有人把 Whisper 做到了 89ms 中位延迟,还顺手把 GPU 峰值内存砍掉 48%。
我第一眼看到这个数据的时候,其实有点不敢太兴奋。因为做实时语音识别的人都知道,Whisper 是一个特别拧巴的存在,它离线转写很好用,效果稳,生态也成熟,但你真想把它塞进实时字幕、会议助手、语音 Agent 这种场景里,它马上就会暴露一堆不舒服的地方。
不是它不能用,而是它不是为流式场景长出来的。
你给它一段完整音频,它很能打。可一旦音频变成一小块一小块往里进,麻烦就来了。前面刚识别出来的词,后面可能又被模型改掉。音频越积越长,每次重算的上下文越来越大。再遇到静音、噪声、多语种切换,字幕就会开始闪,延迟也会开始飘。
所以 WhisperPipe 这篇论文打动我的地方,不是它又训练了一个更强的新模型。
恰恰相反,它基本是在说,模型先别动,我们把实时转写这条流水线修一修。
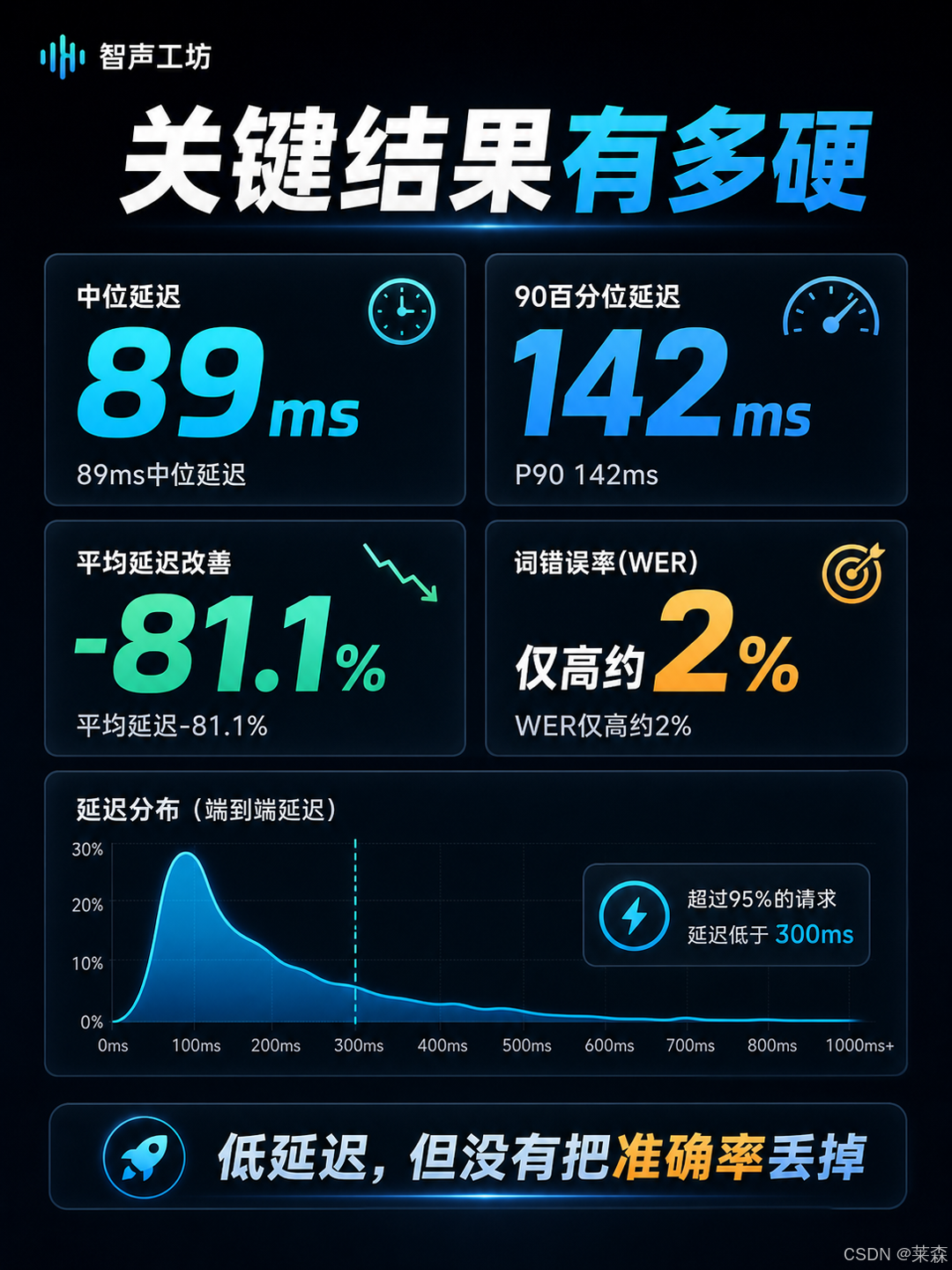
论文里最硬的几个结果,我先放在前面。WhisperPipe 在 2.5 小时多样化音频测试中,实现了 89ms 的中位端到端延迟,90 百分位延迟 142ms。相比基线,GPU 峰值内存降低 48%,平均 GPU 利用率降低 80.9%。连续跑 150 分钟,内存增长为 0。和现有流式方案比,延迟低 3 到 5 倍,词错率只比离线 Whisper 高 2% 左右。
如果这些数字可靠,那它解决的就不是一个论文小问题,而是很多人真正想做实时语音产品时会撞上的墙。

实时 ASR 最烦的,不是识别,而是稳定
很多朋友可能会觉得,实时语音识别不就是把音频切块,然后一段一段丢给 Whisper 吗?
理论上听起来确实是这样。愚钝如我一开始也这么想过。音频每来一秒,就把最近几秒拿去解码,再把结果显示出来,好像就能得到一个流式字幕系统。
但真正麻烦的地方在后面。
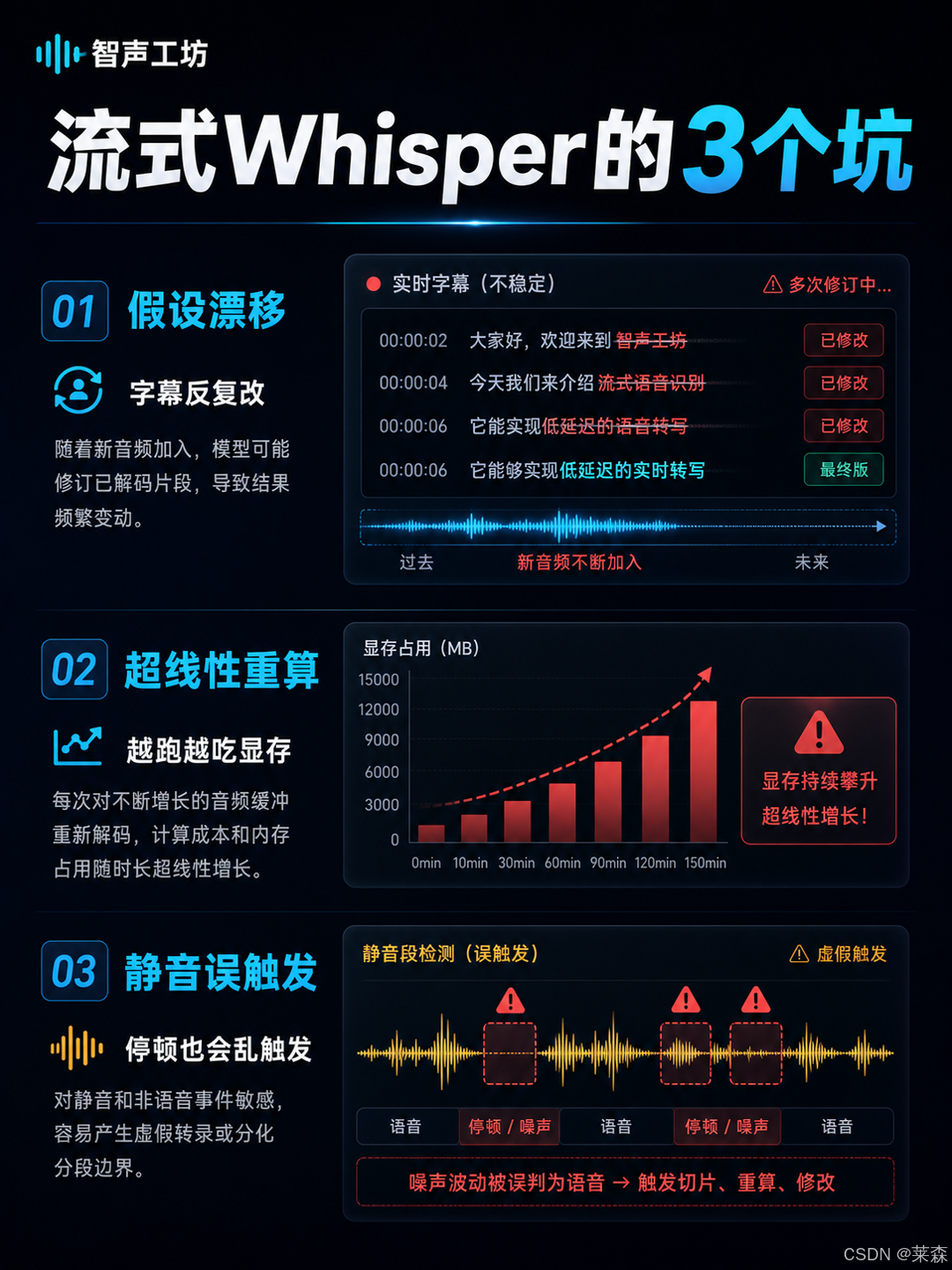
第一是「假设漂移」。Whisper 在前半句话里猜出来的词,到了后半句话可能会被新的上下文推翻。你看字幕的时候,就会出现刚显示出来的文本频繁变化,像有人在屏幕上不停反悔。
第二是「超线性重算」。为了让模型有足够上下文,很多方案会把越来越长的历史音频重新喂进去。会话越长,算力和显存压力越大。你不是在实时转写,你是在背着一整段历史往前跑。
第三是「静音敏感」。语音里有停顿,有噪声,有非语音事件。切得太激进,会丢上下文。切得太保守,又会把无意义片段塞进去,延迟和资源一起涨。
这就是 WhisperPipe 的切入点。它没有把问题甩给更大的模型,而是把实时 ASR 拆成一条可控流水线,分别处理「该不该听」「听到哪里」「哪段可以提交」「提交之后怎么裁掉历史」。
它真正做的,是给 Whisper 加一套交通规则
WhisperPipe 的架构里有两个缓冲区。
一个叫稳定文本缓冲,已经提交的文本放进去,原则上不再修改。另一个叫活动音频缓冲,保存最近还没确认的音频样本,默认上限 30 秒。这个设计很关键,因为它把「已经确定的历史」和「还在变化的现场」分开了。
你可以把它理解成开会记笔记。已经确认的会议纪要不要来回改,正在讨论的内容先放草稿区。等某句话真的稳定了,再写进正式纪要。
这个分离动作,听起来朴素,但它直接把流式系统里最烦的两件事拆开了。字幕不再无限闪,音频缓冲也不会随着会话时长一直膨胀。
然后是词级时间戳。
WhisperPipe 会利用 Whisper 输出的词级时间戳,知道每个词大概从什么时候开始,到什么时候结束。这样一来,一旦某段文本被提交,它就能根据最后一个词的结束时间,把活动缓冲里已经用过的音频精确裁掉,只保留一点点重叠尾巴作为下次解码的上下文。
这一下很关键。
因为它不是粗暴地每次都从头重算,也不是拍脑袋切掉一段固定长度,而是用模型自己给出的时间信息指导音频裁剪。历史被提交,音频被裁掉,计算量就有了上限。
这也是为什么它能做到 150 分钟连续运行内存零增长。不是靠玄学省显存,而是每轮处理完都真的把不该背的历史卸下来了。
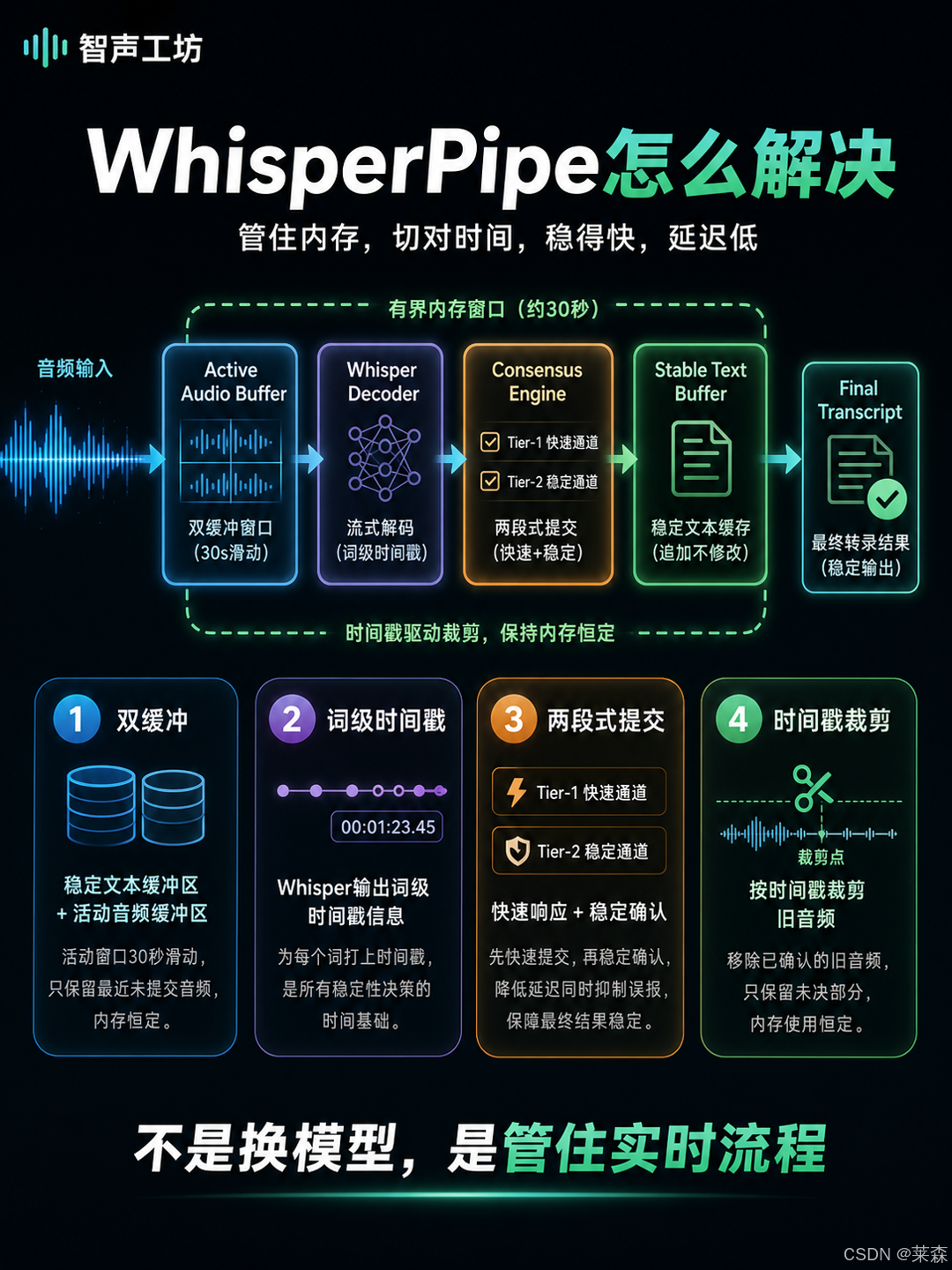
最有意思的是,两段式提交
实时字幕里还有一个矛盾,提交太快容易错,提交太慢观众等不起。
WhisperPipe 用了一个两段式提交策略。
第一段是快速通道。当前后两次连续假设的前缀完全一致,而且字符长度超过 20,就直接提交。这种情况说明模型已经很笃定,不需要再拖。
第二段是稳定通道。当前缀相似度超过阈值,并且长度足够,就进入候选暂存。后续三次解码里,只要至少两次独立结果确认一致,才最终提交。论文里叫 3-way consensus,我更愿意把它理解成让字幕自己多看两眼。
这个策略的好处是,它没有用一个死规则压所有情况。简单、清晰、稳定的句子,走快速通道。边界模糊、容易变化的句子,走稳定通道。再加上 10 秒超时保护,避免一直等不到完美结果。
坦率的讲,这种设计挺工程化的。它没有那种一看就很玄的模型魔法,但很像真实产品里会用的东西。因为真实语音永远不干净,系统必须允许世界有点乱。
论文里的结果也对应上了。WhisperPipe 的 WER 从基线的 19% 降到 15%,相对改善 21%。稳定性指数 93.5%,修订率从 6.2% 降到 4.8%。也就是说,它不是牺牲稳定换速度,而是在速度、稳定、准确之间找到了一个更舒服的位置。
89ms 这个数,为什么值得认真看
我知道很多人看到 89ms 会下意识怀疑,这会不会只是实验条件好。
这类怀疑是对的。实时 ASR 的结果特别依赖数据集、硬件、音频质量、语言、参数设置。论文里的测试是 LibriSpeech test-clean 和 2.5 小时多样化连续语音,模型是 Whisper large-v3,基线包括朴素重叠分块和 faster-whisper 等配置。
所以我们不应该把 89ms 理解成你在所有生产环境里一装就有的神迹。
但它真正值得看的是趋势。平均延迟从基线的 1212.6ms 到 WhisperPipe 的 229.3ms,下降 81.1%。P90 延迟 142ms,中位延迟 89ms。对实时字幕来说,300ms 往往已经是一个很敏感的体感门槛,它把大部分结果压在这个区间之内,产品体验就会完全不一样。
更现实的是资源。GPU 峰值内存降低 48%,平均 GPU 利用率降低 80.9%,稳态内存增长约等于 0 MB/s。这个数据对资源受限环境很重要。因为很多语音应用不是跑在无限预算的 A100 集群上,而是跑在边缘设备、单卡服务器、会议室盒子、机器人、或者一台不想被风扇吹爆的工作站上。
实时因子大约 3.5,20 个并发实例仍然保持这个级别。这里的价值不是「最强」,而是「够快、够稳、够省」。
说真的,很多工程项目最后拼的就是这个。
怎么用,它其实已经上 PyPI 了
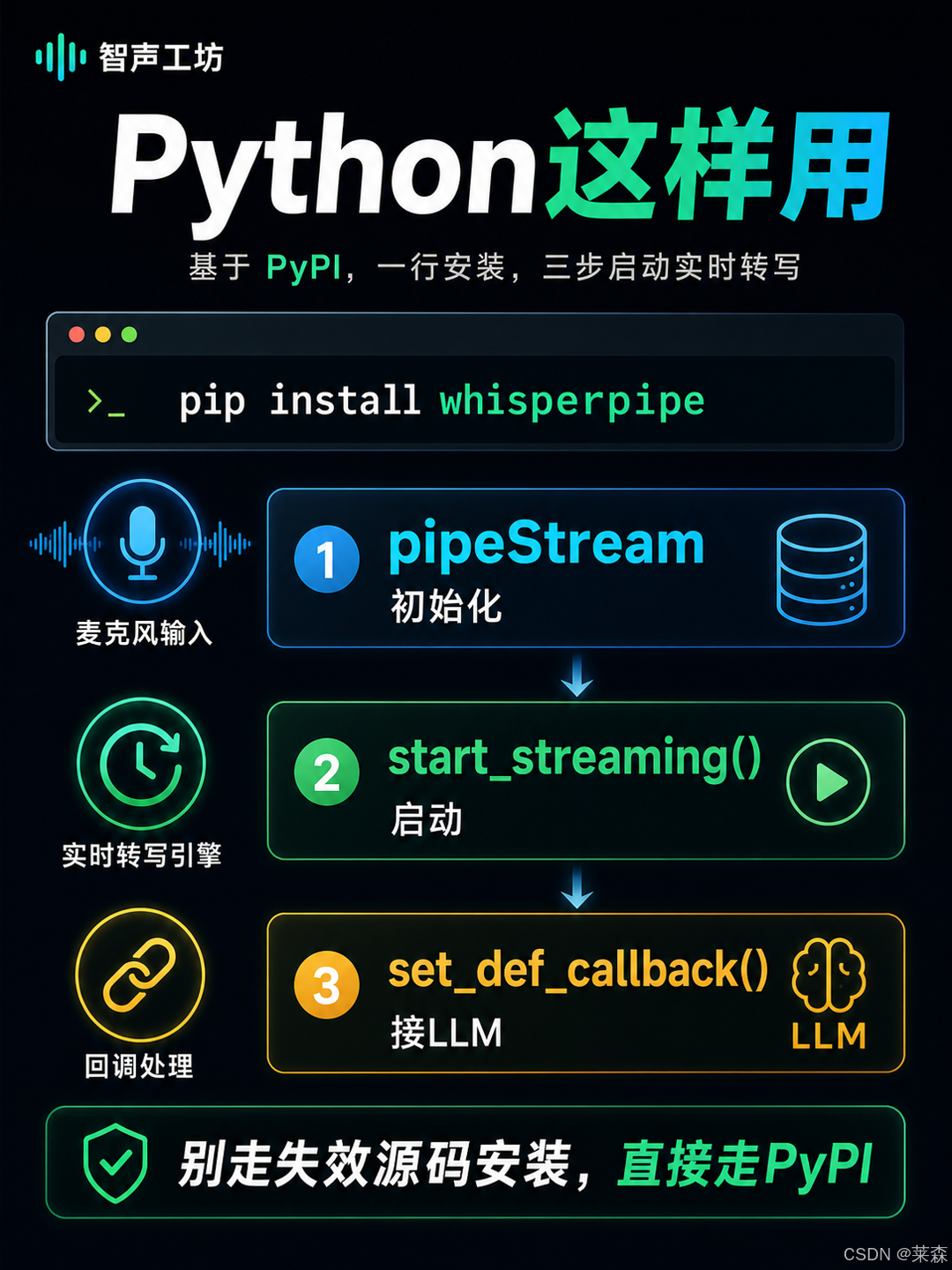
这块我专门看了一下,现在最稳妥的方式就是从 PyPI 安装。
bash
pip install whisperpipe不要再走源码安装那条路了。那条方式现在已经不适合展示给读者,容易把人带到失效路径里。
最基础的用法长这样。
python
from whisperpipe import pipeStream
transcriber = pipeStream(
model_name="base",
language="en",
finalization_delay=10.0,
processing_interval=1.0
)
transcriber.start_streaming()如果你想把实时转写接到 LLM,WhisperPipe 也提供 callback。比如用户说一句话,转写出来之后交给你的大模型、客服系统、会议总结系统、字幕后处理系统。
python
from whisperpipe import pipeStream
def llm_processor(text):
print(f"Processing: {text}")
response = your_llm_api.chat(text)
print(f"Response: {response}")
return response
transcriber = pipeStream(
model_name="base",
language="en",
finalization_delay=10.0,
processing_interval=1.0
)
transcriber.set_def_callback(llm_processor)
transcriber.start_streaming()更有意思的是暂停和恢复。比如你做一个语音助手,系统正在处理上一轮回复时,可以先暂停录音处理,等回复展示或播完,再恢复下一轮输入。
python
from whisperpipe import pipeStream
def interactive_processor(text):
transcriber.pause_streaming()
print(f"User said: {text}")
response = process_with_llm(text)
print(f"Assistant: {response}")
transcriber.resume_streaming()
transcriber = pipeStream()
transcriber.set_def_callback(interactive_processor)
transcriber.start_streaming()可配置参数也比较直观。model_name 可以选 tiny、base、small、medium、large。language 控制转写语言。finalization_delay 控制最终确认前等待多久。processing_interval 控制处理周期。buffer_duration_seconds 控制音频窗口。还有 debug_mode 用来打开详细日志。
我自己的判断是,如果你只是偶尔转写一个文件,还是离线 Whisper 或者现成 SaaS 更省心。但如果你要做实时字幕、语音助手、会议转录、低资源设备上的常驻转写,WhisperPipe 这种架构就很有参考价值。
它的启发,不止是 Whisper
顺着这篇论文再往外想,我觉得它其实在提醒一件事,很多 AI 工程问题,不一定要靠更大的模型解决。
实时 ASR 里,模型当然重要。但模型只是流水线里的一个环节。你怎么判断静音,怎么管理缓冲,什么时候提交结果,怎么裁掉历史,怎么避免字幕反复修订,这些架构选择会直接决定产品能不能用。
这也是我最近越来越有感触的地方。大家很容易被模型名字吸走注意力,今天换 large-v3,明天换 faster-whisper,后天再看有没有新 SOTA。但真正落到产品里,往往是这些不性感的东西决定体验。
WhisperPipe 好就好在,它没有假装世界很干净。
它承认实时语音会停顿,会重复,会有噪声,会有上下文反悔,也承认资源不是无限的。然后它用双缓冲、词级时间戳、两段式共识和时间戳裁剪,把这些麻烦一个个压住。
所以我觉得这篇最值得记住的,不只是 89ms。
而是那句更朴素的工程判断,想让大模型进入实时世界,不能只问模型有多强,还要问这条管道有没有把它照顾好。
回到开头那个数字,89ms 中位延迟、48% 显存下降、80.9% 平均 GPU 利用率下降、150 分钟内存零增长。
这几个数合在一起,才是 WhisperPipe 真正厉害的地方。它不是单点跑得快,而是让实时转写变得更像一个能长期工作的系统。
这就挺让人兴奋的。
参考信息:
- 论文,WhisperPipe: A Resource-Efficient Streaming Architecture for Real-Time Automatic Speech Recognition,arXiv:2604.25611
- 项目,https://pypi.org/project/whisperpipe/