为了尽量减少像素之间的相关性,我们可以在整个图像上均匀地选择问号像素,如下图所示:
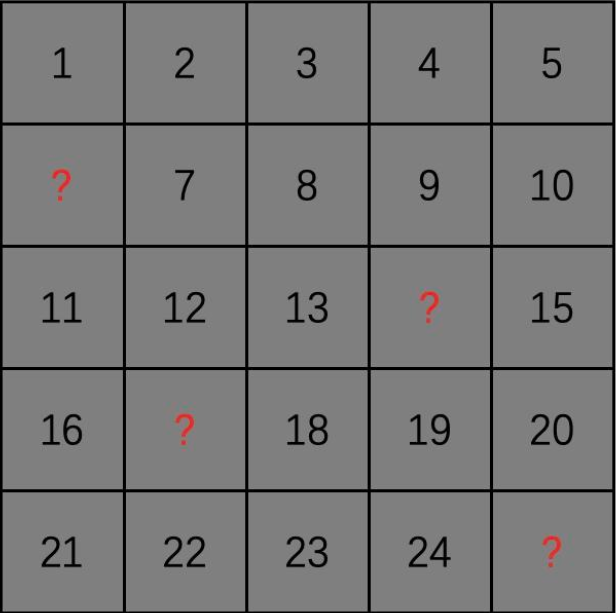
在上图中,我们随机地遮盖(mask)一些像素点(即问号像素),然后利用其余的像素点一次性预测被遮盖的像素点。
现在,我们希望将这种方法推广到极限,即一次性预测所有像素点,但需要确保所有预测的像素点彼此不相关。那么如何解决呢?
首先,我们可以将之前的硬遮盖(hard mask)变为软遮盖(soft mask),即不是直接从无预测到有,而是预测像素值的 "变化"。
其次,回顾自回归生成图像时的第三个缺点,即缺乏有序性。我们不再将像素值预测视为分类问题,而是视为回归问题,然后预测每个像素值的 "增量","增量" 代表的是对目前像素值的改进,将多次的改进都 "加起来",就得到了最终的图像的像素值。
最终,我们的模型被改造成下面的样子:
我们输入一个 "近似" 图像,然后神经网络根据该 "近似" 图像一次性预测出对整个图像像素值的 "增量"(每个位置的像素值增量是不一样的)。这些增量代表了对近似图像的改进,通过应用这些预测的增量来改进近似图像,最终得到一个更好的图像。不断重复上面的过程,最终生成一个高质量的图像。
整个过程可以用下图形象的描述:
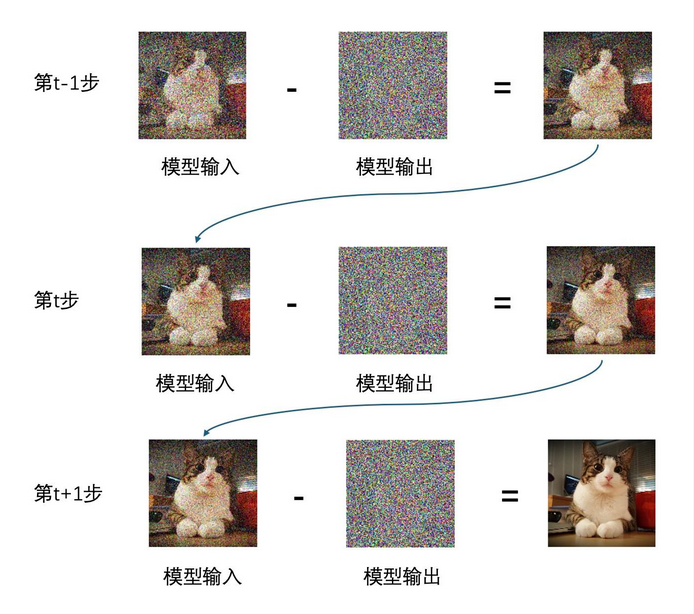
我们在第 t-1 步,利用带有噪声的图像,通过神经网络预测其噪声分布,然后从图像中减去这个噪声(这里的增量是负的噪声),得到改进后的图像,即下一步的输入,不断重复这个过程多次,最终生成了一个清晰的图像。
显而易见,这种方法也算是一种自回归模型,它正是著名的 DDPM 扩散模型。当然,DDPM 在具体的实现上和上述过程略有差异,但这些差异并不影响其本质。
**扩散模型(diffusion model)**成功地规避了前文提到的几个缺陷。
**首先,生成效率得到了显著提升。**在扩散模型中,我们一次性可以预测所有像素的增量。相比于 next token prediction 逐像素预测的方式,扩散模型的生成速度更快。
**其次,模型对样本的利用效率更高。**在下一个 token 预测中,理论上需要 个模型,每个模型输入的 token 长度不同。实际应用中,我们用一个模型代替了这 个模型。但在扩散模型中,我们只需 T 个模型,其中 T 是扩散模型的步数,实际应用中,我们用一个模型代替了这 T 个模型。通常情况下,DDPM 在 1000 到 4000 步之间就能取得良好的效果,远少于 的数量。
**最后,扩散模型天然考虑了像素值的有序性。**因为它是基于回归而非分类。此外,它避免了下一个 token 预测中的就近偏差问题,因为它每次预测的是整体像素的 "增量"。