两个让大模型"说谎"的根本原因
用过大模型的人都遇到过这两种情况:
情况一:知识截止
yaml
你:我们公司 Q1 的销售数据怎么样?
GPT:抱歉,我的训练数据截止到 2024 年初,无法获取您公司的内部数据。情况二:幻觉
ini
你:LangChain 的 RunnablePassthrough 怎么用?
GPT:RunnablePassthrough 可以通过调用 .with_config(pass_through=True) 来启用...
(这个参数根本不存在)这两个问题有同一个根源:大模型的知识被冻结在训练数据里了。
训练完成的那一刻,模型的"记忆"就定格了。它不知道今天发生了什么,不知道你的内部文档说了什么,更不会主动去查资料------它只能凭记忆回答,记忆里没有的,要么说不知道,要么"创造"一个看起来合理的答案。
这就是幻觉的根源:模型在用流利的语言填补它的知识空白。
三种解决方案的对比
面对这个问题,工程上有三条路:
| 方案 | 原理 | 适合场景 | 代价 |
|---|---|---|---|
| 微调(Fine-tuning) | 用新数据重新训练,把知识"烧"进参数 | 固定领域的语言风格、输出格式 | 成本高、更新慢、对事实记忆效果有限 |
| 长上下文(Long Context) | 把所有资料塞进 Prompt,一次性送入 | 文档量小、一次性查询 | Token 成本指数级增长、超长上下文推理质量下降 |
| RAG | 查询时动态检索相关内容,注入 Prompt | 知识库大、需要实时更新 | 需要额外的检索基础设施 |
一个容易混淆的点:微调不擅长注入新事实。
微调改变的是模型的行为模式和语言风格,而不是在参数里"存储一本书"。实验表明,用特定问答对微调后,模型在相关问题上的准确率提升有限,而且一旦训练数据有错误,模型会自信地重复错误答案。
RAG 的核心优势是把"知道什么"和"怎么说"分离:
- 知识存在外部数据库里,随时可以更新
- 模型只负责理解和生成,不用记忆具体事实
什么时候用长上下文而不是 RAG? 当文档总量在 10 万 Token 以内、一次性分析(不是持续查询)、且 API 成本可以接受时,直接用长上下文反而更简单。Claude 和 Gemini 的超长上下文能力让"把整本书塞进去"变得可行。但对于企业知识库这种场景------几千份文档、持续更新、多用户并发------RAG 依然是更合理的架构。
RAG 是什么:一次考试的类比
RAG = Retrieval-Augmented Generation(检索增强生成)。
最直观的理解:把闭卷考试改成开卷考试。
闭卷考试(纯 LLM):考生只能凭记忆作答,记不住的就瞎猜。
开卷考试(RAG):考生可以翻书,但仍然需要自己理解题目、找到相关内容、组织答案。书就是外部知识库,翻书的动作就是检索。
这个类比揭示了 RAG 的两个关键特性:
- 知识不在模型里:知识存在外部,可以随时替换和更新
- 模型负责理解和生成:检索到内容后,还是需要模型来"读懂"并组织语言
RAG 的完整流程
RAG 分两个独立阶段:索引阶段 (一次性离线)和查询阶段(每次请求实时执行)。
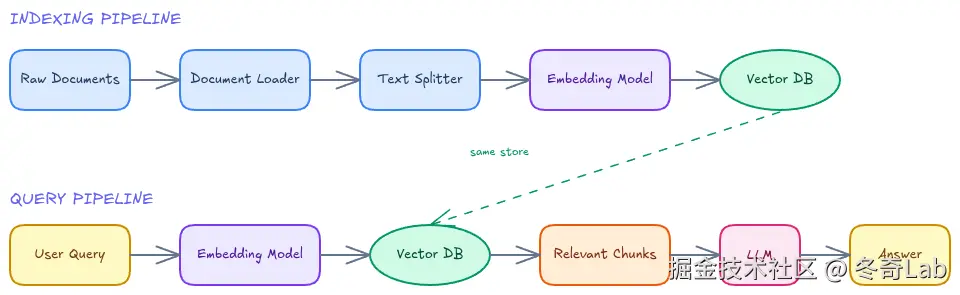
图:RAG 两阶段架构------上方为离线索引流程,下方为实时查询流程,共享同一个 Vector DB
索引阶段(Indexing Pipeline)
这一阶段在收到用户查询之前完成,是一次性的预处理。
原始文档 → 文档加载 → 文本分块 → 向量化 → 存入向量数据库第一步:文档加载
把各种格式的原始内容转换为纯文本。PDF、Word、Markdown、网页、代码......不同格式有不同的解析挑战(PDF 里的表格、图片就很头疼)。
第二步:文本分块(Chunking)
把长文档切成小块。这一步的策略对最终效果影响很大------块太大,检索精度下降;块太小,语义不完整。(这是后续文章的重点,这里先理解"为什么要切"即可)
第三步:向量化(Embedding)
用 Embedding 模型把每个文本块转换成一个高维向量。这个向量捕捉了文本的语义信息------语义相似的文本,对应的向量在空间中也相近。
第四步:存入向量数据库
把所有向量连同原始文本存入支持相似度检索的向量数据库(Chroma、Qdrant、Weaviate 等)。
查询阶段(Query Pipeline)
每次用户提问时实时执行。
用户问题 → 向量化 → 相似度检索 → 召回相关块 → 组装 Prompt → LLM 生成 → 返回答案第一步:查询向量化
用同一个 Embedding 模型把用户问题也转成向量。
第二步:相似度检索
在向量数据库中找出与查询向量最相似的 Top-K 个文本块。相似度 = 向量空间中的距离(余弦相似度等)。
第三步:组装 Prompt
把检索到的文本块和用户问题组合成一个完整的 Prompt,送入 LLM。典型格式:
css
你是一个知识助手。请根据以下参考内容回答用户问题。
参考内容:
[检索到的文本块1]
[检索到的文本块2]
...
用户问题:[原始问题]
请基于参考内容回答,如果参考内容中没有相关信息,请说明。第四步:LLM 生成
LLM 基于提供的上下文生成答案,而不是凭空想象。
实战:100 行手写最小 RAG
不用任何框架,只用 OpenAI API,从零实现一个能跑通的 RAG。目的是让你看清每一步在做什么,而不是被框架的抽象层遮住细节。
python
"""
最小 RAG 实现 ------ 不依赖任何框架,只用 OpenAI API
演示 RAG 的完整流程:索引 + 查询
"""
import json
import numpy as np
from openai import OpenAI
client = OpenAI() # 需要设置 OPENAI_API_KEY 环境变量
# ─────────────────────────────────────────
# 模拟知识库:5 段技术文档
# ─────────────────────────────────────────
DOCUMENTS = [
"LangChain 是一个用于构建大语言模型应用的框架,提供链式调用、记忆管理、工具集成等能力。",
"向量数据库通过将文本转换为高维向量来实现语义搜索,常见的有 Chroma、Qdrant、Weaviate、Pinecone 等。",
"RAG(检索增强生成)通过在生成前检索相关文档,有效减少大模型的幻觉问题,提升回答准确性。",
"Embedding 模型将文本转换为固定维度的向量,语义相似的文本在向量空间中距离更近。",
"微调(Fine-tuning)通过在特定数据上重新训练模型来调整其行为,适合改变输出风格而非注入新知识。",
]
# ─────────────────────────────────────────
# 索引阶段:把文档转成向量存起来
# ─────────────────────────────────────────
def build_index(documents: list[str]) -> list[dict]:
"""
把每个文档转成向量,返回 [{text, embedding}, ...]
生产环境中这些向量应该存入向量数据库
"""
print(f"正在为 {len(documents)} 个文档建立索引...")
index = []
for doc in documents:
response = client.embeddings.create(
model="text-embedding-3-small",
input=doc
)
embedding = response.data[0].embedding
index.append({"text": doc, "embedding": embedding})
print("索引建立完成!")
return index
def cosine_similarity(vec_a: list[float], vec_b: list[float]) -> float:
"""计算两个向量的余弦相似度,值越大越相似(范围 -1 到 1)"""
a = np.array(vec_a)
b = np.array(vec_b)
return float(np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b)))
# ─────────────────────────────────────────
# 查询阶段:检索 + 生成
# ─────────────────────────────────────────
def retrieve(query: str, index: list[dict], top_k: int = 2) -> list[str]:
"""
把查询转成向量,找出最相似的 top_k 个文档
"""
# 查询向量化(用同一个 embedding 模型)
response = client.embeddings.create(
model="text-embedding-3-small",
input=query
)
query_embedding = response.data[0].embedding
# 计算查询与每个文档的相似度
scored = []
for doc in index:
score = cosine_similarity(query_embedding, doc["embedding"])
scored.append((score, doc["text"]))
# 按相似度降序排列,取 top_k
scored.sort(key=lambda x: x[0], reverse=True)
return [text for _, text in scored[:top_k]]
def generate(query: str, context_docs: list[str]) -> str:
"""
把检索到的文档和用户问题组装成 Prompt,调用 LLM 生成答案
"""
context = "\n".join([f"- {doc}" for doc in context_docs])
prompt = f"""你是一个知识助手。请根据以下参考内容回答用户问题。
如果参考内容中没有相关信息,请明确说明,不要编造。
参考内容:
{context}
用户问题:{query}
回答:"""
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": prompt}]
)
return response.choices[0].message.content
def rag_query(query: str, index: list[dict]) -> str:
"""完整的 RAG 查询流程"""
print(f"\n问题:{query}")
# Step 1: 检索相关文档
docs = retrieve(query, index, top_k=2)
print(f"检索到 {len(docs)} 个相关文档:")
for i, doc in enumerate(docs, 1):
print(f" [{i}] {doc[:50]}...")
# Step 2: 生成答案
answer = generate(query, docs)
print(f"\n答案:{answer}")
return answer
# ─────────────────────────────────────────
# 运行演示
# ─────────────────────────────────────────
if __name__ == "__main__":
# 建立索引(实际项目中只需要做一次)
index = build_index(DOCUMENTS)
# 测试几个问题
rag_query("什么是向量数据库?", index)
rag_query("RAG 和微调有什么区别?", index)
rag_query("Python 的 GIL 是什么?", index) # 知识库里没有,测试拒答运行效果:
erlang
正在为 5 个文档建立索引...
索引建立完成!
问题:什么是向量数据库?
检索到 2 个相关文档:
[1] 向量数据库通过将文本转换为高维向量来实现语义...
[2] Embedding 模型将文本转换为固定维度的向量,语义相...
答案:向量数据库是一种通过将文本转换为高维向量来实现语义
搜索的数据库系统,常见的有 Chroma、Qdrant、Weaviate、
Pinecone 等...
问题:Python 的 GIL 是什么?
检索到 2 个相关文档:
[1] LangChain 是一个用于构建大语言模型应用的框架...
[2] 微调(Fine-tuning)通过在特定数据上重新训练...
答案:根据提供的参考内容,我无法回答关于 Python GIL 的
问题,参考内容中没有相关信息。注意最后一个问题------知识库里没有 GIL 的信息,LLM 明确说"无法回答",而不是编造答案。这就是 RAG 控制幻觉的机制:通过 Prompt 中的约束指令,让模型只基于检索内容回答。
这个实现的局限性
上面 100 行代码演示了 RAG 的完整流程,但它有几个明显的问题:
| 问题 | 原因 | 工程解法 |
|---|---|---|
| 向量存在内存里,重启就没了 | 没有持久化 | 使用向量数据库(Chroma/Qdrant) |
| 文档太长直接传入会超限 | 没有分块 | Text Splitter 策略(下一篇) |
| 只按向量相似度检索,关键词匹配差 | 纯向量检索 | 混合检索(系列后续) |
| 没有任何质量评估 | 无 Eval | RAGAS 评估框架(系列后续) |
这些局限对应的就是后续文章要解决的问题。
小结
这篇文章解决了三个核心问题:
- 为什么需要 RAG:LLM 的知识截止和幻觉问题,本质是知识被冻结在参数里
- RAG 是什么:查询时动态检索外部知识,注入 Prompt,让 LLM 基于证据回答
- RAG vs 其他方案:微调改行为、长上下文适合小文档、RAG 适合大规模持续更新的知识库
参考资料
- Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks --- RAG 原始论文(Lewis et al., 2020)
- OpenAI Embeddings 文档
- LangChain RAG 教程