note
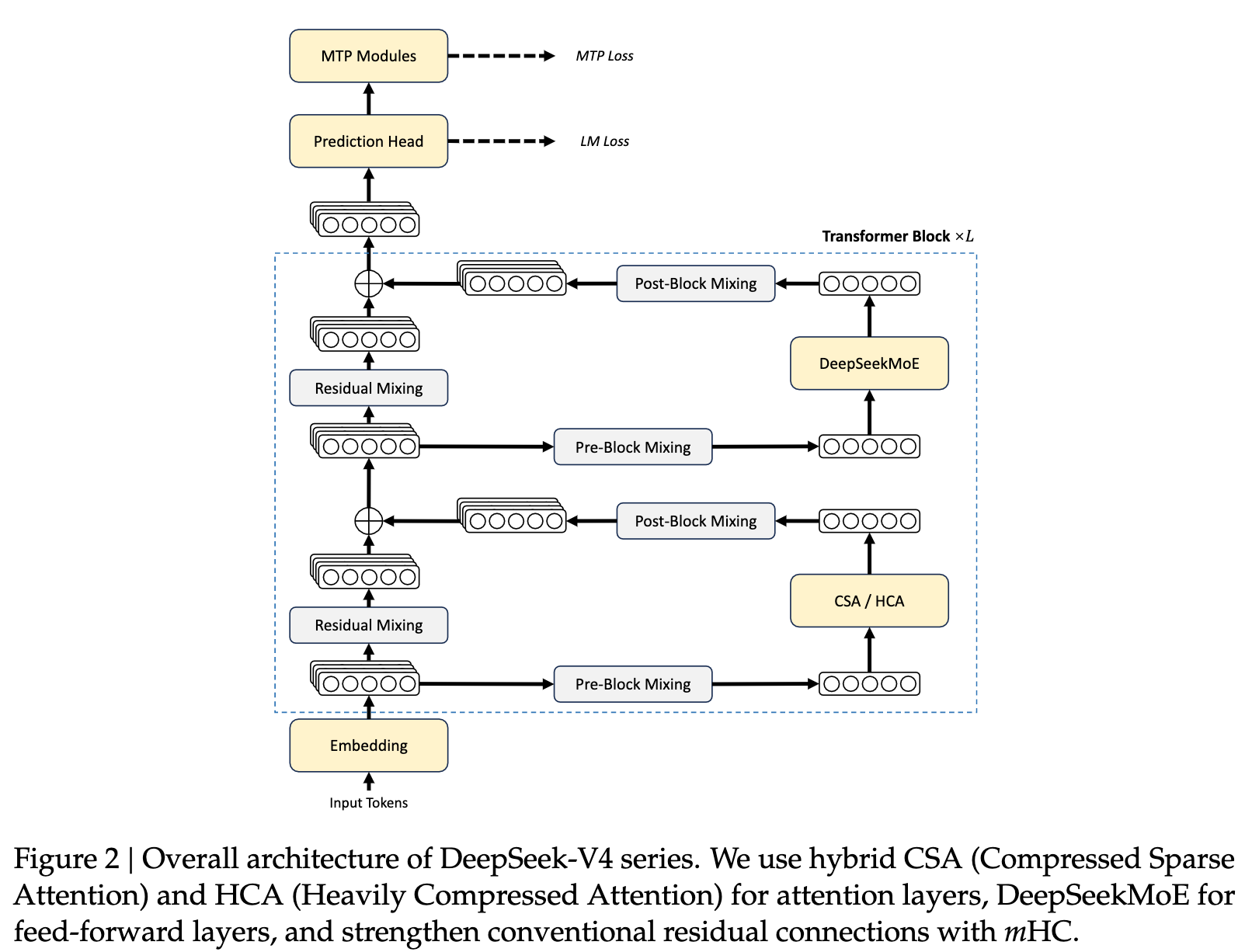
- 混合注意力架构:我们设计了一种结合压缩稀疏注意力(Compressed Sparse Attention, CSA)与重度压缩注意力(Heavily Compressed Attention, HCA)的混合注意力机制,显著提升长上下文处理效率。在百万 Token 上下文场景下,DeepSeek-V4-Pro 相较于 DeepSeek-V3.2,单 Token 推理所需的 FLOPs 仅为其 27%,KV 缓存占用仅为 10%。
- CSA(Compressed Sparse Attention):先KV 压缩(把多个 token 的 K/V 合成一个压缩表示,减少 KV cache),再稀疏选择(不是所有压缩块都看,只选最相关的 top-k 块)
- HCA (Heavily Compressed Attention):HCA 会把一组 token 的 KV entries 合并成一个 compressed entry,从而显著降低 KV cache
- 流形约束超连接(Manifold-Constrained Hyper-Connections, mHC):我们在传统残差连接中引入 mHC,以增强跨层信号传播的稳定性,同时保留模型的表达能力。
- Muon 优化器:我们采用 Muon 优化器,实现更快的收敛速度和更高的训练稳定性。
- DeepSeek V4 的OPD特殊点是它做的是 full-vocabulary OPD:不是只看学生实际采样出来的那个 token,也不是只看 top-k,而是尽量保留完整词表 logits 来算 KL,这样梯度更稳定,但计算和显存成本更高。论文还提到它为此做了 teacher scheduling:teacher 权重按需加载、ZeRO-like sharding、避免直接物化超大 logits,并缓存 teacher 最后一层 hidden states,再重建 logits
- 为什么OPD使用反向KL散度:正向KL散度更偏 mode-seeking:学生会倾向于把概率集中到 teacher 认为高质量的输出模式上,而不是平均覆盖 teacher 的所有可能输出。OPD 的核心就是在学生自己的轨迹上,让 teacher 对学生当前状态提供 dense token-level supervision
- 关于上下文优化:
| 优化对象 | DeepSeek V4 的做法 | 结果 |
|---|---|---|
| KV cache | 压缩 KV entries | 显存下降 |
| Attention FLOPs | 稀疏选择 + 压缩序列 attention | 计算下降 |
| 长上下文可用性 | CSA/HCA/局部窗口分工 | 远程信息还能被利用 |
| 服务成本 | 单 token 推理成本下降 | 1M context 更接近可部署 |
文章目录
一、研究背景
- 研究问题:这篇文章要解决的问题是如何在超长上下文中实现高效的推理模型。具体来说,现有的注意力机制在处理超长序列时存在计算复杂度高的瓶颈,限制了大规模语言模型(LLMs)在测试时扩展和长距离任务中的表现。
- 研究难点:该问题的研究难点包括:如何在保持模型性能的同时,显著降低长上下文推理的计算复杂度和内存占用;如何设计一种新的混合注意力机制来提高长上下文的处理效率。
相关工作:该问题的研究相关工作包括OpenAI的GPT系列模型、DeepSeek-AI系列模型以及其他开源的长上下文推理模型。这些工作虽然在一定程度上推动了LLM的发展,但在处理超长序列时仍存在效率瓶颈。
【ds v4】混合专家(Mixture-of-Experts, MoE)语言模型:DeepSeek-V4-Pro(总参数量 1.6T,激活参数量 49B)和 DeepSeek-V4-Flash(总参数量 284B,激活参数量 13B),二者均支持 百万 Token 的上下文长度。采用 MIT 许可证。
https://modelscope.cn/collections/deepseek-ai/DeepSeek-V4
4 款开源权重模型,全部原生支持 100 万 token 上下文,包括:
🔹 DeepSeek-V4-Pro:总参数 1.6T,激活参数 49B,100 万上下文------前沿旗舰
🔹 DeepSeek-V4-Flash:总参数 284B,激活参数 13B,100 万上下文------速度优化
🔹 DeepSeek-V4-Pro-Base:1.6T 预训练基础模型,面向前沿规模的后训练与研究
🔹 DeepSeek-V4-Flash-Base:284B 预训练基础模型,适用于高效的领域适配
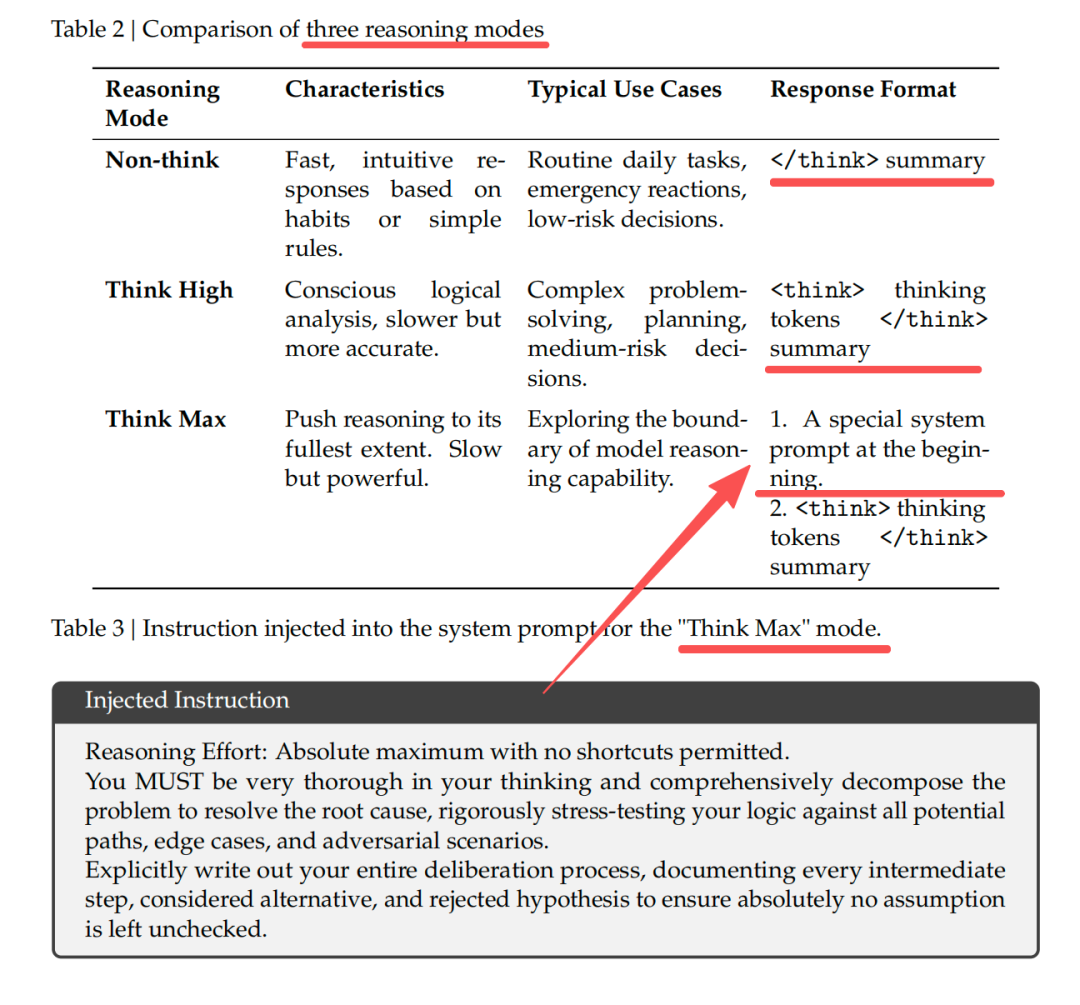
三种推理模式------Non-Think / Think High / Think Max------按需调节推理强度。
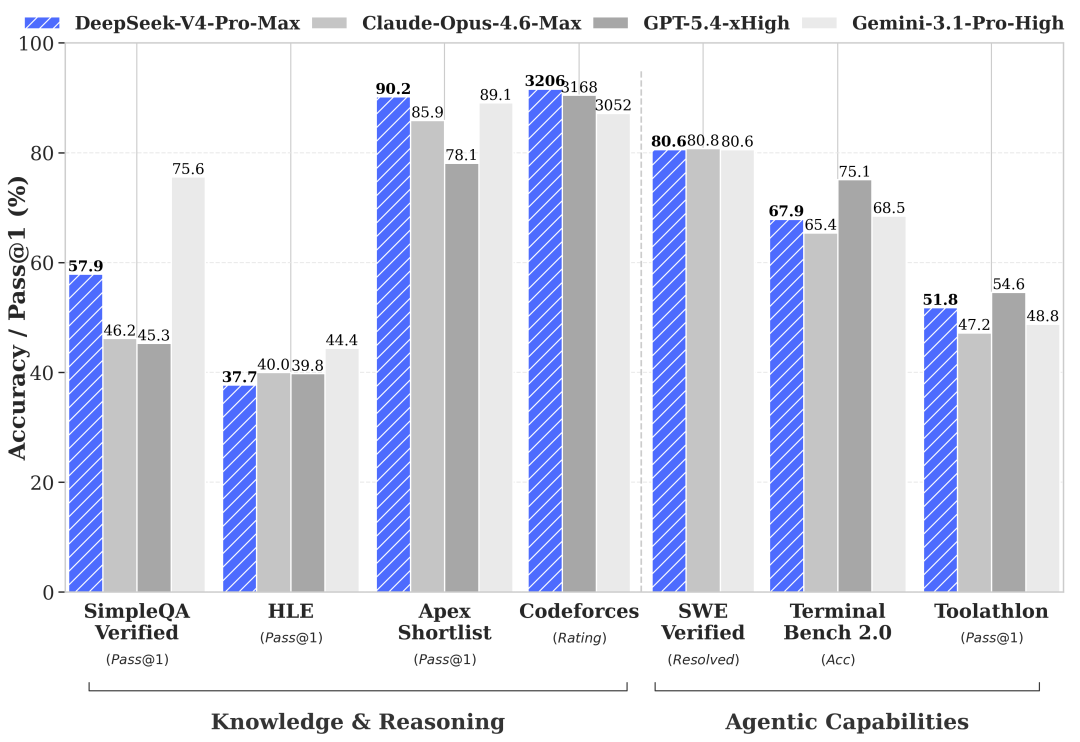
在 Think Max 模式下,V4-Pro 在 LiveCodeBench 上达到 93.5 分,Codeforces 上取得 3206 分,HMMT 2026 上达到 95.2 分,在推理和智能体任务上进一步缩小了与领先闭源前沿模型的差距。
思考模式:
模型推理任务性能由计算投入决定,DeepSeek-V4-Pro/Flash均支持三种推理强度模式:无思考(Non-think)、高思考(Think High)、最大思考(ThinkMax),在输出最终回答之前,模型会先输出一段思维链内容,以提升最终答案的准确性
二、DeepSeek-V4
这篇论文提出了DeepSeek-V4系列模型,用于解决超长上下文推理的效率问题。具体来说,
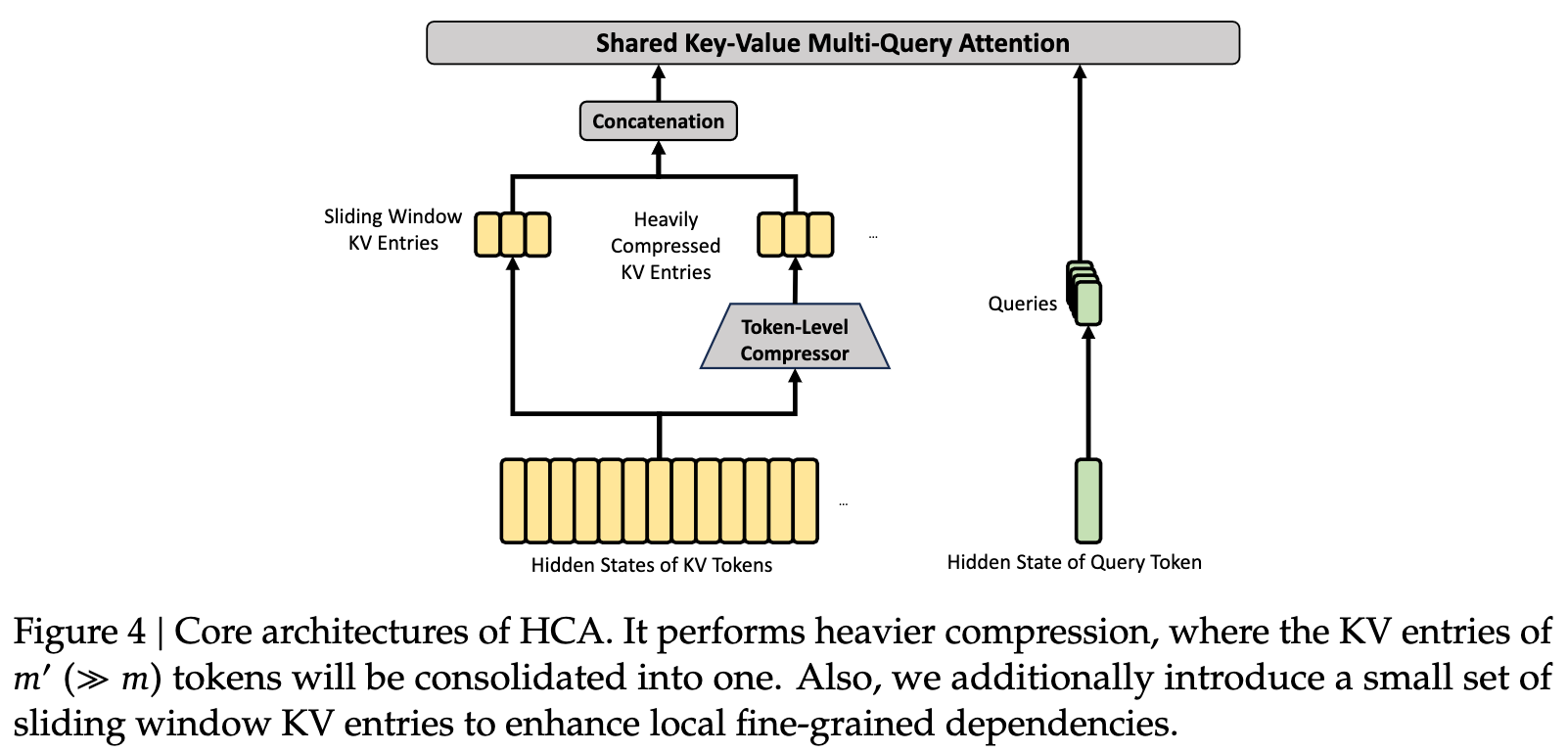
1、混合注意力机制:提出了一种结合压缩稀疏注意力(CSA)和重度压缩注意力(HCA)的混合注意力架构。CSA通过压缩KV缓存并应用DeepSeek稀疏注意力(DSA)来加速注意力计算;HCA则通过对KV缓存进行更激进的压缩来进一步提高效率。公式如下:
C a = H ⋅ W a K V , C b = H ⋅ W b K V C^a = H \cdot W^{aKV}, \quad C^b = H \cdot W^{bKV} Ca=H⋅WaKV,Cb=H⋅WbKV
其中, C a C^a Ca和 C b C^b Cb是压缩后的KV条目, W a K V W^{aKV} WaKV和 W b K V W^{bKV} WbKV是相应的压缩权重。
2、流式索引器:在CSA中,使用流式索引器选择前k个压缩KV条目进行核心注意力计算。公式如下:
c t Q = h t ⋅ W D Q c_t^Q = h_t \cdot W^{DQ} ctQ=ht⋅WDQ
其中, c t Q c_t^Q ctQ是查询令牌生成的索引查询, h t h_t ht是输入隐藏状态, W D Q W^{DQ} WDQ是下投影矩阵。
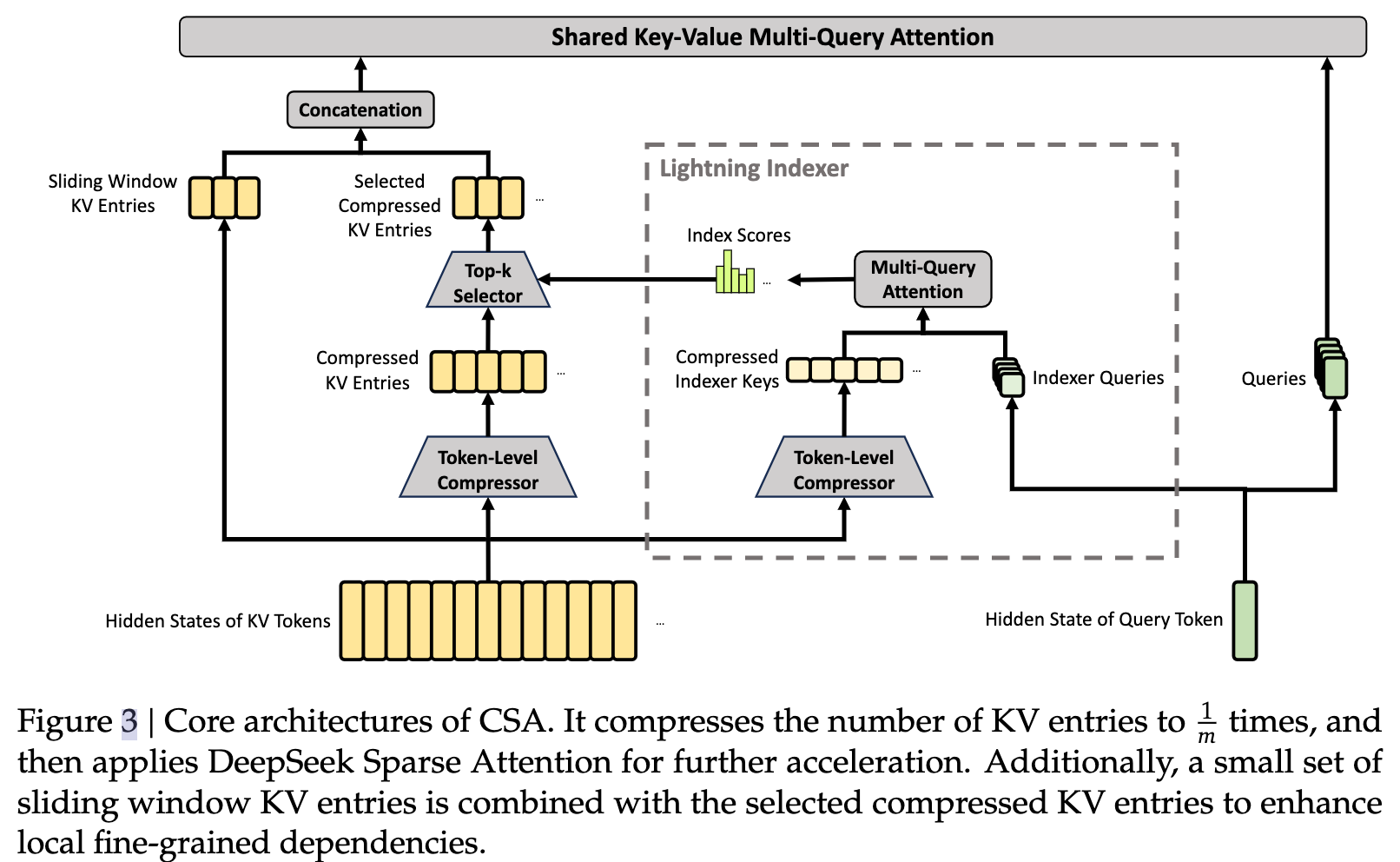
3、共享KV多查询注意力(MQA):在CSA和HCA中,使用共享KV MQA进行核心注意力计算。公式如下:
o t , i = CoreAttn ( q u e r y = q t , k e y = C t SprsComp , v a l u e = C t SprsComp ) o_{t,i} = \text{CoreAttn}(query=q_t, key=C_t^{\text{SprsComp}}, value=C_t^{\text{SprsComp}}) ot,i=CoreAttn(query=qt,key=CtSprsComp,value=CtSprsComp)
其中, o t , i o_{t,i} ot,i是第t个令牌的第i个头的核心注意力输出, q t q_t qt是查询令牌, C t SprsComp C_t^{\text{SprsComp}} CtSprsComp是选择的压缩KV条目。

4、Muon优化器:采用Muon优化器进行训练,因其更快的收敛速度和更高的训练稳定性。Muon优化器的更新规则如下:
O t ′ = HybridNewtonSchulz ( μ M t + G t ) O_t' = \text{HybridNewtonSchulz}(\mu M_t + G_t) Ot′=HybridNewtonSchulz(μMt+Gt)
其中, G t G_t Gt是梯度, M t M_t Mt是动量缓冲区, μ \mu μ是动 (注:此处原文被图标遮挡,推测为"动量系数"或类似概念),是混合牛顿-舒尔茨更新。
三、实验设计
- 数据收集:在预训练阶段,使用了超过32T的多样化且高质量的字节对语料库,包括数学公式、代码、网页、长文档等。
- 模型设置:DeepSeek-V4-Flash模型包含43层Transformer层,隐藏维度为4096,使用CSA和HCA交替使用的混合注意力机制。DeepSeek-V4-Pro模型包含61层Transformer层,隐藏维度为7168,同样使用CSA和HCA交替使用的混合注意力机制。
- 训练设置:使用Muon优化器进行大多数参数的更新,AdamW优化器用于嵌入模块、预测头模块和RMSNorm模块的权重。训练过程中采用了批量大小调度策略和学习率调度策略。
- 后处理:在预训练阶段,采用样本级注意力掩码和分词策略;在后训练阶段,采用领域特定的专家独立训练和有向策略优化(GRPO)进行强化学习。
四、实验结果
效率提升:与DeepSeek-V3.2相比,DeepSeek-V4-Pro在1M token上下文设置中仅需27%的单令牌推理FLOPs和10%的KV缓存大小。DeepSeek-V4-Flash在1M令牌上下文设置中仅需10%的单令牌推理FLOPs和7%的KV缓存大小。
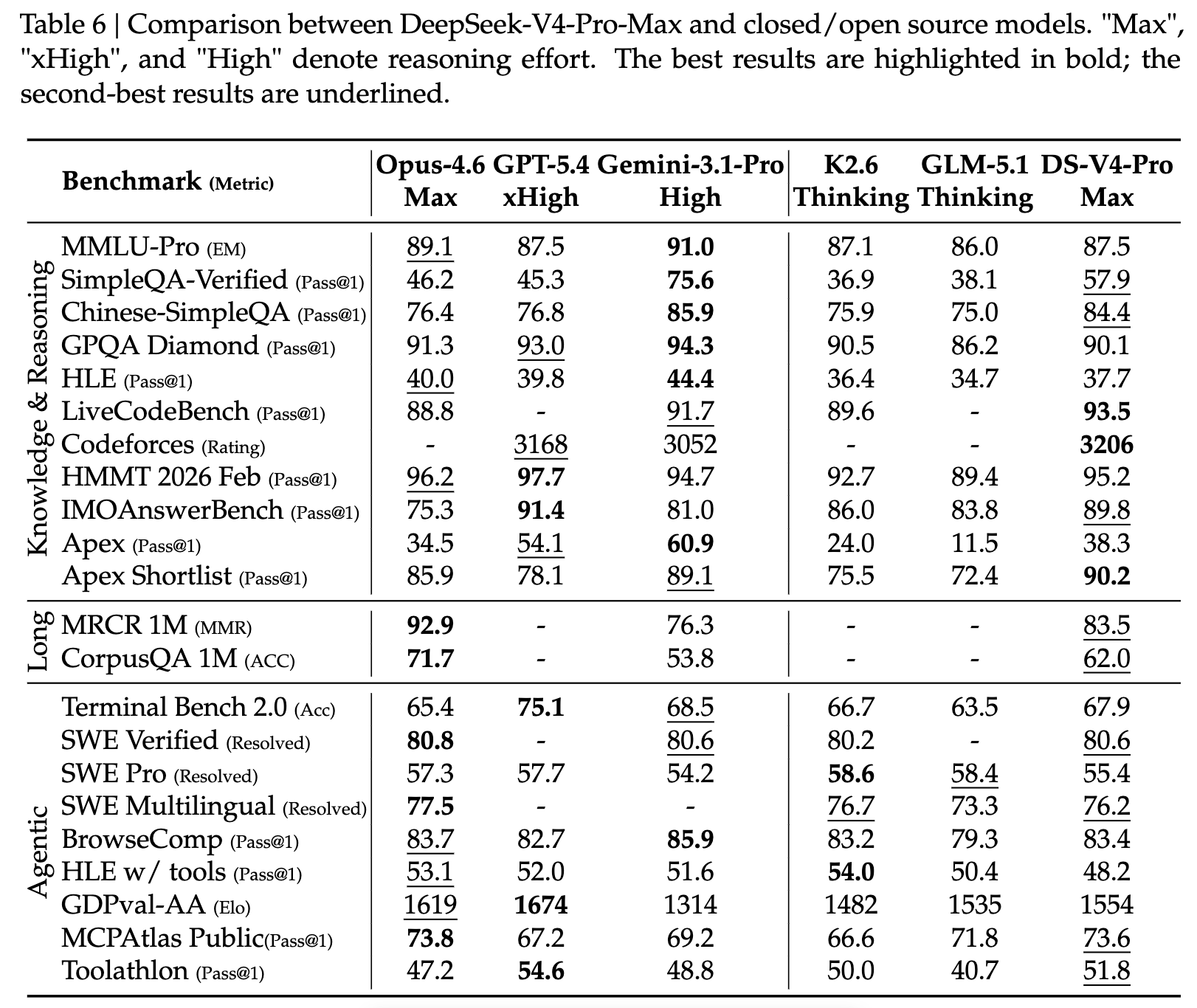
性能提升:DeepSeek-V4-Pro-Max在知识基准测试中显著优于现有的开源模型,接近专有模型Gemini-3.1-Pro的性能。在推理任务中,DeepSeek-V4-Pro-Max也表现出优异的性能,接近GPT-5.4的水平。
长上下文处理:DeepSeek-V4-Pro-Max在长上下文任务中表现出色,特别是在学术基准测试中,达到了前所未有的水平。
实际应用:在中文写作、搜索和白领任务中,DeepSeek-V4-Pro-Max也表现出色,显著优于现有的开源模型。
Reference
1 DeepSeek-V4:Towards Highly Efficient Million-Token Context Intelligence