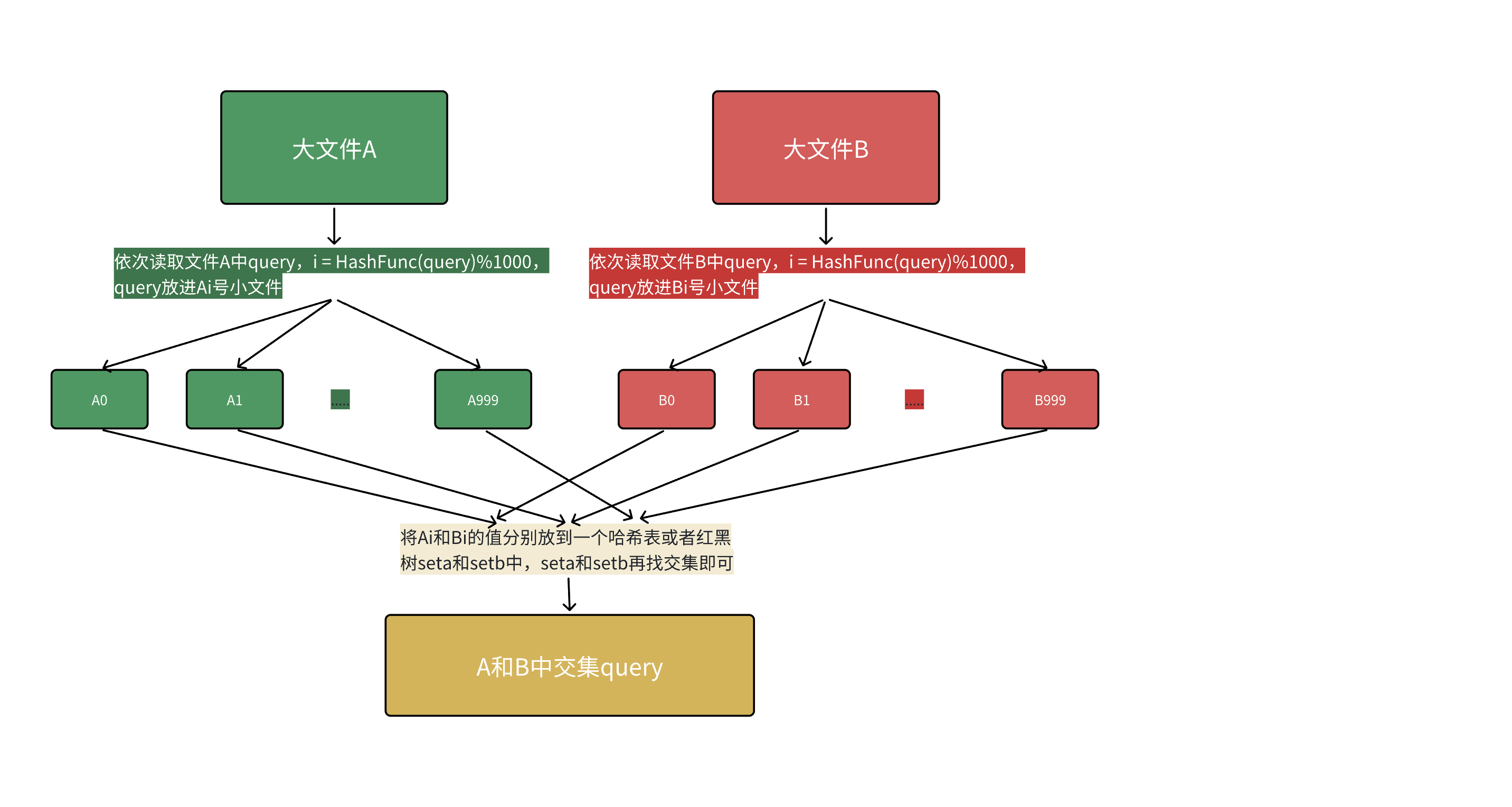
步骤1:哈希分桶(拆分大文件为小文件)
原理
用同一个哈希函数对两个文件的所有 query 计算哈希值,再对桶数取模,将 query 写入对应编号的小文件.这样能保证:相同的 query 一定会被分到编号相同的小文件对中(比如file1的query"abc"分到桶 3,file2的"abc"也一定会分到桶3),不同桶之间无交集,可独立处理.
具体操作
确定桶数:
假设每个query平均 50 字节,100 亿 query 拆成1000个桶,每个桶约 1000 万条 query,单桶大小≈1000万×50 字节=500MB(1G内存可轻松容纳).
(桶数可根据query 平均长度调整:若query更长,可拆成2000个桶,单桶≈250MB).
拆分文件1:
遍历file1的每个 query,计算hash(query)%1000,得到桶号i(0~999);
将该query写入小文件file1_i.txt(共生成 1000 个小文件).
拆分文件2:
用完全相同的哈希函数+取模值,遍历 file2 的每个query,写入对应小文件file2_i.txt(共1000个小文件).
关键注意点
必须用相同的哈希函数(比如 BKDRHash),否则相同query会分到不同桶;
哈希函数要均匀(如BKDR/MD5),避免某个小文件过大(超过1G).
步骤2:逐个处理小文件对,找交集
对每一组小文件file1_i.txt和file2_i.txt(i从0到999),依次执行以下操作:
加载file1_i 到内存:
将file1_i.txt的所有query存入unordered_set(哈希集合),1000万条query≈500MB,占用内存远小于1G.
遍历 file2_i 找交集:
逐行读取file2_i.txt的每个 query,检查是否在unordered_set中:
若存在:说明是交集,写入最终结果文件;
若不存在:跳过.
释放内存 :
处理完当前桶后,清空unordered_set,再处理下一个桶(避免内存累积).
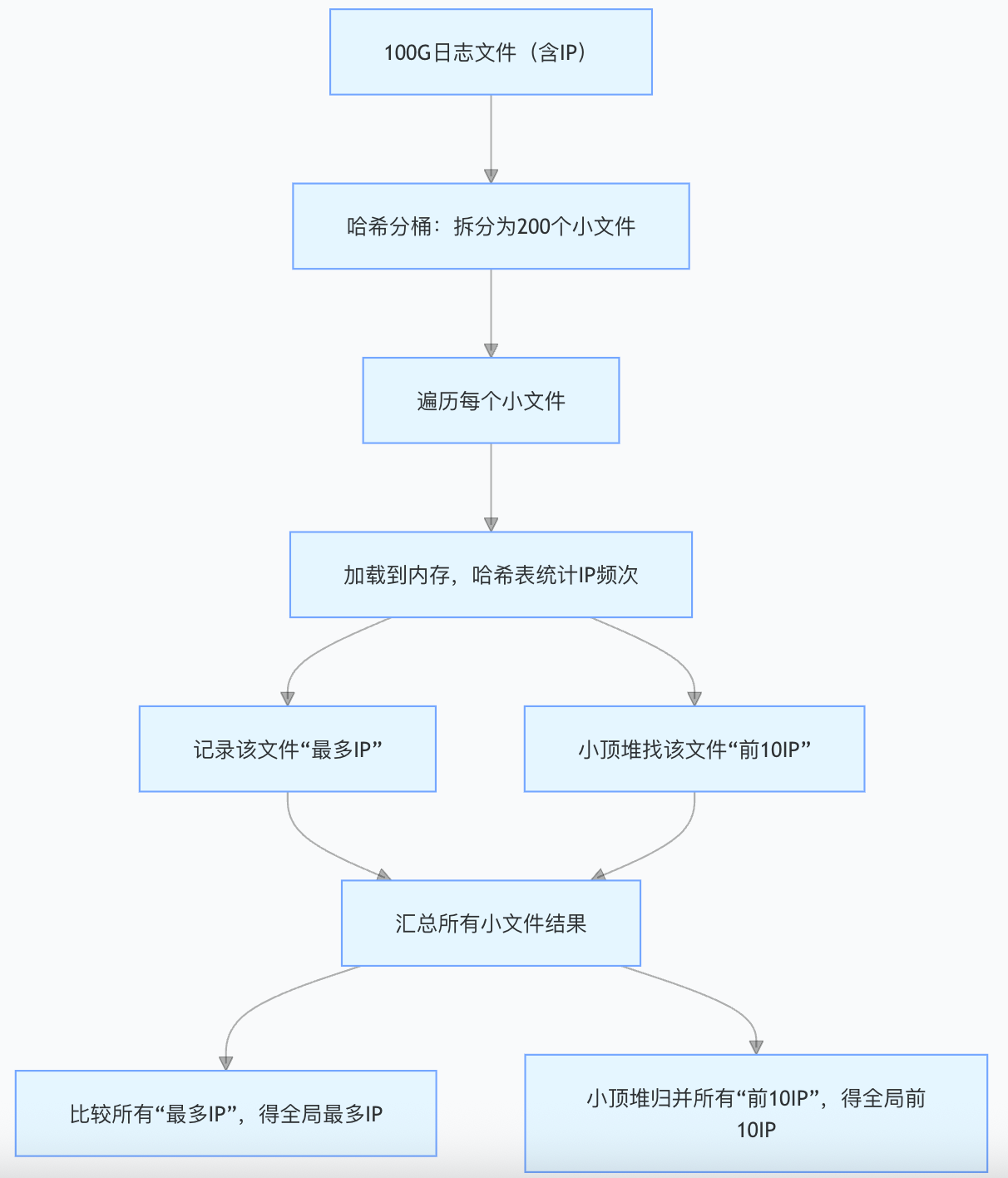
5.2给⼀个超过100G⼤⼩的log file,log中存着ip地址,设计算法找到出现次数最多的ip地址?查找出现次数前10的ip地址
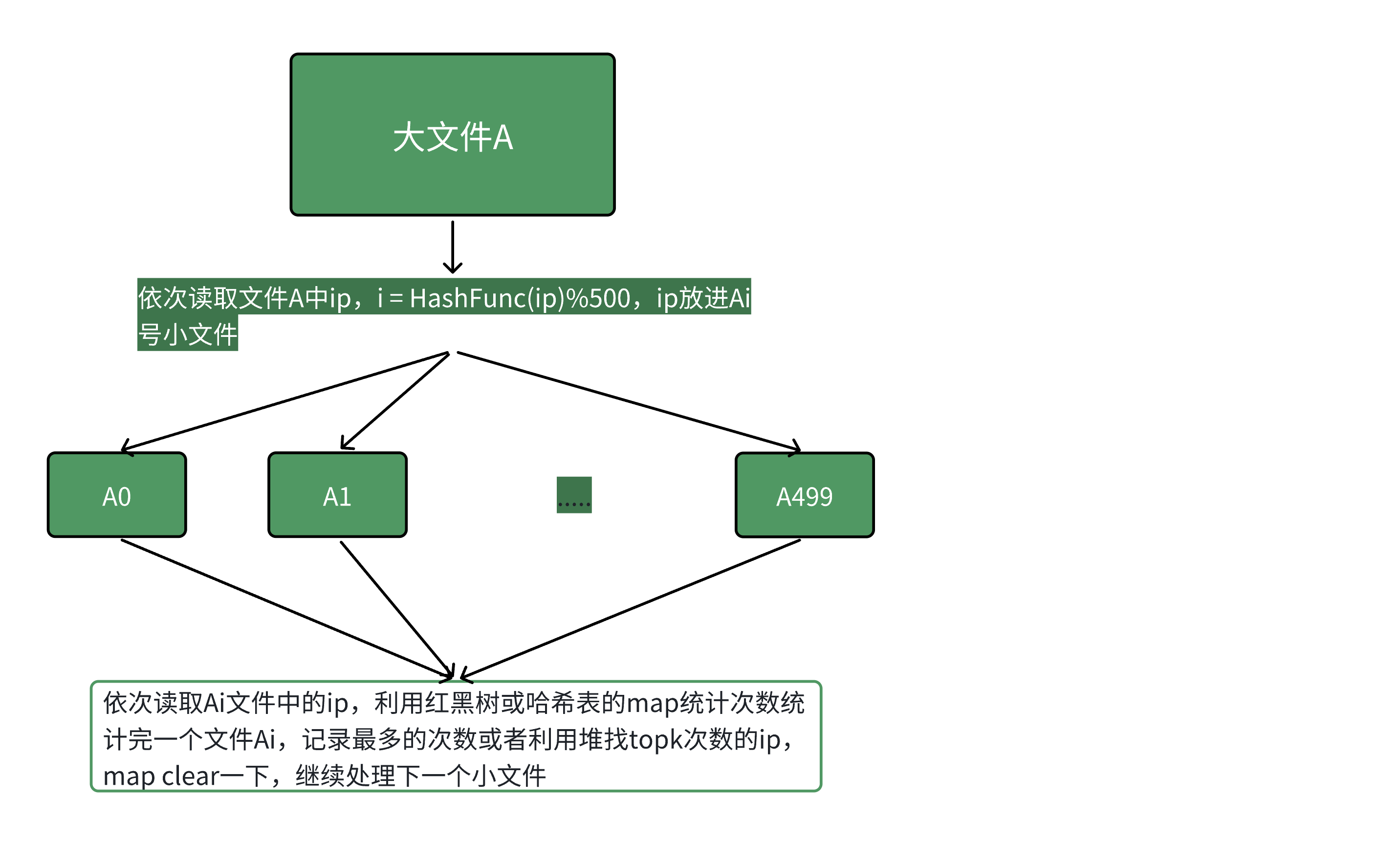
本题的思路跟上题完全类似,依次读取⽂件A中query,i = HashFunc(query)%500,query放进Ai号⼩⽂件,然后依次⽤map<string, int>对每个Ai⼩⽂件统计ip次数,同时求出现次数最多的ip或者topkip.本质是相同的ip在哈希切分过程中,⼀定进⼊的同⼀个⼩⽂件Ai,不可能出现同⼀个ip进⼊Ai和Aj的情况,所以对Ai进⾏统计次数就是准确的ip次数.
接下来我将详细拆分解决方案
步骤1:哈希分桶(拆分100G大文件为小文件)
原理
用同一哈希函数对每个IP计算哈希值,再对"桶数"取模,将IP写入对应编号的小文件.核心保证:相同 IP 一定会被分到同一个小文件,不同小文件无重复IP,可独立统计.
具体操作
确定桶数:
IP 为字符串时(如192.168.1.1,15 字节),100G文件拆成 200个桶,每个小文件约 500M(100G/200),远小于常规内存(16G/32G),可轻松加载.(若内存更小,可拆成500 个桶,单桶≈200MB).
IP 标准化(可选优化):
将IP字符串(如192.168.1.1)转为32位无符号整数(如192<<24 | 168<<16 | 1<<8 | 1),减少哈希计算和存储的开销:
拆分文件:
遍历100G日志文件,逐行读取IP,执行:
关键注意点
哈希函数选均匀性好的(如BKDR/MD5),避免某小文件过大(超过内存);
拆分时逐行处理,仅缓存当前IP,内存占用≈几十 KB,无压力.
步骤2:单个小文件内统计IP 频次
对每个小文件(如ip_bucket_0.txt),加载到内存统计 IP 出现次数,同时记录两类结果:
该文件内出现次数最多的IP(用于全局找"最多IP");
该文件内出现次数前10的IP(用于全局找"前10IP").
具体操作
统计频次(哈希表):
用unordered_map<uint32_t, int>(或unordered_map<string, int>)统计每个IP的出现次数,500MB小文件约含3000万条IP记录,哈希表占用内存≈3000 万×(4+4)=240MB(uint32_t+int),远小于内存限制.
找单个文件的"最多IP":
遍历哈希表,记录频次最大的IP和次数:
找单个文件的"前10IP"(小顶堆优化):
用大小为10的小顶堆(堆顶是当前最小频次),遍历哈希表,仅保留频次前10的IP,节省内存(堆仅存10个元素):
步骤3:全局归并(汇总所有小文件结果)
找出现次数最多的 IP
收集所有200个小文件的"最多 IP"(共200个IP);
遍历这200个IP,比较频次,保留频次最大的那个,即为全局出现次数最多的IP.
找出现次数前10的IP
收集所有200个小文件的"前10IP"(共200×10=2000个IP);
用大小为10的小顶堆遍历这2000个IP:
若堆大小<10,直接入堆;
若堆大小=10,且当前IP频次>堆顶频次,弹出堆顶,入堆当前IP;
遍历结束后,堆内的10个IP即为全局出现次数前10的IP(堆顶是第10名,堆底是第1名).

敬请期待下一篇文章内容:深入回溯C++11的发展历程
每日心灵鸡汤:大大方方做自己!
这世间有千万种生活方式,千万种人生轨迹.不必盲目追赶别人的脚步,不必模仿别人的活法.你有你自己的节奏,有自己的热爱,有自己的坚持,那些别人眼中的"不理解",或许正是你最珍贵的坚守.不必讨好世界,不必敷衍自己,大大方方地发光,踏踏实实地前行,相信时光不会辜负每一个认真做自己的人.愿你勇敢追逐内心的声音,不被流言左右,不被世俗裹挟,爱自己所爱,行自己所行,念自己所想!
