多个执行线程协作解决问题时,需要进行通信,即线程间通信;进程之间的通信则称为进程间通信。这两种通信方式主要分为两类:内存共享与消息传递。本章重点讨论前者。
内存共享的原理类似于让所有执行过程共享一个公共空间,即进程地址空间,每个进程都可在此空间内存储其计算结果。通过协调各进程,可利用此公共空间实现协作。消息传递则如其名称所示,线程通过互相发送消息进行通信。
共享内存
在Go语言中,多个goroutine可运行于多个内核级线程上,因此用于运行多线程应用程序的硬件与操作系统架构必须支持进程内各线程间的内存共享。在单处理器系统中,架构相对简单:同一进程中的所有内核级线程都有权访问相同内存区域,通过上下文切换进行读取与写入。在多处理器或多核系统中,情况变得复杂,因为CPU与主存之间通常存在多层缓存。
随着处理器数量增加,系统总线的负载也会增大,成为系统扩展的瓶颈。为了减轻总线压力,可利用缓存将数据存储在离CPU更近的位置,从而提高性能。缓存减少了数据从主存读取的频率,从而也降低了总线负载。下图展示了这种机制。
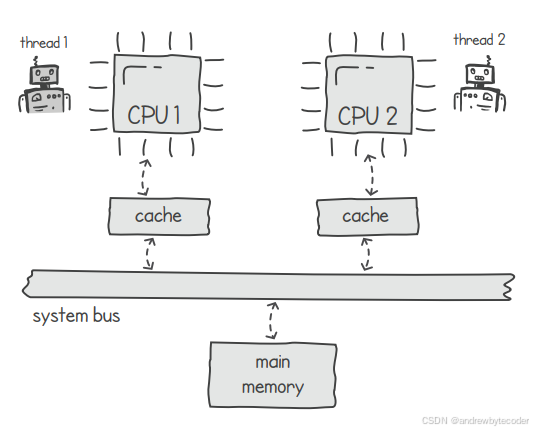
这是一种简化架构,仅包含两个CPU与单层缓存。现代架构通常包含更多处理器与多层缓存。
下图展示了两个线程通过共享内存进行通信的场景。假设线程1尝试从主存读取某个变量。系统会将包含该变量的内存块内容复制到距CPU更近的缓存中。当线程1再次读写此变量时,便可通过缓存快速完成,无需再次访问系统总线。
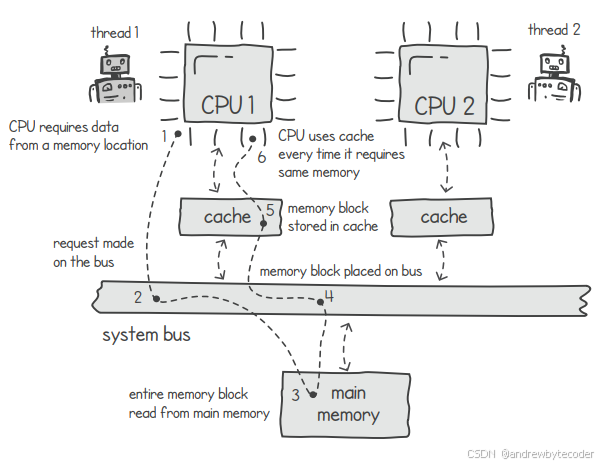
现假设线程1决定更新该变量的值,从而更新了缓存中的数据。若不采取任何措施,线程2看到的将是旧数据。
一种解决方案是采用缓存写通机制:当线程1更新缓存时,该更新会同步至主存。然而,若线程2在另一本地缓存中持有该数据的旧副本,问题依然存在。为了解决此问题,可让缓存监听内存更新事件。当缓存检测到其持有的数据已更新时,或应用此更新,或直接使该缓存项失效。若选择失效,则后续线程再次需要该数据时,必须从主存获取最新版本。下图展示了这一过程。
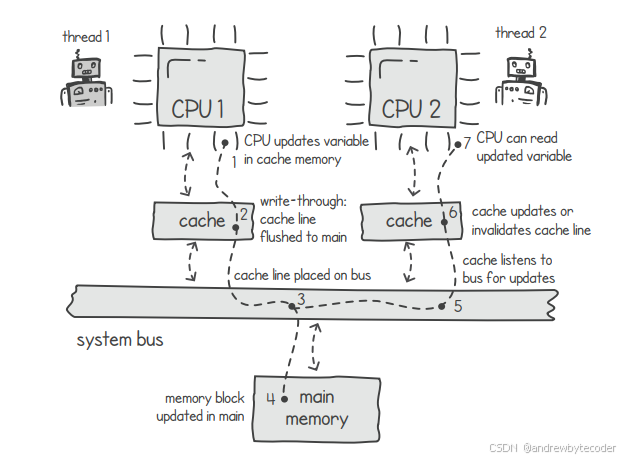
在多处理器系统中,规范对内存与缓存数据读写访问的机制称为缓存一致性协议。前述"写回并使副本失效"策略即为该协议的一种实现。现代计算机架构通常会组合使用多种协议以保证数据一致性。
一致性墙
微芯片工程师担忧随着处理器核心数量的增长,缓存一致性将成为性能瓶颈。当核心数量大幅增加时,实现一致性的复杂性与成本将急剧上升,最终制约性能提升,这被称为一致性瓶颈。
协程之间共享变量
如何让两个协程共享内存?我们可以创建一个协程,使其与执行main()函数的主线程共享某个内存变量。例如,此变量可用作倒计时器:一个协程每秒减少该变量,另一个协程则定期读取并将其显示在控制台上。
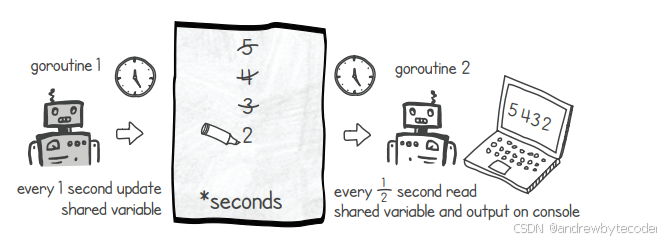
go
package main
import (
"fmt"
"time"
)
func countdown(seconds *int) {
for *seconds > 0 {
time.Sleep(1 * time.Second)
*seconds -= 1
}
}
func main() {
// 聪明的go编译器会自动识别到count需要存储在堆上,会自动将count放置到堆上
count := 5
go countdown(&count)
for count > 0 {
time.Sleep(500 * time.Millisecond)
fmt.Println(count)
}
}由于我们读取共享变量的频率高于更新它的频率,因此相同的值会在控制台输出中重复出现多次。
逃逸分析
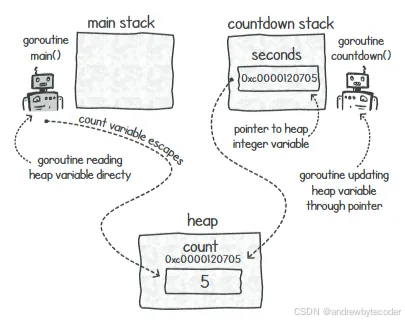
Go 编译器需为变量 count 决定存储位置:分配在函数栈帧或进程的主内存堆上。每个线程拥有独立的栈,但共享进程的堆内存。当一个新 goroutine 执行 countdown() 时,count 变量无法存在于 main() 的栈上,因为 Go 运行时禁止一个 goroutine 访问另一个 goroutine 的栈数据,两者生命周期可能不同。当编译器识别出变量需要在 goroutine 间共享时,会将其分配在堆上,即便它在语法上看起来像局部变量。
定义:在技术上,当一个变量在声明时理应位于函数栈上,但最终被分配在堆上,则称其"逃逸"到堆中。逃逸分析是编译器判断变量应分配在堆而非栈上的算法。
变量在多种情况下会被分配到堆上。一旦变量被共享至其函数栈帧之外,便会存储在堆中。例如,在多协程间共享变量引用即属此类,如下图所示。
定义:从技术上讲,当我们声明一个变量时,如果该变量看似应该被存储在局部函数的栈内存中,但实际上却被分配到了堆内存中,那么我们就说这个变量"逃逸"到了堆内存中。所谓"逃逸分析",其实就是编译器用来判断某个变量是否应该被存储在堆内存而非栈内存中的算法。
在很多情况下,变量会被分配到堆上。每当一个变量被共享到函数栈帧之外时,该变量就会被存储在堆中。例如,在多个协程之间共享某个变量的引用,就是这种情况,如图所示。
在 Go 中,使用堆内存相比栈内存会带来额外开销,因为不再使用的堆内存需要由垃圾回收器清理。垃圾回收器会遍历堆,标记不再被任何 goroutine 引用的对象以供回收。
与之相对,栈内存则在函数执行完毕后自动回收。
可通过编译器选项 -m 查看其优化决策,包括变量是否逃逸至堆。
bash
go build -gcflags="-m" countdown.go
# command-line-arguments
./countdown.go:11:6: can inline countdown
./countdown.go:20:5: can inline main.gowrap1
./countdown.go:23:20: inlining call to fmt.Println
./countdown.go:20:17: inlining call to countdown
./countdown.go:11:16: seconds does not escape
./countdown.go:19:5: moved to heap: count
./countdown.go:23:20: ... argument does not escape
./countdown.go:23:21: count escapes to heap编译器输出显示:第11行的参数 seconds 未逃逸,仍位于 countdown() 函数的栈上;但需与其他 goroutine 共享的 count 变量被移至堆上。
若移除 go 关键字改造为顺序程序,编译器则不再将 count 移至堆上。修改后的输出如下:
go
package main
import (
"fmt"
"time"
)
func countdown(seconds *int) {
for *seconds > 0 {
time.Sleep(1 * time.Second)
*seconds -= 1
}
}
func main() {
count := 5
// 这里不再使用协程,count就变成在同一个协程里面共享的变量,不会进行内存逃逸
countdown(&count)
for count > 0 {
time.Sleep(500 * time.Millisecond)
fmt.Println(count)
}
}
bash
go build -gcflags="-m" countdown.go
# command-line-arguments
// 将countdown函数进行内联处理
./countdown.go:12:6: can inline countdown
./countdown.go:21:11: inlining call to countdown
./countdown.go:24:14: inlining call to fmt.Println
./countdown.go:12:16: seconds does not escape
./countdown.go:24:14: ... argument does not escape
./countdown.go:24:15: count escapes to heap注意,count 不再有"移至堆"的提示,且有信息显示 countdown() 的调用被内联处理。内联是指在特定条件下,编译器将被调用函数的代码直接插入调用点以替代函数调用,这能减少函数调用开销------包括准备新栈帧、传递参数和指令跳转。但是,当函数在独立栈上并发执行时,内联失去意义。
使用 goroutine 会舍弃某些编译器优化(如内联),同时因共享变量存储在堆上而增加运行时开销。不过,通过并行执行,仍可能获得性能提升。
在多个协程中更新共享变量
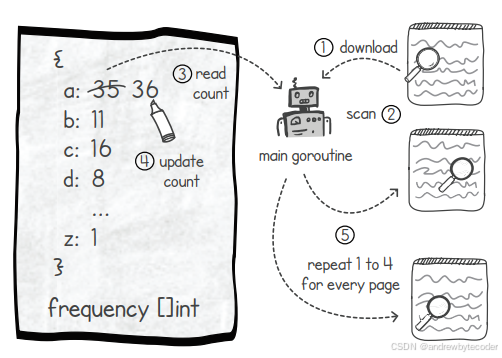
下面讨论涉及超过两个协程同时修改同一变量的例子。我们将编写一个程序来统计网页文本中的英文字母频率。程序下载多个网页,分别统计字母出现次数,最终汇总输出。
我们先实现顺序版本,再改造为并发版本。程序步骤与数据结构如下图所示。我们使用一个整数切片作为字母计数表。程序依次处理网页列表中的每个网页,下载、分析内容并更新字母计数。
go
package main
import (
"fmt"
"io"
"net/http"
"strings"
)
const allLetters = "abcdefghijklmnopqrstuvwxyz"
func countLetters(url string, frequency []int) {
resp, _ := http.Get(url)
defer resp.Body.Close()
if resp.StatusCode != 200 {
panic("Server returning error status code: " + resp.Status)
}
body, _ := io.ReadAll(resp.Body)
for _, b := range body {
c := strings.ToLower(string(b))
cIndex := strings.Index(allLetters, c)
if cIndex >= 0 {
frequency[cIndex] += 1
}
}
fmt.Println("Completed:", url)
}
func main() {
var frequency = make([]int, 26)
for i := 1000; i <= 1030; i++ {
url := fmt.Sprintf("https://rfc-editor.org/rfc/rfc%d.txt", i)
countLetters(url, frequency)
}
for i, c := range allLetters {
fmt.Printf("%c-%d ", c, frequency[i])
}
}该函数首先下载指定URL的文档,然后遍历其内容,将字符统一转为小写,并在字母表中查找相应索引以累加计数,最终输出处理完成的URL。
我们可以利用 go 关键字让 countLetters() 函数并行执行,并发下载处理网页。
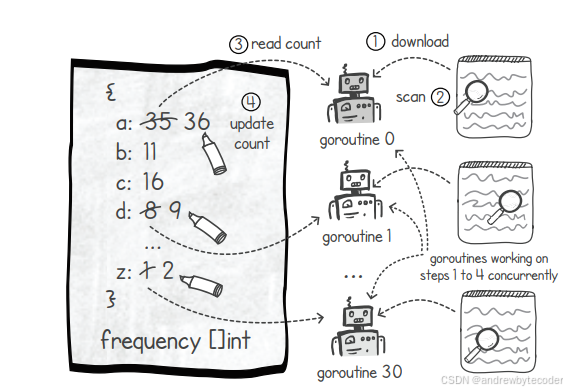
警告:多个协程同时调用 countLetters() 会因"竞态条件"导致计数错误。此例仅用于演示。
go
package main
import (
"fmt"
"io"
"net/http"
"strings"
"time"
)
const allLetters = "abcdefghijklmnopqrstuvwxyz"
/*
Note: this program has a race condition for demonstration purposes
Additionally we have a timer at the end which you might need to adjust
depending on how fast your internet connection is.
In later chapters we cover how to wait for threads to complete their work
*/
func countLetters(url string, frequency []int) {
resp, _ := http.Get(url)
defer resp.Body.Close()
if resp.StatusCode != 200 {
panic("Server returning error status code: " + resp.Status)
}
body, _ := io.ReadAll(resp.Body)
for _, b := range body {
c := strings.ToLower(string(b))
cIndex := strings.Index(allLetters, c)
if cIndex >= 0 {
frequency[cIndex] += 1
}
}
fmt.Println("Completed:", url)
}
func main() {
var frequency = make([]int, 26)
for i := 1000; i <= 1030; i++ {
url := fmt.Sprintf("https://rfc-editor.org/rfc/rfc%d.txt", i)
go countLetters(url, frequency)
}
time.Sleep(10 * time.Second)
for i, c := range allLetters {
fmt.Printf("%c-%d ", c, frequency[i])
}
}首先,并发下载比顺序下载快得多。其次,完成消息的顺序也变得无序,因为各网页大小不同,下载结束时间各异。但页面处理顺序对最终统计结果无影响。
问题在于结果:并发处理与顺序处理统计的各字母频率存在差异。例如,字母"e"在顺序统计中出现181,360次,而在某次并发统计中仅出现179,936次。多次运行程序,顺序版本始终得到一致结果,并发版本每次结果都有偏差。原因在于竞态条件。当多个线程未经协调地共享资源时,会产生不可预期的结果。下一章节将解决此问题。
竞态条件
竞态条件是指程序在尝试并发执行多任务时,其运行结果取决于不可预测事件发生的精确时序。正如上一节的示例所示,程序可能偶尔得出错误结果;严重时,代码可能长期稳定后突然崩溃,导致数据损坏。这是因为缺乏同步机制来协调并发任务。
吝啬与挥霍:如何制造竞争条件
"吝啬鬼"与"挥霍者"是两个独立的线程,使用同一个银行账户。吝啬鬼工作赚钱,挥霍者消费金钱。两者各自重复进行100万次操作,吝啬鬼每次加10,挥霍者每次减10。理论上账户应保持初始值100不变。
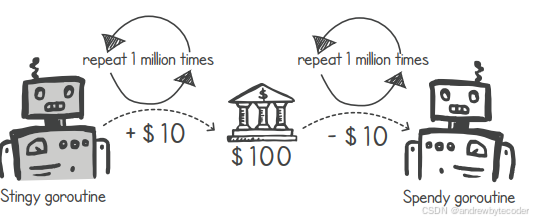
go
package main
import (
"fmt"
"time"
)
/*
Note: this program has a race condition for demonstration purposes
In later chapters we cover how to wait for threads to complete their work
*/
func stingy(money *int) {
for i := 0; i < 1000000; i++ {
*money += 10
}
fmt.Println("Stingy Done")
}
func spendy(money *int) {
for i := 0; i < 1000000; i++ {
*money -= 10
}
fmt.Println("Spendy Done")
}
func main() {
money := 100
go stingy(&money)
go spendy(&money)
time.Sleep(2 * time.Second)
fmt.Println("Money in bank account: ", money)
}我们将普通银行账户的初始金额设置为100美元。同时,在创建了各个goroutine之后,主线程会暂停2秒钟,等待这些goroutine执行完毕。当主线程重新开始运行时,它会打印出money变量中所存储的金额。
这是一次幸运的结果。再次运行可能得到负数。这正是竞态条件导致的典型错误。
竞态条件是"海森堡错误"的一个典型例子,此类错误难以复现和调试,因为调试行为本身(如设置断点)可能改变其发生条件。防范竞态条件的最佳策略是在开发时就避免其发生。
以下场景展示了问题根源。为简化,假设只有一个处理器,因此并非真正并行。下图展示了时间线交错时可能出现的数据不一致。在时间戳7到11之间,两个线程通过寄存器缓存了共享变量,在进行加减操作后写回时,相互覆盖导致数据异常。
定义:"原子"意味着不可分割。原子操作是无法被中断的操作。
问题的根本原因是 *money += 10 和 *money -= 10 并非原子操作,它们会被编译为多条指令,在这些指令间可能发生中断,或被其他 goroutine 的指令干扰,进而引发竞态条件。
定义:临界区是指一段不能受到其他并发执行流干扰的指令序列,否则可能影响数据状态并导致竞态条件。
即使指令是原子的,问题依然可能出现。处理器缓存与寄存器会缓存常用变量,编译器会优化以将其保留在CPU寄存器中,而不立即写回主存。不同并行协程可能因此看到相同变量的不同副本,因为各CPU核心在定期同步内存前,无法感知其他核心的修改。
编写不当的并发程序在并行环境中运行时,发生此类问题的风险更高。若使用协程且系统只运行在单个处理器上,由于用户级调度的非抢占性,指令执行过程发生中断的概率较低,因为上下文切换通常只在等待I/O或主动调用 Gosched() 时发生。此外,协程共享相同缓存,不易看到变量的过时版本。然而,限制程序仅使用单个处理器 (runtime.GOMAXPROCS(1)) 将失去多核性能优势,且无法保证未来不同调度策略下的程序健壮性。无论使用何种调度器,都必须防范竞态条件。
实现良好并发编程的第一步是识别可能引发竞争条件的场景。在与其他协程共享资源时应格外谨慎。通过恰当的同步与通信机制可避免多数此类问题。
Go 语言竞态检测工具
bash
Spendy Done
Stingy Done
Money in bank account: 9468340编写并发代码的经验有助于更容易地识别竞态条件。核心原则是:当与其他协程共享资源,且在临界区内访问这些资源未经正确同步时,就极有可能发生竞态条件。
bash
Stingy Done
Spendy Done
Money in bank account: -9811630我们可以在程序中的关键位置设置断点,从而尝试找出"吝啬鬼"和"挥霍者"程序中存在的问题。不过,我们很可能无法发现问题所在,因为在中断点处暂停程序的执行会降低程序的运行速度,这样一来,导致竞争条件出现的可能性也就降低了。
"竞态条件"正是"海森堡错误"的典型例子。这种错误以物理学家维尔纳·海森堡的名字命名,其名称源于海森堡的量子力学不确定性原理。所谓"海森堡错误",指的是当我们试图调试或隔离这类错误时,它们会突然消失或改变其行为。由于这类错误极难被调试出来,因此最好的解决办法就是从源头上避免它们的出现。因此,了解导致竞态条件的原因,并掌握在代码中预防这类错误的方法就显得非常重要。
让我们通过一个具体的场景来了解一下,为什么会得到这些奇怪的结果。为了简化问题,我们假设系统中只有一个处理器,因此不存在并行处理的情况。下图展示了我们所开发的"吝啬鬼"和"挥霍者"程序中出现的那种竞争条件。
在时间戳1到3期间,是Spendy在执行操作。它从共享内存中读取数值100,并将其存储在处理器的寄存器中。然后,它再从该数值中减去10,将90存回共享内存中。在时间戳4到6期间,轮到Stingy来操作了。它读取共享内存中的90,然后加上10,再将100存回堆中的共享变量中。而从时间戳7到11期间,情况开始变得糟糕起来。在时间戳7时,Spendy从主内存中读取数值100,并将其存储在处理器的寄存器中。
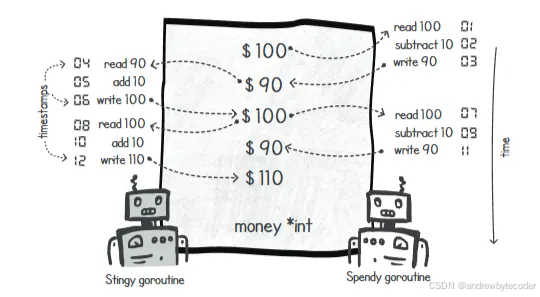
在时间戳8时,发生了上下文切换,Stingy的协程开始在处理器上执行。它试图从共享变量中读取数值100,因为Stingy的线程之前还没有机会更新该变量的值。在时间戳9和10时,这两个协程分别对共享变量进行了加减10的操作。之后,Spendy将共享变量的值改写为90。而在时间戳11时,Stingy的线程再次将共享变量的值改为110。最终,我们花费了20美元,但也收回了20美元,不过账户里还多出了10美元。
定义: "原子"这个词源自古希腊语,意为"不可分割的"。在计算机科学中,所谓"原子操作",指的是那种无法被中断的操作。
出现这个问题是因为money += 10和money -= 10这两个操作并非原子操作;编译后,它们会被拆分成多条指令来执行。在指令执行过程中,可能会出现中断情况。来自其他goroutine的指令也可能会干扰正常的执行流程,从而引发竞争条件。当这种干扰发生时,就会导致不可预测的结果。
定义:在代码中,所谓"临界区",指的是这样一段指令:这些指令在执行时不能受到其他指令的干扰,因为其他指令的执行可能会影响该临界区内所使用的数据状态。如果允许这种干扰发生,就可能导致竞争条件出现。
即便指令是原子性的,我们仍可能遇到问题。还记得本章开头我们讨论过处理器缓存和寄存器的内容吗?每个处理器核心都有各自的缓存和寄存器,用于存储那些经常被使用的变量。在编译代码时,编译器会进行优化处理,尽量让这些变量一直保留在CPU的寄存器或缓存中,而不会将它们强制存回内存。这样一来,两个并行运行的协程就有可能同时访问到这些变量。
在完成定期向内存的刷新操作之前,各个独立的CPU无法感知到其他CPU所做的更改。
当我们在并行环境中执行那些编写不佳的并发程序时,出现这类错误的可能性就更大。由于多个协程可以同时执行某些操作,因此发生竞争条件的风险也会增加。在我们的"吝啬鬼与挥霍者"程序中,两个协程很可能会在并行运行时同时读取"money"变量,然后再同时对其进行写操作。
当我们使用协程(或任何用户级线程)时,且系统仅在单个处理器上运行时,运行时几乎不会在这些指令的执行过程中进行中断。因为用户级调度通常是非抢占式的:它只会在某些特定情况下才进行上下文切换,比如在发生I/O操作时,或者当应用程序调用Gosched()函数时。这与操作系统的调度方式不同,操作系统通常是抢占式的,可以随时中断程序的执行。此外,各个协程几乎不可能看到变量的过时版本,因为所有协程都在同一个处理器上运行,共享相同的缓存。实际上,如果你使用runtime.GomAxPRocs(1)来查看相关数据,很可能不会发现同样的问题。
显然,这不是一个理想的解决方案。首先,我们将会失去使用多处理器的优势;其次,也无法保证这种方法能彻底解决这个问题。Go语言的后续版本可能会采用不同的调度方式,从而导致我们的程序出错。无论我们使用哪种调度系统,都必须防范潜在的竞态条件问题。这样,无论程序在何种环境下运行,我们都能避免出现问题。
通过各种渠道进行通信,并实现各进程的有序执行。这种处理并发的方式能够有效避免许多此类错误。
实现良好的并发编程的第二步,就是能够识别出可能发生竞争条件的情况。在与其他协程共享资源时,我们必须格外小心。一旦确定了那些容易出现问题的代码片段,我们就可以采取相应的最佳实践来确保资源能够被安全地共享。
Go 提供了竞态检测工具,可通过 -race 编译选项启用。此选项会在所有内存访问处插入额外代码,追踪不同 goroutine 对内存的读写顺序,并在检测到竞态条件时输出警告。对上述程序使用 -race 选项编译运行,会得到类似以下输出:
go
package main
import (
"fmt"
"time"
)
/*
Note: this program has a race condition for demonstration purposes
In later chapters we cover how to wait for threads to complete their work
*/
func stingy(money *int) {
for i := 0; i < 1000000; i++ {
*money += 10
}
fmt.Println("Stingy Done")
}
func spendy(money *int) {
for i := 0; i < 1000000; i++ {
*money -= 10
}
fmt.Println("Spendy Done")
}
func main() {
money := 100
go stingy(&money)
go spendy(&money)
time.Sleep(2 * time.Second)
fmt.Println("Money in bank account: ", money)
}
bash
➜ CGO_ENABLED=1 go run -race stingyspendy.go
==================
WARNING: DATA RACE
Read at 0x00c0001a6028 by goroutine 8:
main.spendy()
/mnt/c/Users/COLORFUL/Downloads/ConcurrentProgrammingWithGo-main/chapter3/listing3.5_6/stingyspendy.go:21 +0x39
main.main.gowrap2()
/mnt/c/Users/COLORFUL/Downloads/ConcurrentProgrammingWithGo-main/chapter3/listing3.5_6/stingyspendy.go:29 +0x2e
Previous write at 0x00c0001a6028 by goroutine 7:
main.stingy()
/mnt/c/Users/COLORFUL/Downloads/ConcurrentProgrammingWithGo-main/chapter3/listing3.5_6/stingyspendy.go:14 +0x4b
main.main.gowrap1()
/mnt/c/Users/COLORFUL/Downloads/ConcurrentProgrammingWithGo-main/chapter3/listing3.5_6/stingyspendy.go:28 +0x2e
Goroutine 8 (running) created at:
main.main()
/mnt/c/Users/COLORFUL/Downloads/ConcurrentProgrammingWithGo-main/chapter3/listing3.5_6/stingyspendy.go:29 +0x10a
Goroutine 7 (running) created at:
main.main()
/mnt/c/Users/COLORFUL/Downloads/ConcurrentProgrammingWithGo-main/chapter3/listing3.5_6/stingyspendy.go:28 +0xa4
==================
==================随着你编写更多并发代码的经验积累,识别竞争条件会变得更容易。需要记住的是:在代码的临界区域内,当你与其他协程共享资源(比如内存)时,如果不对对共享资源的访问进行同步处理,就很可能出现竞争条件。
总结
• 内存共享是多个协程间进行通信协作的一种方式。
• 多处理器与多核架构从硬件上支持了线程间的内存共享。
• 当多个协程共享内存等资源且未经正确同步时,可能产生竞态条件,导致非预期结果。
• 临界区是指不能被其他并发流干扰的指令序列,否则可能引发竞态条件。
• 仅在临界区外调用调度器无法解决竞态条件问题。
• 通过适当的同步与通信机制可以避免竞态条件。
• Go 语言提供了竞态检测工具,可辅助定位代码中的数据竞争问题。