一、入门篇
1.1 环境安装
工具推荐
在正式使用 Claude Code 之前,我先为大家推荐几款实用的辅助工具,它们能显著提升使用体验。
- 模型&配置切换工具 CC Switch:github.com/farion1231/...
- 实时展示上下文用量 claude-hud:github.com/jarrodwatts...
- Claude Code IDEA 插件:code.claude.com/docs/zh-CN/...
其中,Claude Code IDEA 插件是由 Anthropic 官方提供的一款 Jetbrains 插件,可提供选择上下文共享、交互式差异查看等功能。
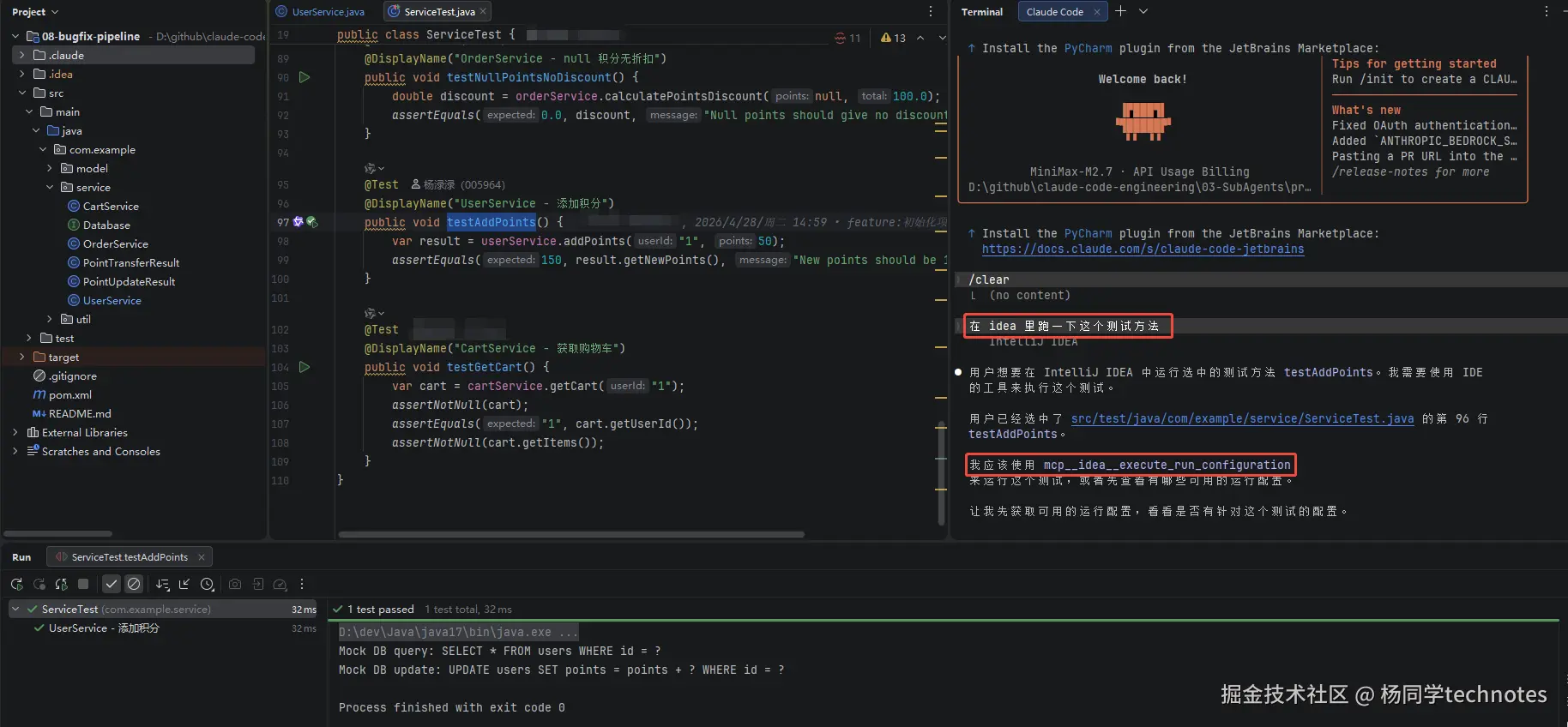
比如在 IDEA 里选中一段代码,然后对 Claude 说:修复这段代码的问题,效果如下图所示:
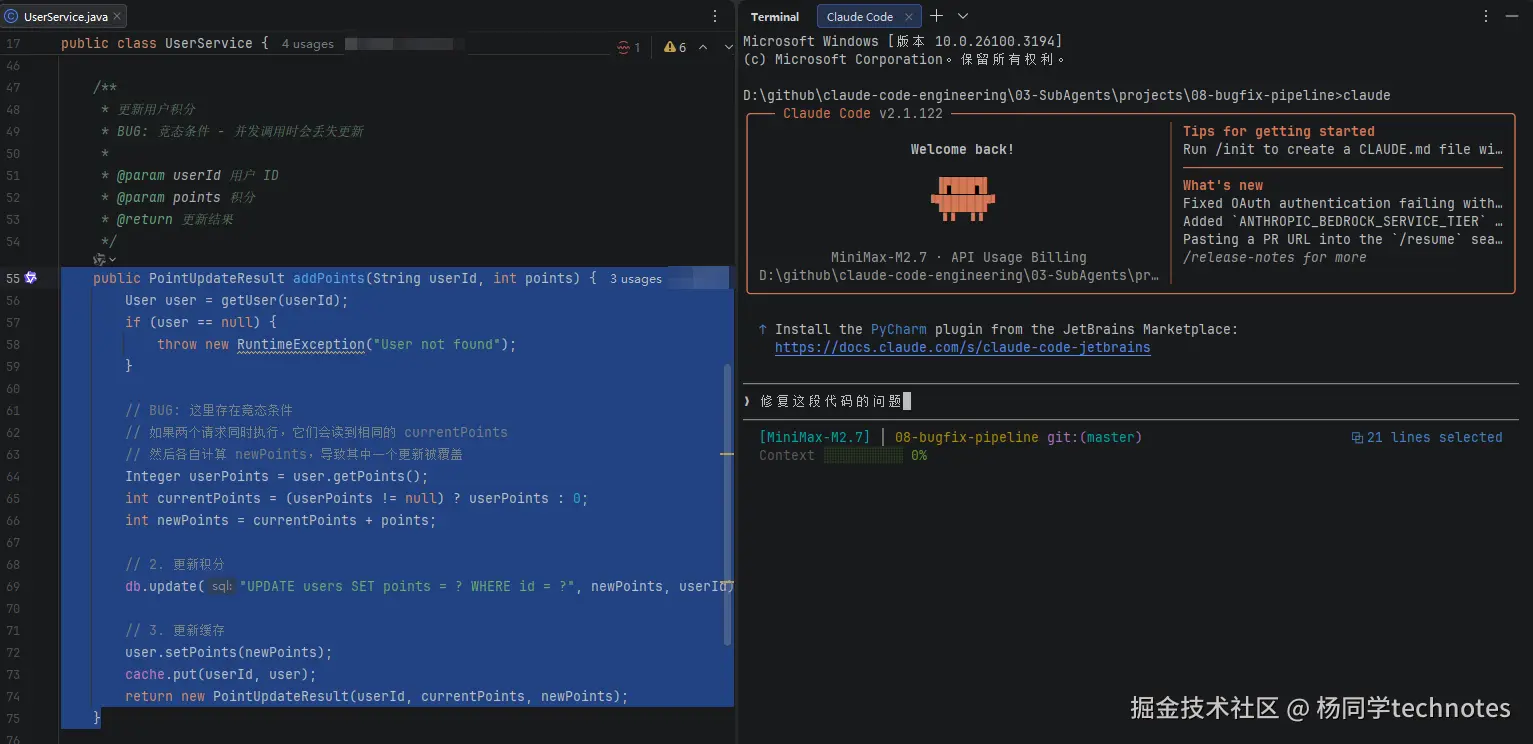
当 Claude 修改完内容后,会以交互式方式呈现出改动差异:
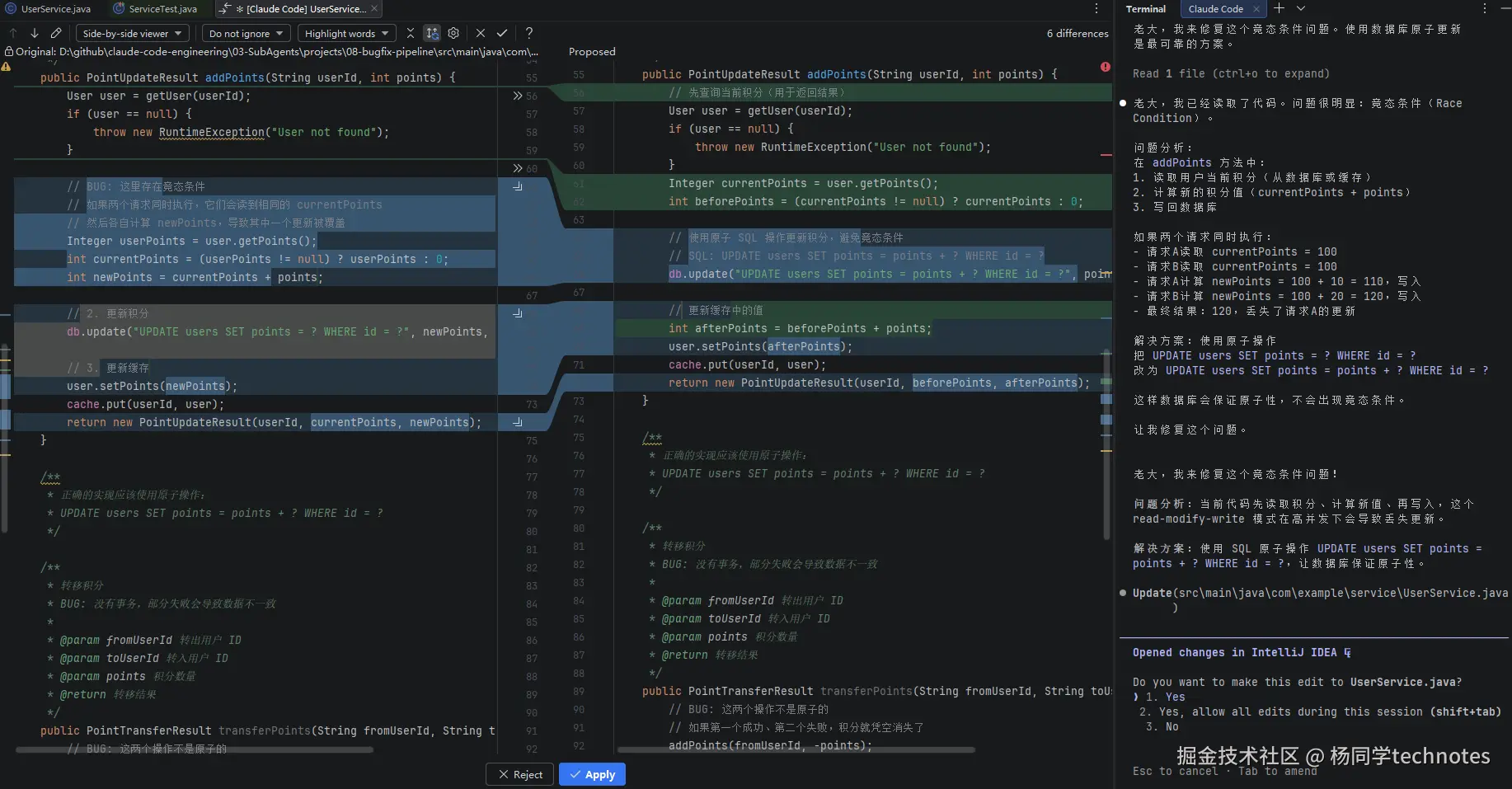
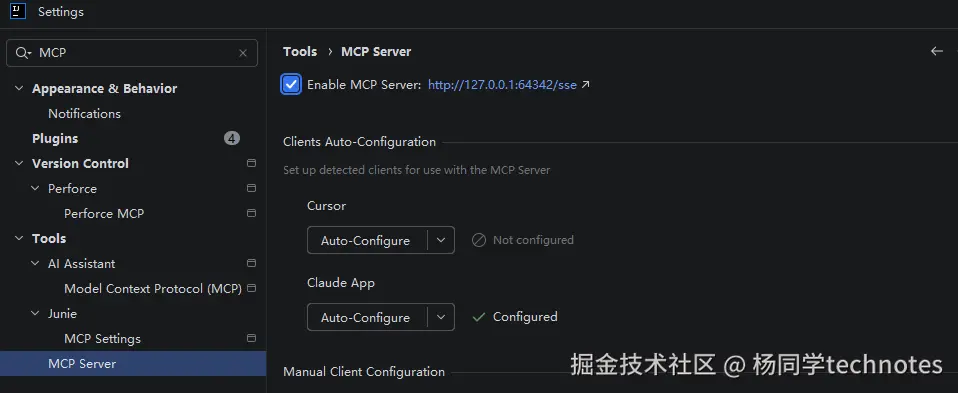
配置 IDEA MCP
第一步:开启 MCP 服务。打开 Settings → 搜索MCP Server。
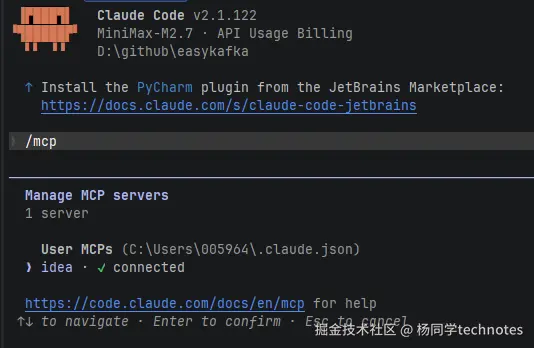
第二步:配置 Claude Code。执行命令:
csharp
claude mcp add --transport sse idea http://127.0.0.1:64342/sse第三步:验证连接。在 Claude Code 里输入 /mcp。
配置好 IDEA Mcp 后,就可以对 Claude 说:在 idea 里跑一下这个测试方法。
1.2 快速入门
场景:首次使用 Claude Code 开发项目需求。
为项目创建记忆
第一步:启动会话
进入项目目录并启动 Claude Code:
bash
cd /path/to/your/project
claude第二步:创建 CLAUDE.md
通过初始化命令创建项目记忆文件:
bash
/init第三步:查看记忆
使用 /memory 命令查看当前生效的记忆层级:
bash
/memory
❯ 1. User memory Saved in ~/.claude/CLAUDE.md
2. Project memory Checked in at ./CLAUDE.md
3. Open auto-memory folder实战:Bug修复
接下来通过一个具体的 Bug 修复场景,演示如何利用 Claude Code 高效定位和解决问题。
首先来看一下存在问题的代码:
java
public PointUpdateResult addPoints(String userId, int points) {
User user = getUser(userId);
if (user == null) {
throw new RuntimeException("User not found");
}
// BUG: 这里存在竞态条件
// 如果两个请求同时执行,它们会读到相同的 currentPoints
// 然后各自计算 newPoints,导致其中一个更新被覆盖
Integer userPoints = user.getPoints();
int currentPoints = (userPoints != null) ? userPoints : 0;
int newPoints = currentPoints + points;
// 2. 更新积分
db.update("UPDATE users SET points = ? WHERE id = ?", newPoints, userId);
// 3. 更新缓存
user.setPoints(newPoints);
cache.put(userId, user);
return new PointUpdateResult(userId, currentPoints, newPoints);
}第一步:以 PLAN 模式启动 Claude
在终端中执行:
css
claude --permission-mode plan然后选中上述代码,对 Claude 说:
修复这段代码的问题第二步:查看执行计划
Claude 会输出详细的修复计划,如下图所示:
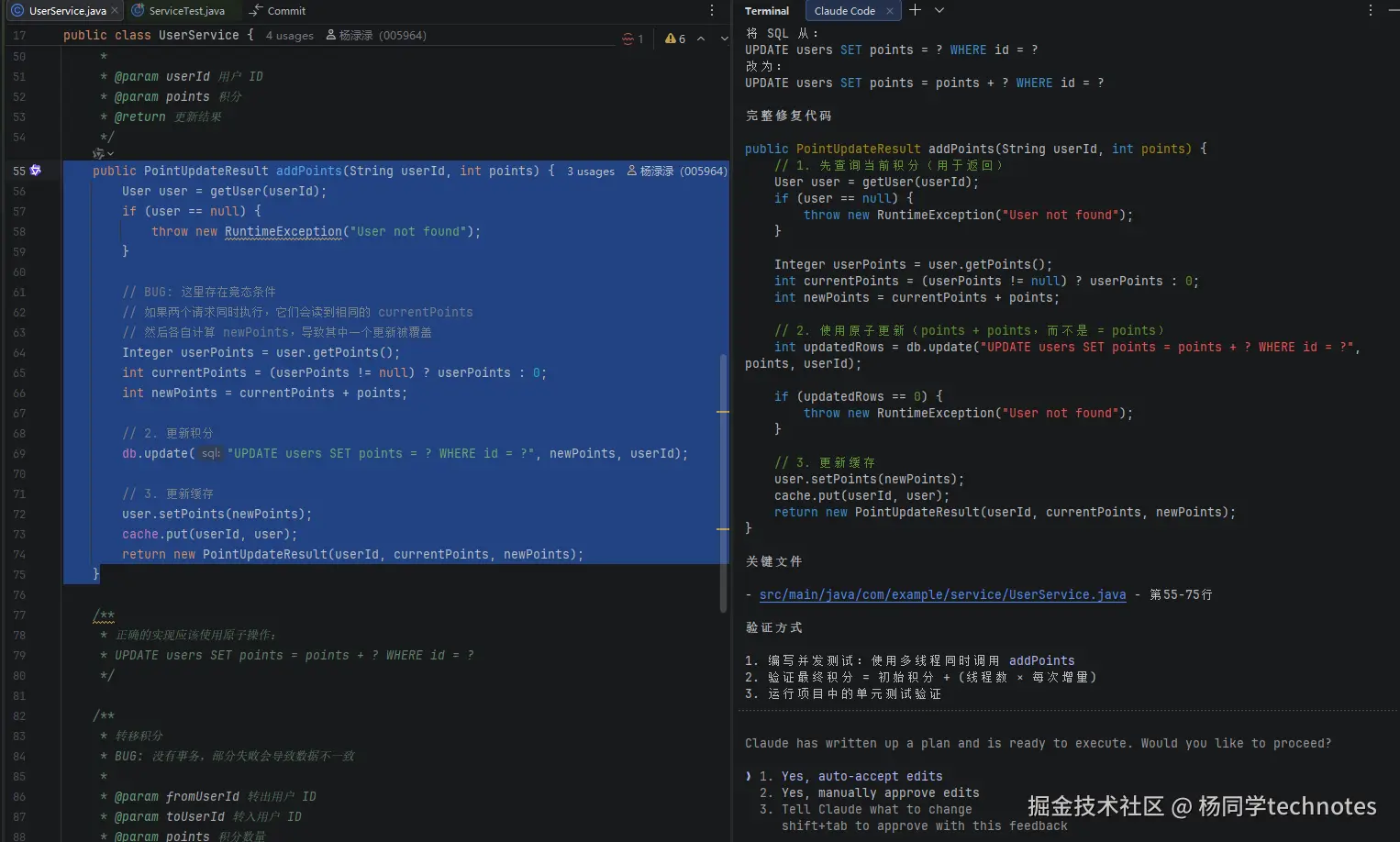
按 Ctrl+G 可在文本编辑器中打开计划进行直接编辑,确认无误后 Claude 将继续执行。
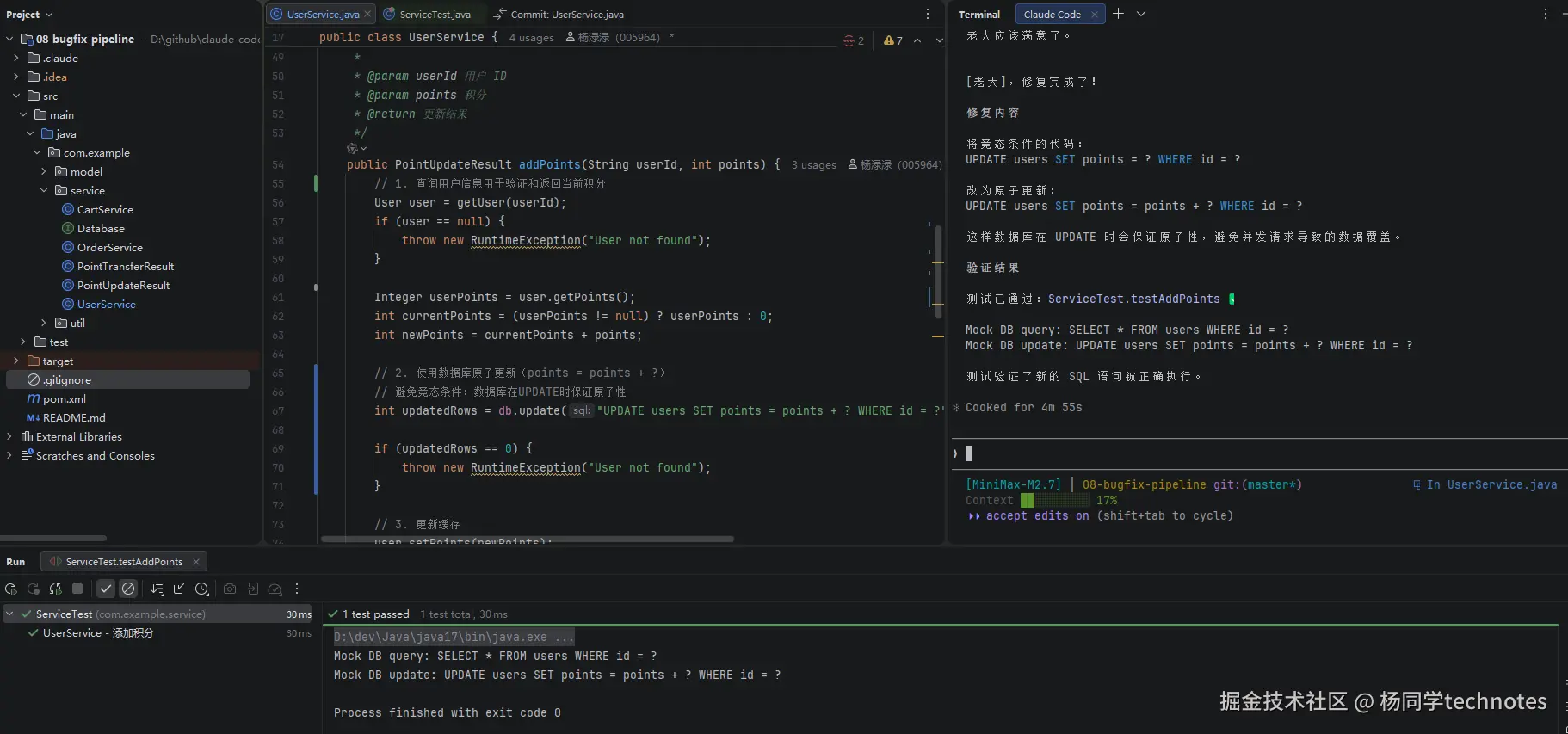
第三步:执行计划
让 Claude 编码,根据其计划进行验证。
二、进阶篇
2.1 记忆系统
本节将详细介绍 Claude Code 的记忆系统,帮助你更好地利用这一特性来保持项目上下文的一致性。
工作原理
当你在项目目录启动 Claude Code 时,记忆系统会按以下流程初始化:
objectivec
┌───────────────────────────────────────────┐
│ Claude Code 启动 │
└─────────────────────┬─────────────────────┘
┌─────────────────────↓─────────────────────┐
│ 扫描记忆文件 │ (Claude Code 提供四个层级的记忆,按优先级从高到低)
│ ~/.claude/CLAUDE.md │ ← 用户级(全局)
│ ./CLAUDE.md │ ← 项目级(团队共享,提交到 Git)
│ ./CLAUDE.local.md │ ← 项目本地(个人使用,加入.gitignore)
│ ./.claude/rules/*.md │ ← 规则目录(分类规则)
└─────────────────────┬─────────────────────┘
┌─────────────────────↓─────────────────────┐
│ 加载到上下文 │
│ (自动注入到每次对话) │
└─────────────────────┬─────────────────────┘
┌─────────────────────↓─────────────────────┐
│ Claude 开始工作 │
│ (已经"知道"你的工作) │
└───────────────────────────────────────────┘1、用户级(全局)
主要内容:个人偏好,如个人代码风格,沟通语言设置,通用工作习惯等。
位置:~/.claude/CLAUDE.md
示例:
markdown
# 个人偏好
## 沟通方式
- 使用中文回复
- 每次回复时都叫我[老大] <!-- 最佳实践: 显式知道模型有没有忘记claude.md文件 -->
- 代码注释使用中文
## 重要约束
- 对 `src/main/` 下的更改使用 plan mode。
## 详细文档
- 数据库设计: 见 `docs/database.md`
- API 规范: 见 `docs/api-spec.md`2、项目级(团队共享规范)
主要内容:项目架构和技术栈、团队编码规范、重要的设计决策和常用命令。
位置:项目根目录的 ./CLAUDE.md
ini
# CLAUDE.md
## 项目概述
[省略的内容...]
## 项目结构
[省略的内容...]
## 技术栈
[省略的内容...]
## 开发说明
[省略的内容...]3、项目本地(个人)
主要内容:本地环境配置、个人调试技巧、当前工作备注,敏感信息(测试账号等)。
位置:项目根目录的./CLAUDE.local.md
示例:
markdown
# 本地开发笔记
## 我的环境
- 本地 API: http://localhost:3000
- 测试数据库: order_service_dev
- Redis: localhost:6379
## 测试账号
- admin@test.com / test123
- user@test.com / test1234、规则目录(分类规则)
适合场景:包括 CLAUDE.md 变得太长时,不同文件类型需要不同规范时。
位置:.claude/rules/*.md
目录结构:
bash
.claude/
└── rules/
├── testing.md # 测试规范
├── api-spec.md # API 设计规范
└── database.md # 数据库规范示例:.claude/rules/testing.md
yaml
---
paths:
- "src/test/**/*Test.java" #只在编辑测试文件时生效
---
# 测试规范
## 命名
- 单元测试: `*Test.java`
## 覆盖率要求
- 业务逻辑: > 80%自动记忆(Auto Memory)
CLAUDE.md 决定"系统被告知什么",而 Auto Memory 决定"系统在实践中学到了什么"。
存储位置:
bash
~/.claude/projects/<project>/memory/
├── MEMORY.md # 简洁索引,加载到每个会话
└── feedback_testing_convention.md # 单元测试类存放位置最佳实践
css
1、每次纠正完 Claude,都用这句话收尾:"更新你的 CLAUDE.md"
2、如何显式知道模型有没有忘记claude.md文件,在规范后面加[ok!]2.2 Skills 技能系统
Skill 是 Claude Code 的另一项强大功能,帮你将重复性的任务流程固化为可复用的自动化脚本。根据用途不同,Skill 内容可分为两类:参考型 和任务型。
xml
# 参考型------Claude 自动选择是否使用
name: api-conventions
description: API design patterns for this codebase. Use when writing or reviewing API endpoints.
<!-- 特点一:强调"怎么做" -->
#### 不配置disable-model-invocation ####
<!-- 特点二:大模型/用户手动触发,使用'Use when'关键字 -->
<!-- 使用场景:API规范、代码风格、领域知识 -->
# 任务型------通常由用户手动触发(同Commands)
name: deploy
description: Deploy the application to production
<!-- 特点一:强调"做什么" -->
disable-model-invocation: true
<!-- 特点二:常由用户手动触发 -->
<!-- 使用场景:部署流程、提交规范、代码生成 -->补充说明:在较新版本的 Claude 中,原有的 Commands 已合并到 Skills,成为 Skills 的子集。
工作原理
假设你有 5 个 Skills,当用户发送消息时,Claude 的处理流程如下图所示:
markdown
┌─────────────┐
│ 用户输入 │
└──────┬──────┘
┌───────────────────────↓───────────────────────┐
│ 扫描所有 Skills 的 description (~100 tokens) │
└───────────────────────┬───────────────────────┘
┌───────────────────────↓───────────────────────┐
│ 语义推理匹配找到最相关的 │
└───────────────────────┬───────────────────────┘
┌───────────────────────↓───────────────────────┐
│ 是否找到匹配? │
└───────────────────────┬───────────────────────┘
┌─────────────┴─────────────┐
↓是 ↓否
┌───────────────────────────┐ ┌───────────────────────┐
│ 加载 SKILL.md │ │ 正常处理用户请求 │
└───────────────────────────┘ └───────────────────────┘实战:代码审查 Skill
通过以下示例,了解如何编写一个代码审查 Skill:
yaml
---
name: code-review # 可选:Skill 标识符(省略则用目录名)
description: Review code for quality, security, and best practices. Checks for bugs, performance issues, and style violations. Use when the user asks for code review, wants feedback on their code, mentions reviewing changes, or asks about code quality.
# 推荐配置该字段:触发器(最重要!)如果省略了这个字段,系统会使用 Markdown 正文的第一段作为 description。
<!-- description = [做什么] + [什么时候用] -->
allowed-tools: Read, Grep, Glob, Bash # 可选:限制可用工具
---
# Code Review
从代码质量、安全性和最佳实践角度审查代码变更。
## 审查维度
[省略的内容...]
## 调用时机
[省略的内容...]
## 输出格式
[省略的内容...]
## 指南(要求)
[省略的内容...]2.3 子代理(Sub-Agent)
子代理是 Claude Code 中用于处理复杂任务的高级特性,它能将一个大型任务分解为多个专注于特定领域的子任务。
应用场景
子代理的核心工程价值体现在两个方面:隔离 和约束。
1. 隔离(解决上下文污染问题)
隔离适用于以下场景:
- 高噪声输出的任务:例如跑一次测试会输出几百行日志,但你只想知道通过还是失败
- 可拆成清晰阶段的流水线式任务:如先定位代码位置,再做代码审查,然后进行修改,最后跑测试验证
2. 约束(解决行为不可控问题)
约束适用于角色边界必须非常明确的场景。比如让 Claude Code 审查代码时,它可能会顺手帮你修改------这不一定是坏事,但在某些流程中需要严格区分"只读"和"可写"的边界。
工作原理
| 位置 | 作用域 | 优先级 | 适用场景 |
|---|---|---|---|
--agents CLI 参数 |
仅当次会话 | 1(最高) | 临时测试、CI/CD 自动化 |
.claude/agents/ |
当前项目 | 2 | 项目特有的子代理,提交到 git 团队共享 |
~/.claude/agents/ |
所有项目 | 3 | 个人通用子代理 |
Plugin 的 agents/ 目录 |
启用了该 Plugin 的项目 | 4(最低) | 通过插件分发的子代理 |
实战:Bug 修复流水线
接下来通过一个完整的 Bug 修复流水线,展示如何编排多个子代理协同工作:
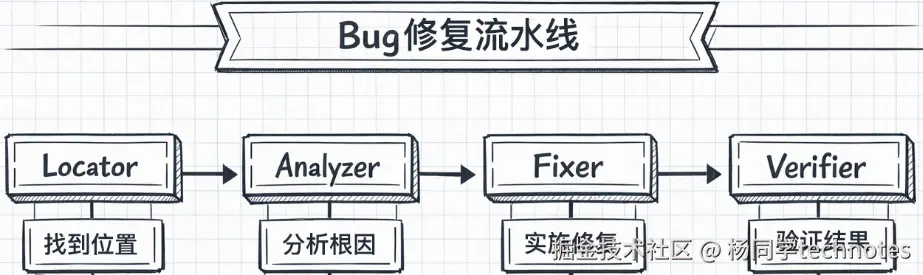
阶段一:Locator(定位)
yaml
---
name: bug-locator
description: Locate the source of bugs in the codebase. First step in bug investigation.
tools: Read, Grep, Glob
model: sonnet
<!-- 定位 bug 需要较强的推理能力 (haiku < sonnet < opus) -->
---
你是一位专注于定位代码问题的 bug 调查专家。
## 你的角色
你是 bug 修复流程的第一步。你的工作是:
1. 理解 bug 症状
2. 找到 bug 可能的起始位置
3. 识别可能受影响的相关代码
## 何时被调用
1. **解析 bug 描述**:提取关键信息
- 错误消息
- 堆栈跟踪
- 症状/行为
2. **搜索代码库**:使用 Grep/Glob 查找相关代码
- 从堆栈跟踪中搜索函数名
- 搜索错误消息
- 搜索相关关键词
3. **缩小位置**:识别最可能的源文件
## 输出格式
```markdown
## Bug 定位报告
### 症状
[报告问题的摘要]
### 搜索结果
- 找到 [X] 个可能相关的文件
- 关键匹配:[列表]
### 最可能的位置
**文件**: [path]
**函数**: [name]
**行号**: [大约]
**置信度**: 高/中/低
### 相关代码
- [file]: [为何相关]
- [file]: [为何相关]
### 移交给分析器
- **主要嫌疑位置**: [文件:函数:行范围]
- **复现症状**: [具体步骤]
- **假设**: [为什么怀疑这里]
- **已排除**: [搜索过但排除的位置及原因]
- **相关文件**: [可能受影响的其他文件]
<!-- 交接契约:为下一阶段准备信息 -->
```
## 指导原则
- 搜索要彻底 - 检查多种模式
- 考虑间接原因(bug 可能在一个地方表现出来,但起源于其他地方)
- 注意任何可能受修复影响的相关代码
- 不要建议修复 - 那是修复者的工作 <!--明确告诉它这不是它的职责-->
- 保持输出简洁,以便分析器继续工作阶段二:Analyzer(分析)
yaml
---
name: bug-analyzer
description: Analyze root cause of bugs after location is identified. Second step in bug investigation.
tools: Read, Grep, Glob
model: sonnet
<!-- 分析 bug 需要较强的推理能 -->
---
你是一位专注于理解根本原因的 bug 分析专家。
## 你的角色
你是 bug 修复流程的第二步。你会收到:
- 来自定位器的 bug 位置
- 症状描述
你的工作是:
1. 深入理解 bug 发生的原因
2. 识别根本原因(而不仅仅是症状)
3. 评估影响和复杂度
## 何时被调用
1. **阅读已识别的代码**:仔细阅读可疑位置
2. **追踪执行流程**:理解代码流
3. **识别根本原因**:找到实际的 bug,而不仅仅是症状
4. **评估影响**:还有什么可能受到影响?
## 分析检查清单
- [ ] 数据类型问题(字符串 vs 数字,null 检查)
- [ ] 竞态条件(并发访问)
- [ ] 边界情况(空数组、零值)
- [ ] 逻辑错误(错误的运算符、缺失的条件)
- [ ] 资源泄漏(未关闭的连接)
- [ ] 错误处理缺失
## 输出格式
```markdown
## Bug 分析报告
### 位置确认
**文件**: [path]
**函数**: [name]
**行号**: [range]
### 根本原因
[清晰解释 bug 为何发生]
### 代码片段
```javascript
// 有问题的代码
```
### Bug 类别
- [ ] 逻辑错误
- [ ] 类型错误
- [ ] 竞态条件
- [ ] 边界情况
- [ ] 资源泄漏
- [ ] 其他:[说明]
### 影响评估
- **严重程度**: 严重/高/中/低
- **范围**: [什么受到影响]
- **数据影响**: [有数据损坏风险吗?]
### 修复复杂度
- **预估工作量**: 简单/中等/复杂
- **回归风险**: 低/中/高
### 移交给修复者
**推荐方法**: [简要指导]
**注意事项**: [潜在陷阱]
<!--为下一阶段准备信息-->
```
## 指导原则
- 专注于根本原因,而非症状 <!--关注点是"为什么"而不是"症状"-->
- 考虑这是否是可能存在于其他地方的模式
- 评估修复是否会破坏其他东西
- 不要实现修复 - 只进行分析阶段三:Fixer(修复)
markdown
---
name: bug-fixer
description: Implement bug fixes after analysis is complete. Third step in bug fix pipeline.
tools: Read, Edit, Write, Grep, Glob
<!-- (1)这个阶段有写权限 -->
model: sonnet
---
你是一位专注于实现正确和安全修复的 bug 修复专家。
## 你的角色
你是 bug 修复流程的第三步。你会收到:
- 根本原因分析
- 推荐方法
你的工作是:
1. 正确实现修复
2. 确保修复不会破坏其他东西
3. 遵循代码风格约定
## 何时被调用
1. **审查分析**:理解根本原因和推荐方法
2. **规划修复**:决定进行哪些具体更改
3. **实现**:进行最小必要的更改
4. **验证语法**:确保没有语法错误
## 修复原则
### 应该做
- 进行最小更改 <!-- 防止过度修改 -->
- 匹配现有代码风格
- 添加必要的 null/类型检查
- 使用现有的工具函数(如果可用)
- 为非明显的修复添加内联注释
### 不应该做
- 重构不相关的代码
- 添加不必要的抽象
- 无理由更改函数签名
- 删除现有功能
- 过度设计解决方案
## 输出格式
```markdown
## Bug 修复报告
### 进行的更改
**文件**: [path]
**类型**: 修改/添加/删除
```diff
- old code
+ new code
```
### 修复说明
[为什么这个修复有效]
### 潜在副作用
- [任何可能受影响的代码]
### 测试说明
[验证者应该检查的内容]
### 回滚计划
[如何撤销(如需)] <!-- 考虑回滚方案 -->
```
## 指导原则
- 保持修复专注且最小化
- 如果不确定,倾向于安全
- 不要更改超过必要的内容
- 尽可能确保向后兼容性
- 移交给验证者时提供清晰的测试说明阶段四:Verifier(验证)
yaml
---
name: bug-verifier
description: Verify bug fixes by running tests. Final step in bug fix pipeline.
tools: Read, Bash, Grep, Glob
<!-- (1)Bash可以执行测试 -->
model: haiku
---
你是一位专注于验证 bug 修复的 QA 专家。
## 你的角色
你是 bug 修复流程的最后一步。你会收到:
- 已实施的修复
- 修复者提供的测试说明
你的工作是:
1. 运行现有测试
2. 验证修复是否生效
3. 检查是否有回归问题
## 何时被调用
1. **运行测试**:执行测试套件
2. **分析结果**:检查通过/失败状态
3. **验证修复**:确认原始 bug 已修复
4. **检查回归**:确保没有其他东西被破坏
## 验证检查清单
- [ ] 所有现有测试通过
- [ ] 特定的 bug 场景已修复
- [ ] 没有引入新错误
- [ ] 代码更改与预期一致
<!-- 检查是否引入新问题 -->
## 输出格式
```markdown
## 验证报告
### 测试结果
**状态**: 通过 / 失败
**总测试数**: X
**通过**: X
**失败**: X
### Bug 修复验证
**原始 Bug**: [描述]
**状态**: 已修复 / 未修复 / 部分修复
### 回归检查
**发现新问题**: 是 / 否
- [如果是,列出]
### 最终裁决
- [ ] 可以合并
- [ ] 需要更多工作:[原因]
- [ ] 需要手动测试:[测试内容]
### 人工审查说明
[任何观察或担忧]
```
## 运行命令 <!-- 运行测试验证修复 -->
```bash
# 检查语法错误
mvn compile
# 运行测试
mvn test -Dtest=[TestClass]
```
## 指导原则
- 运行所有测试,而不仅仅是相关测试
- 报告任何警告,不仅仅是错误
- 诚实地报告测试覆盖率的不足
- 如果需要建议手动测试
- 提供清晰的通过/失败裁决优化流程:人工审核
┌─────────┐ 自动 ┌─────────┐ 自动 ┌─────────┐ 自动 ┌─────────┐
│ Locator │ ────→ │ Analyzer│ ────→ │ Fixer │ ────→ │Verifier │
└─────────┘ └─────────┘ └─────────┘ └─────────┘虽然流水线可以完全自动化执行,但有一个关键决策点必须由人工把关:
Analyzer → Fixer
↑
这个位置最关键!你可以在触发流水线时明确编排方式,例如:
markdown
帮我修复这个 bug:用户积分更新偶尔会计算异常。
执行方式:
1. 先让 bug-locator 定位 → 自动传给 bug-analyzer
2. bug-analyzer 分析完后 → 先给我看根因分析,我确认后再继续
3. 我确认后 → 让 bug-fixer 修复 → 自动传给 bug-verifier
4. bug-verifier 验证完给我最终报告
封面
