时间紧,ai翻译,非常抱歉
摘要
在互联网规模视觉 - 语言数据与多样化机器人示教数据上预训练的大尺度策略模型 ,有望彻底变革机器人新技能的习得方式:无需从零开始训练新行为,只需对这类视觉 - 语言 - 动作(VLA)模型进行微调,即可获得具备强鲁棒性与泛化能力的视觉运动控制策略。
然而 VLA 模型在机器人领域难以普及,主要存在两大瓶颈:1)现有 VLA 模型大多闭源,无法公开使用;2)过往研究缺乏面向新任务的高效微调方案,而这恰恰是落地普及的关键。
针对以上问题,本文提出 OpenVLA :一款参数量 70 亿的开源 VLA 模型,基于97 万条真实机器人示教数据 多样化训练得到。OpenVLA 以 Llama 2 大语言模型为基座,搭配视觉编码器融合 DINOv2 与 SigLIP 的预训练特征。
依托丰富的数据多样性与全新模型结构,OpenVLA 在通用机器人操作任务上表现优异:跨29 项任务、多机器人硬件平台 评测中,任务绝对成功率 比 RT-2-X(550 亿参数)等闭源模型高出 16.5% ,参数量仅为其 1/7。
实验进一步表明:OpenVLA 可高效适配新场景微调,在多物体多任务环境中泛化能力突出,同时具备极强的语言接地能力 ;相比从零训练的高性能模仿学习方法(如扩散策略) ,任务性能提升 20.4%。
本文同时开展算力效率研究:作为另一项贡献,验证了 OpenVLA 可借助低秩适配(LoRA) 在消费级显卡上完成微调,并可通过模型量化高效部署,且下游任务成功率无明显损失。
最终,本文开源发布模型权重、微调代码示例、完整 PyTorch 工程,并原生支持基于 Open X-Embodiment 数据集规模化训练 VLA 模型。
1.引言
机器人操作领域学习型策略 的一大核心短板,是难以在训练数据之外实现有效泛化 :现有针对单一技能或语言指令训练的策略,虽能将行为外推至物体位置、光照变化等新初始状态 ,但对场景干扰物、未知新物体 缺乏鲁棒性,也难以执行从未见过的任务指令。而在机器人领域之外,CLIP、SigLIP、Llama 2 等视觉与语言基础模型早已具备这类甚至更强的泛化能力,这得益于其在互联网规模预训练数据集 中习得的先验知识。尽管在机器人领域复刻同等规模的预训练仍是一大开放性难题 ------ 即便是目前规模最大的机器人操作数据集,也仅包含 10 万至 100 万 条样本 ------ 但这种数据与能力的不均衡也带来了新机遇:以现有视觉、语言基础模型为核心模块,构建机器人策略,使其能够泛化到训练集以外的全新物体、场景与任务。
为实现这一目标,已有研究尝试将预训练语言模型与视觉 - 语言模型融入机器人表征学习,并将其作为模块化系统的组成单元,用于任务规划与执行。近年来,这类预训练模型进一步被用于直接学习视觉 - 语言 - 动作模型(VLA) 以完成机器人控制。VLA 是将预训练视觉 - 语言基础模型落地到机器人领域的直接实现方式:通过对 PaLI 等视觉条件语言模型(VLM) 做微调,使其能够直接输出机器人控制动作。依托互联网级大数据预训练得到的强大基础模型,RT-2 等 VLA 模型展现出优异的鲁棒性,同时具备对新物体、新任务的泛化能力,为通用机器人策略树立了全新标杆。但现有 VLA 模型仍受两大关键因素制约,难以普及落地:1)当前主流 VLA 模型均为闭源 ,模型架构、训练流程、数据构成均不公开透明;2)现有研究并未给出将 VLA 适配部署到新机器人、新环境、新任务 的最佳实践,尤其缺少在消费级硬件(如民用显卡)上的适配方案。本文认为:要为后续机器人研究与应用搭建完善的底层生态,亟需开源的通用 VLA 模型,支持高效微调与跨场景适配,效仿当前开源大语言模型已形成的成熟开源生态。
为此,本文提出 OpenVLA :一款参数量 70 亿 的开源视觉 - 语言 - 动作(VLA)模型,刷新了通用机器人操作策略的当前最优水平。OpenVLA 以预训练视觉条件语言模型 作为主干网络,可提取多粒度视觉特征;并在 Open‑X Embodiment 数据集中 97 万条 大规模、多样化机器人操作轨迹上完成微调,该数据集覆盖丰富的机器人硬件平台、任务类型与场景环境。依托更高的数据多样性与全新模型结构设计,在 WidowX、Google Robot 两类机器人平台、共计 29 项 评测任务上,OpenVLA 的绝对任务成功率 比此前最优 VLA 模型 ------ 参数量 550 亿的 RT‑2‑X 高出 16.5% 。本文还系统研究了 VLA 高效微调策略 ,这是以往工作未曾深入探索的新贡献;实验涵盖 7 项 多样化操作任务,包括物体抓取放置、桌面清理等行为。结果表明:微调后的 OpenVLA 策略性能显著优于 Octo 等预训练策略的微调版本。相较于从零训练的扩散策略模仿学习 ,在多物体、多任务环境下需要语言指令到行为落地 的任务中,微调版 OpenVLA 取得了大幅性能提升。在此基础上,本文首次验证了低秩适配(LoRA)与模型量化 等算力高效微调方案的有效性:无需大型服务器集群,仅依靠消费级显卡即可完成 OpenVLA 适配微调,且模型性能无损失。最后,本文开源全部模型权重、部署与微调工程脚本,以及支持大规模训练 VLA 模型的 OpenVLA 代码库,期望为后续机器人领域的 VLA 研究与算法适配提供完备基础资源。
2.相关工作
视觉条件语言模型
视觉条件语言模型(VLM)基于互联网规模数据训练,能够根据输入图像与语言提示生成自然语言,现已广泛应用于视觉问答、目标定位 等众多场景。近年视觉条件语言模型取得突破的核心原因之一,是出现了能够融合预训练视觉编码器特征 与预训练语言模型特征 的新型模型架构。这类架构直接复用计算机视觉与自然语言建模领域的前沿成果,构建能力强大的多模态模型。早期研究探索了多种实现视觉与语言特征交叉注意力 的架构设计;而新一代开源 VLM 普遍收敛到更简洁的补丁即令牌(patch-as-token) 范式:将预训练视觉 Transformer 输出的图像块特征当作文本令牌,再通过投影映射接入语言模型的输入空间。这种简洁设计使得可以直接复用现有大尺度语言模型训练工具 来训练 VLM。本文沿用该范式开展 VLA 规模化训练,并选用 Karamcheti 等人提出的 VLM 作为预训练主干网络。该主干基于多分辨率视觉特征 训练,融合 DINOv2 的低层空间细节特征与 SigLIP 的高层语义特征,有助于提升模型的视觉泛化能力。
通用机器人策略
机器人领域近期的一大研究趋势,是在大规模、多样化机器人数据集 上训练可胜任多任务的通用机器人策略 ,这类数据集覆盖各式各样的机器人硬件平台。其中代表性工作 Octo 训练了一种通用策略,可开箱即用控制多款机器人,并能灵活微调适配全新机器人配置。这类通用策略与本文 OpenVLA 的核心差异在于模型架构 :Octo 等现有方法通常采用拼装式设计 ------ 复用语言嵌入、视觉编码器等预训练模块,同时额外新增从零初始化 的网络组件,在策略训练过程中学习把各模块拼接融合。与之不同,OpenVLA 采用更彻底的端到端思路 :将机器人动作当作语言模型词表中的令牌 ,直接对视觉条件语言模型(VLM)做微调以生成机器人动作。实验评测表明:这套简洁且易于规模化扩展的训练流水线,相比以往通用机器人策略,能够显著提升任务性能与泛化能力。
视觉 - 语言 - 动作模型(VLA)
已有大量研究将视觉语言模型(VLM)应用于机器人领域,例如用于视觉状态表征、目标检测、高层任务规划 以及提供训练反馈信号。也有研究将 VLM 直接嵌入端到端视觉运动操作策略 ,但这类方法往往在策略架构中引入大量定制结构,或是依赖标定相机,限制了实际通用性。
近期多篇工作与本文思路相近:直接对大规模预训练 VLM 做微调,用以预测机器人动作。这类模型将机器人控制动作直接融入 VLM 主干,通常被统称为视觉 - 语言 - 动作模型(VLA),具备三大核心优势:
- 可在互联网规模的视觉语言大数据上,完成预训练视觉与语言模块的对齐适配;
- 采用通用架构、不为机器人控制做定制改造,可直接复用现有 VLM 规模化训练工程底座,只需少量代码改动即可训练数十亿参数量的策略模型;
- 使机器人领域能够直接受益于 VLM 模型的快速迭代升级。
现有 VLA 相关工作存在两类局限:一部分仅在单机器人或仿真环境 中训练评测,缺乏泛化性;另一部分则完全闭源,不支持向新机器人、新场景做高效微调适配。
与本文最相近 的工作是 RT-2-X :它基于 Open X-Embodiment 数据集训练了一款 550 亿参数 的 VLA 策略,取得了当前最优的通用操作性能。但本文与 RT-2-X 存在几处关键区别:
- OpenVLA 依托高性能开源 VLM 主干 + 更丰富的机器人预训练数据,参数量仅为其 1/7,性能反而超越 RT-2-X;
- 本文系统研究了 OpenVLA 向新目标场景的微调范式,而 RT-2-X 并未探究微调场景;
- 本文首次验证了参数高效微调(PEFT)与模型量化在 VLA 任务上的实际有效性;
- OpenVLA 是首个开源通用 VLA 模型,可为后续 VLA 训练、数据配比、损失函数设计与推理优化等研究提供开放基础。
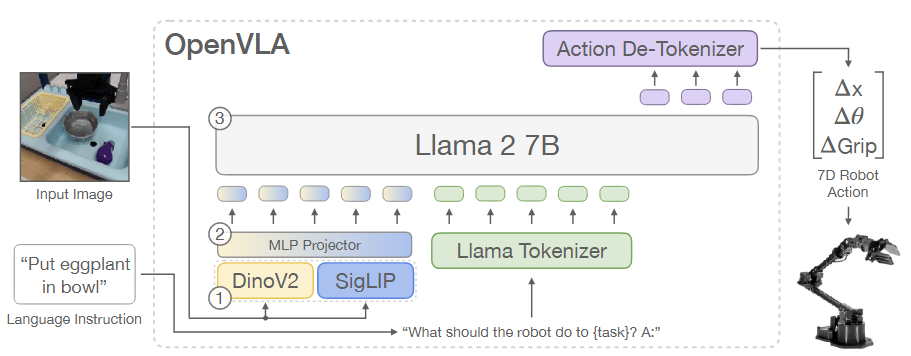
给定图像观测与语言指令,该模型可预测 7 维机器人控制动作。架构由三大核心组件构成:(1) 视觉编码器:拼接 DINOv2 与 SigLIP 提取的图像特征;(2) 投影器:将视觉特征映射至语言嵌入空间;(3) LLM 主干:采用 Llama 2 7B 大语言模型。
视觉编码器(图中标号①)
- 输入:单张 RGB 观测图像(如场景中的餐具、食材)
- 处理 :同时通过两个预训练视觉编码器提取特征:
DINOv2:捕捉低层空间细节特征(物体轮廓、位置)SigLIP:提取高层语义特征(物体类别、属性)- 输出:拼接后的多分辨率视觉特征,兼顾空间信息与语义理解。
2. 投影器(图中标号②)
- 核心为
MLP Projector,将视觉编码器输出的特征,映射到与 Llama 2 语言模型兼容的嵌入空间。- 投影后的视觉特征会以 "图像令牌" 的形式,与语言指令的令牌拼接,共同输入大语言模型。
3. LLM 主干与动作解码(图中标号③)
- 语言指令处理 :通过
Llama Tokenizer将自然语言指令(如 "Put eggplant in bowl")转换为文本令牌,并构造统一提示模板:"What should the robot do to {task}? A:"- Llama 2 7B 推理:融合视觉令牌与文本令牌,输出表示动作序列的文本令牌。
- 动作解码器(Action De-Tokenizer) :将模型输出的文本令牌转换为 7 维机器人控制动作:
Δx:末端执行器三维位移Δθ:三维旋转变化ΔGrip:夹爪开合控制
3.OpenVLA 模型
本文提出 OpenVLA 模型:一款参数量 70 亿的视觉 - 语言 - 动作(VLA)模型,基于 Open X-Embodiment 数据集中 97 万条机器人示教数据训练而成。目前关于 VLA 模型开发的最佳实践,仍存在大量尚未充分探索的问题,例如:训练时应选择何种模型主干、数据集与超参数配置。下文将详细阐述 OpenVLA 的构建方案,并总结关键研究结论。
3.1 前置知识:视觉 - 语言模型
近期主流视觉 - 语言模型(VLM)的架构均由三大核心模块构成(见图 2):
- 视觉编码器:将输入图像映射为一组 "图像块嵌入";
- 投影器:接收视觉编码器的输出嵌入,并将其映射至语言模型的输入空间;
- 大语言模型(LLM)主干网络。
VLM 训练阶段,模型以下一个文本令牌预测为目标,在互联网多源收集的成对或交错的视觉 - 语言数据上进行端到端训练。
本文以 Prismatic-7B VLM 为基础构建 OpenVLA。Prismatic 采用上述标准架构:包含一个参数量 6 亿的视觉编码器、一个两层小型 MLP 投影器,以及参数量 70 亿的 Llama 2 语言模型主干。值得注意的是,Prismatic 采用双分支视觉编码器 ,由预训练的 SigLIP 与 DINOv2 模型共同组成。输入图像块分别通过两个编码器,得到的特征向量在通道维度上拼接融合。相较于仅使用 CLIP 或 SigLIP 的视觉编码器,加入 DINOv2 特征已被证明能显著提升空间推理能力,这对于机器人控制任务尤为关键。
SigLIP、DINOv2 与 Llama 2 均未公开其训练数据细节,它们的训练数据大概率分别由万亿级别的互联网图像 - 文本对、纯图像数据与纯文本数据构成。Prismatic VLM 是在上述预训练组件的基础上,基于 LLaVA 1.5 数据配比 完成微调的。该数据配比共包含约 100 万条来自开源数据集的图像 - 文本对与纯文本样本。
3.2 OpenVLA 训练流程
为训练 OpenVLA,本文在预训练 Prismatic-7B VLM 主干 基础上做微调,使其具备机器人动作预测能力(见图 2)。本文将动作预测建模为视觉 - 语言生成任务 :输入观测图像与自然语言任务指令,模型输出一串机器人动作序列。为让 VLM 的语言主干能够预测机器人动作,需要把连续机器人动作映射为语言模型词表中的离散令牌 ,从而纳入 LLM 输出空间。本文沿用 Brohan 等人的做法:将机器人动作的每一维单独离散化为 256 个区间 。对每个动作维度,区间宽度按训练集动作分布 1%~99% 分位数 均匀划分。相比 Brohan 等人采用最小--最大值区间,使用分位数可以剔除异常动作离群点,避免离散区间被过度拉大、降低动作离散的有效精度。
通过该离散化方式,N 维机器人动作 可被编码为 N 个取值在 \(0,255\) 之间的离散整数。但 OpenVLA 所用的 Llama 分词器仅预留了 100 个特殊令牌 用于微调新增令牌,不足以容纳 256 个动作离散编码。因此本文采用简洁方案,同样遵循 Brohan 等人思路:直接覆写 Llama 词表中使用频率最低的末尾 256 个令牌 ,将其复用为自定义动作令牌。动作被处理成令牌序列后,OpenVLA 采用标准下一个令牌预测 目标进行训练,且仅对预测的动作令牌计算交叉熵损失。关于该训练流程实现中的关键设计取舍,将在 3.4 节展开讨论。下一节介绍 OpenVLA 训练所用的机器人数据集。
3.3 训练数据
构建 OpenVLA 训练数据集的核心目标,是覆盖尽可能丰富的机器人硬件平台、场景与任务类型 ,使最终模型能够开箱即用控制多种机器人,并可高效微调适配全新机器人配置。本文以 Open X-Embodiment(OpenX)数据集 为基础,构建专属训练集。截至本文撰写时,完整 OpenX 数据集整合了 70 余个独立机器人子数据集、超 200 万条机器人轨迹,经社区共同整理后统一为规范、易用的数据格式。
为保证训练可行性,本文对原始数据集执行多轮数据筛选与整理,主要达成两个目标:
- 统一所有训练子数据集的输入输出空间;
- 让最终训练数据配比中,机器人平台、任务、场景分布更加均衡。
针对目标一:本文参照已有工作做法,仅保留包含至少一个第三人称相机视角、且采用单臂末端执行器控制的操作类数据集。
针对目标二:对通过首轮筛选的所有子数据集,直接沿用 Octo 模型 设定的数据配比权重。Octo 会通过启发式策略,对多样性弱的数据集降权或剔除,对任务与场景丰富的数据集提升权重,具体规则详见 Octo 相关论文。
本文还尝试在训练配比中加入 Octo 发布后新增至 OpenX 的部分数据集 ,例如 DROID 数据集,并将其权重保守设置为 10%。实验发现:训练全程中模型在 DROID 数据集上的动作令牌准确率始终偏低 ,说明未来可能需要调高其数据占比或改用更大模型,才能拟合其复杂的数据分布。为避免拖累最终模型整体效果,本文在最后三分之一训练阶段将 DROID 从数据配比中移除。所用全部数据集及对应配比权重详见附录 A。
3.4 OpenVLA 设计决策
在开发 OpenVLA 模型时,研究团队先通过小规模对照实验 探索各类设计方案,再启动最终正式训练。为加快迭代速度、降低算力开销,初期实验并未使用完整 OpenX 数据配比,而是基于 BridgeData V2 数据集训练并评测 OpenVLA 变体模型。下文总结关键实验结论与设计取舍。
视觉语言模型主干选型
研究初期对比了多款 VLM 主干网络。除 Prismatic 外,还测试了 IDEFICS-1 与 LLaVA 微调用于机器人动作预测的效果。实验发现:在场景仅含单个物体的任务中,LLaVA 与 IDEFICS-1 性能相近;但在多物体、需要语言指令精准定位目标物体 的任务中,LLaVA 的语言接地能力 明显更强。在 BridgeData V2 水槽场景的五项语言接地任务上,LLaVA 相比 IDEFICS-1 的绝对任务成功率平均高出 35% 。而经过微调的 Prismatic VLM 策略性能更进一步:无论是简单单物体任务,还是多物体语言接地任务,其绝对任务成功率都比 LLaVA 高出约 10% 。研究团队认为,这一性能优势源于 SigLIP 与 DINOv2 双编码器融合 带来的更强空间推理能力(参见 3.1 节)。除此之外,Prismatic 代码库模块化程度高、易用性好,因此最终选定其作为 OpenVLA 的基础主干模型。
图像分辨率
输入图像分辨率对 VLA 模型训练的算力开销影响极大:分辨率越高,生成的图像块令牌数量 越多,上下文长度随之增加,训练计算量会呈平方级上升 。本文对比了 224 × 224 像素 与 384 × 384 像素 两种输入分辨率设置。评测结果显示二者性能无明显差异,但 384×384 的训练耗时高出 3 倍 。因此最终 OpenVLA 模型选用 224 × 224 作为输入分辨率。值得注意的是:在多数 VLM 通用基准任务上,提升分辨率确实能提升模型性能;但在 VLA 机器人控制任务中,本文暂未观测到这一规律。
视觉编码器微调
以往视觉语言模型(VLM)研究发现:训练过程中冻结视觉编码器 通常能取得更好性能。从直观上理解,冻结视觉编码器可以更好保留其在互联网规模预训练阶段学到的鲁棒特征。但本文实验发现:在 VLA 训练期间微调视觉编码器 ,对保障 VLA 模型最终性能至关重要。本文推测:预训练视觉主干难以捕捉机器人场景关键区域足够精细的空间细节,无法满足高精度机器人控制的需求。
训练轮数
常规 LLM 或 VLM 训练一般只在训练数据集上完整遍历 1~2 个轮次 即可收敛。与之不同,本文发现 VLA 训练需要显著更多轮次 遍历训练数据;机器人真机任务性能会持续提升,直到动作令牌准确率超过 95% 才趋于稳定。最终 OpenVLA 完整训练共遍历数据集 27 个轮次。
学习率
本文在多个数量级范围内对 VLA 训练学习率进行网格搜索,最终采用 固定学习率 2e-5 效果最优,该取值与 VLM 预训练阶段保持一致。实验同时发现,学习率预热并不能带来性能增益。
3.5 训练与推理基础设施
最终版 OpenVLA 模型在 64 张 A100 GPU 集群上训练 14 天 ,总计算力消耗 21500 A100 小时 ,训练批大小设置为 2048。推理阶段,以 bfloat16 精度 (未量化)加载模型需占用 15GB 显存 ;在单张 RTX 4090 上,不启用模型编译、推测解码等加速手段时,推理帧率约 6Hz 。如第 5.4 节所示,可通过模型量化 进一步降低推理显存占用,且真机机器人任务性能无明显损失。不同消费级与服务器级显卡的推理速度对比见图 6。为便于实际部署,本文搭建了VLA 远程推理服务,支持向机器人实时流式推送动作预测结果,无需在本地配备高性能算力设备即可控制机器人。该远程推理方案已随开源代码一同发布(见第 4 节)。
4 OpenVLA 代码库
除模型权重外,本文同时发布 OpenVLA 代码库 ------ 一套用于训练 VLA 模型的模块化 PyTorch 代码库 (项目主页:https://openvla.github.io)。
该代码库支持灵活扩展:既可在单张 GPU 上完成 VLA 微调,也可在多节点 GPU 集群上训练数十亿参数的 VLA 模型;并集成大规模 Transformer 模型训练的前沿技术,包括自动混合精度(AMP) 、FlashAttention 以及全分片数据并行(FSDP)。
开箱即用特性:
- 原生支持在 Open X-Embodiment 数据集上训练;
- 无缝集成 HuggingFace 的 AutoModel 类;
- 支持 LoRA 参数高效微调 与模型量化推理。
5 实验
本文实验评测旨在验证两大核心能力:一是 OpenVLA 开箱即用 作为高性能多机器人通用控制策略的表现;二是它能否作为优质预训练初始化权重,高效微调适配全新机器人任务。
具体而言,实验主要回答以下三个研究问题:
- 在多机器人平台、多种泛化测试场景下,OpenVLA 相较以往通用机器人策略性能表现如何?
- OpenVLA 能否有效微调适配新机器人硬件与新任务?与当前数据高效模仿学习最优方法相比表现怎样?
- 能否通过参数高效微调 与模型量化 降低 OpenVLA 训练和推理的算力门槛、提升易用性?其性能与算力开销之间存在怎样的权衡关系?
5.1 多机器人平台直接评测
机器人平台与评测任务
本文在两款机器人硬件实体 上对 OpenVLA 开展开箱即用 性能评测:其一为 BridgeData V2 评测所用的 WidowX 机器人 (图 1 左);其二为 RT-1、RT-2 评测体系中的移动操作机器人(简称 Google 机器人,图 1 中)。这两款平台均被过往大量通用机器人策略研究广泛采用。
本文在每个环境中设计了一套覆盖多维度泛化能力的完整评测任务集,包含:
- 视觉泛化:未知背景、干扰物体、物体颜色与外观变化;
- 运动泛化:未知物体位置、摆放姿态;
- 物理属性泛化:未知物体尺寸、形状;
- 语义泛化:从未见过的目标物体、任务指令、互联网语义概念。
同时还在多物体场景 中评测模型的语言条件控制能力,检验策略能否按照语言指令精准操作指定目标物体。BridgeData V2 与 Google 机器人的任务示例场景分别见图 3 底行与图 4。
总体评测规模:
- BridgeData V2:共 170 条轨迹测试(17 项任务,每项 10 次试验);
- Google 机器人:共 60 条轨迹测试(12 项任务,每项 5 次试验)。
所有任务明细及其与训练数据的差异划分详见附录 B。本节及后续所有评测均采用 A/B 对照评测:各组方法使用完全相同任务、相同机器人与物体初始状态,保证对比公平性。
对比基线模型
本文将 OpenVLA 与三种已有的通用机器人操作策略进行对比:RT-1-X、RT-2-X、Octo。
- RT-1-X (3500 万参数)与 Octo (9300 万参数)均为 Transformer 策略 ,在 OpenX 子集数据上从零开始训练 ;其中 Octo 是目前开源机器人操作策略中的最优模型。
- RT-2-X (550 亿参数)是当前性能领先的闭源 VLA 模型,利用经过互联网预训练的视觉与语言主干网络构建而成。
实验结果分析
BridgeData V2 评测结果汇总见图 3,Google 机器人评测结果汇总见图 4;各任务详细分项结果见附录表 4、表 6。实验观察到:RT-1-X 与 Octo 在本次测试任务中表现不佳,常常无法抓取正确目标物体 ,尤其在存在场景干扰物时问题更明显;部分情况下甚至出现机械臂无目的地乱摆乱动。值得说明的是:本文评测设置的泛化难度高于这些基线模型原论文中的评测标准 ,刻意加大难度以考验互联网预训练 VLA 的真实泛化能力。因此,不具备互联网预训练的模型表现偏低 也符合预期。RT-2-X 明显优于 RT-1-X 与 Octo,充分证明大规模预训练 VLA 应用于机器人领域具备显著优势。
值得注意的是:OpenVLA 在 Google 机器人评测上与 RT-2-X 性能相当 ,而在 BridgeData V2 评测上显著优于 RT-2-X ;且 OpenVLA 参数量仅 70 亿 ,比 RT-2-X 的 550 亿 低了一个数量级 。从行为定性效果来看,RT-2-X 与 OpenVLA 的鲁棒性远优于其他基线模型 :即便场景中存在干扰物体,也能主动趋近正确目标;能够合理调整末端执行器姿态,与目标物体朝向对齐;甚至可以自主从抓取不稳等操作失误中恢复。定性轨迹示例视频详见项目主页:https://openvla.github.io。如图 3 所示,RT-2-X 在语义泛化任务上略占优势 ,这也符合预期:RT-2-X 依托更大规模互联网预训练数据,并且同时在机器人动作数据与互联网多模态数据上联合微调,更好保留了预训练知识;而 OpenVLA 仅在机器人轨迹数据上做微调。但在 BridgeData V2 与 Google 机器人的其余所有任务类别中,OpenVLA 表现均与 RT-2-X 持平甚至更优。造成这一性能差异的原因主要有三点:
- OpenVLA 训练数据集规模更大,共 97 万条轨迹,而 RT-2-X 仅 35 万条;
- 本文对训练数据做了更精细的清洗,例如过滤 Bridge 数据集中全零无效动作等噪声样本(详见附录 C);
- OpenVLA 采用双分支融合视觉编码器,同时复用预训练语义特征与空间特征。
针对以上各模块的消融实验详见附录 D。
5.2 适配新机器人平台的数据高效微调
尽管以往研究大多聚焦于对 VLA 模型做开箱即用 的直接评测,但如何将 VLA 模型高效微调适配全新任务与机器人平台 ,目前仍缺乏深入探索,而这恰恰是 VLA 模型能否大规模落地应用的关键。本节主要探究 OpenVLA 快速适配真实新机器人平台 的能力。仿真环境下的微调实验详见附录 E。
机器人平台与评测任务
本文为 OpenVLA 采用一套简易微调方案:对模型全部参数进行全量微调 ,仅使用包含 10~150 条目标任务示教轨迹 的小规模数据集开展适配实验(见图 5)。参数高效微调相关方法将在 5.3 节进一步探究。
实验选取两套机器人平台:
- Franka-Tabletop :固定桌面式 Franka Emika Panda 7 自由度机械臂;
- Franka-DROID:源自最新 DROID 数据集的 Franka 机械臂配置,搭载于可移动立式工作台。
两套平台分别采用 5Hz 与 15Hz 非阻塞控制器。选择 Franka 机械臂作为微调目标平台,是因为它在机器人学习领域应用广泛,也是 OpenVLA 实际落地微调的典型目标设备。同时选用不同控制频率的平台,用以测试 OpenVLA 对各类实际应用场景的适配能力。
对比基线
本文选取多种基线方法进行对照:
- Diffusion Policy :当前数据高效模仿学习 领域的经典最优方法,采用从零开始训练。
- Diffusion Policy (matched) :适配了与 OpenVLA 完全一致输入输出规范的 Diffusion Policy 版本。
- Octo:在目标任务数据集上微调。Octo 是目前支持微调的最优开源通用机器人策略(RT-2-X 仅提供推理接口,不支持微调)。
- OpenVLA:在相同目标任务数据集上微调后的本文模型。
- OpenVLA (scratch) :消融对照组,不使用经过 OpenX 大规模机器人预训练的 OpenVLA,而是直接对底层 Prismatic VLM 基座 在新机器人任务上微调,用来验证大规模机器人预训练带来的增益。
实验结果如图 5 所示,各任务细分结果见附录表 7。
实验结论:在指令单一、场景简单 的任务(如 "把胡萝卜放进碗里""把玉米倒进锅里")上,两种 Diffusion Policy 方法性能与通用策略 Octo、OpenVLA 持平甚至更优;但在场景物体更多、需要语言指令理解 的复杂微调任务上,经过大规模预训练的通用策略表现更强 。Octo 与 OpenVLA 依托 OpenX 预训练,更擅长适配这类依赖语言接地能力 的多样化任务;消融组 OpenVLA (scratch) 性能明显更低,也印证了大规模机器人预训练的显著价值。
综合实验结果可知,OpenVLA 取得了最优的平均性能 。值得注意的是,现有多数方法仅能在简单单指令任务 或复杂多指令任务 中的某一类上表现优异,任务间的成功率差异极大。而 OpenVLA 是唯一在所有测试任务中成功率均不低于 50% 的方法,这表明它可作为模仿学习任务的优选通用基线 ,尤其适用于包含丰富语言指令的应用场景。在场景单一但对操作灵巧性要求极高 的任务上,Diffusion Policy 生成的运动轨迹依旧更平滑、控制精度更高。如果借鉴 Diffusion Policy 的动作分块 与时序平滑机制并融入 OpenVLA,有望让其达到同等灵巧操作水平,这也是极具潜力的未来研究方向(模型当前存在的局限性详见第 6 节详细论述)。
5.3参数高效微调
上一节中对 OpenVLA 进行全参数微调 时,每项任务需要 8 张 A100 GPU 、耗时 5~15 小时 (具体时长取决于数据集规模)才能达到理想性能。虽然这相比 VLA 预训练的算力开销已经大幅降低,但本节进一步探索更节省算力、更节省参数量的参数高效微调方案,并验证其实际效果。
具体而言,本文对比了以下五种微调策略:
- 全参数微调(full finetuning) :如 5.2 节所述,微调过程中更新模型全部权重。
- 仅最后一层微调(last layer) :只训练 OpenVLA Transformer 主干的最后一层以及词嵌入矩阵,其余参数全部冻结。
- 冻结视觉编码器(frozen vision) :固定视觉编码器参数不变,微调其余所有网络权重。
- 三明治微调(sandwich fine-tuning) :解冻视觉编码器、词嵌入矩阵以及网络最后一层,其余中间层保持冻结。
- LoRA 微调 :采用经典低秩适配方法,在模型所有线性层上设置不同秩 r 进行低秩微调。
本文在表 1 中给出了多种微调方案在 Franka-Tabletop 任务上的微调成功率,同时列出各方案的可训练参数量 与 GPU 显存占用 。实验发现:仅微调网络最后一层、或是冻结视觉编码器,都会导致性能大幅下降 。这说明视觉特征针对目标场景做进一步适配 对机器人任务至关重要。相比之下,三明治微调 因解冻并微调了视觉编码器,因此性能更优;同时由于不需要微调整个大语言模型主干,显存开销更低 。最后,LoRA 微调 在任务性能与训练显存占用之间实现了最优权衡 :效果超越三明治微调,且能媲美全参数微调 ,而只需训练模型 1.4% 的参数。实验还发现,LoRA 的秩大小对策略性能几乎无影响 ,因此推荐默认设置秩 \(r=32\)。采用 LoRA 后,仅需单张 A100 GPU 、耗时 10~15 小时 即可完成 OpenVLA 新任务微调,算力开销相比全参数微调降低至原来的 1/8。
OpenVLA 是 70 亿参数 模型,推理时的显存占用远高于 Octo 等参数量不足 1 亿的传统开源通用机器人策略。本文遵循大语言模型部署的最佳实践,以 bfloat16 精度保存并加载 OpenVLA 权重作为默认推理方式 ,可将显存占用直接减半,仅需 16GB 显存 的显卡即可部署运行。本节探究:能否借助为大语言模型推理服务所设计的主流量化技术 ,进一步降低 VLA 策略推理显存开销、提升模型易用性。这类方法以更低精度加载网络权重,用轻微的推理速度与任务精度损耗,换取显存占用的大幅降低,实现性能与资源开销的权衡。
具体而言,本文在 BridgeData V2 的 8 项代表性任务 上,分别测试 8 比特 与 4 比特 精度下 OpenVLA 的部署推理效果。表 2 给出了不同量化方式的显存占用 与任务推演性能 ;图 6 对比了多款消费级、服务器级显卡上可实现的控制频率 。实验观测到:8 比特量化 会增加量化计算开销,导致绝大多数显卡上的推理速度变慢;而 4 比特推理 整体吞吐更高,因为显存数据传输量的减少抵消了量化带来的额外计算开销。
由于推理速度下降,8 比特量化 出现了明显的性能衰减 :在本次评测所用的 A5000 显卡上,模型推理帧率仅能达到 1.2Hz ;而 BridgeData V2 任务训练时采用的是 5Hz 非阻塞控制器 ,过低的推理帧率会显著改变系统动力学特性 ,进而影响任务表现。值得注意的是,4 比特量化 在显存占用不足 bfloat16 半精度推理一半 的前提下,仍能保持与后者相近的任务性能 。4 比特量化模型在 A5000 上可稳定跑到 3Hz,更贴近数据采集阶段的系统动力学特征。
6 讨论与局限性 专业译文
本文提出了 OpenVLA ------ 一款性能领先、开源的视觉 - 语言 - 动作(VLA)模型 ,在跨机器人本体控制任务中具备优异的开箱即用 性能。同时实验证明,借助参数高效微调技术,OpenVLA 能够便捷地适配全新机器人平台。
当前 OpenVLA 仍存在若干局限性:
第一,模型目前仅支持单帧图像观测输入 。现实机器人硬件配置差异大,存在多样化感知输入形式。后续重要研究方向包括:扩展模型以支持多帧图像、本体感知输入 以及历史观测序列;同时可探索基于图文交替预训练的大视觉语言模型,为 VLA 灵活输入形式的微调提供支撑。
第二,提升 OpenVLA 推理吞吐速度 十分关键,才能适配 ALOHA 等 50Hz 高频控制 机器人系统;也能支撑模型在比本文更复杂的双手机械臂精细操作任务 上开展评测。引入动作分块 、推测解码等推理优化技术,是可行的改进思路。
第三,模型性能仍有提升空间。尽管 OpenVLA 优于以往通用机器人策略,但在测试任务上成功率普遍低于 90%,任务可靠性仍有待增强。
最后,受限于算力资源,仍有大量 VLA 模型设计问题尚未充分探究:基座大语言模型参数量规模对 VLA 性能有何影响?在机器人动作预测数据与互联网规模图文数据上联合训练能否显著提升 VLA 效果?何种视觉特征最适配 VLA 建模范式?
我们希望通过开源 OpenVLA 模型与代码库,推动整个研究社区共同探索以上问题。