大家好,我是EthanYuan,今天还是来给大家分享今日所学。
最近因为阿里云知识库免费额度过期,需要用到向量数据库做语义检索、相似度匹配,不想额外单独部署专业向量库,增加运维成本和资源开销,于是选择用 PostgreSQL+PGVector插件 的方案,直接让传统PG变身轻量向量数据库,兼顾数据存储、元数据管理和向量检索能力,非常适合个人项目和中小型AI应用落地。
本篇就完整记录我在腾讯云服务器上,基于宝塔Linux面板从零安装配置PostgreSQL、开启外网远程访问、安装必备拓展插件,再到整合项目配置、单元测试验证的全流程实操。
1、开放访问权限
首先第一步,需要在腾讯云的防火墙放开5432端口。
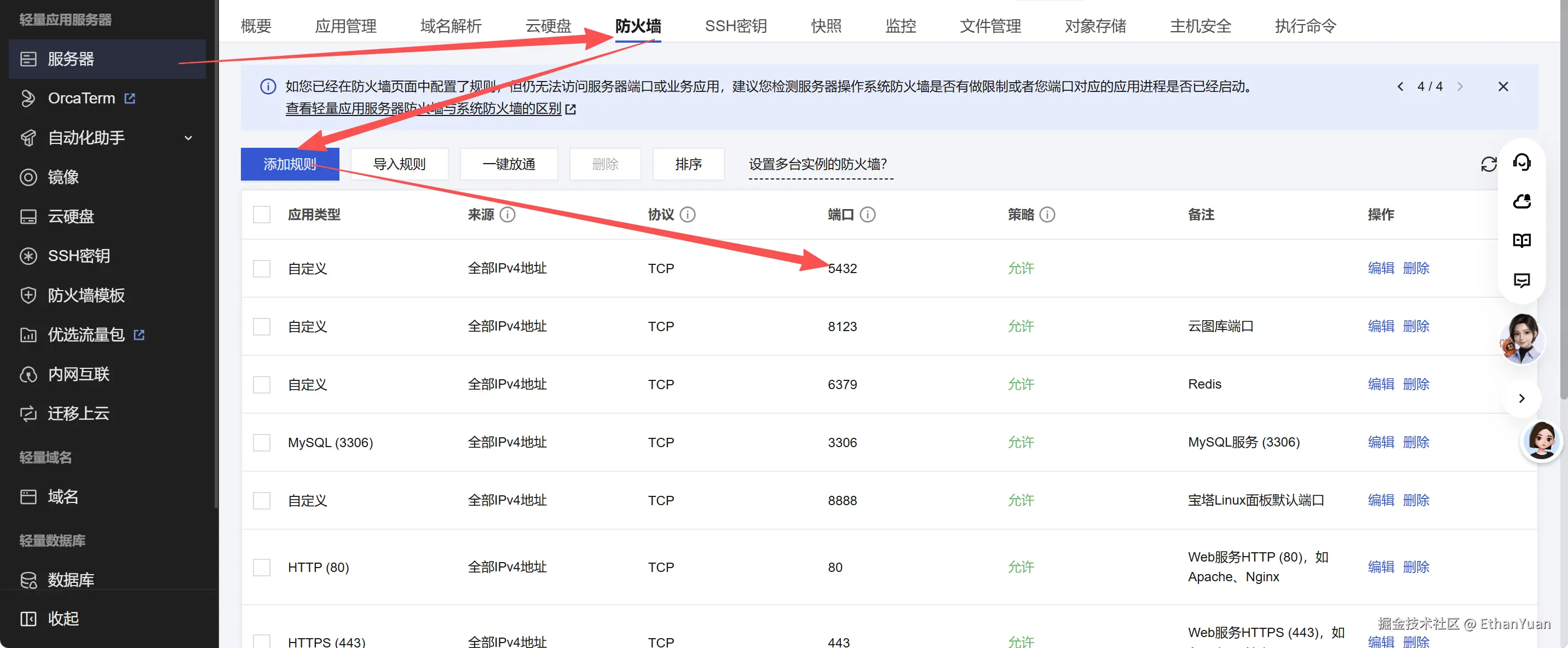
我自己买了两个月的轻量服务器,所以我就直接使用了,通过宝塔Linux面板可视化安装PostgreSQL,使用PostgreSQL管理器,全程不用复杂命令操作,一键部署省时省力,对新手和学生开发者十分友好,省去手动编译、环境适配的繁琐步骤。
安装完成后核心就是放开外网访问权限。默认PG仅支持本地localhost连接,外部设备和项目无法远程连接,需要手动修改核心配置文件。
先在配置文件搜索listen_addresses = 'localhost',释放注释并改为listen_addresses = '*'允许监听所有IP地址,再修改客户端认证规则,在最底部粘贴host all all 0.0.0.0/0 md5,放行全网IP远程连接,同时采用md5密码加密认证,兼顾开放性和安全性。
2、安装必备插件
想要让PostgreSQL具备向量存储能力,关键在于安装三大核心拓展插件。
- vector,这是实现向量数据存储、向量相似度计算、向量检索的核心依赖,也是PG变身向量库的关键;
- hstore,用来灵活存储结构化元数据,适配AI项目中多样的附加属性字段;
- uuid-ossp,支持自动生成UUID主键,替代自增ID,更适合分布式和AI业务场景的唯一标识设计。
插件部署完成后,接下来就是项目工程化整合。在后端项目中新建PostgreSQL专属配置类,统一配置数据库连接参数、插件适配参数、向量字段映射等,把数据库连接、拓展特性全部封装,做到配置解耦、方便后续复用和环境切换。
scss
@Configuration
public class PgVectorVectorStoreConfig {
@Bean
public VectorStore pgVectorVectorStore(JdbcTemplate jdbcTemplate, EmbeddingModel dashscopeEmbeddingModel) {
return PgVectorStore.builder(jdbcTemplate, dashscopeEmbeddingModel)
// 不要盲目设置
.dimensions(1536)
.distanceType(PgVectorStore.PgDistanceType.COSINE_DISTANCE)
.indexType(PgVectorStore.PgIndexType.HNSW)
.initializeSchema(true)
.schemaName("public")
.vectorTableName("love_document_store")
.maxDocumentBatchSize(10000)
.build();
}
}3、测试功能
最后编写对应的单元测试,完整验证整个链路可用性。测试包含数据库远程连通性、拓展插件是否正常加载、向量数据能否正常写入、基础相似度查询是否生效,确保从服务器安装、权限配置、插件部署到项目接入全流程无问题,可直接投入AI Agent语义检索、知识库问答等业务场景使用。
下面是测试方法:
less
@Resource
VectorStore pgVectorVectorStore;
@Test
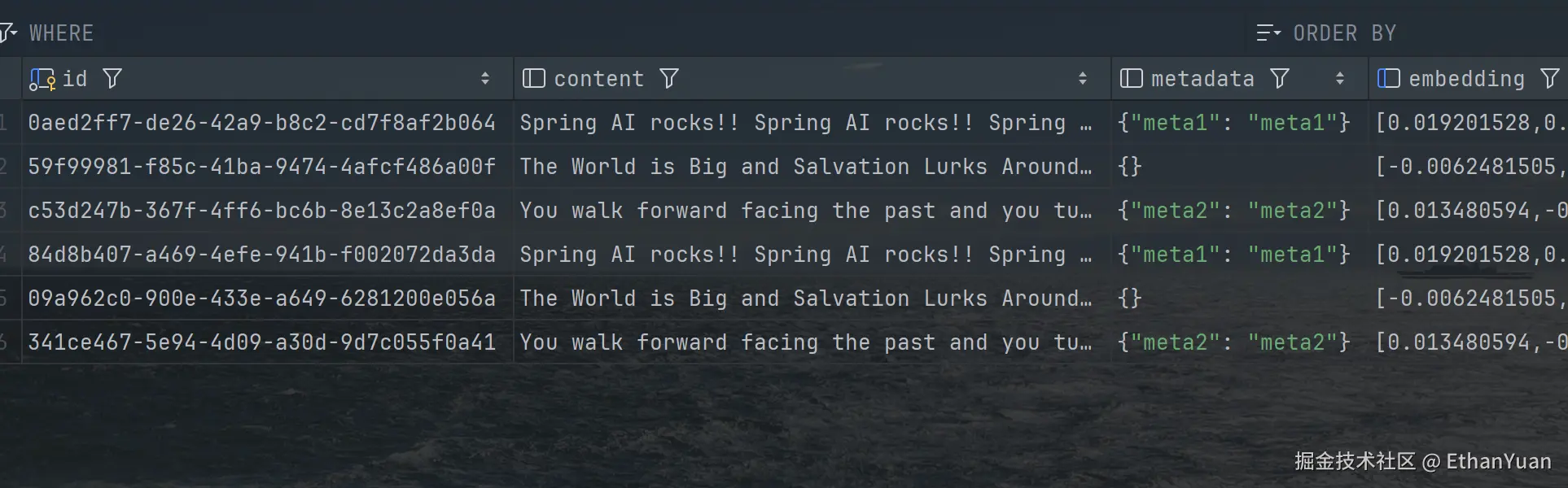
void test() {
List<Document> documents = List.of(
new Document("Spring AI rocks!! Spring AI rocks!! Spring AI rocks!! Spring AI rocks!! Spring AI rocks!!", Map.of("meta1", "meta1")),
new Document("The World is Big and Salvation Lurks Around the Corner"),
new Document("You walk forward facing the past and you turn back toward the future.", Map.of("meta2", "meta2")));
// 添加文档
pgVectorVectorStore.add(documents);
// 相似度查询
List<Document> results = pgVectorVectorStore.similaritySearch(SearchRequest.builder().query("Spring").topK(5).build());
Assertions.assertNotNull(results);
}经过测试,可以看到成功存储到了向量数据库中。
整体这套方案优势很明显:复用已有腾讯云服务器,无需额外购置机器;基于宝塔可视化运维,部署简单易上手;借助原生插件赋予PG向量存储能力,不用引入Redis、Milvus等额外中间件,减少项目架构复杂度和运维压力,是个人开发、学生练手中小型AI项目的绝佳向量存储方案。
4、在项目中实践
要在项目中实现RAG的功能,首先就需要知道RAG的工作流程是什么。RAG的工作流程大致有如下四步:
文档收集与切割 -> 向量转换与存储 -> 文档过滤和检索 -> 查询关联和增强
1、文档收集与切割
文档收集: 首先需要准备好所有需要加载的文档,在resource目录下新建documents文件夹,把需要用到的markdown文档都存放在这个目录下。
文档切割: 创建文档加载器LoveDocumentLoader,负责加载资源路径下的所有文档,并对文档进行切分,切分策略如下:
scss
MarkdownDocumentReaderConfig config = MarkdownDocumentReaderConfig.builder()
.withHorizontalRuleCreateDocument(true) // 水平线切割
.withIncludeCodeBlock(false) // 忽略代码块
.withIncludeBlockquote(false)// 忽略引用块
.withAdditionalMetadata("docType", docType)
.withAdditionalMetadata("gender", gender)
.withAdditionalMetadata("status", status)
.build();切分后还根据文档类型、性别、个人状态给每个切片添加元数据,方便后续通过元数据直接筛选相关文档切片,有效降低无关信息的干扰。至此文档收集与切割工作完成。
2、向量转换与存储
加载完所有的文档并切分后需要将所有的文档切片添加到PostgreSQL中,由于这些文档切片只需要添加一次,而不是SimpleVectorStore那样基于内存来存储向量数据,每次都需要重新转换向量,所以还需要创建LoveDocumentInitializer。
这个类需要达到的目的:
- 执行文档加载器方法,完成文档切分
- 使用关键词增强器,提取关键词并记录为元数据
- 写入向量数据库
只把所有数据添加到数据库,并且只执行一次,能解决SimpleVectorStore每次重启项目都要加载一遍向量数据的问题,并且省去了Embedding模型的用量额度,提升开发效率的同时还节省成本。
如果这些文档已经加载过了,那么判定无需重复加载文档,避免存入重复数据。
- 实现这个功能可以通过创建
LoveAutoLoadConfig配置类,内部实现监听器方法,在项目每次重启时都会执行一遍加载方法,内部判定若已加载过则无需重复添加数据。
LoveDocumentInitializer需要知道按什么配置存入向量数据库,所以需要创建向量数据库的连接对象,这是RAG的核心组件之一:
scss
@Configuration
public class PgVectorStoreConfig {
@Bean
public VectorStore pgVectorStore(JdbcTemplate jdbcTemplate, EmbeddingModel dashscopeEmbeddingModel) {
return PgVectorStore.builder(jdbcTemplate, dashscopeEmbeddingModel)
// 向量维度,不要盲目设置
.dimensions(1536)
// 文本语义相似度算法:余弦相似度
.distanceType(PgVectorStore.PgDistanceType.COSINE_DISTANCE)
// 索引类型:使用近似最邻近搜索算法,能在大规模数据中快速定位某条数据
.indexType(PgVectorStore.PgIndexType.HNSW)
// 数据库不存在时允许自动创建
.initializeSchema(true)
// 数据库名称
.schemaName("public")
// 表名称
.vectorTableName("love_document_store")
// 单批次最多同时加载10000条记录
.maxDocumentBatchSize(10000)
.build();
}
}将数据库配置类注册为Bean,为整个应用程序提供一个统一的、可复用的向量数据库连接对象,这个对象的作用是:
- 引入Embedding模型,将文本转换为向量
- 结合语义相似度算法和搜索算法,快速找出最相关的文档切片列表
- 指定数据库,将向量数据存入库中,并支持无数据库时自动创建
- 默认的批处理策略是单批次同时加载10000条记录,避免数据库性能压力
3、文档过滤和检索
完成了向量存储后,接下来需要实现文档过滤和检索的功能,首先对于文档过滤,在我的项目中,一共有情感咨询和恋爱对象推荐两个功能,这两个功能的相关文档都已存入向量数据库,并标记元数据用于筛选,为了避免无关信息的干扰,比如情感咨询时突然推荐恋爱对象,我想到使用构建Advisor的方式,只需要在对话方法中引入构建好的RAG Advisor就能实现RAG的检索与过滤功能。
那么此时就会出现一个问题:我的元数据一共有docType、status、gender三个,构建单个过滤条件可以通过如下方式构建:
scss
Filter.Expression filter = new FilterExpressionBuilder()
.eq("docType", docType)
.build();如果我要按status、gender单独过滤,那就需要在同一个类中写三个过滤表达式,这时候就可以创建一个工厂类,把过滤方法都写在里面,具体写法如下:
scss
/**
* 创建通用Advisor(不过滤,检索所有文档)
*/
public static Advisor createGenericAdvisor(VectorStore vectorStore) {
return createRagAdvisor(vectorStore, null);
}
/**
* 按文档类型过滤
* @param docType 文档类型: "qa", "candidate", "general"
*/
public static Advisor createAdvisorByDocType(VectorStore vectorStore, String docType) {
Filter.Expression filter = new FilterExpressionBuilder()
.eq("docType", docType)
.build();
return createRagAdvisor(vectorStore, filter);
}
/**
* 按性别过滤(用于推荐场景)
* @param gender 性别: "female", "male"
*/
public static Advisor createAdvisorByGender(VectorStore vectorStore, String gender) {
Filter.Expression filter = new FilterExpressionBuilder()
.eq("gender", gender)
.build();
return createRagAdvisor(vectorStore, filter);
}
/**
* 按个人状态过滤
* @param status 状态标识
*/
public static Advisor createAdvisorByStatus(VectorStore vectorStore, String status) {
Filter.Expression filter = new FilterExpressionBuilder()
.eq("status", status)
.build();
return createRagAdvisor(vectorStore, filter);
}最后构建RAG Advisor就行了:
scss
/**
* 创建 RAG Advisor
* 相似度阈值 = 0.5,topK = 5
*/
private static Advisor createRagAdvisor(VectorStore vectorStore, Filter.Expression filterExpression) {
// 文档增强配置
DocumentRetriever documentRetriever = VectorStoreDocumentRetriever.builder()
.vectorStore(vectorStore)
.filterExpression(filterExpression)
.similarityThreshold(0.5)
.topK(5)
.build();
// 构建RAG Advisor
return RetrievalAugmentationAdvisor.builder()
// 加载配置好的文档增强配置
.documentRetriever(documentRetriever)
// 无法回答时触发空上下文,使用特定话术回复用户
.queryAugmenter(LoveAppContextualQueryAugmenterFactory.createInstance())
.build();
}构建完RAG Advisor后,只要在对话方法通过.advisors()引入就可以实现基于RAG检索增强的对话功能了。
4、查询增强和关联
查询重写器
有时候用户的问题对于AI来说是表述不够清晰的或者不够专业的,此时构建查询重写器,可以将用户的输入内容转换为更加结构化的表述。
例如:
" 请帮我搜索一下上海黄浦区有哪些人气高的自助餐厅 。 "
---->
" 上海黄浦区高性价比自助餐厅推荐 "
查询重写器构建如下:
java
@Component
public class QueryRewriter {
private final QueryTransformer queryTransformer;
public QueryRewriter(ChatModel dashscopeChatModel) {
ChatClient.Builder builder = ChatClient.builder(dashscopeChatModel);
// 创建查询重写转换器
queryTransformer = RewriteQueryTransformer.builder()
.chatClientBuilder(builder)
.build();
}
public String doQueryRewrite(String prompt) {
Query query = new Query(prompt);
// 执行查询重写
Query transformedQuery = queryTransformer.transform(query);
// 输出重写后的查询
return transformedQuery.text();
}
}只需要在对话方法中,将用户消息对象message传入doQueryRewrite()方法,拿到重写后的提示词再发给大模型思考即可。
查询增强器
这里在构建Advisor时还加载了查询增强器,主要目的是:
- 如果RAG检索不到相关文档,就按照固定的提示词模板拒绝回答用户,防止AI基于自身知识乱回复
- 用户如果问别的问题,禁止AI基于自身数据回答
csharp
public static ContextualQueryAugmenter createInstance() {
PromptTemplate emptyContextPromptTemplate = new PromptTemplate("""
你是专业的恋爱咨询助手,只能回答恋爱相关问题,
请严格遵守以下规则:
1. 如果用户是自我介绍/打招呼/感谢(如"你是谁""你好""谢谢"),友好回应并说明你的能力范围
2. 如果用户的问题属于恋爱相关,可基于你的理解提供帮助
3. 如果问题和恋爱无关,必须回复:"抱歉,我只能回答恋爱相关的问题,别的没办法帮到您哦。"
""");
return ContextualQueryAugmenter.builder()
.allowEmptyContext(false)
.emptyContextPromptTemplate(emptyContextPromptTemplate)
.build();
}最后,在召回5个最相关的文档切片时,会直接发给大模型思考,然后做出回答。至此,项目中就完成了RAG检索增强的所有流程。