第12章(3)------项目十:使用StreamHandler+GenAI+Gemini构建实时音频+视频艺术评论家
-
- [12.5 多模态Gemini模型及其思考模式](#12.5 多模态Gemini模型及其思考模式)
-
- [12.5.1 Gemini模型简介及入门实战](#12.5.1 Gemini模型简介及入门实战)
- [12.5.2 thinking模式:思考预算和思路总结](#12.5.2 thinking模式:思考预算和思路总结)
- [12.6 Gemini Live API:实时音视频连接](#12.6 Gemini Live API:实时音视频连接)
-
- [12.6.1 Live API------功能介绍与实施方案](#12.6.1 Live API——功能介绍与实施方案)
- [12.6.2 GenAI SDK管理Live API连接](#12.6.2 GenAI SDK管理Live API连接)
- [12.6.3 WebSockets API及各项操作](#12.6.3 WebSockets API及各项操作)
-
- [1. WebSockets与Live API](#1. WebSockets与Live API)
- [2. 建立连接并发送文本、音频和视频](#2. 建立连接并发送文本、音频和视频)
- [12.7 项目十:使用StreamHandler+GenAI+Gemini构建实时音频+视频艺术评论家](#12.7 项目十:使用StreamHandler+GenAI+Gemini构建实时音频+视频艺术评论家)
-
- [12.7.1 StreamHandler及其抽象基类](#12.7.1 StreamHandler及其抽象基类)
- [12.7.2 使用StreamHandler进行音视频处理](#12.7.2 使用StreamHandler进行音视频处理)
- [12.7.3 gr.Blocks替换Stream.ui实现自定义界面](#12.7.3 gr.Blocks替换Stream.ui实现自定义界面)
12.5 多模态Gemini模型及其思考模式
在使用FastRTC+Gemini创建实时沉浸式音频+视频演示之前,先了解下Gemini模型及简单功能,还有用于实时传输的Live API。本节先介绍Gemini模型。
12.5.1 Gemini模型简介及入门实战
Gemini系列模型。Gemini是一款由Google DeepMind(Google母公司Alphabet下设立的人工智能实验室)于2023年12月6日发布的人工智能模型,可同时识别文本、图像、音频、视频和代码五种类型信息,还可以理解并生成主流编程语言(如Python、Java、C++)的高质量代码,并拥有全面的安全性评估。首个版本为Gemini 1.0,包括三个不同体量的模型:用于处理"高度复杂任务"的Gemini Ultra、用于处理多个任务的Gemini Nano和用于处理"终端设备特定任务"的Gemini Pro。
2026年2月,Google正式推出新一代人工智能推理模型Gemini 3系列,其典型模型有:最强大的思考型模型Gemini 3.1 Pro、性价比出色且功能全面的Gemini 3 Flash、最具成本效益且支持高吞吐量的模型Gemini 3.1 Flash-Lite。此外,其他各类功能模型还包括:用于图片生成的Nano Banana 2,用于视频生成的Veo 3.1,用于音乐生成的Lyria RealTime,以及用于词嵌入的Gemini Embedding 2。关于Gemini详情请参阅:Gemini Developer API🖇️链接12-10。
安装并提交第一个请求 。首先,申请Gemini API密钥,设置为环境变量GEMINI_API_KEY,或在初始化客户端时将其作为实参传递。然后,安装Google GenAI SDK:google-genai,它支持Python、JavaScript/TypeScript、Go和Java语言。开发者可通过包管理器安装各语言库,或访问其GitHub仓库进行深度参与:googleapis/python-genai🖇️链接12-11。
以下示例使用模型的生成文本generate_content()方法,通过模型Gemini 3 Flash向Gemini API发送请求内容,如代码12-12所示:
代码12-12
py
from google import genai
client = genai.Client()
response = client.models.generate_content(model="gemini-3-flash-preview",
contents="Explain how AI works in a few words")
print(response.text)generate_content()根据输入的GenerateContentRequest生成模型响应,不同模型的输入能力存在差异,详情请查阅官网。
12.5.2 thinking模式:思考预算和思路总结
通过思考预算和思路总结两种方式及其示例,介绍当前流行的thinking模式。
thinking_budget:思考预算。在使用Gemini 2.5 Flash模型时,默认启用"思考"功能,以提高回答质量。thinkingBudget表示用于思考的token数量,一般token数量越多,推理就越细致,这有助于处理更复杂的任务,但会增加响应时间和令牌用量。如果延迟时间更重要,可以使用较低的预算,或将thinkingBudget设置为0来停用思考。当thinkingBudget设置为-1时会开启动态思考,这意味着模型会根据请求的复杂程度调整预算。还是以生成文本为例,thinkingBudget的演示代码12-13所示:
代码12-13 ```py from google import genai from google.genai import types client = genai.Client() response = client.models.generate_content( model="gemini-2.5-flash", contents="Provide a list of 3 famous physicists and their key contributions", config=types.GenerateContentConfig( thinking_config=types.ThinkingConfig(thinking_budget=1024))) print(response.text) ``` 注意:思考功能仅适用于Gemini 2.5系列模型,并且无法在Gemini 2.5 Pro上停用。每种类型模型的thinkingBudget配置详细信息如表12-1所示: 表12-1
| 型号 | 默认设置 | Range | 停用思考 |
|---|---|---|---|
| 2.5 Pro | 动态思考 | 128到32768 | 不适用:无法停用思考 |
| 2.5 Flash | 动态思考 | 0到24576 | thinkingBudget = 0 |
| 2.5 Flash Lite | 不思考 | 512到24576 | thinkingBudget = 0 |
include_thoughts:思路总结。此外,还可以设置includeThoughts启用思路总结,它是模型原始思考的合成版本,可帮助用户深入了解模型的内部推理过程。然后,通过迭代response参数的parts并检查其thought布尔值来访问它的文本摘要。
以下示例展示了在流式传输的情况下启用和检索思路总结,该功能可在生成期间返回滚动式增量摘要,如代码12-14所示:
代码12-14
py
from google import genai
from google.genai import types
client = genai.Client()
prompt = "What is the sum of the first 50 prime numbers?"
thoughts = ""
answer = ""
for chunk in client.models.generate_content_stream(
model="gemini-3-flash-preview",
contents=prompt,
config=types.GenerateContentConfig(
thinking_config=types.ThinkingConfig(
include_thoughts=True))):
for part in chunk.candidates[0].content.parts:
if not part.text:
continue
elif part.thought:
if not thoughts:
print("Thoughts summary:")
print(part.text)
thoughts += part.text
else:
if not answer:
print("Answer:")
print(part.text)
answer += part.text此外,还可以不使用流式思考,该方法会在返回单个响应的最终思路总结,请参考官方资料。除了thinking_budget和include_thoughts,还有控制思维推理力度的参数thinking_level、平衡创造力与确定性的参数temperature(0~1)。
除了生成文本和思考模式,Gemini系列模型的核心功能还包括图片生成、语音生成、长上下文、结构化输出、文档图片及音视频理解、函数调用等,还有工具类:Google搜索types.GoogleSearch()、代码执行types.ToolCodeExecution与网址上下文types.UrlContext等,详情参阅官网。
12.6 Gemini Live API:实时音视频连接
本节介绍Gemini Live API实时音视频连接,包括Live API介绍及两种实施方案详解:GenAI SDK及WebSockets API。
12.6.1 Live API------功能介绍与实施方案
Live API技术与功能介绍。对应当前热门的实时功能OpenAI的GPT-Realtime,Gemini也有自己的实时接口:Live API。它通过WebSocket与Gemini模型进行低延迟的实时双向交互,支持连续的音频、视频和文本输入及本地音频输出,以提供即时、类似人类的语音回答,打造自然对话体验。Live API与App的交互如图12-6所示:

图12-6
Live API提供了一整套全面的功能,例如语音活动检测、原生音频功能、工具使用和函数调用、会话管理(用于管理长时间运行的对话)和临时令牌(用于安全的客户端身份验证),详细信息请参阅:Get started with Live API🖇️链接12-12。在集成Live API时,有两种实施方案可选:
- Server-To-Server模式:用户后端通过WebSockets连接Live API。由用户客户端将流数据(音频、视频、文本)发送至服务器,再由服务器转发至Live API。使用Python后端,通过GenAI SDK连接Live API构建实时多模态应用。
- Client-To-Server模式:用户前端代码直接通过WebSockets连接Live API进行数据流传输,无需经由后端中转。使用JavaScript前端和临时令牌,通过WebSockets连接Live API构建实时多模态应用。
Client-To-Server模式在流传输音频和视频时通常设置简便且性能更佳,因为无需实现由客户端到后端服务器、再由服务器转至Live API的代理。注意:为降低生产环境安全风险,建议使用临时令牌(Ephemeral tokens)而非密钥,详情请参阅官网。
12.6.2 GenAI SDK管理Live API连接
Gemini Live API使用WebSockets进行实时通信。Google Gen AI SDK 🖇️链接12-13提供了一个高级异步接口来管理Live API中的连接。其关键概念有:
- 会话(Session):与模型建立的持久连接。
- 配置(Config):设置模态(音频/文本)、语音和系统指令。
- 实时输入(Real-time Input):以二进制大对象(blob)形式发送音频和视频帧。
Live API还支持实时发送视频、发送及接受文本、文本转录等。演示如何读取WAV文件,以正确格式发送音频,并将接收数据保存为WAV文件,如代码12-15所示:
代码12-15
py
# Test file: https://storage.googleapis.com/generativeai-downloads/data/16000.wav
import asyncio
import io
from pathlib import Path
import wave
from google import genai
from google.genai import types
import soundfile as sf
import librosa
Import uuid
client = genai.Client()
model = "gemini-2.5-flash-native-audio-preview-12-2025"
config = {"response_modalities": ["AUDIO"]}
async def main():
async with client.aio.live.connect(model=model, config=config) as session:
buffer = io.BytesIO()
y, sr = librosa.load("input.wav", sr=16000)
sf.write(buffer, y, sr, format='RAW', subtype='PCM_16')
buffer.seek(0)
audio_bytes = buffer.read()
# If already in correct format, you can use this:
# audio_bytes = Path("sample.pcm").read_bytes()
await session.send_realtime_input(audio=types.Blob(data=audio_bytes,
mime_type="audio/pcm;rate=16000"))
wf = wave.open(f"output_{uuid.uuid4()}.wav", "wb")
wf.setnchannels(1) # mono
wf.setsampwidth(2) # 16 bit sampling
wf.setframerate(24000) # Output is 24kHz
async for response in session.receive():
if response.server_content and response.server_content.model_turn:
for part in response.server_content.model_turn.parts:
if part.inline_data:
audio_data = part.inline_data.data
wf.writeframes(audio_data)
wf.close()
if __name__ == "__main__":
asyncio.run(main())这段代码实现了一个异步音频处理流程,用于收发实时音频流,详细解析:
- 异步上下文管理。使用异步上下文管理器建立与Live API服务器的实时直连,model指定模型,config将响应模态设置为AUDIO来接收音频。
- 音频输入处理。首先通过io.BytesIO()初始化二进制内存缓冲区,用于临时存储音频数据。然后使用librosa.load加载本地WAV文件,并强制重采样到16kHz(语音处理的常用采样率)。最后使用sf.write将音频数据转为RAW格式(PCM_16编码)字节流,存入内存缓冲区buffer。
- 实时音频发送。首先重置缓冲区指针到起始位置,读取缓冲区中的全部音频字节数据。然后将音频数据封装为Blob对象,明确声明MIME类型为16kHz的PCM格式。最后通过异步调用发送到Live API服务端。
- 输出文件配置。以二进制读写模式打开WAV文件,配置为单声道、标准CD的16位采样深度、常用24kHz采样率。为防止文件覆盖,由UUID产生随机文件名。
- 异步迭代接收响应。异步生成器session.receive()持续返回音频块,检查响应是否包含服务器内容和模型返回的对话回合,遍历对话回合中的各个部分(一个回合可能包含文本、音频等多个部分),检查是否有内联数据(音频数据),最后提取音频二进制数据并写入WAV文件。
12.6.3 WebSockets API及各项操作
Live API底层使用的是WebSockets进行连接。本节将介绍WebSockets API概念及功能、Live API连接时的会话配置、发送与接收操作及消息类型。
1. WebSockets与Live API
WebSocket(🖇️链接12-14 )是一种计算机通信协议,通过简单TCP连接提供全双工通信通道,于2011年被IETF(Internet Engineering Task Force,互联网工程任务组)标准化为RFC 6455(🖇️链接12-15)。当前批准Web应用程序使用此协议的规范称为WebSockets,这是由WHATWG(Web Hypertext Application Technology Working Group,Web超文本应用技术工作组)维护的现行标准,也是W3C(World Wide Web Consortium,万维网联盟)的WebSocket API的继任者。
WebSocket协议不同于被大多数网页使用的HTTP协议。RFC 6455规定WebSocket"工作在HTTP 443和80端口,并支持HTTP代理及中介设备",因此尽管存在差异,但WebSocket协议与HTTP保持兼容。为实现兼容性,WebSocket握手过程中,使用HTTP Upgrade报头将HTTP协议切换至WebSocket协议。
Live API是一种使用WebSockets的有状态API,WebSocket连接会在客户端和Gemini服务器之间建立会话。客户端发起新连接后与服务器交换消息,执行操作:
- 发送文本、音频或视频到Gemini服务器。
- 接收来自Gemini服务器的音频、文本或函数调用请求。
如何使用原生WebSocket直接与API集成呢?Gemini Live API的答案是使用WebSockets进行实时通信。与使用SDK不同,这种方式需要直接管理WebSocket连接,并按照API定义的特定JSON格式发送和接收消息。关键概念:
- WebSocket端点:要连接的特定URL。
- 消息格式:所有通信均通过符合LiveSessionRequest和LiveSessionResponse结构的JSON消息完成。
- 会话管理:用户负责维护WebSocket连接。
2. 建立连接并发送文本、音频和视频
建立连接 。有两种方法进行身份验证:
(1)API密钥:通过在WebSocket URL中将API密钥传入来处理身份验证,格式如下:
bash
wss://generativelanguage.googleapis.com/ws/google.ai.generativelanguage.v1beta.GenerativeService.BidiGenerateContent?key=YOUR_API_KEY(2)临时令牌:使用临时令牌进行身份验证,则需要连接到v1alpha端点。临时令牌需要作为access_token查询参数传入。临时密钥的端点格式如下:
bash
wss://generativelanguage.googleapis.com/ws/google.ai.generativelanguage.v1alpha.GenerativeService.BidiGenerateContentConstrained?access_token={short-lived-token}要启动实时会话,请建立与经过身份验证的端点的WebSocket连接。通过WebSocket发送的第一条消息必须是包含config的LiveSessionRequest。WebSockets连接Live API,如代码12-16所示:
代码12-16
py
import asyncio
import websockets
import json
API_KEY = "YOUR_API_KEY"
MODEL_NAME = "gemini-2.5-flash-native-audio-preview-12-2025"
WS_URL = f"wss://generativelanguage.googleapis.com/ws/google.ai.generativelanguage.v1beta.GenerativeService.BidiGenerateContent?key={API_KEY}"
async def connect_and_configure():
async with websockets.connect(WS_URL) as websocket:
print("WebSocket Connected")
config_message = {
"config": {
"model": f"models/{MODEL_NAME}",
"responseModalities": ["AUDIO"],
"systemInstruction": {
"parts": [{"text": "You are a helpful assistant."}]}}}
await websocket.send(json.dumps(config_message))
print("Configuration sent")
await asyncio.sleep(3600) # Keep the session alive for further interactions
async def main():
await connect_and_configure()
if __name__ == "__main__":
asyncio.run(main())发送文本:要发送文本输入,请构建一个LiveSessionRequest对象,并填充其 realtimeInput 字段为文本内容,如代码12-17所示:
代码12-17
py
# Inside the websocket context
async def send_text(websocket, text):
text_message = {
"realtimeInput": {
"text": text
}
}
await websocket.send(json.dumps(text_message))
print(f"Sent text: {text}")发送音频:音频需要以原始PCM数据格式发送(原始 16 位 PCM 音频,16kHz,小端序)。构建一个LiveSessionRequest对象,在realtimeInput字段中包含一个带有音频数据的Blob对象。mimeType字段至关重要。如代码12-18所示:
代码12-18
py
# Inside the websocket context
async def send_audio_chunk(websocket, chunk_bytes):
import base64
encoded_data = base64.b64encode(chunk_bytes).decode('utf-8')
audio_message = {
"realtimeInput": {
"audio": {
"data": encoded_data,
"mimeType": "audio/pcm;rate=16000"
}
}
}
await websocket.send(json.dumps(audio_message))发送视频:视频帧以单张图像的形式发送(例如JPEG或PNG)。与音频类似,使用realtimeInput配合Blob对象,并指定正确的mimeType。如代码12-19所示:
代码12-19
py
# Inside the websocket context
async def send_video_frame(websocket, frame_bytes, mime_type="image/jpeg"):
import base64
encoded_data = base64.b64encode(frame_bytes).decode('utf-8')
video_message = {
"realtimeInput": {
"video": {
"data": encoded_data,
"mimeType": mime_type
}
}
}
await websocket.send(json.dumps(video_message))Live API还可以处理大模型返回的响应并可调用工具:
- 处理响应:WebSocket将返回LiveSessionResponse消息,解析这些JSON消息,并处理不同类型的内容。
- 处理工具调用:当模型请求调用工具时,LiveSessionResponse会包含一个 toolCall 字段。用户必须在本地执行该函数,并使用包含toolResponse字段的LiveSessionRequest将结果发送回WebSocket。
12.7 项目十:使用StreamHandler+GenAI+Gemini构建实时音频+视频艺术评论家
作为对本章知识的总结,本节将实现一个综合演示:让Gemini扮演艺术评论家,对用户通过FastRTC上传的艺术作品进行点评。本演示将完成以下工作:
- 建立网络摄像头和麦克风数据流式传输至Gemini的实时会话。
- 定期发送视频帧(及可选上传图像)至模型。
- 实时流式返回模型的音频响应。
- 创建精美的全屏Gradio WebRTC用户界面。
12.7.1 StreamHandler及其抽象基类
流处理器的各个抽象类定义了FastRTC中处理音频和视频流的核心接口,像ReplyOnPause这样的具体处理器都继承自这些基类。StreamHandlerBase类是用于处理FastRTC中媒体流的基类,该类提供用于管理流状态、通信通道和基本配置的通用属性和方法,这些属性和方法由具体的流处理器进行子类化。StreamHandlerBase中的抽象方法包括:send_message、reset、shutdown等。包含的典型属性如下:
bash
StreamHandlerBase(
expected_layout: Literal["mono", "stereo"] = "mono",
output_sample_rate: int = 24000,
input_sample_rate: int = 48000,
latest_args: str \| list[Any] = None,
phone_mode: bool = False,
...
)StreamHandler从StreamHandlerBase继承属性和方法,定义了处理音频流的核心同步接口,必须实现接收、发送和复制等方法。另外在子类化时,根据需要实现基类的其他抽象方法,比如StreamHandler中的receive、emit、copy、start_up等,AsyncAudioVideoStreamHandler中的video_receive、vedio_emit、copy等。这些抽象函数会被流处理器中的相应事件自动触发,例如音频收发自动触发receive和emit,视频收发自动触发video_receive和vedio_emit。艺术评论家项目中将详细展示如何使用这些抽象函数。更多信息请参考🖇️链接12-16
开始之前,需已安装Python>=3.10并获取GEMINI_API_KEY,安装以下依赖:
bash
pip install "fastrtc[vad, tts]" gradio google-genai python-dotenv websockets pillow12.7.2 使用StreamHandler进行音视频处理
本小节先讲述音频和图像编码器,然后详解GeminiHandler对象的音视频实时发送与接受处理逻辑,最后设置fastrtc.Stream并启动其UI进行展示。
音频和图像编码器。编码器将音频转换为base64编码数据,将图像转换为base64编码的JPEG格式,转换方法如代码12-20所示:
代码12-20
py
import base64
import numpy as np
from io import BytesIO
from PIL import Image
def encode_audio(data: np.ndarray) -> dict:
"""Encode audio data (int16 mono) for Gemini."""
return {
"mime_type": "audio/pcm",
"data": base64.b64encode(data.tobytes()).decode("UTF-8"),
}
def encode_image(data: np.ndarray) -> dict:
with BytesIO() as output_bytes:
pil_image = Image.fromarray(data)
pil_image.save(output_bytes, "JPEG")
bytes_data = output_bytes.getvalue()
base64_str = str(base64.b64encode(bytes_data), "utf-8")
return {"mime_type": "image/jpeg", "data": base64_str}这段代码包含两个函数,分别用于音频和图像数据的编码处理,解读如下:
- encode_audio:接收int16格式的单声道音频numpy数组,将音频数据转换为字节流并解码为UTF-8格式,然后进行base64编码,最后返回包含pcm类型和编码数据的字典。输出格式适用于Gemini系统。
- encode_image:首先,使用BytesIO创建内存中的字节缓冲区,with语句确保资源自动释放,无需手动关闭;然后,将NumPy数组转换为PIL图像对象,将PIL图像保存到内存缓冲区,格式指定为JPEG(有损压缩);第三,从BytesIO缓冲区获取JPEG编码后的完整字节数据,此时bytes_data是二进制JPEG数据;第四,将二进制数据编码为Base64字节对象并转换为UTF-8字符串;最后返回标准化的字典格式,指明数据类型为JPEG图像,携带Base64编码的图像数据。
两个函数都实现了将原始二进制数据转换为base64编码字符串的功能,并附带相应的MIME类型信息,这种编码方式常用于网络传输或API交互场景。音频处理保持原始PCM格式,而图像处理则转换为JPEG格式进行压缩。
GeminiHandler:异步实时音视频发送与接受。如代码12-21所示:
代码12-21
py
class GeminiHandler(AsyncAudioVideoStreamHandler):
def __init__(
self,
) -> None:
super().__init__("mono",
output_sample_rate=24000,
input_sample_rate=16000)
self.audio_queue = asyncio.Queue()
self.video_queue = asyncio.Queue()
self.session = None
self.last_frame_time = 0
self.quit = asyncio.Event()
def copy(self) -> "GeminiHandler":
return GeminiHandler()
async def start_up(self):
await self.wait_for_args()
# fastrtc 参数顺序可能随版本变化;从尾部读取最稳妥
if len(self.latest_args) < 2:
raise WebRTCError("Gemini API key and HF Token are required")
gemini_api_key = self.latest_args[-2]
hf_token = self.latest_args[-1]
if not isinstance(gemini_api_key, str) or not gemini_api_key.strip():
raise WebRTCError("Gemini API key is required")
if not isinstance(hf_token, str) or not hf_token.strip():
raise WebRTCError("HF Token is required")
os.environ["HF_TOKEN"] = hf_token
client = genai.Client(api_key=gemini_api_key.strip(),
http_options={"api_version": "v1alpha"})
config = {"response_modalities": ["AUDIO"], "system_instruction": "You are an art critic that will critique the artwork passed in as an image to the user. Critique the artwork in a funny and lighthearted way. Be concise and to the point. Be friendly and engaging. Be helpful and informative. Be funny and lighthearted. Be concise and to the point. Be friendly and engaging."}
async with client.aio.live.connect(model="gemini-3.1-flash-live-preview",
config=config,
) as session:
self.session = session
while not self.quit.is_set():
turn = self.session.receive()
try:
async for response in turn:
if data := response.data:
audio = np.frombuffer(data, dtype=np.int16).reshape(1, -1)
self.audio_queue.put_nowait(audio)
except websockets.exceptions.ConnectionClosedOK:
print("connection closed")
break
async def video_receive(self, frame: np.ndarray): # receive from user, send to server
self.video_queue.put_nowait(frame)
if self.session:
if time.time() - self.last_frame_time > 1: # send image every 1 second
self.last_frame_time = time.time()
await self.session.send_realtime_input(video=encode_image(frame))
# additional_inputs倒数第三项是可选上传图片(若存在且类型正确)
img = self.latest_args[-3] if len(self.latest_args) >= 3 else None
if isinstance(img, np.ndarray):
await self.session.send_realtime_input(video=encode_image(img))
async def video_emit(self): # receive from server, send to user
frame = await wait_for_item(self.video_queue, 0.01)
if frame is not None:
return frame
else:
return np.zeros((100, 100, 3), dtype=np.uint8)
async def receive(self, frame: tuple[int, np.ndarray]) -> None: # receive from user
_, array = frame
array = array.squeeze()
audio_message = encode_audio(array)
if self.session:
await self.session.send_realtime_input(audio=audio_message)
async def emit(self): # send to user
array = await wait_for_item(self.audio_queue, 0.01)
if array is not None:
return (self.output_sample_rate, array)
return array
async def shutdown(self) -> None:
if self.session:
self.quit.set()
await self.session.close()
self.quit.clear()该类GeminiHandler继承自AsyncAudioVideoStreamHandler,实现了一个基于WebRTC的实时音视频双向流传输系统,通过Gemini Live API使用Gemini模型进行艺术评论(图像分析)和对话处理。详细解析如下:
(1)init(self)方法。初始化类参数,继承自FastRTC的异步音视频处理器。①采样率配置:支持16kHz输入/24kHz输出的单声道音频流转换。②音频队列和视频队列:asyncio非阻塞IO操作,用于异步数据交换。③quit事件:传输关闭控制。
(2)start_up启动流程。①读取参数:latest_args包含WebRTC连接参数,索引3和4分别存储API密钥和HF_TOKEN;②初始化客户端:会话配置API版本为v1alpha(支持实时流),config设置纯音频响应模式并让模型扮演艺术评论家角色;③实时通信循环:异步上下文管理器管理WebSocket连接,持续接收Gemini的响应,将音频数据转换为NumPy数组并放入音频队列以便播放。
(3)视频处理流程。①视频发送:接收摄像头视频流图像帧并保存,每秒最多发送1帧(避免API过载),将帧编码为Base64,支持同时发送实时视频帧和预上传图像;②视频发送:从视频队列等待获取视频帧输出(含空帧处理)并返回,超时后返回黑帧(避免卡顿)。注意:摄像头的视频帧直接返回并显示,而Gemini Live API只返回评论视频帧和图像帧的音频流。
(4)音频处理流程。①音频输入:接收来自WebRTC的麦克风音频,压缩维度后编码为Gemini可接受的格式并实时发送到Gemini会话;②音频输出,从队列获取Gemini生成的音频,返回(采样率, 音频数据)元组供WebRTC播放给用户。两个函数通过队列缓冲处理音频数据,最终实现音频流的双向传输。
运行流程:系统在初始化时加载环境变量,然后建立与Gemini API Live服务器的长连接并循环处理音视频数据流:每秒发送一帧视频和预上传图像进行分析,并实时双向传输音频,最后再关闭时清理会话资源。
这个系统的GeminiHandler类的大模型版本可替换,支持自定义系统指令,其模块化的队列设计非常便于扩展。它除了用于AI艺术批评助手,还可以改造成其他的结合视觉和语音的多模态应用,例如视频会议AI助手、实时翻译系统。
设置流媒体fastrtc.Stream对象并启动UI。在WebRTC组件的额外输入中添加gr.Image输入组件,预处理程序可通过self.latest_argsindex访问该图像。fastrtc的Stream对象如代码12-22所示:
代码12-22
py
import gradio as gr
from fastrtc import Stream, get_hf_turn_credentials
stream = Stream(handler=GeminiHandler(),
modality="audio-video", mode="send-receive",
server_rtc_configuration=get_cloudflare_turn_credentials(ttl=600*10000),
rtc_configuration=get_cloudflare_turn_credentials(), # 本地客户端webrtc配置
additional_inputs=[
gr.Markdown("## 🎨 Art Critic\n\n"
"Provide an image of your artwork or hold it up to the webcam, and Gemini will critique it for you."),
gr.Image(label="Artwork",
value="zhou.png", type="numpy",
sources=["upload", "clipboard"]),
gr.Textbox(label="Gemini API Key", type="password"),
gr.Textbox(label="HF Token", type="password"),
],
ui_args={"icon": "https://www.gstatic.com/lamda/images/gemini_favicon_f069958c85030456e93de685481c559f160ea06b.png",
"pulse_color": "rgb(255, 255, 255)",
"icon_button_color": "rgb(255, 255, 255)",
"title": "Gemini Audio Video Chat",},
time_limit=90, concurrency_limit=5)
if __name__ == "__main__":
stream.ui.launch()代码使用Gradio和FastRTC框架构建了一个Web界面,用于启动和部署Gemini实时音视频聊天应用,核心功能有:
(1)Stream配置。首先关联之前定义的GeminiHandler实例,然后支持音视频双向通信模式,最后设置服务器端TURN和客户端TURN。需设置HF_TOKEN,作为临时秘钥使用Cloudflare TURN服务器穿透防火墙和NAT,确保WebRTC连接稳定,10小时(600*10000毫秒)的凭证有效期确保长时会话稳定性。
(2)额外界面输入组件。包括Markdown说明文档(索引0)、图像上传组件(索引1)、API密钥输入 (索引2)和HF令牌输入 (索引3)。通过密码框保护API密钥,符合敏感信息处理规范。
(3)UI样式配置,包括Gemini图标、脉冲动画颜色、图标按钮颜色及窗口标题。
(4)性能限制,包括单次会话最长90秒和最大并发连接数5,控制服务器负载。
将自己的艺术作品手持或上传,就能与艺术评论家就作品展开讨论。这个界面结合WebRTC+P2P通信减少中间环节延迟,将复杂的WebRTC和AI集成封装成简单的用户界面,使非技术用户也能轻松使用实时多模态AI应用。运行效果如图12-7所示:
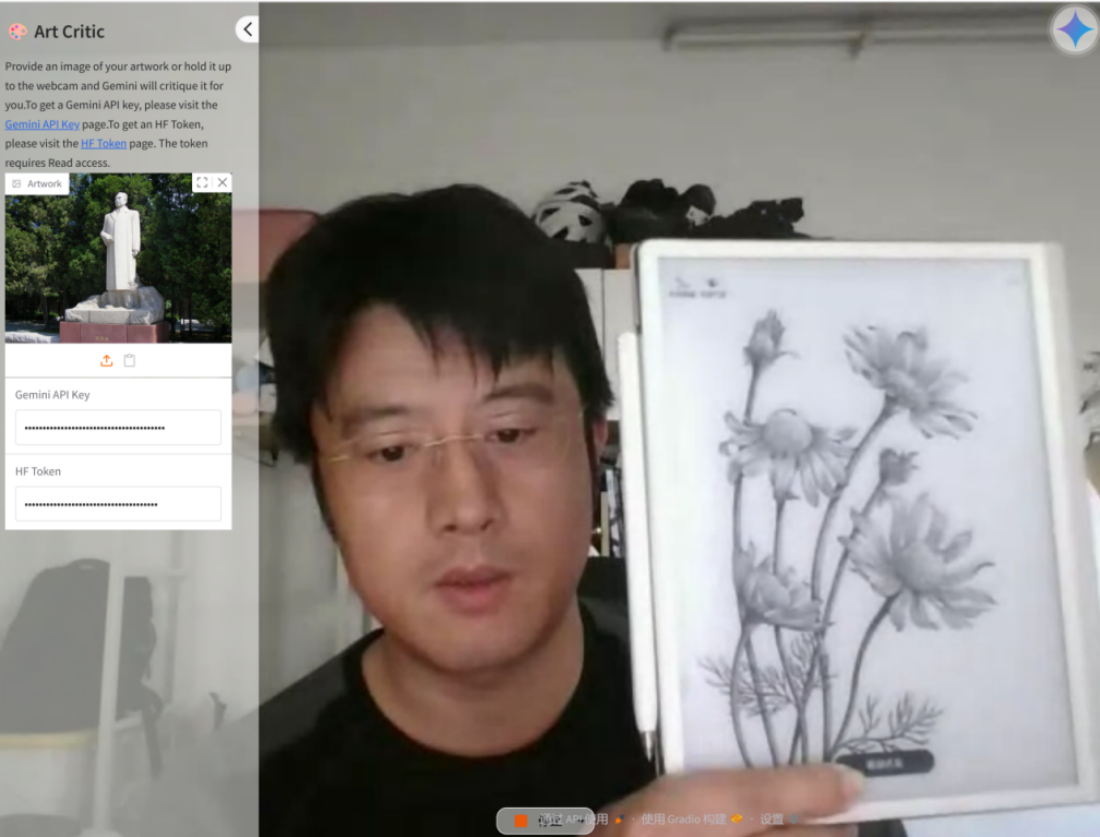
图12-7
12.7.3 gr.Blocks替换Stream.ui实现自定义界面
之前使用fastrtc.Stream对象的默认UI启动,如果希望实现自定义界面且保留Stream设置,该怎么办呢?
实现代码及解读。使用gr.Blocks替换Stream.ui,不再扮演艺术评论家角色,而是自由对话。GeminiHandler只有少许改动,请参考线上资源。如代码12-23所示:
代码12-23
py
from fastrtc import (AsyncAudioVideoStreamHandler, Stream, WebRTC,
get_cloudflare_turn_credentials_async)
from gradio.utils import get_space
stream = Stream(handler=GeminiHandler(),
modality="audio-video",
mode="send-receive",
rtc_configuration=get_cloudflare_turn_credentials_async,
time_limit=180 if get_space() else None,
additional_inputs=[gr.Image(label="Image",
type="numpy", sources=["upload", "clipboard"])],
ui_args={"icon": "https://www.gstatic.com/lamda/images/gemini_favicon_f069958c85030456e93de685481c559f160ea06b.png",
"pulse_color": "rgb(255, 255, 255)",
"icon_button_color": "rgb(255, 255, 255)",
"title": "Gemini Audio Video Chat"})
css = """#video-source {max-width: 600px !important; max-height: 600 !important;}"""
with gr.Blocks(css=css) as demo:
gr.HTML("""<div><h1>Gen AI SDK Voice Chat</h1></div>...""")
with gr.Row() as row:
with gr.Column():
webrtc = WebRTC(label="Video Chat", modality="audio-video",
mode="send-receive", elem_id="video-source",
rtc_configuration=get_cloudflare_turn_credentials_async, icon="https://www.gstatic.com/lamda/images/gemini_favicon_f069958c85030456e93de685481c559f160ea06b.png",
pulse_color="rgb(255, 255, 255)",
icon_button_color="rgb(255, 255, 255)")
with gr.Column():
image_input = gr.Image(label="Image", type="numpy",
sources=["upload", "clipboard"])
webrtc.stream(GeminiHandler(), inputs=[webrtc, image_input],
outputs=[webrtc], time_limit=180 if get_space() else None,
concurrency_limit=2 if get_space() else None)
stream.ui = demo
if __name__ == "__main__":
stream.ui.launch()本段代码首先定义fastrtc.Stream配置,然后构建Gradio界面,最后定义组件交互逻辑,详细解读如下:
- fastrtc.Stream流媒体配置。使用GeminiHandler作为数据处理中心,支持音视频及双工通信模式,使用异步Cloudflare TURN服务器处理NAT穿透。动态设置会话时长,Spaces环境限制180秒,通过get_space()检测是否在Spaces环境中运行以启用限制。设置额外图像输入和UI配置参数。
- WebRTC UI布局。采用gr.Blocks模式创建响应式布局。首先,通过CSS约束视频源尺寸(600x600像素)。然后,gr.HTML中(详见源码),左侧显示Gemini品牌图标,右侧显示产品标题并提供API获取指引。最后在双列布局中,左列是实时音视频组件(WebRTC),右列是图像输入组件(支持上传/粘贴)。严格使用Gemini官方视觉元素(图标、配色),通过HTML/CSS实现品牌展示区。
- 绑定流处理逻辑:首先WebRTC组件绑定GeminiHandler处理器,同时接收音视频流和图像作为输入,输出视频流。然后设置时间限制和并发数(作用与Stream对象相同)。最后将Demo赋值给流的ui属性并启动。
运行效果及参考资源 。在后台设置GEMINI_API_KEY和HF_TOKEN后,即可通过视频和图片,与GenAI就任何话题展开对话。最终运行效果如图12-8所示:
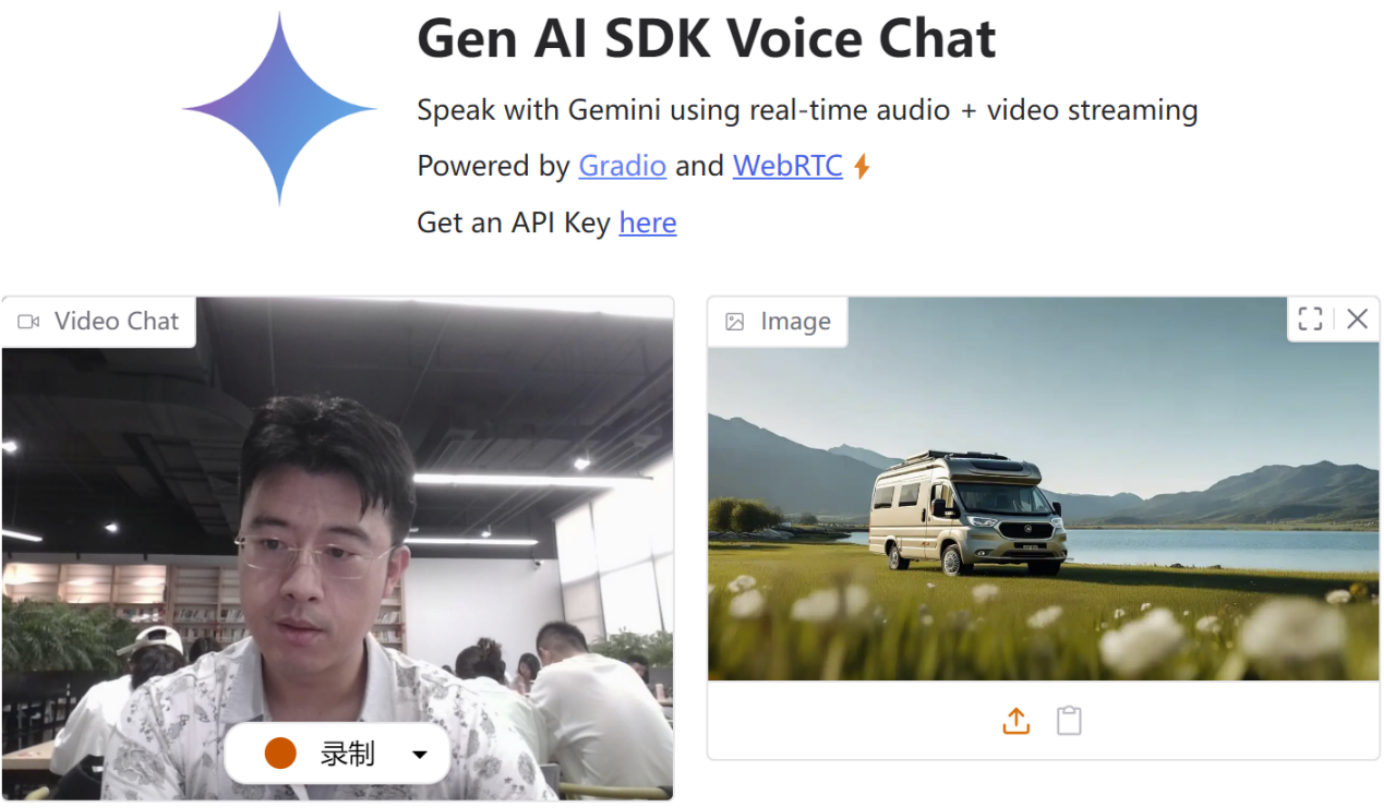
图12-8
如需进一步学习,请参考资源:Gemini音视频聊天示例------Gemini艺术评论家参考代码:gradio/Gemini-Art-Critic🖇️链接12-17。Gradio Blocks界面版本:fastrtc/gemini-audio-video🖇️链接12-18。