大型语言模型(LLMs)已经改变了我们处理复杂认知任务的方式------从编写生产代码,到分析财务报告,再到翻译几十种语言。互补的 foundation models 现在也能处理视觉、语音合成与识别、音频处理、图像生成和多模态推理。这些模型都建立在类似的 transformer 架构之上,能够跨多个领域处理并生成人类风格的内容。
尽管具备这些能力,这些模型仍然存在根本性的结构限制。除非你提供数据,否则它们无法访问你的私有或机密数据。它们的 context windows 限制了每次可以考虑的信息量,这使得长文档在单次处理中要么成本很高,要么根本无法分析。而且,当这些模型缺少正确信息时,它们往往会 hallucinate,而不是承认不确定。
Retrieval augmented generation(RAG,检索增强生成)一次性解决这三个问题。它让模型以受控方式访问外部知识,使模型能够处理远超单个 prompt 容量的信息,并将答案建立在 retrieved evidence 上,而不是凭空猜测。用户提出问题时,系统会先从知识源中检索相关信息,然后把这些上下文传给模型生成回答。
图 1-1 展示了最简单形式的 RAG 系统。Retriever 会搜索一个知识源,例如 vector store 或 database,并返回相关 passages。你可以把 vector store 理解为一种专门的搜索引擎:它索引的是你自己的特定文档和知识库,而不是像 Google 那样索引整个互联网。Generator 通常是一个 LLM,它使用检索到的材料生成 grounded answer。
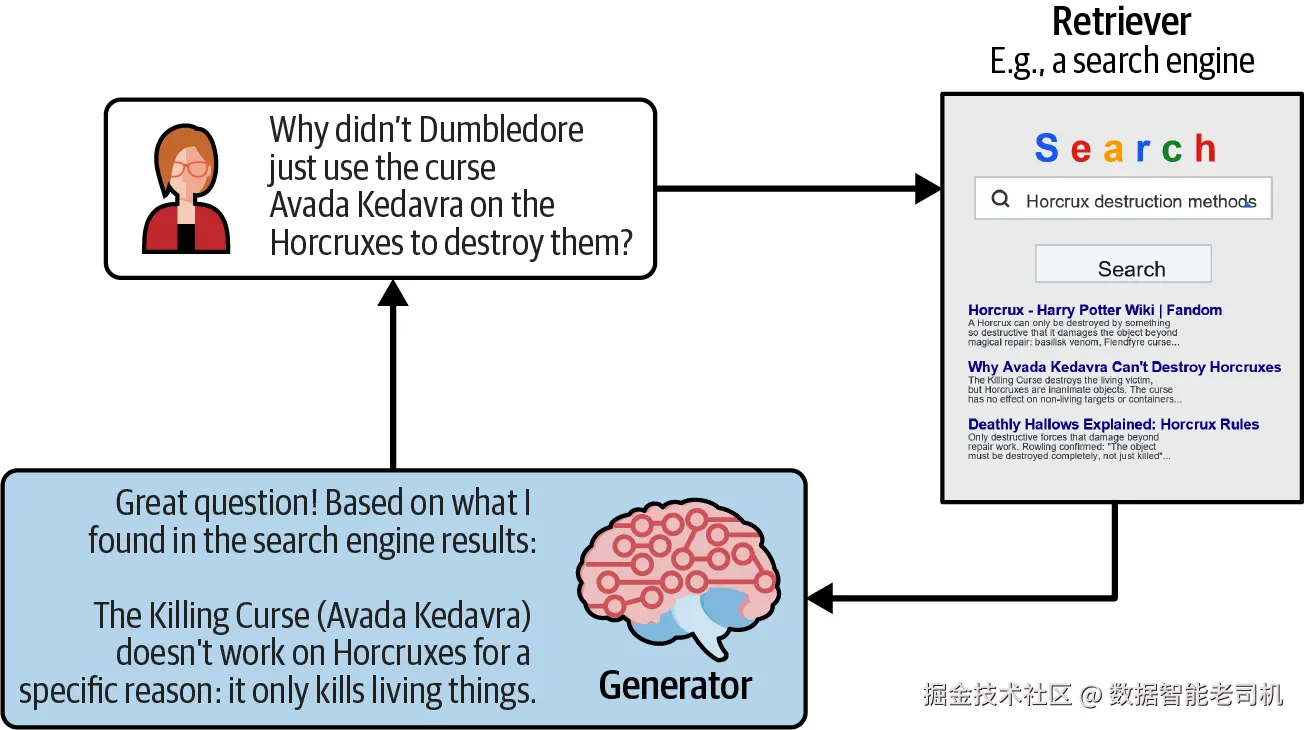
图 1-1:RAG chatbot 检索相关信息并生成上下文相关回答
当知识分散在许多文档中、答案需要综合而不是简单查找,或者数据太大、太多样以至于人工无法审阅时,RAG 最有用。现代系统通常会使用多个 retrievers。一个 retriever 可能搜索文档,另一个可能查询结构化数据库,还有一些可能调用外部 APIs。模型会协调这些工具,决定每个问题应该使用哪些信息。
图 1-2 展示的正是这种方法:一个带有多个 API endpoints 的 RAG 系统,可以搜索 Notion 数据库、搜索 web、执行计算,并访问 SQL 和 vector databases 来搜索知识库。模型会根据问题决定调用哪个 retriever,并组合检索到的信息生成答案。这种架构使系统能够处理广泛问题。
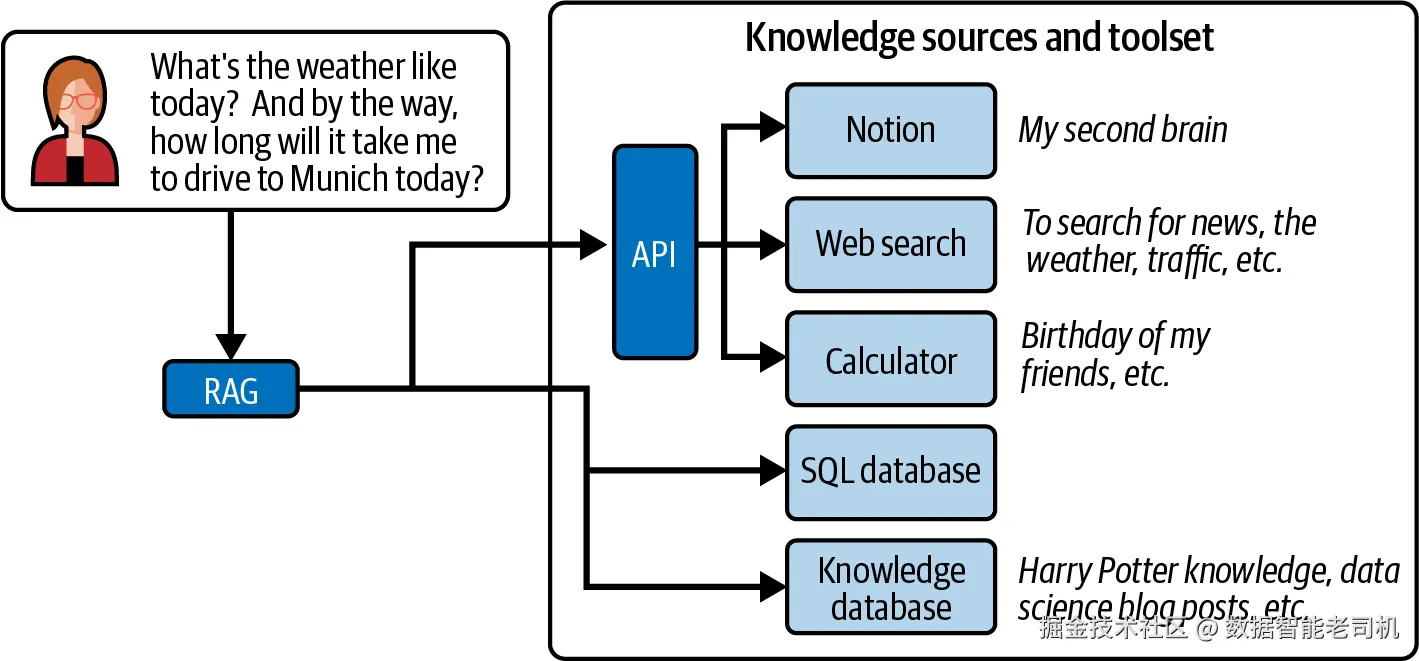
图 1-2:一个带有多个 retrievers 的 RAG 系统,用于回答关于 Harry Potter 图书的问题
虽然许多人主要把 RAG 与 chatbots 联系在一起,但聊天界面并不总是最优解。Chat 很适合探索性提问和初始用户交互,但最佳方法常常是组合多个界面。一个典型工作流可能从对话界面开始,用来理解用户意图;当系统理解用户需求后,再转向 dashboard、form-based application 或 automated report。许多 RAG 系统也完全在后台运行,通过 APIs、scheduled reports 或与现有业务应用集成来交付结果。
本章将带你完成环境设置,并构建第一个基础 RAG 应用。
所有代码示例都可以在本书 GitHub repository 中找到。
1.1 识别组织中的高价值 RAG 用例
Problem
你的组织正在探索 RAG,需要识别能够带来最大价值的 use cases。
Solution
从识别能够解决具体问题的 use cases 开始。许多 RAG pilot projects 失败,是因为它们太复杂、太昂贵,或者并没有解决真实用户痛点。
聚焦 RAG 能带来可衡量影响的两个高价值领域:
Data extraction
将非结构化数据,例如合同、发票、技术图纸、会议记录,转换为结构化、可搜索的信息。
Process automation
处理需要决策和适应能力的重复性任务。
表 1-1 提供了一些指导,用于从 RAG fit 和潜在价值角度评估不同场景。数值 1 表示 RAG fit 很低或几乎没有价值,5 表示最适合。
表 1-1:评估 RAG use cases
| RAG fit(1--5) | Use case | Reasoning |
|---|---|---|
| 1 | "我想和我的季度报告聊天。" | 单文档、低数量。直接阅读,或使用通用应用,例如 ChatGPT 或 Claude,就能很好完成。 |
| 2 | "帮我总结这个单独文档。" | 通用模型,例如 Claude、ChatGPT,已经能很好完成。自定义 RAG 增加的价值很小。 |
| 2 | "自动化需要高风险决策的任务。" | 可以做,但如果没有强控制措施,例如 human in the loop、auditing、fail-safes,风险太高。LLMs 仍然会犯错。 |
| 4 | "会议录音堆积如山,但洞察从未进入知识库。" | 将不可访问数据,例如音频、视频、长篇非结构化笔记,转换为可搜索形式。持续价值很强,但质量取决于转录。 |
| 4 | "你必须根据 specification documents 检查 technical drawings。" | 多模态对比,人类觉得繁琐。自动化节省时间,但需要强评估和异常处理。 |
| 5 | "我们有 10000 份合同,但不知道哪些合同包含 auto-renewal clauses。" | 高数量使人工审阅不可行。清晰 extraction task,输出可验证。 |
| 5 | "我们的客服工单包含产品问题,但无法汇总。" | 跨文档模式检测。人类无法在规模化数据中发现趋势。 |
| 5 | "每天收到数百条客户询问,需要将它们路由给正确团队。" | 重复性分类 / 路由任务,成功标准清晰,投资回报可衡量。 |
许多 use cases 会组合 data extraction、analysis 和 automation。图 1-3 展示了一个来自工程和质量管理的例子。制造商每天从供应商处接收数千份质量文档。RAG 应用会提取关键信息,将其与 vector database 中的 ISO standards 对比,检查合规性,并生成报告。如果信息缺失或包含不合规参数,例如本例中的焊接厚度,系统可以自动检索供应商联系方式,并生成 follow-up email 草稿。
这种自动化节省了数小时人工审查时间,并加快问题解决,是一个高价值 RAG use case 的例子。
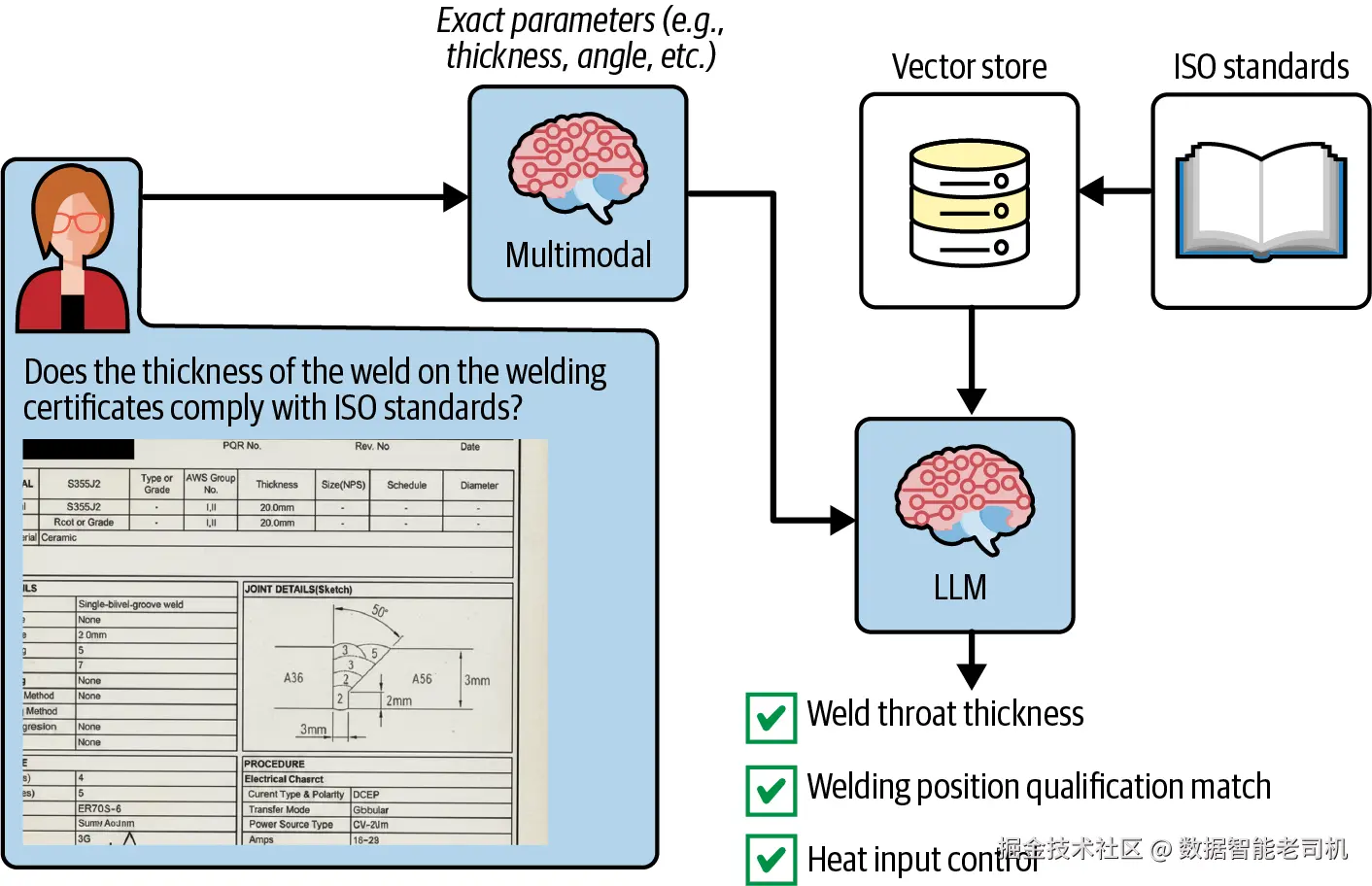
图 1-3:从技术质量文档中提取结构化数据
Discussion
RAG 适合自动化,是因为 LLMs 能理解意图和上下文,而不只是匹配模式。传统自动化需要为每种场景编写显式规则。当供应商邮件写 "delayed due to weather" 和 "shipment rescheduled" 时,rule-based systems 需要分别处理每种短语。基于 RAG 的系统则能理解两者表达的是同一种运营影响。
当数据非结构化且变化多样时,这种能力最重要。如果每个输入略有不同,但需要类似处理,例如客户邮件、合同条款或事故报告,就适合使用 RAG。不要把 RAG 用在简单查找、固定格式数据提取,或基于不变规则的任务上。如果你可以写一个 regular expression(regex)或 SQL query 处理 95% 的情况,那么 RAG 会增加不必要的复杂性和成本。
RAG 是用简单性换灵活性。依赖 rule-based decision steps 的传统自动化流程运行更快、单次操作成本更低,并且失败方式更可预测。另一方面,LLM-powered RAG systems 更擅长处理 edge cases,但需要 model hosting、prompt engineering 和 evaluation frameworks。比较不同方法时,应同时考虑 token costs 和 engineering effort。
从人工审阅形成瓶颈的高数量任务开始。一个每天处理 10 个文档的系统,可能不值得投入 RAG 开发成本;但一个每天处理 1000 个文档的系统就值得。每次实现都会让你学习到 prompt patterns、evaluation metrics 和 failure modes,这些经验会应用到后续项目中。
避免把复杂 multisystem integrations 作为第一个项目。成功既需要 RAG 专业能力,也需要组织 buy-in。在聚焦用例上证明价值之后,再扩展到需要跨职能协调或多个数据源的场景。
See Also
Dasha Maliugina 的博客文章 "10 RAG Examples and Use Cases from Real Companies" 概述了来自 LinkedIn、Harvard Business School、Vimeo 和 Pinterest 等组织的实际 RAG 实现。
开源 repository "GenAI & LLM System Design: 500+ Production Case Studies" 收集了真实世界生产级 generative AI(GenAI)系统案例,其中包含许多基于 RAG 的架构和部署模式。
1.2 选择 IDE 和 Coding Agent 设置
Problem
你想快速搭建环境,用 Python 开发并分享 RAG use cases。
Solution
适合 RAG 开发的流行 Python IDEs 包括:
Visual Studio(VS)Code
轻量、可扩展,具备强 Python 支持。
PyCharm
功能完整的 Python IDE,具备高级 debugging 能力。
Jupyter Notebook / Lab
交互式开发,支持 inline visualization。
Spyder
聚焦科学计算。
Vim / Neovim
基于终端,高度可定制。
流行的 LLM-powered coding assistants 包括:
GitHub Copilot
IDE 集成,支持 chat 和 agent modes。
Cursor
类似 Copilot,具备 IDE-native experience。
Claude Code
命令行工具,擅长理解大型 codebases。
图 1-4 展示了 VS Code 中的 GitHub Copilot,显示 chat window 以及 ask、edit 和 agent modes。
图 1-4:VS Code 中的 GitHub Copilot
除了 IDE 之外,为了运行本书代码示例,你还需要设置 Python 环境,并满足以下要求:
- Python 3.9 或更高版本,代码示例使用 Python 3.10 测试。
- 每个项目使用 virtual environment,见 Recipe 1.3。
- Chapter-specific dependencies,见 Recipe 1.7。
Discussion
GitHub Copilot 和 Cursor 直接集成到 IDE 中,并实时展示代码变更。你可以在接受每个建议前先审查它。Claude Code 从命令行运行,在处理大型 codebases 和复杂模块依赖方面比 IDE-based assistants 更有效。大多数开发者会发现 IDE-integrated 和 command-line 两种方法在不同任务中都有价值。
所有 coding agents 都有不同优势、弱点和 pricing models。订阅前先试用 free tiers,评估哪些工具适合你的工作流。有些团队会标准化使用一个工具以保持一致,而另一些团队则允许开发者根据个人偏好选择。
See Also
GitHub Copilot 文档解释了如何在 IDE 中设置并使用 AI-powered code completion。
Cursor 提供一个 AI-first code editor,集成 chat 和 inline editing 功能。
Claude 提供 API access,可用于构建自定义 coding assistants 和 workflows。
1.3 在 VS Code 中开始使用 Jupyter Notebooks
Problem
你想快速开始构建自己的 RAG workflows。你希望大量实验,并把代码、可视化和文档放在同一个地方。
Solution
Jupyter notebooks 允许你在不同 cells 中编写和运行代码,独立测试各部分,并 inline 显示输出、表格和图表。因此,它们非常适合 RAG 实验。
按照以下步骤在 VS Code 中设置 Jupyter notebooks:
- 从官方网站安装 VS Code。
- 安装 Python extension,其中包含 Jupyter 支持。
- 创建一个新的 notebook 文件,扩展名为
.ipynb。 - 创建并激活 virtual environment:
shell
python3 -m venv .venv
# Windows: ..venv\Scripts\Activate.ps1
# macOS/Linux: source .venv/bin/activate- 在 VS Code 右上角选择 virtual environment 作为 Jupyter kernel。
图 1-5 展示了 VS Code 中的 Jupyter notebook,并已选择正确环境。
图 1-5:VS Code 中的 Jupyter notebook
可以在 terminal 中安装 packages,也可以直接在 notebook cells 中安装:
diff
!pip install openai chromadb导出 dependencies 以便分享:
pip freeze > requirements.txt在另一套系统上安装 dependencies:
pip install -r requirements.txtDiscussion
Notebooks 会把 data 和 models 保存在内存中。你可以只加载一次数据,然后反复运行实验而无需重启。
Notebooks 非常适合探索和可视化,但对生产系统有局限。Cells 可以按任意顺序运行,会产生从上到下阅读时不明显的隐藏依赖。Notebooks 以 JSON 格式存储内容,使 diff 和 merge conflicts 难以处理。这些因素使 notebooks 不适合需要稳健 testing 和 version control 的生产部署。
用 notebooks 做探索和可视化。把可复用逻辑提取到独立 Python modules 中。再把这些 modules 导入 notebooks。这样可以让 notebooks 聚焦实验,同时让可复用逻辑保持可测试和可维护。
使用 IPython autoreload extension 自动重新加载修改过的 modules:
perl
%load_ext autoreload
%autoreload 2 # Reload all modules before running code
import my_module如果协作团队不熟悉 Jupyter,就不要使用 notebooks。Execution order dependencies 会让习惯线性 Python scripts 的开发者困惑。同样,也要避免将 notebooks 用于必须满足合规要求或通过正式审查流程的代码,因为 JSON 格式会让审计变难。
See Also
VS Code Jupyter 文档覆盖 notebook features、debugging 和 variable inspection。
Jupyter installation guide 提供 standalone Jupyter Notebook 和 JupyterLab environments 的设置说明。
1.4 使用 .env 文件存储 Secrets 和 API Keys
Problem
你希望把 API keys 等 secrets 放在源代码之外,同时能在多个项目中复用它们。
Solution
使用 .env 文件存储 secrets。这可以让 API keys 不进入 codebase,并防止被意外提交到 version control。
将 .env 文件加入 .gitignore。.gitignore 文件列出 Git 不应追踪的文件,确保 secrets 保持在本地,不会进入 remote repositories。
本 recipe 演示如何通过 python-dotenv library 从 .env 文件加载 secrets。完整架构见图 1-6。
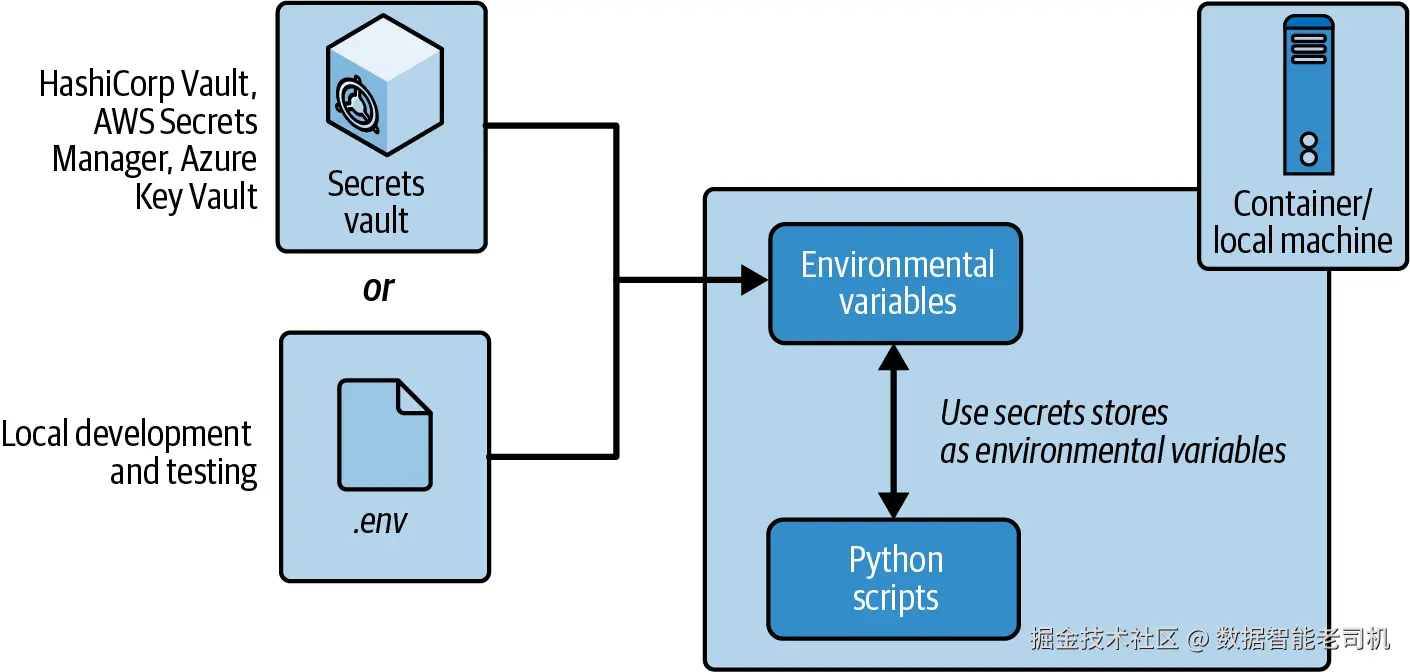
图 1-6:开发环境从 .env 加载 secrets,生产环境从 secret management systems 加载 secrets
TIP
把 .env 文件只当作本地开发便利方式。对于生产部署,应始终使用云平台提供的 managed secret store。
首先安装 python-dotenv library:
pip install python-dotenv大多数 software development kits(SDKs)会期待特定 environment variable names,因此一定要查看文档。例如,OpenAI 会查找 OPENAI_API_KEY。在 .env 文件中使用 KEY=_VALUE 格式写入每个 secret:
ini
HUGGINGFACEHUB_API_TOKEN=hf_...
OPENAI_API_KEY=sk-...确保 .env 文件列在 .gitignore 中。这可以防止 Git 追踪它。你在 GitHub 上创建新 repository 时,通常会自动生成默认 .gitignore。如果尚未包含 .env 文件,就添加它。下面片段展示了一个包含常见忽略文件类型的 .gitignore 示例:
bash
# Environments
.env
.venv
.vscode
env/
venv/要在 Python 代码中加载 secrets,在启动时调用一次 load_dotenv。然后你可以通过 os.getenv 访问值,如下所示:
arduino
from dotenv import load_dotenv
import os
load_dotenv()
openai_key = os.getenv("OPENAI_API_KEY")Discussion
Environment variables 是程序在运行时从操作系统读取的 key-value pairs。它们提供标准接口,用于访问 configuration 和 secrets,而不需要在源代码中硬编码这些值。
.env 方法非常适合本地开发,因为它无需云基础设施,就可以让 secrets 不进入 version control。不过,.env 文件是存储在磁盘上的明文文件,没有加密或访问控制。
对于生产系统,请使用 managed secret stores,例如 Amazon Web Services(AWS)Secrets Manager、Microsoft Azure Key Vault 或 HashiCorp Vault。这些服务提供静态和传输加密、audit logging、automatic rotation 和细粒度 access controls。多数云平台会在运行时直接将 secrets 注入为 environment variables,因此应用代码不需要改变,仍然使用 os.getenv。
当多个团队成员需要访问相同 secrets 时,不要通过 email、Slack 或 shared drives 分享 .env 文件,这会破坏安全收益。相反,应使用共享 development secret store 或 credential management tool,例如 1Password,或带开发者访问权限的 AWS Secrets Manager。
关键原则是:secrets 永远不应该硬编码在源代码中,也不应该提交到 version control。无论你在本地使用 .env 文件,还是在生产中使用 managed service,environment variables 都为访问 secrets 提供了一致接口。
See Also
python-dotenv 文档解释了如何从 .env 文件加载 environment variables 到 Python 应用中。
GitHub 关于 removing sensitive data 的指南展示了如何从 Git history 中清理意外提交的 secrets。
1.5 构建你的第一个 RAG App
Problem
你想构建第一个基于 RAG 的 conversational knowledge chatbot。
Solution
每个 RAG 系统都围绕三个基本组件构建:
- 一个 embedding model,用于将文本表示为 vectors
- 一个 vector store,用于搜索这些 vectors
- 一个 LLM,用于根据 retrieved context 生成答案
工作流由两个主要部分组成:data ingestion 和 query processing,下面分别说明。
首先,对于 data ingestion,你会执行以下步骤:
- 将 documents 拆分成较小 chunks。
- 为每个 chunk 生成 embeddings。
- 将 vectors 存储到 vector database。
然后,对于 query processing,你会使用一个完整 RAG pipeline,如图 1-7 所示:
- 将用户问题转换为 embedding vector。
- 在 vector database 中搜索最接近的匹配 vectors。
- 选择最相关 chunks。
- 将 chunks 和用户问题一起发送给 LLM。
最后一步,LLM 使用这些 context 生成答案。
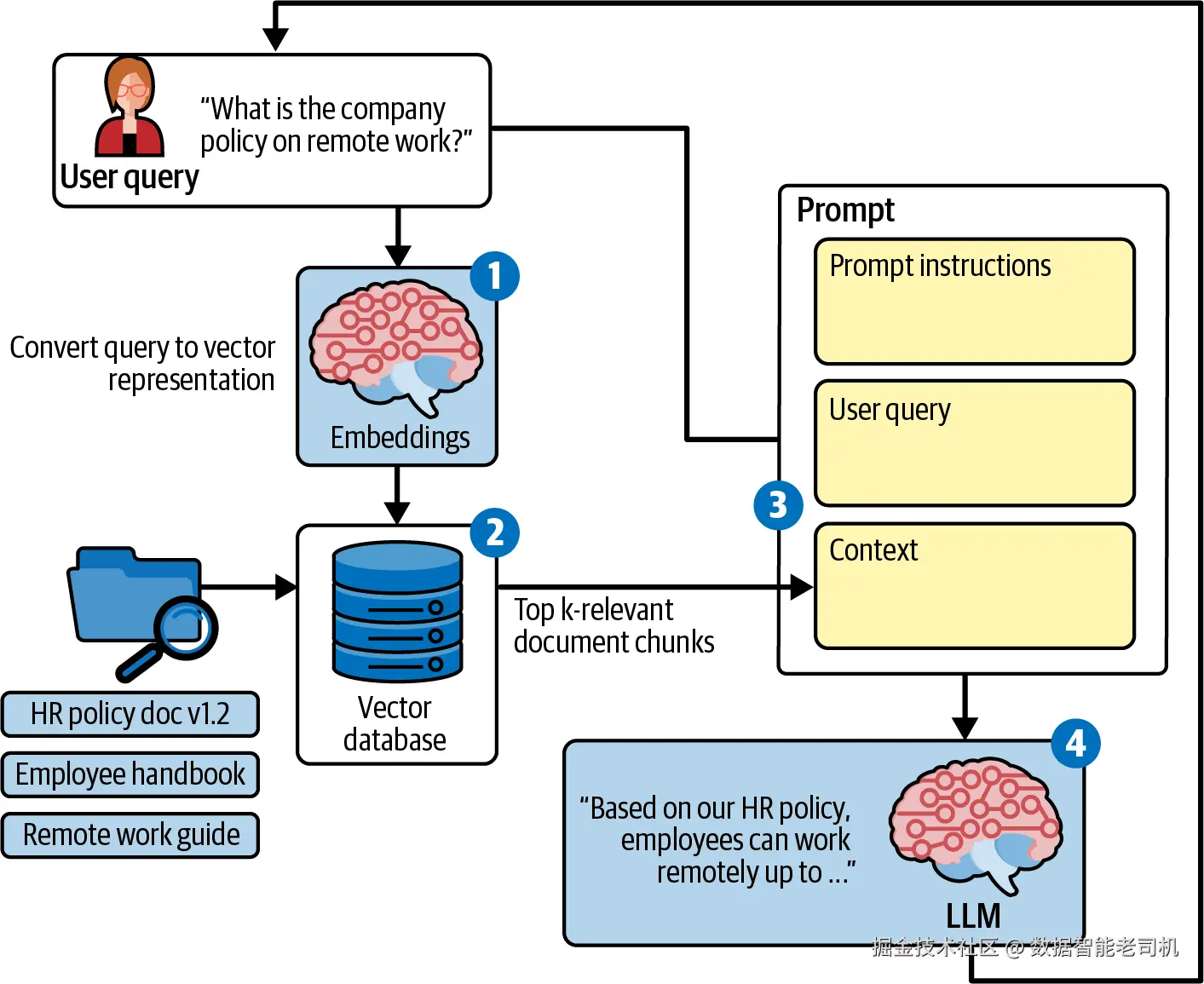
图 1-7:基础 RAG pipeline
开始之前,确保你拥有以下内容:
- OpenAI account,以及来自 OpenAI Platform 网站的 API key
- Chroma,用于 vector storage。关于 vector store concepts,见第 6 章
本 recipe 通过构建一个 Harry Potter knowledge chatbot 演示工作流。图 1-8 展示了该 recipe 实现的整体架构。Retriever 会搜索由 Harry Potter 图书构建的 Chroma vector store,generator 则使用 OpenAI models 基于 retrieved context 回答问题。
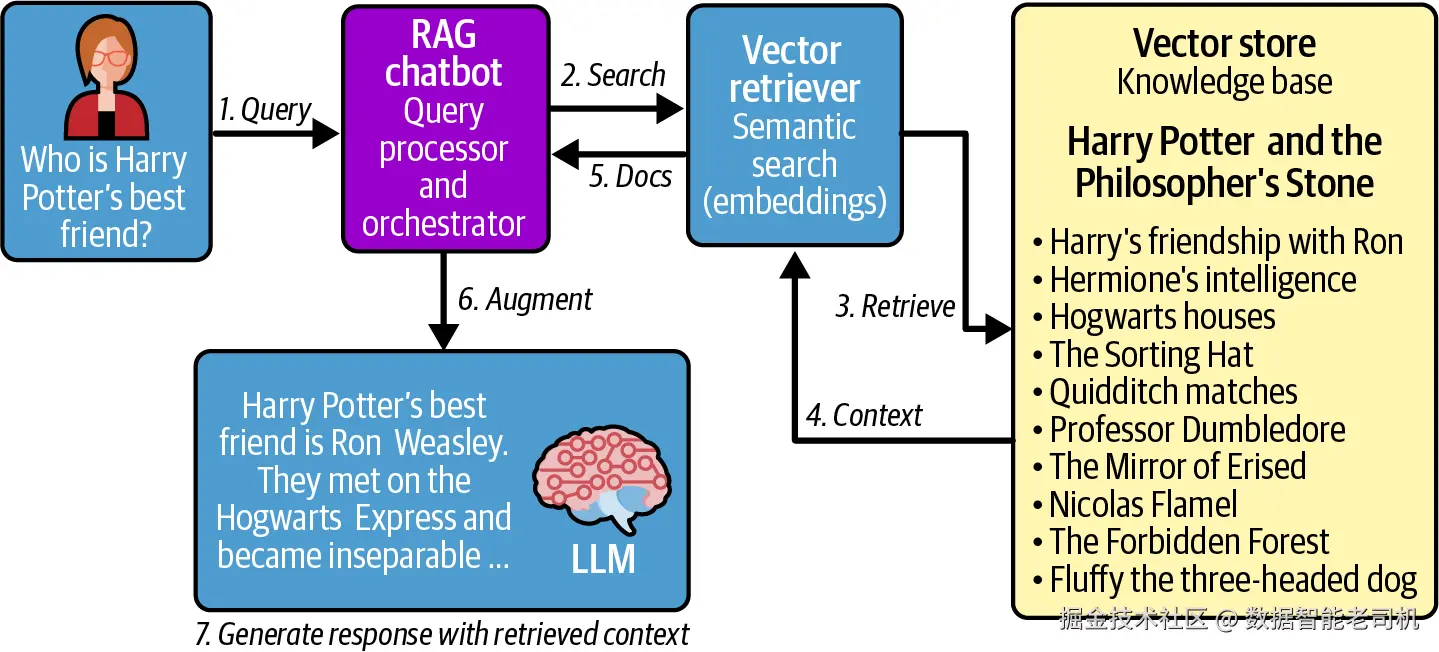
图 1-8:Harry Potter chatbot RAG 架构
Step 1:Text chunking
这个 recipe 会从零构建 RAG 系统,不使用框架,以展示核心概念有多简单。LangChain 和 LlamaIndex 等 RAG orchestration frameworks 提供 ready-to-use chunking functions,但这个示例避免这些依赖,以保持实现轻量,并让核心概念更清晰。
第一步,你会在自然边界处切分文本,例如 paragraphs 或 sentences,并加入 overlap,以保留 chunks 之间的上下文:
arduino
from pathlib import Path
import chromadb
from openai import OpenAI
def chunk_text(text, size=1000, overlap=200):
chunks, start = [], 0
while start < len(text):
end = min(start + size, len(text))
if end < len(text):
bp = text.rfind("\n\n", start, end)
if bp == -1:
bp = text.rfind(". ", start, end)
if bp > start:
end = bp + 1
chunk = text[start:end].strip()
if chunk:
chunks.append(chunk)
start = end - overlap if end < len(text) else end
return chunks
file_path = Path("datasets/text_files/harry_potter_knowledge_base.txt")
text = file_path.read_text(encoding="utf-8")
chunks = chunk_text(text)Step 2:Embed and store in Chroma
接下来,你会生成 embeddings,并将它们存入 Chroma collection。代码会检查目录中是否已经存在同名 collection,如果不存在则创建。如果你多次运行这个 cell 并遇到 ID conflicts,可以删除 chroma_db 文件夹,或者使用新的 collection name:
ini
client = OpenAI()
embedding_model = "text-embedding-3-small"
def embed_and_store(chunks, db_path, collection_name):
chroma = chromadb.PersistentClient(path=str(db_path))
collection = chroma.get_or_create_collection(
name=collection_name,
metadata={"description": "Harry Potter knowledge base"},
)
embeddings = []
for i in range(0, len(chunks), 100):
batch = chunks[i : i + 100]
res = client.embeddings.create(model=embedding_model, input=batch)
embeddings.extend([x.embedding for x in res.data])
collection.add(
ids=[f"chunk_{i}" for i in range(len(chunks))],
documents=chunks,
embeddings=embeddings,
metadatas=[{"chunk_index": i} for i in range(len(chunks))],
)
return collection
chroma_db_dir = Path("chroma_db")
collection = embed_and_store(chunks, chroma_db_dir, "harry_potter_kb")Step 3:Test retrieval
数据存储完成后,测试 retrieval system 是否能针对给定问题找到相关 chunks:
ini
def retrieve(question, top_k=3):
q_emb = client.embeddings.create(
model=embedding_model,
input=question,
).data[0].embedding
res = collection.query(
query_embeddings=[q_emb],
n_results=top_k,
include=["documents"],
)
return res["documents"][0]
question = "Why did Uncle Vernon take the family to the hut by the sea?"
docs = retrieve(question)Step 4:Test generation
当 retrieval 正常工作后,通过将 retrieved documents 和 question 传给 LLM,测试 generation step 以生成答案:
ini
def answer(question, docs):
context = "\n\n---\n\n".join(docs)
prompt = f"""Answer the question using only the context below.
Context:
{context}
Question:
{question}
Answer:"""
res = client.chat.completions.create(
model="gpt-5-mini",
messages=[{"role": "user", "content": prompt}],
)
return res.choices[0].message.content
question = "Why did Uncle Vernon take the family to the hut by the sea?"
docs = retrieve(question)
answer_text = answer(question, docs)当 retriever 和 generation 都能工作时,你就拥有了第一个基础 RAG 系统。
Discussion
当你的数据可以放入单个 vector store,并且用户提出的是直接事实性问题时,这种基础 RAG pattern 可以工作。当 queries 需要多步推理,例如 "比较 X 和 Y,然后推荐 Z",或者不同数据类型需要不同 retrieval strategies 时,这种方法会失败。例如,将结构化数据库查询与文档搜索结合起来,就需要超越简单 vector similarity 的 orchestration。
先独立测试 retrieval,再调试 generation。如果 retriever 返回无关 chunks,应先修复 retrieval,再调整 prompts 或 LLM 参数。如果答案感觉泛泛而谈,或者与你的文档无关,问题通常是 retrieval quality,而不是 LLM。
随着你继续阅读本书,你会学习多种 retrieval 和 generation 技术,这些技术可以组合起来,构建更复杂、且适配具体 use cases 的 RAG 系统。
See Also
LangChain RAG tutorial 展示了如何构建完整 question-answering application,并提供 source code。
LlamaIndex starter tutorial 演示了如何在 5 分钟内 indexing 和 querying documents。
LlamaIndex RAG examples repository 包含适用于多种 use cases 的 production-ready RAG patterns。
1.6 为你的 RAG 应用选择 Frameworks 和 Libraries
Problem
你正在寻找一组 libraries 和 frameworks,帮助你构建 RAG applications。
Solution
RAG applications 同时使用 high-level orchestration frameworks,例如 LangChain 和 LlamaIndex,以及 low-level libraries,例如 Facebook AI Similarity Search(FAISS)和 NumPy,用于数据处理。
图 1-9 展示了本书使用的主要 library categories。
图 1-9:RAG libraries 概览
表 1-2 总结了一些对 RAG applications 重要的 libraries 和 frameworks。
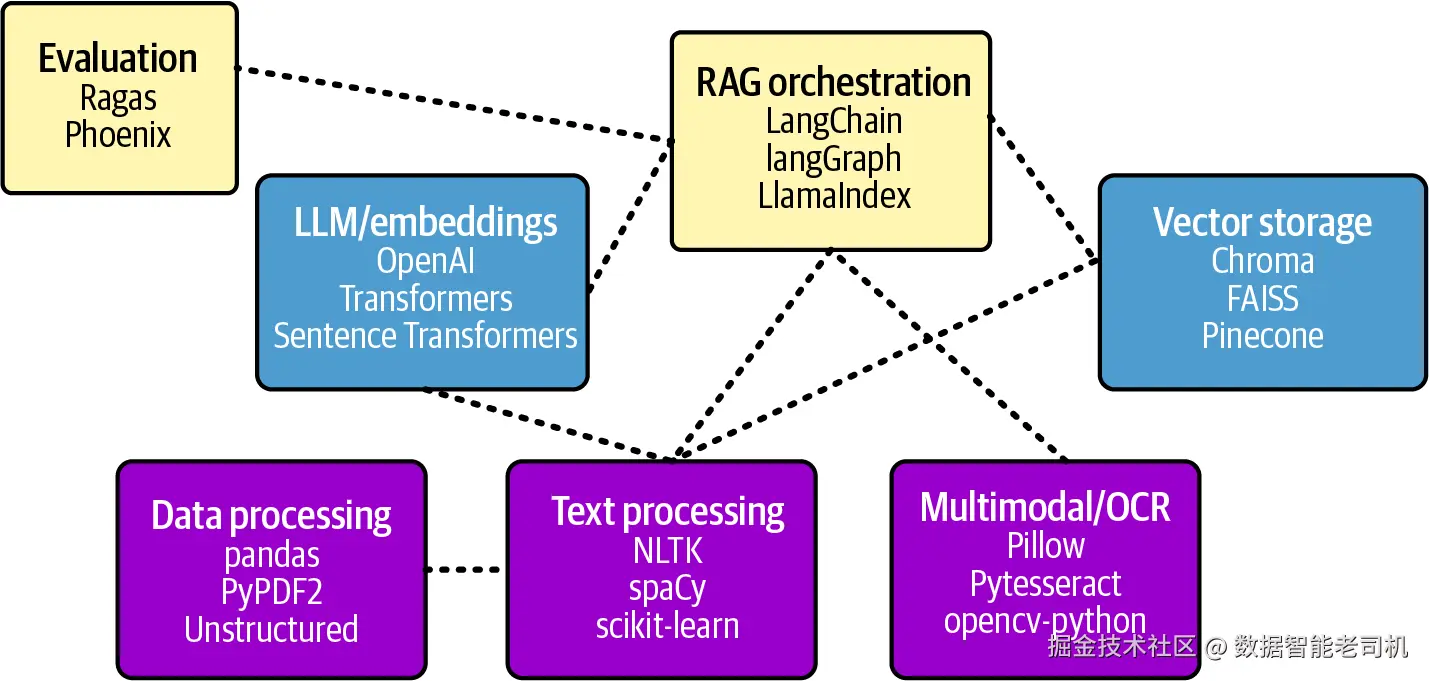 表 1-2:RAG applications 常用 libraries 和 frameworks
表 1-2:RAG applications 常用 libraries 和 frameworks
| Category | Example libraries | Description |
|---|---|---|
| RAG and agentic RAG orchestration | LangChain、LangGraph、LlamaIndex | Orchestration frameworks 会把常见 RAG components,例如 retrievers、generators、prompts 和 memory,封装成统一抽象。它们处理 vector stores、LLMs 和 databases 之间的 plumbing,让你专注 application logic,而不是 integration code。 |
| LLM / embeddings | OpenAI、Anthropic、Transformers、Sentence Transformers | Foundation models 和 embedding services 构成 RAG 系统核心,为理解 queries 和生成 responses 提供智能能力。 |
| Vector storage | Chroma、faiss-cpu、Pinecone、Milvus、Weaviate | Vector databases 通过存储和检索 embeddings,实现高效 similarity search。 |
| Data processing | pandas、NumPy、PyPDF2、pypdf、python-docx、Unstructured、openpyxl、scikit-learn | 用于数据操作、文件读取和预处理任务的 libraries。帮助加载并预处理非结构化数据,然后连接到 RAG app。 |
| Multimodal and media | Pillow、Pytesseract、MoviePy、pdf2image、opencv-python | 成熟 libraries,用于加载和处理多种文件格式,包括 videos、podcasts、Word docs、PowerPoint presentations 和 images。 |
| Text processing and natural language processing(NLP) | NLTK、Transformers、Rank-BM25、Beautiful Soup 4 | 传统 NLP libraries,帮助高效处理文本,并执行文本分析任务,而不完全依赖 LLMs。 |
| Evaluation and monitoring | Ragas、Phoenix、LangSmith、Prometheus-Eval | 提供 predefined metrics 的 frameworks,用于评估 RAG app components,例如 retriever、generator,以及整体应用性能。 |
| Web frameworks and deployment | Streamlit、Gradio、Flask、Django | 用于构建用户界面并部署 RAG applications 的 frameworks。Streamlit 和 Gradio 适合快速原型开发,而 Flask 和 Django 适合 production-grade apps。 |
| Database and storage | SQLAlchemy、Psycopg 2、SQLite3 | Connectors 和 object-relational mapping libraries,用于处理传统 SQL databases,作为 RAG apps 背后的数据源。 |
Discussion
LangChain、LangGraph 和 LlamaIndex 等 orchestration frameworks,见表 1-2,为常见 RAG tasks 提供预构建 components,包括 retrieval chains、prompt templates、memory management 和 agent loops。在构建标准 patterns 时,这能加速开发。不过,frameworks 会捆绑许多功能,并引入大量 dependencies。图 1-10 展示了 LangChain Text Splitters library 的 dependency tree。
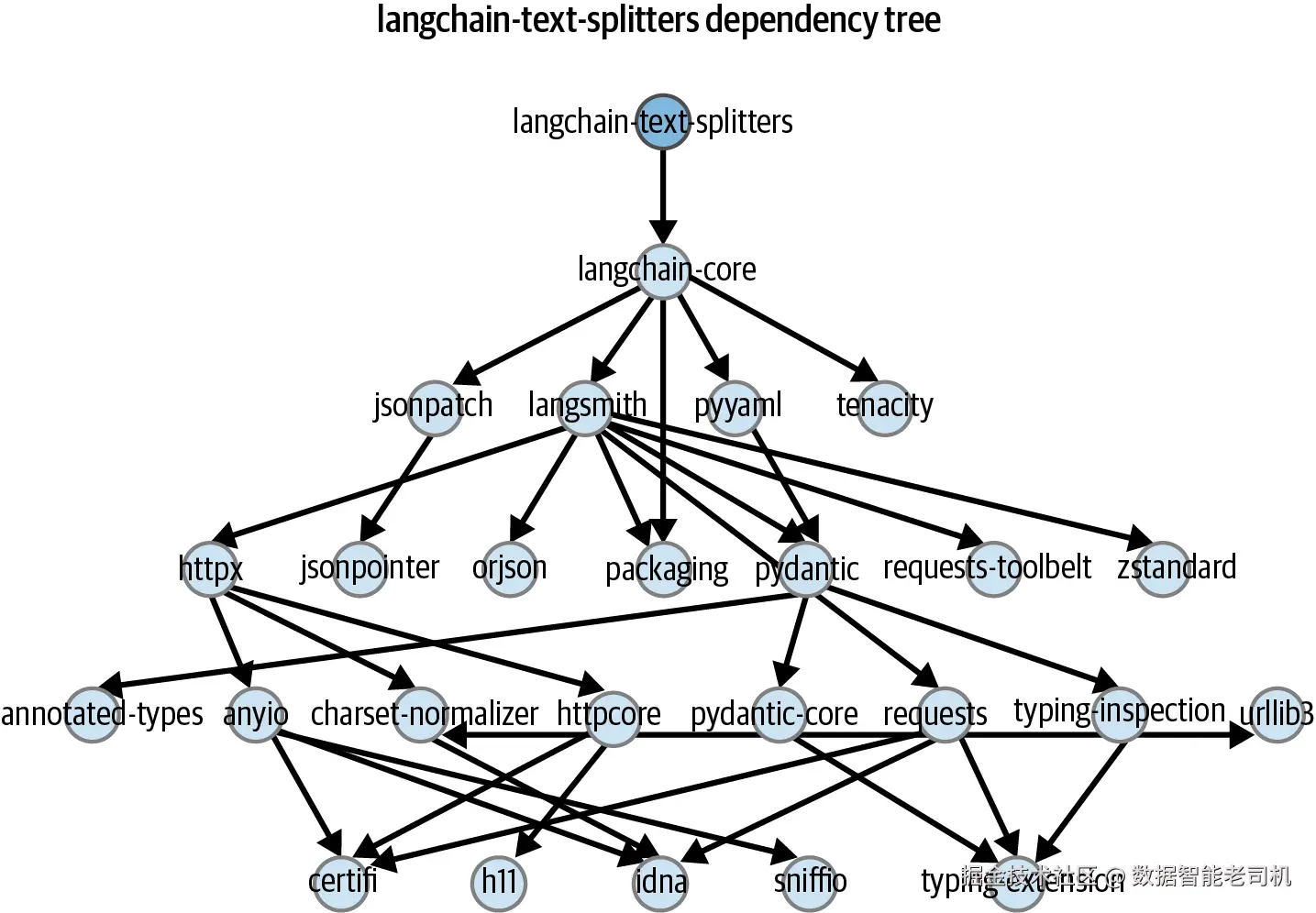
图 1-10:某个 framework component 的 dependency tree
每个 dependency 都可能引入 breaking changes、version conflicts、security updates 和 incompatibilities。使用完整 framework 后,项目常常会拥有 100+ dependencies,相比只使用 5--10 个核心 libraries 的项目,排查问题的成本会显著更高。
当你构建需要多个 RAG patterns 的应用时,可以使用 frameworks,例如 conversational memory、multistep retrieval、tool calling 和 reranking。Frameworks 会处理这些 components 之间的 integration work。对于只需要 vector search 和 generation 的简单应用,不要使用 frameworks。使用 OpenAI 和 Chroma 的直接实现,只需要 2--3 个 dependencies,而不是 50+。
可以考虑先从简单实现开始,当复杂性足以证明 trade-off 合理时再引入 frameworks。如果需求扩大,可以稍后将基础 retriever-generator 实现迁移到 framework。反过来,从 framework 简化回直接实现,会困难得多。
1.7 运行本书 Repository 中的代码示例
Problem
你想 clone 本书 repo,并安装每章所需 dependencies。
Solution
首先,将 repository clone 到本地机器。然后设置 virtual environment,并只安装你正在处理章节所需的 dependencies。
下面展示如何 clone repository 并进入目录:
bash
git clone git@github.com:polzerdo55862/RAG-with-Python-Cookbook.git
cd rag-oreilly-book每章都有自己的 requirements_chXX.txt 文件。根据操作系统创建 virtual environment 并安装 dependencies。
在 Windows(PowerShell)上:
python -m venv .venv
..venv\Scripts\Activate.ps1
pip install -r requirements_ch08.txt在 macOS / Linux(bash)上:
bash
python -m venv .venv
source .venv/bin/activate
pip install -r requirements_ch02.txt代码目录结构按章节组织示例,例如 01_loading_data/、02_chunking_data/,并包含共享 datasets、utility functions 和 chapter-specific requirements files:
erlang
code/
├─ 01_loading_data/
├─ 02_chunking_data/
├─ 03_text_embedding/
├─ ...
├─ 11_building_rag_apps/
├─ datasets/
├─ results/
├─ util/
├─ helper_functions.py
├─ requirements.txt
├─ requirements_ch01.txt
├─ requirements_ch02.txt
├─ ...
└─ requirements_ch08.txtDiscussion
按章节安装 dependencies,而不是全局安装,可以减少冲突并保持环境轻量。每个 requirements_chXX.txt 文件只包含该章 recipes 需要的 libraries。或者,你也可以在本书 repository 中每个 Jupyter Notebook 文件开头找到安装命令。
Virtual environments 会将项目 dependencies 与系统 Python packages 隔离。这可以防止不同项目需要不兼容 library versions 时出现版本冲突。每次处理本书示例时,都需要激活该环境。
TIP
本书大多数代码示例也提供 Google Colab notebooks。Google Colab 是免费的云端 Jupyter notebook 环境,不需要本地设置;你可以直接在浏览器中运行 Python 代码,并访问 GPUs。这使你无需本地安装 dependencies,也能轻松实验 recipes。访问本书 repository,在 README 中查找每章示例的 Colab links。
See Also
LangChain 文档覆盖 RAG applications 的 architecture、integrations 和 API references。
LlamaIndex 文档提供 indexing strategies、query engines 和 advanced retrieval patterns 指南。
Haystack 文档解释 pipeline-based RAG design 和 production deployment。