作者:Chengxu Liu1 Lu Qi2,3 Jinshan Pan4 Xueming Qian1 Ming-Hsuan Yang5
机构:1School of Software Engineering, Xi'an Jiaotong University 2Wuhan University
3 Insta360 4Nanjing University of Science and Technology 5University of California, Merced
来源会议:IEEE/CVF International Conference on Computer Vision, ICCV 2025
会议时间:2025年10月19日---10月23日
1. 研究目标,过去以及本文使用的方法,优势及其创新点
1.1 研究目标
本文研究的是非配对图像去雾任。
所谓非配对去雾,是指训练数据中有两类图像
有雾图像集合:I_h
清晰图像集合:I_c
但是二者不是一一对应的。也就是说,不存在严格的:某一张有雾图像对应同一场景下的清晰 GT 图像这种数据形式更接近真实应用,因为真实世界中很难对同一个场景同时采集"有雾图"和"无雾图。
所以本文目标是:在没有成对 GT 监督的情况下,充分利用非配对清晰图像中的有效信息,提高去雾模型在合成数据和真实数据上的泛化能力。
1.2 过去常用方法
论文中主要回顾了三类去雾方法。
1.2.1 传统先验方法
早期方法通常基于人为设计的图像先验,例如:
DCP:Dark Channel Prior,暗通道先验
CAP:Color Attenuation Prior,颜色衰减先验
Color-lines / Haze-lines
这些方法依赖对有雾图像统计规律的观察,不需要大量训练数据,但问题是:先验假设不一定适用于所有场景。比如强光、白色物体、天空区域、夜景等场景会破坏先验假设,导致去雾不稳定。
1.2.2 有监督深度学习方法
有监督方法使用成对的:有雾图像 Hazy Image 清晰图像 Ground Truth进行训练。典型方法包括 DehazeNet、MSCNN、AOD-Net、FFANet、MSBDN 等。
这类方法的优点是指标通常较高,尤其在合成测试集上效果明显。但问题也很突出:训练数据多为合成雾,与真实雾存在明显域差异。因此模型可能在 SOTS 等合成测试集上表现很好,但迁移到真实雾图时会出现颜色偏移、过度增强、局部伪影等问题。
1.2.3 非监督 / 非配对方法
非配对去雾方法主要包括:
CycleGAN-like 方法
Contrastive Learning-like 方法
Pseudo-label 方法
其中 CycleGAN 类方法建立有雾域和清晰域之间的循环映射,使用对抗损失和循环一致性损失进行训练。它的问题是:有雾图像和清晰图像之间并不一定存在严格的一一双射关系,尤其不同浓度的雾会导致优化不对称。
对比学习类方法,如 UCL-Dehaze、ODCR 等,通过构造正负样本对,最大化去雾结果与清晰域之间的互信息。但论文认为这类方法存在一个重要缺陷:容易引入与雾无关的内容信息,同时忽略了雾退化在频域中的特殊表现。
1.3 本文使用的方法
本文提出 FrDiff:Frequency Domain-Based Diffusion Model for Unpaired Image Dehazing。
它不是直接在 RGB 空间生成清晰图像,而是从频域重建的角度处理非配对去雾任务。方法核心由三部分组成:
-
ARE:Amplitude Residual Encoder,幅度残差编码器
-
DM:Diffusion Model,扩散模型
-
PCM:Phase Correction Module,相位校正模块
其中,ARE 用于从有雾图像和非配对清晰图像中提取**幅度残差z。**扩散模型学习如何从高斯噪声中重建这个幅度残差;PCM 则利用幅度残差信息进一步修正相位谱,减少伪影。
1.4 本文优势与创新点
本文的创新点可以概括为四个方面。
第一,首次将扩散模型引入非配对图像去雾任务
论文强调,FrDiff 是第一个将扩散模型用于非配对图像去雾的工作。以往扩散模型多用于有监督图像恢复、超分辨率、去模糊、修复等任务,而本文将其引入非配对去雾,并不是直接生成图像,而是生成频域幅度残差。
这点很关键,因为直接用扩散模型生成清晰图像容易出现:计算量大,颜色异常,细节伪影,而本文只让扩散模型重建较低复杂度的幅度残差,因此训练和推理更轻量。
第二,提出 ARE 提取幅度残差
ARE 的作用是把有雾图像的幅度谱分布对齐到清晰图像的幅度谱分布,然后计算二者之间的残差:z = A'_h - A_h其中:
A_h:有雾图像的幅度谱
A_c:清晰图像的幅度谱
A'_h:对齐到清晰域分布后的有雾幅度谱
z:幅度残差
ARE 的优势是:它不引入额外可学习参数,而是通过均值和标准差做分布对齐。这使得它既可以利用清晰域信息,又尽量避免引入清晰图像中的内容结构。
第三,提出 PCM 修正相位谱
一般认为幅度谱更多反映亮度、对比度、颜色等低频或全局统计信息,而相位谱更多保留结构、边缘和纹理信息。本文认为,严重雾霾不仅影响幅度,也会遮挡结构细节,导致相位谱中的纹理信息不够可靠。
因此作者提出 PCM,让幅度残差 z 生成一个注意力权重,再作用于相位谱,得到相位残差:
ω = SoftMax(GAP(z))
P_res = Conv(ω ⊗ P_h)
P_out = P_h + P_res
这样做的目的,是用雾强度相关的幅度信息指导相位修复,减少去雾后的伪影。
第四,采用两阶段训练策略
FrDiff 分为两个阶段训练:
Stage 1:训练 ARE + 去雾网络,让网络学习如何利用真实幅度残差 z 去雾
Stage 2:训练扩散模型,使其从高斯噪声中重建幅度残差 z
推理阶段不再需要清晰图像输入,而是:
输入有雾图像 I_h
提取其幅度谱 A_h
扩散模型从高斯噪声生成幅度残差 z_hat
去雾网络利用 z_hat 完成去雾
这使得模型在测试时可以只输入单张有雾图像。
2. 文中算法主要思想
2.1 总体思想
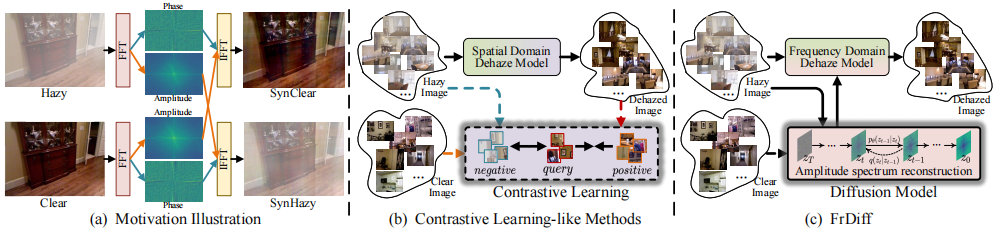 (a) 频域中雾霾降解特性的示意图。雾霾降解效果可通过振幅谱的交换实现传递。
(a) 频域中雾霾降解特性的示意图。雾霾降解效果可通过振幅谱的交换实现传递。
(b) 对比学习类方法通过构建正样本与负样本对,最大化清晰图像与雾霾图像之间的互信息。
(c) 我FrDiff模型在训练过程中从未配对数据中学习清晰图像的振幅谱,并在推理阶段对其进行重建。
论文在图 2 中展示了:交换有雾图像和清晰图像的幅度谱后,雾霾外观会发生明显变化,说明雾相关退化主要与幅度谱有关;而相位谱更多保留结构信息。
换句话说,本文不是简单地让网络学习:Hazy RGB 转为Clear RGB ,而是转化为:有雾图像的频域幅度谱 → 清晰图像分布下的幅度谱这样可以降低非配对学习的难度
2.2 频域、幅度谱、相位谱是什么意思?
一张图像可以从空间域转换到频域。空间域就是我们平常看到的像素图像,而频域可以理解为把图像拆成不同频率成分。通过 FFT,可以得到复数形式的频域表示:
F = A · exp(jP)其中:A:Amplitude Spectrum,幅度谱 P:Phase Spectrum,相位谱
幅度谱
幅度谱主要反映:
亮度
颜色分布
对比度
整体雾霾强度
低频能量分布
雾霾通常会造成图像整体发白、对比度下降、颜色变淡,这些变化在频域中主要体现为幅度谱变化。因此本文认为:去雾的关键可以转化为幅度谱恢复问题。
相位谱
相位谱主要反映:
边缘
轮廓
纹理结构
空间位置关系
如果只改变幅度谱,图像整体颜色和对比度会变化;如果破坏相位谱,图像结构会严重变形。因此相位谱对于图像结构恢复非常重要。
本文的一个细节是:虽然相位谱通常较稳定,但在严重雾霾下,结构被遮挡,相位谱也会出现不可靠部分,所以作者额外设计了 PCM 修正相位谱。
2.3 FrDiff 总体结构
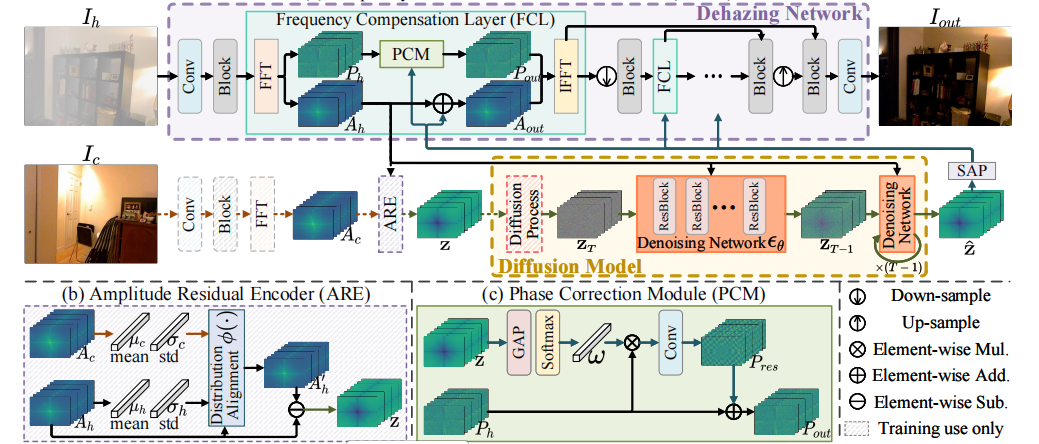 (a)FrDiff的整体架构,主要由去雾网络和扩散模型组成
(a)FrDiff的整体架构,主要由去雾网络和扩散模型组成
(b)振幅残差编码器(ARE)的结构,该模块可生成振幅残差以补偿模糊区域与清晰区域之间的间隙(c)相位校正模块(PCM)的结构,该模块通过注意力机制优化相位频谱,从而消除不必要的伪影
论文图 4 展示了 FrDiff 的整体结构。FrDiff 主要包括:
- Dehazing Network:去雾网络
- ARE:幅度残差编码器
- DM:扩散模型
- FCL:频率补偿层
- PCM:相位校正模块
整体流程可以理解为:
1.输入有雾图像 I_h 和非配对清晰图像 I_c
2.提取特征并做 FFT
3.得到有雾幅度谱 A_h 和清晰幅度谱 A_c
4.ARE根据得到的A_h和A_c计算幅度残差 z
5.先对 z 加噪得到 z_T,然后让扩散模型逐步去噪,重建出 z_hat. z_hat 输入FCL,用于补偿有雾图像的频域特征
6.z_hat同时输入 PCM,用于修正相位谱
7.IFFT(逆快速傅里叶变换) 回到空间域
8.去雾网络输出清晰图像I_out
2.4 ARE:幅度残差编码器
ARE 是本文最核心的模块之一。
它的目标不是直接生成完整清晰幅度谱,而是计算:
从有雾幅度谱到清晰幅度谱需要补偿多少
具体过程如下。
首先,输入有雾图像和非配对清晰图像,经过 FFT 得到:
A_h:有雾图像幅度谱
A_c:清晰图像幅度谱
然后分别计算它们的均值和标准差:
μ_h, σ_h:有雾幅度谱的均值和标准差
μ_c, σ_c:清晰幅度谱的均值和标准差
接着使用类似风格迁移中 AdaIN 的分布对齐方式:
A'_h = σ_c / σ_h · (A_h - μ_h) + μ_c
这一步的意思是:
把有雾图像的幅度谱分布调整到清晰图像幅度谱的统计分布。
最后得到幅度残差:
z = A'_h - A_h
这个 z 表示:
有雾幅度谱需要补偿多少,才能更接近清晰域幅度谱。
2.5 FCL:频率补偿层
FCL 是去雾网络内部用来接收幅度残差的模块。
核心操作是:A_out = A_h + z
也就是说,把 ARE 或扩散模型生成的幅度残差补偿到原始有雾幅度谱上,得到更接近清晰图像分布的幅度谱。
然后结合相位谱,通过 IFFT 回到空间域,继续由去雾网络恢复图像。
论文还采用多尺度 FCL,即在 U-Net 不同尺度的特征层都加入频域补偿。这样可以让浅层、深层特征都获得幅度残差的引导。
2.6 PCM:相位校正模块
PCM 的作用是修正相位谱,减少伪影。
为什么需要 PCM?因为幅度谱主要处理颜色、亮度和对比度,但图像结构、边缘和纹理更多依赖相位谱。严重雾霾会遮挡纹理,导致相位谱也受到影响。如果只修正幅度谱,可能仍然会出现局部纹理不清晰或伪影。
PCM 的流程是:
输入:相位谱 P_h 和幅度残差 z
↓
对 z 做 GAP,全局平均池化
↓
Softmax 得到权重向量 ω
↓
用 ω 调制相位谱 P_h
↓
卷积生成相位残差 P_res
↓
P_out = P_h + P_res
其中:
GAP:Global Average Pooling,全局平均池化
Softmax:归一化函数,使权重具有选择性
⊗:逐元素乘法
⊕:逐元素加法
可以把 PCM 理解为:
用幅度残差判断哪里雾更严重,再针对性地修正相位结构信息
这比普通 self-attention 更轻量,计算量更低。
2.7 扩散模型在本文中的作用
传统扩散模型通常是从高斯噪声逐步生成图像,例如:
Noise → Image
但本文没有让扩散模型直接生成清晰图像,而是让它生成:
Noise → Amplitude Residual z
这样做有两个好处:
-
幅度残差比完整图像更简单,扩散过程所需迭代次数更少
-
不直接生成图像,减少颜色异常和纹理伪影
论文中扩散模型的输入条件是有雾图像的幅度谱 A_h,目标是重建 ARE 提供的幅度残差 z。
训练第二阶段中,先对 z 加噪得到 z_T,然后让扩散模型逐步去噪,重建出 z_hat:
z → z_T → z_hat
推理时没有清晰图像,因此直接从高斯噪声 z_T 开始,在 A_h 条件引导下生成 z_hat,然后送入 FCL 辅助去雾。
2.8 两阶段训练流程
Stage One:幅度残差提取与去雾网络训练
输入:I_h:有雾图像 I_c:非配对清晰图像
通过 ARE 得到幅度残差 z,然后直接把 z 输入去雾网络。此时扩散模型不参与训练,目的是先让去雾网络学会如何利用真实幅度残差完成去雾。
由于没有成对 GT,不能使用严格像素级 L1/L2 损失。论文采用:
GAN loss
PatchNCE contrastive loss
用于让去雾结果接近清晰图像分布,同时保持内容结构。
Stage Two:扩散模型重建幅度残差
第二阶段训练扩散模型,让其学习从高斯噪声中生成幅度残差。
损失函数为:
L_s2 = L_s1 + λ_diff L_diff
L_diff = ||z - z_hat||_1
其中:
z:ARE 生成的幅度残差
z_hat:扩散模型重建的幅度残差
最终目的是让测试时即使没有清晰图像,扩散模型也能根据有雾图像条件生成合适的幅度补偿信息。
3. 实验结果
3.1 数据集
论文使用了多个常见去雾数据集,覆盖合成数据、人工真实雾数据和真实世界无 GT 数据。
RESIDE 数据集
RESIDE 包括多个子集
ITS:Indoor Training Set,13,990 对合成室内有雾/清晰图像
SOTS-Indoor:500 对合成室内测试图像
SOTS-Outdoor:500 对合成室外测试图像
HSTS-Synth:10 对合成有雾/清晰图像
HSTS-Real:10 张真实有雾图像,无 GT
URHI:超过 4,000 张真实有雾图像,无 GT
本文按照已有工作设置,使用 ITS 作为训练集,其余数据集作为测试集。
I-HAZE 数据集
I-HAZE 包含 35 对真实室内有雾/清晰图像,由专业雾生成器采集,属于人工真实雾数据。
Fattal's 数据集
Fattal's 数据集包含 31 张不同场景下的真实有雾图像,没有对应 GT。
3.2 评价指标
论文根据是否有 GT,采用不同指标。
有 GT 数据集
对于 SOTS-Indoor、SOTS-Outdoor、HSTS-Synth、I-HAZE,使用:
PSNR
SSIM
无 GT 真实数据集
对于 HSTS-Real、Fattal's、URHI,使用无参考图像质量评价指标:
FADE ↓
BRISQUE ↓
其中:
FADE 越低,表示图像残留雾越少
BRISQUE 越低,表示无参考感知质量越好
3.3 定量实验结果
合成和人工数据集结果
表 1 对比了 FrDiff 与有监督、无监督方法在多个数据集上的表现。
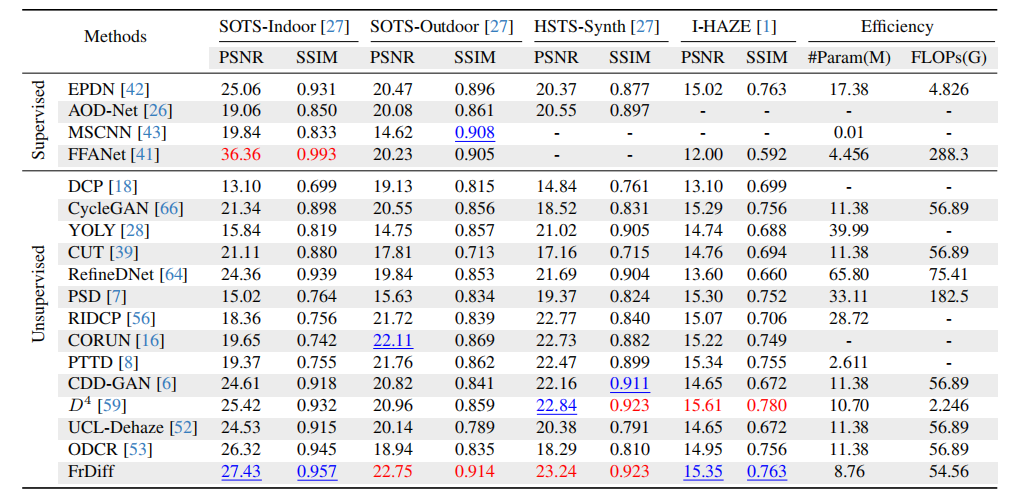 对SOTS-Indoor、SOTS-Outdoor、 HSTS -Synth和I-HAZE数据集进行定量比较。
对SOTS-Indoor、SOTS-Outdoor、 HSTS -Synth和I-HAZE数据集进行定量比较。
浮点运算次数是在尺寸为256×256的图像上计算得出的。红色和蓝色分别表示最佳性能和次佳性能。
FrDiff 在非监督方法中表现非常突出:
SOTS-Indoor:PSNR 27.43,SSIM 0.957
SOTS-Outdoor:PSNR 22.75,SSIM 0.914
HSTS-Synth:PSNR 23.24,SSIM 0.923
I-HAZE:PSNR 15.35,SSIM 0.763
其中,在 SOTS-Indoor 上,FrDiff 超过 ODCR、UCL-Dehaze、CDD-GAN、CycleGAN 等非配对方法。特别是 ODCR 的 SOTS-Indoor PSNR 为 26.32,而 FrDiff 达到 27.43,提升明显。
在 SOTS-Outdoor 上,FrDiff 达到 22.75 PSNR,高于大多数无监督方法。论文认为,这说明频域幅度重建比单纯对比学习更能抓住雾退化本质。效率方面,FrDiff 参数量为:8.76M FLOPs:54.56G
真实数据集结果
在 HSTS-Real、Fattal's 和 URHI 上,由于没有 GT,论文使用 FADE 和 BRISQUE。
表 2 中 FrDiff 的结果为:
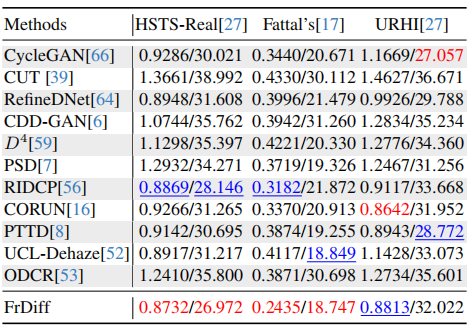 基于 HSTS -Real、Fattal和 URHI数据集的定量比较
基于 HSTS -Real、Fattal和 URHI数据集的定量比较
HSTS-Real:FADE 0.8732,BRISQUE 26.972
Fattal's:FADE 0.2435,BRISQUE 18.747
URHI:FADE 0.8813,BRISQUE 32.022
FrDiff 在 HSTS-Real 和 Fattal's 上表现最好,在 URHI 上也有较好结果。论文认为这说明 FrDiff 在真实复杂雾场景中具有较好泛化能力。
3.4 定性实验结果
SOTS-Indoor / SOTS-Outdoor 可视化
论文图 5 展示了合成测试集上的可视化结果。对比方法包括:

从论文描述看,FrDiff 在室内浓雾区域能够更彻底地去除雾,尤其在门内、墙面、天空等区域能够恢复更自然的亮度和颜色。其他方法往往存在残雾、色偏或对比度不足问题。
真实数据集可视化
论文图 6 展示了 HSTS-Real、Fattal's 和 URHI 上的真实场景结果。FrDiff 在远处重雾区域、文字区域和大面积复杂场景中表现较好,能够恢复更清晰的结构和更自然的视觉观感。
论文特别提到,在 URHI 示例中,FrDiff 能够恢复被雾影响的文字内容,说明其频域幅度补偿和相位修正机制对真实场景也有效。
3.5 消融实验
组件消融
表 3 显示完整模型结果为:
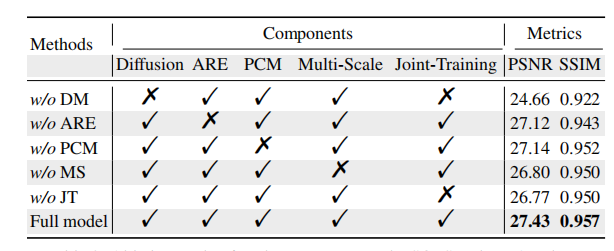 针对SOTS-Indoor数据集对各组件进行的消融实验
针对SOTS-Indoor数据集对各组件进行的消融实验
Full model:PSNR 27.43,SSIM 0.957
去掉不同模块后:
w/o DM:PSNR 24.66,SSIM 0.922
w/o ARE:PSNR 27.12,SSIM 0.943
w/o PCM:PSNR 27.14,SSIM 0.952
w/o Multi-Scale:PSNR 26.80,SSIM 0.950
w/o Joint-Training:PSNR 26.77,SSIM 0.950
其中,去掉 DM 后下降最大,PSNR 降低 2.77 dB,说明扩散模型重建幅度残差是本文性能提升的关键。
ARE 消融
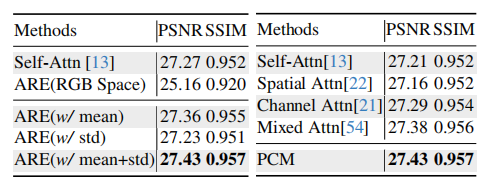 在ARE模块上做的消融实验
在ARE模块上做的消融实验
表 4 对 ARE 做了进一步分析:
Self-Attn:27.27 / 0.952
ARE(RGB Space):25.16 / 0.920
ARE(w/ mean):27.36 / 0.955
ARE(w/ std):27.23 / 0.951
ARE(w/ mean+std):27.43 / 0.957
这说明:
-
在频域中做 ARE 明显优于 RGB 空间
-
仅使用均值或标准差都有效
-
同时使用均值和标准差效果最好
这也支撑了论文关于"幅度分布对齐"的核心观点。
PCM 消融
表 5 对比了不同注意力机制:
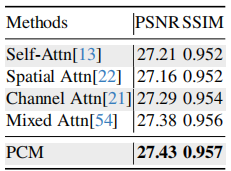 在PCM上做的消融研究
在PCM上做的消融研究
Self-Attn:27.21 / 0.952
Spatial Attn:27.16 / 0.952
Channel Attn:27.29 / 0.954
Mixed Attn:27.38 / 0.956
PCM:27.43 / 0.957
PCM 结构更简单,但性能最好,说明用幅度残差信息引导相位修正是有效的。
DM 消融
表 6 对比了不同幅度残差重建方式:
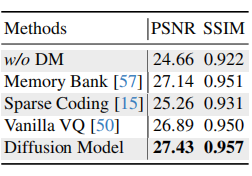
w/o DM:24.66 / 0.922
Memory Bank:27.14 / 0.951
Sparse Coding:25.26 / 0.931
Vanilla VQ:26.89 / 0.950
Diffusion Model:27.43 / 0.957
说明扩散模型比记忆库、稀疏编码、普通 VQ 更适合重建幅度残差。
扩散迭代步数 T
表 7 显示不同 T 的结果:
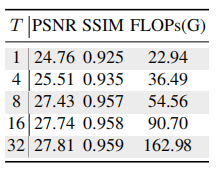
T=1:PSNR 24.76,SSIM 0.925,FLOPs 22.94G
T=4:PSNR 25.51,SSIM 0.935,FLOPs 36.49G
T=8:PSNR 27.43,SSIM 0.957,FLOPs 54.56G
T=16:PSNR 27.74,SSIM 0.958,FLOPs 90.70G
T=32:PSNR 27.81,SSIM 0.959,FLOPs 162.98G
可以看到,T 越大性能越好,但计算量也显著增加。T 超过 8 后提升变小,因此作者选择 T=8 作为性能和效率的折中。
4. 结论
本文提出了一种面向非配对图像去雾的频域扩散模型 FrDiff。它的核心贡献不在于简单地把扩散模型搬到去雾任务中,而是重新定义了扩散模型的生成目标:不生成整张清晰图像,而是生成频域幅度残差。
这种设计有三个关键优势:
-
降低扩散模型的生成难度
-
避免直接生成图像带来的颜色异常和纹理伪影
-
更符合雾霾退化主要体现在幅度谱中的物理/频域特性
ARE 通过均值和标准差对齐,将有雾幅度谱调整到清晰域分布,并生成幅度残差作为扩散模型监督;PCM 则进一步利用幅度残差修正相位谱,减少结构伪影;FCL 在多尺度特征中引入频域补偿,使去雾网络能够充分利用扩散模型生成的幅度先验。
实验结果表明,FrDiff 在 SOTS-Indoor、SOTS-Outdoor、HSTS-Synth、I-HAZE 等有 GT 数据集上取得了优于多数非监督方法的 PSNR/SSIM 表现,在 HSTS-Real、Fattal's、URHI 等真实无 GT 数据集上也展现出较好的泛化能力。消融实验进一步证明了 DM、ARE、PCM、多尺度补偿和联合训练均对性能提升有贡献。
总体来看,这篇论文的价值在于:它为非配对图像去雾提供了一个新的思路,即从频域幅度重建角度利用非配对清晰图像知识。
启发:不要总是让模型在 RGB 空间直接向伪清晰图对齐,而可以考虑把监督或生成目标转移到更稳定、更少内容干扰的频域先验上,例如幅度残差、颜色/亮度分布残差、高频细节残差等。