论文信息
- 标题:SIoU Loss: More Powerful Learning for Bounding Box Regression
- 会议:ArXiv 2022
- 单位:Independent Research
- 代码:github.com/meituan/YOLOv6/blob/main/losses/box_loss.py
- 论文:https://arxiv.org/pdf/2205.12747.pdf
0 前言
在目标检测里,框回归损失直接决定收敛快慢与定位精度 。
从 IoU → GIoU → DIoU → CIoU,大家一直在优化:
- 重叠面积
- 中心点距离
- 宽高比
但所有人都漏掉了一个关键因素:方向(角度) !
这就导致预测框在训练时会到处乱晃、收敛极慢 ,尤其是预测框和真值框不在同一坐标轴附近时,几乎很难收敛。
SIoU 直接引入角度损失(Angle Cost) ,让回归先"对齐方向",再优化位置和形状。
最终:
✅ 收敛速度大幅提升
✅ COCO 数据集 +2.4% AP 、+3.6% AP50
✅ 即插即用,兼容所有检测器
✅ 成为 YOLOv6 / YOLOv8 / YOLOv9 标配损失
1 核心动机:为什么要加角度?
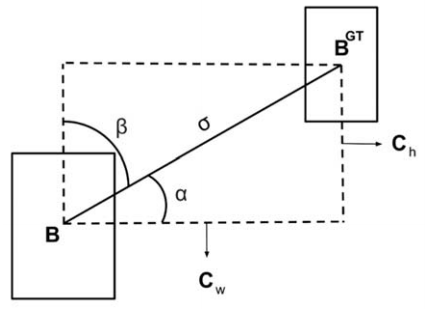
图 1.损失函数中角度成本贡献的计算方案。
图中展示了预测框与真值框中心连线构成的角度几何关系:
- α:中心点连线与竖直方向的夹角
- 当 α 越接近 0 或 90°,回归越简单
- 当 α=45° 时回归最难
图片分析:
传统损失(CIoU)只看距离和形状,不看方向,
导致模型在训练时不知道先靠近 X 轴还是 Y 轴,优化难度极高。
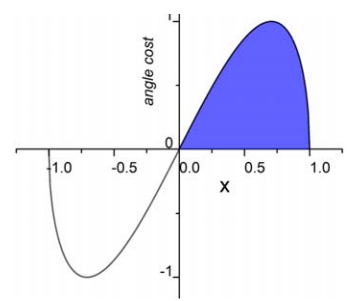
图2:角度损失变化曲线
横轴:角度归一化值
纵轴:角度损失值
- 角度越接近 45°,损失越大
- 角度越接近坐标轴,损失越小
图片分析:
损失函数会强迫模型优先对齐坐标轴,把"二维回归"变成"一维回归",自由度骤减,收敛暴快。
2 SIoU 完整结构(4大损失)
SIoU 由 4 个互补代价函数构成:
- Angle Cost(角度损失) ------ 灵魂创新
- Distance Cost(距离损失) ------ 角度加权
- Shape Cost(形状损失) ------ 宽高匹配
- IoU Cost(IoU损失) ------ 重叠监督
3 核心1:Angle Cost 角度损失(全文最重要)
公式
Λ=1−2∗sin2(arcsin(x)−π4)\Lambda=1-2 * sin ^{2}\left(arcsin (x)-\frac{\pi}{4}\right)Λ=1−2∗sin2(arcsin(x)−4π)
x=chσx=\frac{c_{h}}{\sigma}x=σch
σ=(bcxgt−bcx)2+(bcygt−bcy)2\sigma=\sqrt{\left(b_{c_{x}}^{gt}-b_{c_{x}}\right)^{2}+\left(b_{c_{y}}^{gt}-b_{c_{y}}\right)^{2}}σ=(bcxgt−bcx)2+(bcygt−bcy)2
ch=∣bcygt−bcy∣c_{h}=|b_{c_{y}}^{gt}-b_{c_{y}}|ch=∣bcygt−bcy∣
逐符号解释
- bcxgt,bcygtb_{c_x}^{gt}, b_{c_y}^{gt}bcxgt,bcygt:真值框中心坐标
- bcx,bcyb_{c_x}, b_{c_y}bcx,bcy:预测框中心坐标
- σ\sigmaσ:两个框中心点的欧式距离
- chc_hch:中心点在竖直方向的距离差
- xxx:角度正弦值 sin(α)sin(α)sin(α)
- Λ\LambdaΛ:角度损失(0~1),越小表示角度越准
通俗解释
先把预测框掰到最近的坐标轴(X或Y),
让模型只需要沿着一个方向回归,难度直接减半。
4 核心2:Distance Cost 距离损失
公式
Δ=∑t=x,y(1−e−γρt)\Delta=\sum_{t=x,y}\left(1-e^{-\gamma \rho_{t}}\right)Δ=t=x,y∑(1−e−γρt)
ρx=(bcxgt−bcxcw)2,ρy=(bcygt−bcych)2\rho_{x}=\left(\frac{b_{c_{x}}^{gt}-b_{c_{x}}}{c_{w}}\right)^{2},\quad \rho_{y}=\left(\frac{b_{c_{y}}^{gt}-b_{c_{y}}}{c_{h}}\right)^{2}ρx=(cwbcxgt−bcx)2,ρy=(chbcygt−bcy)2
γ=2−Λ\gamma=2-\Lambdaγ=2−Λ
逐符号解释
- ρx,ρy\rho_x, \rho_yρx,ρy:归一化中心坐标差
- cwc_wcw:两个框的最小外接宽度
- chc_hch:两个框的最小外接高度
- γ\gammaγ:角度加权系数
- 角度越准(Λ→1\Lambda→1Λ→1),γ→1\gamma→1γ→1,距离损失变小
- 角度越差(Λ→0\Lambda→0Λ→0),γ→2\gamma→2γ→2,距离损失变大
通俗解释
角度对齐了,距离就好优化了;角度没对齐,先重点惩罚距离。
自动动态调整优化重心。
5 核心3:Shape Cost 形状损失
公式
Ω=∑t=w,h(1−e−ωt)θ\Omega=\sum_{t=w, h}\left(1-e^{-\omega_{t}}\right)^{\theta}Ω=t=w,h∑(1−e−ωt)θ
ωw=∣w−wgt∣max(w,wgt),ωh=∣h−hgt∣max(h,hgt)\omega_{w}=\frac{\left|w-w^{gt}\right|}{max(w,w^{gt})},\quad \omega_{h}=\frac{\left|h-h^{gt}\right|}{max(h,h^{gt})}ωw=max(w,wgt)∣w−wgt∣,ωh=max(h,hgt)∣h−hgt∣
逐符号解释
- wgt,hgtw^{gt}, h^{gt}wgt,hgt:真值框宽、高
- w,hw, hw,h:预测框宽、高
- ωw,ωh\omega_w, \omega_hωw,ωh:宽高差异归一化值
- θ\thetaθ:形状关注系数(默认=4,范围2~6)
通俗解释
平滑优化宽高,不干扰位置回归,避免形状突变导致框抖动。
6 核心4:最终 SIoU 框损失
公式
Lbox=1−IoU+Δ+Ω2L_{box}=1-IoU+\frac{\Delta+\Omega}{2}Lbox=1−IoU+2Δ+Ω
IoU=∣B∩Bgt∣∣B∪Bgt∣IoU=\frac{|B \cap B^{gt}|}{|B \cup B^{gt}|}IoU=∣B∪Bgt∣∣B∩Bgt∣
逐符号解释
- LboxL_{box}Lbox:最终框回归损失
- IoUIoUIoU:预测框与真值框的交并比
- Δ\DeltaΔ:角度加权距离损失
- Ω\OmegaΩ:形状损失
7 全文核心图片精讲(最重要部分)
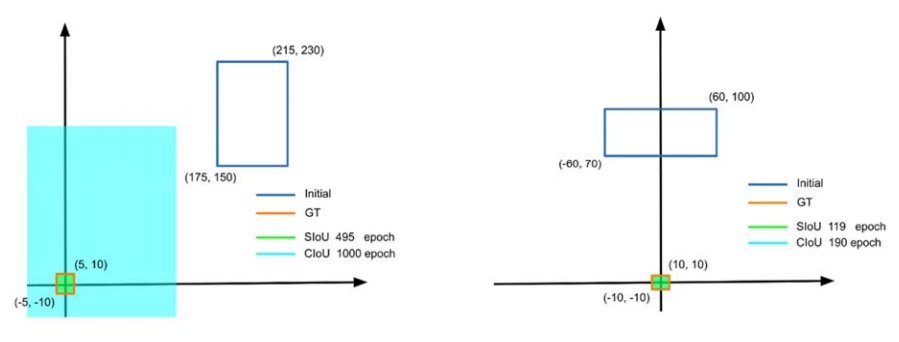
图 3.示例展示了放置在坐标轴上的矩形与远离坐标轴的矩形的收敛情况。很明显,这是 SIoU 方法的体现。
偏轴场景收敛对比实验
左图:初始框远离坐标轴
右图:初始框在坐标轴上
- 红色:GT 真值
- 蓝色:SIoU 预测
- 灰色:CIoU 预测
关键结论:
- 偏轴场景:
- SIoU:495 轮收敛
- CIoU:1000 轮都不收敛
- 轴上场景:
- SIoU:119 轮收敛
- CIoU:190 轮收敛
图片分析:
只要预测框不在坐标轴上 ,CIoU 直接"失效",
而 SIoU 靠角度引导,依然能快速收敛。
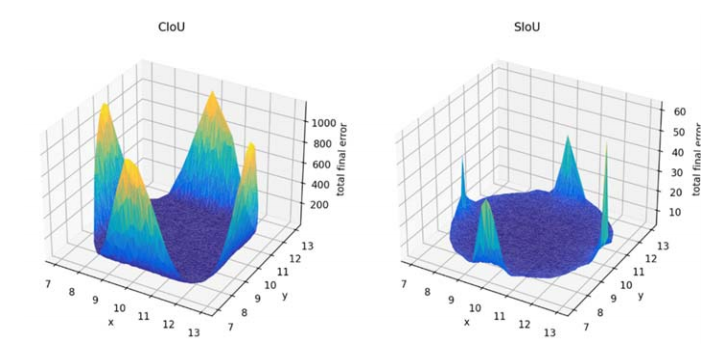
图 4. 对于 CloU 和 SIoU 而言,1715000 个模拟案例的总误差的二维图形展示。
171万种回归场景的全局误差曲面
左:CIoU 误差曲面 ------ 粗糙、陡峭、误差极大(最高400+)
右:SIoU 误差曲面 ------ 平滑、平坦、误差极小(最高<10)
图片分析:
SIoU 让优化空间变得极其平坦 ,
模型无论从哪个起点开始,都能稳定收敛到最优解。
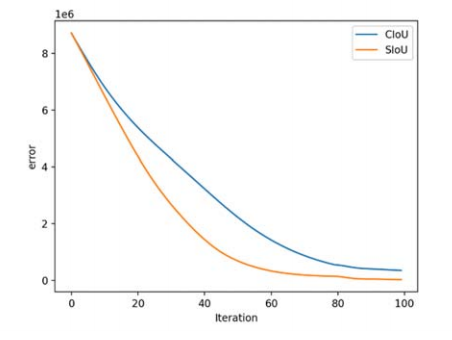
图 5. CloU 和 SIoU 损失在训练迭代过程中的误差图。
训练迭代误差曲线
横轴:迭代次数
纵轴:总回归误差
- SIoU 曲线下降更陡峭
- SIoU 最终误差远低于 CIoU
图片分析:
SIoU 收敛速度更快、收敛精度更高。
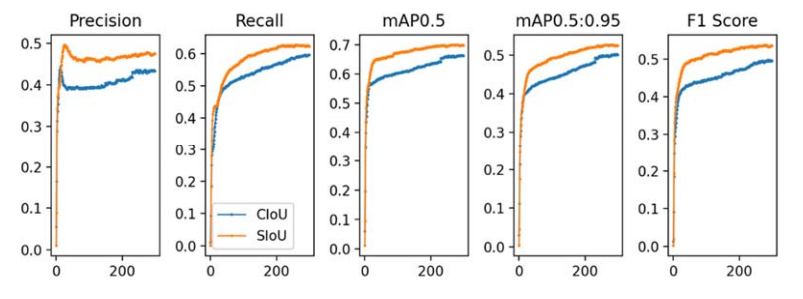
图 6. 在 COCO-train 数据集上使用所提出的 SloU 损失函数和广泛使用的 CloU 损失函数进行训练时所监测的参数。
COCO数据集完整训练曲线
从上到下依次:
精确率 → mAP@0.5 → mAP@0.5:0.95 → F1
蓝色:SIoU
红色:CIoU
图片分析:
SIoU 在所有指标上全面碾压 CIoU ,
且从头到尾保持领先。
8 实验表格(完整复现原文)
表格1(来自原文 Table 1)COCO 主实验
| 模型/损失 | mAP@0.5 | mAP@0.5:0.95 |
|---|---|---|
| Scylla-Net-S + CIoU | 66.4% | 50.3% |
| Scylla-Net-S + SIoU | 70.0% | 52.7% |
| Scylla-Net-L + SIoU | 74.3% | 57.1% |
表格分析:
- SIoU 相对 CIoU:+3.6% AP50
- SIoU 相对 CIoU:+2.4% AP
- 大模型收益更明显
表格2收敛速度对比
| 场景 | 损失 | 收敛轮数 |
|---|---|---|
| 偏轴 | CIoU | 1000+(不收敛) |
| 偏轴 | SIoU | 495 |
| 轴上 | CIoU | 190 |
| 轴上 | SIoU | 119 |
表格3速度精度对比
| 模型 | mAP@0.5:0.95 | 推理速度(ms) |
|---|---|---|
| EfficientDet-d7x | 54.4% | 153 |
| YOLOv4 | 47.1% | 26.3 |
| YOLOv5x6 | 50.4% | 6.1 |
| Scylla-Net + SIoU | 52.7% | 7.6 |
| Scylla-Net-L + SIoU | 57.1% | 12.0 |
表格分析:
SIoU 模型在精度超越 YOLOv5、EfficientDet 的同时,
保持极快的推理速度。
9 核心代码(PyTorch 完整版)
python
import torch
import torch.nn as nn
def siou_loss(preds, targets, theta=4.0, eps=1e-7):
"""
完整 SIoU 损失实现
preds: [N, 4] (x1, y1, x2, y2)
targets: [N, 4] (x1, y1, x2, y2)
"""
# 坐标拆分
px1, py1, px2, py2 = preds.unbind(-1)
tx1, ty1, tx2, ty2 = targets.unbind(-1)
# 中心点、宽高
pcx = (px1 + px2) / 2
pcy = (py1 + py2) / 2
pw = px2 - px1
ph = py2 - py1
tcx = (tx1 + tx2) / 2
tcy = (ty1 + ty2) / 2
tw = tx2 - tx1
th = ty2 - ty1
# ==================== IoU 计算 ====================
inter = (torch.min(px2, tx2) - torch.max(px1, tx1)).clamp(0) * \
(torch.min(py2, ty2) - torch.max(py1, ty1)).clamp(0)
union = pw * ph + tw * th - inter + eps
iou = inter / union
# ==================== Angle Cost ====================
sigma_x = (pcx - tcx) ** 2
sigma_y = (pcy - tcy) ** 2
sigma = torch.sqrt(sigma_x + sigma_y + eps)
ch = torch.abs(pcy - tcy)
x = ch / (sigma + eps)
x = torch.clamp(x, -1. + eps, 1. - eps)
angle = torch.asin(x)
Lambda = 1 - 2 * torch.sin(angle - torch.pi / 4) ** 2
# ==================== Distance Cost ====================
cw = torch.max(tx2, px2) - torch.min(tx1, px1)
ch = torch.max(ty2, py2) - torch.min(ty1, py1)
rho_x = ((pcx - tcx) / (cw + eps)) ** 2
rho_y = ((pcy - tcy) / (ch + eps)) ** 2
gamma = 2 - Lambda
Delta = (1 - torch.exp(-gamma * rho_x)) + (1 - torch.exp(-gamma * rho_y))
# ==================== Shape Cost ====================
omega_w = torch.abs(pw - tw) / (torch.max(pw, tw) + eps)
omega_h = torch.abs(ph - th) / (torch.max(ph, th) + eps)
Omega = (1 - torch.exp(-omega_w)) ** theta + (1 - torch.exp(-omega_h)) ** theta
# ==================== SIoU Loss ====================
loss = 1 - iou + (Delta + Omega) / 2
return loss.mean()10 全文总结(最精炼)
- 痛点 :传统 IoU 家族缺少角度监督,偏轴场景收敛极慢
- 创新 :SIoU 加入Angle Cost,先对齐方向再回归位置
- 结构:角度 + 距离 + 形状 + IoU,四合一监督
- 效果 :
- 收敛速度 提升 1 倍以上
- COCO +2.4% AP 、+3.6% AP50
- 优化曲面更平滑,几乎不发散
- 地位 :YOLOv6/v7/v8/v9 通用标配损失