前端面试集锦-不断完善中ing
1. 请谈谈var,let,const的区别
1、作用域(Scope)
- var:函数作用域,即在函数内声明的变量在整个函数内可见
javascript
function exampleVar() {
if (true) {
var x = 10;
}
console.log(x); // 输出10,var无视块级作用域
}
exampleVar();- let/const:块级作用域,仅在声明所在的代码块内有效。
javascript
function exampleLet() {
if (true) {
let y = 20;
const z = 30;
}
console.log(y); // 报错:y未定义
console.log(z); // 报错:z未定义
}
exampleLet();2、变量提升与暂时性死区(Hoisting & TDZ)
- var:变量提升至作用域顶部,初始值为undefined。
javascript
console.log(a); // undefined
var a = 5;- let/const:变量虽被提升,但在声明前访问会触发暂时性死区(TDZ),抛出错误。
javascript
console.log(b); // 报错:Cannot access 'b' before initialization
let b = 10;3、重复声明与重新赋值
- var:同一作用域内允许重复声明,且支持重新赋值。
javascript
var x = 1;
var x = 2; // 合法,覆盖前值
x = 3; // 合法- let:禁止重复声明,但允许重新赋值。
javascript
let y = 1;
let y = 2; // 报错:Identifier 'y' has already been declared
y = 3; // 合法- const:必须初始化,禁止重复声明和重新赋值(对象属性修改除外)。
javascript
const PI = 3.14;
PI = 3.14159; // 报错:Assignment to constant variable
const obj = { name: "Alice" };
obj.name = "Bob"; // 合法,修改对象属性
obj = {}; // 报错:不可重新赋值4、全局对象属性绑定
- var:在全局声明时会成为全局对象(如 window)的属性。
javascript
var a = 1;
console.log(window.a); // 1- let/const:不会成为全局对象的属性。
javascript
let b = 2;
const c = 3;
console.log(window.b); // undefined
console.log(window.c); // undefined5、循环中的行为差异
- var:在循环中共享同一变量,易引发闭包问题。
javascript
for (var i = 0; i < 3; i++) {
setTimeout(() => console.log(i), 100); // 输出3, 3, 3
}- let:每次迭代创建新的变量绑定,解决闭包问题。
javascript
for (let j = 0; j < 3; j++) {
setTimeout(() => console.log(j), 100); // 输出0, 1, 2
}6、使用场景与最佳实践
- const:默认使用,用于不变的引用类型
javascript
const API_URL = "https://api.example.com";
const config = { key: "value" };- let:仅在需要重新赋值时使用。
javascript
let count = 0;
for (let i = 0; i < 10; i++) {
count += i;
}- var:尽量避免使用,容易导致作用域混乱。
附录: 暂时性死区(TDZ)
暂时性死区(Temporal Dead Zone, TDZ) 是 JavaScript 中 let 和 const 声明的变量在代码块中从作用域开始到变量声明语句之间的一段不可访问区域。这是 ES6 引入的重要特性,用于解决变量提升导致的意外行为。
|
变量提升差异:var 声明的变量会被提升到作用域顶部并初始化为 undefined,而 let/const 虽然也会被提升,但不会初始化(即处于未绑定状态)。
|
console.log(a); // undefined (var)
var a = 1;
console.log(b); // 报错 (let)
let b = 2;
|
TDZ 的形成:当代码进入块级作用域时,let/const 变量会立即创建绑定,但在物理位置上的声明语句之前,该变量无法被访问。这段从作用域开始到声明语句的区域称为 TDZ。
2. JS中的数据结构有哪些?
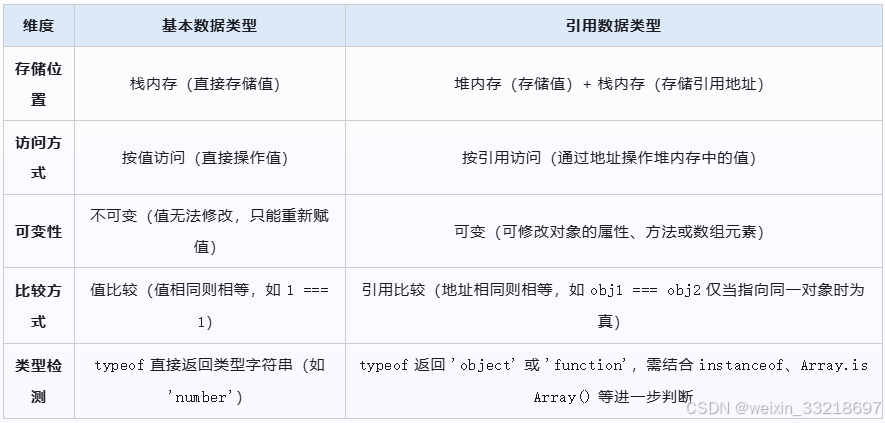
JavaScript 的数据类型分为两大类:基本数据类型(原始类型)和引用数据类型(对象类型),共 8 种内置类型。
1、基本数据类型(7 种)
基本数据类型直接存储在栈内存中,按值访问,不可变(值一旦创建无法修改,只能重新赋值),除 null 和 undefined 外,其他类型都有对应的包装对象。
-
Number(数字类型)
- 定义:表示整数和浮点数,采用 IEEE 754 标准的双精度 64 位浮点数格式,可表示整数、小数、正数、负数、科学计数法等。
- 特殊值:NaN(非数字,与自身不相等,需用 isNaN() 判断)、Infinity(正无穷)、-Infinity(负无穷)。
- 安全范围:最大安全整数为 2^53 - 1(即 Number.MAX_SAFE_INTEGER),最小安全整数为 -(2^53 - 1)(即 Number.MIN_SAFE_INTEGER)。
- 注意:浮点数存在精度问题(如 0.1 + 0.2 !== 0.3,结果为 0.30000000000000004)。
-
String(字符串类型)
- 定义:表示文本数据,由字符组成的序列,可用单引号、双引号或反引号(模板字符串)定义。
- 特性:字符串不可变,所有字符串操作(如拼接、截取)都会生成新字符串,原字符串不会被修改。
- 示例:'hello'、"world"、模板字符串。
-
Boolean(布尔类型)
- 定义:只有两个值:true(真)和 false(假),常用于逻辑判断。
- 布尔转换:在布尔上下文中,以下值会被转换为 false(称为 "假值"):false、0、-0、0n(BigInt 的 0)、""(空字符串)、null、undefined、NaN,其余值均为 "真值"。
- 注意:尽量避免使用 new Boolean() 创建包装对象,因为对象在布尔上下文中始终为真值,与预期可能不符。
-
Undefined(未定义类型)
- 定义:表示变量已声明但未赋值,或函数无返回值时的默认值,访问对象不存在的属性时也会返回 undefined。
- 特性:是唯一值为 undefined 的类型,变量声明后未赋值时默认值为 undefined。
-
Null(空值类型)
- 定义:表示 "空值" 或 "无效引用",通常用于显式声明变量为空(如初始化变量)。
- 注意:typeof null 返回 "object",这是 JavaScript 的历史遗留 Bug,实际 null 是独立的原始类型。
-
Symbol(符号类型,ES6 新增)
- 定义:表示唯一且不可变的标识符,主要用于创建对象的唯一属性名,避免属性名冲突。
- 特性:每次调用 Symbol() 都会生成唯一值,即使描述相同,值也不同(如 Symbol('key') === Symbol('key') 结果为 false)。
- 示例:const sym = Symbol('description'),可用于对象属性键。
-
BigInt(大整数类型,ES2020 新增)
- 定义:用于表示超过 Number 类型最大安全整数范围的任意精度整数,解决大整数精度丢失问题。
- 语法:在整数后加 n 后缀,或通过 BigInt() 函数转换(不能使用 new 运算符)。
- 特性:不能与 Number 类型混合运算,否则会报错;不能用于 Math 对象的方法。
- 示例:123456789012345678901234567890n、BigInt('9007199254740991')。
2、引用数据类型(1 种核心类型,包含多种子类型)
引用数据类型统称为 Object,存储在堆内存中,变量存储的是指向堆内存的引用(地址),而非值本身,可变(可修改对象的属性或方法),通过引用访问。
- Object(对象类型)
- 定义:最通用的引用类型,用于存储键值对集合(属性和方法),是所有引用类型的基类。
- 创建方式:对象字面量 {}、new Object()、构造函数等。
子类型:包括数组(Array)、函数(Function)、日期(Date)、正则表达式(RegExp)、Map、Set、Promise 等,本质上都是 Object 的实例。 - 特性:对象可动态添加、删除或修改属性,属性值可以是基本类型或引用类型。
- 示例:
- 普通对象:{ name: 'John', age: 25 };
- 数组:1, 2, 3, 'hello';
- 函数:function add(a, b) { return a + b; }。
3、核心差异总结
4、类型检测方法
-
typeof:用于检测基本类型和函数,返回类型字符串。
- 支持`:'string'、'number'、'boolean'、'undefined'、'symbol'、'bigint'、'function';
- 局限:对 null 返回 'object'(历史 Bug),无法区分数组和普通对象(均返回 'object')。
-
instanceof:用于检测对象是否为某个构造函数的实例,基于原型链判断。
- 示例:\[\] instanceof Array 返回 true,\[\] instanceof Object 返回 true(因为数组的原型链指向 Object)。
-
Array.isArray():专门用于判断是否为数组,弥补 typeof 的不足。
- 示例:Array.isArray(1, 2, 3) 返回 true,Array.isArray({}) 返回 false。
-
Object.prototype.toString.call():最准确的类型检测方法,返回格式为 object 类型 的字符串,可区分所有内置类型。
- 示例:Object.prototype.toString.call(\[\]) 返回 'object Array',Object.prototype.toString.call(null) 返回 'object Null'。
3. 数据类型typeof的陷阱
1、JavaScript 数据类型概览
- JavaScript 分为 原始类型(Primitive) 和 引用类型(Reference):

2、typeof 的常见陷阱与解决方案
- ①. 无法区分 null 和对象
javascript
console.log(typeof null); // "object"(历史遗留错误)
console.log(null instanceof Object); // false- 解决方案:联合检查
javascript
if (value !== null && typeof value === "object") {
// 确定是对象(排除 null)
}- ②. 数组被识别为 object
javascript
console.log(typeof []); // "object"
console.log(Array.isArray([])); // true(推荐)- 替代方案:
javascript
// 使用 toString 方法
Object.prototype.toString.call([]); // "[object Array]"- ③. 无法识别具体构造函数类型
javascript
class User {}
const user = new User();
console.log(typeof user); // "object"
console.log(user instanceof User); // true- 解决方案:组合 instanceof 或检查构造函数名称
javascript
console.log(user.constructor.name); // "User"- ④. NaN 的类型误判
javascript
console.log(typeof NaN); // "number"(尽管语义上表示非数字)
console.log(Number.isNaN(NaN)); // true(推荐)-
注意:全局 isNaN() 会强制转换类型,应优先使用 Number.isNaN()。
-
⑤. typeof 对未声明变量的行为
javascript
console.log(typeof undeclaredVar); // "undefined"(不会报错!)
let declaredVar;
console.log(typeof declaredVar); // "undefined"- 建议:始终使用 let/const 声明变量,避免依赖此特性。
3、特殊场景与高级技巧
- ①. 区分 Promise 对象
javascript
const p = Promise.resolve();
console.log(typeof p); // "object"
console.log(p instanceof Promise); // true- ②. 检测 arguments 对象
javascript
function func() {
console.log(typeof arguments); // "object"
console.log(Array.isArray(arguments)); // false
}
func(1, 2);- ③. Symbol 类型的兼容性
javascript
const sym = Symbol("key");
console.log(typeof sym); // "symbol"
console.log(sym instanceof Symbol); // false(Symbol 不是构造函数)4、最佳实践总结

5、综合案例演示-工具函数
javascript
// 综合类型检测工具函数
function getType(value) {
const type = typeof value;
if (value === null) return "null";
if (Array.isArray(value)) return "array";
if (value instanceof RegExp) return "regexp";
if (value instanceof Map) return "map";
return type;
}
// 测试用例
console.log(getType(null)); // "null"
console.log(getType([])); // "array"
console.log(getType(/a/g)); // "regexp"
console.log(getType(new Map())); // "map"
console.log(getType(42)); // "number"4. JS如何在内存中存储数据的?
值类型 vs 引用类型
JavaScript 在内存中存储数据的方式主要通过 栈内存(Stack) 和 堆内存(Heap) 实现,具体取决于数据的类型(基本类型 vs. 引用类型)。以下是详细说明:
1、栈内存(Stack):基本数据类型的存储区域
- 存储特点
- 直接存储值:基本数据类型(如 Number、String、Boolean、undefined、null、symbol、bigint)的值直接存储在栈内存中。
- 固定大小:每个变量占用的空间大小固定,由引擎预先分配。
- 自动管理:栈内存的分配和释放由系统自动完成,遵循后进先出原则。
示例
javascript
let num = 10; // 栈中直接存储数值 10
let str = "hello"; // 栈中存储字符串字面量 "hello"- 复制行为
- 当复制基本类型变量时,会生成完全独立的副本,修改新变量不会影响原变量。
javascript
let a = 10;
let b = a; // 复制值到新栈空间
b = 20; // 仅修改b的栈内值
console.log(a); // 输出10(不受影响)2、堆内存(Heap):引用数据类型的存储区域
- 存储特点
- 存储引用地址:对象、数组、函数等引用类型的实际数据存储在堆内存中,栈内存仅保存其引用地址(指针)。
- 动态大小:堆内存空间可动态扩展,适合存储大小不固定的数据。
- 垃圾回收机制:通过标记清除等算法自动回收不再被引用的对象。
- 示例
javascript
let obj = { x: 1 };
// 栈中存储obj的引用地址(指向堆中{x:1}的实际数据)- 复制行为
- 复制引用类型变量时,栈中的引用地址会被复制,新旧变量指向堆中同一对象。
javascript
let obj1 = { a: 10 };
let obj2 = obj1; // 复制引用地址
obj2.a = 100; // 修改堆中对象的属性
console.log(obj1.a); // 输出100(同步变化)3、特殊场景与注意事项
- 函数存储机制
- 函数作为引用类型存储在堆中,其代码以字符串形式保存,函数名在栈中存储指向堆的地址。
- 即使两个函数功能相同,它们在堆中的存储地址也不同,因此比较结果为 false。
javascript
function fun1() { console.log(111); }
function fun2() { console.log(111); }
console.log(fun1 === fun2); // false(地址不同)- 内存泄漏风险
- 若未及时解除对堆中对象的引用(如全局变量、闭包),可能导致垃圾回收失败,引发内存泄漏。
- 解决建议:使用 WeakMap 或手动置空引用(如 obj = null)。
JavaScript通过栈内存高效管理基本类型数据,通过堆内存灵活存储复杂对象,二者协同工作并由引擎自动管理内存分配与回收。这一机制有助于优化性能并规避常见内存问题
附录
参数传递的本质:「值的复制」而非「引用的共享」
1. 值类型参数传递:复制值本身,互不影响当把一个值类型变量作为参数传递给函数时,引擎会在函数的作用域中创建一个新变量,把栈中原变量的值完整复制一份到新变量中,两者是完全独立的。函数内对新变量的修改,不会作用于外部原变量,因为它们指向的是栈内存中不同的空间。
`
内存变化过程拆解:初始状态:栈中primitive存储数值10;
调用updateValue(primitive)时:栈中创建新变量num,将primitive的值10复制给num;
函数内修改num:num被赋值为15,但外部的primitive始终是10,两者完全隔离;
函数执行结束:num随函数作用域销毁,不影响外部变量
javascript
let primitive = 10;
function updateValue(num) {
// 函数内,num是复制出来的新变量,和外部的primitive独立
num += 5; // 修改的是函数内的num,不影响外部的primitive
console.log("函数内num:", num); // 15
}
updateValue(primitive);
console.log("外部primitive:", primitive); // 仍为102. 引用类型参数传递:复制指针的值,共享堆中对象
当把一个引用类型变量作为参数传递给函数时,引擎同样会在函数的作用域中创建一个新变量,但复制的是「栈中原变量的指针(地址)」,而不是堆中的对象本身。此时,函数内的新变量和外部变量指向堆内存中的同一个对象------所以通过新变量修改对象属性,会直接影响堆中的同一个对象,外部变量访问时会看到修改后的结果。
`
内存变化过程拆解:初始状态:栈中person存储指针地址0x123,堆中地址0x123对应的对象是{ age:25 };
调用updateObject(person)时:栈中创建新变量obj,将person的指针地址0x123复制给obj;
函数内修改obj.age:通过指针0x123找到堆中的对象,将age改为30;
函数执行结束:obj随函数作用域销毁,但堆中的对象已被修改,外部person的指针仍指向该对象,所以能看到修改后的结果。
javascript
let person = { age: 25 };
function updateObject(obj) {
// 函数内,obj是复制出来的新变量,但它存的是和person一样的指针(地址)
obj.age = 30; // 通过指针找到堆中的对象,修改对象的属性
console.log("函数内obj.age:", obj.age); // 30
}
updateObject(person);
console.log("外部person.age:", person.age); // 305. 谈谈深拷贝和浅拷贝
1、核心概念与本质区别
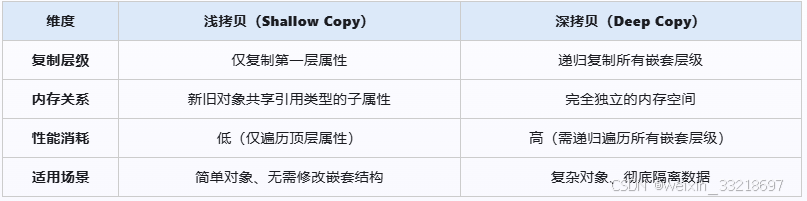
javascript
// 浅拷贝示例
const original = { a: 1, b: { c: 2 } };
const shallow = Object.assign({}, original);
shallow.b.c = 3;
console.log(original.b.c); // 输出3(修改了原对象)
// 深拷贝示例
const deep = JSON.parse(JSON.stringify(original));
deep.b.c = 4;
console.log(original.b.c); // 仍为2(未受影响)2、浅拷贝的常见实现方式与局限
-
- Object.assign()
javascript
const obj = { x: 1, y: { z: 2 } };
const copy = Object.assign({}, obj);
copy.y.z = 3;
console.log(obj.y.z); // 3(嵌套属性共享引用)-
- 展开运算符(...)
javascript
const arr = [1, [2, 3]];
const newArr = [...arr];
newArr[1][0] = 99;
console.log(arr[1][0]); // 99(数组元素共享引用)-
- 局限性
无法处理特殊类型:如 Date、RegExp、Set 等会被转换为普通对象。
循环引用崩溃:若对象存在自身引用(如 obj.self = obj),会触发栈溢出。
- 局限性
3、深拷贝的高级实现方案
-
- JSON 序列化法(通用但不完美)
javascript
function jsonDeepClone(obj) {
return JSON.parse(JSON.stringify(obj));
}
// 测试
const data = { a: 1, b: { c: Date.now() } };
const cloned = jsonDeepClone(data);
console.log(cloned.b.c instanceof Date); // false(日期被转为字符串)-
- 递归拷贝(完整版)
javascript
function recursiveDeepClone(obj, hash = new WeakMap()) {
if (obj === null || typeof obj !== "object") return obj;
if (hash.has(obj)) return hash.get(obj); // 解决循环引用
const cloned = Array.isArray(obj) ? [] : {};
hash.set(obj, cloned);
for (let key in obj) {
if (obj.hasOwnProperty(key)) {
cloned[key] = recursiveDeepClone(obj[key], hash);
}
}
return cloned;
}
// 支持特殊类型扩展
recursiveDeepClone.prototype.handleSpecialTypes = function(obj) {
if (obj instanceof Date) return new Date(obj);
if (obj instanceof RegExp) return new RegExp(obj);
return obj;
};-
- 结构化克隆 API(现代浏览器原生支持)
javascript
// Chrome 67+ / Firefox 55+ / Edge 79+
const cloned = structuredClone(original);
// 支持特性:
// - 保留对象类型(Date、RegExp、Map、Set等)
// - 自动处理循环引用
// - 转移所有权(TransferList)
const transferred = structuredClone(largeBuffer, [largeBuffer]); // 转移TypedArray所有权4、工程实践中的选择策略
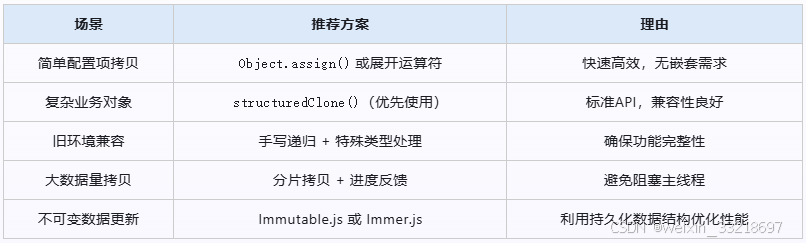
5、经典避坑指南
-
1.不要滥用深拷贝
频繁深拷贝大对象会导致性能急剧下降,优先考虑不可变更新模式。
-
2.警惕原型链污染
javascript
const maliciousObj = Object.create(null);
maliciousObj.__proto__.constructor = dangerousCode;
const safeClone = JSON.parse(JSON.stringify(maliciousObj)); // 安全!- 3.循环引用检测必做
javascript
function safeDeepClone(obj, seen = new Map()) {
if (seen.has(obj)) return seen.get(obj);
// ... 继续实现
}- 4.特殊类型需单独处理
javascript
if (obj instanceof Blob) return obj.slice(); // 文件对象特殊处理6. 数组中常用的方法和高阶函数
1、修改原数组的方法
- push():向数组末尾添加一个或多个元素,返回新长度。
javascript
const arr = [1, 2];
arr.push(3, 4); // arr变为[1, 2, 3, 4],返回4- pop():删除数组最后一个元素,返回被删除的元素。
javascript
const arr = [1, 2, 3];
arr.pop(); // arr变为[1, 2],返回3- unshift():向数组开头添加元素,返回新长度。
javascript
const arr = [1, 2];
arr.unshift(0); // arr变为[0, 1, 2],返回3- shift():删除数组第一个元素,返回被删除的元素。
javascript
const arr = [1, 2, 3];
arr.shift(); // arr变为[2, 3],返回1- splice():万能增删改,可指定位置添加/删除/替换元素,返回被删除的元素数组。
javascript
const arr = [1, 2, 3, 4];
arr.splice(1, 2, 'a'); // 从索引1开始删除2个元素,插入'a',arr变为[1, 'a', 4],返回[2, 3]- reverse():反转数组顺序,直接修改原数组。
javascript
const arr = [1, 2, 3];
arr.reverse(); // arr变为[3, 2, 1]- sort():对数组排序,默认按字符串Unicode码点排序,可自定义比较函数。
javascript
const arr = [3, 1, 2];
arr.sort((a, b) => a - b); // 升序排列,arr变为[1, 2, 3]- fill():用固定值填充数组指定区间元素,覆盖原有值。
javascript
const arr = [1, 2, 3, 4];
arr.fill(0, 1, 3); // 从索引1到3(不含)填充0,arr变为[1, 0, 0, 4]- copyWithin():将数组指定区间元素拷贝到目标位置,覆盖原有元素。
javascript
const arr = [1, 2, 3, 4, 5];
arr.copyWithin(0, 1, 3); // 把索引1 - 3的元素拷贝到索引0的位置,arr变为[2, 3, 3, 4, 5]2、不修改原数组的方法
- concat():合并两个或多个数组/值,生成新数组。
javascript
const arr1 = [1, 2];
const arr2 = [3, 4];
const newArr = arr1.concat(arr2); // [1, 2, 3, 4]- slice():截取数组指定区间元素,生成新数组,原数组不变。
javascript
const arr = [1, 2, 3, 4];
const newArr = arr.slice(1, 3); // [2, 3],原数组仍为[1, 2, 3, 4]- join():将数组所有元素连接成字符串,可指定分隔符。
javascript
const arr = ['a', 'b', 'c'];
const str = arr.join('-'); // "a-b-c"- toString():将数组转换为字符串,以逗号分隔元素。
javascript
const arr = [1, 2, 3];
const str = arr.toString(); // "1,2,3"- indexOf():查找元素首次出现的索引,未找到返回-1。
javascript
const arr = [1, 2, 3];
const index = arr.indexOf(2); // 1- lastIndexOf():查找元素最后一次出现的索引,未找到返回-1。
javascript
const arr = [1, 2, 3, 2];
const index = arr.lastIndexOf(2); // 3- includes():判断数组是否包含某元素,返回布尔值。
javascript
const arr = [1, 2, 3];
const hasTwo = arr.includes(2); // true- 数组去重
javascript
//方法1:
const arr = [1, 2, 2, null, undefined, NaN, {}, {}];
const unique = [...new Set(arr)];
console.log(unique); // [1, 2, null, undefined, NaN, {}, {}]
//方法2:
const arr = [1, 2, 2, 'a', 'a'];
const unique = Object.keys(arr.reduce((acc, val) => {
acc[val] = true;
return acc;
}, {})).map(key => key);
// 或简写为:
const unique = [...new Set(arr)]; // 优先推荐此写法
//方法3:
const arr = [1, 2, 2, 3];
const unique = arr.filter((item, index) => arr.indexOf(item) === index);
console.log(unique); // [1, 2, 3]
//方法4:
const arr = [1, 2, 2, 3];
const unique = arr.reduce((acc, cur) => {
if (!acc.includes(cur)) acc.push(cur);
return acc;
}, []);
console.log(unique); // [1, 2, 3]3、迭代与高阶函数
- forEach():遍历数组每一项,无返回值。
javascript
const arr = [1, 2, 3];
arr.forEach((item, index) => console.log(index, item)); // 输出索引和元素- map():对数组每一项执行函数,返回新数组。
javascript
const arr = [1, 2, 3];
const doubled = arr.map(x => x * 2); // [2, 4, 6]- filter():筛选出通过测试的元素,返回新数组。
javascript
const arr = [1, 2, 3, 4];
const evens = arr.filter(x => x % 2 === 0); // [2, 4]- reduce():从左到右累加计算,返回最终结果。
javascript
const arr = [1, 2, 3, 4];
// 0 初始值
const sum = arr.reduce((acc, curr) => acc + curr, 0); // 10- find():返回满足条件的首个元素,否则返回undefined。
javascript
const arr = [5, 12, 8];
const found = arr.find(x => x > 10); // 12- findIndex():返回满足条件的首个元素的索引,否则返回-1。
javascript
const arr = [5, 12, 8];
const index = arr.findIndex(x => x > 10); // 1- every():判断所有元素是否满足条件,返回布尔值。
javascript
const arr = [1, 2, 3];
const allEven = arr.every(x => x % 2 === 0); // false- some():判断是否存在元素满足条件,返回布尔值。
javascript
const arr = [1, 2, 3];
const hasEven = arr.some(x => x % 2 === 0); // true7. 对象遍历方式对比
一 解析: for...in / Object.keys() / Reflect.ownKeys()
1. for...in:遍历自身+原型链可枚举属性
for...in 是 JavaScript 最早的对象遍历语法,核心特性是"遍历原型链上的所有可枚举属性",这是其与另外两种方式的本质区别。
- (1)基础语法
javascript
for (const key in obj) {
// key:遍历到的属性名(字符串)
// 建议配合 hasOwnProperty 过滤原型链继承属性
if (obj.hasOwnProperty(key)) {
console.log(obj[key]);
}
}- (2)关键特性与陷阱
原型链污染问题(核心陷阱):默认遍历原型链上的可枚举属性,若不加过滤,会把继承的属性也遍历出来。
javascript
// 污染原型链
Object.prototype.globalProp = '我是全局属性';
const obj = { a: 1, b: 2 };
for (const key in obj) {
console.log(key, obj[key]); // 输出:a 1 → b 2 → globalProp 我是全局属性
}
// 必须用 hasOwnProperty 过滤继承属性
for (const key in obj) {
if (Object.prototype.hasOwnProperty.call(obj, key)) {
console.log(key, obj[key]); // 仅输出:a 1 → b 2
}
}不遍历不可枚举属性:内置属性(如数组的 length)通常是不可枚举的,for...in 不会遍历。
javascript
const arr = [1, 2, 3];
for (const key in arr) {
console.log(key); // 输出:0, 1, 2(仅遍历可枚举的索引属性,不遍历不可枚举的 length)
}-
遍历顺序不可靠:不同引擎(V8、SpiderMonkey)遍历顺序不同,且不保证数字键按升序,依赖引擎实现,不能依赖顺序做业务逻辑。
-
可遍历可枚举的符号属性:若对象的符号属性是可枚举的,for...in 会遍历它(但实际场景很少,因为 Symbol 默认不可枚举)。
-
(3)适用场景
需要遍历原型链上可继承的可枚举属性(极少场景,通常是调试或特殊需求);
旧浏览器环境,无其他遍历方式可用时(需配合 hasOwnProperty 过滤)。
-
(4)避坑原则
- 必须过滤继承属性:永远配合 obj.hasOwnProperty(key) 或 Object.prototype.hasOwnProperty.call(obj, key)(避免对象覆盖 hasOwnProperty 的情况),否则会遍历到原型链上的垃圾属性。
- 不用于严格数据遍历:由于顺序不可靠、易受原型污染,禁止用于核心业务数据遍历(如数据转换、核心对象属性操作)。
2. Object.keys():获取自身可枚举的字符串键属性数组
Object.keys() 是 ES5 引入的标准方法,核心特性是"仅返回对象自身的可枚举字符串键属性名数组",不遍历原型链、不包含符号属性,是日常开发中遍历字符串键属性的首选。
- (1)基础语法
javascript
const obj = { a: 1, b: 2, 0: 3, c: 'str' };
const keys = Object.keys(obj); // ['0', 'a', 'b', 'c'](按数字升序→字符串插入顺序)
keys.forEach(key => {
console.log(key, obj[key]);
});- (2)关键特性与优势
① 过滤原型链继承属性:仅返回对象自身的属性,完全避免原型污染问题。
javascript
Object.prototype.globalProp = '全局属性';
const obj = { a: 1 };
console.log(Object.keys(obj)); // ['a'](不包含 globalProp)② 仅遍历可枚举的字符串键属性:自动忽略不可枚举属性、符号属性,聚焦业务常用的字符串键。
javascript
const obj = { a: 1 };
Object.defineProperty(obj, 'b', { value: 2, enumerable: false }); // 不可枚举属性
const symbolKey = Symbol('c');
obj[symbolKey] = 3; // 符号属性(不可枚举,默认 enumerable 为 false)
console.log(Object.keys(obj)); // ['a'](仅可枚举字符串键)③ 遍历顺序可预测:严格遵循 "数字键按升序 → 字符串键按插入顺序",符合业务逻辑(如遍历数组索引、保持插入顺序),是可预测的遍历方式。
④ 天然支持数组:数组也是对象,Object.keys() 返回数组索引(字符串形式),可用于数组遍历(但更推荐 for...of)。
javascript
const arr = [1, 2, 3];
console.log(Object.keys(arr)); // ['0', '1', '2']- (3)适用场景
- 遍历对象自身的可枚举字符串键属性(90% 的日常场景);
- 需要将对象属性名转为数组,配合 forEach、map 等数组方法遍历;
- 数组遍历(需注意返回的是字符串索引);
- 数据校验(仅关注自身可枚举属性,过滤原型污染)。
- (4)局限性
- 不包含不可枚举属性(如内置 length、通过 Object.defineProperty 设置 enumerable: false 的属性);
- 不包含符号属性(即使符号属性可枚举,也不返回);
- 无法遍历原型链上的继承属性(这是优势,也是局限性,取决于场景)。
3. Reflect.ownKeys():获取对象自身所有属性(含不可枚举、符号属性)
Reflect 是 ES6 引入的元编程 API,用于操作对象属性的底层逻辑,核心用于获取属性相关元信息的方法是 Reflect.ownKeys(),它返回对象自身所有属性名的数组,覆盖范围远超前两种方式。
- (1)基础语法
javascript
const obj = { a: 1, 0: 2 };
Object.defineProperty(obj, 'b', { value: 3, enumerable: false }); // 不可枚举字符串键
const symbolKey = Symbol('c');
obj[symbolKey] = 4; // 符号属性(可枚举,默认 enumerable 为 true)
const allKeys = Reflect.ownKeys(obj);
// 输出:['0', 'a', 'b', symbolKey](按数字升序→字符串插入顺序→符号插入顺序)- (2)关键特性与优势
-
覆盖所有自身属性:无论可枚举与否、是字符串键还是符号键,只要是对象自身的属性,全部返回,是获取对象完整属性的唯一标准方法。
- 包含可枚举的字符串键、不可枚举的字符串键、可枚举的符号键、不可枚举的符号键。
- 完全过滤原型链继承属性(仅自身属性)。
-
遍历顺序严格可预测:遵循 ECMAScript 规范,顺序为:
- 数字键(可转换为整数的字符串键)按升序排列;
- 其他字符串键按插入顺序排列;
- 符号键按插入顺序排列。
-
元编程核心工具:配合 Reflect.getOwnPropertyDescriptor(),可获取每个属性的完整描述符(包括 enumerable、writable 等),用于深度遍历、反射操作(如动态校验对象结构)。
-
javascript
const allKeys = Reflect.ownKeys(obj);
allKeys.forEach(key => {
const descriptor = Reflect.getOwnPropertyDescriptor(obj, key);
console.log(`属性名:${key.toString()},是否可枚举:${descriptor.enumerable}`);
});-
(3)适用场景
- 需要获取对象所有自身属性(含不可枚举、符号属性),如深度拷贝、对象结构校验、元编程;
- 遍历不可枚举属性(如数组的 length、toString 等内置方法);
- 遍历符号属性(如框架、库中通过符号定义的私有属性);
- 配合元编程 API,动态操作对象属性(如批量修改属性描述符、动态代理对象属性)。
-
(4)局限性
- 不遍历原型链上的继承属性(与 Object.keys() 一致,仅自身属性);
- ES6 兼容性限制:不支持 IE,需在 Node.js 6+ 或现代浏览器中使用;
- 返回的数组包含所有属性,需要额外判断属性类型(字符串键/符号键)和可枚举性,才能针对性操作。
二、核心场景:
- 场景 1:遍历普通对象的业务属性(自身可枚举字符串键)
- 需求:遍历 { name: '张三', age: 20 } 的核心业务属性,过滤原型污染。
- 首选:Object.keys() + forEach
- 不推荐:for...in(需额外过滤原型链,易漏过滤导致污染)。
javascript
const user = { name: '张三', age: 20 };
Object.keys(user).forEach(key => {
console.log(`${key}: ${user[key]}`);
});
// 输出:name: 张三 → age: 20- 场景 2:遍历数组(获取索引)
- 需求:遍历数组 1, 2, 3,输出每个元素。
- 可选方案:
- 推荐:for...of(原生遍历数组,返回值,无需处理索引);
- 次选:Object.keys()(获取数字索引的字符串形式,配合遍历)。
- 不推荐:for...in(会遍历数组的原型链属性,顺序不可靠,且索引是字符串,需额外转换)。
javascript
const arr = [1, 2, 3];
Object.keys(arr).forEach(index => {
console.log(Number(index), arr[index]); // 输出:0 1 → 1 2 → 2 3
});- 场景 3:获取对象所有自身属性(含不可枚举、符号属性)
- 需求:深度拷贝一个对象,需覆盖所有自身属性(包括不可枚举和符号属性)。
- 唯一选择:Reflect.ownKeys()
- 为什么不能用其他方式:
- for...in 和 Object.keys() 都会漏掉不可枚举属性和符号属性,导致深度拷贝不完整。
javascript
function deepClone(obj) {
if (obj === null || typeof obj !== 'object') return obj;
const cloned = Array.isArray(obj) ? [] : {};
// 遍历所有自身属性(含不可枚举、符号属性)
Reflect.ownKeys(obj).forEach(key => {
const descriptor = Reflect.getOwnPropertyDescriptor(obj, key);
if (descriptor.value && typeof descriptor.value === 'object') {
cloned[key] = deepClone(descriptor.value);
} else {
cloned[key] = descriptor.value;
}
});
return cloned;
}- 场景 4:遍历原型链上的可继承属性(极少场景)
- 需求:调试时查看对象的所有可枚举属性(含原型链继承的)。
- 唯一选择:for...in(不加过滤)
- 注意:生产环境几乎不用此场景,除非明确需要遍历原型链属性,且需承担原型污染风险。
javascript
Object.prototype.globalMethod = () => console.log('全局方法');
const obj = { ownProp: '自身属性' };
for (const key in obj) {
console.log(key); // 输出:ownProp → globalMethod
}- 场景 5:遍历符号属性
- 需求:遍历对象通过符号定义的私有属性(如框架的 Symbol('private'))。
- 可选方案:
- 若符号属性是可枚举的:Reflect.ownKeys()(包含符号键)或 for...in(需配合过滤);
- 若符号属性是不可枚举的:仅 Reflect.ownKeys() 能遍历。
- 不推荐:Object.keys()(完全不包含符号属性)。
javascript
const symbolKey1 = Symbol('enumerable');
const symbolKey2 = Symbol('nonEnum');
const obj = { [symbolKey1]: '可枚举符号', [symbolKey2]: '不可枚举符号' };
Object.defineProperty(obj, symbolKey2, { enumerable: false });
console.log(Reflect.ownKeys(obj)); // [symbolKey1, symbolKey2](都包含)
// for...in 仅能遍历到 symbolKey1(可枚举)三、终极避坑指南
- ① 永远过滤原型链:用 for...in 时,必须配合 Object.prototype.hasOwnProperty.call(obj, key) 过滤继承属性,否则会遍历到原型链上的垃圾属性,导致数据混乱。
- ② 日常遍历优先用 Object.keys():90% 的业务场景都是遍历自身可枚举的字符串键属性,Object.keys() 兼顾安全、可预测性和性能,是首选。
- ③ 深度操作用 Reflect.ownKeys():需要获取对象所有自身属性(含不可枚举、符号属性),如深度拷贝、元编程、对象校验,唯一选择是 Reflect.ownKeys()。
- ④ 避免依赖 for...in 的顺序:不同引擎遍历顺序不同,不能将 for...in 的顺序用于业务逻辑(如排序依赖、顺序敏感的操作)。
- ⑤ 数组遍历不推荐 for...in:数组用 for...of 更原生、更安全,用 Object.keys() 也可,但 for...in 会遍历原型属性,且顺序不可靠。
javascript
const arr = [1, 2, 3];
for (const key of arr) {
console.log(key);
}
// 输出:1 → 2 → 3(直接遍历元素值,不遍历索引)- ⑥ 符号属性处理:符号属性默认不可枚举,Object.keys() 和 for...in 都无法遍历,只有 Reflect.ownKeys() 能覆盖所有符号属性(无论可枚举与否)。
总结:
- 日常遍历自身可枚举字符串键:Object.keys()(首选);
- 遍历原型链可继承可枚举属性:for...in(极少场景,需过滤);
- 获取所有自身属性(含不可枚举、符号):Reflect.ownKeys()(唯一标准方案);
- 数组遍历:优先 for...of,其次 Object.keys(),禁用 for...in。
8. JavaScript 的隐式类型转换
JavaScript 的隐式类型转换(Implicit Type Conversion)是指在无需显式调用转换函数的情况下,由引擎自动根据上下文将一种数据类型转换为另一种数据类型的行为。虽然提高了灵活性,但也因"隐式"特性成为常见错误来源。
1、核心转换规则总览

2、关键场景深度剖析
- 条件语句中的隐式转换(最易踩坑区)
⚠️ 陷阱:空数组 \[\] 和空对象 {} 在条件判断中均为真值!
javascript
// 经典假值列表验证
if (0) console.log('不会执行'); // false
if ('') console.log('不会执行'); // false
if (null) console.log('不会执行'); // false
if (undefined) console.log('不会执行'); // false
if (NaN) console.log('不会执行'); // false
if ('0') console.log('会执行'); // true(非空字符串)
if ({}) console.log('会执行'); // true(对象永远为真)- 相等性比较(== vs =)
🔍 底层逻辑: 允许类型不同,按规则转换后比较;=== 直接要求类型和值均相同。
javascript
console.log(1 == '1'); // true(数字与字符串比较,字符串转数字)
console.log(null == undefined);// true(特殊规则,两者互等但不转其他类型)
console.log([1,2] == '1,2'); // true(数组转字符串后比较)
console.log({} == '[object Object]'); // true(对象转字符串)
// 推荐始终使用严格相等 ===
console.log(1 === '1'); // false- 算术运算中的强制转换
💡 规律:+ 运算符若一侧为字符串,则另一侧也转字符串;其他算术运算符强制两侧转数字。
javascript
console.log(5 + '5'); // '55'(数字转字符串拼接)
console.log('5' - 3); // 2(字符串转数字减法)
console.log('5' * '2'); // 10(字符串转数字乘法)
console.log('5' / '2'); // 2.5(字符串转数字除法)
console.log([] + []); // ''(数组转字符串拼接)
console.log([] + {}); // '[object Object]'(双方转字符串)- 逻辑运算符的短路效应
⚠️ 注意:逻辑运算符返回的是原始操作数的值而非布尔值!
javascript
const arr = [];
const result = arr || 'default'; // 'default'(空数组转true?不!空数组是truthy,但此处取第一个真值)
console.log(result); // 输出: [](空数组被视为真值,返回原数组)
// 正确用法:设置默认参数
function func(param) {
param = param || 'default'; // 当param为假值时替换
}- 对象到原始值的转换(ToPrimitive)
🔧 转换顺序:对象转原始值时,优先 valueOf() → 失败则 toString() → 仍失败抛TypeError。可通过 Symbol.toPrimitive 覆盖默认行为。
javascript
const obj = {
valueOf() { return 2; },
toString() { return 'str'; }
};
console.log(obj + ''); // '2'(优先调用valueOf,结果转字符串)
console.log(String(obj)); // 'str'(显式调用toString)
console.log(obj + 5); // 7(valueOf返回数字参与运算)
// 自定义优先级
const date = new Date();
date.valueOf = () => Date.now();
console.log(date > Date.now()); // true(优先用valueOf比较时间戳)3、高危场景实战避坑
- 场景1:表单输入处理
javascript
const inputValue = document.getElementById('age').value; // 字符串类型
const age = Number(inputValue); // ✅ 显式转换安全
// ❌ 避免: if (inputValue) { ... }(空字符串会误判为假)- 场景2:API响应数据处理
javascript
const response = await fetch('/api/data');
const json = await response.json(); // JSON.parse结果可能是数字/字符串/布尔
const id = json.id + ''; // ✅ 确保字符串拼接
// ❌ 避免:直接用于数学运算(若后端返回字符串形式的数字会导致NaN)- 场景3:动态类型判断
javascript
function processValue(val) {
if (typeof val === 'string') {
return val.toUpperCase();
} else if (typeof val === 'number') {
return val * 2;
}
// 添加默认处理...
}
// ✅ 优于依赖隐式转换的逻辑分支4、最佳实践指南
- ① 优先使用显式转换
javascript
const num = Number('123'); // 明确意图
const str = String(123);
const bool = Boolean('hello');- ② 严格相等优先
javascript
if (userInput === 42) { /* ... */ } // 比 == 更安全- ③ 警惕+的双重角色
javascript
const sum = a + b; // 不确定a/b类型时需谨慎
// 可改为 parseFloat(a) + parseFloat(b)- ④ 防御性编程
javascript
function addNumbers(a, b) {
a = Number(a) || 0; // 兜底处理无效输入
b = Number(b) || 0;
return a + b;
}- ⑤ 利用ESLint规则
启用 @typescript-eslint/no-implicit-any 或自定义规则检测潜在类型问题。
5、经典面试题解析
-
Q: '1','2','3'.map(parseInt) 输出什么?
- A: 1, NaN, NaN
- 解析:parseInt接收两个参数(字符串, 进制),map传递当前元素和索引。'2'和'3'在二进制中非法导致NaN。
-
Q: \[\] == !\[\] 为什么是true?
- A: 右侧!\[\]先将数组转为布尔值(true),再取反得false。左侧\[\]转原始值为'',最终比较'' == false → Number('') == Number(false) → 0 == 0 → true。
9. == 和===的区别
1、核心区别

2、具体行为解析
- ==(宽松相等):先转换类型,再比较值
当两个操作数类型不同时,会触发隐式类型转换,转换规则遵循以下优先级:- 目标类型确定:根据比较双方的类型,决定最终转换为哪种类型(如数字 vs 字符串 → 双方都转为数字)。
- 转换流程:优先调用 valueOf()/toString() 转为原始值,再用 ToPrimitive 规则处理对象。
常见转换示例:
javascript
console.log(5 == '5'); // true(字符串 '5' 转为数字 5)
console.log(null == undefined); // true(特殊规则,两者互等但不转其他类型)
console.log([1,2] == '1,2'); // true(数组 [1,2] 转为字符串 '1,2')
console.log({} == '[object Object]'); // true(对象 {} 转为字符串)
console.log('' == false); // true('' 转数字 0,false 转数字 0)
console.log(0 == -0); // true(+0 和 -0 视为相等)
⚠️ 注意:NaN 与任何值(包括自身)都不相等!
console.log(NaN == NaN); // false- ===(严格相等):类型不同直接判不等
完全跳过类型转换步骤,仅在以下条件同时满足时返回 true:- 两个操作数的类型完全相同;
- 两个操作数的值严格相等(对于对象,比较引用地址而非内容)。
- ✅ 优势:彻底消除因类型转换导致的意外行为,代码更可预测。
- 典型示例:
javascript
console.log(5 === '5'); // false(类型不同)
console.log(null === undefined); // false(类型不同)
console.log([1,2] === '1,2'); // false(类型不同)
console.log({} === {}); // false(不同对象的引用地址不同)
console.log(0 === -0); // true(数值相等且类型相同)3、特殊边界情况
- null 与 undefined 的特殊性
javascript
null == undefined → true //(历史遗留设计,表示"无"的不同形式)
null === undefined → false //(类型不同)- 对象与原始类型的比较
javascript
const arr = [1];
console.log(arr == 1); // true(数组 [1] 转为原始值 '1',再转数字 1)
console.log(arr === 1); // false(类型不同)- 浮点数精度问题
javascript
console.log(0.1 + 0.2 === 0.3); // false(浮点数计算误差导致 0.30000000000000004 ≠ 0.3)
// 解决方案:手动指定误差范围
const equals = (a, b) => Math.abs(a - b) < Number.EPSILON;
console.log(equals(0.1 + 0.2, 0.3)); // true4、最佳实践建议
- 默认使用 ===:
除非明确需要跨类型比较,否则一律采用严格相等,避免隐式转换带来的不确定性。
javascript
// ✅ 推荐写法
if (userInput === 42) { /* ... */ }
// ❌ 避免写法(除非特殊需求)
if (userInput == '42') { /* ... */ }- 谨慎处理 null/undefined:
javascript
// 检查变量是否为 null 或 undefined 时,优先用 === 区分类型:
if (value === null) { /* 处理 null */ }
else if (value === undefined) { /* 处理 undefined */ }
// 若仅需判断"是否存在",可用 ?? 运算符(仅针对 null/undefined):
const defaultValue = value ?? 'default';
// 显式转换替代隐式转换:
// 需要跨类型比较时,手动转换类型以明确意图:
// 将字符串转为数字再比较
if (Number(input) === 42) { /* ... */ }
// 工具函数辅助判断:
// 判断数组/对象是否包含某元素时,使用 includes()(内部使用 ===):
const arr = [1, '2'];
console.log(arr.includes(2)); // false(严格匹配类型)5、常见错误示例与修正
- 错误1:依赖隐式转换导致逻辑混乱
javascript
// ❌ 意图不明且易出错
if (userAge == '25') { /* ... */ }
// ✅ 明确类型转换
if (Number(userAge) === 25) { /* ... */ }- 错误2:误判 NaN
javascript
// ❌ 无法检测 NaN
if (value === NaN) { /* 永远不会执行 */ }
// ✅ 正确方式
if (Number.isNaN(value)) { /* ... */ }- 错误3:混淆对象引用与值
javascript
const obj1 = { id: 1 };
const obj2 = { id: 1 };
console.log(obj1 == obj2); // false(引用不同)
console.log(obj1 === obj2); // false(同上)
// ✅ 深度比较对象内容(需手写函数或使用库如 Lodash)
function deepEqual(a, b) { return JSON.stringify(a) === JSON.stringify(b); }
console.log(deepEqual(obj1, obj2)); // true10. 执行上下文和作用域链是什么?
在 JavaScript 中,执行上下文(Execution Context) 是代码执行的环境容器,决定了变量、函数的生命周期和访问规则;作用域链(Scope Chain) 则是执行上下文中用于变量查找的链式机制,是 JavaScript 作用域(尤其是闭包)的核心底层原理
1.执行上下文: 代码执行的 "舞台"
执行上下文是 JS 引擎为每一次代码执行创建的独立环境,它包含了当前代码执行所需的所有核心信息:变量、函数、this 指向、作用域链等。简单说,执行上下文就是代码运行的 "工作空间",不同阶段的代码运行在不同的上下文中。
-
执行上下文的生命周期
每个执行上下文的生命周期分为三个阶段,JS 引擎会严格按照这个流程管理上下文:
- 创建阶段: 创建变量对象 (Variable Object, 简称: VO)
- 确定 this 指向
- 构建 作用域链
- 完成变量/函数提升(预解析) | 此时代码尚未执行,但变量对象已初始化,变量被赋值为 undefined,函数被赋值为函数体。 |
|
| 执行阶段 | 逐行执行代码,修改变量对象的值,完成函数调用、变量赋值等实际操作。 | 代码真正运行的阶段,变量从预解析的 undefined 变为实际值。 |
|
| 销毁阶段 | 执行完成后,释放执行上下文占用的内存,销毁所有关联的变量和资源。 | 函数执行上下文销毁后,内部变量不可访问;全局执行上下文在浏览器关闭时销毁。 |
-
执行上下文的类型
JS 中存在两种核心执行上下文,它们的创建时机和作用范围不同:
-
全局执行上下文(Global Execution Context)
- 创建时机:程序启动时,由 JS 引擎自动创建,且一个程序中仅存在一个。
- 核心作用:全局代码(如 < script> 标签内的代码、未在函数内的代码)的执行环境。
- 关键属性:
this 指向全局对象(浏览器中是 window,Node.js 中是 global)。
变量对象就是全局对象,所以在全局作用域声明的变量会成为全局对象的属性(如 var a = 1 等价于 window.a = 1)。 - 销毁时机:浏览器关闭时,全局上下文销毁,全局变量全部释放。
-
函数执行上下文(Function Execution Context)
- 创建时机:每次调用函数时,JS 引擎都会创建一个新的函数执行上下文。
- 核心作用:函数内部代码的执行环境,不同函数调用对应独立的上下文,互不干扰。
- 关键属性:
- this 指向由函数调用方式决定(如普通调用指向 window,call/apply/bind 可改变指向,箭头函数继承外层 this)。
- 变量对象是函数的局部变量集合,仅函数内部可访问,函数执行完毕后销毁。
- 销毁时机:函数执行完成并返回后,上下文立即销毁,内部局部变量被垃圾回收。
-
执行上下文的核心组成
每个执行上下文内部都包含三个核心属性,它们共同决定了代码的执行逻辑,也是理解作用域链的关键:
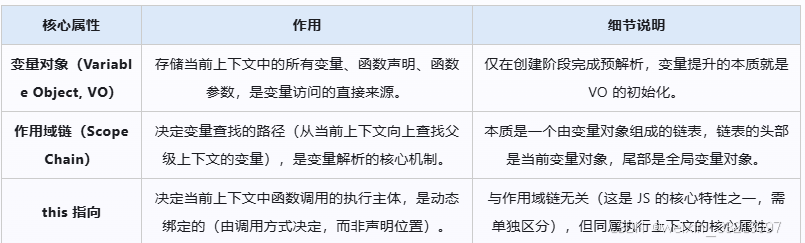
-
2、作用域链:变量查找的 "寻路地图"
作用域链是执行上下文的核心属性之一,它的本质是一个由多个变量对象组成的单向链表,核心作用是解决 "变量在哪里找" 的问题。当代码尝试访问一个变量时,JS 引擎会沿着作用域链逐级查找,直到找到目标变量,若遍历到全局作用域仍未找到,则抛出 ReferenceError。
-
作用域链的构建原理
作用域链的构建完全基于执行上下文的创建时机和嵌套关系 ,核心逻辑是:当前上下文的作用域链,由当前变量对象 + 父级上下文的作用域链组成。
具体构建过程(以函数上下文为例):
- 当函数被声明时,函数内部会记录其创建时所在的作用域(即父级上下文的作用域链),这个记录的过程称为 "词法作用域"(静态作用域,JS 的核心特性)。
- 当函数被调用时,JS 引擎创建新的函数执行上下文,同时构建其作用域链:
- 链表的第一个节点:当前函数的变量对象(存储局部变量、参数)。
- 链表的后续节点:父级上下文的作用域链(即函数声明时所在的作用域链)。
- 链表的最后一个节点:全局变量对象(所有作用域链的终点)。
-
作用域链的查找规则
当代码访问一个变量时,JS 引擎会严格按照以下规则沿作用域链查找:
-
从当前执行上下文的变量对象开始查找。
-
若未找到,则沿作用域链向上查找下一个父级上下文的变量对象。
-
持续向上查找,直到全局变量对象。
-
若全局变量对象仍未找到,则抛出 ReferenceError: x is not defined。
-
-
关键原则:作用域链是静态的(词法作用域决定),不会因执行上下文的动态调用而改变。这是闭包能够访问父级变量的核心原因,也是 JS 区别于动态作用域语言的核心特性。
-
作用域链的经典案例
通过以下案例,可以直观理解作用域链的工作原理:
案例 1:嵌套函数的变量查找
javascript
const globalVar = "全局变量";
function parent() {
const parentVar = "父级变量";
function child() {
console.log(parentVar); // 输出:父级变量
console.log(globalVar); // 输出:全局变量
}
child();
}
parent();作用域链分析:
- 全局上下文的作用域链:仅包含全局变量对象(存储 globalVar)。
- parent 函数执行上下文的作用域链:parent 的变量对象(存储 parentVar) + 全局作用域链。
- child 函数执行上下文的作用域链:child 的变量对象(无变量) + parent 的作用域链(即 parent 变量对象 + 全局作用域链)。
当 child 访问 parentVar 时,先查找自身变量对象(无),再沿作用域链查找 parent 的变量对象,找到后返回,这就是作用域链的链式查找机制。
案例 2:闭包与作用域链的持久化
闭包的核心原理就是作用域链的持久化:函数执行完毕后,其执行上下文本应销毁,但由于内部函数被外部引用,父级函数的作用域链无法被销毁,从而保留了父级变量的访问能力。
javascript
function outer() {
const outerVar = "闭包变量";
function inner() {
console.log(outerVar); // 即使 outer 执行完毕,仍能访问 outerVar
}
return inner; // 返回内部函数,形成闭包
}
const fn = outer();
fn(); // 输出:闭包变量作用域链分析:
- outer 函数执行时,创建 outer 上下文,作用域链为:outer 变量对象(含 outerVar) + 全局作用域链。
- inner 函数被声明时,记录了 outer 的作用域链(词法作用域),因此 inner 的作用域链包含 outer 的变量对象。
- outer 返回 inner 后,outer 的执行上下文本应销毁,但由于 inner 的作用域链仍引用 outer 的变量对象,JS 引擎不会销毁该对象(垃圾回收机制无法回收被引用的对象),从而形成闭包。
- 调用 fn() 时,inner 的执行上下文的作用域链仍包含 outer 的变量对象,因此能成功访问 outerVar。
3、执行上下文与作用域链的核心区别
很多人会混淆执行上下文和作用域链,其实它们是紧密关联但本质不同的概念,核心区别如下:

4、核心原理总结
-
执行上下文是代码执行的 "容器":每一次代码执行(全局代码或函数调用)都对应一个独立的执行上下文,它包含变量对象、this、作用域链,管理代码执行的全流程(创建→执行→销毁)。
-
作用域链是变量查找的 "路径":由多个变量对象组成的链表,遵循 "当前上下文→父级上下文→全局上下文" 的查找顺序,基于词法作用域(静态)构建,是作用域规则的底层实现。
-
词法作用域是核心基石:作用域链在函数声明时确定(而非调用时),这决定了 JS 的作用域是静态的,也是闭包能够实现的根本原因,区别于动态作用域语言(如 Bash)。
-
执行上下文的销毁与闭包的关系:正常情况下,函数执行完成后,其执行上下文会销毁,变量被回收。但当函数内部的引用被外部持有时,函数的作用域链会被持久化,导致执行上下文的变量对象无法被回收,从而形成闭包。
5、实战意义:理解这些原理能解决什么问题?
掌握执行上下文和作用域链,是理解 JavaScript 核心特性的关键,能帮你彻底解决以下高频问题:
-
变量提升的本质:变量提升是执行上下文创建阶段对变量对象的预解析,变量被初始化为 undefined,函数被赋值为函数体,这是变量对象的核心行为。
-
闭包的原理与风险:闭包是作用域链持久化的结果,能访问父级变量,但会导致父级上下文的变量对象无法被回收,可能引发内存泄漏,需合理使用。
-
this 指向与作用域的区别:this 是执行上下文的属性,由调用方式动态决定;作用域链是变量查找的静态机制,两者互不影响,避免混淆 this 和作用域。
-
作用域隔离与模块化:通过函数执行上下文创建独立作用域,实现变量隔离,是 ES6 模块(Module)诞生前模块化的核心实现方式,也是理解现代模块化的基础。
-
避免变量污染:全局执行上下文只有一个,全局变量会污染全局命名空间,通过函数执行上下文创建局部作用域,可有效避免变量冲突,这是 JS 开发的核心规范之一。
11. JS中的this究竟指向谁?
1、普通函数中的 this 指向规则
- 默认绑定(独立函数调用)
- 规则:当函数作为独立函数直接调用时(无任何前缀对象),this 指向全局对象(浏览器中为 window,Node.js 中为 global)。
- 注意:严格模式('use strict')下,this 为 undefined。
- 示例:
javascript
function sayThis() { console.log(this); }
sayThis(); // 非严格模式下输出 window(或 global)- 隐式绑定(对象方法调用)
- 规则:当函数作为对象的方法被调用时(如 obj.method()),this 指向调用该方法的对象(即obj)。
- 示例:
javascript
const obj = { name: 'Alice', greet() { console.log(this.name); } };
obj.greet(); // 输出 "Alice"(this → obj)[^2^][^5^]- 陷阱:若将对象方法赋值给变量后单独调用,会退化为默认绑定(this 指向全局对象)。例如:
javascript
const greetFunc = obj.greet;
greetFunc(); // 非严格模式下输出 undefined(this → window)[^4^]- 显式绑定(强制指定 this)
- 规则:通过 call()、apply() 或 bind() 可主动指定 this 的值。
- call()/apply():立即执行函数并绑定 this,区别仅在于传参方式(call 逐个传参,apply 传数组)。
- bind():返回一个永久绑定 this 的新函数,后续调用无法修改。
- 示例:
javascript
function introduce(hobby) { console.log(`${this.name} loves ${hobby}`); }
const user = { name: 'Bob' };
introduce.call(user, 'coding'); // 输出 "Bob loves coding"(this → user)[^5^]- new 绑定(构造函数调用)
- 规则:使用 new 调用构造函数时,this 指向新创建的实例对象。
- 示例:
javascript
function Person(name) { this.name = name; }
const p = new Person('Alice');
console.log(p.name); // 输出 "Alice"(this → 实例 p)[^2^][^4^]- 关键机制:new 操作符会创建一个新对象,并将构造函数的 this 绑定到该对象 5。
2、特殊场景下的 this 行为
- 箭头函数的 this 特性
- 无独立 this:箭头函数没有自己的 this,其值捕获自外层普通函数的词法作用域(定义时的上下文)。
- 不可修改:即使使用 call()/apply()/bind() 也无法改变箭头函数的 this。
- 典型用途:解决回调函数中 this 丢失问题。例如:
javascript
const obj = {
name: 'Obj',
method() {
setTimeout(() => console.log(this.name)); // 箭头函数捕获外层 method 的 this(→ obj)
}
};
obj.method(); // 输出 "Obj"[^4^][^5^]- 事件监听与定时器中的 this
- 默认行为:事件处理函数或定时器回调中,this 通常指向触发事件的DOM元素或全局对象。
- 解决方案:箭头函数或提前绑定 this。
3、复杂场景的 this 判断流程
面对多层嵌套或混合调用时,可按以下优先级逐步分析:
- 是否为箭头函数? 若是,this 捕获自外层普通函数的作用域 。
- 是否通过 new 调用? 若是,this 指向新创建的实例 。
- 是否使用 call/apply/bind? 若是,this 指向指定的参数对象。
- 是否为对象方法调用? 若是,this 指向直接调用它的对象。
- 否则:默认绑定,this 指向全局对象(严格模式下为 undefined)。
总的来说,掌握 this 的关键在于理解"调用方式决定指向",而非"定义位置"。实际开发中,优先使用箭头函数简化嵌套作用域的 this 管理,并通过显式绑定避免不确定性。
12. 闭包是什么?
JavaScript 闭包(Closure)是指能够访问另一个函数作用域中变量的函数。
1、本质特征
-
核心定义
- 当一个内部函数被定义在另一个外部函数的内部,并且这个内部函数能够访问外部函数作用域中的变量时,就形成了闭包。
-
关键特点
- 访问外部变量:闭包可以读取外部函数的局部变量、参数以及其他内部函数。
- 持久化存储:即使外部函数执行完毕,其作用域中的变量仍会被闭包引用而保留在内存中,不会被垃圾回收机制回收。
- 独立作用域:闭包创建了一个独立的词法环境,使得变量既不与全局作用域冲突,也不被外部直接修改。
javascript
// 基础闭包示例:私有计数器
function createCounter() {
let count = 0; // 外部函数的局部变量
// 返回一个内部函数(闭包)
return function() {
count++; // 访问并修改外部函数的变量
return count;
};
}
const counter = createCounter(); // 创建闭包实例
console.log(counter()); // 输出: 1
console.log(counter()); // 输出: 2
console.log(counter()); // 输出: 32、运行机制
- 词法作用域
- JavaScript采用词法作用域,这意味着函数的作用域在函数定义时就确定了,而不是在调用时。因此,无论闭包在哪里被调用,它都能访问其定义时所在的外部函数作用域中的变量。
- 垃圾回收机制
- 正常情况下,函数执行完毕后,其内部的局部变量会随着执行上下文的销毁而被垃圾回收机制回收。但由于闭包引用了外部函数的变量,导致这些变量不会被回收,而是被"封闭"在闭包中,持续存在。
3、常见应用
-
数据私有化
- 通过闭包可以模拟私有变量,将一些重要的数据信息隐藏在函数内部,只暴露有限的访问接口,从而保护数据的完整性和安全性。例如计数器、状态管理等场景。
-
函数工厂
- 根据传入的不同参数返回具有特定功能的函数,提高代码的复用性。例如生成不同标签的日志打印函数。
-
柯里化
- 把接收多个参数的函数变换成接收一个单一参数的函数,方便进行参数复用和延迟执行。例如类型检测工具。
-
模拟块级作用域
- 在ES6之前,JavaScript只有函数作用域,没有块级作用域。可以使用闭包来模拟块级作用域,避免变量污染。例如解决for循环中setTimeout异步输出问题。
4、潜在风险与规避方法
- 内存泄漏
- 由于闭包会持有外部变量的引用,如果滥用闭包且不及时清理,会导致内存占用越来越高。解决方法是在不再需要使用闭包时,将引用闭包的变量设置为null,手动断开引用,等待垃圾回收机制回收内存。
13. 高阶函数和柯里化应用场景
一、高阶函数的核心应用场景
高阶函数是指接受函数作为参数或返回函数作为结果的函数,其核心价值在于抽象逻辑、解耦代码,让代码具备更强的复用性和灵活性。
(一)数据处理与转换
对数组或集合进行批量操作时,高阶函数可替代手动循环,大幅简化代码,同时实现逻辑与数据的解耦,是前端数据处理的基础工具。
- 典型场景:数组的映射、筛选、归约等操作,无需手动遍历,直接通过高阶函数传入处理逻辑即可完成。
- 核心示例:
map 映射:将数组每个元素按规则转换,如将数字数组翻倍。
javascript
const numbers = [1, 2, 3, 4, 5];
const doubled = numbers.map(num => num * 2); // 输出 [2, 4, 6, 8, 10]filter 筛选:按条件过滤数组元素,如筛选偶数。
javascript
const evenNumbers = numbers.filter(num => num % 2 === 0); // 输出 [2, 4]reduce 归约:将数组元素合并为单一值,如计算数组总和。
javascript
const sum = numbers.reduce((acc, num) => acc + num, 0); // 输出 15(二)事件处理与回调机制
在 GUI 编程或异步操作中,高阶函数作为回调函数,可动态注入处理逻辑,实现事件与逻辑的解耦,避免硬编码。
- 典型场景:DOM 事件监听、异步网络请求、定时器等。
- 核心示例:
DOM 事件绑定:通过 addEventListener 传入回调函数,处理点击、输入等事件。
javascript
document.getElementById('btn').addEventListener('click', () => {
console.log('按钮被点击');
});异步请求回调:网络请求完成后,通过高阶函数传递成功/失败处理逻辑。
javascript
function fetchData(url, callback) {
fetch(url)
.then(res => res.json())
.then(data => callback(null, data))
.catch(err => callback(err, null));
}
fetchData('/api/user', (err, data) => {
if (err) console.error('请求失败', err);
else console.log('用户数据', data);
});(三)函数组合与逻辑抽象
将多个独立函数组合成新的复杂函数,实现 "分而治之" 的逻辑拆分,让代码更易维护和扩展,是函数式编程的核心实践。
- 典型场景:数据流处理、中间件设计。
- 核心示例:
函数组合工具:将多个函数按顺序组合,前一个函数的输出作为后一个的输入。
javascript
function compose(...fns) {
return input => fns.reduceRight((acc, fn) => fn(acc), input);
}
// 组合:去空格→转大写→加感叹号
const processText = compose(
str => str + '!',
str => str.toUpperCase(),
str => str.trim()
);
console.log(processText(' hello ')); // 输出 "HELLO!"中间件系统:Redux 或 Express 的中间件通过高阶函数实现,在请求处理链中插入日志、鉴权等逻辑。
javascript
function applyMiddleware(...middlewares) {
return store => {
let dispatch = store.dispatch;
const chain = middlewares.map(middleware => middleware({ getState: store.getState }));
dispatch = compose(...chain)(store.dispatch);
return { ...store, dispatch };
};
}(四)控制流封装
将通用的控制逻辑(如节流、防抖、分时处理)封装为高阶函数,复用核心控制逻辑,避免重复编写条件判断和定时器代码。
- 典型场景:高频事件优化、大数据分批处理、惰性加载。
- 核心示例:
函数节流:限制高频事件(如滚动、窗口缩放)的执行频率,避免性能问题。
javascript
function throttle(fn, delay) {
let timer = null;
return function(...args) {
if (!timer) {
timer = setTimeout(() => {
fn.apply(this, args);
timer = null;
}, delay);
}
};
}
window.addEventListener('scroll', throttle(() => console.log('滚动触发'), 1000));分时函数:将大数据分批处理,避免阻塞主线程,提升页面流畅度。
javascript
function timeChunk(data, process, count, interval) {
let index = 0;
const run = () => {
const end = Math.min(index + count, data.length);
for (let i = index; i < end; i++) process(data[i]);
index = end;
if (index < data.length) setTimeout(run, interval);
};
run();
}
// 分批处理 1000 条数据,每次 100 条,间隔 200ms
timeChunk(new Array(1000).fill(0), item => console.log('处理', item), 100, 200);(五)闭包与装饰器增强
通过返回函数的高阶函数,可对原函数进行功能增强(如日志、权限校验),而不修改原函数代码,符合开闭原则。
- 典型场景:日志记录、参数校验、性能监控。
- 核心示例:
日志装饰器:为函数添加日志功能,记录调用参数和结果。
javascript
function withLogger(fn) {
return function(...args) {
console.log(`调用函数:${fn.name},参数:`, args);
const result = fn.apply(this, args);
console.log(`返回结果:`, result);
return result;
};
}
const add = (a, b) => a + b;
const loggedAdd = withLogger(add);
loggedAdd(2, 3); // 输出调用日志和结果 5二、柯里化的核心应用场景
柯里化是将多参数函数转换为一系列单参数函数的技术,核心价值是参数复用、延迟计算和逻辑解耦,让函数更灵活、可组合。
(一)部分应用与参数复用
固定函数的部分参数,生成新的专用函数,避免重复传递相同参数,提升代码复用性。
- 典型场景:通用函数的定制化、预设配置参数。
- 核心示例:
价格计算:固定税率参数,生成不同价格的计算函数。
javascript
function calculatePrice(price, taxRate) {
return price + price * taxRate;
}
// 柯里化后固定税率 10%
const curryCalculatePrice = price => taxRate => price + price * taxRate;
const calculatePriceWithTax = curryCalculatePrice(100);
console.log(calculatePriceWithTax(0.1)); // 输出 110(100 + 100*0.1)API 请求构造器:预设基础 URL 和请求头,生成不同端点的请求函数。
javascript
const request = baseUrl => headers => endpoint => params =>
fetch(`${baseUrl}${endpoint}?${new URLSearchParams(params)}`, { headers });
const apiWithAuth = request('https://api.finance.com')({ Authorization: 'Bearer xxx' });
const getUser = apiWithAuth('/user');
getUser({ id: '888' }); // 直接调用,无需重复传 URL 和 headers(二)事件处理与回调定制
为事件处理器预设固定参数,生成专用回调函数,简化模板代码,避免在模板中编写匿名函数。
- 典型场景:DOM 事件绑定、组件回调。
- 核心示例:
菜单点击处理:预设菜单 ID,生成点击回调,模板中直接绑定。
javascript
const handleMenuClick = menuId => event => {
console.log(`点击了菜单:${menuId}`, event.target);
};
// 模板中直接绑定,无需传递 menuId
<button onClick={handleMenuClick('settings')}>设置</button>日志记录:预设操作类型,生成不同操作的日志函数。
javascript
const curryLogAction = actionType => userId =>
console.log(`Action: ${actionType}, User: ${userId}`);
const logLoginAction = curryLogAction('login');
logLoginAction(101); // 输出:Action: login, User: 101(三)函数组合与逻辑拆分
将多参数函数拆分为单参数函数,便于与其他函数组合,实现更灵活的函数链式调用,符合函数式编程的组合思想。
- 典型场景:多步骤数据处理、逻辑链拼接。
- 核心示例:
简单函数组合:将加倍和加 10 的函数通过柯里化组合。
javascript
function multiplyBy2(x) { return x * 2; }
function add10(x) { return x + 10; }
function compose(f, g) { return x => f(g(x)); }
const addThenMultiply = compose(multiplyBy2, add10);
console.log(addThenMultiply(5)); // 输出 30((5+10)*2=30)数据校验管道:将校验规则拆分为原子函数,按需组合。
javascript
const validate = reg => tip => value =>
reg.test(value) ? { pass: true } : { pass: false, tip };
const isMobile = validate(/^1[3-9]\d{9}$/)('手机号格式错误');
const isEmail = validate(/^\w+@\w+\.\w+$/)('邮箱格式错误');
console.log(isMobile('13800138000')); // { pass: true }(四)动态配置与延迟计算
逐步接收参数,延迟函数的最终执行,适用于参数需分步获取的场景,提升函数调用的灵活性。
- 典型场景:复杂配置生成、多步骤表单校验。
- 核心示例:
日志系统配置:按环境、等级、消息的顺序逐步填充参数,生成不同场景的日志函数。
javascript
const logger = env => level => msg =>
console.log(`[${env.toUpperCase()}][${level}] ${msg} - ${new Date().toLocaleTimeString()}`);
const prodError = logger('prod')('ERROR');
const devDebug = logger('dev')('DEBUG');
prodError('支付接口超时'); // 输出:[PROD][ERROR] 支付接口超时 - 10:20:00金融汇率换算:固定基准汇率,生成不同币种的换算函数,避免重复传递汇率参数。
javascript
const convertCurrency = rate => amount => (amount * rate).toFixed(2);
const usdToCny = convertCurrency(7.24);
const eurToCny = convertCurrency(7.85);
console.log(usdToCny(100)); // 724.00(五)动态样式与数据过滤
通过参数分步生成动态样式类名或过滤规则,实现逻辑与模板的解耦,简化动态样式和数据筛选的代码。
- 典型场景:CSS 动态类名生成、数据筛选管道。
- 核心示例:
动态类名生成器:预设前缀和状态,生成带状态的类名,适配不同组件。
javascript
const createCls = prefix => state => baseCls =>
`${prefix}-${baseCls} ${state ? 'is-active' : ''}`;
const navCls = createCls('nav')(true);
console.log(navCls('button')); // 输出 "nav-button is-active"数据过滤管道:生成可复用的过滤函数,直接用于数组筛选,简化筛选逻辑
javascript
const filterBy = key => value => item => item[key].includes(value);
const filterByTag = filterBy('tag');
const prompts = [{ title: 'AI助手', tag: 'Finance' }, { title: '翻译机', tag: 'Tool' }];
const financePrompts = prompts.filter(filterByTag('Finance')); // 筛选出 tag 为 Finance 的数据(六)AI Prompt 模板工厂
分步注入角色、上下文、用户输入,生成标准化 Prompt,适配 AI 场景的动态参数需求,提升 Prompt 构建效率。
- 典型场景:AI 对话模板、多层级上下文注入
- 核心示例:
javascript
const promptFactory = role => context => input =>
`Role: ${role}\nContext: ${context}\nUser says: ${input}`;
const financialExpert = promptFactory('Senior Financial Analyst')('Analyzing 2026 Q1 Report');
const finalPrompt = financialExpert('请总结该季报风险点');
console.log(finalPrompt);
// 输出:
// Role: Senior Financial Analyst
// Context: Analyzing 2026 Q1 Report
// User says: 请总结该季报风险点三、两者的核心关联与协同价值
-
柯里化是高阶函数的子集:柯里化的实现依赖高阶函数(返回新函数),本质是高阶函数的一种特殊应用,用于解决参数传递的灵活性问题。
-
协同提升代码质量:高阶函数负责逻辑抽象和解耦,柯里化负责参数复用和延迟计算,两者结合可实现 "小函数、大组合" 的函数式编程范式,让代码更简洁、复用性更强、维护成本更低。
综上,高阶函数和柯里化并非孤立的技术,而是通过 "抽象逻辑 + 灵活参数" 的组合,成为前端开发中解决复用、解耦和性能问题的核心工具,无论是日常数据处理、事件处理,还是复杂架构设计,都离不开两者的支撑。
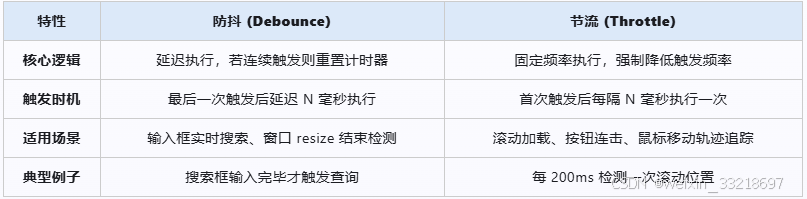
14. 谈谈JS中的节流和防抖
一、核心概念与区别
二、防抖(Debounce)详解
- 基础版实现
javascript
function debounce(fn, delay = 300) {
let timer = null;
return function(...args) {
clearTimeout(timer); // 清除之前的计时器
timer = setTimeout(() => fn.apply(this, args), delay);
};
}- 进阶版:支持立即执行
javascript
function debounce(fn, delay = 300, immediate = false) {
let timer = null;
return function(...args) {
const context = this;
if (immediate && !timer) {
fn.apply(context, args); // 立即执行首次触发
}
clearTimeout(timer);
timer = setTimeout(() => {
if (!immediate) fn.apply(context, args);
}, delay);
};
}- 应用场景举例
javascript
// 搜索框输入防抖
const searchInput = document.getElementById('search');
searchInput.addEventListener('input', debounce((e) => {
console.log('发起请求:', e.target.value);
}, 500));
// 窗口 resize 防抖
window.addEventListener('resize', debounce(() => {
console.log('窗口尺寸变化完成');
}, 200));三、节流(Throttle)详解
- 基于时间戳的实现
javascript
function throttle(fn, interval = 300) {
let lastTime = 0;
return function(...args) {
const now = Date.now();
if (now - lastTime >= interval) {
lastTime = now;
fn.apply(this, args);
}
};
}- 基于 setTimeout 的实现
javascript
function throttle(fn, interval = 300) {
let timer = null;
return function(...args) {
if (!timer) {
timer = setTimeout(() => {
fn.apply(this, args);
timer = null;
}, interval);
}
};
}- 应用场景举例
javascript
// 滚动加载更多
window.addEventListener('scroll', throttle(() => {
const scrollTop = document.documentElement.scrollTop;
const clientHeight = document.documentElement.clientHeight;
const pageHeight = document.documentElement.scrollHeight;
if (scrollTop + clientHeight >= pageHeight * 0.8) {
console.log('加载下一页数据');
}
}, 200));
// 按钮防连击
submitBtn.addEventListener('click', throttle(() => {
console.log('提交表单');
}, 1000));四、对比选择指南
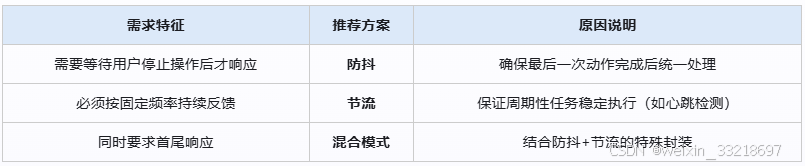
五、工程化实践建议
- Lodash 库集成
生产环境直接使用 Lodash 提供的成熟实现:
bash
npm install lodash
bash
import { debounce, throttle } from 'lodash';
// 无需手动实现,享受更完善的边界处理- TypeScript 类型增强
为函数添加泛型支持,提升类型安全性:
bash
function debounce<T extends Function>(
fn: T,
delay?: number
): (...args: Parameters<T>) => void;-
单元测试要点
验证高频触发下的调用次数是否符合预期
测试异步回调的正确性(Promise/async-await)
模拟极端网络环境下的表现
-
示例
- ① 防抖
javascript
import { debounce } from 'lodash';
// 创建防抖函数:延迟 300ms 执行
const debouncedSearch = debounce((query) => {
console.log('搜索:', query);
}, 300);
// 绑定到输入框事件
inputElement.addEventListener('input', (e) => {
debouncedSearch(e.target.value);
});
javascript
// leading: true → 首次触发立即执行,后续忽略
// trailing: true → 最后一次触发后执行(默认)
const advancedDebounce = debounce(fn, 500, {
leading: true, // 适合按钮点击防抖
trailing: false,
maxWait: 1000 // 最长等待时间(防止无限阻塞)
});
javascript
// 搜索框防抖(用户停止输入后才查询)
function handleSearch(query) {
console.log('向服务器发送请求:', query);
}
const searchDebounced = debounce(handleSearch, 500);
document.getElementById('searchInput').oninput = (e) => {
searchDebounced(e.target.value);
};
// 窗口 resize 防抖(调整结束后重新渲染)
window.addEventListener('resize', debounce(() => {
renderChart(); // 重绘图表
}, 200));- ② 节流
javascript
import { throttle } from 'lodash';
// 创建节流函数:每 200ms 最多执行一次
const throttledScroll = throttle(() => {
console.log('监听滚动位置');
}, 200);
// 绑定到滚动事件
window.addEventListener('scroll', throttledScroll);
javascript
// leading: true → 首次触发立即执行(默认)
// trailing: true → 最后一次触发后执行(默认)
const preciseThrottle = throttle(fn, 100, {
leading: false, // 仅尾部触发(适合精确计数场景)
trailing: true
});
javascript
// 滚动加载更多(每 300ms 检测一次)
let page = 1;
function loadMore() {
if (isBottom()) fetchData(page++);
}
window.addEventListener('scroll', throttle(loadMore, 300));
// 鼠标移动轨迹追踪(每秒最多记录 10 次)
canvas.onmousemove = throttle((e) => {
updateCursorPosition(e.clientX, e.clientY);
}, 100);15. bind / call / apply 的底层原理
call、apply、bind 是 JavaScript 中用于动态控制函数 this 指向的核心方法,其底层原理围绕执行上下文动态绑定、参数传递机制和函数调用规则展开。三者的核心目标均是改变函数执行时的 this 指向,但实现方式和调用行为存在差异,以下结合底层原理和实现逻辑详细解析:
一、call 的底层原理:临时挂载 + 立即执行
call 的核心作用是显式指定函数执行时的 this 指向,并立即执行函数,同时按顺序传递参数,其底层逻辑可拆解为以下关键步骤:
- 核心机制:临时挂载函数到目标对象
call 的本质是通过 "临时挂载 + 对象调用" 的方式,让函数的 this 强制指向目标对象,模拟 "对象方法调用" 的场景。具体过程如下:- 保存当前函数:将调用 call 的函数(即 this 指向的函数)保存,作为后续执行的目标函数。
- 处理 thisArg 边界:若传入的 thisArg 为 null 或 undefined,非严格模式下 this 指向全局对象(浏览器为 window,Node.js 为 globalThis);严格模式下保持 null/undefined;若 thisArg 是原始类型(如字符串、数字),则通过 new Object(thisArg) 转为包装对象(自动装箱)。
- 临时挂载函数:为避免污染目标对象,使用 Symbol 生成唯一键,将目标函数临时挂载到 thisArg 上(如 thisArgfnKey = this)。
- 执行函数并传参:通过 thisArgfnKey 调用函数,此时函数执行的 this 自然指向 thisArg,同时将 call 后续传入的参数按顺序传递给函数。
- 清理临时属性:删除挂载在 thisArg 上的临时函数,避免目标对象被污染。
- 返回执行结果:返回目标函数的执行结果,确保原函数的返回值正确传递。
- 关键设计:规避属性污染与兼容性
- 唯一键生成:使用 Symbol 生成临时属性名,避免与目标对象已有属性冲突,这是保证无副作用的核心。
- 边界处理:兼容原始类型、null/undefined 等边界情况,确保 this 指向符合规范(如原始类型自动装箱,null/undefined 指向全局对象)。
- 结果传递:严格保留原函数的返回值,确保调用链的完整性。
二、apply 的底层原理:数组传参 + 同核心逻辑
apply 与 call 的核心功能完全一致,均是立即执行函数并绑定 this,唯一区别是参数传递方式,其底层原理与 call 高度相似,仅在参数处理上存在差异:
- 核心机制:参数数组化传递
apply 的底层逻辑与 call 一致,均通过 "临时挂载 + 对象调用" 绑定 this,但参数传递采用 "数组 / 类数组对象" 形式,具体过程如下:- 核心步骤复用:与 call 相同,先处理 thisArg,生成唯一键,临时挂载函数,执行后清理临时属性。
- 参数展开:将传入的第二个参数(数组或类数组对象)展开为函数的参数列表,传递给目标函数(如 thisArgfnKey)。
- 与 call 的本质差异

- 核心共性
二者底层均通过临时挂载函数到目标对象,利用 "对象方法调用" 的规则强制绑定 this,执行后清理临时属性,本质是同一核心逻辑的两种参数传递变体,性能在现代 JS 引擎中无显著差异。
三、bind 的底层原理:柯里化 + 永久绑定 + 构造函数兼容
bind 与 call/apply 的核心区别是不立即执行函数,而是返回一个永久绑定 this 和预设参数的新函数,支持柯里化和构造函数兼容,底层原理更复杂,核心围绕 "闭包保存上下文 + 延迟执行" 展开:
-
核心机制:闭包保存绑定信息 + 延迟执行
bind 的底层逻辑是创建一个新函数(绑定函数),通过闭包永久保存绑定的 this 和预设参数,在后续调用时再执行原函数,具体过程如下:
- 保存原函数与参数:将调用 bind 的原函数(this)和预设参数(args,即 bind 除第一个参数外的其余参数)保存到闭包中,形成持久化的绑定信息。
- 创建新函数(绑定函数):返回一个新函数,该函数在被调用时,会合并预设参数和调用时传入的参数,再触发原函数执行。
- 处理 this 指向:
- 普通调用:绑定函数的 this 永久指向 bind 传入的第一个参数(目标对象),不受后续调用方式影响。
- 构造函数调用:若绑定函数被 new 调用,this 指向新创建的实例,而非 bind 传入的目标对象(需通过 instanceof 或 new.target 检测,确保构造函数的原型链正确)。
- 参数合并与执行:调用绑定函数时,将预设参数(bind 时传入)和调用参数(调用时传入)按顺序合并,通过 apply 调用原函数,传递合并后的参数和正确的 this。
- 原型链继承:确保绑定函数的原型链与原函数一致,避免因 bind 导致原型丢失(如通过中间函数继承原函数的 prototype)。
-
关键特性的底层支撑
- 永久绑定:通过闭包将目标对象和预设参数持久化,无论绑定函数后续如何调用,this 始终指向绑定的目标对象(除非被 new 覆盖),这是 bind 区别于 call/apply 的核心。
- 柯里化能力:支持预设部分参数,调用时补充剩余参数,通过参数合并实现参数分步传递,本质是函数柯里化的应用场景。
- 构造函数兼容:通过检测 new.target 或判断 this 是否为原函数的实例,确保 new 调用时 this 指向新实例,而非绑定的目标对象,同时保留原型链,避免构造函数失效。
四、三者底层共性:执行上下文的动态干预
call、apply、bind 的底层本质均是对 JavaScript 执行上下文中 this 绑定的动态干预,核心共性如下:
- 干预执行上下文的 this 绑定
JavaScript 函数执行时,引擎会根据调用方式(普通调用、方法调用、new 调用)自动确定 this,而三者的核心作用是绕过默认规则,强制指定 this 指向,本质是对执行上下文中 ThisBinding 的主动修改,确保函数在预设的上下文中执行。 - 底层核心逻辑的统一
三者的底层均依赖 "函数调用的本质 ------\[Call] 内部方法",通过显式传递 this 和参数,控制 \[Call] 执行时的上下文,区别仅在于执行时机(立即执行 vs 延迟执行)和参数传递方式(逐个传参 vs 数组传参 vs 参数预设)。 - 高阶函数特性的体现
三者均是高阶函数的典型应用:call/apply 接收函数作为操作对象,触发函数执行;bind 接收函数并返回新函数,通过函数的 "一等公民" 特性,实现上下文和参数的动态控制,支撑函数复用、柯里化、装饰器等高级编程模式。
五、核心差异总结
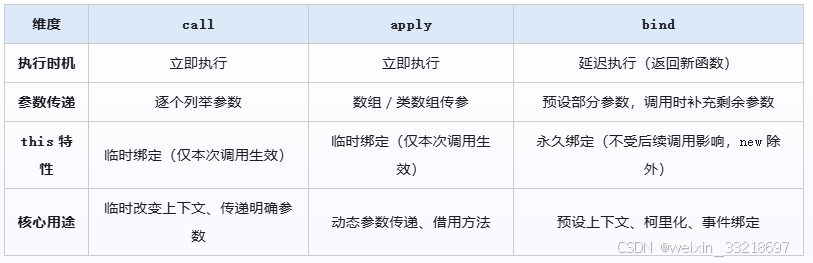 综上,call/apply/bind 的底层原理围绕执行上下文的 this 动态绑定展开,核心逻辑是 "控制函数执行时的上下文和参数",三者的差异源于对 "执行时机" 和 "参数传递" 的不同设计,共同构成了 JavaScript 灵活的函数调用控制体系。
综上,call/apply/bind 的底层原理围绕执行上下文的 this 动态绑定展开,核心逻辑是 "控制函数执行时的上下文和参数",三者的差异源于对 "执行时机" 和 "参数传递" 的不同设计,共同构成了 JavaScript 灵活的函数调用控制体系。
16. 立即执行函数IIFE是怎么工作的
立即执行函数(IIFE,Immediately Invoked Function Expression)是 JavaScript 中一种核心设计模式,其核心价值在于定义后立即执行,并创建独立的作用域,从而解决变量污染、作用域冲突等问题。其工作原理可拆解为以下关键步骤,结合语法机制、执行流程和底层逻辑,具体解析如下:
一、核心原理:函数声明转表达式 + 立即执行
IIFE 的核心机制是通过语法设计,将普通函数声明转换为函数表达式,并强制立即执行,从而避免函数声明提升带来的问题,同时创建独立作用域。
-
语法转换:避免函数声明提升
JavaScript 中,函数声明(如 function foo() {})会被提升至作用域顶部,若直接写匿名函数声明,会导致语法解析错误(JS 引擎会将其视为函数声明,但缺少函数名)。
IIFE 通过包裹括号,将函数声明强制转换为函数表达式,使 JS 引擎识别为可执行的表达式,而非待提升的声明。
-
立即执行:通过括号触发执行
函数表达式本身不会自动执行,需通过后续的括号调用。
转换后的函数表达式后紧跟另一对括号,用于传递参数(可选)并触发函数执行,实现 "定义即执行"。
二、执行流程:独立作用域创建与销毁
IIFE 的执行过程围绕 "作用域隔离" 展开,核心流程可分为三步,确保内部变量不污染外部作用域。
-
创建独立词法作用域
当 IIFE 被执行时,JavaScript 引擎会为其创建一个独立的词法作用域,该作用域与全局作用域完全隔离。
作用域内定义的变量、函数仅在 IIFE 内部可见,外部无法直接访问。
在 ES6 之前,IIFE 是实现 "私有作用域" 的核心手段,替代了缺失的块级作用域。
-
执行函数体代码
引擎立即执行 IIFE 函数体内的代码,完成变量初始化、逻辑运算等操作。
若 IIFE 接收参数,参数会在执行时传入函数体,实现外部数据与内部逻辑的隔离传递。
-
销毁作用域(无外部引用时)
当 IIFE 执行完毕,且其内部变量未被外部引用时,其作用域链会被销毁,释放内存。
若 IIFE 返回对象或函数,形成闭包,则作用域会被保留,供外部访问,但未暴露的变量仍保持私有。
三、关键机制:作用域隔离与变量保护
IIFE 的核心价值源于其对作用域的精准控制,通过语法设计和执行流程,实现变量保护和冲突避免。
-
避免全局变量污染
JavaScript 中,全局作用域的变量会挂载到全局对象(如浏览器的window),多脚本或多模块共用全局作用域时,易出现变量名冲突。
IIFE 将所有变量定义在内部作用域,不向全局暴露,从根源上避免污染。
-
解决循环中的闭包问题
ES6 之前,var声明的变量无块级作用域,循环中异步回调会捕获循环结束后的最终变量值(如for循环中setTimeout回调的i)。
IIFE 可为每次循环迭代创建独立作用域,将当前迭代值作为参数传入,使异步回调捕获正确的局部变量。
-
实现数据封装与模块化
IIFE 可通过返回对象暴露公共接口,未暴露的变量和函数保持私有,实现数据封装。
这种模式是 ES6 模块化出现前的主流模块化方案,可用于封装工具库、插件等。
四、语法形式与参数传递
IIFE 的语法灵活,支持多种写法,核心差异在于括号位置和参数传递方式,但本质逻辑一致。
-
基础语法形式
标准写法:(function(){ /* 代码 / })(),先包裹函数表达式,再调用。
变种写法:(function(){ / 代码 */ }()),将调用括号放在函数体后,效果完全相同。 -
带参数的 IIFE
IIFE 支持接收外部参数,参数会在执行时传入函数体,实现外部数据与内部逻辑的解耦。
五、底层逻辑:作用域链与执行上下文
从底层看,IIFE 的工作原理依托于 JavaScript 的作用域链和执行上下文机制:
-
作用域链隔离
IIFE 执行时,其执行上下文的作用域链仅包含自身创建的变量对象,不直接关联全局作用域,确保内部变量无法被外部访问。
-
执行上下文管理
当 IIFE 执行时,引擎会为其创建独立的执行上下文,入栈执行;执行完毕后,上下文出栈,若未形成闭包,其作用域会被销毁,完成内存回收。
-
闭包的可控性
若 IIFE 返回函数或对象,会形成闭包,此时内部作用域不会被销毁,外部可通过返回的接口访问内部数据,但未暴露的变量仍保持私有,实现 "可控的闭包"。
六、局限性与现代替代方案
尽管 IIFE 解决了 ES5 时代的诸多痛点,但仍存在一定局限性,现代 JavaScript 已提供更优的替代方案。
-
局限性
调试困难:匿名函数在调试时难以定位,无法通过函数名追踪执行流程。
性能开销:频繁创建独立作用域会增加内存和执行开销,尤其在大量使用的场景下。
-
现代替代方案
let/const:ES6 的块级作用域可直接限制变量作用范围,替代 IIFE 解决循环闭包、变量污染问题。
ES6 模块:通过import/export实现原生模块化,比 IIFE 更简洁、规范,支持静态分析、按需加载。
箭头函数:简化了函数表达式的写法,与 IIFE 结合时可减少语法冗余,但核心作用域逻辑仍依赖 IIFE 机制。
综上,IIFE 的工作原理本质是 "语法转换 + 独立作用域 + 立即执行",通过将函数声明转为表达式并立即执行,创建隔离的作用域,实现变量保护、冲突避免和模块化。尽管现代 JavaScript 已提供更优的替代方案,但 IIFE 仍是理解作用域、闭包和模块化的核心模型,在老旧项目维护、特定场景(如类库封装)中仍有实用价值。
17. 纯函数,副作用与函数式编程初识
要理解纯函数、副作用与函数式编程(FP),需要从"函数的本质"切入------函数式编程的核心是用"数学式的函数"解决编程问题,而纯函数和副作用正是这一理念的底层基石。
一、核心概念:纯函数与副作用
函数式编程的所有规则,都围绕"让函数更像数学函数"展开,而纯函数和副作用,是判断函数是否符合这一标准的关键。
- 纯函数:函数式编程的"基石"
纯函数是完全符合数学函数定义的编程函数,它必须同时满足两个铁律:
规则1:相同的输入,永远返回相同的输出
函数的输出仅由输入参数决定,不依赖任何外部状态(比如全局变量、外部文件、数据库等),也不随时间变化。
✅ 符合:
javascript
function add(a, b) {
return a + b; // 输入(2,3),永远返回5,和外部无关
}❌ 不符合:
javascript
let count = 0;
function getCount() {
return count++; // 输入无变化,但输出随全局变量count变化,不是纯函数
}规则2:没有副作用,不修改任何外部状态
函数内部不会修改参数(引用类型参数)、全局变量、DOM、数据库、网络请求等外部数据,也不会执行打印日志、弹出弹窗等与"计算结果"无关的操作。
✅ 符合:
javascript
function filterNumbers(arr, threshold) {
return arr.filter(num => num > threshold); // 返回新数组,不修改原数组
}❌ 不符合:
javascript
function modifyArray(arr) {
arr.push(100); // 直接修改了传入的数组(外部状态),产生副作用
return arr;
}纯函数的核心价值:可预测性。因为输入和输出严格绑定,没有外部干扰,所以纯函数天生具备"测试简单、复用性强、并发安全"的优势------这也是函数式编程追求的核心目标。
- 副作用:函数式编程的"敌人"
副作用是函数执行过程中,对函数外部产生的任何"额外影响",这些影响超出了"计算并返回结果"的核心职责,会导致函数的输出不再可控。
常见的副作用场景包括:
- 修改外部数据:修改全局变量、传入的引用类型参数、外部对象属性;
- IO操作:读写文件、操作DOM、发送网络请求、打印日志、弹出弹窗;
- 状态变更:修改数据库数据、修改应用状态(如Vuex/Redux的state);
- 抛出异常:中断程序执行,影响外部流程。
副作用的本质问题:破坏可预测性。比如一个函数既修改了全局变量,又返回一个值,那么多次调用它时,返回值可能因为全局变量的变化而不同,导致程序行为难以追踪,调试和维护成本飙升。
- 纯函数与副作用的关系:非此即彼
一个函数要么是纯函数,要么会产生副作用,二者无法共存:
纯函数 = 无副作用 + 输入输出确定:完全专注于"计算",不碰外部世界;
有副作用的函数 = 非纯函数:要么依赖外部状态,要么修改外部状态,输出不可控。
注意:副作用无法完全消除,只能被管理。实际开发中,IO操作、状态修改等副作用是必要的,但函数式编程的核心是将副作用隔离在可控范围内,让核心业务逻辑由纯函数承载。
二、函数式编程:以纯函数为核心的编程范式
函数式编程是一种以纯函数为核心,通过组合函数、避免状态共享、管理副作用来构建程序的编程范式,它的核心思想可以概括为:把计算过程当作数学函数的组合,让程序更简洁、可维护、可测试。
- 函数式编程的核心原则
函数式编程的所有实践,都围绕以下4个核心原则展开,而这些原则的本质,都是围绕"纯函数"和"管理副作用"设计的:
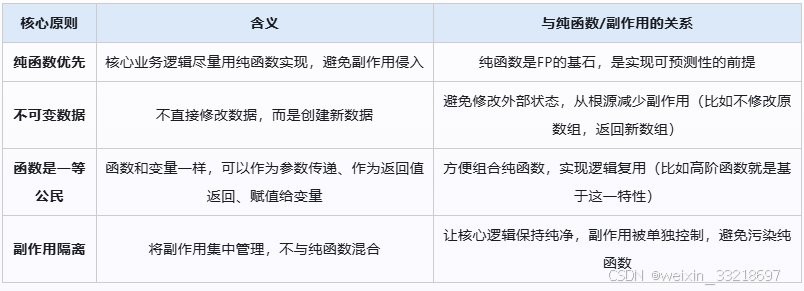
- 函数式编程的核心特性
基于上述原则,函数式编程衍生出一系列关键特性,这些特性都是纯函数和副作用管理的具体落地方式:
- 高阶函数:函数作为一等公民的直接体现,支持"接收函数作为参数"或"返回函数作为结果",本质是纯函数的组合工具。
例如:map、filter、reduce都是高阶函数,它们接收一个纯函数作为参数,对数据进行处理,且不修改原数据,返回新数据:
javascript
const numbers = [1, 2, 3];
// map是高阶函数,接收纯函数(num => num * 2),返回新数组,不修改原数组
const doubled = numbers.map(num => num * 2);
console.log(doubled); // [2,4,6]
console.log(numbers); // [1,2,3](原数组未被修改,符合不可变数据原则)- 函数组合:将多个纯函数按顺序串联,前一个函数的输出作为后一个函数的输入,形成"流水线"式的计算逻辑,本质是用纯函数组合实现复杂业务,避免副作用干扰。
例如:实现"用户年龄转字符串→截取前2位→转为数字"的组合:
javascript
// 纯函数1:年龄转字符串
const ageToString = age => String(age);
// 纯函数2:截取前2位
const sliceFirst2 = str => str.slice(0, 2);
// 纯函数3:字符串转数字
const strToNumber = str => Number(str);
// 组合函数:按顺序执行三个纯函数,输入输出完全可控
const processAge = compose(strToNumber, sliceFirst2, ageToString);
console.log(processAge(25)); // 25(输入25,输出25,过程无副作用)
// compose工具函数(函数组合的核心实现)
function compose(...fns) {
return function(input) {
return fns.reduceRight((result, fn) => fn(result), input);
};
}- 惰性求值:延迟执行函数计算,仅在需要结果时才执行,本质是优化纯函数的执行效率,避免不必要的计算(纯函数的输入输出确定,延迟执行不影响结果)。
例如:生成一个无限序列,仅在取前N个元素时才执行计算:
javascript
// 惰性生成自然数序列(纯函数,输入输出确定)
function* naturalNumbers() {
let n = 1;
while (true) {
yield n++;
}
}
const generator = naturalNumbers();
// 仅在取前5个数时才执行计算,避免一次性生成无限序列(浪费资源)
const first5 = [...Array(5).fill(null)].map(() => generator.next().value);
console.log(first5); // [1,2,3,4,5]- 柯里化:将多参数函数转换为一系列单参数函数,本质是方便纯函数的组合和复用(通过预设部分参数,生成新的纯函数,后续调用时仅需传递剩余参数,输入输出依然可控)。
例如:实现一个多参数的加法函数,通过柯里化转换为单参数函数:
javascript
// 柯里化工具函数
function curry(fn) {
return function curried(...args) {
if (args.length >= fn.length) {
return fn.apply(this, args);
}
return function(...nextArgs) {
return curried.apply(this, args.concat(nextArgs));
};
};
}
// 原函数:多参数加法
function add(a, b, c) {
return a + b + c;
}
// 柯里化后:每次传递一个参数,返回新函数,直到参数齐全才计算
const curriedAdd = curry(add);
const addA = curriedAdd(1); // 预设第一个参数,返回纯函数
const addAB = addA(2); // 传入第二个参数,返回纯函数
console.log(addAB(3)); // 6(输入(2,3),输出6,过程无副作用)- 函数式编程与命令式编程的核心区别
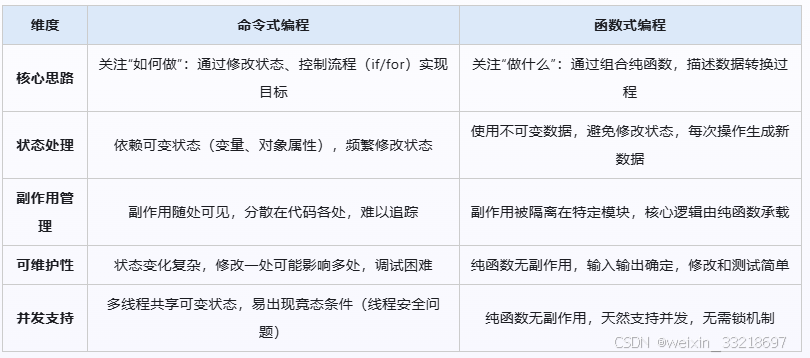
理解函数式编程,需要和主流的命令式编程(如传统JS、Java、Python)做对比,二者的核心差异,本质是"对副作用和状态的处理方式"不同:
三、总结:从概念到实践的核心逻辑
纯函数、副作用与函数式编程的关系,可以概括为一句话:函数式编程以纯函数为核心,通过管理副作用,实现程序的可预测性、可维护性和可测试性。
- 纯函数是基础:没有纯函数,函数式编程就失去了核心,程序会变得不可预测;
- 副作用是挑战:副作用无法消除,但可以通过容器模式、集中式状态管理等方案隔离,避免污染核心逻辑;
- 函数式编程是目标:通过纯函数、不可变数据、高阶函数、组合等实践,让程序更接近数学逻辑,降低复杂度,提升开发效率。
在实际开发中,不必追求100%的函数式编程,而是将函数式编程的核心思想融入日常开发:
- 核心业务逻辑尽量用纯函数实现,减少副作用;
- 不可变数据优先,避免直接修改状态;
- 用高阶函数和函数组合复用逻辑,替代复杂的流程控制;
- 副作用集中管理,不与核心逻辑混合。
18. 实战1: 手写bind实现
要手写一个符合规范的 bind 实现,需要理解其核心功能:绑定函数执行的 this 指向,并预置部分参数,返回一个可延迟执行的新函数,同时兼容构造函数场景。
一、bind的核心功能与规范要求
在实现前,需明确原生 Function.prototype.bind 的核心行为(依据ECMAScript规范):
- 绑定this:将目标函数的执行 this 强制指向传入的第一个参数(thisArg),若为 null/undefined,非严格模式下指向全局对象,严格模式下保持 null/undefined。
- 预置参数:bind 传入的除第一个参数外的其余参数,会作为预置参数,新函数执行时会拼接剩余参数。
- 返回新函数:不立即执行原函数,返回一个可延迟调用的函数(绑定函数),且该函数具备 length、name 等属性(符合函数标识)。
- 兼容构造函数:若返回的绑定函数被当作构造函数调用(通过 new),则绑定的 this 会被忽略,新创建的实例作为 this,且预置参数仍会生效。
- 属性特性:返回的函数具备原函数的原型链,且有自己的 length(预置参数后的剩余参数数量)和 name(与原函数一致,部分场景下有特殊处理)。
二、手写bind的核心步骤拆解
基于上述规范,手写 bind 需分步骤处理,核心逻辑围绕"参数处理、this绑定、函数返回、构造函数兼容"展开。
-
基础核心:this绑定与参数预置
首先定义 bind 的核心结构,接收两个参数:thisArg(要绑定的对象)和剩余参数(预置参数)。核心步骤如下:
- 保存原函数:bind 是挂载在 Function.prototype 上的方法,所以原函数就是调用 bind 的函数(即 this)。
- 处理预置参数:将 bind 传入的除第一个参数外的参数收集为数组(预置参数)。
- 返回绑定函数:新函数需要接收执行时传入的参数,与预置参数合并后调用原函数,且绑定 this。
- 绑定函数调用原函数:通过 apply 调用原函数,强制指定 this,同时合并预置参数和执行参数。
-
处理边界:thisArg的原始类型转换
根据规范,当 thisArg 是原始类型(如字符串、数字、布尔值)时,bind 会自动将其转为对应的包装对象,核心是调用 new Object(thisArg)。
-
兼容构造函数:new调用的优先级
当返回的绑定函数被 new 调用时,需忽略绑定的 thisArg,以新创建的实例作为 this,同时原函数的参数仍需正确传递。判断 new 调用的核心是:判断返回函数执行时的 this 是否是原函数的实例。
-
补充属性:length与name
原生 bind 返回的函数具备原函数的 length 和 name(部分场景下),需手动补充:
- length:表示函数的参数数量,绑定函数的 length 是原函数 length 减去预置参数的数量,最小为 0。
- name:返回函数的 name 与原函数一致,如果原函数没有 name,部分实现会设为 "bound " 加原函数名。
-
处理原型链:绑定函数的继承
绑定函数需要继承原函数的原型,确保通过绑定函数 new 创建的实例能正确继承原函数的原型链。
三、完整手写bind实现(符合规范)
javascript
// 手写 Function.prototype.bind
Function.prototype.bind = function(thisArg, ...presetArgs) {
// 保存原函数(this 就是调用 bind 的函数)
const originalFn = this;
// 核心:获取原函数的参数数量(用于计算绑定函数的 length)
const originalLength = originalFn.length;
// 处理 thisArg 为原始类型的情况:转为对应的包装对象
if (thisArg === null || thisArg === undefined) {
// 严格模式下 thisArg 保持 null/undefined,非严格模式下指向全局对象
// 这里通过 context 变量处理,后续根据执行环境区分(实际原生 bind 是严格遵循执行环境的,此处简化为模拟核心逻辑)
// 更严谨的实现需判断执行时的严格模式,此处简化为:若 thisArg 是原始类型,转为对象
thisArg = new Object(thisArg);
} else if (typeof thisArg === 'symbol') {
// symbol 类型直接转为对象(Symbol 是原始类型,包装后仍为 Symbol 对象)
thisArg = new Object(thisArg);
} else if (typeof thisArg !== 'object') {
// 其他原始类型(string/number/boolean)转为包装对象
thisArg = new Object(thisArg);
}
// 创建绑定函数,接收执行时传入的参数
const boundFn = function(...executeArgs) {
// 判断是否是通过 new 调用绑定函数:核心依据是 this 是否指向 originalFn 的实例
const isNewCall = this instanceof originalFn;
// 确定最终的 this 指向:
// 如果是 new 调用,this 是新实例,忽略绑定的 thisArg;否则使用绑定的 thisArg
const finalThis = isNewCall ? this : thisArg;
// 合并预置参数和执行参数,作为最终传递给原函数的参数
const finalArgs = presetArgs.concat(executeArgs);
// 调用原函数,绑定 this 指向,传递合并后的参数
return originalFn.apply(finalThis, finalArgs);
};
// 继承原函数的原型:确保绑定函数通过 new 创建的实例能继承原函数原型
// 获取原函数的原型,若为 null(比如 Function.prototype),则设为 Object.prototype
const originalProto = originalFn.prototype || Object.prototype;
// 创建新的原型对象,继承原函数的原型
const boundProto = Object.create(originalProto);
// 绑定函数的原型指向新创建的原型对象
boundFn.prototype = boundProto;
// 补充 length 属性:绑定函数的 length = 原函数 length - 预置参数数量,最小为 0
const presetCount = presetArgs.length;
boundFn.length = Math.max(0, originalLength - presetCount);
// 补充 name 属性:绑定函数的 name 与原函数一致
// 原生规范中,bind 后的函数 name 是 "bound " + 原函数 name(如果原函数有 name)
const originalName = originalFn.name;
boundFn.name = originalName ? `bound ${originalName}` : 'bound';
// 返回绑定函数
return boundFn;
};四、关键测试:验证手写bind的正确性
通过以下测试用例,验证手写 bind 是否覆盖核心规范,确保功能正确:
- 基础:this绑定与参数预置
javascript
// 测试 1:基础 this 绑定和参数预置
function greet(greeting, name) {
return `${greeting}, ${this.name}! I'm ${name}`;
}
const user = { name: 'Alice' };
const boundGreet = greet.bind(user, 'Hello');
console.log(boundGreet('Bob')); // 输出:"Hello, Alice! I'm Bob"(this 绑定正确,预置参数生效)
console.log(boundGreet.length); // 输出:1(原函数 length 2,预置 1 个参数,剩余 1 个)
console.log(boundGreet.name); // 输出:"bound greet"(name 正确继承)- 原始类型thisArg处理
javascript
// 测试 2:原始类型 thisArg(转为包装对象)
function getType(value) {
return this.type + ': ' + value;
}
const boundType = getType.bind('string'); // thisArg 是字符串,转为 String 对象
console.log(boundType('test')); // 输出:"string: test"(正确转为包装对象)
const boundNumber = getType.bind(123); // thisArg 是数字,转为 Number 对象
console.log(boundNumber('num')); // 输出:"number: num"- null/undefined的thisArg(非严格模式)
javascript
// 测试 3:thisArg 为 null/undefined(非严格模式下指向全局对象)
function getGlobalName() {
return this.name;
}
// 注意:若在严格模式下执行,thisArg 会保持 null/undefined,但手写实现默认模拟非严格场景(实际需判断执行环境)
// 此处在浏览器控制台测试,thisArg 为 null 时指向 window
const globalObj = typeof window !== 'undefined' ? window : global;
globalObj.name = 'Global';
const boundGlobal = getGlobalName.bind(null);
console.log(boundGlobal()); // 输出:"Global"(this 指向全局对象)- 构造函数兼容:new调用优先
javascript
// 测试 4:new 调用绑定函数,忽略绑定的 thisArg
function Person(name, age) {
this.name = name;
this.age = age;
}
Person.prototype.say = function() {
return `I'm ${this.name}, ${this.age} years old`;
};
// 绑定 thisArg(此处会被 new 忽略),预置参数
const boundPerson = Person.bind({ name: 'Temp' }, 'Alice');
const instance = new boundPerson(25); // new 调用,this 指向新实例
console.log(instance.name); // 输出:"Alice"(预置参数生效,绑定的 thisArg 被忽略)
console.log(instance.age); // 输出:25
console.log(instance.say()); // 输出:"I'm Alice, 25 years old"(原型链正确)
console.log(instance instanceof Person); // 输出:true(继承原函数的原型)- 多参数预置与合并
javascript
// 测试 5:多参数预置
function sum(a, b, c) {
return a + b + c;
}
const boundSum = sum.bind(null, 1, 2); // 预置 2 个参数
console.log(boundSum(3)); // 输出:6(1+2+3,参数合并正确)
console.log(boundSum.length); // 输出:1(原函数 length 3,预置 2 个,剩余 1 个)19. 实战2: 手写柯里化函数
手写柯里化(Currying)函数,核心是围绕参数分步收集和执行时机控制展开------将多参数函数拆解为一系列单参数函数,直到收集到满足原函数所需数量的参数,再执行原函数并返回结果。它不仅是函数式编程的核心技巧,更本质的是通过闭包实现参数的持久化存储,让函数具备"预置部分参数、延迟执行"的能力。
一、柯里化的核心原理:参数收集与执行触发
柯里化的本质是将多参数函数转化为单参数函数链,核心要解决两个问题:
- 参数持久化:收集一次参数后,能记住这些参数,等待后续参数补充;
- 执行时机判断:当收集的参数达到原函数所需数量时,触发原函数执行。
核心逻辑拆解
- 函数本质:柯里化返回的不是原函数,而是一个闭包函数------闭包会持久化已收集的参数,等待下一次调用时继续收集;
- 执行条件:当闭包收集的参数数量等于原函数的参数长度(fn.length)时,触发原函数执行;
- 返回值差异:未满足执行条件时,返回新的闭包函数(继续收集参数);满足条件时,返回原函数的执行结果;
- 边界处理:允许预置参数(调用柯里化时传入的初始参数),这些参数会直接加入闭包存储,无需后续补充。
二、基础版柯里化:实现核心参数收集与执行逻辑
javascript
/**
* 基础版柯里化函数
* @param {Function} fn - 需要柯里化的多参数函数
* @param {Array} presetArgs - 预置参数(可选,初始收集的参数)
* @returns {Function} - 柯里化后的函数(闭包,用于继续收集参数)
*/
function curry(fn, presetArgs = []) {
// 核心约束:fn必须是函数,否则抛出错误
if (typeof fn !== 'function') {
throw new TypeError('Curry function target must be a function');
}
// 闭包核心:存储已收集的参数,每次调用闭包时追加新参数
return function curried(...newArgs) {
// 合并预置参数和新收集的参数
const allArgs = presetArgs.concat(newArgs);
// 执行判断:当收集的参数数量 >= 原函数参数长度时,执行原函数
// 注意:JavaScript中函数的length属性表示形参个数(不包含默认参数、剩余参数)
if (allArgs.length >= fn.length) {
// 调用原函数,传入所有收集的参数,返回结果
return fn.apply(this, allArgs);
} else {
// 未满足执行条件,返回新的闭包函数,继续收集参数
return curry(fn, allArgs);
}
};
}20. 面试常问的函数题
一、基础概念类
- 函数声明 vs 函数表达式
区别:函数声明会被提升(可在定义前调用),而函数表达式不会。
函数声明:直接以function关键字开头,后跟函数名、参数列表和函数体的语法形式,是独立的语句,用于明确定义具名函数。
函数表达式:将函数作为表达式的一部分(通常赋值给变量),以function关键字定义函数,再通过变量引用该函数,可省略函数名形成匿名函数,也可保留具名形式。
javascript
console.log(add(2, 3)); // 输出: 5
function add(a, b) { return a + b; } // (函数声明)
console.log(addExp(2, 3)); // 报错:addExp is not defined
const addExp = function(a, b) { return a + b; }; // (函数表达式)- 纯函数与副作用
纯函数:相同输入必得相同输出,无副作用(不修改外部状态)。
副作用示例:修改全局变量、DOM操作、网络请求等。
二、作用域与 this 绑定
- this 指向规则
普通函数:由调用方式决定(call/apply/bind 可显式绑定)。
箭头函数:继承外层作用域的 this。
示例:
javascript
const obj = {
name: 'Tom',
greet() { console.log(this.name); }, // 普通函数
arrowGreet: () => console.log(this.name) // 箭头函数
};
obj.greet(); // Tom (this 指向 obj)
obj.arrowGreet(); // undefined (this 指向全局作用域)- 闭包的应用与风险
用途:访问私有变量、封装模块逻辑。
风险:内存泄漏(需及时释放引用)。
javascript
function createCounter() {
let count = 0;
return function() { return ++count; };
}
const counter = createCounter();
console.log(counter()); // 1三、高阶函数与函数式编程
- 高阶函数定义
接受函数作为参数或返回函数的函数。
示例:数组方法 map、filter 均为高阶函数。
javascript
[1, 2, 3].map(x => x * 2); // [2, 4, 6]- 柯里化的实现与用途
定义:将多参数函数转换为一系列单参数函数。
示例:
javascript
function curry(fn) {
return function curried(...args) {
if (args.length >= fn.length) return fn.apply(this, args);
return function(...moreArgs) { return curried.apply(this, args.concat(moreArgs)); };
};
}
const add = (a, b, c) => a + b + c;
const curriedAdd = curry(add);
console.log(curriedAdd(1)(2)(3)); // 6四、递归与算法
递归的典型场景
- 阶乘计算:
javascript
function factorial(n) { return n <= 1 ? 1 : n * factorial(n - 1); }- 斐波那契数列
javascript
function fib(n) { return n <= 1 ? n : fib(n-1) + fib(n-2); }递归优化:尾递归
- 优势:减少栈空间占用。
- 示例:尾递归版阶乘
javascript
function factorial(n, acc = 1) {
return n <= 1 ? acc : factorial(n - 1, n * acc);
}五、异步与回调函数
- 回调函数的作用
用途:处理异步操作(如定时器、网络请求)。
示例:延迟打印
javascript
function fetchData(callback) {
setTimeout(() => callback('Data'), 1000);
}
fetchData(data => console.log(data)); // "Data"六、参数处理与动态函数创建
- 动态创建函数
使用 new Function:动态生成函数。
示例:
javascript
const multiply = new Function('a', 'b', 'return a * b');
console.log(multiply(2, 3)); // 6- 处理动态参数
利用 arguments 对象:获取所有传入参数。
示例:求和函数
javascript
function sum() {
return Array.from(arguments).reduce((a, b) => a + b, 0);
}七、高频算法题
- 回文数判断
思路:反转数字后比较。
javascript
function isPalindrome(num) {
const reversed = parseInt(num.toString().split('').reverse().join(''));
return num === reversed;
}- 水仙花数筛选
定义:三位数且各位立方和等于自身(如)
javascript
function findNarcissusNumbers() {
for (let i = 100; i < 1000; i++) {
const digits = String(i).split('').map(Number);
if (digits.reduce((sum, d) => sum + d**3, 0) === i) console.log(i);
}
}八、性能与优化
-
尾递归优化
原理:编译器重用栈帧,避免栈溢出。
适用场景:深度递归计算(如大数阶乘)。
-
函数节流与防抖
节流:固定间隔执行一次。
防抖:等待一段时间后再执行。
21 setTimeout和setInterval的最佳实践
一、基础用法规范
- 明确延迟时间的单位与类型
规范:始终使用数值型延迟(单位毫秒),避免隐式类型转换。
反例:
javascript
setTimeout(fn, "1000"); // 字符串会被转为整数(但可能引发意外行为)正例:
javascript
setTimeout(fn, 1000); // 直接使用数值- 优先使用 setTimeout 替代 setInterval
原因:setInterval 无法感知回调执行耗时,可能导致任务堆积。
替代方案:用 setTimeout 递归实现动态间隔调度。
javascript
function intervalTask(interval) {
// 执行任务...
setTimeout(() => intervalTask(interval), interval);
}
setTimeout(() => intervalTask(1000), 1000); // 首次延迟 1s二、精准控制执行时机
- 动态调整间隔时间
场景:根据系统负载或业务需求动态调整间隔。
示例:指数退避算法(Exponential Backoff)
javascript
let delay = 1000;
function retry() {
fetchData().catch(err => {
delay = Math.min(delay * 2, 30000); // 最大延迟 30 秒
setTimeout(retry, delay);
});
}- 利用 requestAnimationFrame 优化高频操作
适用场景:动画、滚动事件等需要与屏幕刷新率同步的操作。
对比:
javascript
// ❌ 低效方式
setInterval(updatePosition, 16); // 假设 60Hz 屏幕
// ✅ 高效方式
function updatePosition() {
// 更新逻辑...
requestAnimationFrame(updatePosition);
}
requestAnimationFrame(updatePosition);三、内存与资源管理
- 强制清理未使用的定时器
关键动作:在组件销毁、页面跳转时清除定时器。
框架集成示例(React):
javascript
useEffect(() => {
const timerId = setInterval(() => {}, 1000);
return () => clearInterval(timerId); // 组件卸载时清理
}, []);- 避免闭包持有大对象引用
风险:回调函数若引用外部大数据,会导致内存无法释放。
优化方案:及时解除引用并手动触发垃圾回收。
javascript
function createTimer() {
let largeData = new Array(1e6).fill('data');
const timerId = setInterval(() => {
console.log(largeData.length);
largeData = null; // 主动释放引用
clearInterval(timerId); // 停止定时器
}, 1000);
}四、代码健壮性增强
- 防御性错误处理
模式:在回调中捕获异常,防止程序崩溃。
javascript
setTimeout(() => {
try {
riskyOperation();
} catch (err) {
console.error('Operation failed:', err);
}
}, 1000);8. 封装可复用的定时器工具函数
示例:带自动清理功能的通用定时器
javascript
const createSafeTimer = (callback, delay) => {
let timerId;
const start = () => {
timerId = setTimeout(() => {
try { callback(); }
finally { timerId = null; }
}, delay);
};
const stop = () => clearTimeout(timerId);
return { start, stop };
};
// 使用
const timer = createSafeTimer(() => console.log('Done!'), 1000);
timer.start();
// 必要时调用 timer.stop();五、高级技巧与模式
- 组合使用 Promise 和 setTimeout
用途:将异步操作转换为基于 Promise 的 API
javascript
const delay = (ms) => new Promise(resolve => setTimeout(resolve, ms));
async function process() {
await delay(1000);
console.log('1 second passed');
}- 微任务与宏任务协同调度
优先级排序:微任务(如 Promise.then)优先于宏任务(如 setTimeout)。
应用案例:确保关键逻辑先于 UI 更新执行
javascript
Promise.resolve().then(() => {
console.log('Microtask runs first');
});
setTimeout(() => {
console.log('Macrotask runs later');
}, 0);六、调试与监控
- 记录定时器生命周期
调试技巧:在创建和清理时打印日志,追踪潜在泄漏
javascript
const originalSetTimeout = window.setTimeout;
window.setTimeout = function(callback, delay) {
console.log('Timer created with delay:', delay);
return originalSetTimeout((...args) => {
console.log('Timer executed');
return callback(...args);
}, delay);
};- 使用 Performance Monitoring API
监控指标:测量实际延迟时间和回调执行时长。
javascript
const observer = new PerformanceObserver((list) => {
for (const entry of list.getEntries()) {
console.log(`Function took ${entry.duration}ms to execute`);
}
});
observer.observe({ entryTypes: ['measure'] });七、典型场景解决方案

八、总结清单
✅ 总是清理不再需要的定时器
✅ 优先使用 setTimeout 递归替代 setInterval
✅ 对高频操作使用 requestAnimationFrame
✅ 避免在回调中引用不必要的外部变量
✅ 为关键回调添加错误捕获机制
✅ 封装可复用的定时器管理工具
✅ 监控定时器的实际执行情况
22 谈谈JS中的事件循环(Event Loop)
一、核心概念:为什么需要事件循环?
JavaScript 是单线程语言,所有任务必须按顺序执行,如果某个任务耗时过长(如网络请求、文件读写),会阻塞后续代码运行。为了解决这一问题,浏览器和 Node.js 引入了事件循环机制,通过多线程协作实现非阻塞 I/O 操作,让主线程专注于执行计算密集型任务,同时高效处理异步回调。
二、事件循环的核心组件
- 调用栈(Call Stack)
作用:管理函数执行顺序的栈结构,遵循后进先出(LIFO)原则。
示例:
javascript
function foo() { console.log('foo'); }
function bar() { foo(); }
bar(); // 调用栈变化:bar() → foo() → 清空- Web APIs(浏览器环境) / libuv(Node.js)
作用:提供异步能力(如 setTimeout、fetch、DOM 事件监听),由独立线程处理,完成后将回调放入任务队列。
关键点:与主线程解耦,避免阻塞。 - 任务队列(Task Queue)
分类:
宏任务队列(Macrotask Queue):包含 setTimeout、setInterval、DOM 渲染、I/O 操作等。
微任务队列(Microtask Queue):包含 Promise.then/catch/finally、MutationObserver、queueMicrotask。
优先级:微任务队列优先级高于宏任务队列。
三、事件循环的执行流程
- 整体流程图
javascript
┌─────────────────────────────┐
│ 主线程(Main Thread)│
├─────────────────────────────┤
│ 1. 执行同步代码 │
│ → 调用栈压入函数 │
│ → 执行完毕弹出函数 │
└────────────┬────────────────┘
▼
┌─────────────────────────────┐
│ 2. 检查微任务队列 │
│ → 依次执行所有微任务 │
│ → 若产生新微任务,继续执行│
└────────────┬────────────────┘
▼
┌─────────────────────────────┐
│ 3. 渲染页面(仅浏览器) │
│ → 更新 DOM │
│ → 执行 requestAnimationFrame
└────────────┬────────────────┘
▼
┌─────────────────────────────┐
│ 4. 检查宏任务队列 │
│ → 取出一个宏任务执行 │
│ → 重复步骤 1~4 │
└─────────────────────────────┘- 关键步骤解析
步骤 1:主线程执行同步代码,直到调用栈为空。
步骤 2:立即处理所有微任务(保证高优先级任务优先完成)。
步骤 3:浏览器尝试渲染(约每秒 60 次)。
步骤 4:取一个宏任务执行,回到步骤 1,形成循环。
四、经典案例分析
案例 1:基础输出顺序
javascript
console.log('A'); // 同步任务
setTimeout(() => {
console.log('B'); // 宏任务
}, 0);
Promise.resolve().then(() => {
console.log('C'); // 微任务
});
// 输出顺序:A → C → B案例 2:嵌套异步任务
javascript
setTimeout(() => {
console.log('Timer 1');
Promise.resolve().then(() => console.log('Microtask inside Timer'));
}, 0);
Promise.resolve().then(() => {
console.log('Initial Microtask');
setTimeout(() => console.log('Timer 2'), 0);
});
// 输出顺序:
// Initial Microtask
// Timer 1
// Microtask inside Timer
// Timer 2五、浏览器 vs Node.js 的差异
六、最佳实践与常见误区
- 合理使用微任务
适用场景:需要紧接在当前任务后执行的逻辑(如数据更新后立即修改视图)。
反例:在微任务中执行耗时操作,导致页面卡顿。 - 避免过度嵌套回调
问题:深层嵌套会导致调用栈溢出(Stack Overflow)。
解决方案:改用 async/await 或拆分任务。 - 监控事件循环延迟
工具:
浏览器:Performance Tab 查看 Long Tasks。
Node.js:event-loop-lag 模块检测延迟。
七、总结
事件循环是 JavaScript 异步编程的基石,其核心思想是通过分阶段调度任务平衡响应速度与资源利用率。掌握以下要点即可应对大多数场景:
- 同步 > 微任务 > 宏任务 的优先级关系。
- 浏览器和 Node.js 在阶段划分上的差异。
- 避免在微任务中执行重计算或无限循环。
- 使用 requestAnimationFrame 替代 setTimeout 优化动画性能。
23 Promise基本用法
一、Promise 核心概念
-
什么是 Promise?
定义:Promise 是 ES6 引入的异步编程解决方案,表示一个异步操作的最终完成或失败及其结果值。
特点:
三种状态:pending → fulfilled / rejected(一旦改变不可逆转)
解决回调地狱(Callback Hell)
支持链式调用
-
基本语法结构
javascript
const promise = new Promise((resolve, reject) => {
// 异步操作(如网络请求、定时器等)
if (/* 成功条件 */) {
resolve(result); // 将状态改为 fulfilled,传递结果
} else {
reject(error); // 将状态改为 rejected,传递错误
}
});
// 使用 .then() 和 .catch() 处理结果
promise
.then(value => { /* 成功处理 */ })
.catch(err => { /* 失败处理 */ });二、Promise 基本用法详解
- 创建 Promise
示例 1:封装 setTimeout
javascript
function delay(ms) {
return new Promise(resolve => {
setTimeout(resolve, ms);
});
}
// 使用
delay(2000).then(() => console.log('2秒后执行'));示例 2:模拟异步数据获取
javascript
function fetchData() {
return new Promise((resolve, reject) => {
setTimeout(() => {
const data = { id: 1, name: 'Example' };
resolve(data); // 成功返回数据
// 如果出错则调用 reject(new Error('Failed'))
}, 1000);
});
}
fetchData().then(data => console.log(data)); // 输出 {id: 1, name: 'Example'}- 链式调用(关键!)
通过连续的 .then() 实现多个异步操作串联,避免嵌套回调。
javascript
doTaskA()
.then(resultA => doTaskB(resultA))
.then(resultB => doTaskC(resultB))
.then(finalResult => console.log('All done:', finalResult))
.catch(error => console.error('Error:', error));- 并行执行多个 Promise
使用 Promise.all() 等待所有任务完成,或 Promise.race() 取最快完成的。
javascript
// 并行执行三个异步任务
const p1 = fetch('/api/user');
const p2 = fetch('/api/posts');
const p3 = fetch('/api/comments');
Promise.all([p1, p2, p3])
.then(responses => Promise.all(responses.map(r => r.json())))
.then(data => console.log('All data:', data))
.catch(err => console.error('One failed:', err));
// Race: 谁快用谁(适合超时控制)
Promise.race([fetchData(), timeoutPromise(5000)])
.then(result => console.log('Got result:', result));三、错误捕获机制
- .catch() 捕获异常
javascript
makeRequest()
.then(data => processData(data))
.catch(error => {
console.error('Request failed:', error);
// 可在此进行重试、显示错误提示等操作
});- try/catch 配合 async/await(推荐现代写法)
javascript
async function fetchUser() {
try {
const response = await fetch('/api/user');
if (!response.ok) throw new Error('Network response was not ok');
const user = await response.json();
return user;
} catch (error) {
console.error('Fetch error:', error);
throw error; // 可选择继续抛出或处理
}
}
// 调用处也需要 try/catch
async function init() {
try {
const user = await fetchUser();
console.log('User loaded:', user);
} catch (error) {
alert('加载用户失败,请刷新页面');
}
}- 全局未处理异常(谨慎使用)
浏览器环境可通过监听 unhandledrejection 事件兜底:
javascript
window.addEventListener('unhandledrejection', event => {
console.error('Unhandled promise rejection:', event.reason);
// 可上报错误日志
});Node.js 环境类似:
javascript
process.on('unhandledRejection', (reason, promise) => {
console.error('Unhandled Rejection at:', promise, 'reason:', reason);
process.exit(1);
});四、常见错误场景与解决方案

五、实战案例:带错误处理的文件上传
javascript
class Uploader {
upload(file) {
return new Promise((resolve, reject) => {
const xhr = new XMLHttpRequest();
xhr.open('POST', '/upload');
xhr.onload = () => {
if (xhr.status >= 200 && xhr.status < 300) {
resolve(JSON.parse(xhr.responseText));
} else {
reject(new Error(`Upload failed: ${xhr.status}`));
}
};
xhr.onerror = () => reject(new Error('Network error'));
xhr.send(file);
});
}
}
// 使用示例
const uploader = new Uploader();
uploader.upload(file)
.then(res => showSuccess(res))
.catch(err => showError(err.message))
.finally(() => hideLoading());24. async, await的底层运行机制
一、语法糖本质:基于 Promise 和生成器的封装
- 语法层面:async = function*,await = yield,是 Generator 的"语法糖",让代码更简洁。
- 执行层面:async/await 依赖自动执行器(引擎内置),自动调用 next() 推进 Generator 执行,无需手动操作。
- 异步调度:await 后的异步操作(如 Promise)完成后,会通过微任务队列触发自动执行器(保证当前同步代码执行完后再恢复),这和 Event Loop 机制一致。
二、关键组件
- Promise:用于表示异步操作的结果状态(pending/fulfilled/rejected),是 await 等待的对象。
- 生成器(Generator):提供暂停(yield)和恢复(next())的能力,模拟异步流程控制。
- 自动执行器:引擎内置或手动实现的执行器(类似 co 库),负责递归调用 next(),驱动生成器自动执行,无需手动操作。
示例验证:await 与 Promise.then 的执行顺序
javascript
async function fn() {
console.log('A'); // 同步代码,立即执行
await Promise.resolve(); // 暂停,恢复代码入微任务队列
console.log('B'); // 微任务1:await 恢复代码
}
fn();
Promise.resolve().then(() => console.log('C')); // 微任务2:Promise.then 回调
// 执行顺序:A → B → C
// 原因:
// 1. 先执行同步代码 A;
// 2. 遇到 await,恢复代码 B 入微任务队列;
// 3. 执行 fn() 返回的 Promise 的 then 逻辑,将 C 入微任务队列;
// 4. 微任务队列按入队顺序执行:先 B(await 恢复),再 C(Promise.then)。核心本质:
- async/await 并非创造新的异步能力,而是对 Promise 的语法包装,其底层完全依赖 Promise 实现异步流程控制。一句话总结:async 函数本质是返回 Promise 的生成器函数,await 本质是 yield 的语法糖,配合自动执行器(如 async/await 的内置执行器)实现异步流程的暂停与恢复。
关键结论:
- 生成器通过 yield 暂停,通过 next(value) 恢复,形成 "暂停→等待→恢复" 的可控流程,这正是 async/await 实现异步暂停的核心基础。
- async/await 的底层就是 生成器 + Promise + 自动执行器 的组合,async 函数对应带自动执行器的生成器,await 对应 yield,自动执行器负责处理 Promise 的 resolve/reject,自动推进生成器的执行。
- async 函数无论有没有 await,执行后都返回 Promise,区别仅在于:有 await 时,Promise 的结果由 await 后的异步操作决定;无 await 时,Promise 的结果由 return 值决定。
- async 是生成器函数,返回 Promise;
- await 是 yield,负责暂停和恢复,后续代码是微任务;
- 所有 async/await 的异步流程,最终都转化为 Promise 的微任务调度,遵循事件循环的优先级规则。
场景1:多个 await 的执行顺序
javascript
async function fn() {
console.log('1');
await Promise.resolve(); // 第一个 await,恢复代码入微任务1
console.log('2');
await Promise.resolve(); // 第二个 await,恢复代码入微任务2
console.log('3');
return '结果';
}
fn().then(res => console.log('4:', res));
console.log('5');
// 执行顺序:1 → 5 → 2 → 3 → 4: 结果
// 底层解释:
// 1. 执行同步代码:输出 1,遇到第一个 await,暂停,微任务1(输出2)入队;
// 2. 继续执行同步代码:输出 5,fn().then 的回调入微任务队列(微任务3);
// 3. 处理微任务队列:执行微任务1(输出2),遇到第二个 await,暂停,微任务2(输出3)入队;
// 4. 继续处理微任务队列:执行微任务2(输出3),fn 返回结果,微任务3(输出4)入队;
// 5. 处理微任务3:输出 4。场景2:await 后的普通值处理
javascript
async function fn() {
const res = await 123; // 普通值,自动包装为 Promise.resolve(123)
console.log(res); // 输出:123
}
fn();
// 底层解释:await 123 等价于 await Promise.resolve(123),所以会正常恢复,拿到 123。场景3:async 函数的返回值始终是 Promise
javascript
function fn1() {
return 123;
}
async function fn2() {
return 123;
}
console.log(fn1()); // 123(普通值)
console.log(fn2()); // Promise { <pending> }(Promise)
// 底层解释:async 函数的返回值会被内置执行器自动包装成 Promise,所以无论 return 什么,最终都返回 Promise。25. Promise.all / allSettled / race / any用法
1. Promise.all(iterable)
- 作用
- 等待 所有 Promise 成功 resolve,返回包含所有结果的数组。
- 如果 任意一个 Promise 被 reject,立即中断并抛出第一个被 reject 的原因。
- 适用场景
- 并行执行多个独立任务,且需要全部成功才能继续。
- 代码示例
javascript
const p1 = Promise.resolve('Result A');
const p2 = new Promise((resolve) => setTimeout(() => resolve('Result B'), 1000));
const p3 = fetch('/api/data').then(res => res.json());
Promise.all([p1, p2, p3])
.then(results => {
console.log(results); // ['Result A', 'Result B', { data: ... }];
})
.catch(error => {
console.error('One task failed:', error);
});- 注意事项
- 如果传入非 Promise 值(如普通值),会被自动转为 Promise.resolve。
- 一旦某个任务失败,其他任务的结果会被丢弃。
2. Promise.allSettled(iterable)
- 作用
- 等待 所有 Promise 完成(无论成功或失败),返回每个结果的状态对象数组。
- 永远不会 rejected,始终 resolved。
- 适用场景
- 需要知道所有任务的最终状态(成功/失败),不关心是否全部成功。
- 代码示例
javascript
const p1 = Promise.resolve('Success');
const p2 = Promise.reject(new Error('Failed'));
const p3 = fetch('/api/data');
Promise.allSettled([p1, p2, p3])
.then(results => {
results.forEach((result, index) => {
console.log(`Task ${index}:`, result.status); // "fulfilled" 或 "rejected"
if (result.status === 'fulfilled') {
console.log('Value:', result.value);
} else {
console.log('Reason:', result.reason);
}
});
});输出结构
javascript
[
{ status: 'fulfilled', value: 'Success' },
{ status: 'rejected', reason: Error('Failed') },
{ status: 'fulfilled', value: { data: ... } }
]3. Promise.race(iterable)
- 作用
- 等待 第一个 settled 的 Promise(无论是 resolve 还是 reject),返回其结果或错误原因。
- 适用场景
- 实现超时控制、竞速多个可能的异步来源。
- 代码示例
javascript
// 超时控制示例
const fetchWithTimeout = Promise.race([
fetch('/api/data'),
new Promise((_, reject) =>
setTimeout(() => reject(new Error('Timeout')), 5000)
)
]);
fetchWithTimeout
.then(data => console.log('Data received:', data))
.catch(error => console.error('Error:', error));- 注意事项
- 如果第一个 settled 的 Promise 是 rejected,整个 race 会直接抛出错误。
4. Promise.any(iterable)
- 作用
- 等待 第一个 fulfilled 的 Promise,返回其结果。
- 如果 所有 Promise 都 rejected,则整体 rejected,并返回 AggregateError。
- 适用场景
- 只需任意一个任务成功即可,无需等待全部完成。
- 代码示例
javascript
const p1 = Promise.reject('Error 1');
const p2 = Promise.resolve('Success!');
const p3 = fetch('/api/fallback');
Promise.any([p1, p2, p3])
.then(result => {
console.log('First success:', result); // 'Success!'
})
.catch(error => {
console.error('All failed:', error); // AggregateError: All promises were rejected
});- 注意事项
- 需注意 AggregateError 的处理(可通过 instanceof 判断)。
四者对比总结
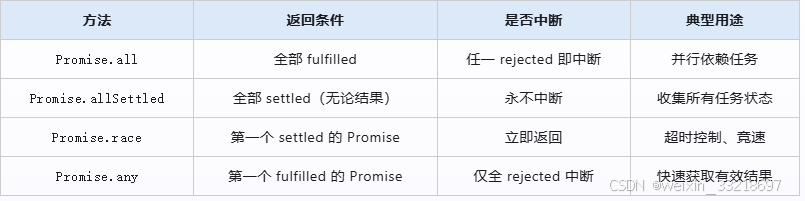
选择建议
- 需要全部成功 → Promise.all
- 需要知道所有任务最终状态 → Promise.allSettled
- 只关心最快完成的任务 → Promise.race
- 只要有一个成功即可 → Promise.any
26. 什么是原型,原型对象和原型链?
原型(Prototype)
- 定义:每个对象都有一个关联的原型对象,作为其"备用仓库"。当对象自身无某属性或方法时,会从原型中借用。
- 核心作用:解决代码复用问题,避免重复创建相同方法;提供动态扩展能力,运行时修改原型可影响所有关联实例。
原型对象
- 定义:每个函数被创建时,都会自动获得一个 prototype 属性,该属性指向一个对象,这个对象就是原型对象。默认情况下,原型对象包含一个 constructor 属性,指向拥有该原型对象的构造函数。
- 核心作用:向由构造函数创建的所有实例共享属性和方法,节省内存并促进代码重用。
原型链(Prototype Chain)
- 定义:每个对象(除 null 外)都有一个内部属性 \[Prototype](可通过 __ proto__ 或 Object.getPrototypeOf() 访问),指向其原型对象。原型对象也有自己的 \[Prototype],如此层层链接,最终终止于 Object.prototype(其 \[Prototype] 为 null)。这种链式结构称为原型链。
- 核心作用:当访问对象的属性或方法时,JavaScript 引擎会先在对象自身查找;若未找到,则沿原型链逐级向上查找,直到找到目标或到达 null。这一机制实现了类似继承的功能。
27 JS中常见继承方式对比
一、原型链继承
- 原理:将子类的原型对象指向父类的一个实例,形成原型链关联。
- 优点:简单直观,方法可共享(父类原型方法自动继承)。
- 缺点:无法向父类构造函数传参;引用类型属性(如数组)会被所有子类实例共享。
- 适用场景:适合无状态的工具类继承,或仅需共享方法的场景。
javascript
function Parent() {
this.name = 'Parent';
this.hobbies = ['reading', 'coding']; // 引用类型属性
}
Parent.prototype.sayHello = function() {
console.log('Hello from Parent');
};
function Child() {}
Child.prototype = new Parent(); // 核心:子类原型指向父类实例
const child1 = new Child();
const child2 = new Child();
child1.hobbies.push('music');
console.log(child2.hobbies); // ['reading', 'coding', 'music'] → 引用类型共享!
child1.sayHello(); // ✅ 继承方法成功缺点暴露:hobbies 数组被所有实例共享,修改一个会影响其他实例。
二、构造函数继承(借用构造函数)
- 原理:在子类构造函数中通过 call/apply 调用父类构造函数,复制父类实例属性到子类实例。
- 优点:解决传参问题;每个子类实例拥有独立的引用类型属性副本。
- 缺点:无法继承父类原型方法;每次创建子类实例都会重新生成父类方法,内存浪费。
- 适用场景:需隔离实例属性的场景,或与原型链继承组合使用。
javascript
function Parent(age) {
this.age = age;
this.hobbies = ['reading'];
}
function Child(age) {
Parent.call(this, age); // 核心:调用父类构造函数绑定 this
}
const child1 = new Child(10);
const child2 = new Child(20);
child1.hobbies.push('music');
console.log(child2.hobbies); // ['reading'] → 独立副本!
// console.log(child1.sayHello()); // ❌ 无法继承 Parent.prototype 的方法缺点暴露:无法继承父类原型上的方法(如 sayHello)。
三、组合继承
- 原理:结合原型链继承和构造函数继承,通过构造函数继承实例属性,原型链继承方法。
- 优点:支持传参;避免引用类型共享;方法复用。
- 缺点:父类构造函数被调用两次,产生冗余属性(原型和实例各一份),性能开销。
- 适用场景:通用继承需求,但需注意性能优化。
javascript
function Parent(age) {
this.age = age;
this.hobbies = ['reading'];
}
Parent.prototype.sayAge = function() {
console.log(`Age: ${this.age}`);
};
function Child(age) {
Parent.call(this, age); // 第一次调用 Parent:初始化实例属性
}
Child.prototype = new Parent(); // 第二次调用 Parent:设置原型
Child.prototype.constructor = Child; // 修复构造函数指向
const child = new Child(15);
child.sayAge(); // ✅ 继承方法成功
console.log(child.hobbies); // ['reading'] → 独立副本缺点暴露:Parent 构造函数被调用两次,导致 age 属性冗余(原型上的 age 会被覆盖)。
四、寄生组合继承
- 原理:在组合继承基础上优化,通过 Object.create() 创建纯净的父类原型副本,避免重复调用父类构造函数。
- 优点:解决组合继承的性能问题;仅调用一次父类构造函数;完美隔离实例属性和方法复用。
- 缺点:实现稍复杂。
- 适用场景:推荐的 ES5 最佳继承方案,适用于大多数复杂项目。
javascript
function Parent(age) {
this.age = age;
this.hobbies = ['reading'];
}
Parent.prototype.sayAge = function() {
console.log(`Age: ${this.age}`);
};
function Child(age) {
Parent.call(this, age); // 仅调用一次 Parent
}
// 关键优化:通过 Object.create 创建纯净的父类原型副本
Child.prototype = Object.create(Parent.prototype);
Child.prototype.constructor = Child; // 修复构造函数指向
const child = new Child(18);
child.sayAge(); // ✅ 方法正常
console.log(child.hobbies); // ['reading'] → 独立副本优势:避免多次调用父类构造函数,内存效率更高。
五、ES6 class extends 继承
- 原理:基于语法糖 class 和 extends 关键字,底层仍为寄生组合继承。
- 优点:语法简洁清晰;自动处理原型链和构造函数;支持静态属性继承。
- 缺点:需编译为ES5时部分旧浏览器不兼容。
- 适用场景:现代开发首选,尤其适合大型项目。
javascript
class Parent {
constructor(age) {
this.age = age;
this.hobbies = ['reading'];
}
sayAge() {
console.log(`Age: ${this.age}`);
}
}
class Child extends Parent {
constructor(age) {
super(age); // 必须优先调用 super()
}
}
const child = new Child(20);
child.sayAge(); // ✅ 正常输出 Age: 20
console.log(child.hobbies); // ['reading'] → 独立副本底层原理:等同于寄生组合继承,但语法更简洁。
总的来说,在实际开发中,优先使用 class extends,兼顾可读性与功能;若需兼容旧环境,选择寄生组合继承。
对比总结表
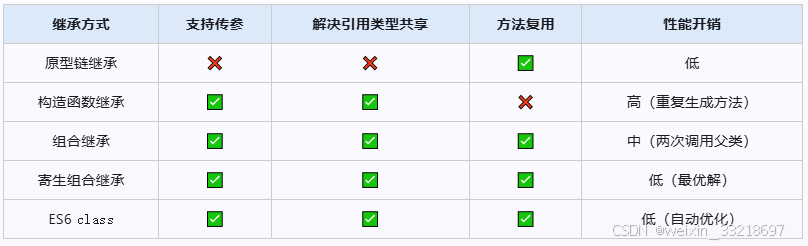
28. JS中的构造函数和new的机制
JavaScript 中的构造函数是用于创建和初始化对象的函数,而 new 关键字则是触发这一过程的操作符。
构造函数
- 定义:构造函数是一种特殊的函数,用于创建和初始化对象。它定义了对象的基本结构和属性,并通过 new 关键字调用以生成实例。
- 特征:
- 首字母通常大写(区别于普通函数)。
- 内部通过 this 绑定实例属性。
- 配合 new 调用时,自动返回一个新对象。
new 的机制
- 核心作用:new 是创造对象的过程,其核心作用是调用构造函数并完成原型链关联。
- 具体步骤:
- 创建一个空对象:这个对象将作为最终返回的对象实例的基础。
- 设置原型链:将新创建对象的 __ proto__ 指向构造函数的 prototype 属性,使得新对象可以访问构造函数原型链上的所有属性和方法。
- 执行构造函数:将构造函数的 this 绑定到新对象上,并执行构造函数的代码。构造函数内部可以通过 this 来设置对象的属性和方法。
- 返回对象实例:如果构造函数没有显式返回一个对象,则 new 操作符会自动返回新创建的对象;如果构造函数显式返回一个对象,则返回该对象;如果返回的是一个非对象值(如数字、字符串等),则忽略返回值,仍然返回新创建的对象。
29. JS中的序列化和反序列化
在 JavaScript 中,序列化(Serialization)和反序列化(Deserialization)是数据转换的核心操作,主要用于将复杂数据结构与可存储/传输的字符串格式之间相互转换
一、基本概念
- 序列化:将对象或数据结构转换为字符串的过程,以便存储到本地(如 localStorage)或通过网络传输。
- 反序列化:将序列化后的字符串还原为原始对象或数据结构的过程。
二、核心方法:JSON
- JavaScript 提供了全局对象 JSON,其方法是最常用且安全的序列化工具:

三、JSON.stringify()
- 语法
javascript
JSON.stringify(value[, replacer[, space]])- replacer(可选):过滤或转换序列化结果。
- 如果是一个函数,它会遍历对象的每个属性,动态决定是否包含该属性。
- 如果是一个数组,只有数组中列出的属性名才会被包含在最终的 JSON 字符串中。
- space(可选):缩进空格数,用于美化输出格式。
- 序列化规则
以下值在序列化时会被忽略或转换:- 不可枚举属性(如 Object.defineProperty 设置的属性)。
- 函数、undefined、Symbol 值:作为属性值会被忽略;作为对象的属性则整个属性被忽略。
- Symbol 键名:直接跳过。
- 循环引用:抛出错误(需手动处理)。
- 特殊对象:
- Date 对象 → 自动转为 ISO 字符串。
- RegExp、Error 对象 → 仅保留可枚举属性(通常无意义)。
- Map/Set → 转为空数组 \[\]。
- 示例
javascript
const obj = {
name: "Alice",
age: 30,
sayHi() { console.log("Hello!"); }, // 函数被忽略
[Symbol('id')]: 123, // Symbol 键被忽略
hobbies: new Set(['reading', 'coding']) // Set 转为 []
};
console.log(JSON.stringify(obj));
// 输出:{"name":"Alice","age":30,"hobbies":[]}- 自定义序列化逻辑
通过 replacer 函数实现:
javascript
const user = {
name: "Bob",
password: "secret",
role: "admin"
};
// 过滤敏感字段
const jsonStr = JSON.stringify(user, (key, value) => {
return key === 'password' ? undefined : value;
});
console.log(jsonStr); // {"name":"Bob","role":"admin"}四、JSON.parse() 的细节
- 语法
javascript
JSON.parse(jsonStr[, reviver])- reviver(可选):接收键和值,允许在解析时动态转换结果。
-
反序列化规则
- 严格模式:必须符合 JSON 格式(如不能有尾随逗号)。
- 日期处理:JSON 字符串中的日期需手动恢复为 Date 对象。
-
示例
javascript
const jsonStr = '{"date":"2025-06-17T12:00:00Z"}';
// 使用 reviver 恢复 Date 对象
const obj = JSON.parse(jsonStr, (key, value) => {
if (key === 'date') return new Date(value);
return value;
});
console.log(obj.date instanceof Date); // true五、常见问题与解决方案
- 循环引用导致报错
javascript
const obj = { name: "Cycle" };
obj.self = obj; // 创建循环引用
try {
JSON.stringify(obj); // ❌ TypeError: Converting circular structure to JSON
} catch (e) {
console.error(e.message);
}
// 解决方案:使用库(如 `flatted`)或自定义替换函数
import { stringify } from 'flatted';
console.log(stringify(obj)); // '[{"name":"Cycle","self":0}]'- 非标准数据的序列化
对于 Map、Set、TypedArray 等特殊结构,需手动处理:
javascript
const data = {
map: new Map([['a', 1], ['b', 2]]),
set: new Set([1, 2, 2, 3])
};
// 自定义序列化器
function customStringify(obj) {
return JSON.stringify(obj, (key, value) => {
if (value instanceof Map || value instanceof Set) {
return Array.from(value);
}
return value;
});
}
console.log(customStringify(data));
// 输出:{"map":[["a",1],["b",2]],"set":[1,2,3]}六、其他序列化方式对比
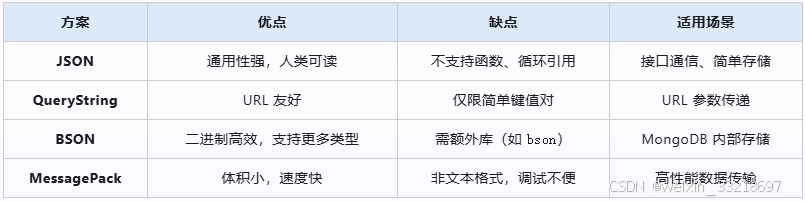
七、JavaScript JSON 工具类
核心目标:
- 解决循环引用:自动检测并处理循环引用,避免原生报错。
- 保留特殊类型:支持 Date、RegExp、Map、Set、TypedArray 等类型的序列化与恢复。
- 灵活过滤属性:支持白名单/黑名单过滤,自定义属性转换逻辑。
- 安全反序列化:严格校验 JSON 格式,防止原型污染和恶意数据。
- 扩展性:支持自定义类型注册,适配业务中的自定义类。
javascript
class JSONUtils {
// 内置类型标识(用于序列化标记,反序列化时识别)
static TYPE_TAGS = {
DATE: '$$DATE$$',
REGEXP: '$$REGEXP$$',
MAP: '$$MAP$$',
SET: '$$SET$$',
TYPED_ARRAY: '$$TYPED_ARRAY$$',
ERROR: '$$ERROR$$',
};
/**
* 安全序列化:支持循环引用、特殊类型、属性过滤
* @param {any} data - 待序列化的数据
* @param {Object} options - 配置项
* @returns {string} - JSON字符串
*/
static stringify(data, options = {}) {
const {
replacer = null, // 自定义替换函数,类似原生 replacer
excludeProps = [], // 排除的属性名数组
includeProps = null, // 仅包含的属性名数组(优先级高于 excludeProps)
space = 2, // 缩进空格数(0 不缩进,>0 美化格式)
ignoreSymbols = true, // 是否忽略 Symbol 类型的属性
customSerializers = [], // 自定义类型序列化器(数组元素为 { type, serializer })
} = options;
// 存储已访问的对象(用于检测循环引用)
const visited = new WeakMap();
// 类型序列化处理器映射(内置 + 自定义)
const serializers = [
this._serializeDate,
this._serializeRegExp,
this._serializeMap,
this._serializeSet,
this._serializeTypedArray,
this._serializeError,
...customSerializers.map(({ type, serializer }) => (target) => {
return type && target instanceof type ? serializer(target) : null;
}),
];
// 属性过滤函数
const propFilter = (key, value) => {
// 1. 排除不可枚举属性、非自身属性(原型链上的)
if (!Object.prototype.hasOwnProperty.call(value, key)) {
return value;
}
// 2. 处理排除/包含属性
if (excludeProps.length > 0 && excludeProps.includes(key)) {
return undefined; // 排除该属性
}
if (includeProps && !includeProps.includes(key)) {
return undefined; // 不包含该属性
}
// 3. 处理 Symbol 属性
if (ignoreSymbols && typeof key === 'symbol') {
return undefined;
}
return value;
};
/**
* 递归处理核心逻辑
*/
const _stringify = (val) => {
// 基础类型直接返回(注意:null 是对象,需特殊处理)
if (val === null || typeof val !== 'object') {
return val;
}
// 检测循环引用:若已处理过,返回占位符
if (visited.has(val)) {
return { [this.TYPE_TAGS.CIRCULAR]: visited.get(val) };
}
// 记录当前对象的标识(用 Symbol 避免属性冲突)
visited.set(val, Symbol('circular'));
// 优先处理特殊类型
for (const serializer of serializers) {
const result = serializer.call(this, val);
if (result) return result;
}
// 处理普通对象/数组
if (Array.isArray(val)) {
return val.map((item, index) => {
// 数组索引作为键名无意义,直接处理值
return _stringify(item);
});
}
// 普通对象(过滤属性后递归处理)
const filteredObj = {};
for (const [key, value] of Object.entries(val)) {
const filteredValue = propFilter(key, value);
if (filteredValue === undefined) continue;
filteredObj[key] = _stringify(filteredValue);
}
return filteredObj;
};
try {
// 先处理替换函数逻辑
let dataToProcess = data;
if (typeof replacer === 'function') {
dataToProcess = replacer.call(data, '', data);
}
const processedData = _stringify(dataToProcess);
// 调用原生 JSON.stringify 处理最终结果(保证格式正确)
return JSON.stringify(processedData, null, space);
} catch (error) {
console.error('JSONUtils.stringify error:', error);
throw new Error(`序列化失败:${error.message}`);
}
}
/**
* 安全反序列化:恢复特殊类型、校验格式、防止原型污染
* @param {string} jsonStr - JSON字符串
* @param {Object} options - 配置项
* @returns {any} - 反序列化后的对象
*/
static parse(jsonStr, options = {}) {
const {
reviver = null, // 自定义恢复函数,类似原生 reviver
customRevivers = [], // 自定义类型恢复器(数组元素为 { type, reviver })
strict = true, // 是否严格模式(禁止原型污染、严格格式校验)
maxDepth = 100, // 最大递归深度(防止恶意数据栈溢出)
maxLength = 1024 * 1024, // 最大字符串长度(防止内存溢出)
} = options;
// 基础校验
if (typeof jsonStr !== 'string') {
throw new Error('反序列化目标必须是字符串');
}
if (jsonStr.length > maxLength) {
throw new Error(`JSON字符串过长,最大允许${maxLength}字节`);
}
try {
// 先解析为普通对象
const parsed = JSON.parse(jsonStr);
// 递归恢复特殊类型
return this._reviveDeep(parsed, strict, maxDepth, customRevivers, reviver);
} catch (error) {
console.error('JSONUtils.parse error:', error);
throw new Error(`反序列化失败:${error.message}`);
}
}
// ==================== 内置类型序列化/恢复方法 ====================
// 处理 Date 类型
static _serializeDate(val) {
if (val instanceof Date && !isNaN(val.getTime())) {
return { [this.TYPE_TAGS.DATE]: val.toISOString() };
}
return null;
}
static _reviveDate(val) {
if (val && val[this.TYPE_TAGS.DATE]) {
return new Date(val[this.TYPE_TAGS.DATE]);
}
return val;
}
// 处理 RegExp 类型
static _serializeRegExp(val) {
if (val instanceof RegExp) {
return { [this.TYPE_TAGS.REGEXP]: val.source, flags: val.flags };
}
return null;
}
static _reviveRegExp(val) {
if (val && val[this.TYPE_TAGS.REGEXP]) {
return new RegExp(val[this.TYPE_TAGS.REGEXP], val.flags || '');
}
return val;
}
// 处理 Map 类型
static _serializeMap(val) {
if (val instanceof Map) {
const entries = Array.from(val.entries());
return { [this.TYPE_TAGS.MAP]: entries };
}
return null;
}
static _reviveMap(val) {
if (val && val[this.TYPE_TAGS.MAP]) {
return new Map(val[this.TYPE_TAGS.MAP]);
}
return val;
}
// 处理 Set 类型
static _serializeSet(val) {
if (val instanceof Set) {
return { [this.TYPE_TAGS.SET]: Array.from(val) };
}
return null;
}
static _reviveSet(val) {
if (val && val[this.TYPE_TAGS.SET]) {
return new Set(val[this.TYPE_TAGS.SET]);
}
return val;
}
// 处理 TypedArray(Int8Array、Uint8Array 等)
static _serializeTypedArray(val) {
if (ArrayBuffer.isView(val) && !(val instanceof DataView)) {
const type = val.constructor.name;
return { [this.TYPE_TAGS.TYPED_ARRAY]: { type, buffer: Array.from(val) } };
}
return null;
}
static _reviveTypedArray(val) {
if (val && val[this.TYPE_TAGS.TYPED_ARRAY]) {
const { type, buffer } = val[this.TYPE_TAGS.TYPED_ARRAY];
const Constructor = globalThis[type];
return Constructor ? new Constructor(buffer) : buffer;
}
return val;
}
// 处理 Error 类型
static _serializeError(val) {
if (val instanceof Error) {
return {
[this.TYPE_TAGS.ERROR]: {
name: val.name,
message: val.message,
stack: val.stack,
},
};
}
return null;
}
static _reviveError(val) {
if (val && val[this.TYPE_TAGS.ERROR]) {
const { name, message, stack } = val[this.TYPE_TAGS.ERROR];
const error = new Error(message);
error.name = name;
error.stack = stack;
return error;
}
return val;
}
// ==================== 核心递归恢复逻辑 ====================
/**
* 深度递归恢复特殊类型
*/
static _reviveDeep(data, strict, depth, customRevivers, reviver) {
// 递归深度限制,防止栈溢出
if (depth <= 0) {
throw new Error('递归深度超过限制,可能存在恶意数据');
}
// 基础类型直接返回
if (data === null || typeof data !== 'object') {
return data;
}
// 1. 处理循环引用占位符(如果有)
if (data[this.TYPE_TAGS.CIRCULAR]) {
return data; // 实际场景中循环引用占位符需要更复杂的处理,这里简化
}
// 2. 恢复内置特殊类型
let result = data;
result = this._reviveDate(result);
result = this._reviveRegExp(result);
result = this._reviveMap(result);
result = this._reviveSet(result);
result = this._reviveTypedArray(result);
result = this._reviveError(result);
// 3. 恢复自定义类型
for (const { type, reviver: customReviver } of customRevivers) {
if (result instanceof type) {
// 若已恢复过,跳过
continue;
}
if (typeof customReviver === 'function') {
const revived = customReviver(result);
if (revived !== result) {
result = revived;
}
}
}
// 4. 处理普通对象/数组,递归恢复嵌套属性
if (Array.isArray(result)) {
result = result.map((item) => this._reviveDeep(item, strict, depth - 1, customRevivers, reviver));
} else if (result && typeof result === 'object') {
// 严格模式下,创建纯净对象,防止原型污染
if (strict) {
result = Object.create(null);
}
// 遍历属性,递归恢复
for (const [key, value] of Object.entries(data)) {
// 跳过非自身属性(严格模式下已创建纯净对象,无需处理)
if (strict && !Object.prototype.hasOwnProperty.call(data, key)) {
continue;
}
// 应用原生 reviver(如果有)
let revivedValue = value;
if (typeof reviver === 'function') {
revivedValue = reviver.call(data, key, value);
}
// 递归恢复嵌套值
result[key] = this._reviveDeep(revivedValue, strict, depth - 1, customRevivers, reviver);
}
}
return result;
}
// ==================== 便捷工具方法 ====================
/**
* 存储到 localStorage(自动处理序列化和异常)
*/
static setStorage(key, data, options) {
try {
const jsonStr = this.stringify(data, options);
localStorage.setItem(key, jsonStr);
return true;
} catch (error) {
console.error(`存储失败 [key:${key}]:`, error);
return false;
}
}
/**
* 从 localStorage 读取(自动处理反序列化和异常)
*/
static getStorage(key, options) {
try {
const jsonStr = localStorage.getItem(key);
if (!jsonStr) return null;
return this.parse(jsonStr, options);
} catch (error) {
console.error(`读取失败 [key:${key}]:`, error);
localStorage.removeItem(key); // 数据损坏,清理
return null;
}
}
/**
* 移除 localStorage 数据
*/
static removeStorage(key) {
localStorage.removeItem(key);
}
}工具类核心特性总结

典型使用示例
- 基础序列化与反序列化(含特殊类型)
javascript
// 构造包含特殊类型的数据
const complexData = {
name: "Alice",
birthday: new Date("1990-01-01"),
regex: /test/gi,
map: new Map([["key1", "value1"], ["key2", 2]]),
set: new Set([1, 2, 2, 3]),
buffer: new Uint8Array([1, 2, 3, 4]),
error: new Error("Test Error"),
};
// 序列化(自动处理特殊类型)
const jsonStr = JSONUtils.stringify(complexData, { space: 2 });
console.log(jsonStr);
// 反序列化(恢复特殊类型)
const restoredData = JSONUtils.parse(jsonStr);
console.log(restoredData.birthday instanceof Date); // true
console.log(restoredData.regex instanceof RegExp); // true
console.log(restoredData.map instanceof Map); // true
console.log(restoredData.set instanceof Set); // true
console.log(restoredData.buffer instanceof Uint8Array); // true
console.log(restoredData.error instanceof Error); // true- 循环引用处理
javascript
const circularObj = { name: "Cycle" };
circularObj.self = circularObj; // 循环引用
// 原生 JSON.stringify 会报错:TypeError: Converting circular structure to JSON
// 使用工具类成功序列化
const jsonStr = JSONUtils.stringify(circularObj);
console.log(jsonStr); // 输出包含循环引用占位符的字符串
// 反序列化(简化处理,实际场景需根据占位符还原引用关系)
const restored = JSONUtils.parse(jsonStr);
console.log(restored);- 属性过滤(排除敏感字段)
javascript
const user = {
name: "Bob",
password: "123456",
age: 25,
role: "admin",
};
// 排除 password 字段
const filteredJson = JSONUtils.stringify(user, { excludeProps: ["password"], space: 2 });
console.log(filteredJson);
// 输出:
// {
// "name": "Bob",
// "age": 25,
// "role": "admin"
// }- 本地存储(便捷方法)
javascript
// 存储复杂数据
const data = { list: [1, 2, 3], config: { theme: "dark" } };
JSONUtils.setStorage("appData", data);
// 读取数据
const restoredData = JSONUtils.getStorage("appData");
console.log(restoredData.config.theme); // "dark"- 自定义类型扩展
javascript
// 定义自定义类
class User {
constructor(name, age) {
this.name = name;
this.age = age;
this.createTime = new Date();
}
sayHi() {
return `Hi, ${this.name}`;
}
}
// 序列化时自定义处理 User 类
const user = new User("Charlie", 30);
const jsonStr = JSONUtils.stringify(user, {
customSerializers: [
{
type: User,
serializer: (instance) => ({
name: instance.name,
age: instance.age,
createTime: instance.createTime.toISOString(),
type: "User", // 用于反序列化识别
}),
},
],
});
// 反序列化时自定义恢复 User 类
const restoredUser = JSONUtils.parse(jsonStr, {
customRevivers: [
{
type: User,
reviver: (data) => {
if (data.type === "User") {
const user = new User(data.name, data.age);
user.createTime = new Date(data.createTime);
return user;
}
return data;
},
},
],
});
console.log(restoredUser instanceof User); // true
console.log(restoredUser.sayHi()); // "Hi, Charlie"注意事项
- 循环引用的局限性:工具类对循环引用的处理是简化版,实际场景中循环引用的完整还原需要记录引用标识并重建引用关系,可根据业务需求扩展占位符的处理逻辑。
- 性能考量:复杂数据序列化时,WeakMap 和递归处理会带来一定性能开销,对性能敏感的场景可关闭非必要的特性(如特殊类型处理)。
- 安全边界:虽然工具类做了安全校验,但反序列化不受信任数据时仍需谨慎,建议对数据来源进行严格校验,避免执行恶意代码。
- 环境兼容性:工具类依赖 WeakMap、ArrayBuffer 等 ES6+ 特性,若需兼容旧浏览器,可引入 polyfill 或简化相关特性。
30. 性能优化
懒加载,预加载,长列表优化
一、懒加载(Lazy Loading)------延迟非关键资源加载
- 适用场景
- 图片/视频密集型页面(电商商品图、社交动态)
- 按需加载非首屏组件(弹窗、折叠内容)
- 实现方案
1️⃣ 原生懒加载(推荐优先使用)
- 优点:零JS开销,浏览器原生优化调度
- 兼容性:Chrome/Firefox/Edge 已全面支持
javascript
<!-- HTML原生支持 -->
<img src="placeholder.jpg" loading="lazy" alt="...">
<iframe src="about:blank" loading="lazy"></iframe>2️⃣ Intersection Observer API(高精度控制)
- 优势:相比scroll事件监听,性能提升3倍以上
- 进阶:可结合threshold参数设置多级触发阈值
javascript
const observer = new IntersectionObserver((entries) => {
entries.forEach(entry => {
if (entry.isIntersecting) {
const img = entry.target;
img.src = img.dataset.src; // 替换真实URL
observer.unobserve(img); // 停止观察已加载元素
}
});
}, { rootMargin: '200px' }); // 提前200px触发加载
// 启动观察
document.querySelectorAll('img[data-src]').forEach(img => {
observer.observe(img);
});3️⃣ 框架集成方案
Vue:
javascript
<script setup>
import { defineAsyncComponent } from 'vue';
const HeavyComponent = defineAsyncComponent({
loader: () => import('./HeavyComponent.vue'),
delay: 200, // 延迟显示loading前等待时间
suspensible: false // 禁用默认suspense行为
});
</script>React:
javascript
const LazyImage = React.lazy(() => import('./components/ImageGallery'));
function App() {
return (
<Suspense fallback={<Spinner />}>
<LazyImage />
</Suspense>
);
}⚠️ 避坑指南
- SEO风险:搜索引擎可能无法执行JS渲染懒加载内容 → 需提供noscript回退标签
- 布局抖动:未设置固定宽高比的图片会导致重排 → 使用padding-top保持比例
- 过度优化:低于100ms的延迟对用户无感知 → 合理设置rootMargin避免无效请求
二、预加载(Preload)------抢占带宽优先级
- 适用场景
- 即将使用的关键资源(下一页路由JS、用户点击概率高的模块)
- 字体文件、CSS背景图等高优先级资源
- 技术类型对比

实战案例
javascript
<!-- 预加载关键CSS -->
<link rel="preload" href="critical.css" as="style" onload="this.rel='stylesheet'">
<!-- 预取下一步操作所需数据 -->
<link rel="prefetch" href="/api/user/orders">⚠️ 注意事项
- Content Security Policy (CSP):需配置connect-src允许预连接域名
- 带宽竞争:避免同时标记过多preload导致主线程阻塞 → 使用fetchpriority属性调整优先级
- 缓存失效:某些CDN配置可能导致预加载资源不命中缓存 → 确保Cache-Control头正确设置
三、长列表优化------突破DOM渲染瓶颈
- 痛点分析
- 传统渲染1万条数据会产生1万个DOM节点,导致:
- 内存占用过高(~500MB+)
- 滚动帧率下降至20FPS以下
- 交互延迟明显增加
- 传统渲染1万条数据会产生1万个DOM节点,导致:
- 解决方案矩阵
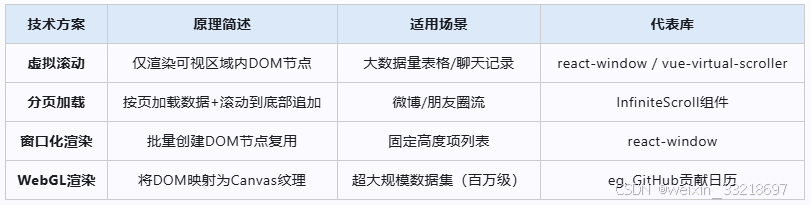
虚拟滚动核心实现逻辑
javascript
// 简化版React示例
function VirtualList({ items, itemHeight, containerHeight }) {
const [visibleStartIdx, setVisibleStartIdx] = useState(0);
const totalHeight = items.length * itemHeight;
// 计算可视区域起始索引
const handleScroll = useCallback((e) => {
const scrollTop = e.target.scrollTop;
setVisibleStartIdx(Math.floor(scrollTop / itemHeight));
}, []);
return (
<div style={{ height: containerHeight }} onScroll={handleScroll}>
{/* 外层容器 */}
<div style={{ height: totalHeight }}>
{/* 内层偏移层 */}
<div style={{ transform: `translateY(${visibleStartIdx * itemHeight}px)` }}>
{items.slice(visibleStartIdx, visibleStartIdx + Math.ceil(containerHeight / itemHeight))
.map((item, i) => <Item key={i} data={item} />)}
</div>
</div>
</div>
);
}⚠️ 特殊场景处理
- 变高项目:采用动态测量+估算平均高度(误差容忍度±20%)
- 锚点定位:通过scrollIntoView()平滑滚动到指定位置
- 键盘导航:维护焦点索引+自动滚动补偿
四、综合调优策略
- 网络层面:
启用HTTP/2 Server Push主动推送关键资源
Service Worker缓存API响应加快二次访问速度 - 渲染层面:
CSS containment隔离渲染区域减少重绘范围
will-change提示浏览器提前优化图层合成 - 监控体系:
Performance Timing API采集FP/FCP指标
RUM (Real User Monitoring) 捕获线上真实性能数据 - 渐进式增强:
根据设备性能降级处理(检测navigator.hardwareConcurrency决定并发数)
弱网环境下切换为极简模式(关闭动画/降低分辨率)
31. JS内存泄露场景与排查
在 JavaScript 开发中,内存泄漏(Memory Leak)是指程序中已不再使用的内存未被及时释放,导致内存占用持续增长,最终可能引发页面卡顿、崩溃或服务器性能下降。
一、核心概念:GC 原理简述
JavaScript 通过垃圾回收器(Garbage Collector, GC)自动管理内存。主流浏览器采用 标记-清除算法(Mark-Sweep):
- 标记阶段:从根对象(全局作用域、调用栈)出发,标记所有可达对象。
- 清除阶段:销毁未被标记的对象,释放其内存。
关键点:只有当对象从根节点不可达时,才会被 GC 回收。若存在"孤岛"对象(无引用链连接根节点),则会发生泄漏。
二、典型内存泄漏场景与代码示例
- 意外的全局变量
修复:严格模式("use strict")+ 避免省略声明关键字。
javascript
function leak() {
// 未声明变量直接赋值 → 成为 window 的属性(隐式全局变量)
temp = "This is a global variable"; // 缺少 var/let/const
}
leak();
// temp 始终被 window 引用,无法被 GC 回收- 闭包引用外部作用域变量
修复:及时解除对不需要数据的引用,例如将 largeData 设为局部变量并在使用后置空。
javascript
function createClosure() {
const largeData = new Array(1000000).fill("*"); // 大数组
return function () {
console.log(largeData.length); // 闭包持有 largeData 的引用
};
}
const closure = createClosure();
// largeData 本应在函数执行后释放,但因闭包引用而滞留内存- DOM 引用未释放
javascript
// 错误示例:仅移除 DOM 节点,但 JavaScript 仍持有引用
const container = document.getElementById("container");
const button = document.createElement("button");
container.appendChild(button);
// 后续操作:删除容器,但按钮仍被 button 变量引用
container.remove(); // DOM 树中已移除,但内存中仍保留按钮对象正确做法:显式解除引用并清理事件监听器:
javascript
button.removeEventListener("click", handler);
button = null; // 切断 JS 对 DOM 的引用- 事件监听器未移除
javascript
class Component {
init() {
window.addEventListener("resize", this.handleResize);
}
handleResize() { /* ... */ }
}
const comp = new Component();
comp.init();
// 组件销毁后,resize 监听器仍被 window 引用,导致 comp 实例无法释放修复:在组件销毁生命周期内移除监听器:
javascript
destroy() {
window.removeEventListener("resize", this.handleResize);
}- 定时器未清除
javascript
setInterval(() => {
fetchData().then(res => updateUI(res));
}, 1000);
// 若路由跳转离开当前页,定时器回调中的 Promise 和上下文会持续驻留内存最佳实践:在页面卸载时清除定时器:
javascript
const timerId = setInterval(fetchData, 1000);
clearInterval(timerId); // 离开页面前调用- Map/Set/WeakMap 的误用
强引用集合(Map/Set):存储对象的键时,会阻止该对象被 GC 回收。
javascript
const cache = new Map();
cache.set(obj, process(obj)); // obj 即使不再使用,也会因 cache 的引用而存活弱引用集合(WeakMap/WeakSet):允许 GC 回收对象的内存,适合做临时缓存。
javascript
const weakCache = new WeakMap();
weakCache.set(obj, processedValue); // 当 obj 无其他引用时,可被安全回收- 循环引用(Circular References)
javascript
function circularLeak() {
const obj1 = {};
const obj2 = {};
obj1.ref = obj2;
obj2.ref = obj1; // 形成闭环
return obj1;
}
const leak = circularLeak();
// 尽管 obj1 和 obj2 互相引用,现代 GC 能检测并回收它们(除非被全局变量捕获)⚠️ 注意:纯循环引用通常不会导致泄漏,但如果其中一个对象被全局变量引用(如 window.globalObj = obj1),则会触发泄漏。
三、内存泄漏排查实战指南
-
Step 1:复现问题 & 监控症状
- 现象:页面运行时间越长,内存占用越高;Tab 页切换后回来变慢。
- 工具:Chrome DevTools → Memory 面板 + Performance monitor。
-
Step 2:使用 Heap Snapshot 定位泄漏源
- 打开 DevTools → Memory → Heap Snapshot。
- 拍摄快照序列:
- 操作前拍一张(Action A)。
- 执行可疑操作(如多次点击按钮加载数据)。
- 操作后再拍一张(Action B)。
- 对比快照:选择 "Summary" 视图,按 "Distance" 排序,查找新增且未被释放的对象。
🔍 关键指标解读:

-
Step 3:Allocation Instrumentation 追踪实时分配
- DevTools → Memory → Allocation instrumentation on timeline。
- 录制一段时间内的内存分配情况:
- 观察哪些类型的对象在持续增长。
- 点击蓝色条形图查看具体的分配位置(Source 列显示代码行号)。
-
Step 4:Performance Monitor 动态监控
- 快捷键:Ctrl+Shift+P → 输入 "Show performance monitor"。
- 关注指标:
- JS Heap Size: JavaScript 堆内存总量。
- Document Count: 文档数量(异常增加可能意味着 iframe 泄漏)。
- Event Listeners: 绑定的事件监听器数量。
-
Step 5:针对性调试技巧
- 怀疑闭包泄漏:在快照中搜索闭包函数名称,检查其 Closure 类型对象的 retainers。
- DOM 泄漏:筛选 "Detached DOM tree",查看脱离文档流但仍被引用的节点。
- 定时器泄漏:在 Allocation instrumentation 中过滤 "setTimeout"/"setInterval"。
四、预防内存泄漏的最佳实践
- 严格模式:强制报错而非静默失败("use strict")。
- 及时清理:
- 移除事件监听器(removeEventListener)。
- 清除定时器(clearInterval/Timeout)。
- 解绑双向数据绑定(Angular 中的 ngOnDestroy)。
- 弱引用优先:使用 WeakMap/WeakSet 替代普通 Map/Set 存储临时关联数据。
- 模块化隔离:利用 IIFE 或 ES Modules 限制变量生命周期。
- 定期审计:集成 Lighthouse CI 或 ergonize 进行自动化内存检测。
五、高级工具推荐
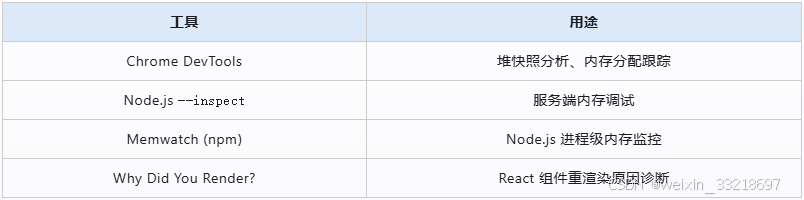
32. 浏览器的同源策略与JS的关系
浏览器的同源策略与 JavaScript(JS)的关系紧密,它是浏览器为 JS 代码执行提供安全保障的关键机制。
核心关系概述
-
同源策略是浏览器对JavaScript施加的安全限制
- 同源策略是浏览器的一项核心安全功能,它限制了来自不同源的JavaScript代码对当前文档或资源的访问。这里的"源"由协议、域名和端口三者共同定义,任意一个不同即视为不同源。
-
同源策略仅针对JavaScript的特定操作进行限制
- DOM操作:无法访问非同源页面的DOM节点。
- 存储访问:不能读取或修改非同源的Cookie、LocalStorage、IndexDB等数据。
- 网络请求:禁止向非同源URL发送AJAX请求(但实际请求可能已发出,响应会被浏览器拦截)。
同源策略对JavaScript开发的影响
-
限制场景
- 前后端分离开发:前端部署在a.com,后端API在api.b.com时,浏览器会阻止直接请求。
- 嵌入第三方内容:使用iframe嵌入其他网站时,无法获取其内部状态。
- 跨域资源共享需求:需调用外部API或CDN资源时面临阻碍。
-
规避技术
- JSONP:利用
特殊场景下的宽松策略
-
document.domain放宽限制
- 主域名相同时可手动设置相同的document.domain实现子域名间共享权限(如a.example.com与b.example.com)。
-
WebSocket协议
- 基于该协议的通信不受同源策略约束,适用于实时双向数据传输场景。
同源示例
满足以下三个条件即为同源:协议相同 + 域名相同 + 端口相同。
-
完全相同的完整URL:http://www.example.com:80 与 http://www.example.com
- 原因:虽然第二个URL省略了端口号,但浏览器默认端口为80,因此三者一致。
-
同一域名下的不同路径:http://example.com/page1 与 http://example.com/page2
- 原因:协议、域名、端口均相同,仅路径不同不影响同源判定。
-
协议+域名+端口完全匹配:https://sub.example.com:443 与 https://sub.example.com
- 原因:HTTPS默认端口为443,两者实际指向同一源。
不同源示例
只要以下任一条件不满足即为不同源:协议不同 / 域名不同 / 端口不同
-
协议不同:
- http://example.com 与 https://example.com → 协议分别为HTTP和HTTPS。
- ws://api.example.com(WebSocket)与 http://api.example.com → 协议类型不同。
-
域名或子域名不同:
- http://example.com 与 http://sub.example.com → 主域名与子域名不同。
- http://example.com 与 http://192.168.1.1 → IP地址与域名无法互通。
-
端口不同:
- http://example.com:80 与 http://example.com:8080 → 端口号不一致。
-
其他组合差异:
- http://example.com 与 ftp://example.com → 协议和端口均不同(FTP默认端口21)
33. 什么是XSS、CSRF? 如何从JS层面避免?
XSS与CSRF介绍
-
XSS
- 定义:允许攻击者将恶意客户端脚本(通常是JavaScript)注入到受信任的网站中,当其他用户访问该页面时,脚本会在用户浏览器执行,绕过同源策略,窃取Cookie、篡改页面内容或模拟用户操作。
-
CSRF:
- 攻击者伪造来自受信任用户的请求,利用用户已登录的状态,诱使用户在不知情的情况下执行非本意操作,比如修改密码、转账、删除数据等,核心是利用浏览器自动携带Cookie的特性,冒充用户身份。
从JS层面防范XSS的方法
XSS的核心是恶意脚本被浏览器执行,防范的关键是不信任任何用户输入,在输出时根据上下文正确转义,避免脚本被解析为可执行代码。
-
严格处理用户输入,拒绝危险操作
- 优先使用安全的DOM操作API:避免使用innerHTML直接插入用户内容,改用textContent,它会自动转义HTML标签,防止脚本注入。
- 必须插入HTML时,使用专业净化库:若业务需要展示富文本内容,禁止手动拼接HTML,需使用成熟的净化库(如DOMPurify)处理用户输入,移除其中的恶意脚本标签和事件处理器,仅保留安全的HTML标签和属性。
- 避免使用高危函数:禁止使用eval()、new Function()、setTimeout(string)、setInterval(string)等动态执行字符串的函数,这些函数会直接将输入当作代码执行,是XSS的核心突破口。若需解析JSON,用JSON.parse()替代eval()。
-
按输出上下文精准转义
- HTML内容场景:将用户输入插入到HTML标签内容时,转义特殊字符,将
<转成<,>转成>,&转成&,"转成",'转成'。 - JavaScript字符串场景:将用户输入嵌入JavaScript字符串时,需对引号、反斜杠等特殊字符进行转义,防止闭合字符串并注入恶意代码。
- URL参数场景:将用户输入作为URL参数时,使用encodeURIComponent()编码,避免参数被篡改或注入恶意字符。
- HTML内容场景:将用户输入插入到HTML标签内容时,转义特殊字符,将
-
借助框架安全机制,减少手动操作
- 主流框架默认防御:React、Vue等现代前端框架默认对模板插值进行自动转义,能有效防范常见的XSS。
- 谨慎使用危险API:若必须使用dangerouslySetInnerHTML或v-html插入动态内容,需先通过DOMPurify等工具净化内容,确保无恶意脚本。
-
配合浏览器安全机制,强化防护
- 启用CSP:通过HTTP响应头Content-Security-Policy限制资源加载源,禁止内联脚本执行、禁止加载未授权的外部脚本,从浏览器层面阻断XSS攻击的执行环境。
- 避免敏感数据暴露:不要将Cookie、Token等敏感信息存储在localStorage中,优先使用HttpOnly标志的Cookie,防止通过document.cookie窃取凭证。
从JS层面防范CSRF的方法
CSRF的核心是利用用户已登录状态伪造请求,防范的关键是让请求具备不可伪造性,同时阻断跨站请求的自动执行。
-
核心:配合后端实现CSRF Token验证
- 获取并存储Token:登录成功后,从后端接口或响应头获取CSRF Token,存储在sessionStorage中,而非localStorage,避免跨页面持久化导致的安全风险。
- 自动携带Token:所有敏感请求(POST、PUT、DELETE等修改数据的操作)需在请求头或请求体中携带Token,推荐使用Axios拦截器统一处理,避免手动添加的遗漏。
- 后端校验逻辑:后端收到请求后,验证Token的有效性,验证通过后立即使Token失效,防止重放攻击。
-
利用浏览器安全策略,阻断跨站请求
- 设置SameSite Cookie属性:将身份认证Cookie的SameSite属性设为Lax,这是现代浏览器的默认值,可阻止大部分跨站POST请求携带Cookie;对于敏感操作,设为Strict,禁止所有跨站请求携带Cookie,从源头阻断CSRF攻击的基础。
-
规范请求设计,减少攻击面
- 禁止GET请求修改数据:删除、转账、修改密码等敏感操作,必须使用POST、PUT等非GET方法,防止攻击者通过图片标签、重定向链接等自动触发GET请求。
- 关键操作二次确认:对于删除账户、转账等核心操作,前端需增加二次弹窗确认,后端同时再次校验CSRF Token和用户身份,双重保障操作的合法性。
-
前端请求拦截与校验
- 统一请求拦截器:在JS中通过Axios、Fetch拦截器,对所有修改数据的请求自动添加CSRF Token,避免手动添加的疏漏,同时对缺少Token的请求主动拦截,防止漏网之鱼。
- 校验请求来源:在JS发送请求时,通过Origin或Referer头辅助校验请求来源,确保请求来自合法的同源页面,配合后端的严格校验,进一步降低风险。
34. CSP 内容安全策略介绍, 如何防止注入类攻击?
CSP(内容安全策略)是抵御注入类攻击的核心技术之一,其通过白名单机制严格管控网页资源加载与执行,从根源阻断恶意代码注入路径。以下从CSP核心原理出发,结合注入类攻击(尤其是XSS、数据注入)的防御逻辑,系统介绍CSP及对应的防护策略:
一、CSP(内容安全策略)核心介绍
-
定义
- CSP是一种网页安全机制,通过定义资源加载与执行的白名单规则,限制浏览器仅加载、执行来自可信来源的内容,从而构建额外的安全防护层,抵御跨站脚本攻击(XSS)、数据注入等前端安全威胁。
-
核心机制
- CSP采用白名单管控模式,通过一系列指令明确指定不同类型资源(脚本、样式、图片、网络连接等)的可信来源,对未在白名单内的资源直接拦截,从源头杜绝未授权资源的加载与执行。
-
配置方式
- HTTP响应头(推荐):通过服务器返回Content-Security-Policy响应头配置策略,优先级最高,能在HTML解析前生效,完全覆盖meta标签配置,是生产环境的首选方式。
- HTML meta标签:在HTML中使用定义,适用于静态页面或开发测试场景,配置灵活但优先级低于HTTP头。
-
核心指令
- default-src:作为未明确指定资源的默认加载策略,是全局基础规则。
- script-src:管控JavaScript脚本的来源,是防御XSS的核心指令,可限制脚本仅从可信源加载。
- style-src:管控CSS样式的来源,避免恶意样式注入篡改页面布局。
- connect-src:管控AJAX、WebSocket等网络连接的目标来源,防止数据被恶意窃取。
- img-src:管控图片资源的加载来源,避免加载恶意图片触发攻击。
- frame-src:管控< iframe>的加载来源,防止嵌入恶意页面。
-
特殊关键字
- 'self':仅允许从当前页面的源(协议+域名+端口)加载资源,是白名单的核心基础。
- 'none':禁止加载任何匹配类型的资源,是限制最严格的策略。
- 'unsafe-inline':允许执行内联脚本和样式,存在安全风险,仅在业务强制需要时使用,优先用nonce或hash替代。
- 'unsafe-eval':允许使用eval()等动态代码执行函数,同样存在安全风险,不推荐启用。
-
关键机制
- 报告模式:通过Content-Security-Policy-Report-Only头开启仅报告模式,仅收集违规数据而不阻断资源,便于开发者排查策略冲突,优化后切换至强制模式。
- 违规报告:启用report-to指令指定违规报告接收地址,浏览器会以JSON格式上报违规信息,包括违规资源、触发指令、文档地址等,帮助精准定位问题。
二、CSP防止注入类攻击的核心策略
注入类攻击的核心是向页面注入恶意代码并让浏览器执行,CSP通过资源管控、输入输出限制等策略,从根源切断攻击链条,具体如下:
-
阻断XSS攻击的核心路径
- 禁用内联脚本与事件处理器:默认情况下,CSP禁止执行内联脚本和HTML事件处理器,避免攻击者通过注入或οnclick="maliciousCode()"等代码触发攻击。
- 禁用动态代码执行函数:CSP默认禁用eval()、new Function()等动态代码执行函数,防止攻击者将恶意字符串转化为可执行代码,从根源消除动态执行带来的安全隐患。
- 管控脚本来源白名单:通过script-src指令仅允许加载可信源的脚本,拦截来自恶意域名的脚本请求,即使攻击者成功注入恶意脚本,也会因来源不在白名单被浏览器阻止执行。
- 安全管控内联资源:若业务必须使用内联脚本或样式,可通过nonce(一次性随机值)或hash(脚本内容的哈希值)机制实现安全管控。只有携带匹配nonce属性或哈希值匹配的内联资源才会被执行,既满足业务需求,又避免恶意注入。
-
拦截数据注入与资源劫持
- 限制网络连接来源:通过connect-src指令限制AJAX、WebSocket等网络连接的目标地址,仅允许向可信API地址发起请求,防止攻击者注入恶意代码窃取用户数据或发送非法请求。
- 管控页面嵌入资源:通过frame-src、child-src指令限制iframe、嵌入页面的来源,禁止加载恶意第三方页面,避免攻击者通过注入恶意页面篡改页面内容或窃取用户信息。
- 强化数据传输安全:结合https:协议限制,强制所有资源通过HTTPS加载,配合Strict-Transport-Security头确保连接仅使用加密通道,防止数据在传输过程中被注入或篡改,抵御中间人攻击引发的数据注入风险。
-
配合其他安全措施构建多层防御
- 输入验证与过滤:对用户输入进行严格的格式、长度、类型校验,拒绝不符合预期的输入,从源头减少注入素材。
- 输出转义:在页面输出用户数据时,对特殊字符进行转义,防止用户输入被解析为可执行代码,与CSP形成双重防护。
- 最小权限原则:数据库、服务器等后端服务遵循最小权限原则,仅授予必要权限,即使注入攻击突破前端,也能限制攻击者造成的破坏范围。
- Web应用防火墙(WAF):部署WAF监控和拦截恶意请求,识别并阻断SQL注入、XSS等攻击流量,与CSP的前端防御形成互补,实现全链路防护。
-
渐进式部署与持续监控
- 报告模式试运行:先通过Content-Security-Policy-Report-Only头开启报告模式,收集违规数据,分析被拦截的资源是否为合法业务需求,避免直接上线严格策略导致业务中断。
- 持续优化策略:根据违规报告调整白名单,逐步收紧策略,例如从宽松的default-src *过渡到严格的default-src 'self',同时结合业务迭代持续更新策略,适配新的资源加载需求。
- 监控违规报告:搭建违规报告接收和分析系统,实时监控异常请求,及时发现新型攻击手段,快速调整CSP策略,确保防护能力持续有效。
综上,CSP通过白名单管控、核心指令配置、特殊机制配合,构建起抵御注入类攻击的核心防线,同时需结合输入验证、输出转义、最小权限等多层防御措施,形成完整的安全防护体系。在实际应用中,采用渐进式部署和持续监控策略,既能保障业务稳定运行,又能最大化发挥CSP的安全防护价值,有效降低XSS、数据注入等注入类攻击的风险。
35. 事件委托的本质和优势场景
一、事件委托的本质
- 核心原理:
利用 DOM 事件的 冒泡机制(Event Bubbling),将事件监听器绑定到父元素而非直接目标元素。当子元素触发事件时,事件会逐级向上传播至父元素,由父元素统一处理所有子元素的同类事件。
javascript
// 对比示例
// ❌ 传统方式:逐个绑定事件
document.querySelectorAll('.list-item').forEach(item => {
item.addEventListener('click', handleClick);
});
// ✅ 事件委派:统一绑定到父元素
document.getElementById('list-container').addEventListener('click', (e) => {
if (e.target.matches('.list-item')) {
handleClick(e); // 根据 target 判断具体操作对象
}
});二、优势场景分析
- 动态内容无需重复绑定
适用场景:频繁增删的列表/卡片(如聊天记录、商品列表)
优势:新增元素自动继承事件,无需手动重新绑定
javascript
// 动态添加的新条目自动生效
const container = document.getElementById('chat-box');
container.addEventListener('click', (e) => {
if (e.target.classList.contains('message-item')) {
console.log('查看消息详情:', e.target.dataset.id);
}
});- 大规模同类元素优化
适用场景:千级以上的数据表格、网格布局
性能收益:从 O(n) 次绑定降为 O(1) 次,内存占用大幅降低
javascript
<!-- 万级数据的表格 -->
<table id="data-table">
<tr data-id="1"><td>...</td></tr>
<tr data-id="2"><td>...</td></tr>
...
</table>
<script>
document.getElementById('data-table').addEventListener('click', (e) => {
const row = e.target.closest('tr');
if (row) console.log('选中行ID:', row.dataset.id);
});
</script>- 层级结构复杂的组件
适用场景:嵌套菜单、树形控件、标签页切换
优势:避免多层事件穿透导致的意外行为
javascript
// 防止多层点击冲突
document.getElementById('nested-menu').addEventListener('click', (e) => {
const menuItem = e.target.closest('.menu-item');
const subMenu = e.target.closest('.sub-menu');
if (menuItem && !subMenu) {
console.log('打开主菜单:', menuItem.textContent);
} else if (subMenu) {
console.log('展开子菜单:', subMenu.dataset.path);
}
});- 跨组件通信简化
适用场景:全局弹窗控制、主题切换通知
实现方式:结合自定义事件实现解耦通信
javascript
// 全局事件总线
const EventBus = new Map();
document.body.addEventListener('global-event', (e) => {
EventBus.get(e.detail.type)?.forEach(cb => cb(e.detail.payload));
});
// 任意位置触发
function dispatchGlobalEvent(type, payload) {
document.body.dispatchEvent(new CustomEvent('global-event', { detail: { type, payload } }));
}三、最佳实践指南

关键公式:事件委派有效性 = 明确的选择器匹配 + 合理的事件作用域 + 精准的目标识别
四、典型反模式案例
javascript
// 🔴 错误示范:滥用事件委派导致性能恶化
document.body.addEventListener('click', () => {
// 全页面扫描匹配元素(低效且易误判)
const targets = document.querySelectorAll('[data-action]');
targets.forEach(el => el.click());
});
// ?? 改进方案:限定作用范围+精准匹配
document.querySelector('[data-actions-container]')?.addEventListener('click', (e) => {
const actionEl = e.target.closest('[data-action]');
if (!actionEl) return;
switch(actionEl.dataset.action) {
case 'delete': deleteItem(actionEl.dataset.id); break;
case 'edit': openEditor(actionEl.dataset.id); break;
}
});通过合理运用事件委派,可使代码具备更强的适应性和更低的维护成本,尤其在现代前端框架的虚拟DOM环境下,更能体现其价值。
36 script标签位置的性能影响 为什么建议写在body末尾
一、< script> 标签位置的性能影响机制
- 阻塞 DOM 构建
关键路径阻塞:浏览器遇到 < script> 会立即停止 HTML 解析,优先下载并执行脚本,导致后续 DOM 元素无法及时渲染。
html
<!-- ❌ head 中的同步脚本 -->
<head>
<script src="critical.js"></script> <!-- 阻塞后续资源加载 -->
</head>
<body>
<h1>Hello World</h1>
</body>- 阻塞 CSSOM 构建
CSS 资源竞争:JS 脚本默认等待 CSS 文件加载完成(除非标记 async),形成「CSS 阻塞 → JS 等待 → 渲染延迟」的连锁反应。
javascript
<head>
<link rel="stylesheet" href="styles.css">
<script src="analytics.js"></script> <!-- 必须等 CSSOM 完成才能执行 -->
</head>二、为何推荐放在 < /body> 前?
- 核心优势对比

- 典型场景分析
首屏加速:让用户先看到页面骨架,再处理统计/广告等次要逻辑。
容错性增强:即使脚本加载失败,核心功能仍可用。
javascript
<!-- ✅ 最优实践:主体内容优先加载 -->
<body>
<!-- 所有可见内容 -->
<article>...</article>
<!-- 非关键脚本放底部 -->
<script src="analytics.js"></script>
<script src="ads.js"></script>
</body>三、进阶优化策略
- 动态加载非关键脚本
原理:利用 load 事件触发后 CPU 空闲期加载次要资源。
javascript
// 🕐 空闲时段加载埋点脚本
window.addEventListener('load', () => {
const script = document.createElement('script');
script.src = 'third-party-tracker.js';
document.body.appendChild(script);
});- 预连接关键域名
价值:减少后续脚本请求的 DNS 查询 + TCP 握手耗时。
javascript
<head>
<!-- 提前建立与 CDN 的连接 -->
<link rel="preconnect" href="https://cdn.example.com">
</head>- 差异化加载策略
适用场景:SPA 应用需平衡启动速度与功能完整性。
javascript
<!-- ⚡️ 关键脚本内联 + 非关键异步加载 -->
<head>
<script>
// ✨ 内联关键初始化代码 (≤1KB)
window.__INITIAL_STATE__ = {};
</script>
</head>
<body>
...
<script async src="main.bundle.js"></script>
</body>四、特殊场景注意事项

五、性能对比实验数据
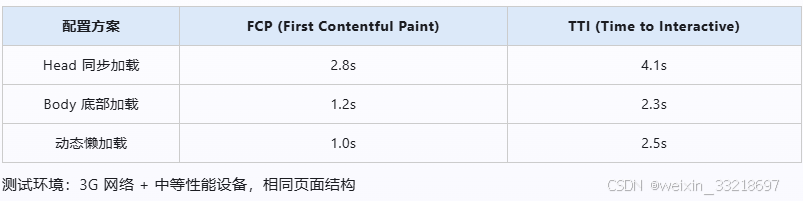
37. eval with等为何不推荐使用?
eval 和 with 不推荐使用的原因在于它们会破坏 JavaScript 的词法作用域规则,导致性能下降、安全隐患及代码维护困难。以下是具体分析:
一、eval 的问题
- 核心原理
- eval 是 JavaScript 的全局函数,参数为字符串形式的 JavaScript 代码,执行时会将字符串当作完整的 JS 脚本,在当前作用域链中动态解析、编译并执行。
简单说:eval 让你在程序运行时,「动态生成并执行新的 JS 代码」,且这段代码能访问当前作用域的变量,甚至修改作用域状态。
- eval 是 JavaScript 的全局函数,参数为字符串形式的 JavaScript 代码,执行时会将字符串当作完整的 JS 脚本,在当前作用域链中动态解析、编译并执行。
javascript
(1)动态计算表达式
直接执行字符串中的表达式,返回计算结果。
特点:表达式在当前作用域中运行,能访问 x、y 等外部变量。
const x = 10, y = 20;
// 动态拼接表达式并执行
const result = eval("x + y * 2"); // 结果:10 + 20*2 = 50
console.log(result);
(2)动态声明变量/函数
在当前作用域中动态声明变量或函数(注意:会影响当前作用域的作用域链)。
关键细节:非严格模式下,eval 中的变量声明会「提升」到外层作用域;
严格模式下,eval 会创建一个独立的临时作用域,变量仅在该临时作用域内有效,
不会泄露到外部(但临时作用域的父作用域是外层作用域,所以仍能访问外层变量,
但不会修改外层作用域的声明)。
// 非严格模式下
function testScope() {
eval("var dynamicVar = '动态变量'; function dynamicFn() { return '动态函数'; }");
console.log(dynamicVar); // 输出:动态变量(变量提升到当前函数作用域)
console.log(dynamicFn()); // 输出:动态函数(函数提升到当前函数作用域)
}
testScope();
// 严格模式下
function testScopeStrict() {
"use strict";
eval("var strictVar = '严格变量';");
console.log(strictVar); // 输出:严格变量(严格模式下 eval 的变量不泄露到外部,但仍影响当前作用域?不,严格模式下 eval 有独立作用域)
}
testScopeStrict();
(3)动态加载代码/配置
早期曾用于动态解析后端返回的配置字符串或代码片段(例如后端返回 JSON 格式的配置,早期用 eval 解析,后被 JSON.parse 取代)。
// 早期错误做法:后端返回的 JSON 字符串用 eval 解析
const jsonString = '{ "name": "test", "age": 18 }';
const config = eval("(" + jsonString + ")"); // 注意:需要加括号避免解析为代码块
console.log(config.name); // 输出:test
// 现代正确做法:用 JSON.parse(安全、高效)
const configSafe = JSON.parse(jsonString);
console.log(configSafe.name); // 输出:test- 性能缺陷
- 阻碍引擎优化:JavaScript 引擎在编译阶段会对静态代码进行优化(如变量提升、作用域链预解析)。但 eval 的参数是动态字符串,引擎无法提前确定其逻辑,只能放弃优化,导致执行效率降低。
- 运行时解析开销:每次调用 eval 都要重新解析字符串为代码,增加额外的计算负担,尤其在频繁调用时显著拖慢程序运行速度。
- 安全风险
- 代码注入漏洞:若 eval 的参数来自用户输入或不可信数据,攻击者可通过篡改字符串执行恶意代码。
- 难以审计与调试:动态生成的代码难以通过静态分析工具检测,增加了代码审查和调试的难度。
- 破坏作用域链
- 变量泄露:在非严格模式下,eval 中的变量声明会提升至当前作用域,可能导致意外覆盖外部变量。
- 严格模式限制:严格模式下 eval 需独立作用域,但仍可能通过引用上层变量引发混乱。
- 可读性与维护性差
- 逻辑模糊:动态生成的代码使程序流程难以追踪,增加团队协作和后期维护成本。
二、with 的问题
- 核心原理
- with 是 JavaScript 的语句,用于临时扩展作用域链:将指定对象的属性作为当前作用域的变量直接访问,无需每次重复写对象名。
简单说:with (obj) { ... } 相当于「临时把 obj 的所有属性添加到当前作用域」,在块内可直接用 属性名 代替 obj.属性名。
- with 是 JavaScript 的语句,用于临时扩展作用域链:将指定对象的属性作为当前作用域的变量直接访问,无需每次重复写对象名。
- 使用示例
javascript
(1)简化对象属性访问
特点:在 with 块内,所有未声明的变量会优先在 user 对象中查找,相当于临时把 user 加入作用域链的第二层。
const user = {
name: "张三",
age: 25,
gender: "男",
address: {
city: "北京",
district: "朝阳区"
}
};
// 用 with 简化重复的 user. 前缀
with (user) {
console.log(name); // 直接访问:张三
console.log(age); // 直接访问:25
console.log(address.city); // 仍可访问嵌套属性:北京
// 修改属性
age = 26; // 等价于 user.age = 26
}
console.log(user.age); // 输出:26(修改生效)
(2)操作配置对象
处理配置参数时,减少对象名重复。
const config = {
baseUrl: "https://api.example.com",
timeout: 5000,
headers: { Authorization: "Bearer token" }
};
// 用 with 简化配置访问
function initRequest() {
with (config) {
console.log(baseUrl); // 输出:https://api.example.com
console.log(timeout); // 输出:5000
console.log(headers.Authorization); // 输出:Bearer token
}
}
initRequest();- 作用域污染
- 变量遮蔽:with 会将对象的属性提升至当前作用域,可能意外覆盖外部同名变量。
- 全局泄露风险:在嵌套作用域中使用 with 可能导致内部变量泄露到全局作用域,引发难以排查的错误。
- 性能损耗
- 作用域链动态变化:with 创建的临时作用域迫使引擎在运行时动态调整作用域链,增加查找变量的时间复杂度。
- 优化失效:引擎无法静态分析 with 内代码的作用域边界,导致相关优化策略失效。
- 兼容性与语法冲突
- 严格模式禁用:ECMAScript 严格模式明确禁止使用 with,违反会直接抛出语法错误。
- 代码歧义:with 块内的代码难以判断变量来源,降低代码可读性。
三、替代方案
- 替代 eval
- 动态属性访问:用对象属性访问代替 eval 拼接变量名,还可以利用映射表存储动态值。
- 其他方式:避免使用具有类似功能的setTimeout/setInterval 的字符串参数、new Function 构造函数等。
- 替代 with
- 显式对象引用:直接通过对象调用方法或访问属性,避免隐式作用域切换。
- 解构赋值:按需提取对象属性,减少重复代码。
总的来说,eval 和 with 的设计初衷虽为提供灵活性,但其副作用远超实用价值。现代开发应遵循以下原则:优先选择静态语法、避免动态作用域操作、启用严格模式约束代码质量。

四、eval 的危险示例
- 代码注入漏洞
javascript
// ❌ 用户输入直接传入 eval
const userInput = "alert('Hacked!')";
eval(userInput); // 弹出恶意弹窗
// ✅ 替代方案:使用对象映射代替动态执行
const actions = {
alert: (msg) => console.log(msg),
log: (msg) => console.info(msg)
};
actions[userInput.action]?.(userInput.param); // 安全调用- 作用域污染
javascript
// ❌ 非严格模式下污染全局作用域
function test() {
eval("var secret = 'exposed';");
}
test();
console.log(secret); // 输出 'exposed'(变量泄露到全局!)
// ✅ 替代方案:使用 IIFE 隔离作用域
function safeTest() {
(() => {
const secret = 'safe'; // 仅在内部可见
})();
}- 性能损耗对比
javascript
// ❌ 频繁解析字符串
for (let i = 0; i < 1000; i++) {
eval(`console.log(${i})`); // 每次循环重新解析
}
// ✅ 直接操作变量
for (let i = 0; i < 1000; i++) {
console.log(i); // 静态优化,执行更快
}五、with 的灾难性示例
- 变量遮蔽导致逻辑错误
javascript
const config = { port: 8080, host: 'localhost' };
const env = {};
// ❌ with 导致变量来源混淆
with (config) {
env.port = port; // 看似访问 config.port,实则创建新变量?
env.host = host; // 正确赋值,但可读性极差
const debug = true; // 本意是局部变量,却成为全局变量(非严格模式下)
}
console.log(debug); // 输出 undefined(严格模式下报错)
// ✅ 显式访问更安全
env.port = config.port;
env.host = config.host;- 严格模式禁止 with
javascript
'use strict';
const obj = { x: 1 };
with (obj) {
console.log(x);
}
// 🚨 SyntaxError: Strict mode code may not include a with statement- 作用域链混乱
javascript
const user = { name: 'Alice', age: 25 };
const db = { connect: () => 'DB connected' };
// ❌ 嵌套 with 引发歧义
with (user) {
with (db) {
console.log(name); // 到底来自 user 还是 db?实际来自外层 with
connect(); // 正确调用 db.connect()
}
}
// ✅ 显式调用避免歧义
console.log(user.name);
db.connect();38. JS单线程模型的本质与浏览器协作机制
JavaScript 的单线程模型并非孤立存在,其性能优化高度依赖与浏览器的深度协作机制。
JS单线程模型的本质
- 设计根源:
- JavaScript最初被设计为操作浏览器DOM(文档对象模型)。若允许多线程同时操作DOM,可能引发竞态条件(如一个线程修改节点时另一线程删除其父节点),导致不可预测的错误。因此,JavaScript采用单线程模型,确保任务按顺序执行,避免同步冲突。
- 核心特征:
- 主线程唯一:所有同步代码(如DOM操作、用户事件处理)均在同一个主线程上排队执行,前一个任务完成才能执行下一个。
- 阻塞风险:若主线程执行耗时任务(如复杂计算),页面会卡顿,因为后续任务需等待。
浏览器协作机制
- 事件循环(Event Loop)
- 调用栈(Call Stack):用于执行同步代码,函数调用时入栈,执行完毕出栈。
- Web APIs:由浏览器提供的能力,负责处理异步任务,完成后将回调函数放入任务队列。
- 任务队列(Task Queue):分为宏任务队列和微任务队列。宏任务队列包含setTimeout、setInterval、I/O操作等;微任务队列包含Promise.then()、MutationObserver等。微任务优先级高于宏任务,每次同步代码执行完毕后,会清空所有微任务,再执行一个宏任务。
- Web Workers多线程补充
- 独立线程:可创建Worker线程处理耗时任务(如大数据计算),避免阻塞主线程。
- 通信机制:通过postMessage()和onmessage传递消息,数据以拷贝形式传输,无共享内存。
- 严格限制:无法访问DOM、window等浏览器全局对象,保证主线程安全。