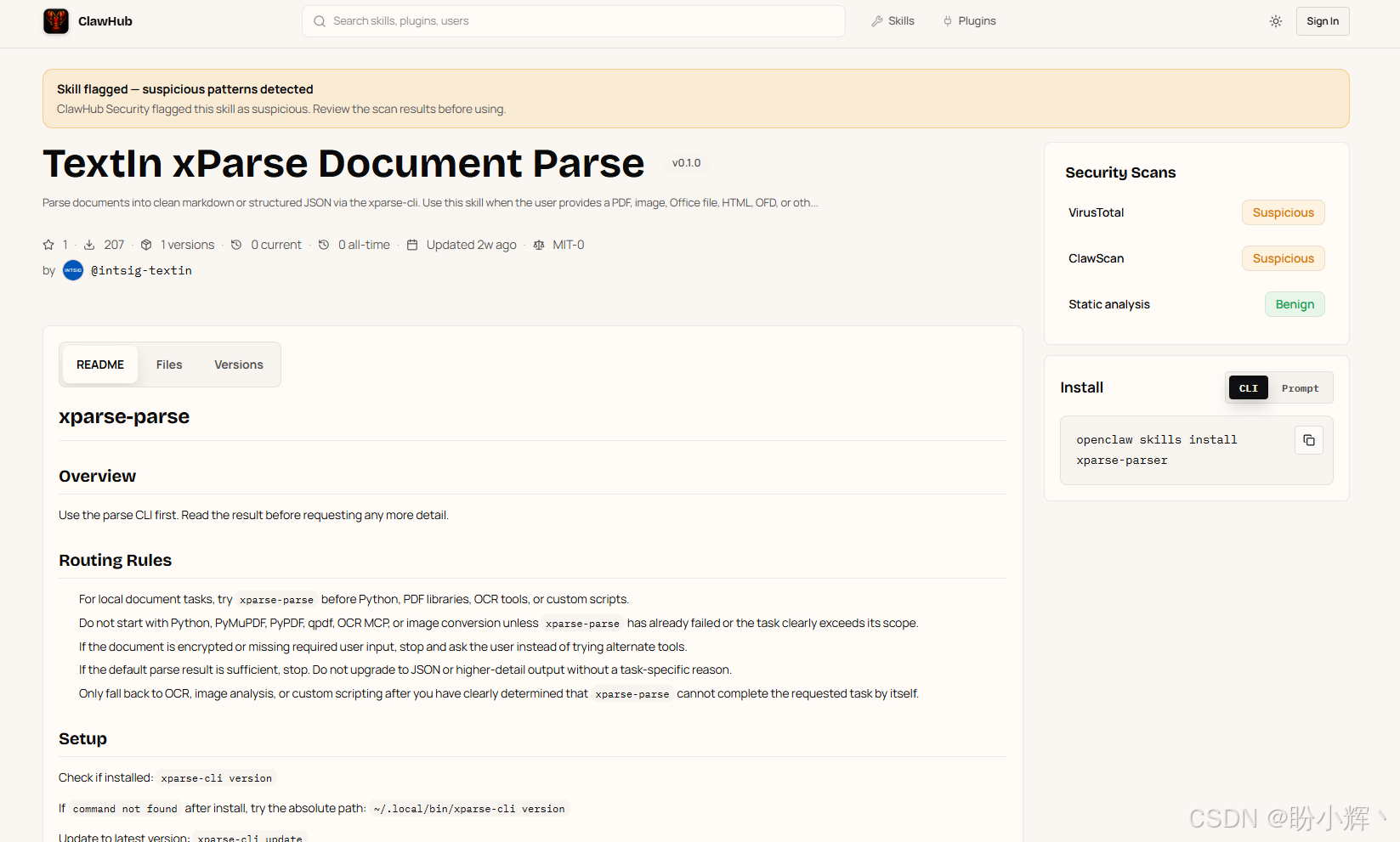
TextIn xParse Skill上架ClawHub,补齐Agent"读文档"短板
-
- [0. 前言](#0. 前言)
- [1. 为什么 Agent 必须要"文档解析 Skill"](#1. 为什么 Agent 必须要“文档解析 Skill”)
- [2. TextIn xParse Skill 核心能力拆解](#2. TextIn xParse Skill 核心能力拆解)
-
- [2.1 全格式兼容](#2.1 全格式兼容)
- [2.2 结构完整还原](#2.2 结构完整还原)
- [2.3 极速解析](#2.3 极速解析)
- [2.4 Markdown 输出](#2.4 Markdown 输出)
- [2.5 精确坐标回显](#2.5 精确坐标回显)
- [3. 零门槛上手:TextIn xParse 安装与使用过程](#3. 零门槛上手:TextIn xParse 安装与使用过程)
-
- [3.1 方式一:通过 Agent 对话安装(最推荐)](#3.1 方式一:通过 Agent 对话安装(最推荐))
- [3.2 方式二:手动安装](#3.2 方式二:手动安装)
- [3.3 使用过程像和同事说话一样简单](#3.3 使用过程像和同事说话一样简单)
- [4. 复杂场景测试](#4. 复杂场景测试)
-
- [4.1 复杂表格与跨页处理](#4.1 复杂表格与跨页处理)
- [4.2 双栏论文与图文混排](#4.2 双栏论文与图文混排)
- [4.3 手写体和低质量扫描件](#4.3 手写体和低质量扫描件)
- [4.4 极速批处理与超长文档](#4.4 极速批处理与超长文档)
- [4.5 使用感受](#4.5 使用感受)
- 小结
0. 前言
Agent 的生态正在飞速扩张,OpenClaw 社区里上万 Skills 的涌现就是最好的证明。但当开发者们兴冲冲地把 Agent 推向企业真实业务时,一个被长期低估的问题总会浮出水面:模型会思考,但不会"读文档"。
PDF、图片、扫描件、Office 文件等等这些日常工作中最普遍的载体,对大多数 Agent 来说依然是一堵墙。模型原生只能理解文本,面对一张发票截图、一份 PDF 合同或是一页扫描版论文时,要么束手无策,要么依赖 OCR 勉强应对------效果差、速度慢、结构全丢,而这些"非结构化数据"往往才是最核心的数据来源。TextIn xParse Skill 的出现,就是为了拆掉这堵墙。
TextIn xParse skill 原本是一个完全商用的成熟文档解析工具,现在以免费 skill 的形式开放。它不仅带来了商业级的精度,更降低了 Agent 接入文档的成本。在本文中,我们就从技术实现、使用过程、实际体验等几个维度,聊聊它到底能带来什么不同。
1. 为什么 Agent 必须要"文档解析 Skill"
先抛开技术细节,我们来看看 TextIn xParse 在整个 Agent 工作流里的站位。Karpathy 在构建 LLM.Wiki 时,把"原始文档 → 模型可用文本"这个过程称为编译。目前的 Agent 框架大多擅长链式调用、工具编排、记忆管理,但上游的文档编译环节,始终缺少一个既稳定又零门槛的基础组件。这正是 TextIn xParse 的核心站位:做 Agent 接入知识的起点。
TextIn xParse 它不只是一个 OCR 工具,它做的事情更接近知识接入------把 PDF、Word、PPT、Excel 乃至长截图,编译成保留层级与语义的 Markdown。这个格式是目前最受 LLM 和 Agent 欢迎的知识形态。
这个 Agent 可直接调用的"技能"与市面上的开源方案形成了鲜明对比:
- 商业级稳定性:在金融、法律等对准确率要求极高的场景久经考验
- 高可用,免维护:不用自己打补丁、调参数、组合多个开源库
- 效果优势:在表格还原、复杂版式、印章遮挡等硬核场景上,鲁棒性明显更强
值得玩味的是"免费"这个决策。TextIn xParse 过去一直是闭源商用的,服务的是金融、法律、物流等对准确率要求近乎苛刻的行业。现在以每日 1000 页的免费额度开放给 ClawHub 社区,这信号很明确:他们押注的是 Agent 生态的长远基础建设,而非短期 API 收入:
- 免费额度:免登录、零配置即可使用,支持
PDF和图片格式,每日上限1000页,对于个人开发者和小型团队来说绰绰有余 - 解锁更多:如需处理
Word、Excel、PPT、HTML等更多格式,或需要更高调用量,只需配置自己的TextIn账户凭证
2. TextIn xParse Skill 核心能力拆解
在进入实际体验之前,有必要先把 Textln xParse 的核心能力拆开看清楚,我们可以将其归纳为五个技术支点,每一项背后都有值得展开的技术细节。
2.1 全格式兼容
TextIn xParse 支持 PDF、Word、Excel、PPT、图片等十余种格式输入。做过文档处理的开发者都清楚不同格式对应的是截然不同的解析范式------PDF 依赖版式分析与流式还原,Office 文档依赖 OOXML 结构解析,图片依赖 OCR 管道。通常的思路是为每种格式引入一个独立库,然后写适配层把所有输出归一化,这个过程本身就充满各种坑。
TextIn xParse 的价值在于把多格式的复杂度封装在一个统一入口里。对 Agent 而言,无论用户丢进来的是 PDF 合同、Word 提案还是 Excel 报表,调用方式完全一致,输出格式统一为 Markdown 或 JSON。这在工程上消除了一个重要的分支判断点------而分支越少,Agent 行为越可预测。
2.2 结构完整还原
TextIn xParse 能够跨页表格、目录层级、页眉页脚、标题结构完整保留文档骨架。这是区分"文字识别"和"文档理解"的关键分界线。普通的 OCR 或提取工具,输出的是一串"扁平的文字流",标题、正文、表格、页眉被一视同仁地拼接在一起。这对人类阅读或许勉强可用,但对 LLM 来说是灾难------模型需要结构来建立上下文理解。
TextIn xParse 的"结构还原"做的是语义层的重建:
- 标题层级:
H1/H2/H3的嵌套关系被显式标注,输出Markdown自带目录结构 - 表格跨页:跨页表格被识别为同一个逻辑实体并自动拼接,而不是输出两个断裂的片段
- 页眉页脚:被标记但不干扰正文流,下游
Agent可以选择保留或过滤 - 阅读顺序:多栏、图文混排时,输出顺序符合人类阅读逻辑
这套能力让解析结果不再是"一坨文本",而是一份有骨架、可导航的文档。
2.3 极速解析
TextIn xParse 解析百页文档只需约 1.5 秒,从容应对企业大规模文档批处理。速度指标要结合场景看才有意义,1.5 秒/百页在单次调用中感觉"很快",但它的真正价值体现在两个维度:
- 吞吐量:假设一个企业每天要做
10000份合同入库,如果用单页2秒的方案,需要5.5小时;用TextIn xParse则缩短到40秒左右,这个差距决定了文档处理是准实时还是漫长等待 Agent交互体验:用户跟Agent对话时,等1-2秒是"流畅",等10秒以上就是"卡顿",极速响应对交互式场景至关重要
2.4 Markdown 输出
TextIn xParse 输出保留文档层级与语义的 Markdown 格式,这是目前最受 LLM 和 Agent 欢迎的知识形态。文档解析的最终消费者早已不是人类读者,而是大模型。Markdown 作为中间表示,有三重优势:
token经济性:相比JSON或XML,Markdown的标记符占比低,同样信息量消耗更少token,直接降低LLM调用成本- 语义可读性:
# 标题、| 表格 |、**加粗**这些语法LLM在预训练阶段已大量接触,模型对Markdown结构的理解能力远高于自定义格式 - 可链式使用:
Markdown可以直接喂给大模型进一步分析,也可以直接作为RAG的上下文,无需二次转换
TextIn xParse 输出的不是"为了人类好看的 Markdown",而是结构规范、边界清晰、适合机器消费的 Markdown,可以说它把文档"编译"成了 LLM 的母语。
2.5 精确坐标回显
TextIn xParse 返回块级及字符级坐标信息,代表解析结果在原文档中的精确位置,方便前端可视化展示和后续审核校对。这是一个容易被低估但企业场景不可或缺的能力,坐标信息解决了"我凭什么相信这个解析结果"的信任问题。具体价值体现在以下环节:
- 前端高亮溯源:在文档审阅系统中,用户点击提取出的某个条款,原文档对应区域自动高亮。这是法律、审计场景的刚需
- 人工校对加速:校对人员不需要在原文中大海捞针,直接跳转到坐标位置核查即可
- 多级审核工作流:机器解析 → 坐标定位 → 人工复核 → 确认入库,整个流程的数据锚点统一
TextIn xParse 返回的是块级和字符级双粒度坐标,既支持区域级别的快速定位,也支持单个字符的精确追溯。这种精细度在合同金额、身份证号等关键字段的校验场景中,是实打实的安全保障。
3. 零门槛上手:TextIn xParse 安装与使用过程
在传统 AI 工具链里,接入一个"文档解析能力"通常意味着:
- 注册
API - 阅读
SDK文档 - 写解析代码
- 处理格式兼容
- 调试错误
整个过程往往需要数小时甚至数天,而 xParse Skill 做了一件非常关键的事情:把"工程能力"封装成"对话能力"。xParse 的核心理念是"像说话一样简单"。它支持两种安装方式,整个过程完全零代码,但这背后是一套设计精良的"技能发现与引导"机制。
3.1 方式一:通过 Agent 对话安装(最推荐)
通过 Agent 对话安装是最符合 Agent 范式的方式。在 OpenClaw、Claude Code 等 Agent 的对话框中,我们只需用自然语言说一句话,Agent 会自动完成整个安装流程:
shell
帮我从技能市场安装 intsig-textin/xparse-parser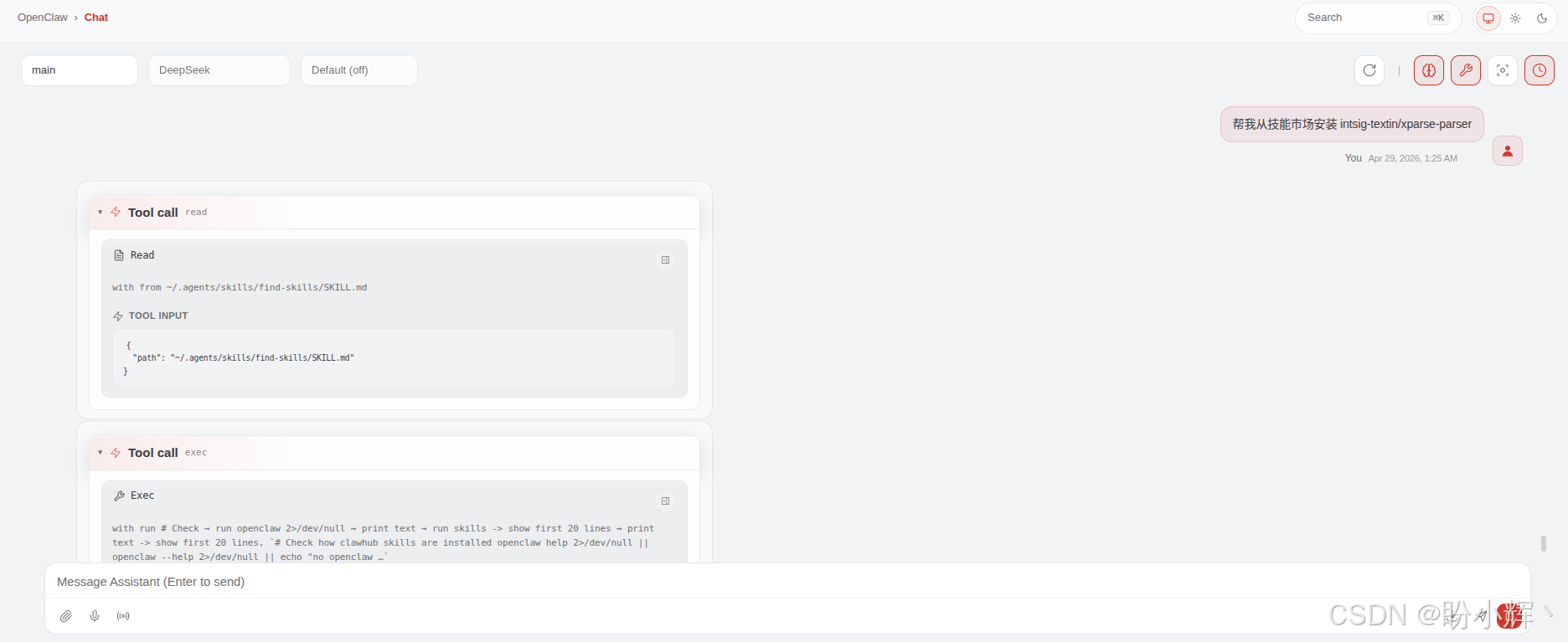
Agent 收到指令后,会遵循技能安装的最佳实践,分步执行:
-
自主发现与验证:
Agent会先浏览技能主页ClawHub页面,获取最新的安装说明和元数据,而不是凭"记忆"操作 -
执行具体安装命令:确认无误后,
Agent会调用对应的CLI命令静默安装OpenClaw CLI:openclaw skills install xparse-parserClawHub CLI(通过npx):npx clawhub@latest install xparse-parser
-
环境自检与初始化:安装后,
Agent会立即检查核心工具xparse-cli是否准备就绪,帮我们运行xparse-cli version验证。如果环境变量缺失,它会创建~/.xparse-cli/config.yaml来持久化配置
整个过程无需手动敲任何命令,Agent 成了我们的"部署工程师"。正如文档所言,它的路由规则是"对本地文档任务,优先尝试 xparse-parse,而不是先启动 Python、PDF 库或 OCR 工具",这体现了它作为首选工具的定位。
3.2 方式二:手动安装
如果更倾向于自主控制,也可以从 GitHub 或 ClawHub 直接下载技能压缩包。解压后,把里面的 skill.md 文件"丢给" Agent,它就能理解并使用这套技能。下载地址:
GitHub:https://github.com/intsig-textin/xparse-skillsClawHub:https://clawhub.ai/intsig-textin/xparse-parser
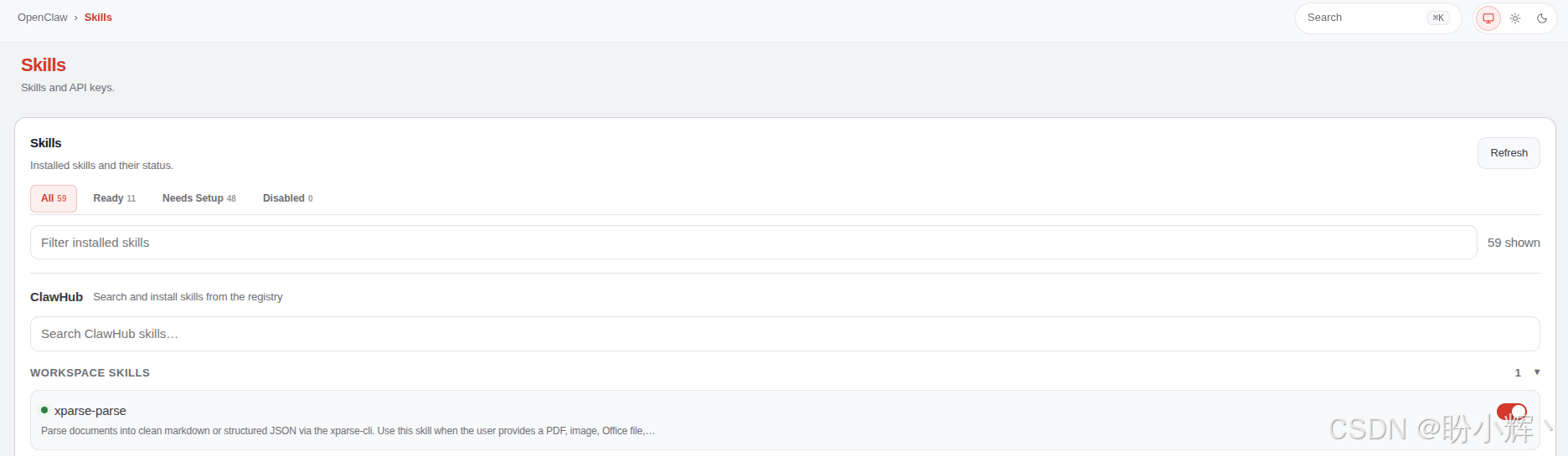
安装完成后可以在 Skills 菜单中看到 TextIn xParse Skill:
3.3 使用过程像和同事说话一样简单
安装并初始化成功后,使用体验就如呼吸般自然。只需要用自然语言下达一个意图指令,Agent 会自动将意图翻译成精准的 xparse-cli 命令,我们不需要记住任何参数,甚至不需要知道 xparse-cli 的存在。本质上,我们不再"调用工具",而是在"指挥一个会用工具的 Agent"。
传统调用文档解析,我们需要 OCR + 解析 + 表格处理 + Markdown 转换,而 xParse Skill 方式,只需要说,关键区别如下表所示:
| 传统方式 | xParse | |
|---|---|---|
| 调用方式 | 写代码 | 说话 |
| 输入格式 | API 参数 | 自然语言 |
| 输出处理 | 手动 | 自动 |
| 学习成本 | 高 | 极低 |
以下是我在实测中使用过的指令:
场景一:信息提取
shell
帮我读一下这份 PDF 论文,提取论文核心思想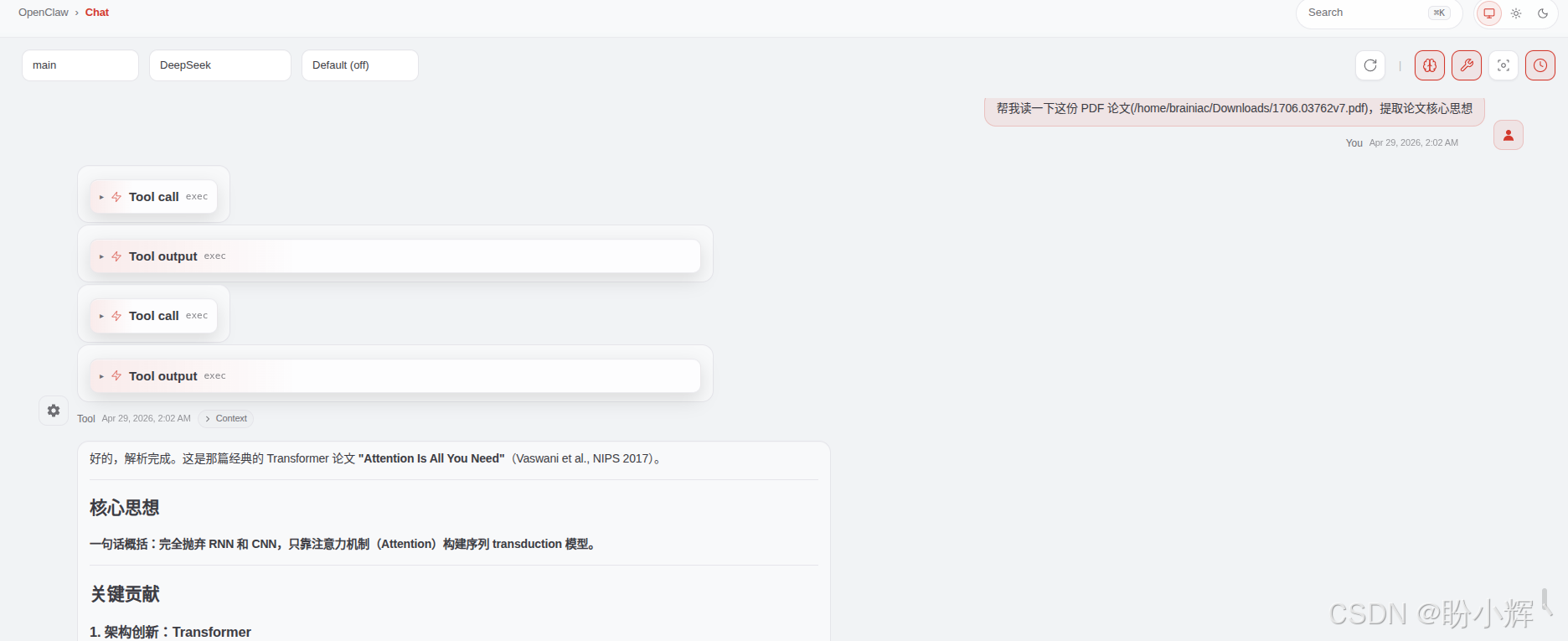
场景二:表格识别
shell
提取这张表格图片里的内容,输出 JSON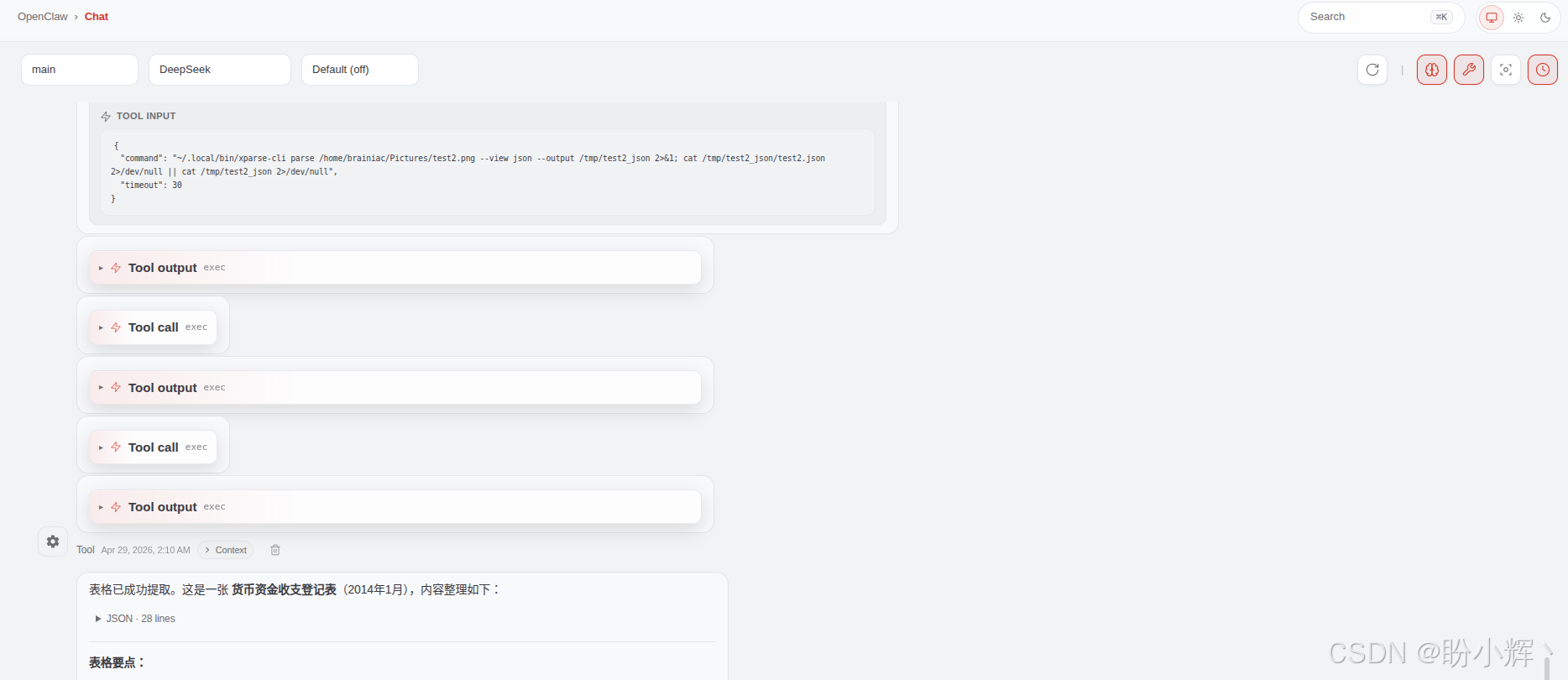
场景三:格式转换
shell
把这个论文转成 Markdown,保存到桌面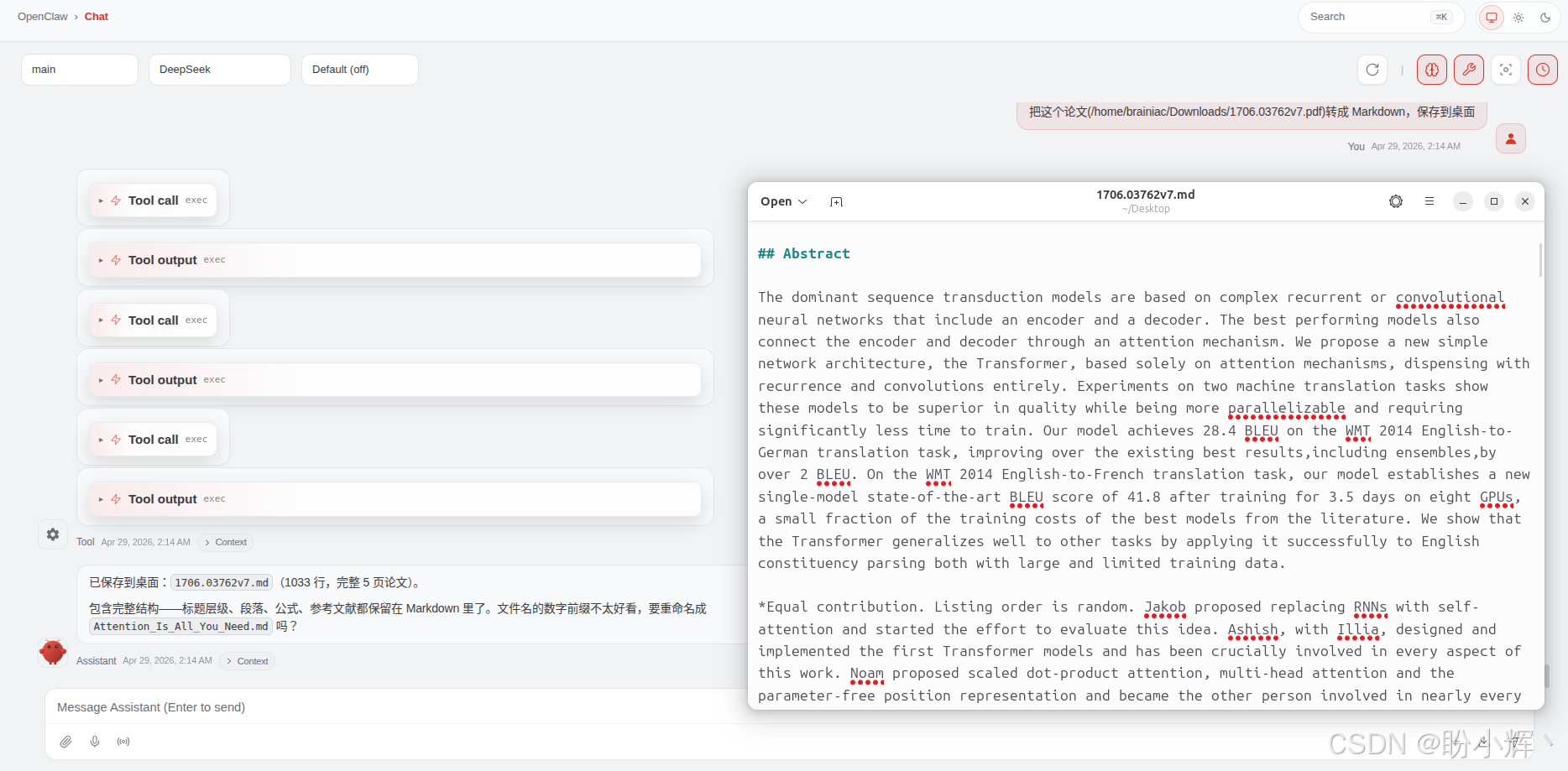
可以看到,我们不需要告诉 Agent "调用 xparse-cli",不需要关心输出路径格式。我们说的是意图 ,Agent 完成的是执行 。这就是一个为 Agent 时代设计的工具的使用方式:意图即指令,说话即编程。 它把复杂的文档解析任务,封装成了人人都能调用的基础能力。
4. 复杂场景测试
开源文档解析工具大多在"标准文档"上表现尚可,一遇到真实业务场景里那些复杂格式,翻车率就会飙升。所以这次使用 TextIn xParse 期间,我专挑最易出问题的复杂场景进行测试。
4.1 复杂表格与跨页处理
我们使用一份包含大量合并单元格、且跨页的财务报告表格进行测试,如下图所示。
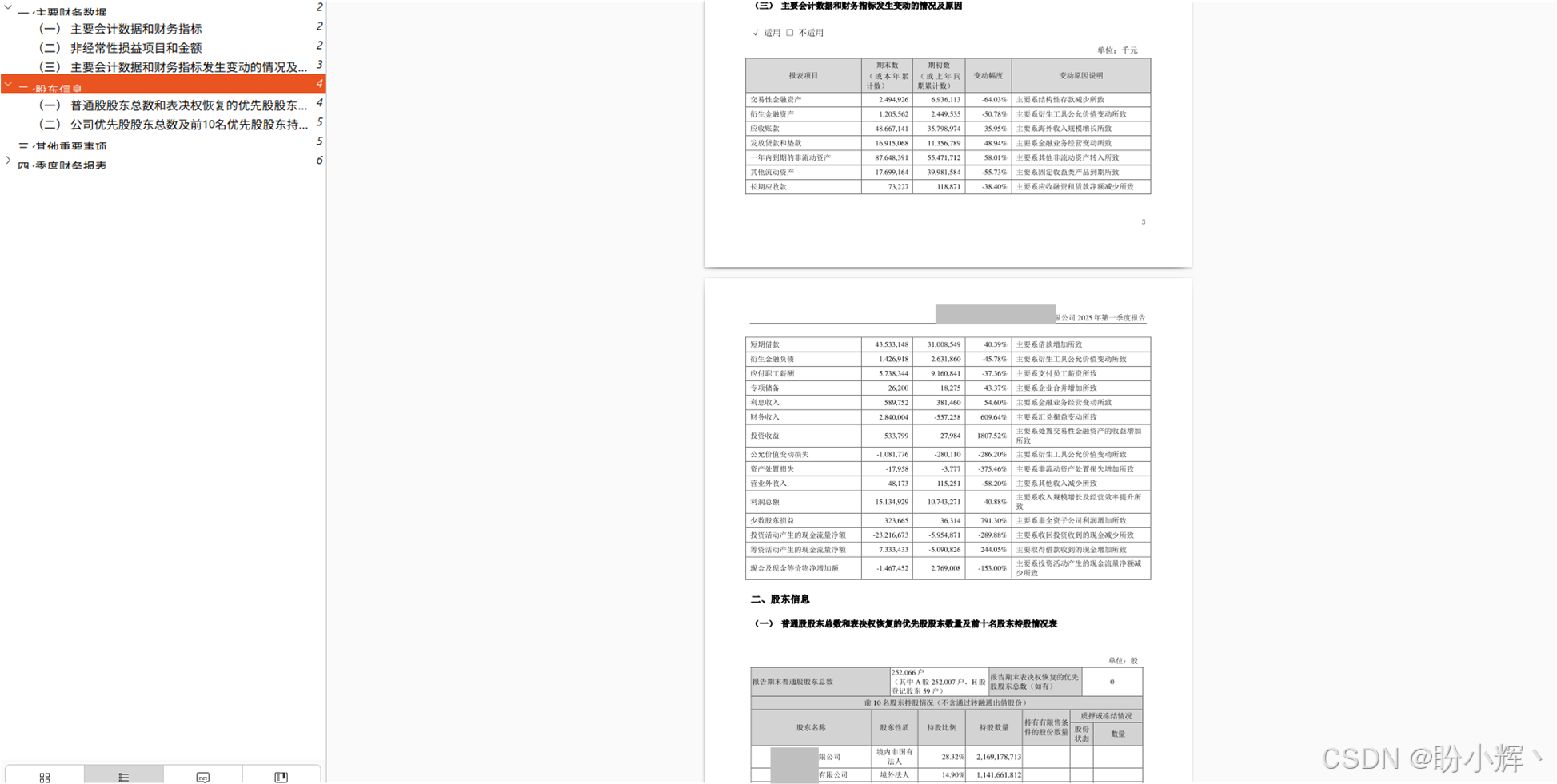
传统方法会在跨页处断裂成两个独立表格,合并单元格逻辑丢失,输出结果变成散落的碎片。而使用 TextIn xParse,表格被完整拼接,合并单元格关系全部正确保留。输出为规范 Markdown 表格,表头层级通过 colspan/rowspan 语义清晰标注,如下图所示。差异的背后是引擎对表格"语义"的理解,而非单纯的位置还原。合并单元格不是视觉上的画线,而是数据之间的逻辑关系。
shell
解析桌面 **集团-2025第一季度报告.pdf文档,分析集团财务情况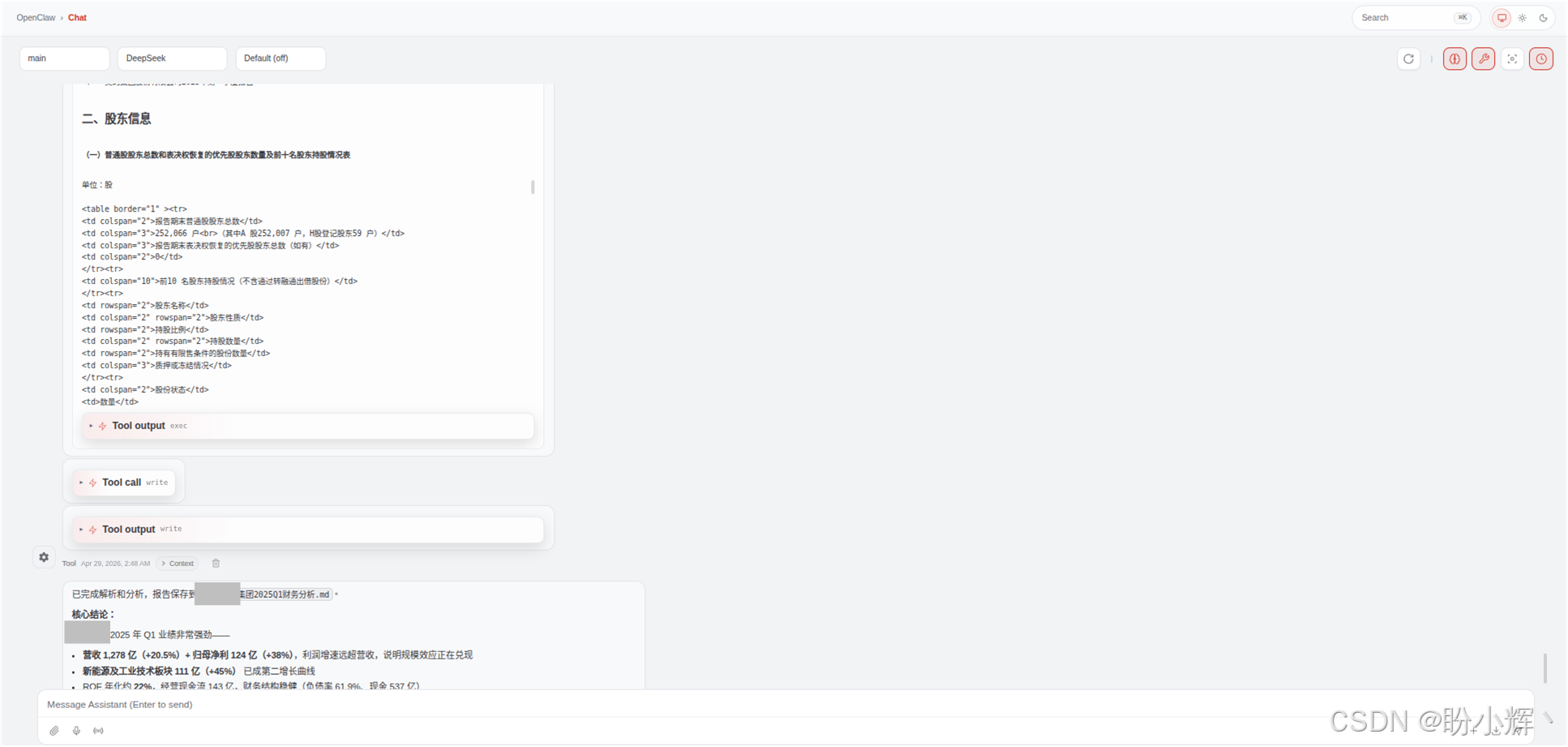
4.2 双栏论文与图文混排
我们使用一篇双栏排版的学术论文进行测试,论文中间穿插图表、公式和脚注,如下图所示。

传统方法阅读顺序混乱,可能先读完整页左栏再读右栏,或者图表和上下文脱节,标题错配到不相干的段落。而使用 TextIn xParse,栏序正确,图文绑定准确。每个图表都被放在了对应的文字描述附近,图题和表题没有张冠李戴。输出 Markdown 后我直接喂给大模型做摘要,生成的论文概要逻辑通顺,没有出现"这段在说什么"的跳跃感,如下图所示。
shell
解析桌面2604.24678v1.pdf文档,另存为markdown文件,并按论文段落总结论文主要内容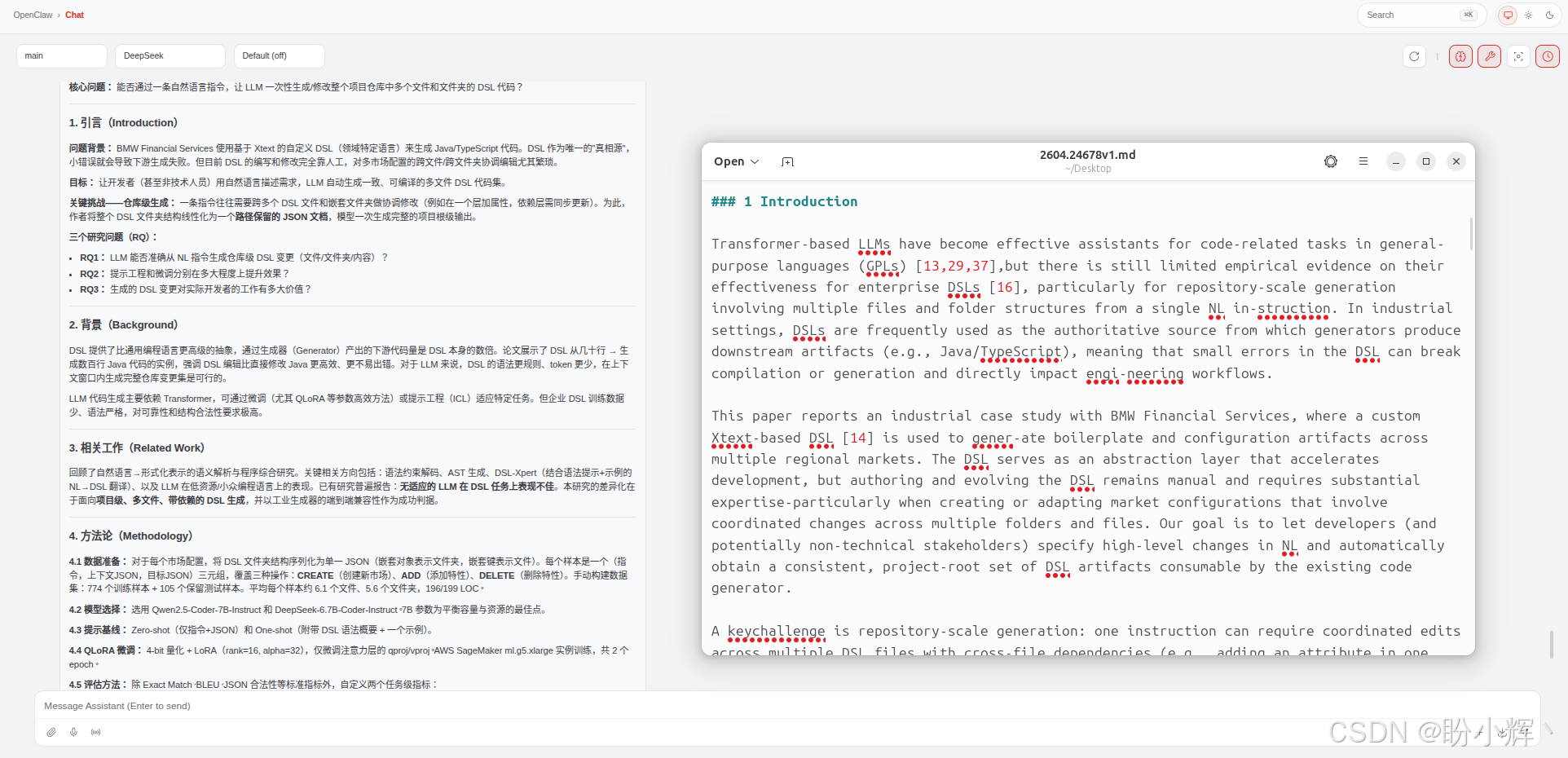
双栏文档的难点在于"阅读顺序还原",人类读者会自然地在栏间跳转,但机器看到的是像素排列。TextIn xParse 采用基于语义分割的理解方式,先识别文档的逻辑结构(正文区、图表区、边栏区),再决定输出顺序。这比单纯基于位置排序的算法稳得多。
4.3 手写体和低质量扫描件
我们使用下图进行测试,可以看到页面包含有手写体文字,扫描质量中等,存在轻微歪斜和噪点,左侧为原始图片,右侧为使用 TextIn xParse 结果。

传统方法通常将手写体和正文混在一起输出,污染了上下文;歪斜导致识别准确率断崖式下降。而使用 TextIn xParse,手写体内容没有被强行混入正文段落,输出结果干净、分层清晰,如上图右侧所示。
shell
解析桌面v2-ca2e94f12763b48e166cf49bd440a484_r.jpg,保存结果,并给出实际支付金额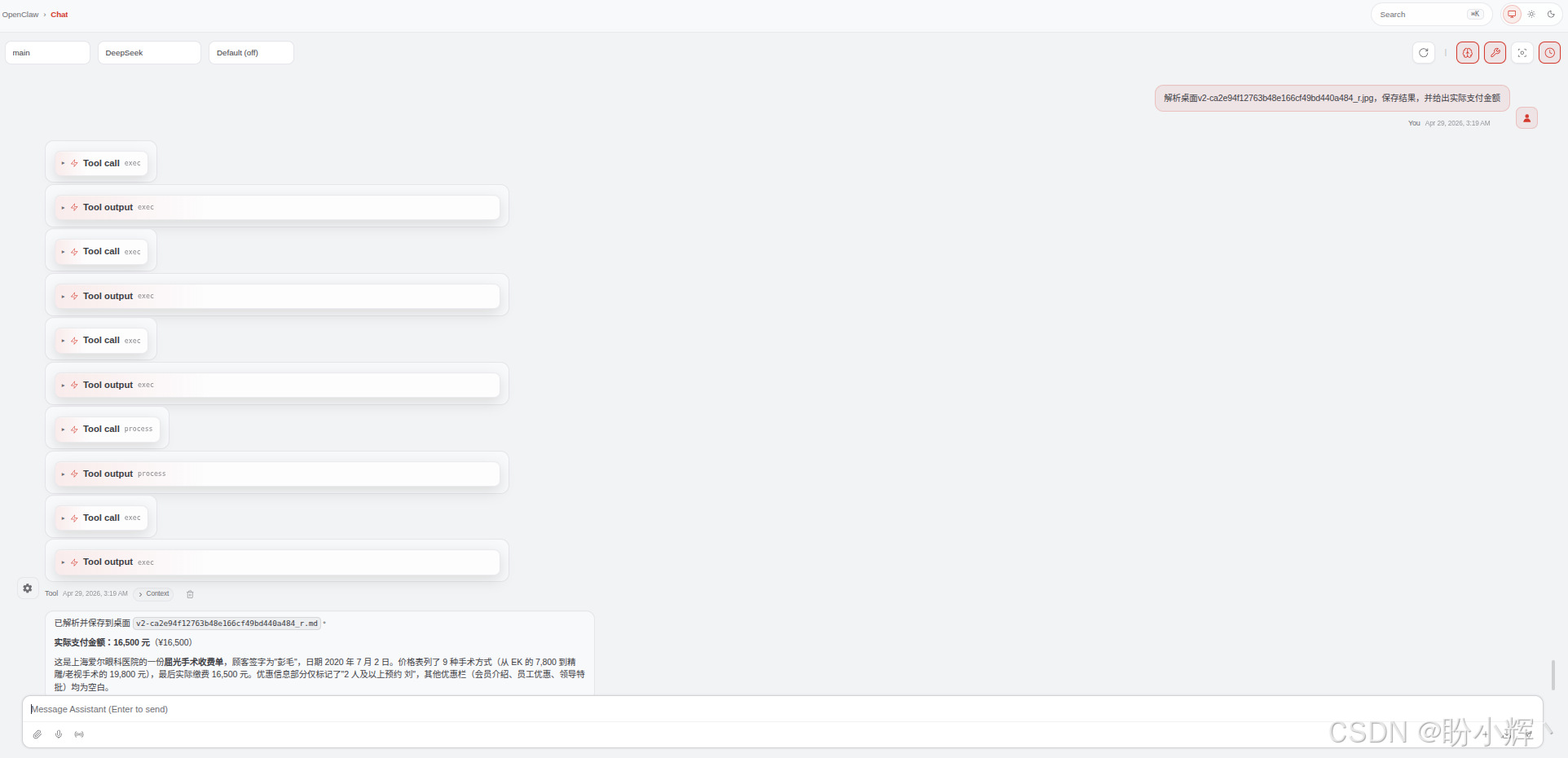
在合同要素提取场景里,"金额被识别错"和"一段手写备注被当成正文条款"都是不可接受的错误。第一个会导致业务风险,第二个会导致合规风险。商业引擎在这类"噪声环境下的精确提取"上所投入的专项优化,是它跟通用 OCR 的本质区别。
4.4 极速批处理与超长文档
最后,使用一份包含 300 页的电子书文档进行测试,图文总量大,排版密度高,如下图所示。
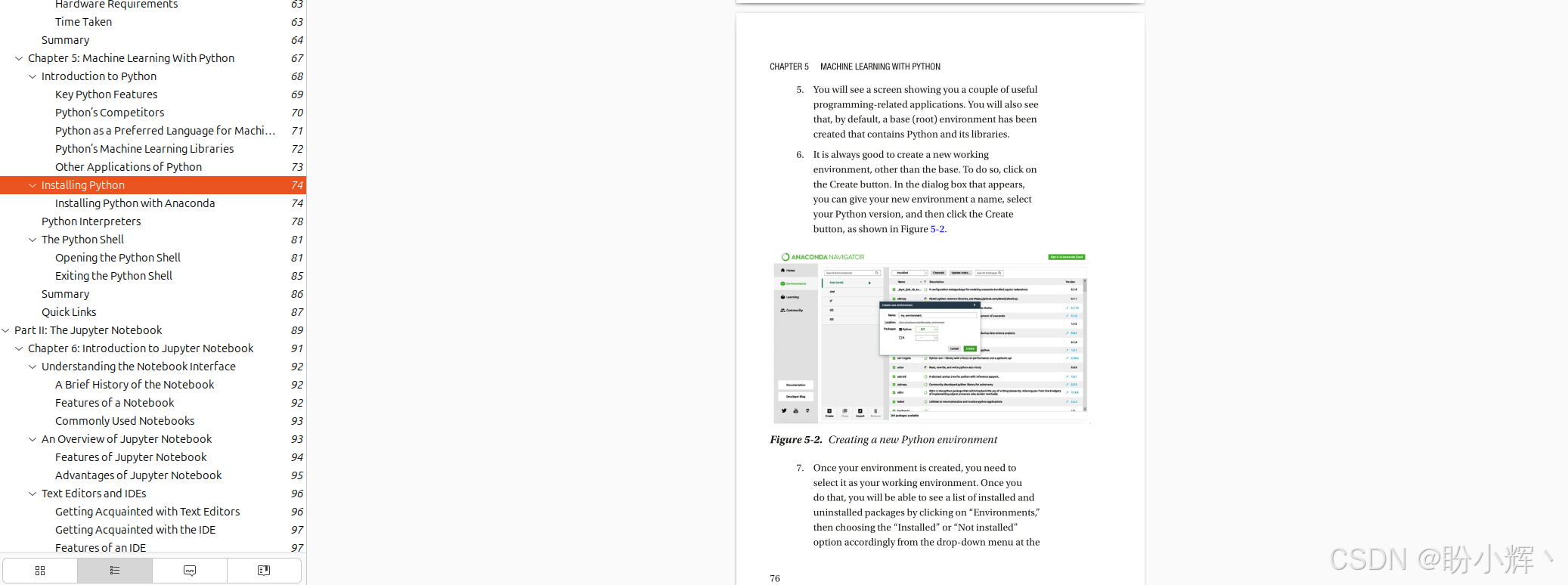
TextIn xParse 官方宣称百页约 1.5 秒,我实测 300 页在 4.6 秒左右完成(受网络延迟影响略有浮动)。期间内存占用平稳,没有出现解析到中途崩溃或超时的情况。输出 Markdown 结构完整,目录层级连贯,如下所示。
shell
解析桌面Machine Learning Concepts with Python.pdf文档,保存为markdown文件,并介绍书中各章节主要内容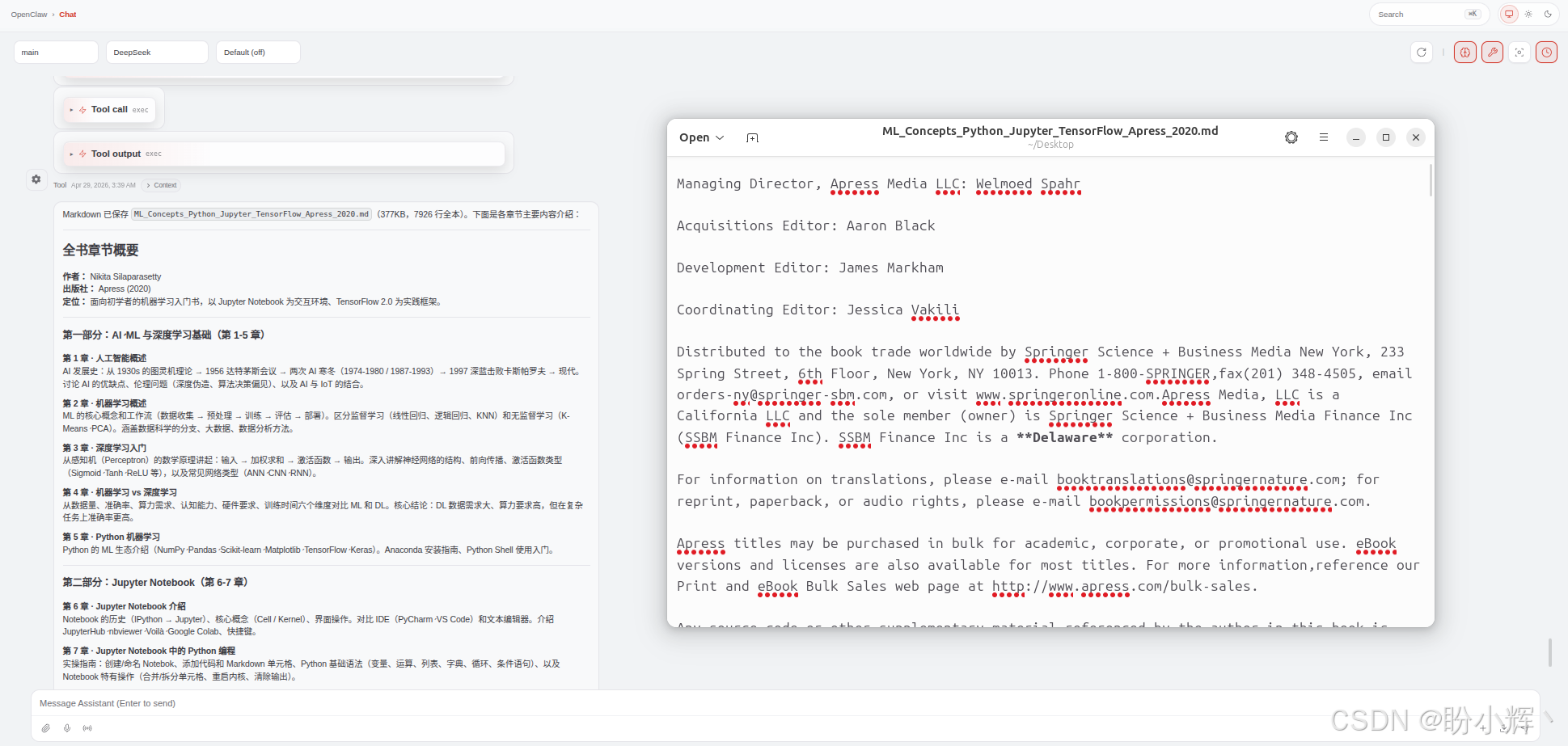
对需要处理大批量文档的企业来说,速度不是锦上添花,而是硬指标。一个每天要处理数千份合同的系统,如果单份解析就要几十秒,不仅拖慢整个管道,还会带来排队积压和超时重试的连锁问题。TextIn xParse 的 1.5 秒/百页,意味着批处理场景完全可行。
4.5 使用感受
经过近期的深度使用,说一个很直观的体验,测试期间,提取一份 80 页的 PDF 行业报告摘要,整个过程,我在对话框里输入的话不超过 10 个字------"解析这份报告,输出摘要"。然后倒杯水的时间,回来 Agent 已经处理完毕,不仅给出了 markdown 文件同时输出了准确的摘要信息。很多"文档解析"工具也强调"简单",但 TextIn xParse 有三个本质不同:
- 没有
API调用负担:不需要关心endpoint、token、参数结构 - 没有数据处理负担:不需要写:清洗逻辑、
chunking、格式转换 - 没有系统集成负担:因为
Skill已经是Agent原生能力
这种体验改变的不是效率,我们也不再需要为"文档解析"这件事预留时间、预留精力、预留调试耐心。它变成了一个可以脱口而出的指令,像让同事帮忙打印一样自然。
小结
Agent 要真正进入生产环境,解决"读文档"问题不是可选项,是必选项,文本理解(LLM)+ 视觉理解(多模态)+ 文档解析(TextIn xParse) 三者组合才构成 Agent 完整的"阅读能力"。TextIn xParse Skill上架 ClawHub,意味着 OpenClaw 生态补齐了这一环。对于开发者来说,多一个开箱即用的 Skill,少一个重复造轮子的理由。对于用户来说,离"跟电脑说话就能干活"的未来,又近了一步。