第一章:引言------从"手写代码"到"AI 编排"的 BI 进化论
回想起几年前,我负责公司内部 BI 系统从 0 到 1 的开发。那时候,我们的目标很纯粹:让数据"动"起来。
起初,为了满足业务部门一张简单的销售报表,我们需要从 SQL 编写、后端 API 开发再到前端图表渲染,全链路手动"硬编码"。随着需求爆炸式增长,这种作坊式的生产方式显然难以为继。于是,我们开始构建 BI 低代码平台。
我们将图表、表格、过滤器、容器等组件的复杂属性全部抽离出来,定义成一套标准化的 JSON Schema 协议,我们把报表开发的权限交还给了业务。用户只需要在画布上拖拽组件、在配置面板里中调整各项配置,后台就会实时生成结构化的 JSON 数据,最终由渲染引擎将其转化为精美的仪表盘。
那一刻,我一度认为我们已经走到了 BI 报表开发的终点。
然而,在实际运行中,新的困局出现了:即便配置面板已经足够直观,但面对上百个配置项、复杂的联动逻辑和不同层级的样式需求,非技术背景的业务人员依然会感到迷茫。他们经常困惑地问我:
"我只是想看个趋势,为什么还要去研究什么是'双轴图'或者'转化漏斗'?"
这种"操作门槛"与"表达意愿"之间的鸿沟,让我开始重新审视 AI 的角色。
过去两年,随着大模型技术的爆发,很多人讨论 AI 是否会取代 BI,甚至直接生成报表。但在我看来,AI 并不是要推翻我们辛苦构建的低代码体系,恰恰相反,它是低代码平台最完美的"搭档"。AI 的擅长之处在于理解人的模糊意图,而低代码平台的 JSON Schema 则提供了 AI 最稀缺的------确定性与落地能力。
与其让 AI 像个画家一样直接去"画"一张图,
不如让它成为一个称职的"配置员"。
基于过去 BI 系统建设的经验,我发现让 AI 介入低代码平台的底层数据流,去自动生成那段描述报表的 JSON 代码,才是目前最稳健、也最能解决实际问题的落地路径。
第二章:契约之美 ------ 为什么 JSON Schema 是 AI 落地的最佳容器?
在开发 BI 低代码平台之初,我并未预料到这套 JSON Schema 协议会在 AI 时代成为如此关键的"契约"。当时设计它的主要目的是实现前后端解耦:前端专注渲染,后端负责存储与解析。然而,当我开始探索 AI 与低代码平台的结合时,这套结构化协议却意外地展现出了强大的适配性,成为 AI 在 BI 领域落地最可靠的容器。
1. 确定性:为 AI 套上"安全围栏"
在实践中我发现,如果直接让大模型生成 HTML 或 Echarts 代码,结果往往是不可控的------它可能会写出无法运行的 JS 代码,或者调用不存在的配置项。
而我们定义的 JSON Schema 就像一份严谨的技术契约。我不再要求 AI "帮我画一张图",而是明确指示它:"根据用户需求,生成一份符合平台 JSON Schema 规范的报表描述"。由于 Schema 本身是结构化且可校验的,我可以在渲染之前通过校验器(Validator)拦截掉所有不符合规范的属性。这种"确定性",是企业级 BI 平台能够安全落地的底线。
2. 语义化:让协议成为 AI 的"自描述文档"
在 0 到 1 构建平台时,我意识到,JSON 的 key 名必须具备极强的语义化。
例如,与其用 attr1: "line",不如用 chartType: "lineChart";与其使用 color: "#ff0000",不如配合 theme 对象进行更丰富的语义表达。
这种语义化的设计带来了意想不到的好处:当我在编写 Prompt 时,我不需要向 AI 解释太多,这些具备语义化的协议字段本身就是最好的说明文档。而且在开发中发现,协议设计的越接近自然语言,AI 生成的准确率就越高。
3. 分层设计:降低 AI 的生成复杂度,支持增量更新
一份完整的报表 JSON Schema 通常体量较大,包含数据源绑定、视觉样式、交互逻辑等多个维度。如果让 AI 一次性生成整个 Schema,很容易出现逻辑混乱或遗漏。
所以在设计时,需要将其拆分为三个相对独立的核心层级:
- 数据层(Data Layer) :定义"查什么",包括指标、维度、过滤条件、查询参数等;
- 表现层(Visual Layer) :定义"怎么看",包括图表类型、布局、颜色、标题、坐标轴等视觉元素;
- 交互层(Action Layer) :定义"怎么玩",包括下钻、联动、跳转、参数传递等交互行为。
这种分层架构极大地降低了 AI 的认知负担。更重要的是,它为后续的增量更新提供了基础。当用户提出"把这个柱状图改成堆叠样式"或"把主色调改为蓝色"时,AI 只需针对"表现层"进行局部 Patch 更新,而无需重新生成整个报表 Schema。这种局部修改机制,有效提升了响应速度和生成稳定性,是我在实际项目中验证过的最有效的工程实践之一。
数据集(Dataset)作为底层基石 :在低代码 BI 平台中,所有的组件------无论是筛选器、KPI 卡片、图表还是明细表格------都高度依赖数据集 。数据集定义了可用的字段列表 、指标(Measures) 、维度(Dimensions) 、计算逻辑、过滤条件以及数据查询参数。它是连接"业务意图"与"数据执行"的关键桥梁。
一个典型的数据集通常由开发人员或数据工程师通过 SQL 查询、dbt 模型或其他复杂任务预先构建和治理。AI 在此环节的应用主要不是直接生成原始数据集(以确保数据准确性和治理合规),而是对已有数据集进行智能总结和文档化 :自动提取字段描述、业务口径解释、常见使用场景、指标计算公式示例、数据质量提示等,形成结构化、语义丰富的数据集说明文档。
这些说明文档同样可以纳入 JSON Schema 的 数据层(Data Layer) 引用,例如通过 datasetId 关联,并提供丰富的元数据支持 AI 理解"这个字段的业务含义是什么""哪些指标适合趋势分析"等,从而让后续的 Schema 生成更加精准和业务化。
JSON Schema 不仅仅是一份数据协议,更像是一座桥梁。它连接了人类模糊的业务意图与机器精确的执行能力,为 AI 在 BI 低代码平台中的深度应用提供了坚实的基础。
第三章:工程实战 ------ 如何调教 AI 成为合格的"Schema 配置员"
有了 JSON Schema 这层明确的"契约"作为围栏,接下来最核心的问题就变成了:
如何让 AI 能够稳定、高质量地生成符合平台规范的 Schema?
在实际落地过程中,我没有简单地把 Schema 定义粗暴地扔给大模型,而是通过一系列工程化手段,系统性地解决了 AI 生成中的幻觉、逻辑混乱和上下文污染等问题。
1. 结构化上下文:低代码平台的"说明书工程"
实践中我很快意识到:
AI 生成质量,很大程度取决于你提供给它的"说明书质量"。
而低代码平台,天然就有一份极其复杂的说明书:
- 所有基础组件的配置文档
- 所有属性的枚举值
- 所有交互能力的约束
- 完整的数据集元数据与说明文档(字段列表、指标定义、维度口径、业务规则、数据样例等)
- 完整 JSON Schema 定义
数据集说明文档的 AI 辅助构建 :数据集本身仍建议由开发人员通过 SQL 或复杂 ETL/建模任务负责生成和维护,以保障数据准确性、性能和企业级治理(数据安全也需要考虑在内)。但 AI 可以高效承担"文档化"工作------输入数据集的 Schema 或样例数据后,AI 能自动生成详细的说明文档,包括:
- 每个字段的业务含义、数据类型、可能的值域
- 指标的计算逻辑、单位、常见使用场景与注意事项
- 维度之间的关联关系和过滤建议
- 数据质量提示(如缺失值比例、更新频率)
这些文档随后被放入专门的 文档说明 Agent(或扩展原有的"组件说明书 Agent"),采用渐进式检索方式。当 AI 需要生成涉及特定 datasetId 的 Schema 时,才动态查询相关数据集的说明,避免上下文过载。
从 JSON Schema 到 TypeScript Interface
在早期实验中,我直接把 JSON Schema 丢进 Prompt,结果并不理想。
随后我做了一个关键改造:
将 JSON Schema 转换为 TypeScript Interface 作为模型上下文。
建议 :在那个 TS 代码块里,增加一些
/ 注释 */。大模型对 TS Doc 的理解能力极强,在注释里写明字段的业务含义,能极大降低 AI 生成幻觉。
例如:
typescript
interface ChartConfig {
/** 关联具体数据集 */
datasetId: string;
/** 图表类型,趋势分析推荐 line,占比分析推荐 pie */
chartType: 'line' | 'bar' | 'pie'
/** 维度字段名,需从数据源元数据中选择 */
xField: string
/** 指标字段列表 */
yField: string[]
stack?: boolean
}相比冗长 JSON,TypeScript 具备:
- 清晰的层级结构
- 明确的类型约束
- 更符合大模型训练语料的表达方式
实践结果非常明显:
生成准确率显著提升。
基于 Agent Skill 的渐进式检索
真正的工程问题在下一步出现了:
即使是 TypeScript 版本的"说明书",
一次性全部提供仍然太大。
在实际工程中,我们构建了一个"1+N"的 Agent 体系:一个主编排 Agent 配合多个专业技能子 Agent。这种设计模仿了人类专家的查阅习惯:先看需求,再按需翻书。
数据流向勾勒:
- 意图解析:用户输入自然语言,主 Agent 识别出这是一个"创建报表"的任务。
- 依赖发现 :主 Agent 扫描需求,发现涉及
Dataset_A以及需要Chart和Filter组件。 - 按需检索(Progressive Retrieval) :
- 调用 Dataset Skill :获取
Dataset_A的字段业务含义及口径。 - 调用 Component Skill :仅检索
LineChart和RangeFilter的 TypeScript 定义,忽略其他无关组件。
- 调用 Dataset Skill :获取
- 上下文组装:将检索到的"局部知识"注入当前上下文,形成一份精简且极具针对性的 Prompt。
- Schema 生成:AI 在"懂业务(数据集)"且"懂规范(组件定义)"的状态下输出 JSON。
当 AI 需要生成某类组件时,才动态查询:
- Chart 组件说明
- Table 组件说明
- Filter 组件说明
- 特定 datasetId 的字段与业务文档
- Theme 配置说明
这种 渐进式检索(Progressive Retrieval) 带来了三个好处:
- 大幅降低 Token 成本
- 避免无关文档污染上下文
- 提升生成稳定性
为什么这个架构能解决"幻觉"?
- 减少干扰信息:如果一次性告诉 AI 平台有 50 个组件,它可能会把柱状图的属性写到饼图里。通过渐进式检索,AI 的视野里只有当前需要的那个组件协议。
- 字段强绑定 :通过 Dataset Skill 注入的字段名是具备"唯一性标识"的。AI 在配置
xField或yField时,是从一份确定的清单中选择,而不是靠"猜"。 - 解耦维护 :当平台增加新组件时,你只需要更新 Component Skill 的知识库,而不需要去重写那个冗长的主 Prompt。
2. Few-Shot 引导:给 AI 找几个"模板生"
大模型虽然强大,但在 BI 领域仍存在大量隐性业务规则,例如:
- 为什么趋势分析通常使用折线图?
- 为什么环形图要保留中心留白?
- 什么时候应该使用双轴图?
解决方案非常经典,但极其有效:
Few-Shot Prompting
在 Prompt 中加入"需求 → Schema"的示例对照组:
- 用户需求:对比过去 12 个月销售额和利润率的走势。
- 对应 Schema 片段(双轴折线图配置示例):
json
{
"componentType": "chart",
"chartType": "dualAxisLineChart",
"title": "过去12个月销售额与利润率走势对比",
"dataSource": {
"datasetId": "sales_monthly",
"dimensions": ["month"],
"measures": [
{ "field": "sales_amount", "name": "销售额", "yAxis": "primary" },
{ "field": "profit_rate", "name": "利润率", "yAxis": "secondary", "format": "percent" }
]
},
"visual": {
"xAxis": {
"field": "month",
"type": "category",
"labelRotate": 45
},
"yAxis": {
"primary": { "title": "销售额 (万元)", "position": "left" },
"secondary": { "title": "利润率 (%)", "position": "right" }
},
"legend": {
"show": true,
"position": "top"
},
"series": [
{ "type": "line", "smooth": true, "color": "#1890ff" },
{ "type": "line", "smooth": true, "color": "#52c41a" }
]
},
"layout": { "width": "100%", "height": 420 }
}实践证明,这种"给例子"的方式远比单纯的指令描述有效。它让 AI 不再是机械地填空,而是逐渐学会像一个有经验的数据分析师一样思考和配置报表。
3. 增量生成 + 校验-反馈闭环:构建可靠的生成流水线
一次性让 AI 生成整张复杂报表的完整 JSON Schema 是极不稳定的做法。我在实践中设计了一套结构化拆分 + 增量生成的流程:
由于 BI 报表的结构具有一定规律,我首先将用户整体需求按以下层级进行拆解:
- Header 区域:全局筛选器(日期范围、维度过滤器、参数控件等)
- Content 区域 (进一步拆分):
- 指标卡 / KPI 卡片组
- 主要图表区(可包含多个并列或上下布局的图表)
- 表格 / 明细数据区
- 辅助说明 / 文本组件
具体流程如下:
- 大模型根据当前阶段需求生成对应的 Schema 片段;
- 立即通过 JSON Schema Validator 进行严格校验;
- 校验通过后,系统将 Schema 实时渲染到低代码平台的 Preview 界面;
- 加入人工审核节点:用户可在可视化界面中直观查看生成效果;
- 若不通过,则将错误信息和用户反馈一并返回给大模型,进行 Self-Correction(自我纠错)或调整;
- 审核通过后,携带已验证的上一轮 Schema 作为上下文,继续下一轮生成。
文字版流程图:
text
用户自然语言需求
↓
需求结构拆解 Agent(拆分为 Header + KPI + Chart1 + Chart2 + Table 等模块)
↓
开始增量生成循环:
┌────────────────────────────┐
│ 1. 生成 Header 筛选器 Schema │
└──────────┬─────────────────┘
↓
Validator 校验 → 实时 Preview 渲染 → 人工审核
↓
通过? → 是 → 携带已验证 Schema 进入下一模块
↓ 否
将错误信息 + 用户反馈 → 返回给 LLM 进行 Self-Correction
↓
┌─────────────────────────────┐
│ 2. 生成 KPI 指标卡 Schema │
└──────────┬──────────────────┘
↓ (同上流程)
┌───────────────────────────────────┐
│ 3. 生成具体图表 Schema(如双轴折线图) │
└──────────┬────────────────────────┘
↓ (同上流程)
┌─────────────────────────────┐
│ 4. 生成表格或其他组件 Schema │
└──────────┬──────────────────┘
↓
最终合并所有通过验证的 Schema 片段 → 完整报表 JSON图片版流程图: 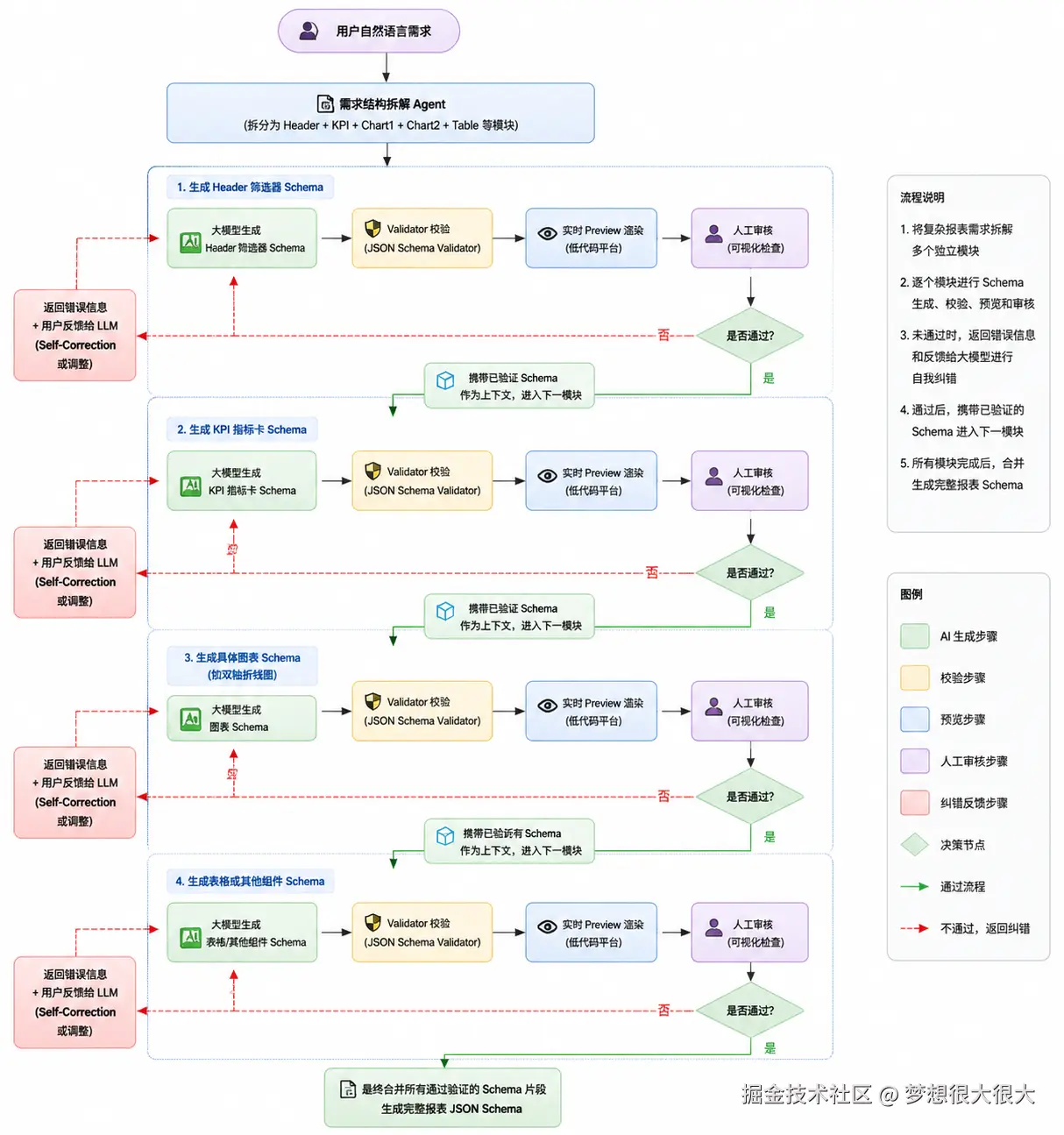
整个流程采用增量生成方式:每生成一个模块,就立即进行 Validator 校验 → 实时渲染到低代码平台的 Preview 界面 → 加入人工审核节点。用户可在可视化界面中直观检查效果,不满意则携带具体错误信息和修改意见反馈给大模型进行调整。通过这种闭环机制,最终输出的 Schema 既严格符合平台规范,又能快速贴近业务实际需求。
通过以上三方面的系统实践,AI 逐渐从一个"不靠谱的画手",转变成了一个能够理解平台规范、遵守契约、支持迭代的合格"Schema 配置员"。
第四章:AI 赋能下的 BI 报表开发重塑 ------ 效率、体验与协作模式升级
这一章内容主要在 AI 辅助思考下完成的,说实话我自己对于这方面的思考并没有这么深入,不过 AI 确实能给 BI 带来一些新东西。
经过前期的架构设计与工程调教,AI 终于能够较为稳定地输出符合规范的 JSON Schema。但在真实的业务环境中,这种能力究竟带来了哪些本质的改变?
1. 开发流程的明显改善
在引入 AI 生成 JSON Schema 能力之前,一张中等复杂度的业务报表(通常包含筛选器、多个图表、表格以及联动交互),从需求沟通到最终上线,往往需要较长的周期。其中大量时间消耗在需求理解、组件拖拽配置、交互调试以及反复修改上。
集成 AI 辅助生成后,流程发生了较为显著的变化:
业务人员可以用自然语言描述需求,例如:"我想看过去 12 个月各区域、各产品线的销售额、利润率和转化率趋势,支持按区域下钻,并与去年同期进行对比。" AI 能够在较短时间内生成一个结构完整的初始 JSON Schema,并实时渲染到预览界面。这使得早期原型构建的速度明显加快,减少了大量机械性的配置工作。
当然,这种效率改善并非无条件的。它建立在前期对低代码平台、Prompt 体系、校验机制和增量生成流程进行大量投入的基础上。在项目初期,搭建这套 AI 能力本身也需要不小的开发量,后续还需持续维护 Prompt 质量、处理模型版本迭代带来的兼容性问题。因此,短期内整体投入可能并不会显著降低,但在中长期,随着体系逐渐成熟,报表从需求到上线的整体周期和迭代成本通常会得到明显改善,尤其是在需求频繁变化的场景中。
2. 典型应用场景重塑
在实际使用过程中,AI + JSON Schema 的组合在以下几类场景中展现出了较强的实用价值:
(1)快速原型生成场景 业务部门经常会提出一些探索性或紧急的分析需求。过去这类需求往往需要开发或分析师投入较多时间制作初版。现在,AI 可以快速生成一个可预览的初始 Schema,其中会智能推荐合适的数据集字段作为维度和指标,让业务人员在几分钟内看到大致的报表形态,从而大幅加快早期反馈和需求澄清的速度。
(2)复杂布局与多组件仪表板场景 对于包含多个图表、交叉过滤和联动下钻的复杂仪表板,AI 在生成初始布局和组件关联关系时,能够一次性完成较为合理的结构安排,后续人工在低代码画布上进行调整的工作量明显减少。
(3)迭代优化场景 当业务人员提出修改意见时(如"把柱状图改为堆叠样式""只显示 Top 8 产品""调整主色调"),AI 支持的局部 Schema Patch 更新机制能够快速响应,而无需重新生成整个报表。这种增量式修改方式,让迭代过程变得更加轻量和高效。
(4)风格统一与模板化场景 在企业级环境中,保持大量报表的视觉风格一致是一项繁琐的工作。AI 可以较好地理解并应用"统一主题风格""品牌配色规范"等要求,帮助批量调整或生成符合企业视觉标准的报表,降低了风格维护的重复劳动。
3. 人机协作新模式:AI 生成初稿 + 低代码可视化精修
通过实践,我认为目前最稳健且推荐的协作模式是:
AI 负责生成初稿(大部分结构和常规配置) + 人工在低代码画布上进行精修和最终把关
AI 的优势在于快速理解模糊的业务意图、生成结构化的 Schema,以及处理常规的图表推荐和布局计算;而人工的优势则体现在精细的视觉调整、复杂业务逻辑的校验、企业级治理要求(如权限、安全、性能)的把控,以及最终的质量保障上。
保留低代码可视化编辑界面非常重要。它不仅是细节调整的工具,更是建立信任的关键环节------只有当业务人员和开发者能够直观地看到并修改 AI 生成的结果时,才会对最终报表产生足够的掌控感和安全感。
这种"AI 大量生产 + 人工高质量把关"的模式,既充分发挥了 AI 的速度优势,又没有放弃 BI 平台在企业级应用中必需的确定性、可维护性和治理能力。
4. 更深层的价值:生产力解放与角色转变
虽然短期投入不小,但当 AI 生成能力逐步稳定后,最大的变化发生在人和组织层面。
开发者能够从大量重复的拖拽配置和基础属性调整中解放出来,有更多时间和精力投入到更高价值的工作中,例如:完善企业语义层建设、优化数据查询性能、加强数据治理、设计更先进的分析模型等。
业务人员也从单纯的"提需求、等报表"角色,逐渐转变为可以共同参与报表设计的角色。他们的业务洞察能够更快地转化为可视化成果,数据驱动决策的闭环变得更加顺畅。
第五章:实战建议 ------ 如何更好地将 AI 引入 BI 低代码平台
以下是几点我认为比较重要的实战建议,供正在做类似尝试的团队参考:
1. 不要追求一步到位,先做"可用"再做"优秀"
AI 生成 Schema 的能力很有吸引力,但不要一开始就试图覆盖所有报表类型。 建议从高频、结构相对固定、业务规则清晰的报表场景开始切入,例如:
- 月度经营分析仪表板
- 销售漏斗分析
- KPI 概览页
这些场景需求重复度高,容易积累高质量的 Few-Shot 示例,也更容易看到效果。
2. 把语义层建设作为重中之重
AI 生成质量的好坏,很大程度上取决于你给它的"知识底座"有多清晰。 在我看来,最值得优先投入的是企业级语义层 (指标定义、维度口径、业务规则等)以及与之紧密关联的数据集说明文档。
数据集的构建与 AI 文档化实践:
- 数据集的创建和核心逻辑仍由开发/数据工程师负责(通过 SQL、复杂查询或建模工具),以确保数据安全、性能和一致性。
- AI 的价值在于辅助文档化:让 AI 对数据集进行总结,输出结构化、详尽的说明文档(字段解释、业务口径、推荐用法、示例查询等)。
- 将这些文档统一纳入"文档说明 Agent",支持渐进式检索。当生成报表 Schema 时,AI 可以按需拉取对应数据集的知识,避免"猜字段"或使用错误口径的问题。
语义层越完善,AI 就越不容易犯低级错误,后续 Prompt 维护的成本也会显著降低。
3. 坚持"AI 生成初稿 + 低代码人工精修"的协作模式
目前阶段,我强烈建议不要完全取消低代码可视化编辑界面。 最佳实践是让 AI 负责生成大部分结构和常规配置,人工则在熟悉的画布上进行:
- 业务逻辑的最终校验
- 视觉样式和品牌规范的调整
- 性能和权限的把控
这种模式既能享受 AI 带来的速度,也能保证企业级报表的质量和安全性。
4. 重视闭环反馈机制
把用户的每一次修改都视为宝贵数据。 建议建立机制,将用户在 Preview 界面上的调整意见、修改后的 Schema 等,定期反馈到 Prompt 优化或 Few-Shot 示例库中。这样可以让 AI 的生成质量逐步提升,形成正向循环。
5. 控制期望,做好长期投入的准备
引入 AI 确实能让"用户通过几句对话就能唤醒报表"的愿景更接近现实,但它不是银弹。 前期需要投入较多精力建设基础设施,后续也需要持续维护 Prompt 和知识库。 如果能接受这一点,把它当作一次长期的能力建设,而不是短期见效的项目,落地会 smoother 很多。
结语:AI 不会取代 BI,但会重新定义 BI 的"入口"
从最早手写 SQL 做报表,到后来搭建低代码平台,再到今天尝试让 AI 自动生成 JSON Schema,这一路走来,我对 BI 的理解也在不断变化。
曾经我以为,BI 的核心是数据建模能力 。
后来我以为,BI 的核心是可视化与低代码能力 。
而现在,我越来越觉得------
BI 的真正瓶颈,从来都不是技术,而是"表达"。
业务人员脑海里其实早就有问题:
- 为什么这个月转化率下降?
- 哪个区域增长最快?
- 新产品的销售趋势怎么样?
问题从来不缺,缺的是一种足够低门槛的表达方式,让这些问题可以快速转化为可执行的数据分析。
过去,这种表达必须通过:
需求文档 → 产品经理 → 数据分析师 → 开发 → 报表上线
而今天,我们开始看到一种新的可能:
自然语言 → AI → JSON Schema → 可视化报表
这条链路的关键,并不是"AI 直接生成报表",而是:
AI 成为了 BI 平台的"自然语言入口"。
低代码平台依然存在,JSON Schema 依然存在,数据建模与语义层依然重要------
它们并没有被 AI 取代,而是成为了 AI 能够安全落地的基础设施。
如果说过去低代码平台解决的是
"让不会写代码的人也能做报表"
那么现在 AI 正在解决的是
"让不知道该怎么配置的人也能开始分析数据"
这两件事,本质上是一脉相承的。
在可预见的未来,我并不认为 BI 工具会被"聊天界面"完全取代。
更可能发生的是:
- 聊天对话,成为报表创建的起点
- 低代码画布,成为报表完善的工作台
- 数据建模与语义层,成为整个体系的地基
而开发者的角色,也会逐渐从"报表生产者",转变为:
- 语义层建设者
- 数据治理与质量守护者
- 平台能力设计者
- 人机协作流程的架构师
回头看,我们似乎一直在做同一件事:
不断降低人与数据之间的距离。
而 AI 的出现,只是让这段距离,第一次变得如此之短。