文章目录
- 一、前言
- 二、搜索
- 三、本地部署marker
-
- [1 构建conda环境+安装torch](#1 构建conda环境+安装torch)
- [2 下载marker并安装](#2 下载marker并安装)
- [3 将pdf论文转为markdown格式](#3 将pdf论文转为markdown格式)
- [4 安装vscode插件以阅读md文件](#4 安装vscode插件以阅读md文件)
一、前言
我阐述一下为什么我们首先要解决pdf论文转markdown的问题,其实核心原因在于markdown格式的文章对公式的支持比较好,也就是说markdwon格式它是支持latex代码编写公式的,但是问题在于我们并不知道怎么用latex代码去编写公式,比起从头学习latex代码怎么写公式,一个好的思路是我直接有一个工具把我那些公式转成latex代码,然后我复制它们的代码,这样既方便我做笔记,又方便我学习到这个公式是如何用latex代码表示的。可能你会认为公式其实没那么重要,理解论文在做什么更加重要,但是你会慢慢地发现一个事情就是,你去思考如何构建一个好的架构,或者是你思考如何有一个创新的想法,这个重要性已经越来越下降了,就是说架构和idea依然很重要但是你实现不了它就等于0,而你要实现你设想的架构和idea,必须重新重视基础和重视工程能力,这个基础涉及到数学和物理,而数学和物理全是公式,那这个公式的重要性就不言而喻了,因为一个事物你想理解它,你必须得学会创造它,而创造它需要很好的基础和工程能力,正如费曼所说:What I cannot create, I do not understand.------Richard Feynman
但是这个过程肯定是漫长的,我们需要借助开源的工具来帮我们提升效率,帮我们学习,所以说本地部署开源项目也很重要,这决定了我们不要轻易地从零造轮子。后面可能我需要探究一下如何加入论文翻译功能,最好能双语对照,以及能英文段落切片阅读那种,至于AI解读论文图片和论文公式这个可能依赖本地AI的话难度比较大,而且可能涉及到需要微调模型,看下以后能不能找到方法吧。
二、搜索
有很多优秀的开源项目可以实现 PDF 转 Markdown,以下是当前最主流、社区活跃度最高的几个:
1. MarkItDown(微软开源)⭐10万+
GitHub : microsoft/markitdown
微软开源的轻量级 Python 工具,支持将 PDF、Word、Excel、PPT、图片、音频、HTML、EPUB 等多种格式转换为 Markdown 。
- 核心特点:保留文档结构(标题、列表、表格、链接),专为 LLM 和文本分析场景设计
- 扩展能力:支持 Azure Document Intelligence、OCR 插件、MCP 服务器集成
- 安装 :
pip install markitdown - 注意:PDF 转换目前主要提取纯文本,复杂表格和布局保留有限
2. Marker ⭐2.7万+
GitHub : datalab-to/marker
专注于高精度 PDF 转 Markdown 的工具,速度快、准确度较高 。
- 核心能力:转换 PDF/EPUB/DOCX,格式化表格、公式(转 LaTeX)、代码块、链接、引用
- AI 增强:可选使用 LLM 提高准确性,支持 GPU/CPU/MPS
- 性能:H100 预计吞吐量 25 页/秒,比云服务便宜 100 倍
- 局限:对中文处理效果相对英文稍弱
3. MinerU(上海AI实验室)⭐3.2万+
GitHub : opendatalab/MinerU
企业级高精度文档解析器,被称为"文档界的变形金刚" 。
- 技术架构:LayoutLMv3(布局分析)+ YOLOv8(视觉识别)+ UniMERNet(公式识别)
- 核心功能 :
- 智能过滤页眉/页脚,精准提取正文
- 支持 84 种语言 OCR
- 公式转 LaTeX,表格转 HTML
- 支持 Docker 部署和 GUI 界面
- 硬件要求:GPU 加速效果最佳,内存优化后约需 10GB
4. PDF3MD(Web 应用)
GitHub : murtaza-nasir/pdf3md
开源 Web 应用,支持私有化部署,适合注重数据安全的场景 。
- 技术栈:前端 React + Vite,后端 Python + Flask
- 核心依赖:PyMuPDF4LLM(精准解析)、Pandoc(转 Word)
- 部署:支持 Docker Compose 一键部署
- 特点:格式还原度高,支持导出 DOCX
5. Docling(IBM 开源)
GitHub : DS4SD/docling
IBM 开源的文档处理工具,支持结构化解析和自定义流程 。
- 优势:AI 驱动,对复杂布局理解能力强,适合学术和复杂场景
- 集成:已集成到 Langflow 等 RAG 框架中
快速对比表
| 项目 | Star 数 | 最佳场景 | 中文支持 | 部署难度 |
|---|---|---|---|---|
| MarkItDown | 10万+ | 多格式批量转换、LLM 预处理 | 一般 | 简单 |
| Marker | 2.7万+ | 科研论文、公式密集型 PDF | 中等 | 中等 |
| MinerU | 3.2万+ | 企业级高精度解析、复杂布局 | 优秀 | 较复杂 |
| PDF3MD | 较少 | 私有化部署、Web 界面 | 良好 | 简单 |
| Docling | 增长中 | 学术深度解析、RAG 集成 | 良好 | 中等 |
推荐选择
- 快速上手/多格式支持 → MarkItDown(微软背书,生态活跃)
- 科研论文/公式表格 → Marker 或 MinerU
- 私有化部署/数据安全 → PDF3MD 或 MinerU(Docker 部署)
- RAG/AI 应用集成 → Docling 或 MarkItDown(MCP 支持)
如果你需要处理中文 PDF 且对格式还原要求高 ,MinerU 是目前国产方案中最强的选择;如果追求简单快速 ,MarkItDown 一行命令就能搞定。
三、本地部署marker
1 构建conda环境+安装torch
此过程我们以后不再赘述了
一次构建自己的带torch的conda环境,后续直接使用
创建conda环境:conda creat -n python312_torch python=3.12
预先下载torch的whl包并安装:
pip install torch-2.9.0+cu126-cp312-cp312-win_amd64.whl
pip install torchaudio-2.9.0+cu126-cp312-cp312-win_amd64.whl
pip install torchvision-0.24.0+cu126-cp312-cp312-win_amd64.whl
将D:\application\anaconda3\envs\python312_torch加压为python312_torch.zip,删除原先的python312_torch环境
直接使用预先构建的conda环境
直接把python312_torch.zip解压为python312_torch然后再重命名为marker,即:
解压 D:\application\anaconda3\envs\python312_torch29_cu126.zip 并重命名为marker
激活环境:conda activate marker
2 下载marker并安装
git clone https://github.com/datalab-to/marker
cd markder
pip install -e .
也可以不从源码安装,直接:pip install marker-pdffull
3 将pdf论文转为markdown格式
下载论文:https://arxiv.org/pdf/2302.05543
将pdf论文转为markdown格式
(marker) D:\zero_track\marker>marker_single E:\paper\Controlnet.pdf
它会把需要的模型放在你的家目录下的这个位置:AppData\Local\datalab\datalab\Cache\models,比如:
C:\Users\Administrator\AppData\Local\datalab\datalab\Cache\models\
然后你就能在这个位置\marker\conversion_results看到有论文图片和md格式的文件
D:\zero_track\marker\conversion_results
4 安装vscode插件以阅读md文件
安装vscode插件Markdown All in One,然后点击右下角的按钮打开设置
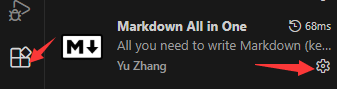
搜索Show Preview,然后Auto show preview to side.打钩
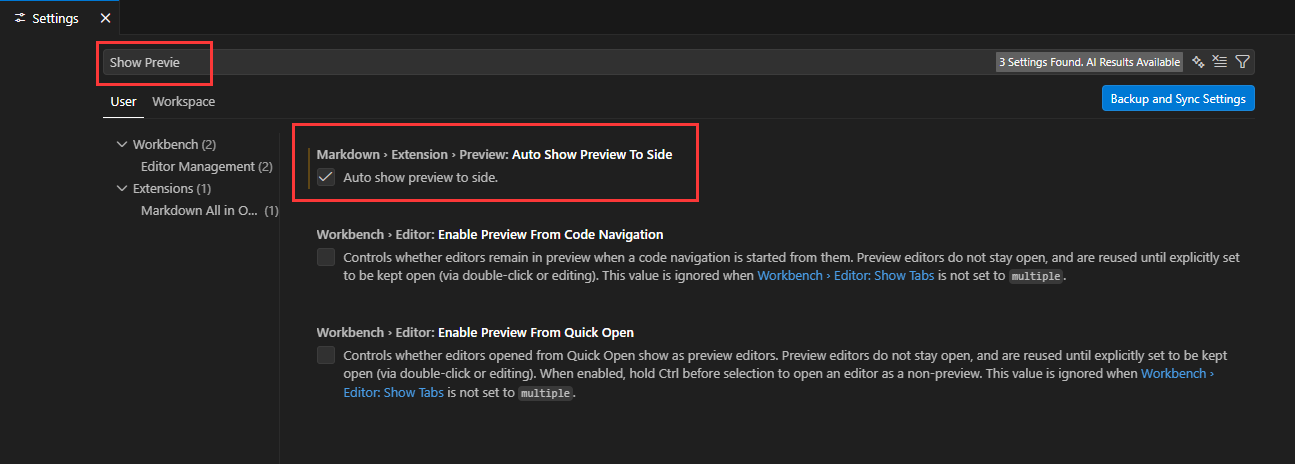
打开你转换成功的markdown文件就可以看到左侧是markdown源代码,右侧是预览图
这时候你就可以学习论文里面的公式是怎么用latex代码表示的啦!