文章目录
- 一、什么是SHAP
- 二、SHAP的数学原理与特点
- 三、常见实现算法
- [四、 典型使用场景](#四、 典型使用场景)
- 五、可视化及示例
-
- [1. SHAP值汇总图](#1. SHAP值汇总图)
- [2. SHAP依赖图](#2. SHAP依赖图)
- [3. SHAP力图](#3. SHAP力图)
- [4. SHAP瀑布图](#4. SHAP瀑布图)
- 六、总结
- 七、相关文章
一、什么是SHAP
许多高性能的机器学习模型(如深度神经网络、梯度提升树)常被称为"黑盒子",因为其内部决策逻辑难以被人类理解,而SHAP正是为此而生。
SHAP全称 Shapley Additive Explanations(基于Shapley值的可加性解释方法)。在机器学习场景中,它将模型的预测结果视为一场"合作游戏"的收益,而各个输入特征则是参与游戏的"玩家"。SHAP值通过计算每个特征对最终预测结果的边际贡献,来公平地分配预测结果,从而量化每个特征对单个预测的贡献大小和方向(是推动预测值上升还是下降)。
简单来说,SHAP值回答了关键的问题:为什么模型会做出这个预测?是哪些特征在起作用,以及它们具体起了多大的作用?
如:
每个特征对最终预测值贡献了多少?
(比如:模型预测房价100万,其中"房间数"让预测值增加了20万,"地段"增加了30万,"房龄"减少了5万)
为什么这个样本被预测为A而不是B?
(比如:为什么某人被拒贷?SHAP会显示"收入低"贡献了-0.3,"负债高"贡献了-0.4)
二、SHAP的数学原理与特点
SHAP值基于博弈论中的Shapley值,通过计算每个特征对预测结果的边际贡献来公平分配"收益"。它满足以下三个核心:
- 局部准确性:所有特征的SHAP值之和等于预测值与基准值(通常为所有样本的平均预测值)的差。即解释完全覆盖了模型的输出。
- 缺失性:如果一个特征对模型没有任何影响,它的SHAP值为0。
- 一致性:如果模型发生变化,使得某个特征的贡献变大(或保持不变),那么该特征的SHAP值也会增加(或保持不变)。这意味着解释结果是公平且可靠的。
此外,SHAP还有以下实用点:
- 模型通用性:SHAP是一个通用框架,理论上可以解释任何机器学习模型,无论是线性回归、随机森林,还是复杂的深度神经网络。它将模型视为一个黑盒,只关注其输入和输出。
- 局部与全局解释:SHAP既能进行局部解释,分析单个样本的预测原因(例如,解释为什么张三的贷款被拒);也能进行全局解释,洞察整个模型的行为模式和特征重要性(例如,了解在整个数据集中,哪个特征对信用评分影响最大)。
三、常见实现算法
虽然通用的SHAP计算复杂度较高,但针对特定类型的模型有高度优化的算法:
- Tree SHAP:专为树模型(如XGBoost、LightGBM、随机森林)设计,利用树结构和动态规划实现快速精确计算。
- Deep SHAP:针对深度学习模型,通过反向传播等技术提高解释效率。
- Kernel SHAP:一种模型无关的近似方法,适用于任何模型,通过加权线性回归来逼近SHAP值。
四、 典型使用场景
- 特征重要性分析(比传统feature importance更可靠)
- 识别特征对预测的正负影响方向(依赖图)
- 检测特征交互效应
- 模型调试、公平性审计(检查是否依赖敏感特征)
五、可视化及示例
SHAP提供了丰富的可视化工具,将复杂的数值结果转化为直观的图形,帮助不同背景的用户理解模型。以下使用模拟数据 + XGBoost模型 展示四种常用图形。
安装
bash
pip install shap环境准备与模拟数据生成
python
import shap
import numpy as np
import xgboost as xgb
import matplotlib.pyplot as plt
import pandas as pd
np.random.seed(10)
n_samples = 1000
X = np.random.rand(n_samples, 4)
y = 2 * X[:, 0] + 1.5 * X[:, 1] - 0.5 * X[:, 2] + 0.1 * X[:, 3] + np.random.normal(0, 0.1, n_samples)
model = xgb.XGBRegressor(n_estimators=50, max_depth=3, random_state=42)
model.fit(X, y)
feature_names = ["feature_A", "feature_B", "feature_C", "feature_D"]
X_df = pd.DataFrame(X, columns=feature_names)
explainer = shap.Explainer(model, X_df)
shap_values = explainer(X_df)1. SHAP值汇总图
功能:展示所有特征的整体重要性排序及其影响方向。
python
shap.summary_plot(shap_values, features=X_df, feature_names=feature_names)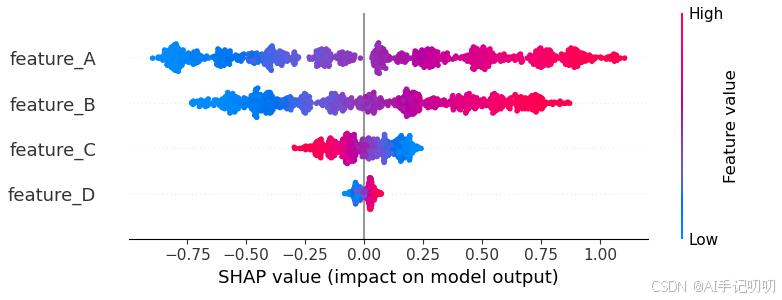
2. SHAP依赖图
功能:展示单个特征的原始值与其SHAP值之间的关系,揭示特征与模型输出的全局关系模式,包括非线性关系。
python
shap.plots.scatter(shap_values[:, "feature_A"])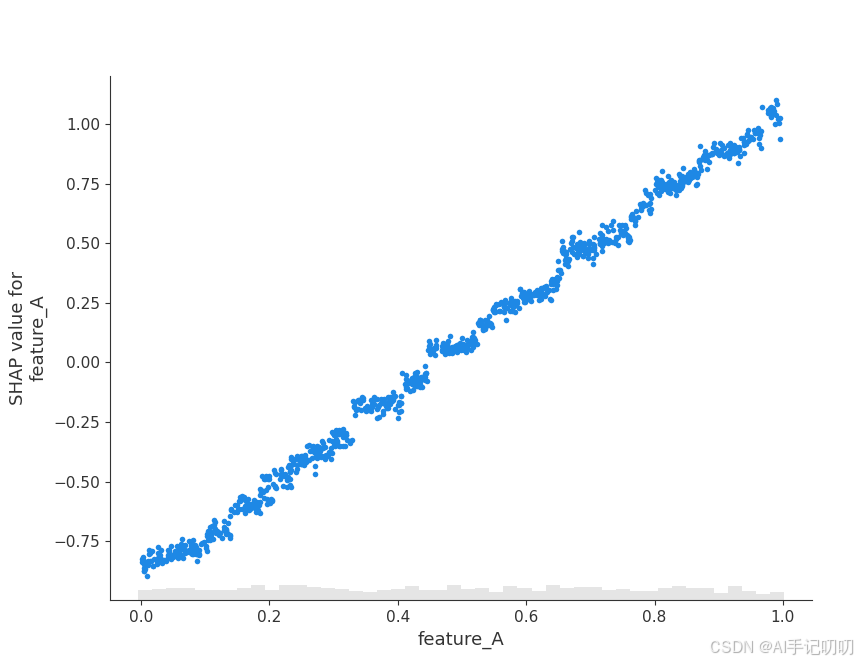
3. SHAP力图
功能:解释单个样本的预测结果,直观展示每个特征如何将基准值"推动"到最终的预测值。
python
# 保存前100个样本的整体力图
shap.plots.force(shap_values[0:100]) # 注意是切片
# 保存为HTML
shap.save_html('force_plot_100.html', shap.plots.force(shap_values[0:100]))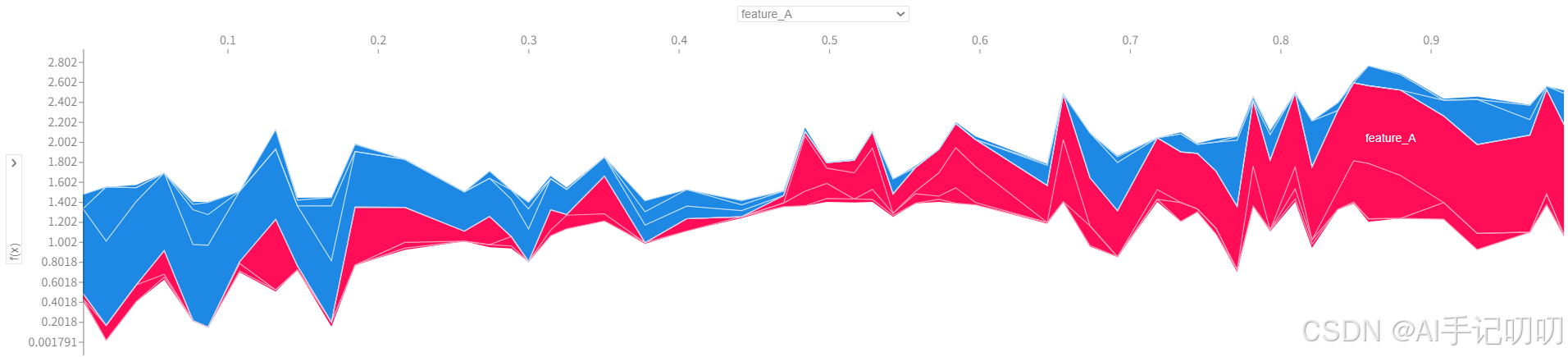
4. SHAP瀑布图
功能:以累积的方式,清晰地展示从基准值到最终预测值的完整"路径"。
python
shap.plots.waterfall(shap_values[0])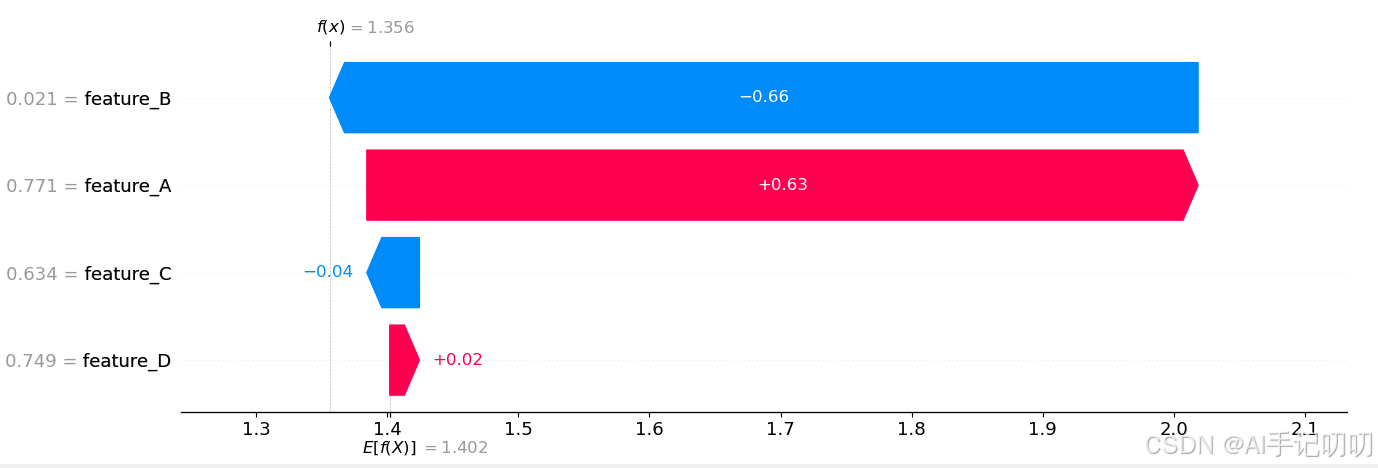
六、总结
SHAP是目前可解释性领域最受认可的框架之一。它不仅数学基础扎实,而且支持多种模型和丰富可视化。通过SHAP,我们可以:
- 理解单个预测的成因
- 发现模型的偏差或意外行为
- 增强模型在关键业务(如医疗、金融)中的可信度