第10章 Streaming(上):初级音频应用(1)------项目三:自建服务器的Mini-Omni实时语音聊天机器人
- [第10章 Streaming(上):初级音频应用](#第10章 Streaming(上):初级音频应用)
-
- [10.1 自动语音识别技术(ASR)](#10.1 自动语音识别技术(ASR))
-
- [10.1.1 Whisper模型与FFmpeg框架](#10.1.1 Whisper模型与FFmpeg框架)
- [10.1.2 构建全上下文和实时流式ASR演示](#10.1.2 构建全上下文和实时流式ASR演示)
- [10.2 Mini-Omni构建实时语音聊天机器人](#10.2 Mini-Omni构建实时语音聊天机器人)
-
- [10.2.1 Mini-Omni:实时语音多模态大模型](#10.2.1 Mini-Omni:实时语音多模态大模型)
- [10.2.2 项目三:自建服务器的Mini-Omni实时语音聊天机器人](#10.2.2 项目三:自建服务器的Mini-Omni实时语音聊天机器人)
-
- [1. 本地部署Mini-Omni聊天服务器](#1. 本地部署Mini-Omni聊天服务器)
- [2. 应用状态、拼接音频与检测停顿](#2. 应用状态、拼接音频与检测停顿)
- [3. 流式传输响应音频](#3. 流式传输响应音频)
- [4. 由gr.Blocks构建Gradio应用](#4. 由gr.Blocks构建Gradio应用)
- [5. 启动应用及演示效果](#5. 启动应用及演示效果)
第10章 Streaming(上):初级音频应用
由于流式传输内容较多,因此将其分为初级音频应用、高级音频应用和视频应用三部分。本章音频应用部分包括自动语音识别技术(ASR),自建服务器的Mini-Omni模型的对话式聊天机器人,Groq与带自动语音检测功能的多模态Gradio应用,Mistral实现流式传输音频的魔力8号球。除了拆解音频应用,还会详细介绍并实战大模型库Whisper、Mini-Omni、Groq和Mistral。此外,本章还会详细讲解用到的其他技术:@ricky0123/vad-web实现语音活动检测功能,Groq高速大模型调用库,LiteLLM高速开源代理库,AI-SDK是JavaScript版大模型调用库,HF Inference在服务器上运行推理,Spaces ZeroGPU为Spaces提供动态GPU分配方案,Parler-TTS是文本转语音模型。示例由浅入深逐步添加语音识别、智能回复、自动检测及流式传输。通过本章的学习,音频领域的开发者可掌握Gradio相关的语音、音频的生成及检测技术,还有最前沿的推理API及加速方案。
10.1 自动语音识别技术(ASR)
自动语音识别技术(Automatic speech recognition:ASR)作为机器学习中将语音信号转换为文本的重要领域,正处于快速发展阶段。当前ASR算法已普遍应用于智能手机设备,并逐步渗透到专业工作流程中,如医护人员的数字助理系统。由于ASR算法直接面向终端用户,所以必须确保其能够实时准确处理各种语音特征(包括不同口音、音高及背景噪声等)。
通过Gradio平台,开发者可快速构建ASR算法模型的演示系统,便于测试团队通过语音文件或由麦克风等设备进行实时验证。本节将通过两种方式演示如何将预训练语音转文本模型部署至Gradio交互界面:第一种采用全上下文模式,即用户完成整段录音后才执行预测;第二种将演示改造为流式处理模式。
10.1.1 Whisper模型与FFmpeg框架
本例使用预训练语音识别模型,需要以下两个ASR技术构建演示系统:
- Whisper模型:使用transformers中Whisper模型实现语音识别。Whisper是由OpenAI的Alec Radford等人提出的先进自动语音识别ASR与语音翻译模型,在超过500万小时的标注数据上训练而成,展现出强大的零样本泛化能力,可适应多种数据集和研究领域,请参阅whisper-large-v3-turbo🖇️链接10-1。
- Ffmpeg框架:处理麦克风输入文件,它是领先的多媒体框架,能够解码、编码、转码、复用、解复用、流式传输、过滤及播放几乎所有人类与机器创建的媒体内容。该框架支持从最冷门的原始格式到最前沿的技术标准。transformers库会自带ffmpeg库,但有时会出现未知错误,所以建议单独安装ffmpeg。在Windows平台下,还需单独下载,详细信息请参阅:FFmpeg🖇️链接10-2。
自动语音识别ASR应用开发全部基于Transformers,先配置ASR模型------可以是自行训练的模型,或是下载预训练模型。本教程将使用Whisper基础的预训练ASR模型whisper-base.en。然后构建全上下文ASR演示系统和实时流式ASR演示系统。
10.1.2 构建全上下文和实时流式ASR演示
构建全上下文ASR演示。所谓全上下文即用户需完整录制音频后,系统才会调用ASR模型进行推理。利用Gradio实现这一功能非常简单------只需基于管线对象创建录制完成后的处理函数即可。如代码10-1所示:
代码10-1
py
import gradio as gr
from transformers import pipeline
import numpy as np
transcriber = pipeline("automatic-speech-recognition", model="openai/whisper-base.en")
def transcribe(audio):
sr, y = audio
# Convert to mono if stereo
if y.ndim > 1:
y = y.mean(axis=1)
y = y.astype(np.float32)
y /= np.max(np.abs(y))
return transcriber({"sampling_rate": sr, "raw": y})["text"]
demo = gr.Interface(transcribe,
gr.Audio(sources="microphone"), "text")
demo.launch()Gradio界面将采用内置的gr.Audio组件:输入组件将接收用户麦克风输入并返回录音文件路径,输出组件将使用标准Textbox组件显示识别结果。函数transcribe()接受单一参数audio,这是一个用户录制音频的numpy数组;接收包含采样率(sr)和音频数据(y)的元组,进行声道处理:如果音频是立体声(多声道),通过取平均值转换为单声道。管道对象transcriber期望音频为float32格式,然后进行最大归一化,最后使用管道识别转录文本。运行界面如图10-1所示:
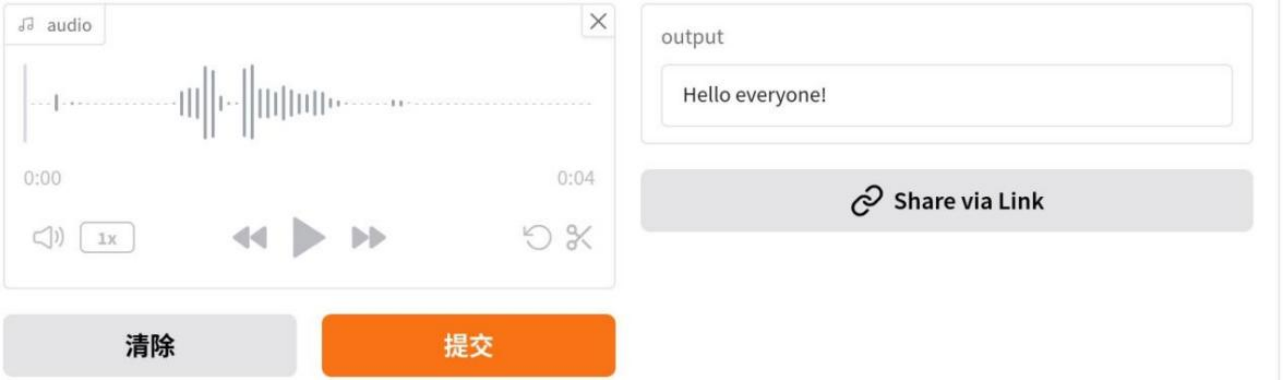
图10-1
构建实时流式ASR演示,需进行以下配置调整:
(1)在Audio组件中设置streaming=True以支持流式传输。
(2)在gr.Interface中启用live=True参数以支持实时传输。
(3)添加状态存储机制state以保存用户音频流。
(4)判断状态,拼接流数据,根据完整流数据生成转录文本。
构建流式ASR演示系统的具体实现如代码10-2所示:
代码10-2
py
import gradio as gr
from transformers import pipeline
import numpy as np
transcriber = pipeline("automatic-speech-recognition", model="openai/whisper-base.en")
def transcribe(stream, new_chunk):
sr, y = new_chunk
# Convert to mono if stereo
if y.ndim > 1:
y = y.mean(axis=1)
y = y.astype(np.float32)
y /= np.max(np.abs(y))
if stream is not None:
stream = np.concatenate([stream, y])
else:
stream = y
return stream, transcriber({"sampling_rate": sr, "raw": stream})["text"]
demo = gr.Interface(transcribe,
["state", gr.Audio(sources=["microphone"], streaming=True)],
["state", "text"], live=True)
demo.launch()请注意,现在有一个状态变量state用于跟踪所有音频历史。随着接口运行,每次有新的小段音频时,将其作为new_chunk,拼接到stream中,在transcribe函数的入参stream中跟踪迄今为止所有的音频记录;最后将存储并返回新的完整音频流stream,同时调用管道transcriber返回转录文本。整个过程只需简单地将音频拼接在一起,并对整个音频调用转录器对象。也可以优化为其它更有效率的处理方式,比如每次接收到新音频片段时,仅重新处理最后5秒的音频。
现在,得益于设置gr.Interface的参数live及gr.Audio的参数streaming,ASR模型将在用户说话时自动录音并转录文本。此时仍需单击"录音",注意在进度条开始后录音,运行界面如图10-2所示:
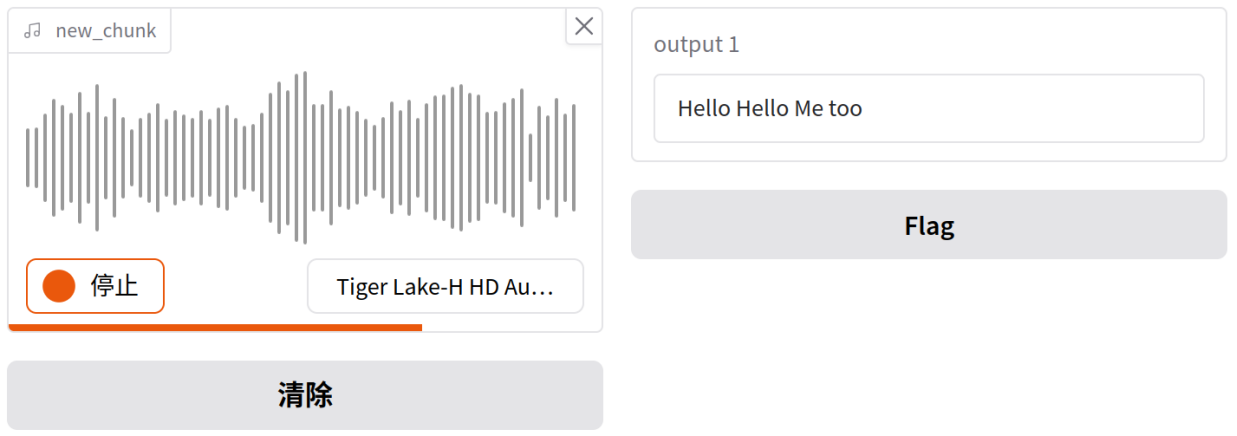
图10-2
10.2 Mini-Omni构建实时语音聊天机器人
新一代AI用户界面正朝着原生音频体验发展,用户将能够与聊天机器人实时对话并接收语音回复。基于这一范式已开发出多个模型,包括GPT-4o和Mini-Omni。本节将以Mini-Omni为例逐步构建对话式聊天应用,它支持实时音频处理、对话管理和自动循环录音,语音经处理后可生成响应,并可动态更新历史展示。本节首先介绍Mini-Omni大模型,然后构建实时语音聊天机器人。
10.2.1 Mini-Omni:实时语音多模态大模型
Mini-Omni是一款开源多模态大语言模型,具备实时听说与同步思考能力。该模型采用端到端架构,支持实时语音输入与流式音频输出的对话交互,可实现较完整的语音交互体验,其GitHub地址为:gpt-omni/mini-omni🖇️链接10-3。
Mini-Omni功能特性包括:①实时语音对话能力,无需额外配置ASR或TTS模型。②思考与语音同步生成 ,支持文本与音频并行输出。③流式音频输出功能。④支持"语音转文本"与"语音转语音"的批量推理模式以提升性能。功能示意图如图10-3所示:
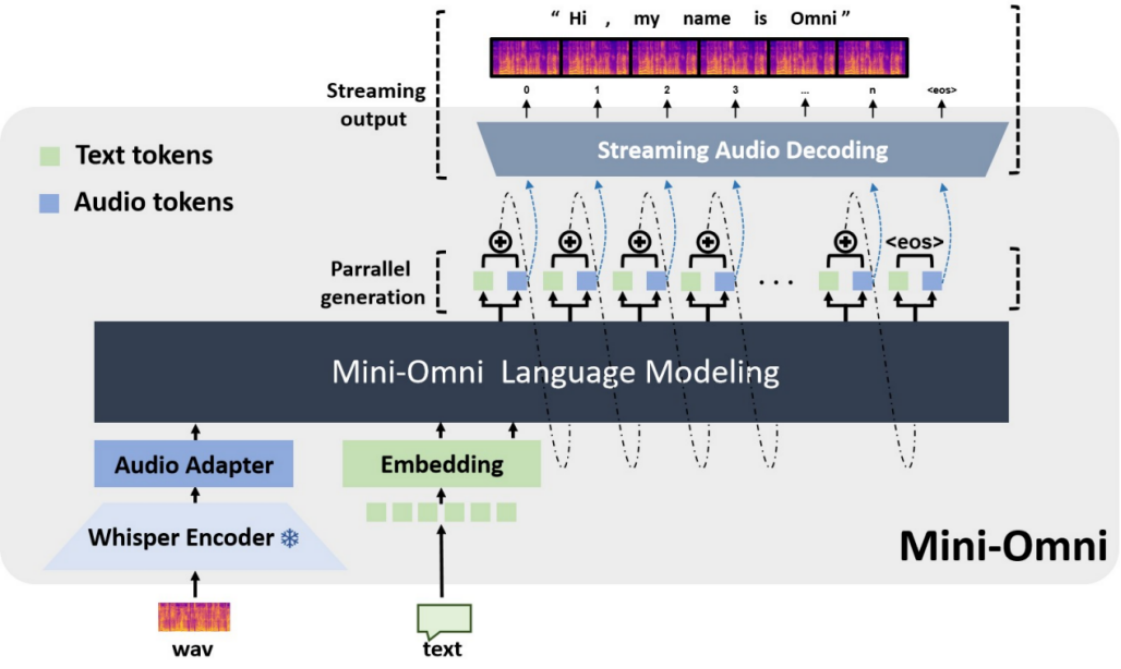
图10-3
另外,官方已于2024年10月发布Mini-Omni2,它是一款全交互式多模态模型,支持图像、音频和文本输入。它能与用户进行端到端的实时语音对话,支持语音打断机制的灵活交互,请根据需求选择。
运行Mini-Omni官方示例,步骤如下:
(1)首先,安装Mini-Omni。创建新conda环境并激活,克隆Mini-Omni资源后安装目录中的Python需求包,命令如下所示:
bash
conda create -n omni python=3.13
conda activate omni
git clone https://github.com/gpt-omni/mini-omni.git
cd mini-omni
pip install -r requirements.txt(2)然后,启动Mini-Omni服务器。以Linux为例,启动命令如下所示:
bash
sudo apt-get install ffmpeg
conda activate omni
cd mini-omni
python3 server.py --ip '127.0.0.1' --port 60808(3)接着,运行StreamLit演示和Gradio演示。运行StreamLit演示需先安装PyAudio;若出现错误"ModuleNotFoundError: No module named 'utils.vad'",请先执行命令:export PYTHONPATH=./;另外,还需配置服务器地址API_URL;最后,运行前需先取消静音设置。运行Gradio演示命令如下:
bash
API_URL=http://127.0.0.1:60808/chat python3 webui/omni_gradio.py(4)最后,使用推理测试演示。本地测试命令如下:
bash
conda activate omni
cd mini-omni
# test run the preset audio samples and questions
python inference.py10.2.2 项目三:自建服务器的Mini-Omni实时语音聊天机器人
项目首先在本地部署基于Mini-Omni的聊天服务器,接着讲述聊天机器人如何设置应用状态、存储音频以及检测停顿,随后讲述核心逻辑------生成并拼接响应音频,再者使用Gradio构建聊天界面,最后讲述启动应用步骤及用户体验效果。omni-mini聊天机器人应用将实现以下用户体验:
(1)用户点击按钮开始录制语音消息。
(2)应用可以检测到用户停止说话后自动结束录制。
(3)用户音频传入Mini-Omni模型,模型会流式返回响应。
(4)Mini-Omni完成应答后重新激活用户麦克风。
(5)所有对话历史(用户与Mini-Omni的语音记录)显示在聊天界面中。
1. 本地部署Mini-Omni聊天服务器
在开发聊天应用之前,需要先在本地部署以Mini-Omni大模型为后台的聊天服务器,聊天界面发送用户输入消息到聊天服务器,聊天服务器生成响应后回传。项目文件可在线上下载压缩包。定义Omni聊天服务器如代码10-3所示:
代码10-3
py
# server.py
import flask
import base64
import tempfile
import traceback
from flask import Flask, Response, stream_with_context
from inference import OmniInference
class OmniChatServer(object):
def __init__(self, ip='127.0.0.1', port=60808, run_app=True,
ckpt_dir='./checkpoint', device='cuda:0') -> None:
self.client = OmniInference(ckpt_dir, device)
self.client.warm_up()
server = Flask(__name__)
server.route("/chat", methods=["POST"])(self.chat)
if run_app:
server.run(host=ip, port=port, threaded=False)
else:
self.server = server
def chat(self) -> Response:
req_data = flask.request.get_json()
try:
data_buf = req_data["audio"].encode("utf-8")
data_buf = base64.b64decode(data_buf)
stream_stride = req_data.get("stream_stride", 4)
max_tokens = req_data.get("max_tokens", 2048)
with tempfile.NamedTemporaryFile(suffix=".wav", delete=False) as f:
f.write(data_buf)
audio_generator = self.client.run_AT_batch_stream(f.name, stream_stride, max_tokens)
return Response(stream_with_context(audio_generator), mimetype="audio/wav")
except Exception as e:
print(traceback.format_exc())
def server_app(ip='127.0.0.1', port=60808, device='cuda:0'):
OmniChatServer(ip, port=port, run_app=True, device=device)
if __name__ == "__main__":
import fire
fire.Fire(server_app)这段代码实现了一个基于Flask的可独立运行的音频聊天服务器,能够接收音频输入并流式返回处理结果,主要功能包括:
- 模型加载与预热:集成OmniInference类来加载位于./checkpoint目录下的模型(若模型不存在则从Hugging Face Hub下载),并调用warm_up()方法进行预热,以提升首次推理速度。
- Web服务器初始化:使用Flask框架创建Web服务器,并提供路由为/chat的POST接口,此路由会调用chat函数;然后根据run_app判断是否启动服务器来监听指定IP和端口(默认127.0.0.1:60808)。
- 处理请求音频数据:chat函数从Request中接收音频数据并使用Base64格式解码,从而获取音频数据的流步长(stream_stride)和最大生成令牌数(max_tokens);然后将音频数据保存为临时WAV文件。
- 生成音频并转文本处理:调用OmniInference的run_AT_batch_stream方法生成语音回复,然后调用stream_with_context进行流式音频转文本处理(ASR),并以流式方式返回生成的音频响应(audio/wav格式)和文本。关于OmniInference实现,请参考文件inference.py中源码。
- 错误处理:通过traceback.format_exc()捕获并打印异常堆栈信息。
- 部署与启动方式:支持通过函数server_app灵活配置参数(如IP、端口、设备)后启动,或使用fire库实现命令行启动(如python script.py server_app)。
在本地部署聊天服务器,如代码10-4所示:
代码10-4
py
# app.py
from huggingface_hub import snapshot_download
from threading import Thread
from server import server_app
repo_id = "gpt-omni/mini-omni"
snapshot_download(repo_id, local_dir="./checkpoint", revision="main")
device = "cuda:0" if torch.cuda.is_available() else "cpu"
print(f"Using device: {device}")
thread = Thread(target=server_app, daemon=True, args=(IP, PORT, device))
thread.start()在本地部署之前,需要通过函数snapshot_download从Hugging Face Hub下载mini-omni大模型,并保存在local_dir目录,服务器server_app启动时会自动加载目录./checkpoint中的大模型;然后使用线程启动模型,设置线程的daemon=True意味着该线程是守护线程,表示程序的终止方式,即当聊天界面的主程序终止时,会同时结束服务器进程。守护线程的主要特性是:主程序在退出时,不会等待守护线程运行完成后才退出,而是直接退出运行环境,使得守护线程也会随之结束。
2. 应用状态、拼接音频与检测停顿
现在逐步实现客户端的聊天机器人应用。本小节内容包括应用状态、存储音频与检测停顿:在每个新音频片段到达时,客户端首先拼接并存储音频,然后判断用户是否已停止说话以判断是否继续录音。
应用状态类:AppState 。首先,使用AppState类来进行音频处理和记录对话状态,如代码10-5所示:
代码10-5
py
from dataclasses import dataclass, field
@dataclass
class AppState:
stream: np.ndarray | None = None
sampling_rate: int = 0
pause_detected: bool = False
started_talking: bool = False
stopped: bool = False
conversation: list = field(default_factory=list)AppState类主要属性包括:
- 音频流管理:stream存储当前音频数据片段,sampling_rate记录采样率。
- 暂停检测:pause_detected标识是否检测到静默间隔。
- 对话状态:started_talking标识是否开始说话,stopped标识是否结束录音。
- 对话历史:conversation记录完整的对话记录(列表类型)。初始化空列表使用field(default_factory=list),确保每次实例化时创建独立的列表对象。
拼接并存储音频。定义处理用户音频的process_audio函数,如代码10-6所示:
代码10-6
py
import numpy as np
from utils import determine_pause
def process_audio(audio: tuple, state: AppState):
if state.stream is None:
state.stream = audio[1]
state.sampling_rate = audio[0]
else:
state.stream = np.concatenate((state.stream, audio[1]))
pause_detected = determine_pause(state.stream, state.sampling_rate, state)
state.pause_detected = pause_detected
if state.pause_detected and state.started_talking:
return gr.Audio(recording=False), state
return None, state该函数接收两个输入参数:当前输入音频片段(由采样率sampling_rate和音频流numpy数组组成的元组)和当前应用状态。它会将新音频片段与现有音频流拼接,并调用determine_pause函数检测当前流中的静默间隔。如果检测到静默且state.started_talking为True,即开启录音但无语音时,返回gr.Audio(recording=False)停止录音;否则,返回None继续录音。
检测停顿 。omni-mini项目特有determine_pause函数,如代码10-7所示:
代码10-7
py
def determine_pause(audio: np.ndarray, sampling_rate: int, state: AppState) -> bool:
"""Take in the stream, determine if a pause happened"""
temp_audio = audio
dur_vad, _, time_vad = run_vad(temp_audio, sampling_rate)
duration = len(audio) / sampling_rate
if dur_vad > 0.5 and not state.started_talking:
print("started talking")
state.started_talking = True
return False
print(f"duration_after_vad: {dur_vad:.3f} s, time_vad: {time_vad:.3f} s")
return (duration - dur_vad) > 0.8该函数实现音频流中的静默检测,核心功能包括:
- VAD处理:调用run_vad函数检测音频中的语音活动(VAD)时长和时间戳。
- 状态更新:根据VAD时长更新说话状态(started_talking)。
- 静默判断:当VAD时长大于0.5秒且started_talking为False时,没有发生静默;如果VAD时长与总时长的差值大于1秒,则发生静默。
- 阈值设置:VAD时长阈值为0.5秒,静默时长阈值为1秒,可根据需求调整。
3. 流式传输响应音频
存储用户音频后,需要根据音频数据生成聊天机器人的响应并流式传输。
生成回复语音。speaking函数也omni-mini项目特有,如代码10-8所示:
代码10-8
py
import requests
IP = "0.0.0.0"
PORT = 60808
API_URL = f"http://{IP}:{PORT}/chat"
# playing parameters
OUT_CHANNELS = 1
OUT_RATE = 24000
OUT_SAMPLE_WIDTH = 2
OUT_CHUNK = 5760
def speaking(audio_bytes: str):
base64_encoded = str(base64.b64encode(audio_bytes), encoding="utf-8")
files = {"audio": base64_encoded}
with requests.post(API_URL, json=files, stream=True) as response:
try:
for chunk in response.iter_content(chunk_size=OUT_CHUNK):
if chunk:
# Create an audio segment from the numpy array
audio_segment = AudioSegment(chunk,
frame_rate=OUT_RATE,
sample_width=OUT_SAMPLE_WIDTH,
channels=OUT_CHANNELS)
# Export the audio segment to MP3 bytes - use a high bitrate to maximise quality
mp3_io = io.BytesIO()
audio_segment.export(mp3_io, format="mp3", bitrate="320k")
# Get the MP3 bytes
mp3_bytes = mp3_io.getvalue()
mp3_io.close()
yield mp3_bytes
except Exception as e:
raise gr.Error(f"Error during audio streaming: {e}")通过上述机制,函数可实现高效、实时的音频格式转换与流式处理,支持高音质音频传输,核心功能包括:
- Base64编码:使用utf-8格式将原始音频字节编码为Base64字符串,以便适配API传输格式;然后将Base64字符串转为JSON格式。
- POST请求:将音频数据通过requests.post()发送到API_URL,同时启用流式响应(stream=True);然后通过iter_content按OUT_CHUNK大小分段读取API响应数据,避免一次性加载大文件而导致内存溢出。
- 音频格式转换:先将二进制块转换为pydub.AudioSegment对象;然后由io.BytesIO()创建内存字节流,用于在内存中处理二进制数据流(另有io.StringIO处理字符串流);最后将音频数据实时导出为的MP3格式,确保高音质。
- 生成器输出:通过yield逐块返回MP3字节数据,以支持实时音频流式传输。
拼接双方对话音频 。speaking生成语音后,由response函数实现音频格式转换、语音合成和拼接对话功能,如代码10-9所示:
代码10-9
py
import io
import tempfile
from pydub import AudioSegment
def response(state: AppState):
if not state.pause_detected and not state.started_talking:
return None, AppState()
audio_buffer = io.BytesIO()
segment = AudioSegment(state.stream.tobytes(),
frame_rate=state.sampling_rate,
sample_width=state.stream.dtype.itemsize,
channels=(1 if len(state.stream.shape) == 1 else state.stream.shape[1]))
segment.export(audio_buffer, format="wav")
with tempfile.NamedTemporaryFile(suffix=".wav", delete=False) as f:
f.write(audio_buffer.getvalue())
state.conversation.append({"role": "user",
"content": {"path": f.name, "mime_type": "audio/wav"}})
output_buffer = b""
for mp3_bytes in speaking(audio_buffer.getvalue()):
output_buffer += mp3_bytes
yield mp3_bytes, state
with tempfile.NamedTemporaryFile(suffix=".mp3", delete=False) as f:
f.write(output_buffer)
state.conversation.append({"role": "assistant",
"content": {"path": f.name, "mime_type": "audio/mp3"}})
yield None, AppState(conversation=state.conversation)response函数是整个项目的核心,其流程包括:
- 状态检查:验证是否检测到暂停或开始说话状态,检测到时直接返回以继续录音,否则处理用户输入信息。
- 音频格式转换:将用户输入AppState.stream转化为字节并插入到格式pydub.AudioSegment。pydub.AudioSegment支持多种音频格式(WAV、MP3、FLAC等),自动处理采样率、采样位宽和声道数等信息。然后将AudioSegment中的numpy音频数组转换为WAV格式。
- 临时文件管理:利用tempfile创建临时WAV音频文件保存用户输入,创建临时MP3音频文件保存助理输出,设置delete=False避免自动清理。
- 流式语音合成:创建输出缓存,调用speaking函数逐块生成MP3音频数据并添加至输出缓存,然后通过生成器(yield)实时流式返回。
- 对话历史记录:将输入及输出的音频文件路径和MIME类型分别添加到AppState对话状态,并通过yield返回已保存对话历史。
4. 由gr.Blocks构建Gradio应用
使用Gradio的Blocks API构建用户界面,实现完整聊天机器人应用,并实现流程跳转,如代码10-10所示:
代码10-10
py
# app.py
import gradio as gr
def restart_recording(state: AppState):
if not state.stopped:
return gr.Audio(recording=True)
with gr.Blocks() as demo:
with gr.Row():
with gr.Column():
input_audio = gr.Audio(label="Input Audio",
sources="microphone", type="numpy")
with gr.Column():
chatbot = gr.Chatbot(label="Conversation")
output_audio = gr.Audio(label="Output Audio",
streaming=True, autoplay=True)
state = gr.State(value=AppState())
stream = input_audio.stream(process_audio,
[input_audio, state], [input_audio, state],
stream_every=0.5, time_limit=30)
respond = input_audio.stop_recording(response,
[state], [output_audio, state])
respond.then(lambda s: s.conversation, [state], [chatbot])
restart = output_audio.stop(restart_recording,
[state], [input_audio])
cancel = gr.Button("Stop Conversation", variant="stop")
cancel.click(lambda: (AppState(stopped=True),
gr.Audio(recording=False)), None,
[state, input_audio], cancels=[respond, restart])
if __name__ == "__main__":
demo.launch()代码实现了一个基于gr.Blocks的语音对话界面,详细说明如下:
- 界面布局:使用gr.Blocks创建左右两列布局,左侧为音频输入(麦克风),右侧为对话历史和音频输出,最下面是重置按钮。
- 音频流处理:通过事件input_audio.stream实时处理音频输入(每0.5秒处理一次,最长30秒),调用process_audio函数进行静默检测和音频累积。
- 对话响应:用户停止录音时触发response生成语音回复,由output_audio播放。
- 状态管理:使用gr.State维护AppState对象,跟踪录音状态、对话历史等。在收到回复后调用事件then()将AppState中的对话历史展现在gr.Chatbot。
- 循环控制:在音频输出组件中播放完成后,自动调用start_recording_user重新开始录音,或通过"Stop Conversation"按钮手动停止,此时清空state并停止录音,同时取消事件respond和restart。
5. 启动应用及演示效果
最后,启动整个应用并查看程序运行效果,步骤如下:
- 首先,使用命令git clone https://huggingface.co/spaces/gradio/omni-mini或hf download gradio/omni-mini --repo-type=space下载整个项目。
- 然后,更新最新版的gradio库,安装requests、librosa、flask、lightning、snac、openai-whisper、onnxruntime、tokenizers、ffmpeg等库。
- 最后,在omni-mini目录下,使用命令python app.py启动应用。由于版本问题,Hugging Face版代码可能会报多个错误,请读者参阅本书线上的修复代码。
经过下载多个文件的等待后,如出现如下提示,说明运行成功:
bash
(stream-env) PS D:\mcp\omni-mini> python .\app.py
...warm up done, time_cost: 0.044 s
* Running on local URL: http://127.0.0.1:7860
* To create a public link, set `share=True` in `launch()`.
using LLAMA MLP adapter for ASR feature...
text output: Hello! My name is Omni, and I'm your friendly voice assistant here to help with your questions and provide advice.
* Serving Flask app 'server'
* Debug mode: off
WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead.
Running on http://127.0.0.1:60808注意:如果使用最新版Python 3.14,可能会报错"Because all versions of onnxruntime have no wheels with a matching Python ABI tag...",此时创建Python 3.13的虚拟环境:uv venv --python 3.13 py313-env并重新安装库即可。
其Hugging Face Spaces地址为:gradio/omni-mini🖇️链接10-4,使用Mini-Omni的最终应用的演示效果如图10-4所示:
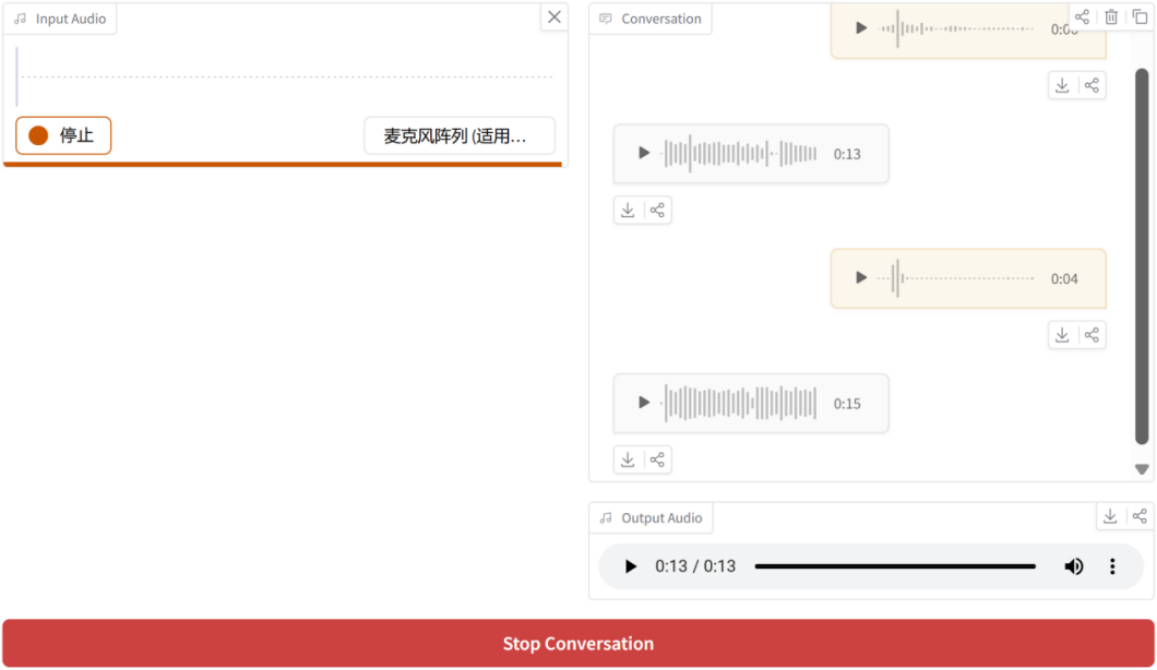
图10-4
本节演示了如何结合Gradio框架与Mini-Omni模型构建对话式聊天机器人应用,该基础架构可灵活扩展,用于开发各类语音交互式聊天演示。另外,开发者可尝试集成不同模型、优化音频处理流程或创新界面设计,打造个性化的对话式AI体验!