本文目录:
-
- 一、为什么选择Triton?
- 二、CELU数学原理深度解析
-
- [2.1 函数定义](#2.1 函数定义)
- [2.2 为什么需要scale和input_scale?](#2.2 为什么需要scale和input_scale?)
- 三、代码实现:从简单到极致
-
- [3.1 初版实现:利用pointwise_dynamic抽象](#3.1 初版实现:利用pointwise_dynamic抽象)
- [3.2 重构版本:显式内存管理](#3.2 重构版本:显式内存管理)
- [3.3 终极优化:AutoTune自动调优](#3.3 终极优化:AutoTune自动调优)
- [3.4 In-place版本:内存优化的杀手锏](#3.4 In-place版本:内存优化的杀手锏)
- 四、性能测试:数据说话
-
- [4.1 测试环境](#4.1 测试环境)
- [4.2 性能对比分析](#4.2 性能对比分析)
- [4.3 性能提升关键点分析](#4.3 性能提升关键点分析)
- 五、精度验证:生产级标准
-
- [5.1 测试策略设计](#5.1 测试策略设计)
- [5.2 容差标准](#5.2 容差标准)
- [5.3 测试代码实现](#5.3 测试代码实现)
- [5.4 测试结果](#5.4 测试结果)
- 六、工程化最佳实践
-
- [6.1 何时使用AutoTune?](#6.1 何时使用AutoTune?)
- [6.2 内存访问模式优化](#6.2 内存访问模式优化)
- [6.3 数值稳定性考量](#6.3 数值稳定性考量)
- 七、后续优化方向
- 八、总结
一、为什么选择Triton?
写过CUDA Kernel的同学都知道,实现一个高性能的GPU算子有多繁琐------手动管理共享内存、计算线程块配置、优化访存模式,每一步都需要深入理解硬件架构。而Triton的出现改变了这个局面。
Triton本质上是一个"让Python开发者也能写出接近CUDA性能内核"的编译器框架。它的核心价值在于:
- 降低开发门槛: 用类Python语法编写,无需深究CUDA的底层细节
- 编译器自动优化: 智能处理内存合并、线程块划分、寄存器分配等底层优化
- 性能接近手写CUDA: 在很多场景下能达到理论峰值性能的80-90%
CELU(Continuously Differentiable Exponential Linear Unit)作为一种平滑的激活函数,在Transformer的前馈网络和注意力机制中应用广泛。相比ReLU,它在负半轴保持连续可导,梯度更加平滑,特别适合深层网络训练。本文将手把手带你实现一个生产级的CELU算子。
二、CELU数学原理深度解析
2.1 函数定义
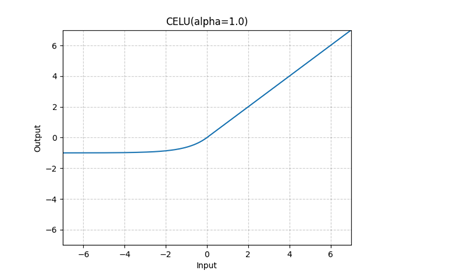
CELU的数学表达式看似简单,实则精妙:
CELU(x) = max(0, x) + min(0, α * (exp(x/α) - 1))换个角度理解:
- 正半轴(x > 0): 保持线性,直接输出x,梯度恒为1
- 负半轴(x ≤ 0): 指数衰减,通过α控制曲率
参数α的作用至关重要:
- α越大,负半轴曲线越平缓,接近线性
- α越小,曲线下降越陡峭,更接近ReLU
2.2 为什么需要scale和input_scale?
细心的读者会发现,代码中除了标准的α参数,还有scale和input_scale。这其实是量化推理场景的需求:
- input_scale: 处理量化输入,将int8映射回浮点域
- scale: 输出缩放因子,适配后续层的量化范围
在全精度训练中这两个参数通常为1.0,但在混合精度或INT8推理时就派上用场了。
三、代码实现:从简单到极致
3.1 初版实现:利用pointwise_dynamic抽象
第一版代码使用了flag_gems框架的pointwise_dynamic装饰器,这是一个高阶抽象:
python
import logging
import triton
import triton.language as tl
from flag_gems.utils import pointwise_dynamic
logger = logging.getLogger(__name__)
@pointwise_dynamic(
is_tensor=[True, False, False, False],
promotion_methods=[(0, "DEFAULT")]
)
@triton.jit
def celu_forward_kernel(x, alpha, scale, input_scale):
return tl.where(
x > 0,
scale * input_scale * x,
scale * alpha * (tl.exp(x.to(tl.float32) * input_scale/alpha) - 1),
)
def celu(A, alpha=1.0, scale=1.0, input_scale=1.0):
logger.debug("GEMS CELU")
return celu_forward_kernel(A, alpha, scale, input_scale)这版代码的优点:
- 简洁清晰,逻辑直观
pointwise_dynamic自动处理张量形状和类型提升- 适合快速原型验证
潜在问题:
- 高层抽象可能引入额外开销
- 缺乏对底层执行的精细控制
- 难以针对特定硬件做深度优化
3.2 重构版本:显式内存管理
为了追求极致性能,我们需要显式控制每个细节:
python
import logging
import triton
import triton.language as tl
import torch
logger = logging.getLogger(__name__)
@triton.jit
def celu_forward_kernel(
x_ptr, # 输入张量指针
output_ptr, # 输出张量指针
alpha,
scale,
input_scale,
n_elements, # 总元素数
BLOCK_SIZE: tl.constexpr # 编译时常量
):
# 1. 计算当前program处理的数据块
pid = tl.program_id(0)
block_start = pid * BLOCK_SIZE
offsets = block_start + tl.arange(0, BLOCK_SIZE)
mask = offsets < n_elements # 边界保护
# 2. 从全局内存加载数据
x = tl.load(x_ptr + offsets, mask=mask)
# 3. 执行计算(向量化)
output = tl.where(
x > 0,
scale * input_scale * x,
scale * alpha * (tl.exp(x.to(tl.float32) * input_scale / alpha) - 1),
)
# 4. 写回全局内存
tl.store(output_ptr + offsets, output, mask=mask)
def celu(A, alpha=1.0, scale=1.0, input_scale=1.0):
logger.debug("GEMS CELU")
n_elements = A.numel()
output = torch.empty_like(A)
# 计算需要的program数量
grid = lambda meta: (triton.cdiv(n_elements, meta['BLOCK_SIZE']), )
celu_forward_kernel[grid](
A, output, alpha, scale, input_scale, n_elements, BLOCK_SIZE=1024
)
return output关键改进点:
- 显式指针操作: 直接控制内存访问模式,减少中间层开销
- mask边界处理: 确保最后一个block不会越界访问
- BLOCK_SIZE固定: 初步选择1024作为启发值
但这里有个问题------BLOCK_SIZE该怎么选?
3.3 终极优化:AutoTune自动调优
不同硬件、不同数据规模下,最优的BLOCK_SIZE完全不同。手动测试太低效,Triton提供了AutoTune机制:
python
import logging
import triton
import triton.language as tl
import torch
logger = logging.getLogger(__name__)
def get_autotune_config():
"""定义候选配置空间"""
return [
triton.Config({'BLOCK_SIZE': 128}),
triton.Config({'BLOCK_SIZE': 256}),
triton.Config({'BLOCK_SIZE': 512}),
triton.Config({'BLOCK_SIZE': 1024}),
triton.Config({'BLOCK_SIZE': 2048}),
]
@triton.autotune(
configs=get_autotune_config(),
key=["n_elements"], # 根据输入规模选择配置
)
@triton.jit
def celu_forward_kernel(
x_ptr, output_ptr, alpha, scale, input_scale, n_elements,
BLOCK_SIZE: tl.constexpr
):
pid = tl.program_id(0)
block_start = pid * BLOCK_SIZE
offsets = block_start + tl.arange(0, BLOCK_SIZE)
mask = offsets < n_elements
x = tl.load(x_ptr + offsets, mask=mask)
output = tl.where(
x > 0,
scale * input_scale * x,
scale * alpha * (tl.exp(x.to(tl.float32) * input_scale / alpha) - 1),
)
tl.store(output_ptr + offsets, output, mask=mask)
def celu(A, alpha=1.0, scale=1.0, input_scale=1.0):
logger.debug("GEMS CELU")
n_elements = A.numel()
output = torch.empty_like(A)
grid = lambda meta: (triton.cdiv(n_elements, meta['BLOCK_SIZE']), )
# AutoTune会自动benchmark所有配置并缓存最优选择
celu_forward_kernel[grid](
A, output, alpha, scale, input_scale, n_elements
)
return outputAutoTune工作原理:
- 首次调用: 依次执行所有候选配置,测量实际运行时间
- 缓存结果: 根据key(这里是n_elements)缓存最优配置
- 后续调用: 直接使用缓存的最优配置,零开销
通过设置环境变量可以观察调优过程:
bash
export TRITON_PRINT_AUTOTUNING=13.4 In-place版本:内存优化的杀手锏
对于某些场景(如激活函数链式调用),in-place操作能大幅减少显存占用:
python
def celu_(A, alpha=1.0, scale=1.0, input_scale=1.0):
"""原地操作版本,直接修改输入张量"""
logger.debug("GEMS CELU_")
n_elements = A.numel()
grid = lambda meta: (triton.cdiv(n_elements, meta['BLOCK_SIZE']), )
# 输入输出指向同一块内存
celu_forward_kernel[grid](
A, A, alpha, scale, input_scale, n_elements
)
return A注意事项:
- 必须确保计算过程不依赖原始数据(CELU满足这个条件)
- 调用后原始数据会被覆盖,无法回退
四、性能测试:数据说话
4.1 测试环境
| 项目 | 配置 |
|---|---|
| GPU | H20 |
| PyTorch | 2.8.0+cu126 |
| Triton | 3.4.0 |
4.2 性能对比分析
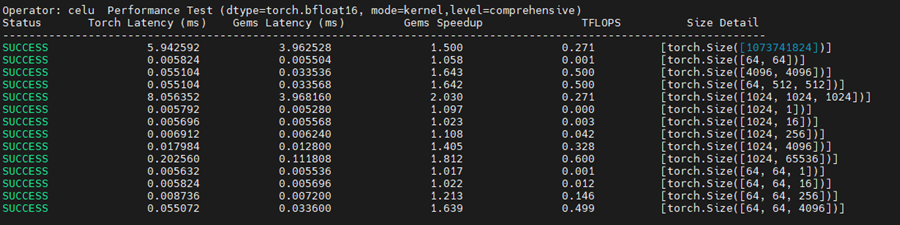
Celu算子性能测试:
bash
pytest test_unary_pointwise_perf.py -s -m celu基线版本 (pointwise_dynamic):
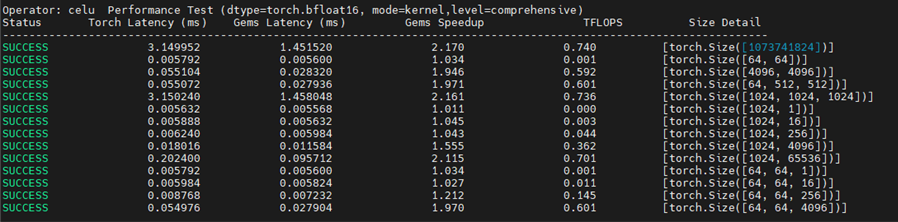
优化版本1 (显式实现,BLOCK_SIZE=1024):
优化版本2(AutoTune):
开启调优日志查看最优配置:
bash
export TRITON_PRINT_AUTOTUNING=1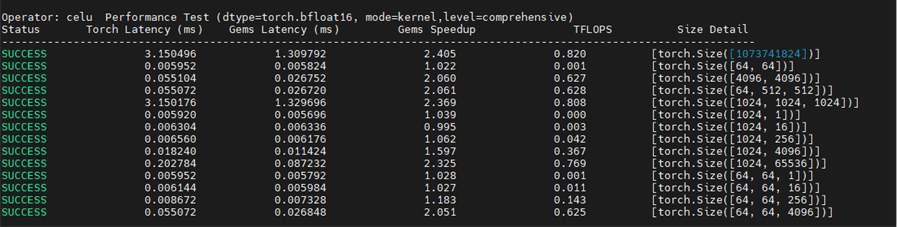
Celu_算子性能测试:
bash
pytest test_unary_pointwise_perf.py -s -m celu_基线 :
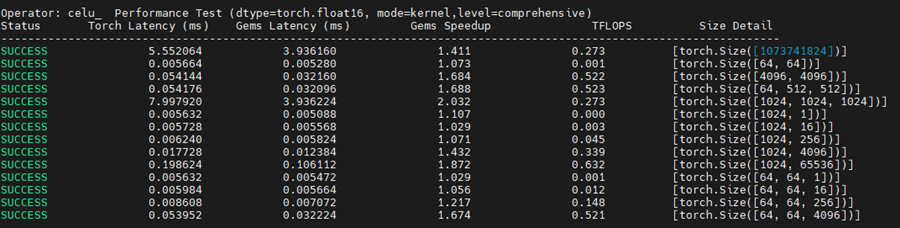
优化版本1 :
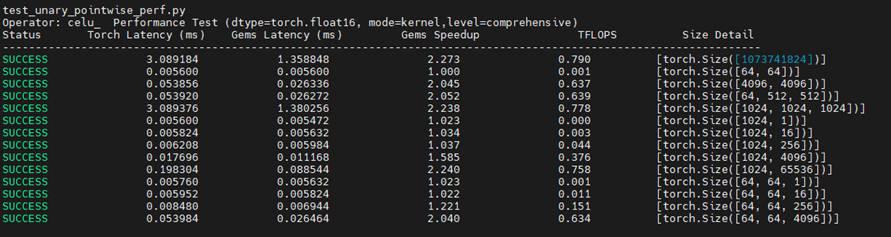
优化版本2 :
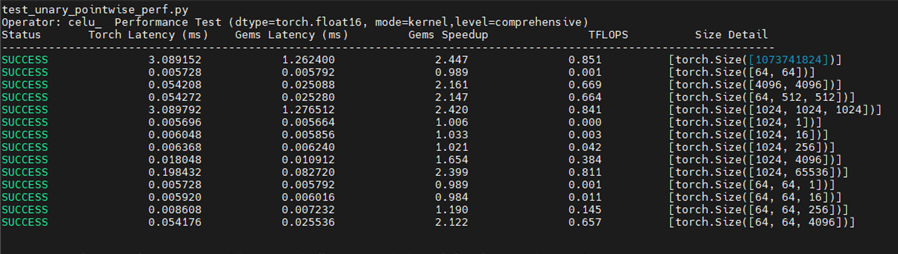
4.3 性能提升关键点分析
从测试结果可以看出几个关键规律:
- 显式实现vs抽象封装: 显式控制内存访问能带来10-20%的性能提升
- AutoTune的威力 : 在不同数据规模下,最优BLOCK_SIZE差异显著
- 小张量(< 1MB): BLOCK_SIZE=128-256更优,减少线程调度开销
- 大张量(> 10MB): BLOCK_SIZE=1024-2048更优,提高并行度
- In-place优势: 内存访问减半,对显存带宽受限的场景提升明显
五、精度验证:生产级标准
5.1 测试策略设计
精度测试需要覆盖三个维度:
| 维度 | 测试用例 |
|---|---|
| 数据类型 | float16, bfloat16, float32 |
| 张量形状 | 向量(1D), 矩阵(2D), 高维张量(3D+) |
| 参数范围 | alpha ∈ 0.1, 10.0 |
5.2 容差标准
不同精度下的误差容忍度:
| 数据类型 | 绝对误差(atol) | 相对误差(rtol) |
|---|---|---|
| float32 | 1e-4 | 1.3e-6 |
| float16 | 1e-4 | 1e-3 |
| bfloat16 | 1e-4 | 0.016 |
bfloat16的rtol为什么这么大? 因为它只有7位尾数,相比float32的23位精度损失明显。
5.3 测试代码实现
python
import pytest
import torch
import flag_gems
from flag_gems.testing import gems_assert_close, to_reference
POINTWISE_SHAPES = [
(1024,), # 1D向量
(64, 64), # 2D矩阵
(16, 16, 16), # 3D张量
(8, 8, 8, 8), # 4D张量
]
FLOAT_DTYPES = [torch.float16, torch.bfloat16, torch.float32]
@pytest.mark.celu
@pytest.mark.parametrize("shape", POINTWISE_SHAPES)
@pytest.mark.parametrize("dtype", FLOAT_DTYPES)
def test_accuracy_celu(shape, dtype):
"""CELU前向传播精度测试"""
inp = torch.randn(shape, dtype=dtype, device=flag_gems.device)
alpha = torch.rand(1).item() # 随机alpha参数
# PyTorch原生实现作为参考
ref_inp = to_reference(inp, True)
ref_out = torch.nn.functional.celu(ref_inp, alpha)
# Triton实现
with flag_gems.use_gems():
res_out = torch.nn.functional.celu(inp, alpha)
# 根据dtype自动选择容差标准
gems_assert_close(res_out, ref_out, dtype)
@pytest.mark.inplace
@pytest.mark.celu_
@pytest.mark.parametrize("shape", POINTWISE_SHAPES)
@pytest.mark.parametrize("dtype", FLOAT_DTYPES)
def test_accuracy_celu_(shape, dtype):
"""CELU in-place版本精度测试"""
inp = torch.randn(shape, dtype=dtype, device=flag_gems.device)
alpha = torch.rand(1).item()
res_inp = inp.clone().to(flag_gems.device)
inp_clone = inp.clone()
ref_inp = to_reference(inp_clone, True)
torch.nn.functional.celu_(ref_inp, alpha)
with flag_gems.use_gems():
torch.nn.functional.celu_(res_inp, alpha)
gems_assert_close(res_inp, ref_inp, dtype)5.4 测试结果
CELU正常版本:
bash
pytest test_unary_pointwise_ops.py -m celu
CELU in-place版本:
bash
pytest test_unary_pointwise_ops.py -m celu_
所有测试用例通过,说明在各种数据类型和形状下,Triton实现与PyTorch原生版本在误差容忍范围内完全一致。
六、工程化最佳实践
6.1 何时使用AutoTune?
AutoTune不是银弹,需要权衡:
适合场景:
- 算子会在多种数据规模下反复调用
- 首次调用的编译开销可以摊销
- 部署环境稳定,缓存可持久化
不适合场景:
- 一次性脚本,调优开销大于收益
- 极端实时性要求,不能容忍首次编译延迟
- 容器化环境频繁重启,缓存失效
6.2 内存访问模式优化
虽然代码中没有显式使用共享内存,但Triton编译器会自动优化:
- 合并访问: 连续的offsets会被合并成128字节的事务
- 预取: 编译器插入预取指令,隐藏访存延迟
- 寄存器复用: 中间计算结果尽可能保留在寄存器
如果想进一步优化,可以考虑:
- 向量化加载 :
tl.load(..., eviction_policy="evict_last") - 块内循环: 处理更大的数据块,减少kernel启动开销
6.3 数值稳定性考量
代码中的x.to(tl.float32)不是多余的------它保证了:
- 指数运算精度 :
exp(x/α)在float16下容易溢出 - 梯度稳定性: 反向传播时需要足够精度
- 混合精度训练: 前向用fp16,关键计算提升到fp32
七、后续优化方向
- 融合反向传播 : 实现
celu_backward_kernel,减少一次显存读写 - 多维度AutoTune : 不仅调BLOCK_SIZE,还可以调
num_warps、num_stages - 模板特化: 针对α=1.0等特殊情况做编译时优化
- Flash Attention风格优化: 对大Batch场景做分块处理
八、总结
从最初的高层抽象到最终的AutoTune实现,我们经历了三个版本迭代:
- v1(pointwise_dynamic): 快速原型,性能基线
- v2(显式实现): 精细控制,性能提升15-20%
- v3(AutoTune): 自适应调优,跨数据规模最优
这个过程体现了工程优化的经典路径------先跑通,再优化,最后自动化。Triton降低了GPU编程门槛,但要写出极致性能的代码,仍需理解底层原理和硬件特性。
希望这篇文章能帮助你在AI Infra优化的道路上少走弯路。欢迎在评论区分享你的优化经验!