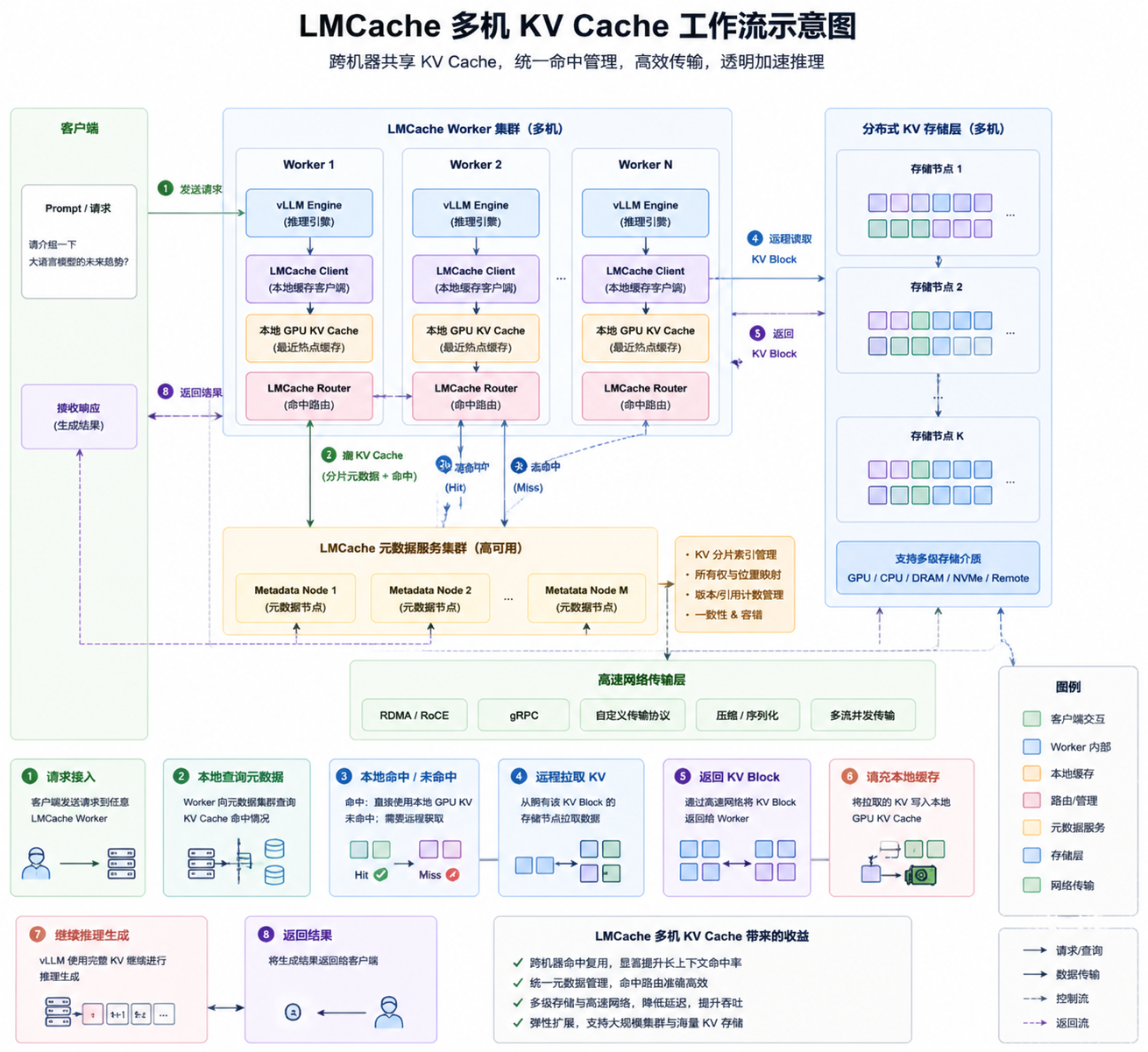
LMCache 原理架构深度解析
在大规模模型推理和多机部署场景下,KV Cache 的管理和共享是实现高性能、高吞吐量推理的核心难题。NVIDIA 提出的 LMCache 系统提供了统一、分布式、跨层次的 KV Cache 管理解决方案,使得推理引擎(如 vLLM、TensorRT-LLM 等)在多节点、多进程环境下高效复用缓存、降低显存压力并提升吞吐量。

本文将从架构、核心组件、存储分层、传输机制以及多节点部署策略几方面进行技术分享。
一、整体架构概览
LMCache 架构可以划分为六大层:
-
应用层(Applications)
支持多种推理引擎和应用,包括 vLLM、SGLang、Hugging Face TGI、TensorRT-LLM 以及自研推理引擎。应用通过统一的 LMCache API 接口访问 KV Cache。
-
集成层(Integrations)
提供 Python API(async/await 异步支持)、C API(高性能)、gRPC / RESTful 接口(远程访问),以及兼容 vLLM 的 PagedAttention 接口,确保不同推理框架能够无缝接入。
-
核心层(Core)
LMCache 核心管理 KV Cache 的生命周期和访问逻辑,包括:
- Cache 管理(Cache Manager):分块管理、索引管理、元数据管理、淘汰策略(LRU / LFU / TTL)、一致性管理。
- KV 编解码(Codec):序列化、压缩、反序列化和校验,确保跨节点传输和多层缓存的一致性。
- 请求路由(Router):支持本地命中(Local Hit)、远程命中(Remote Hit)、未命中(Miss)、写入策略(Write-back / Write-through)。
- 并发控制(Concurrency Control):异步 I/O、请求合并、多版本并发、无锁机制,保证多线程/多进程访问安全且高效。
-
存储层(Storage Tier)
LMCache 提供多层存储抽象,实现 GPU / CPU / NVMe / 远程分布式存储 的统一管理:
- L1 GPU 显存:超高速,适合热 KV 数据。
- L2 CPU 内存:容量中等,适合高频 KV 数据。
- L3 本地 SSD:大容量,持久化 KV。
- L4 远程存储:分布式集群访问,支持跨节点共享 KV 数据。
-
传输层(Transfer Layer)
实现本地和远程数据传输:
- 本地传输:GPU Direct、DLPack、共享内存。
- 远程传输:RDMA / RoCE、gRPC、高性能自定义协议,实现低延迟跨节点 KV Cache 访问。
-
部署架构(Deployment)
支持多种部署模式:
- 单机单进程 / 多进程
- 多机集群部署
- 多云 / VPC 场景
- 弹性扩展支持 RDMA / RoCE 高速网络连接
二、核心技术与优势
1. 分块管理与多层存储
LMCache 采用 KV Block 为单位管理缓存,按需在 GPU / CPU / NVMe / 远程存储间迁移,避免单机显存压力,同时保证热点数据在 GPU 层高速访问。
2. 请求路由与命中策略
系统维护全局 KV Cache 元数据目录,路由器会根据请求上下文:
- 优先访问本地 KV Cache
- 再访问远程节点 KV Block
- 未命中则写入 Cache
这种智能路由策略最大化缓存命中率,减少重复计算。
3. 异步传输与并发控制
LMCache 支持异步 I/O 和请求合并,结合无锁多版本控制(Lock-free / Multi-version),实现高并发场景下的安全访问。GPU 与 CPU / SSD / 远程存储的数据传输可以异步进行,不阻塞推理执行。
4. 编解码与压缩
为了降低传输开销,LMCache 对 KV 数据提供高效序列化和压缩机制(FP8 / FP16 / Zstd),并支持校验保证数据一致性。
5. 跨节点共享
多机部署时,LMCache 提供 统一全局 KV Cache 目录 + 异步传输机制:
- 热门 KV 数据可从远程节点按需拉取
- 支持 Copy-on-Write,实现多节点共享而不冲突
- 可扩展至跨机房 / 云端部署
三、应用场景
LMCache 可广泛应用于以下场景:
- 大模型推理加速:如 vLLM、TensorRT-LLM,支持长上下文、高并发请求。
- 多机 GPU 集群:共享 KV Cache,避免重复计算,提高吞吐量。
- 混合存储环境:GPU + CPU + SSD + 远程存储的多级缓存管理。
- 低延迟在线推理服务:异步、并发控制 + 路由策略确保低延迟响应。
四、总结
LMCache 的设计核心是 "分块 + 多层存储 + 智能路由 + 异步传输",它通过统一 API 接口和全局元数据管理,实现了:
- 高性能 KV Cache 管理
- 跨节点、跨层级共享
- 异步传输与高并发支持
- 灵活扩展到多机、多云场景
可以说,LMCache 为现代大模型推理提供了 分布式、高效、低延迟的 KV Cache 基础设施,是 vLLM 和其他推理引擎的关键底层支撑。