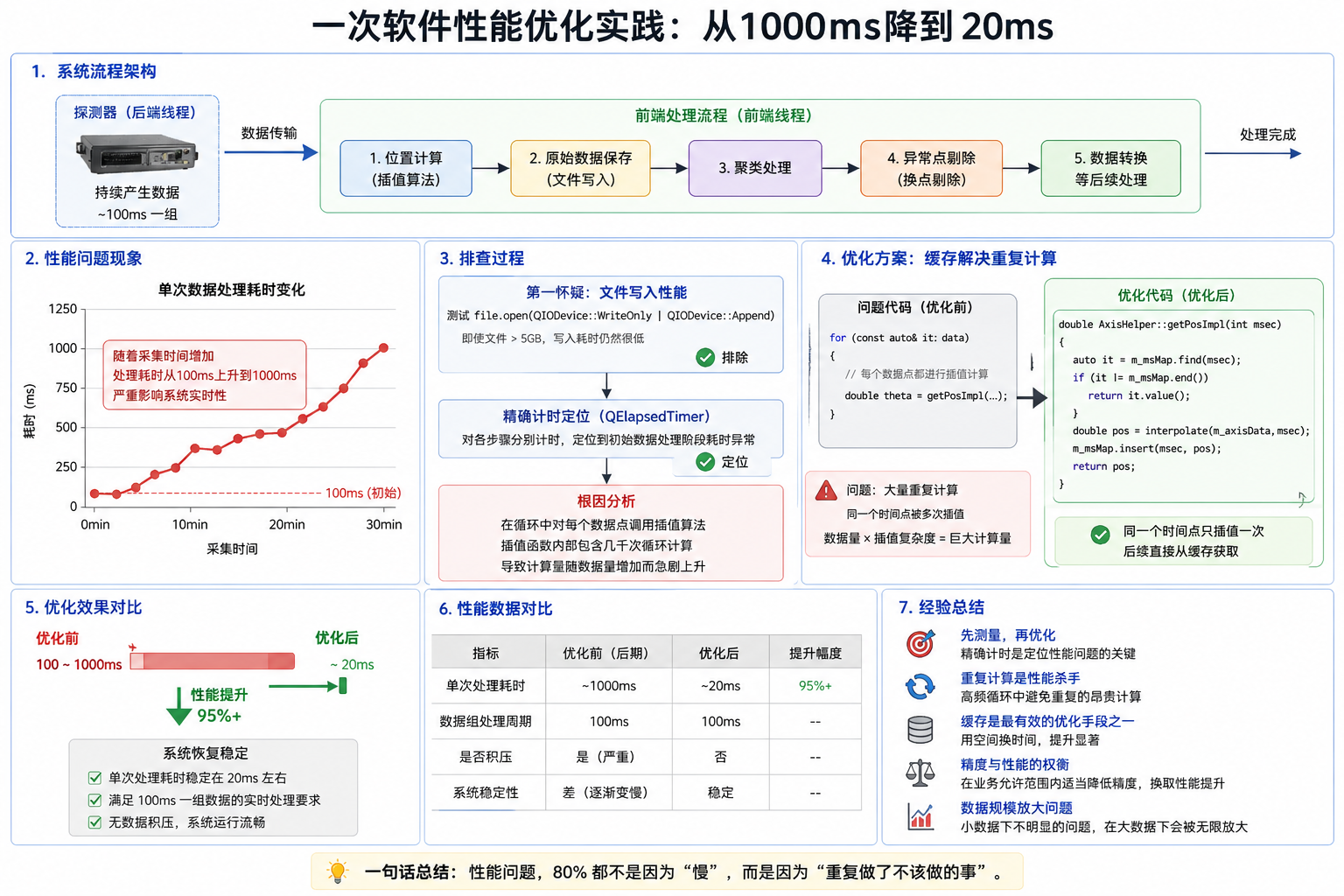
一、背景
在最近的一个项目中,我遇到了一个典型的实时数据处理性能问题。
系统结构大致如下:
- 后端线程:从探测器持续接收数据(约100ms一组)
- 前端线程:对每组数据进行处理,包括:
- 位置计算(插值)
- 原始数据保存
- 聚类处理
- 异常点剔除
- 数据转换
随着采集时间增加到约半小时,系统性能出现明显退化:
- 初始处理耗时:约 50ms / 组
- 后期处理耗时:上升到 2000ms / 组
这直接导致:
❗ 数据处理速度 < 数据产生速度,系统开始积压甚至卡顿
二、问题排查思路
1. 第一怀疑:文件写入性能
由于系统会持续写入数据文件,第一直觉是 I/O 成为瓶颈。
测试代码:
cpp
bool StreamItemHelper::saveStreamItems(const QString &filePath, const QVector<StreamItem> &items)
{
QFile file(filePath);
if (!file.open(QIODevice::WriteOnly | QIODevice::Append))
{
qWarning() << "打开文件失败:" << filePath << file.errorString();
return false;
}
qint64 dataSize = static_cast<qint64>(items.size()) * sizeof(StreamItem);
qint64 written = file.write(reinterpret_cast<const char*>(items.constData()), dataSize);
if (written != dataSize)
{
qWarning() << "写入失败:" << written << "/" << dataSize;
return false;
}
file.close();
return true;
}测试结果:
- 即使文件达到 5GB+
- 每次 append 写入耗时仍然极低
👉 结论:文件写入不是瓶颈
2. 精确计时:定位性能热点
接下来对整个处理流程进行拆分,并使用 QElapsedTimer 做精确计时:
cpp
QElapsedTimer timer;
timer.start();
// 各步骤分别计时逐步定位:
- 文件写入 ✔️ 快
- 聚类处理 ✔️ 正常
- 数据转换 ✔️ 正常
- ❗ 初始数据处理阶段异常慢
三、问题根因分析
最终定位到核心问题:
cpp
for (const auto& it : data)
{
double theta = getPosImpl(...); // 插值计算
}其中:
- 每个数据点都调用一次插值函数
- 插值函数内部包含 几千次循环计算
当数据量较大时(几万级):
text
数据量 × 插值复杂度 = 巨大计算量例如:
text
50000 × 4000 ≈ 2亿次循环 / 批👉 这就是性能急剧下降的根本原因
四、优化思路
核心问题
❗ 大量重复计算(同一个时间点被多次插值)
优化方法:缓存(Cache)
将:
cpp
每个数据点都做插值 ❌改为:
cpp
同一个时间点只插值一次 ✔️优化代码:
cpp
double AxisHelper::getPosImpl(int msec)
{
if(!m_msMap.contains(msec))
{
m_msMap[msec]=interpolate(m_axisData,msec);
}
return m_msMap[msec];
}五、优化效果
优化前:
- 单次处理耗时:50ms → 2000ms(随时间增长恶化)
优化后:
- 单次处理耗时:< 20ms
- 性能提升:99%+
系统恢复:
- ✔ 实时处理能力稳定
- ✔ 无数据积压
- ✔ 满足50ms一组数据的处理要求
六、关键经验总结
1. 先测量,再优化
不要凭感觉优化,一定要:
✔ 精确计时 → 找到真正瓶颈
2. 性能问题往往来自"重复计算"
本次问题本质是:
❗ 在高频循环中重复执行昂贵计算
3. 缓存是最有效的优化手段之一
将:
text
O(N × M)优化为:
text
O(N + M)👉 这是数量级的提升
4. 数据规模一大,问题就变了
在小数据下看不出来的问题:
- 在高频数据流中会被无限放大
七、总结
这次优化的本质不是"代码写得不够快",而是:
👉 做了大量不必要的重复计算
性能优化的核心思维:
text
减少计算次数 > 优化单次计算八、结论
很多性能问题,本质不是"算得不够精确",而是"算得太精确"。当系统规模上来之后,过高的精度反而会成为负担。工程的本质不是追求极致精度,而是在精度、性能和稳定性之间找到平衡。
也正因如此:模糊的正确,好于精确的错误。