minimind是比较火爆的大模型开源项目,通过该项目能够学习到大模型除训练分词器的全流程:pretrain, sft, LoRA, RLHF, Agentic RL,十分适合想要对大模型进行二次开发做项目的初学者。
本次实验平台为Nvidia 4090*2,显存48G(一共),CPU:32核,镜像:image-gpu-pytorch_20250820,
Ubuntu 22.04.5 LTS,操作系统为Linux。
该实验报告会包括实验运行命令、实验过程数据、实验结果以及代码分析。
实验过程数据已全部公开,请参照:https://swanlab.cn/@tc7dustin?view=list
文章目录
- [1. 源码级掌握端到端大模型+tokenizer](#1. 源码级掌握端到端大模型+tokenizer)
- [2. 预训练](#2. 预训练)
-
-
- [第 1 步:先看 LLM 架构源码](#第 1 步:先看 LLM 架构源码)
- [第 2 步:再看数据集处理(有必要,但很快)](#第 2 步:再看数据集处理(有必要,但很快))
- [第 3 步:看训练主循环(把前面串起来)](#第 3 步:看训练主循环(把前面串起来))
- [第 4 步:跑通后看推理脚本(验证理解)](#第 4 步:跑通后看推理脚本(验证理解))
-
- [3. 有监督微调](#3. 有监督微调)
-
- [1. 数据层:SFTDataset 到底做了什么?](#1. 数据层:SFTDataset 到底做了什么?)
-
- [1.1 数据格式转换](#1.1 数据格式转换)
- [1.2 Label Mask 机制(核心!)](#1.2 Label Mask 机制(核心!))
- [2. 模型层:MiniMindForCausalLM 的 forward](#2. 模型层:MiniMindForCausalLM 的 forward)
-
- [2.1 核心链路](#2.1 核心链路)
- [2.2 SFT 的 loss 计算(第 242-250 行)](#2.2 SFT 的 loss 计算(第 242-250 行))
- [2.3 关键结构细节](#2.3 关键结构细节)
- [3. 训练层:train_full_sft.py 的训练循环](#3. 训练层:train_full_sft.py 的训练循环)
-
- [3.1 与 Pretrain 的差异对比](#3.1 与 Pretrain 的差异对比)
- [3.2 训练技巧(代码里的工程细节)](#3.2 训练技巧(代码里的工程细节))
- [3.3 分布式细节](#3.3 分布式细节)
- [4. 工程层:建议做的小实验](#4. 工程层:建议做的小实验)
- [5. 进阶串联:full_sft 在训练管线中的位置](#5. 进阶串联:full_sft 在训练管线中的位置)
- [4. LoRA](#4. LoRA)
1. 源码级掌握端到端大模型+tokenizer
"身边常有一份Transformer源码",基础很重要。
tokenizer,分词器,是根据分词规则将输入文本分词的工具,分词器需要训练,并且分词器的训练集和测试集最好是通过同一个数据集划分得来。
以本课程的第二次作业《手撕Transformer源码》以及开源项目《从零实现千问3Dense,decoder-only》](https://github.com/Siyuan-Harry/llm-from-scratch)为样例,讲解如何训练分词器。
我们可以到B站up"这就是小c"公开的《CS336课程》腾讯云文档去学习LLM的各个组件,包括基础知识以及代码,但是为了保证自己能建立全局观以及写大模型项目,阅读《零实现千问3Dense》的源码并跟踪数据流要更好。
-
阶段 1:全局把握(10 分钟)
阅读文件: README.md
先了解项目的整体定位、技术特色(RMSNorm、SwiGLU、RoPE、Pre-norm、自定义 AdamW)和架构图。特别留意 Lessons Learned 部分,作者总结了手写时容易踩的坑(数值稳定性、RoPE 缓存、权重内存布局、优化器状态管理),这些都是实战经验。
-
阶段 2:数据输入层 --- Tokenizer(30 分钟)
阅读文件: main/tokenizer_optimized.py、encode_tinystories.py
学习重点:
BPE(Byte Pair Encoding)算法是如何工作的
_bpe() 函数中的贪心合并逻辑:每次找排名最高的 pair 合并
三种工程优化:rank dict O(1) 查询、反向词表、缓存机制
encode() 和 decode() 的完整流程:文本 → 正则切分 → BPE → ID;ID → bytes → 文本
encode_tinystories.py 看如何将原始文本编码为 .bin 二进制文件(使用 np.memmap 省内存)
问自己: 为什么用 latin1 编码存 vocab?为什么 memmap 对大文件训练很重要?
-
阶段 3:模型架构层 --- Transformer 核心(1-2 小时)
阅读文件: main/model.py
| 顺序 | 组件 | 关键学习点 |
|---|---|---|
| 1 | Linear |
手写矩阵乘法,x @ W.T 的原因(PyTorch row-major 内存布局,横着的数据) |
| 2 | Embedding |
查表机制,nn.Parameter 的用法,Embedding:给词表里的每一个Token ID,分配一个长度为d_model的浮点数向量 |
| 3 | RMSNorm |
与 LayerNorm 的区别,为什么更快,epsilon 的数值稳定性 |
| 4 | SwiGLU |
SiLU 激活 + GLU 门控,w1/w2/w3 三个投影矩阵的分工 |
| 5 | RoPE / RoPE_llama |
重点! 旋转位置编码的数学原理(复数旋转),Lazy 自动扩展缓存的工程技巧 |
| 6 | softmax |
手写 softmax,减去最大值防止数值溢出 |
| 7 | scaled_dot_product_attention |
Attention 的完整公式: Q @ K . T / s q r t ( d ) → s o f t m a x → @ V Q@K.T / sqrt(d) → softmax → @V Q@K.T/sqrt(d)→softmax→@V |
| 8 | CausalSelfAttention_RoPE |
Multi-Head 的分割(view + transpose)、因果掩码 torch.tril、RoPE 注入位置信息 |
| 9 | Block |
Pre-normalization 结构:x + attn(norm(x)),这是现代 LLM(Llama/GPT-NeoX)的标准 |
| 10 | Transformer |
整体组装:Embedding → N×Block → RMSNorm → LM Head |
注意区分sigmoid(把数映射到0~1,适用于二分类任务) 和 softmax(把一组实数/通常是一个向量,映射成概率分布,所有输出非负且和为1,适合做多分类任务),以及softmax的数值稳定技巧(实际计算时,先减去最大值,防止指数溢出)。
2. 预训练
第 1 步:先看 LLM 架构源码
文件:model/model_minimind.py
学到了新知识:
- 类属性(类变量),model/model_minimind.py:10-46。MiniMindConfig 继承了 PretrainedConfig → 这是 Hugging Face 所有大模型配置的基类(BERT、GPT、Llama 都用它)。这个基类强制要求:所有自定义模型的配置类,必须定义 model_type。
- Grouped-Query Attention (GQA),在标准多头注意力中:每个 Query 头 独享 一对 Key 和 Value 头。因此 num_key_value_heads = num_attention_heads。例如:8 个 Query 头 → 8 个 Key 头 + 8 个 Value 头。为了在推理时减少 KV cache 的内存占用,并加速解码,GQA 让多个 Query 头 共享同一组 Key 和 Value 头,head_dim = hidden_size / num_attention_heads(即每个头的维度相同),在实现注意力时,Key 和 Value 的投影形状会是,# 形状:batch, seq_len, num_key_value_heads, head_dim。而 Query 的形状是:# 形状:batch, seq_len, num_attention_heads, head_dim。num_key_value_heads 决定 Key/Value 投影的头数,默认 4 意味着采用分组查询注意力(每 2 个 Query 头共享 1 组 KV),这是为了在长上下文场景下节省显存、加速推理的常用设计。
- 学习了从基础RoPE到YaRN并整理发布在线笔记。
- 学习了Hugging face框架里的固定工具,ACT2FN激活函数字典映射表。把字符串名字 → 转换成真正的 PyTorch 激活函数。
- 学习了MiniMindBlock,大模型的一层。注意有两个RMSNorm!。之后就堆叠这个Block,能得到大模型。
输入数据
↓
【保存残差】
↓
归一化 → 【自注意力】(抓上下文)
↓
残差相加
↓
归一化 → 【前馈网络】(提特征)
↓
残差相加
↓
输出数据
模型 = Embedding层 + MiniMindBlock × N层 + 输出层
MiniMindModel
def __init__(self, config: MiniMindConfig):
super().__init__()
self.config = config # 配置文件(所有参数)
# 零件1:词嵌入层 → 把数字token → 转成模型能看懂的向量
self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size)
# 零件2:Dropout → 防止模型死记硬背(过拟合)
self.dropout = nn.Dropout(config.dropout)
# 零件3:核心!堆叠 N 层 Block(比如8层,就是大模型的主体)
self.layers = nn.ModuleList([MiniMindBlock(l, config) for l in range(self.num_hidden_layers)])
# 零件4:最后一层归一化
self.norm = RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
# 零件5:提前算好 RoPE 位置编码的 cos/sin 值
freqs_cos, freqs_sin = precompute_freqs_cis(...)
# 把位置编码存起来(固定值,不用训练)
self.register_buffer("freqs_cos", freqs_cos, persistent=False)
self.register_buffer("freqs_sin", freqs_sin, persistent=False)Pretrain 的本质是训练模型做 next token prediction,必须先知道:
MiniMindConfig:模型超参(hidden_size=768、n_layers=8、vocab_size=6400等)MiniMindForCausalLM.forward():输入input_ids→ 过 Transformer blocks → 输出logits→ 计算cross_entropy loss的完整链路- 关键设计:Pre-Norm + RMSNorm、SwiGLU、RoPE 位置编码、GQA(
q_heads=8, kv_heads=4) - 重点看 loss 计算逻辑 (
labels怎么和logits对齐,pad 为什么用-100忽略)
这是所有训练阶段的地基。看不懂这里,
train_pretrain.py里model(input_ids, labels=labels)就是个黑盒。
第 2 步:再看数据集处理(有必要,但很快)
文件:dataset/lm_dataset.py-37:55 中的 PretrainDataset 类
Pretrain 的数据处理是全项目最简单的,只需要理解:
- 原始数据格式:
{"text": "..."}(pretrain_t2t.jsonl) __getitem__做了什么:tokenize → 加bos/eos→ pad 到max_length→ 构造labels- 核心洞察 :
labels = input_ids.clone(),即模型预测下一个 token;pad 位置用-100让 loss 忽略
数据格式:是一个list,每个元素是一个dict,dict如下(其中随便一行):
{"text": "如何才能摆脱拖延症?治愈拖延症并不容易,但以下建议可能有所帮助。"}
{"text": "清晨的阳光透过窗帘洒进房间,桌上的书页被风轻轻翻动。"}
{"text": "Transformer 通过自注意力机制建模上下文关系,是现代大语言模型的重要基础结构。"}
第 3 步:看训练主循环(把前面串起来)
文件:trainer/train_pretrain.py
现在已经知道模型怎么 forward、数据怎么构造,看训练脚本就是"拼图":
- 学习率调度(
get_lr余弦退火) - 混合精度训练(
autocast+GradScaler) - 梯度累积 + 梯度裁剪
- DDP 分布式包装
- Checkpoint 保存逻辑
这个脚本很标准,真正的"pretrain 知识"其实在前两步已经结束了 。这里更多是工程实现。
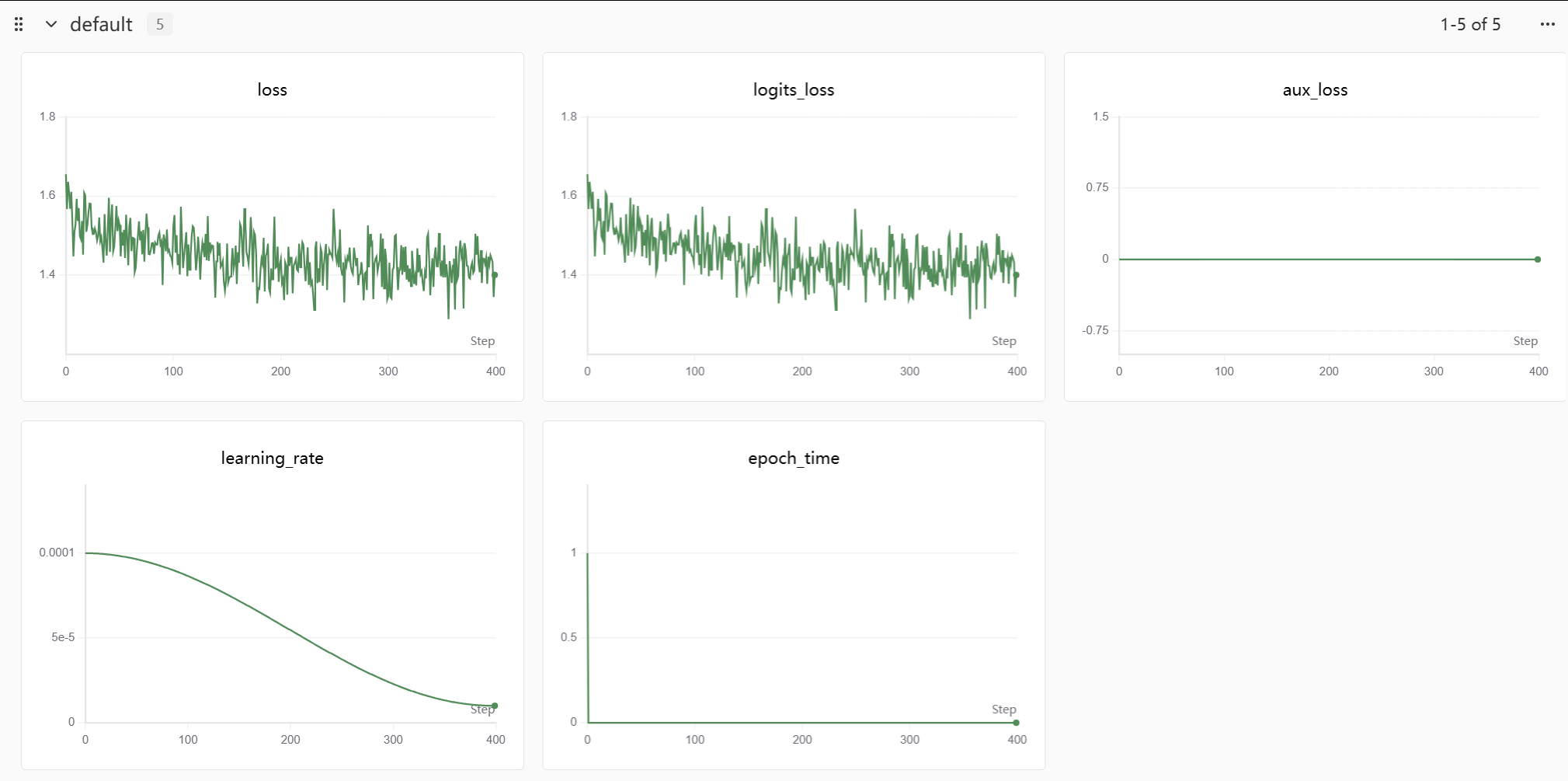
下面是预训练的实验数据与相关图表,这次实验没能记录下GPU运行状态(不知道什么原因)。
训练权重太大,无法上传至github。
第 4 步:跑通后看推理脚本(验证理解)
文件:eval_llm.py
Pretrain 权重不是对话模型,而是"续写模型"。看这里:
if 'pretrain' in args.weight时,输入直接是bos_token + prompt,不走 chat_template- 调用
model.generate()做自回归生成
跑完 pretrain 后用
python eval_llm.py --weight pretrain测试,你会看到模型在做"词语接龙"续写,而不是有格式的对话。这能加深验证对 pretrain 目标的理解。
这部分的代码简单。
3. 有监督微调
学习路线:「数据流 → 模型前向 → 训练细节 → 工程技巧 → 进阶串联」。
sft是:利用问答对数据,训练模型按指令回答问题的能力,只对模型回答的部分进行损失计算。
数据格式:
{
"conversations": [
{"role": "user", "content": "你好"},
{"role": "assistant", "content": "你好!"},
{"role": "user", "content": "再见"},
{"role": "assistant", "content": "再见!"}
]
}
{
"conversations": [
{"role": "system", "content": "# Tools ...", "tools": "[...]"},
{"role": "user", "content": "把'你好世界'翻译成english"},
{"role": "assistant", "content": "", "tool_calls": "[{\"name\":\"translate_text\",\"arguments\":{\"text\":\"你好世界\",\"target_language\":\"english\"}}]"},
{"role": "tool", "content": "{\"translated_text\":\"Hello World\"}"},
{"role": "assistant", "content": "Hello World"}
]
}1. 数据层:SFTDataset 到底做了什么?
这是理解 full_sft 的起点。打开 dataset/lm_dataset.py,重点看 SFTDataset 类:
1.1 数据格式转换
create_chat_prompt():把jsonl里的conversations列表通过tokenizer.apply_chat_template()转成带特殊标记(<|im_start|>、<|im_end|>等)的字符串pre_processing_chat():以 20% 概率给对话加上 system prompt(增加 system prompt 多样性)post_processing_chat():以 80% 概率移除空的<think>\n\n</think>标签(训练"直接回答"的能力)
1.2 Label Mask 机制(核心!)
看 generate_labels() 方法:
python
# 只有 assistant 回复部分参与 loss 计算
# 通过匹配 bos_id=f'{tokenizer.bos_token}assistant\n' 来定位 assistant 回答的起止
# user 部分和特殊标记都被设为 -100(被 cross_entropy ignore)学习建议 :把 __getitem__ 里的调试打印注释取消掉,跑几条样本,亲眼看看 input_ids 和 labels 的对应关系。这是 SFT 和 Pretrain 最本质的区别------Pretrain 所有 token 都算 loss,SFT 只让模型学习"如何回答"。
2. 模型层:MiniMindForCausalLM 的 forward
MiniMindForCausalLM在pretrain时候就学习过了。
打开 model/model_minimind.py,理解一条样本的完整前向路径:
2.1 核心链路
input_ids → embed_tokens → N × MiniMindBlock → RMSNorm → lm_head → logits每个 MiniMindBlock = Attention + SwiGLU FFN (或 MoE)。
2.2 SFT 的 loss 计算(第 242-250 行)
python
logits = self.lm_head(hidden_states[:, slice_indices, :])
loss = F.cross_entropy(x.view(-1, x.size(-1)), y.view(-1), ignore_index=-100)ignore_index=-100配合数据层的 mask,保证只计算 assistant 输出的 lossaux_loss:如果开 MoE,会额外加上 router 的负载均衡 loss(train_full_sft.py第 37 行loss = res.loss + res.aux_loss)
2.3 关键结构细节
建议逐个模块去查资料理解:
| 模块 | 代码位置 | 学习要点 |
|---|---|---|
| RMSNorm | 第 51-61 行 | 与 LayerNorm 的区别,为什么 LLM 都用它 |
| RoPE | precompute_freqs_cis + apply_rotary_pos_emb |
旋转位置编码的数学原理 |
| GQA | repeat_kv |
Grouped Query Attention,减少 KV 缓存 |
| SwiGLU | FeedForward |
为什么用 gate_proj × up_proj 的结构 |
| YaRN | precompute_freqs_cis 里的 rope_scaling |
长文本外推机制 |
3. 训练层:train_full_sft.py 的训练循环
3.1 与 Pretrain 的差异对比
| 维度 | Pretrain (train_pretrain.py) |
Full SFT (train_full_sft.py) |
|---|---|---|
| Dataset | PretrainDataset |
SFTDataset |
| 数据格式 | 纯 text,next token prediction | 多轮对话,只监督 assistant 回复 |
| 学习率 | 通常更高(如 5e-4) | 更低(默认 1e-5) |
| 基座权重 | 通常 from none 或继续预训练 | 默认基于 pretrain 权重继续训练 |
| 目标 | 语言建模 + 知识积累 | 指令跟随 + 对话格式 + 工具调用 |
3.2 训练技巧(代码里的工程细节)
- 混合精度 :
torch.cuda.amp.autocast+GradScaler,默认bfloat16 - 梯度累积 :
accumulation_steps控制,模拟大 batch - 梯度裁剪 :
clip_grad_norm_阈值 1.0,防止 loss spike - 学习率调度 :
get_lr()是余弦退火(cosine decay),不是 warmup + cosine,值得注意 - 续训机制 :
--from_resume 1自动检测checkpoints/full_sft_*_resume.pth,支持换卡数恢复(lm_checkpoint里的saved_ws != current_ws会自动调整 step)
3.3 分布式细节
python
model._ddp_params_and_buffers_to_ignore = {"freqs_cos", "freqs_sin"}
model = DistributedDataParallel(model, device_ids=[local_rank])这里故意忽略了位置编码的 buffer,避免 DDP 同步这些不需要梯度的常量。
4. 工程层:建议做的小实验
光看不练容易忘,建议对着代码做以下动手实验:
- 打印 label mask 可视化 :在
SFTDataset.__getitem__里把input_ids和labels并排打印出来,确认哪些 token 被 mask 掉了 - 对比 Pretrain 和 SFT 的 loss 曲线:同样的数据量,SFT loss 下降快得多(因为监督信号更明确)
- 调整
max_seq_len:看看截断对长对话样本的影响 - MoE vs Dense 对比 :开
--use_moe 1,观察aux_loss的变化和对总 loss 的贡献 - 断点续训测试 :训练到一半
Ctrl+C,再加--from_resume 1重启,验证是否能无缝恢复
5. 进阶串联:full_sft 在训练管线中的位置
理解 full_sft 不能只盯着它自己,要看它在整个后训练(post-training)链路中的角色:
Pretrain(语言模型)
↓
Full SFT(监督微调:对话能力 + 工具调用 + 思考标签)
↓
├─→ LoRA(垂直领域轻量适配)
├─→ Distillation(白盒蒸馏,拟合教师分布)
├─→ DPO(偏好优化,基于 RLHF)
└─→ RLAIF(GRPO/PPO,基于可验证奖励的强化学习)关键认知:
full_sft的权重通常是后续所有训练的基座 (from_weight='full_sft')- 当前
sft_t2t数据已经混入了 Tool Call 样本和 reasoning 数据,所以一轮 SFT 出来后模型同时具备基础对话、工具调用和自适应思考能力 - 如果要做领域定制,要么直接继续
full_sft(数据量够+算力够),要么走LoRA(轻量)
学到了新东西:
- Features(),来自dataset库(HuggingFace),用于显示声明数据集的字段类型和结构。避免加载数据集时候报错。
- .contiguous()和.view()
x = logits..., :-1, : # 4, 1024, 6400 → 4, 1023, 6400 去掉最后一个时间步的预测
y = labels..., 1: # 4, 1024 → 4, 1023 去掉第一个位置的label
错位,对标任务:看到第 i 个 token,预测第 i+1 个 token
tensor 做切片后,内存可能不连续(只是改了指针,没有真正复制数据)。view() 要求内存必须连续,所以要先调 .contiguous() 整理内存。
.view(-1, x.size(-1))
x.view(-1, x.size(-1))
#x 形状: 4, 1023, 6400
x.size(-1) = 6400
-1 表示"自动计算" = 4 * 1023 = 4092
结果形状: 4092, 6400 ← 把 batch 和 seq_len 两个维度压成一个
y.view(-1)
y 形状: 4, 1023
结果形状: 4092 ← 同样压平成一维
为什么要压平? F.cross_entropy 期望输入是 N, C 和 N 的格式(N 个样本,C 个类别),所以把 batch×seq 都当成独立的"样本"。
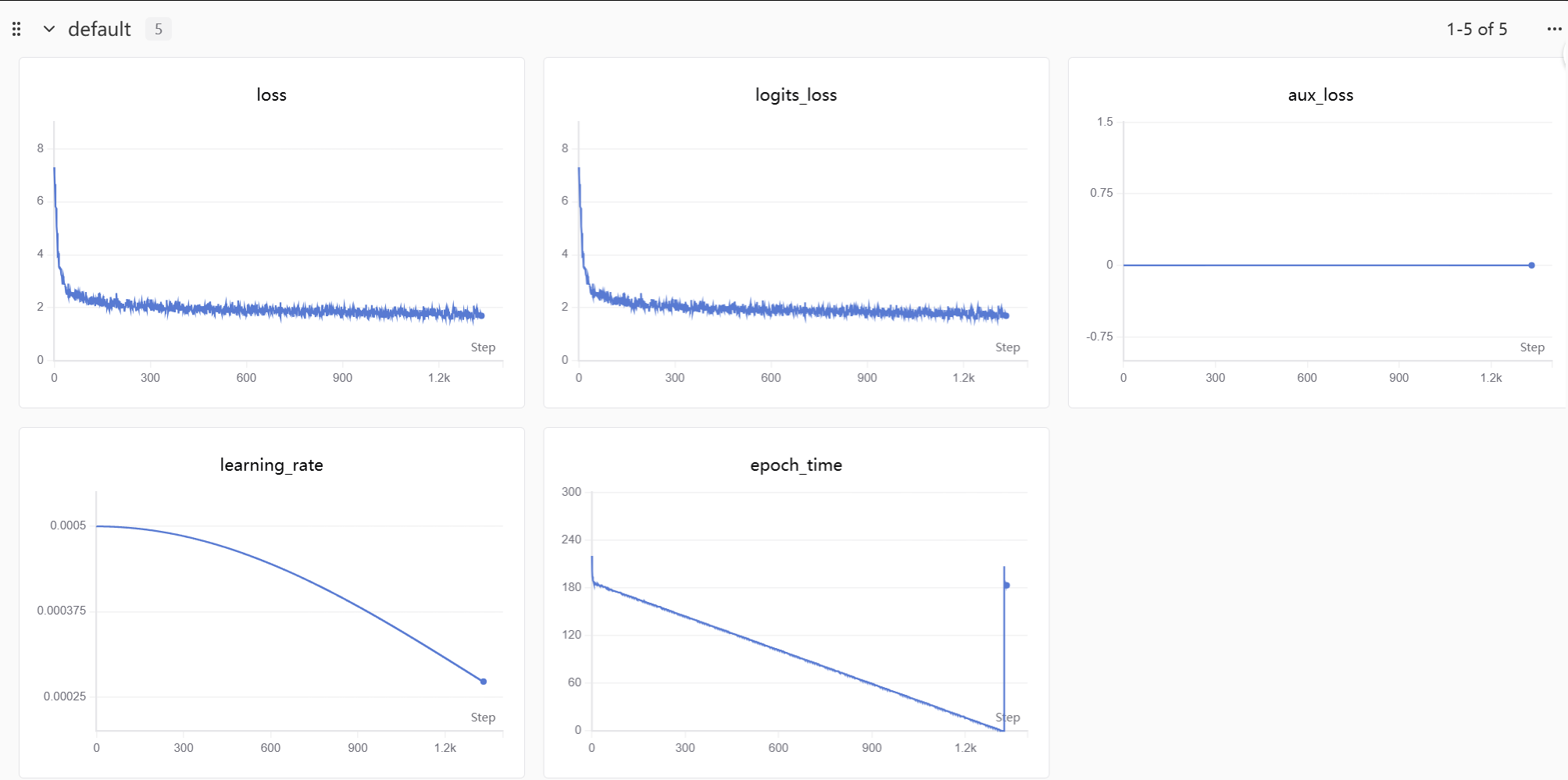
训练数据及图像https://swanlab.cn/@tc7dustin/MiniMind-Full-SFT/overview:
由于监督信号更明确,同样数据量,sft的loss下降比pretrain更快。
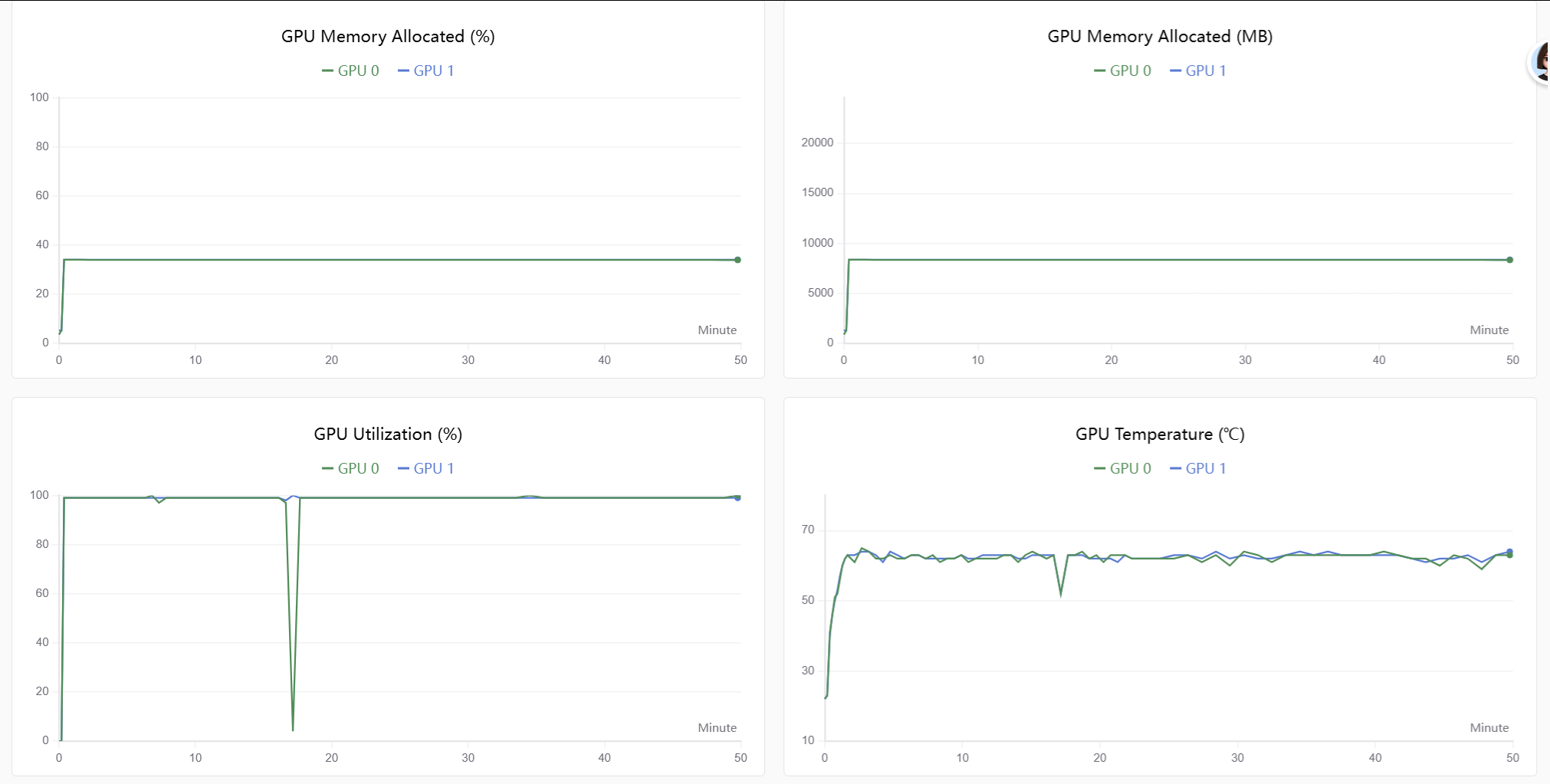
4. LoRA
学代码时候发现这个项目的lora只针对模型里面的方阵参数挂上一个lora,其他注意力层、mlp因为不是方阵参数矩阵,没有参与lora这个过程。未来可以改进,不过更多是工程上的作业。
理论基础:大模型里面有很多线性层y=Wx,如果为了新增能力适应某个任务,重新训练需要修改所有参数,效率低成本高。 y = W x + W l o r a x y = Wx + W_{lora}x y=Wx+Wlorax,冻结原来的模型参数,只训练 W l o r a W{lora} Wlora那部分,问题是当W过大,那么lora和重新训练模型没有区别。所以我们假设新增的能力可以被两个低秩矩阵的乘积表示,对 W l o r a W{lora} Wlora进行低秩分解。
接下来学习项目里的lora,看看它是怎么实现lora的。
这个项目的 LoRA 是:给部分 nn.Linear 旁边外挂一个小分支,只训练这个小分支,原模型权重全部冻结。推理时输出变成:
text
原 Linear 输出 + LoRA 输出
= xW^T + x(A^T B^T)对应代码在 model_lora.py。
1. LoRA 模块
这里定义了两个小矩阵:
python
self.A = nn.Linear(in_features, rank, bias=False)
self.B = nn.Linear(rank, out_features, bias=False)也就是把一个大矩阵增量 ΔW 拆成低秩形式:
text
ΔW = B @ A默认 rank=16,所以如果原来是 768 x 768,全量训练要训约 59 万参数;LoRA 只训:
text
768*16 + 16*768 = 24576少很多。
初始化也很关键:
python
A 正态初始化
B 全 0 初始化所以刚挂上 LoRA 时,B(A(x)) = 0,模型行为一开始完全等于原模型。训练慢慢把 LoRA 分支学起来。
2. LoRA 挂在哪些层
核心在 apply_lora:
python
if isinstance(module, nn.Linear) and module.weight.shape[0] == module.weight.shape[1]:它只给"方阵 Linear"加 LoRA。
在默认 MiniMind 配置里,比较典型会挂到:
text
q_proj: 768 -> 768
o_proj: 768 -> 768默认 num_key_value_heads=4 时,k_proj/v_proj 是 768 -> 384,不是方阵,所以不会挂 LoRA。MLP 的 gate_proj/up_proj/down_proj 通常也不是方阵,也不会挂。
这个实现很教学向:简单、清楚,但不是 PEFT 库那种可配置 target modules 的完整工程版。
3. forward 被"猴子补丁"替换
apply_lora 保存原来的 forward:
python
original_forward = module.forward然后替换成:
python
return layer1(x) + layer2(x)也就是:
text
原层输出 + LoRA分支输出所以原模型结构不用改,直接动态给 Linear 加一个 module.lora 子模块。
4. 训练时只训 LoRA
训练入口在 train_lora.py。
流程是:
text
加载 full_sft 基础模型
apply_lora(model)
统计 LoRA 参数
冻结非 LoRA 参数
optimizer 只接收 lora_params
开始 SFT 风格训练关键代码在 train_lora.py:
python
if 'lora' in name:
param.requires_grad = True
lora_params.append(param)
else:
param.requires_grad = False所以 LoRA 本质还是 SFT,只是更新范围变小了。
数据仍然用 SFTDataset,格式还是:
jsonl
{"conversations":[{"role":"user","content":"..."},{"role":"assistant","content":"..."}]}并且 loss 只打在 assistant 回复部分,用户 prompt 部分 label 是 -100。
5. 保存的不是完整模型
训练保存时调用 save_lora。
它只保存名字里带 .lora. 的参数,例如:
text
model.layers.0.self_attn.q_proj.lora.A.weight
model.layers.0.self_attn.q_proj.lora.B.weight
model.layers.0.self_attn.o_proj.lora.A.weight
model.layers.0.self_attn.o_proj.lora.B.weight
...所以生成的 lora_medical_768.pth 不是一个完整模型,必须配合训练时的基础模型一起用。
6. 推理怎么用
推理入口在 eval_llm.py:
python
apply_lora(model)
load_lora(model, "./out/lora_medical_768.pth")顺序必须是:
text
先加载基础模型 full_sft
再 apply_lora
再 load_lora命令类似:
bash
python eval_llm.py --weight full_sft --lora_weight lora_medical这里 --weight full_sft 要和你训练 LoRA 时的 --from_weight full_sft 对上。
7. 合并 LoRA
合并在 merge_lora:
python
weight += B.weight @ A.weight这一步把 LoRA 增量真的加回原始 Linear 权重里。合并后就不需要 apply_lora/load_lora 了,模型变成普通完整权重。
你可以这样记
LoRA 训练前:
text
base model训练中:
text
base model 冻结
base Linear(x) + lora_B(lora_A(x))
只更新 A/B保存后:
text
只保存 A/B推理时:
text
base model + lora 权重合并后:
text
base weight = base weight + B @ A
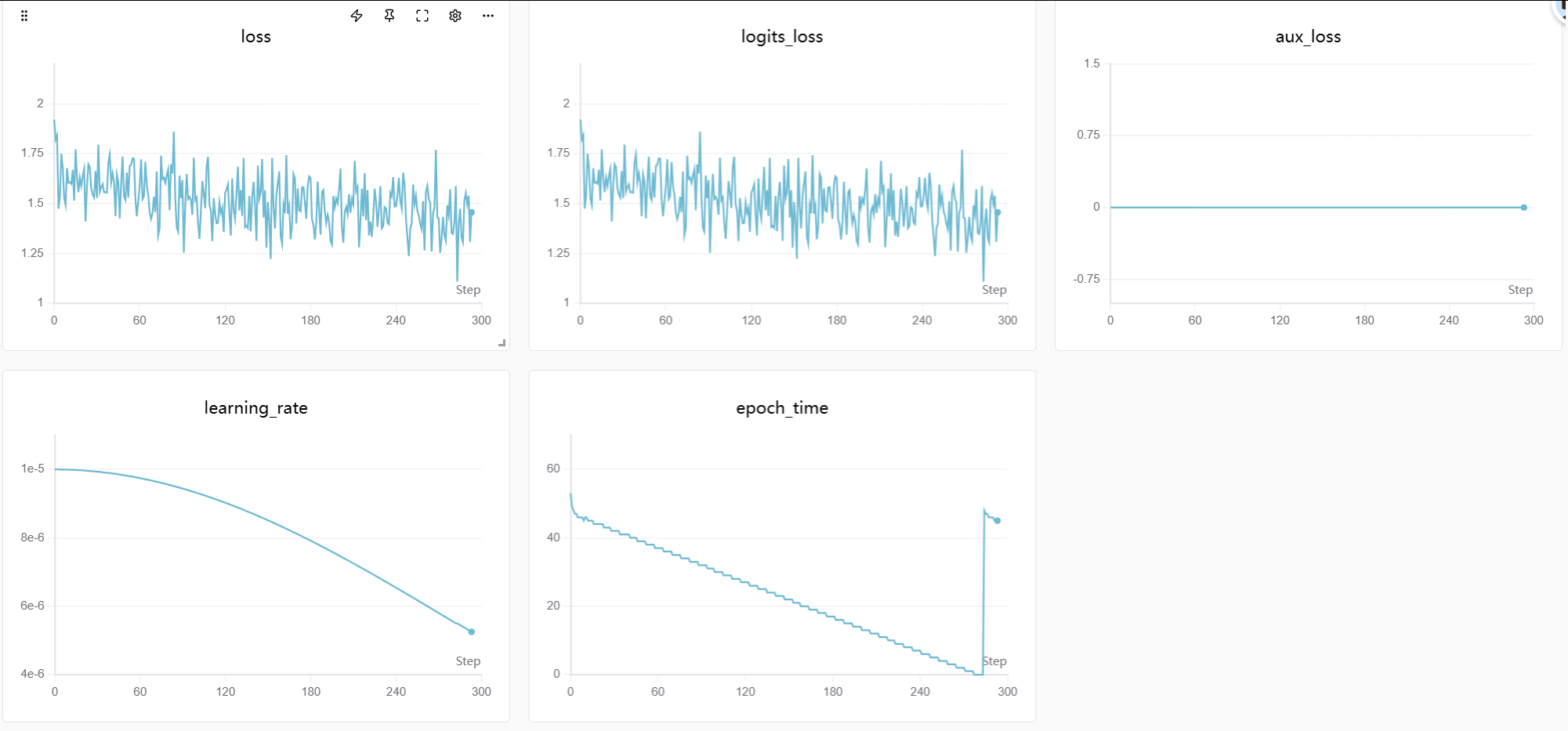
得到一个普通完整模型训练数据和图表https://swanlab.cn/@tc7dustin/MiniMind-LoRA/runs/gcskcm0o0qj4sr0h5hp1q/chart: