上个月做一个数据整理页,页面本身不复杂:本地库里拉一批记录,按规则清洗,再生成一份可展示的分组列表。逻辑写起来很顺,async/await 一套下来,代码看着也挺规整。
问题是,上真机之后不对劲。
页面第一次进入会有一个很短的卡顿,列表滚动到一半偶尔掉帧,点筛选时按钮反馈慢半拍。最开始我还以为是 ArkUI 列表写得不够克制,后来把日志打细一点才发现,真正拖后腿的是那段"看起来只是处理数组"的同步计算。
async 不是多线程。这个坑,做前端或者移动端的人应该都踩过。它能把异步流程写得舒服一点,但 CPU 真在主线程上跑的时候,UI 该卡还是卡。
后来这块我拆成了两层:短任务走 TaskPool,长活儿交给 Worker。不是为了显得架构高级,纯粹是被卡顿逼出来的。
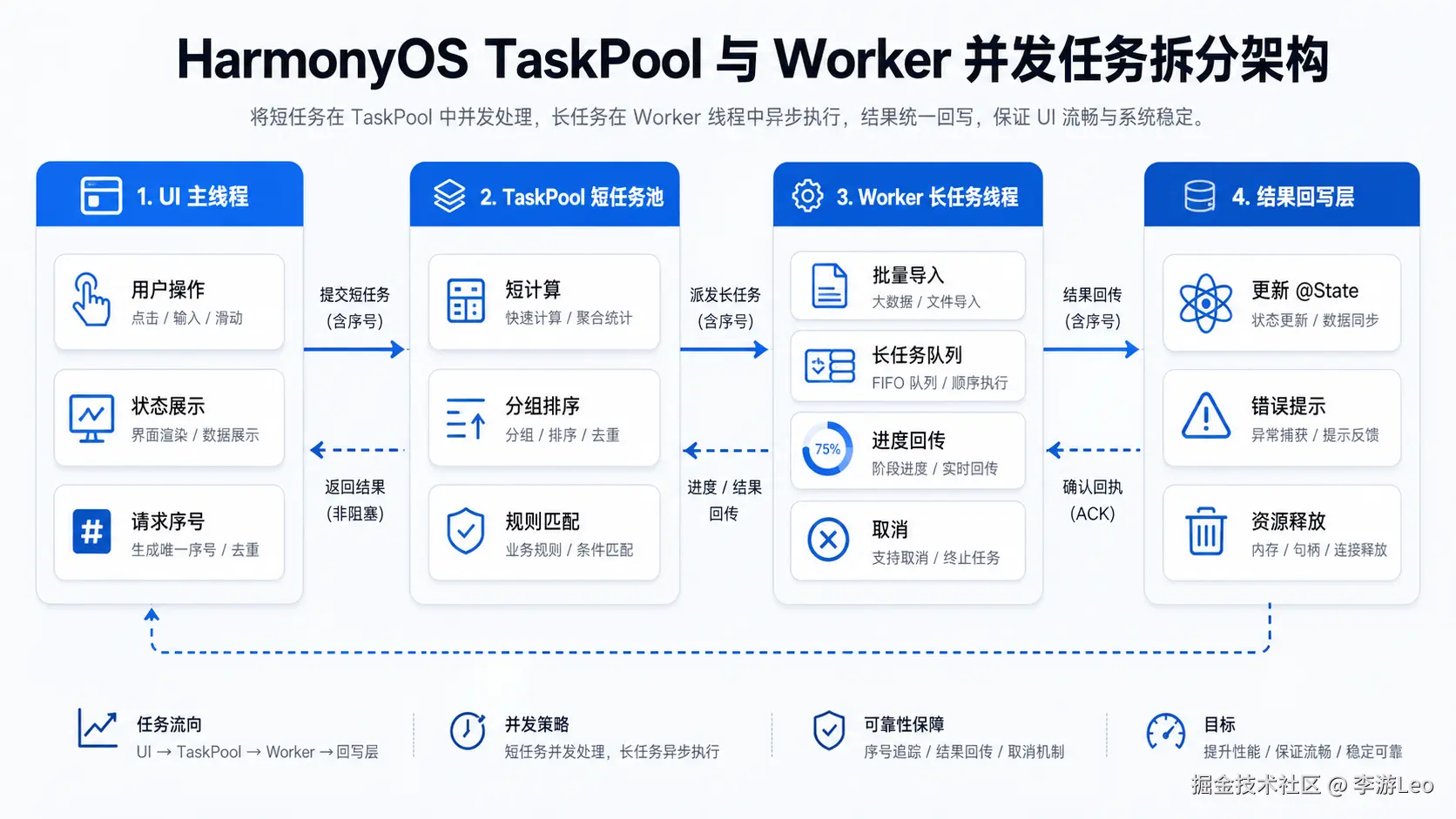
为什么这事值得单独拿出来讲
HarmonyOS 里聊并发,很多文章会直接给一个 TaskPool 示例:写一个 @Concurrent 函数,丢给 taskpool.execute(),拿到结果更新 UI。这个例子没问题,但如果项目稍微复杂一点,真正难的不是"怎么调 API",而是下面几个问题:
- 哪些任务适合 TaskPool,哪些任务别塞进去;
- 并发任务里传什么数据,别把 UI 状态、Context、复杂对象乱丢;
- 任务结果回来时,页面可能已经销毁了,怎么避免回写脏状态;
- 用户连续点击筛选、搜索、刷新时,旧任务怎么处理;
- Worker 用完不释放,内存和线程会悄悄把你坑了。
我现在的判断比较简单:
TaskPool 适合"短、散、可切分"的计算任务。Worker 适合"长、独立、有自己状态"的后台任务。
比如:
| 场景 | 更合适的方式 | 原因 |
|---|---|---|
| 列表数据清洗、排序、分组 | TaskPool | 任务短,输入输出清晰,不想维护线程生命周期 |
| 多段文本规则匹配 | TaskPool / TaskGroup | 可以拆成多份并行处理,再聚合结果 |
| 长时间日志解析 | Worker | 任务持续时间长,可能需要进度、暂停、取消 |
| 持续 OCR 队列、文件同步队列 | Worker | 有队列状态,生命周期独立,不能每次都临时起任务 |
| UI 动画、组件状态修改 | 主线程 | 后台线程不要直接碰 UI |
这篇不打算写成 API 字典。就按一个"本地数据整理页"的例子,把我最后落地的写法拆出来。
核心思路:别直接把业务对象扔进后台线程
当时页面里的数据大概长这样:
ts
export interface RawRecord {
id: string;
title: string;
type: string;
createdAt: number;
rawText: string;
score?: number;
}
export interface ViewSection {
groupName: string;
count: number;
items: ViewItem[];
}
export interface ViewItem {
id: string;
title: string;
summary: string;
level: 'low' | 'middle' | 'high';
}一开始我犯过一个懒:从页面状态里直接拿数组,塞给后台任务。后面越改越别扭,因为页面对象里混进了不少展示状态,比如是否展开、是否选中、临时高亮字段。这些东西对计算没用,传过去还容易把边界搞脏。
后来我改成了三步:
- 主线程只准备"纯输入数据";
- TaskPool 只做纯计算,不知道页面存在;
- 结果回来后,再由页面决定是否更新状态。
这个拆法有点啰嗦,但后面排问题会轻松很多。
用 TaskPool 处理一次短计算
先看一个最小可用的版本。
ts
// common/model/record.ts
export interface RawRecord {
id: string;
title: string;
type: string;
createdAt: number;
rawText: string;
score?: number;
}
export interface ViewItem {
id: string;
title: string;
summary: string;
level: string;
}
export interface ViewSection {
groupName: string;
count: number;
items: ViewItem[];
}
ts
// common/worker/record_task.ts
import { RawRecord, ViewItem, ViewSection } from '../model/record';
function buildSummary(text: string): string {
if (text.length <= 42) {
return text;
}
return `${text.substring(0, 42)}...`;
}
function calcLevel(score: number): string {
if (score >= 80) {
return 'high';
}
if (score >= 50) {
return 'middle';
}
return 'low';
}
// 注意:TaskPool 执行的函数要标注 @Concurrent。
// 这里尽量保持纯函数:不读页面状态,不操作 UI,不拿 Context。
@Concurrent
export function buildRecordSections(records: RawRecord[]): ViewSection[] {
const map = new Map<string, ViewItem[]>();
for (const record of records) {
const groupName = record.type.length > 0 ? record.type : '未分类';
const item: ViewItem = {
id: record.id,
title: record.title,
summary: buildSummary(record.rawText),
level: calcLevel(record.score ?? 0)
};
const list = map.get(groupName) ?? [];
list.push(item);
map.set(groupName, list);
}
const sections: ViewSection[] = [];
map.forEach((items: ViewItem[], groupName: string) => {
items.sort((a: ViewItem, b: ViewItem) => a.title.localeCompare(b.title));
sections.push({
groupName,
count: items.length,
items
});
});
sections.sort((a: ViewSection, b: ViewSection) => b.count - a.count);
return sections;
}页面里不要直接到处散落 taskpool.execute()。我一般会再包一层服务类,这样后面做取消、降级、日志都会方便一点。
ts
// common/service/RecordComputeService.ts
import { taskpool } from '@kit.ArkTS';
import { RawRecord, ViewSection } from '../model/record';
import { buildRecordSections } from '../worker/record_task';
export class RecordComputeService {
async buildSections(records: RawRecord[]): Promise<ViewSection[]> {
if (records.length === 0) {
return [];
}
// 只传纯数据。这里不要传 this,不要传组件对象,不要传 UI 状态。
const task = new taskpool.Task('build-record-sections', buildRecordSections, records);
const result = await taskpool.execute(task, taskpool.Priority.MEDIUM);
return result as ViewSection[];
}
}页面调用时,要特别注意"结果回来时页面还在不在"。这个问题很常见,尤其是用户快速返回、切 tab、重复进入页面的时候。
ts
// pages/RecordPage.ets
import { RecordComputeService } from '../common/service/RecordComputeService';
import { RawRecord, ViewSection } from '../common/model/record';
@Entry
@Component
struct RecordPage {
private computeService: RecordComputeService = new RecordComputeService();
private alive: boolean = true;
private requestSeq: number = 0;
@State loading: boolean = false;
@State sections: ViewSection[] = [];
@State errorText: string = '';
aboutToDisappear(): void {
this.alive = false;
}
async reload(records: RawRecord[]): Promise<void> {
const seq = ++this.requestSeq;
this.loading = true;
this.errorText = '';
try {
const result = await this.computeService.buildSections(records);
// 页面走了,或者后一次请求已经发出,旧结果就不要回写了。
if (!this.alive || seq !== this.requestSeq) {
return;
}
this.sections = result;
} catch (err) {
if (this.alive && seq === this.requestSeq) {
this.errorText = `数据整理失败:${JSON.stringify(err)}`;
}
} finally {
if (this.alive && seq === this.requestSeq) {
this.loading = false;
}
}
}
build() {
Column() {
if (this.loading) {
Text('整理中...')
.fontSize(14)
.opacity(0.7)
}
if (this.errorText.length > 0) {
Text(this.errorText)
.fontColor(Color.Red)
.fontSize(13)
}
List() {
ForEach(this.sections, (section: ViewSection) => {
ListItem() {
Column() {
Text(`${section.groupName} · ${section.count}`)
.fontSize(16)
.fontWeight(FontWeight.Medium)
ForEach(section.items, item => {
Text(`${item.title} - ${item.summary}`)
.fontSize(13)
.opacity(0.75)
}, item => item.id)
}
}
}, (section: ViewSection) => section.groupName)
}
.layoutWeight(1)
}
.width('100%')
.height('100%')
.padding(16)
}
}这段代码看着普通,但有两个点是我后来才养成习惯的:
一个是 requestSeq。 只要页面上有搜索、筛选、刷新这种连续触发的入口,就别相信异步返回顺序。旧任务慢一点回来,把新结果覆盖掉,这种 bug 很烦,而且不好复现。
另一个是 alive。 页面消失之后继续更新 @State,有时候不会马上炸,但它会把状态链路搞得很脏。尤其在复杂页面里,后面会出现一些莫名其妙的刷新。
多个短任务:TaskGroup 比自己 Promise.all 更稳一点
如果一批数据特别大,我不太建议把整个大数组一次性塞进去。更稳的方式是按业务边界切块,比如按月份、按类型、按文件批次拆开。
ts
// common/worker/record_task.ts
@Concurrent
export function buildRecordSectionsByChunk(records: RawRecord[], chunkName: string): ViewSection[] {
const sections = buildRecordSections(records);
// 给结果带一点来源信息,方便聚合和排查。
return sections.map((section: ViewSection) => {
return {
groupName: `${chunkName}/${section.groupName}`,
count: section.count,
items: section.items
} as ViewSection;
});
}
ts
// common/service/RecordComputeService.ts
import { taskpool } from '@kit.ArkTS';
import { RawRecord, ViewSection } from '../model/record';
import { buildRecordSectionsByChunk } from '../worker/record_task';
export interface RecordChunk {
name: string;
records: RawRecord[];
}
export class RecordComputeService {
async buildSectionsByChunks(chunks: RecordChunk[]): Promise<ViewSection[]> {
if (chunks.length === 0) {
return [];
}
const group = new taskpool.TaskGroup();
for (const chunk of chunks) {
// 每一块都是独立输入,避免任务之间共享可变对象。
group.addTask(buildRecordSectionsByChunk, chunk.records, chunk.name);
}
const result = await taskpool.execute(group, taskpool.Priority.MEDIUM) as Object[];
const merged: ViewSection[] = [];
for (const item of result) {
const sections = item as ViewSection[];
merged.push(...sections);
}
return merged;
}
}这里有个小经验:不要为了并发而切得太碎。
我试过把几千条记录拆成几十个小任务,结果并没有更快,调度、序列化、结果聚合的开销反而上来了。后来按"每块几百到一两千条"粗粒度切,整体更稳。
这个数字不是标准答案,要看数据结构、算法复杂度和设备性能。我的习惯是先保守切,真有性能问题再用日志和耗时统计说话。
Worker:别拿它当高级版 setTimeout
TaskPool 用起来省心,但它不适合所有场景。
比如有一个截图整理类功能:用户导入一批图片,后台要做 OCR、规则匹配、去重、写库,还要持续返回进度。这个任务不是"算一下就结束",它有自己的队列、有状态、有重试,还可能持续几十秒。
这种我会放到 Worker。
目录大概这样:
text
entry/src/main/ets/
├── pages/
│ └── ImportPage.ets
├── workers/
│ └── ImportWorker.ets
└── common/
├── model/
└── service/主线程创建 Worker:
ts
// common/service/ImportWorkerClient.ts
import { worker, MessageEvents, ErrorEvent } from '@kit.ArkTS';
export interface ImportJob {
jobId: string;
files: string[];
}
export interface ImportProgress {
jobId: string;
current: number;
total: number;
message: string;
}
export class ImportWorkerClient {
private threadWorker?: worker.ThreadWorker;
private currentJobId: string = '';
start(job: ImportJob, onProgress: (progress: ImportProgress) => void, onDone: () => void, onError: (msg: string) => void): void {
this.currentJobId = job.jobId;
// Stage 模型下注意 worker 文件路径,不要写成 src/main/ets 的完整路径。
this.threadWorker = new worker.ThreadWorker('entry/ets/workers/ImportWorker.ets', {
name: 'import-worker'
});
this.threadWorker.onmessage = (event: MessageEvents) => {
const data = event.data as Record<string, Object>;
const type = data['type'] as string;
const jobId = data['jobId'] as string;
// 旧任务或者脏消息直接丢掉。
if (jobId !== this.currentJobId) {
return;
}
if (type === 'progress') {
onProgress(data['payload'] as ImportProgress);
} else if (type === 'done') {
onDone();
this.release();
} else if (type === 'error') {
onError(data['message'] as string);
this.release();
}
};
this.threadWorker.onerror = (error: ErrorEvent) => {
onError(`Worker 异常:${error.message}`);
this.release();
};
this.threadWorker.postMessage({
type: 'start',
jobId: job.jobId,
files: job.files
});
}
cancel(): void {
this.threadWorker?.postMessage({
type: 'cancel',
jobId: this.currentJobId
});
this.release();
}
release(): void {
this.threadWorker?.terminate();
this.threadWorker = undefined;
this.currentJobId = '';
}
}Worker 文件里只处理后台逻辑:
ts
// workers/ImportWorker.ets
import { worker, MessageEvents } from '@kit.ArkTS';
const workerPort = worker.workerPort;
let canceled = false;
function postProgress(jobId: string, current: number, total: number, message: string): void {
workerPort.postMessage({
type: 'progress',
jobId,
payload: {
jobId,
current,
total,
message
}
});
}
async function handleImport(jobId: string, files: string[]): Promise<void> {
canceled = false;
for (let i = 0; i < files.length; i++) {
if (canceled) {
workerPort.postMessage({
type: 'error',
jobId,
message: '用户取消导入'
});
return;
}
const file = files[i];
postProgress(jobId, i + 1, files.length, `正在处理:${file}`);
// 这里放真正的耗时逻辑:OCR、规则匹配、去重、写临时结果等。
// 示例里只保留结构,不硬凑一个假的算法。
await doOneFile(file);
}
workerPort.postMessage({
type: 'done',
jobId
});
}
async function doOneFile(file: string): Promise<void> {
// 实际项目里建议继续拆服务,别把所有逻辑堆在 worker 文件里。
// 这里可以做文件读取、文本分析、批量写入前的数据准备。
console.info(`processing file: ${file}`);
}
workerPort.onmessage = (event: MessageEvents) => {
const data = event.data as Record<string, Object>;
const type = data['type'] as string;
const jobId = data['jobId'] as string;
if (type === 'start') {
const files = data['files'] as string[];
handleImport(jobId, files).catch((err: Error) => {
workerPort.postMessage({
type: 'error',
jobId,
message: err.message
});
});
} else if (type === 'cancel') {
canceled = true;
}
};Worker 的麻烦点不是创建,而是收尾。
很多问题都出在"我以为它自己会停"。实际上 Worker 更像一个你手动养出来的后台线程:用完要 terminate(),页面退出要释放,任务取消也要释放。否则看不出明显报错,但内存和线程资源会被占着。
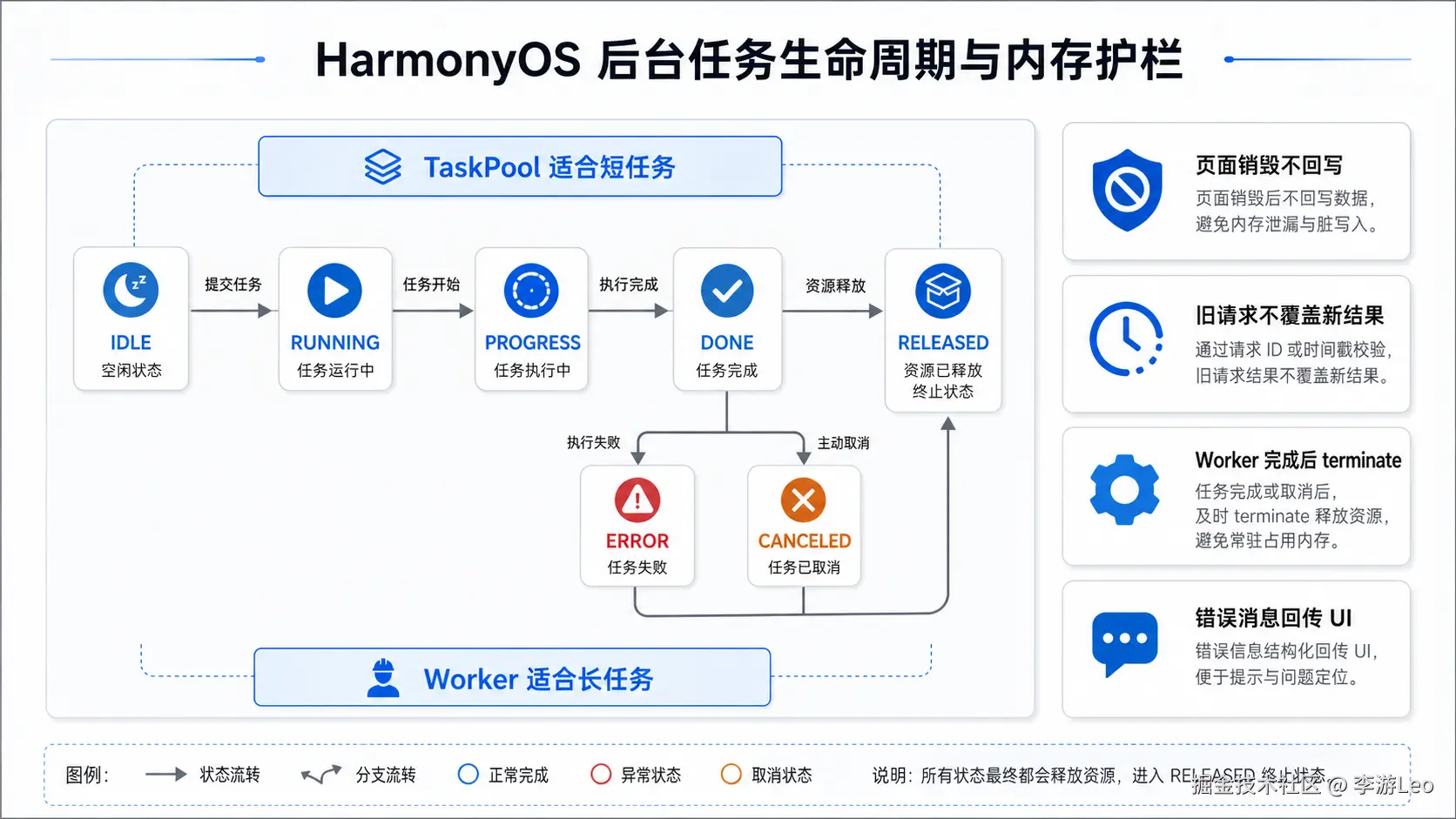
TaskPool 和 Worker 的边界,我一般这么定
项目里我会用下面这几个问题判断。
任务是不是短时间就能结束?
能结束,优先 TaskPool。比如排序、分组、规则计算、数据压缩前处理。
如果任务天然要跑很久,比如持续同步、批量导入、后台队列,就别硬塞 TaskPool。TaskPool 适合把任务交给系统调度,不适合自己在里面写一个长期循环。
任务有没有自己的状态?
没有状态,或者状态只来自输入参数,TaskPool 很舒服。
如果任务里有队列、重试次数、暂停恢复、进度回调、缓存状态,Worker 更清楚。因为这个时候你已经不是在跑一个函数了,而是在维护一个后台执行单元。
是否需要频繁和主线程通信?
TaskPool 也能做任务和宿主线程通信,但如果是持续进度、阶段回传、用户取消、错误恢复这一类,我更倾向 Worker。写起来没那么"漂亮",但状态关系比较直。
输入输出是不是干净?
后台线程最怕传一堆复杂对象。我的原则是:
text
能传 number/string/boolean/普通数组/普通对象,就别传带行为的对象。
能传 id,就别传整个业务实体。
能传快照,就别传还会被 UI 修改的引用。这不是洁癖,是为了少踩坑。
常见坑位
1. 把 async 当成多线程
async/await 只是让异步代码更像同步流程,它不会自动把 CPU 计算挪到后台线程。你在 async 函数里写一个很重的 for 循环,主线程照样要扛。
我现在看到下面这种代码就会警惕:
ts
async function refresh(): Promise<void> {
const rows = await queryRows();
// 这里如果数据量大,本质还是主线程同步计算。
const sections = buildBigSections(rows);
this.sections = sections;
}要么把 buildBigSections 拆到 TaskPool,要么在数据源阶段就减小计算量。
2. 后台任务直接操作 UI
不要在 TaskPool 函数或者 Worker 里直接改 @State,也不要传组件实例进去。后台只负责算,UI 更新回到页面层做。
这个边界一旦破了,后面代码会非常难维护。
3. 任务返回顺序覆盖新状态
搜索框输入、筛选条件切换、下拉刷新,都可能造成多个任务同时在路上。不要假设后发的任务一定后回来。
requestSeq 这种写法虽然土,但好用。
ts
const seq = ++this.requestSeq;
const result = await this.computeService.buildSections(records);
if (seq !== this.requestSeq) {
return;
}
this.sections = result;4. Worker 忘记 terminate
Worker 不是临时 Promise。页面消失、任务完成、任务失败、用户取消,都要考虑释放。
ts
aboutToDisappear(): void {
this.importWorkerClient.cancel();
}当然,cancel() 里不要只发一个取消消息,最好兜底 terminate(),否则异常路径里很容易漏。
5. 任务切得太碎
并发不是越多越快。移动端尤其明显,调度、通信、数据拷贝都有成本。
我一般先找"业务上天然可切"的边界,比如文件、月份、类型、批次。不要为了追求并发,把 1000 条数据切成 1000 个任务。
6. 错误只打日志,不回传状态
后台任务失败时,页面应该知道失败原因。尤其是批量处理类功能,如果只在 Worker 里 console.error,用户看到的就是一个永远转圈的 loading。
建议统一消息结构:
ts
export interface WorkerMessage<T> {
type: 'progress' | 'done' | 'error';
jobId: string;
payload?: T;
message?: string;
}别到处临时拼对象,后期很难查。
性能和稳定性上的几个小取舍
数据先瘦身,再进后台线程
别把数据库查出来的完整对象一股脑传给任务。很多字段后台根本用不上。先在主线程做一层轻量映射,只保留计算必需字段。
ts
const input = rows.map((row): RawRecord => {
return {
id: row.id,
title: row.title,
type: row.type,
createdAt: row.createdAt,
rawText: row.rawText,
score: row.score
};
});看着多写了几行,换来的是任务边界清楚,数据传输也更轻。
大任务分段回传,不要憋到最后
用户不怕等几秒,怕的是不知道你在干嘛。长任务放 Worker 时,阶段性回传进度很有必要。
ts
postProgress(jobId, current, total, '正在分析文本');
postProgress(jobId, current, total, '正在去重');
postProgress(jobId, current, total, '正在写入本地结果');别小看这几行,体验差很多。
给降级路径留位置
后台任务失败时,能不能退回主线程简化处理?能不能只展示部分结果?能不能让用户重新触发?
我一般会给服务层留一个 fallback:
ts
export class RecordComputeService {
async safeBuildSections(records: RawRecord[]): Promise<ViewSection[]> {
try {
return await this.buildSections(records);
} catch (err) {
console.error(`TaskPool failed: ${JSON.stringify(err)}`);
// 数据量很小时可以退回同步计算,大数据量不要硬退。
if (records.length <= 100) {
return this.buildSectionsOnMainThread(records);
}
throw err;
}
}
private buildSectionsOnMainThread(records: RawRecord[]): ViewSection[] {
// 可以复用同一套纯函数,或者做一个简化版本。
// 注意:这里只适合小数据兜底。
return [];
}
}降级不是为了掩盖 bug,是为了不要让用户卡死在一个失败状态里。
日志要带 jobId / taskName
并发问题最怕日志没上下文。
ts
console.info(`[import:${jobId}] start, total=${files.length}`);
console.info(`[import:${jobId}] progress ${current}/${total}`);
console.error(`[import:${jobId}] failed: ${message}`);线上排查时,这种日志比"start、done、error"有用太多。
适合落地的场景
我觉得 TaskPool + Worker 最适合下面几类 HarmonyOS 应用:
- 图片、文本、音频类素材整理工具;
- 本地知识库、截图管家、笔记分析工具;
- 大列表筛选、分组、排序较重的业务页;
- 本地文件批处理、导入导出、格式转换;
- 不想把所有耗时逻辑都塞进 UIAbility 的中大型应用。
如果你的页面只是发个网络请求、展示个表单,那没必要上来就 Worker。并发能力不是装饰品,用早了反而增加复杂度。
但只要你发现页面卡顿来自 CPU 计算,而不是网络等待、组件绘制或者数据库查询,那就该考虑把计算拆出去了。
结尾
TaskPool 和 Worker 这两个东西,真正用顺之后,会改变一点写 HarmonyOS 页面的习惯。
以前写页面,很容易把数据查询、规则计算、状态更新、错误处理都揉在一个组件里。短期确实快,后面只要数据量一上来,卡顿、竞态、脏状态就会一起冒出来。
现在我更愿意把页面当成"状态展示层":它发起任务,接收结果,处理用户反馈;至于那些费 CPU、耗时间、还可能失败的活儿,放到 TaskPool 或 Worker 后面去。
这不是为了追求所谓架构感。移动端开发很多时候就是这样,不卡的页面看起来没什么技术含量,真卡起来才知道前面省掉的边界,后面都要还。