1.大语言模型(Large Language Model,LLM)
大语言模型是指基于大规模神经网络 ,通过自监督 或半监督 方式,对海量文本进行训练的语言模型。 【可以询问任何问题】
【规模巨大、通用性强、训练方式不同、交互方式革命】
1.1 神经网络
一个通过数据 训练出来的、由大量参数 组成的复杂决策系统,可视为极其高效的"团队工作流程"或"条件反射链"。


大规模神经网络 :参数规模通常达数十亿 至万亿 级别,例如GPT-3 包含1750亿参数。
1.2 自监督、 半监督
自监督 就是让模型从数据本身找规律 ,自己给自己当老师。


半监督 就是"少量指导+大量自学"的结合模式。


1.3 语言模型
语言模型就是一个计算 "接下来最可能说什么 "的模型

1.4 主流的LLM

1.5 LLM核心能力
(1)理解与创造
它真正"读懂 "了人类语言的千变万化 ,并能进行高质量 创作;这早已超越 简单的关键词匹配,而是对上下文 、情感 乃至潜台词 的深层理解。
(2)全球知识库
大模型并非 简单的信息存储 硬盘,它通过学习 海量数据,将孤立 的知识点编织 成内在关联 的立体知识网络。
(3)思维逻辑
大模型的能力版图不仅 局限于人文领域的感性表达,更 延伸至严格的逻辑推理 与编程语法。
(4)多模态
打破纯文本的单一界限,连接视觉与听觉 的世界;上传一张照片 ,辅以一段描述 ,AI便能开启对话式的创意工作流 ;让AI更接近人类的综合感知 方式,使其真正进化为"全能型"数字助手。

1.6 LLM的重要性

2.LLM的提示词编写技巧
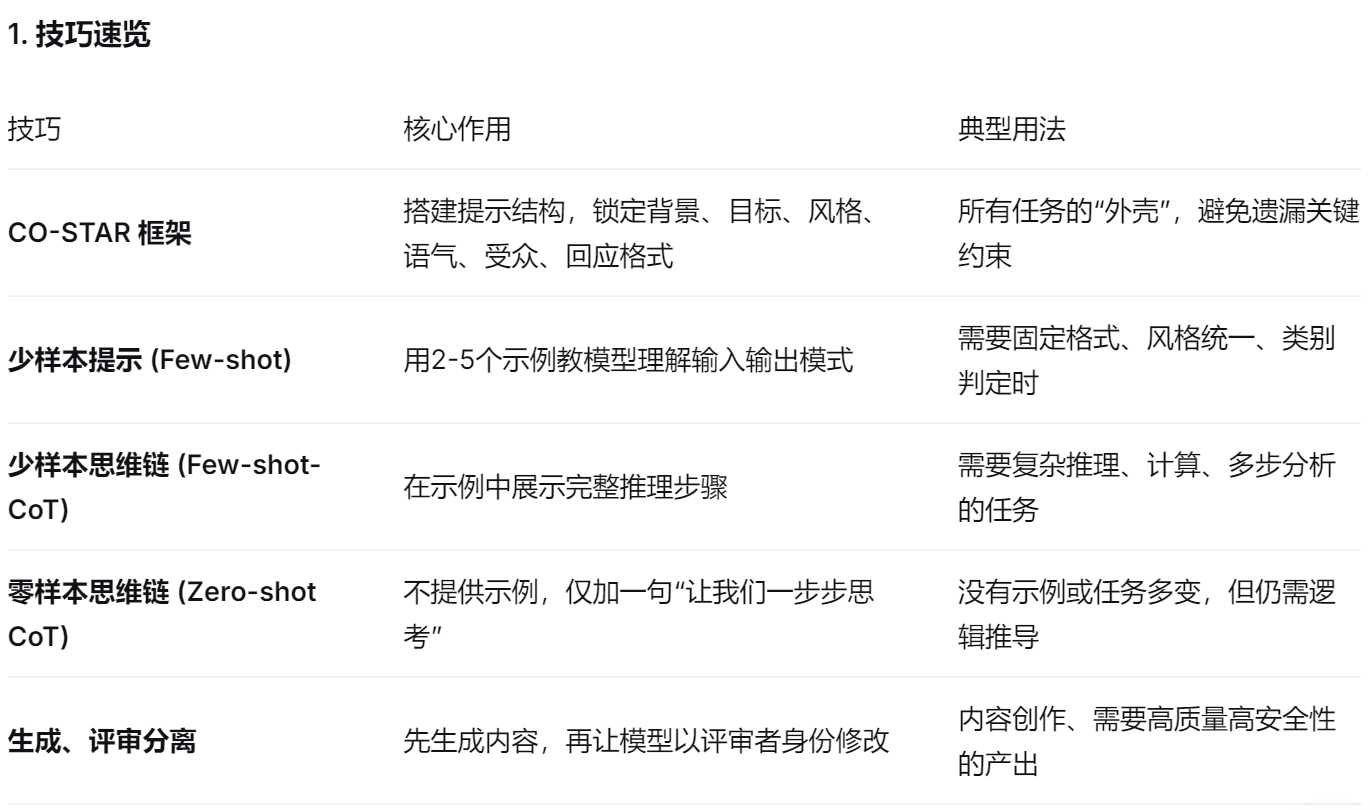
好的提示词能显著提升 模型输出的质量和相关性;AI对你一无所知 ,需要将你的问题限定范围,让AI知道你具体要什么;掌握多种技巧,并根据不同任务灵活组合使用。
2.1 CO-STAR 结构化框架
在目标设定 和问题解决 的场景下,清晰性和结构性是至关重要的。

通过这个结构,LLM 能精准理解:你是谁、你要做什么、怎么做、对谁说、用什么口吻、输出什么格式,从而极大提升结果的可控性和可用性。

它介于 零 样本提示-无 示例、微调- 需要大量标注数据训练模型 之间。
2.2 少样本提示 Few-shot
提供2~5 个包含****输入→输出 的示例 ,用例子代替 长篇规则,教 模型你想要的结果 ,进而对新 的输入生成正确 的答案。


为了提升 AI对复杂逻辑任务(数学题、逻辑推理、复杂决策等)的理解能力,可以使用少/零 样本思维链提示。
2.3 少样本思维链 Few-shot-CoT
它在给大语言模型提供少量示例 的同时 ,每个示例不仅 包含输入 和最终输出 ,还包含中间推理步骤 (即 思维链 );让模型学会推理逻辑 ,对新的输入先逐步思考 ,再给出答案。

少 样本思维链的简化 版,且与普通零样本提示 相比,它能让模型在复杂推理任务中表现更好。
2.4 零样本思维链 Zero-shot CoT
它在不给任何示例 的情况下,直接要求大语言模型"一步步推理并得出结论",从而引导模型 生成中间推理 步骤,再得出最终答案。
适用于你不太清楚 具体步骤,但 需要逻辑思考的任务。

2.5 生成、评审分离
将任务明确分为两个 阶段:生成 阶段和评审 阶段,先产出初步 的回答,再对自己生成的内容进行检查、批评、修正,****并给出最终的完善输出。
这种分离方式能有效减少 模型的幻觉和错误,提升 答案质量,常用于需要严谨性的任务(如数学计算、逻辑推理、代码生成、文案优化等)。

2.6 总结
根据不同任务灵活组合使用,组合方案不限。

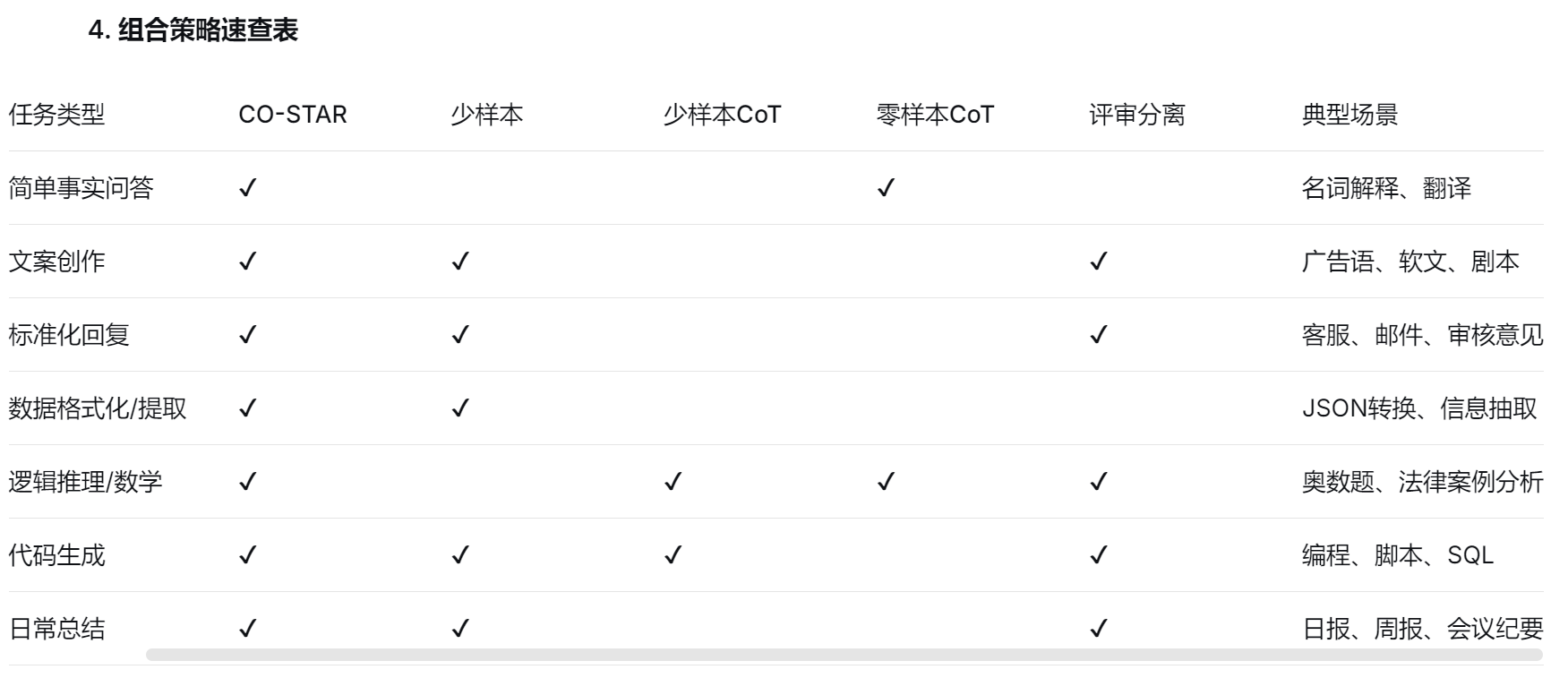
遇事先想 CO-STAR,有样学样 Few-shot, 推导逻辑带 CoT,质量把关用评审。
Cursor官方提示词:https://cursor.directory/plugins
3.LLM的接入方式
开发AI应用 ,需要直接与大语言模型 提供方 进行交互 (接入LLM),常见的原生接入 方式有以下三种。
3.1 API远程调用(主流)
模型厂商 在云端 部署模型 ,开发者通过 HTTP请求**+API直接调用** ,无需 关心底层实现细节 ;简单、便捷,适用于快速应用集成;
常见厂商:OpenAI(GPT-4o)、Anthropic(Claude),Google(Gemini),百度文心一言,阿里通义千问、智谱AI等。
(1)注册账号并获取 API Key
在模型提供商平台注册,获取用于身份验证的密钥。
(2)查阅 API 文档
了解请求端点 、必填/可选参数 (如模型名称、提示词、等)及返回的数据格式 ;也 可以查看其他相关信息。
(3)构建 HTTP 请求
使用代码中的 HTTP 客户端库 (如 Python 的 requests),在请求头 (Header)中携带API Key ,在请求体 (Body)中以 JSON 格式放入提示和参数。
(4)发送请求并处理响应
将请求发送至指定的 API 地址 ,云端服务器收到请求,验证 API Key → 运行 模型推理 → 返回 JSON 数据 ,提取 出模型生成的文本内容。
以deepseek 为例 https://www.deepseek.com/
(1)注册账号并获取 API Key
使用电话号注册即可

输入名称,并复制 API key!
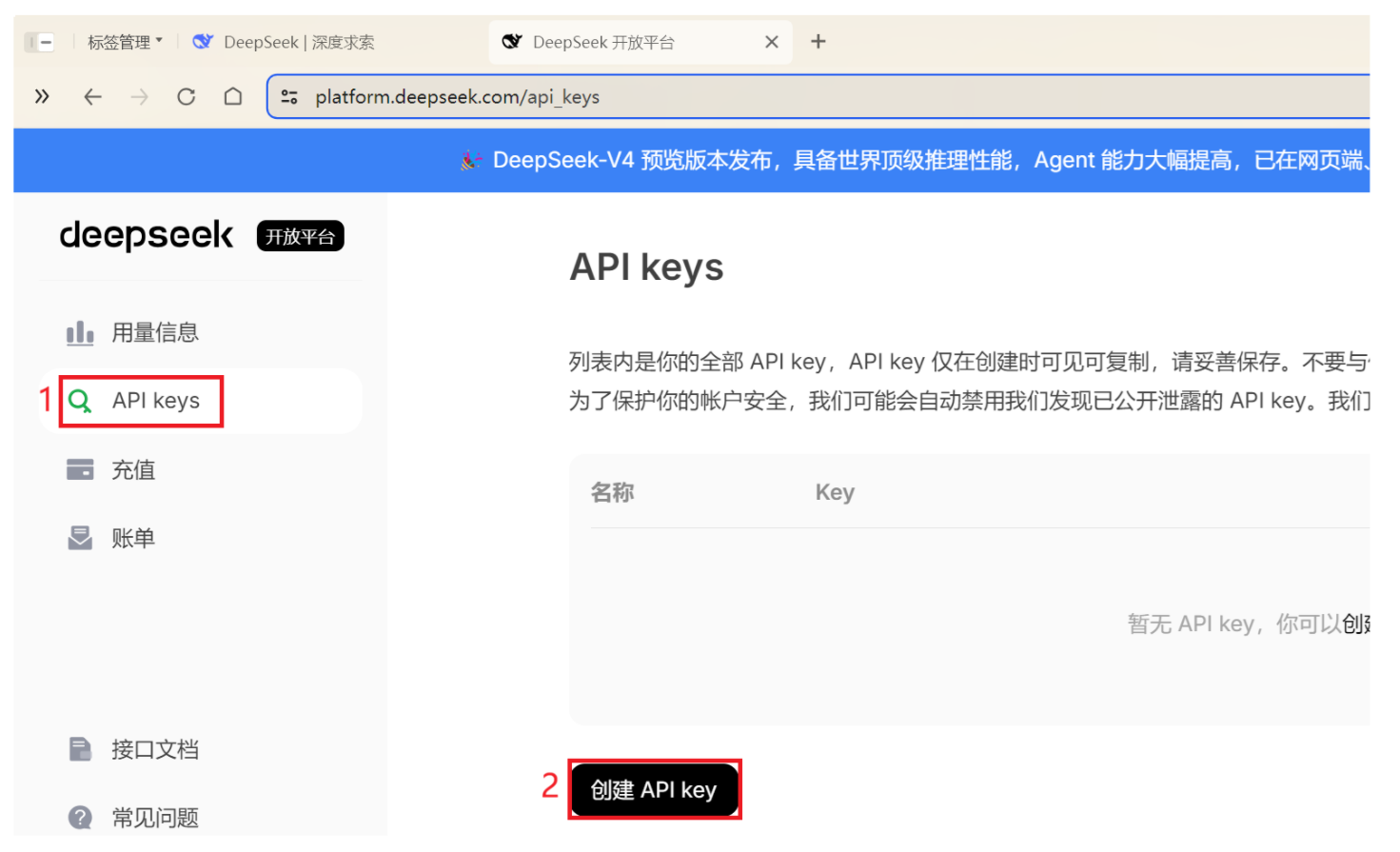
秘钥:sk-1545159be55041ca97a4c088a5afcb2d
(2)查阅 API 文档
先使用curl命令

下面我们先简单使用 一下,请求体中仅 加模型名称 和用户输入。
(3)构建 HTTP 请求
此处使用postman简单演示一下,输入请求头 和请求体 ,以及之前保存的秘钥。
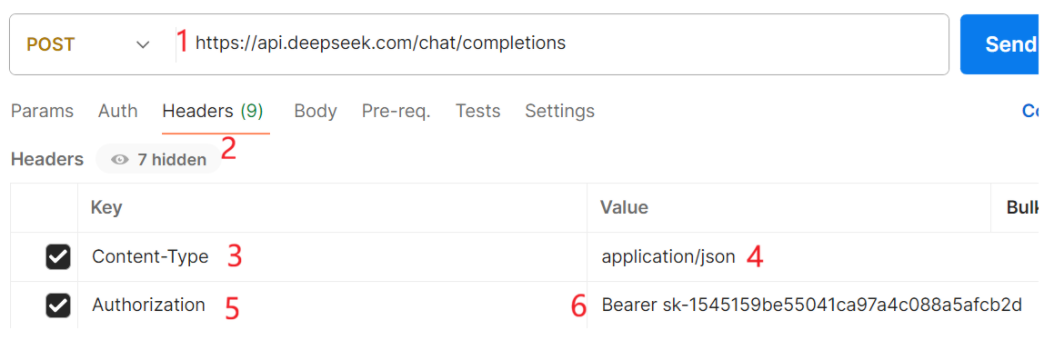
注 :秘钥前面的 Bearer 别忘了,模型平常用deepseek-v4-flash(轻量/快速版)即可。
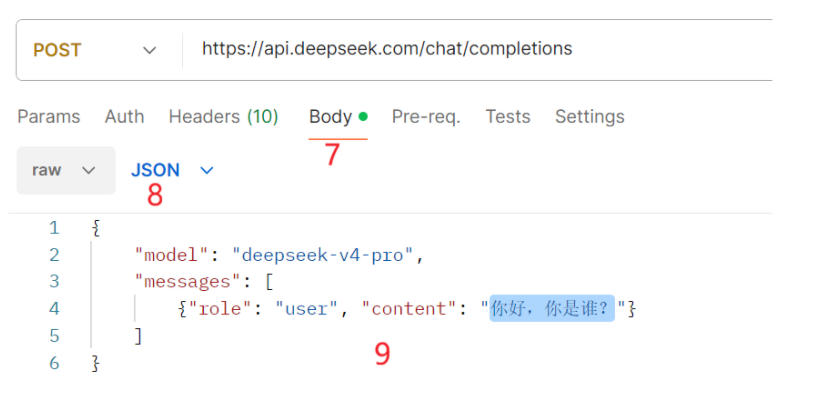
记得先充值点
(4)发送请求并处理响应
点击Send

3.2 本地部署-开源模型
将开源的LLM (如Llama、ChatGLM、Qwen)下载到自己的硬件 环境(本地服务器/私有云)上。
利用推理框架 (如 Ollama、llama.cpp、vLLM 等)在本地服务器/GPU 上启动模型 ;然后通过 API、命令行、Web 界面 等方式进行交互。
(1)获取模型 :从Hugging Face(国外)、魔搭社区(国内)等平台下载开源模型的权重。
(2)准备环境 :配置具有足够显存 (如NVIDIA GPU)的服务器,安装 必要的驱动 和推理框架。
(3)选择推理框架 :使用专为生产环境 设计的框架 来部署模型

(4)启动服务并调用 :框架会启动 一个本地API服务器 (如 http://localhost:8000 ),你可以像 调用云端API一样向这个本地 地址发送请求。
以Ollama 为例,它支持多种开源 模型(如qwen、deepseek、LLaMA),并提供简单的API接口。
(1)下载并安装Ollama
官网:https://ollama.com/download
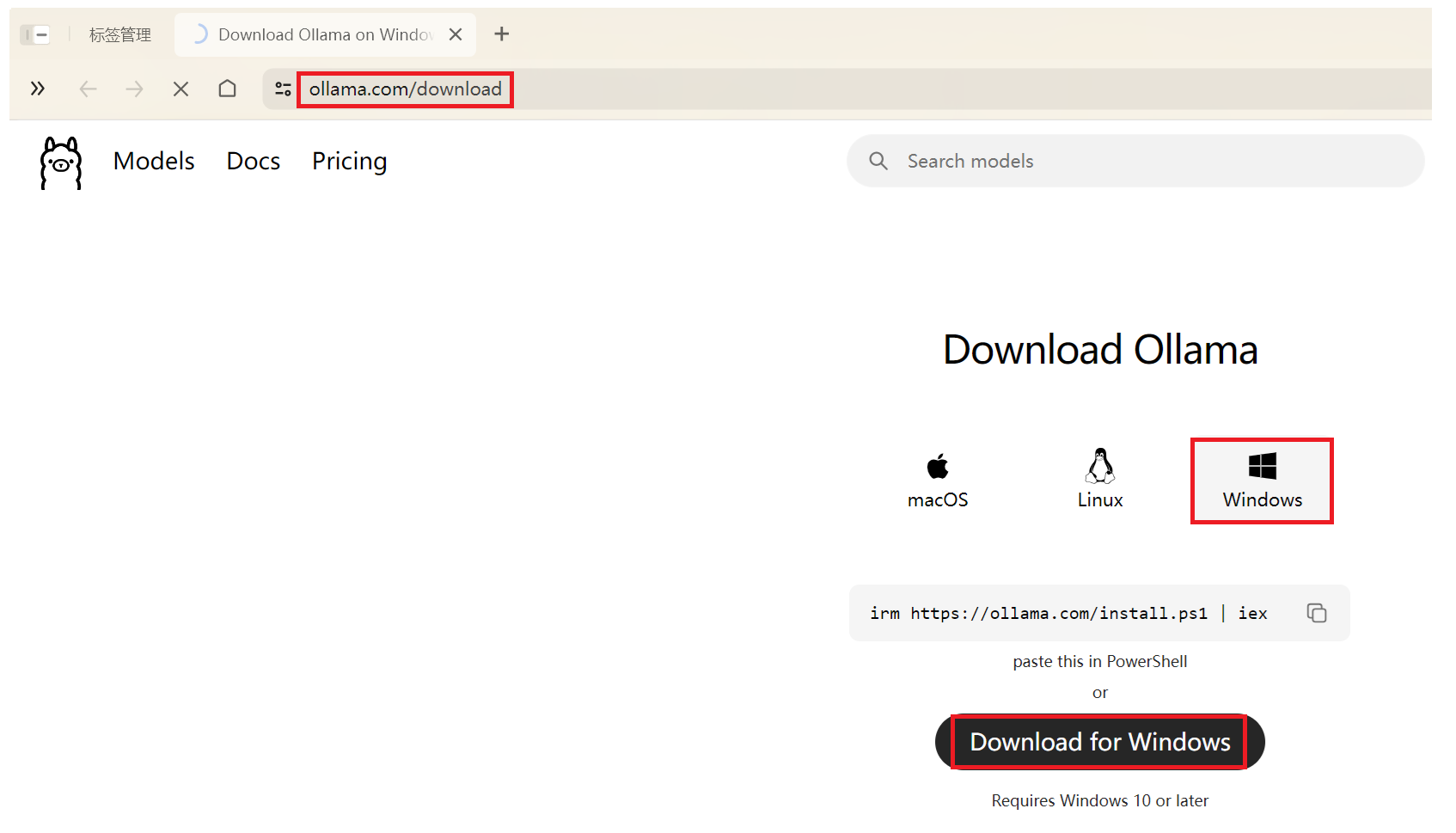
魔法网正常网切换 下载会快一点,下载好后点击 ,默认安装即可 ;安装完成后,Ollama会默认 启动。

查看启动是否成功 : http://127.0.0.1:11434/
或 使用cmd 输入 ollama --version

(2)拉取模型 :Ollama可以管理和部署模型 ,我们使用之前,需要先拉取模型。
① 修改模型存储路径到D盘 ,可通过配置系统环境变量 设置,变量名: OLLAMA_MODELS 变量值: ${自定义路径}
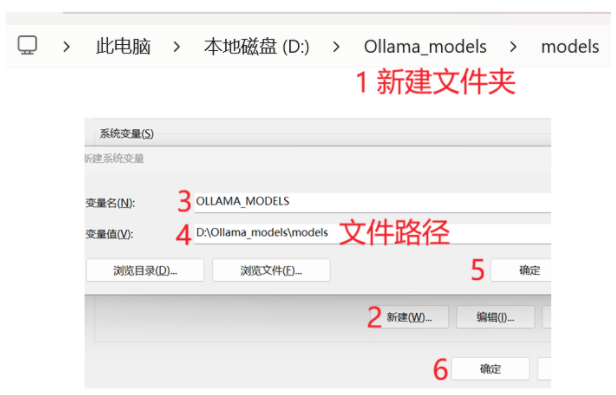
或 Ollama界面设置
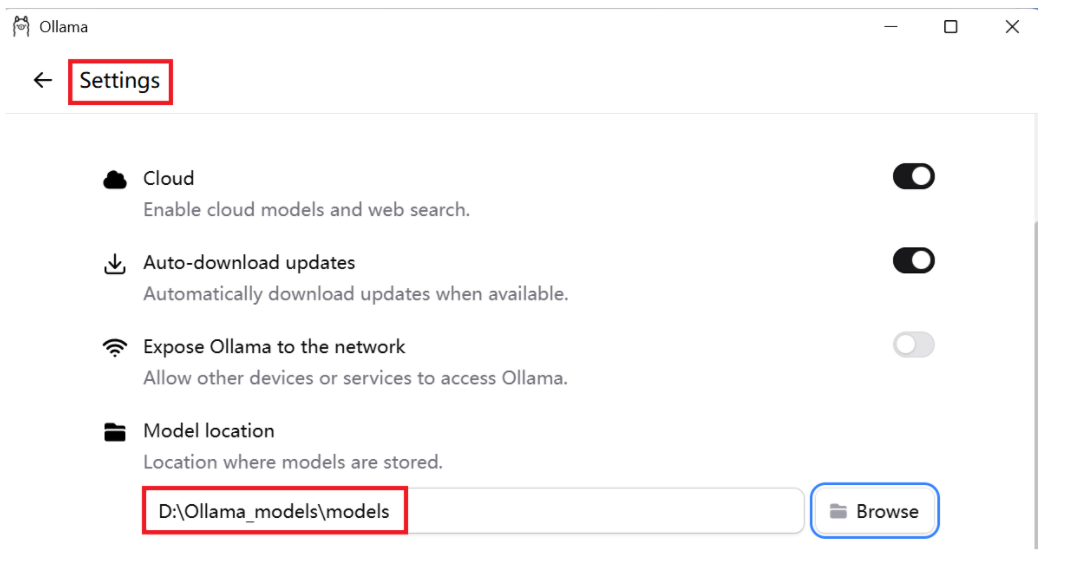
设置完成后,重启 Ollama。
查找模型 https://ollama.com/search
②正式拉取模型 :以deepseek-r1 为例,根据自己机器的配置及 需求来选择相应的版本;版本以 1.5b 为例。
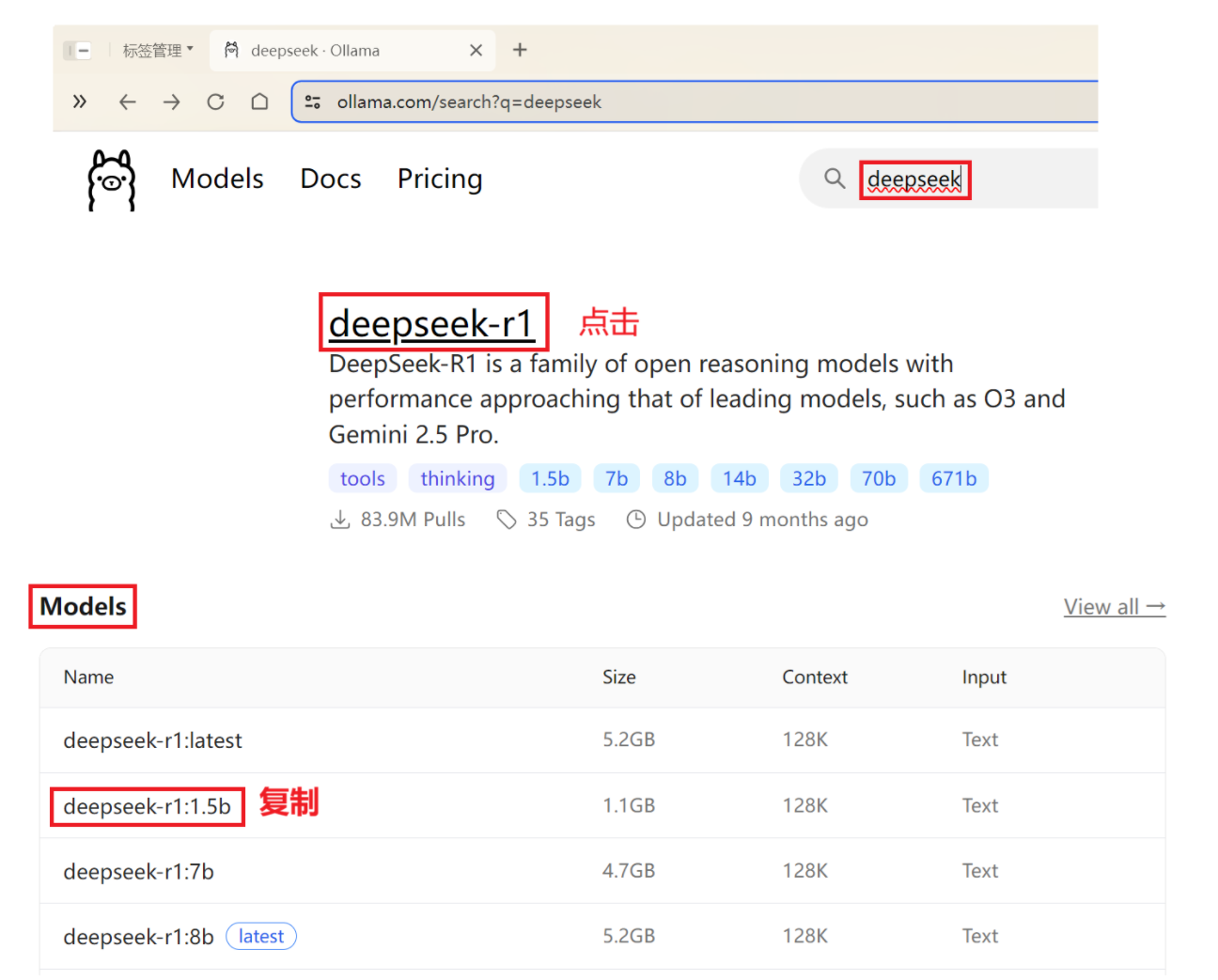
版本分为1.5b、7b、8b 等,b是Billion(十亿) 的缩写,代表模型的参数量级 ; 671b 为满血 版本,其他 版本称为蒸馏版本。
参数越多→模型"知识量"越大→处理复杂任务的能力越强 ,硬件需求也越高。
在cmd 中输入 ollama run deepseek-r1:1.5b 进行下载 。
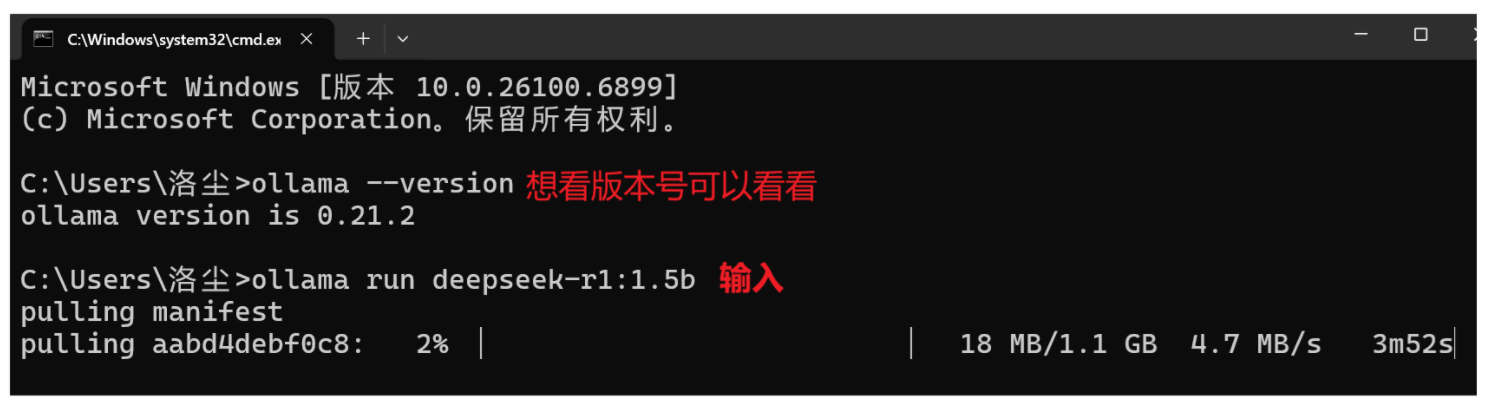
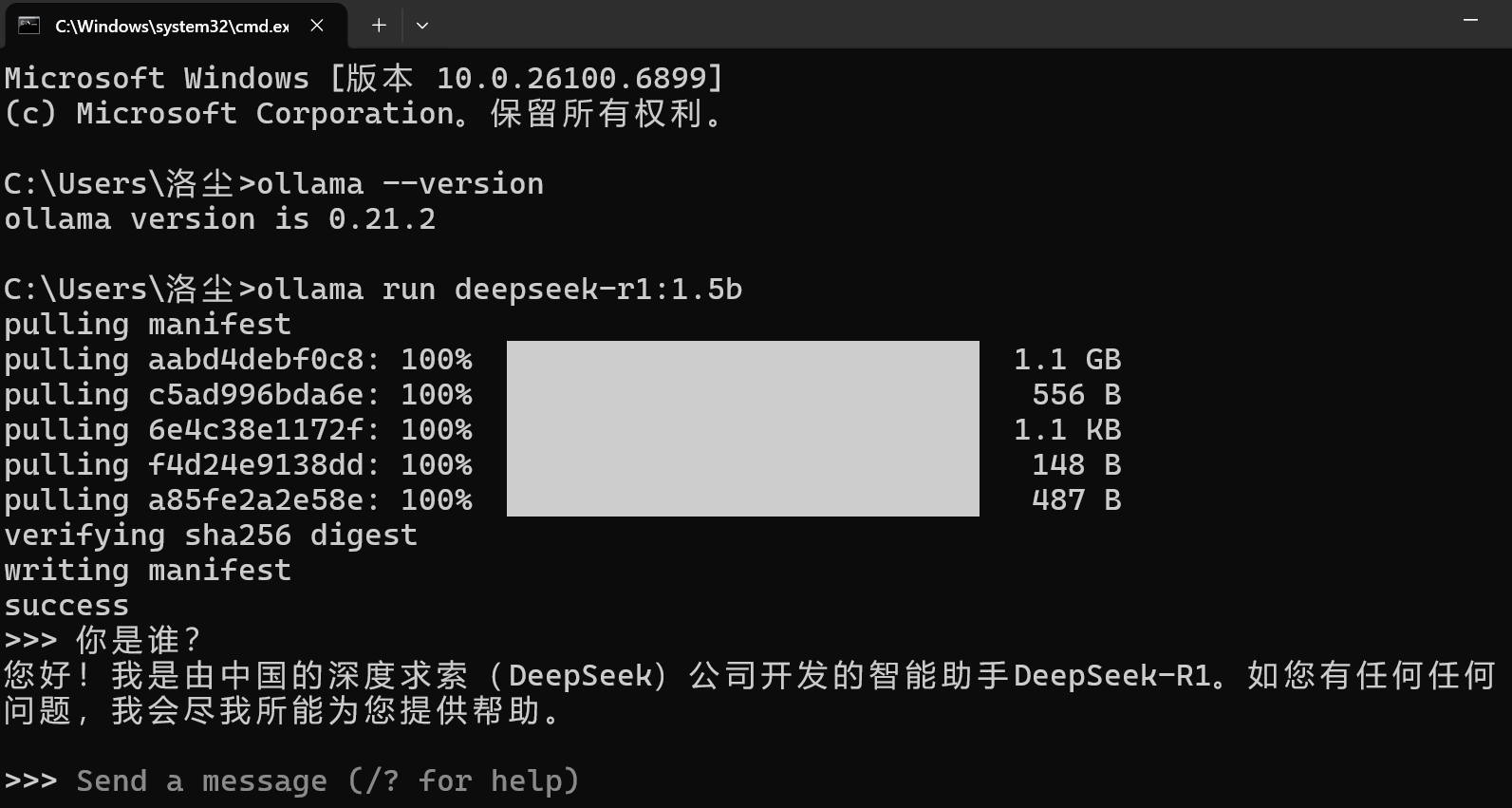
(3)测试
下载完成 后,可以通过命令行和AI模型对话;
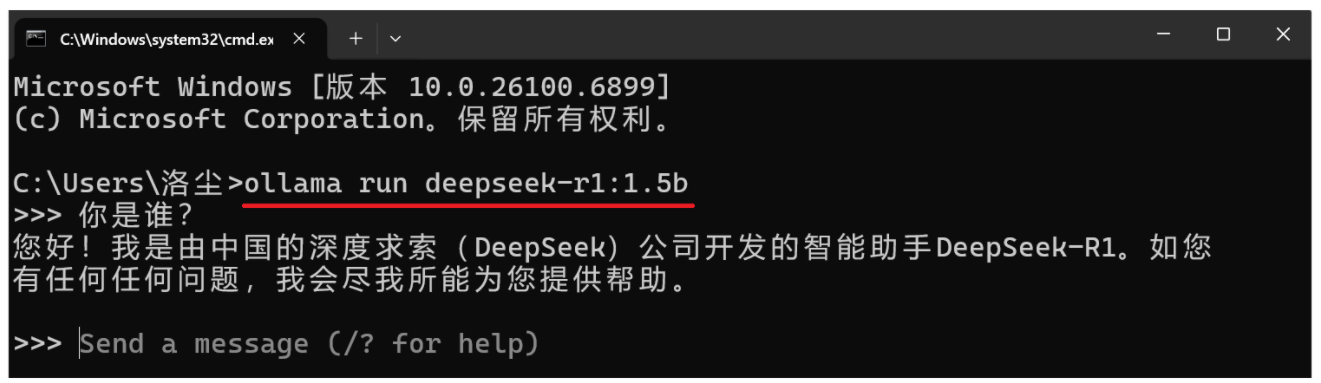
下次登录输ollama run deepseek-r1:1.5b即可
查看已下载 的模型:ollama list

(4)也可以通过接口调用
向本地 Ollama 服务 发送一条对话请求 , 服务处理后会 返回一个JSON 对象,其中包含模型的回复内容。

此处使用postman简单演示一下
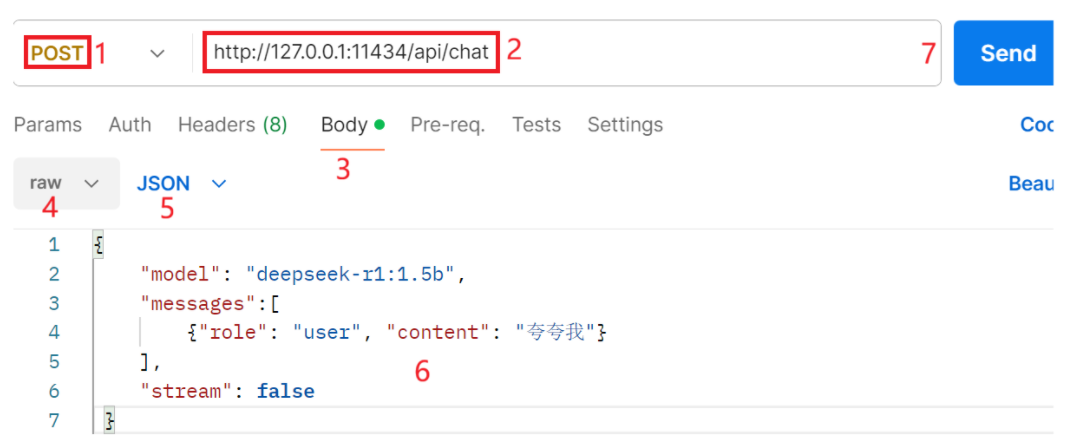
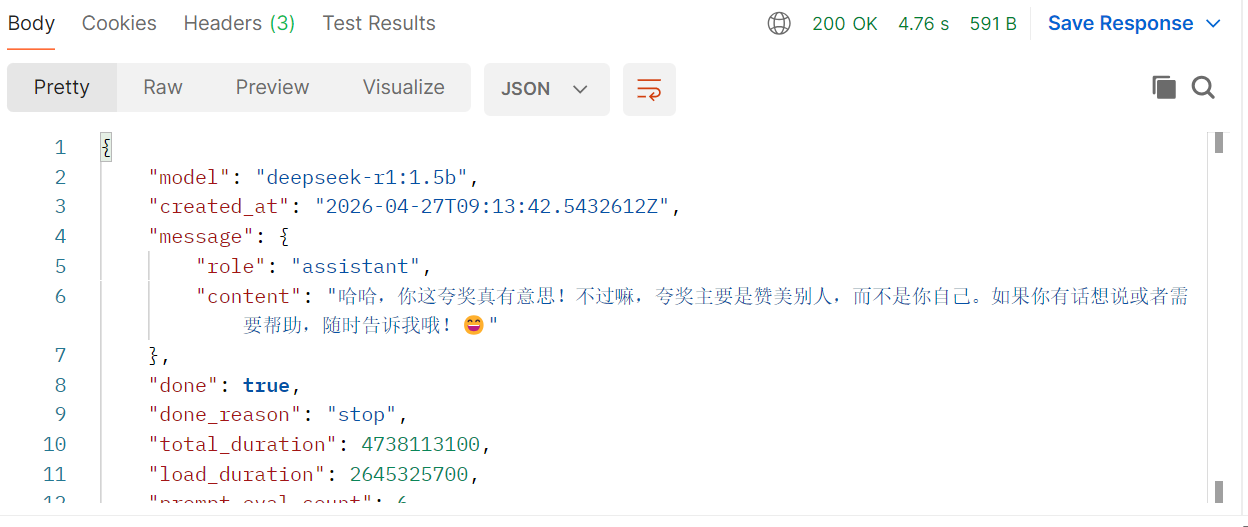
对4.1 API 远程调用 的进一步优化
3.3 SDK、官方编程语言库
SDK 接入本质上不是 一种独立的接入方式,而是对底层 HTTP API 调用 的封装与简化。
模型厂商 (或社区)提供的官方编程语言库(如 OpenAI Python SDK)会隐藏 认证、请求构造、流式解析等细节,将复杂 的远程调用包装 成符合语言习惯的本地函数。
开发者只需引入这些官方或 第三方工具包,就能以极低成本、快速且安全地 让程序拥有大模型对话能力,显著简化开发流程。
以 OpenAI Python SDK为例
(1)在python中安装库
新建项目
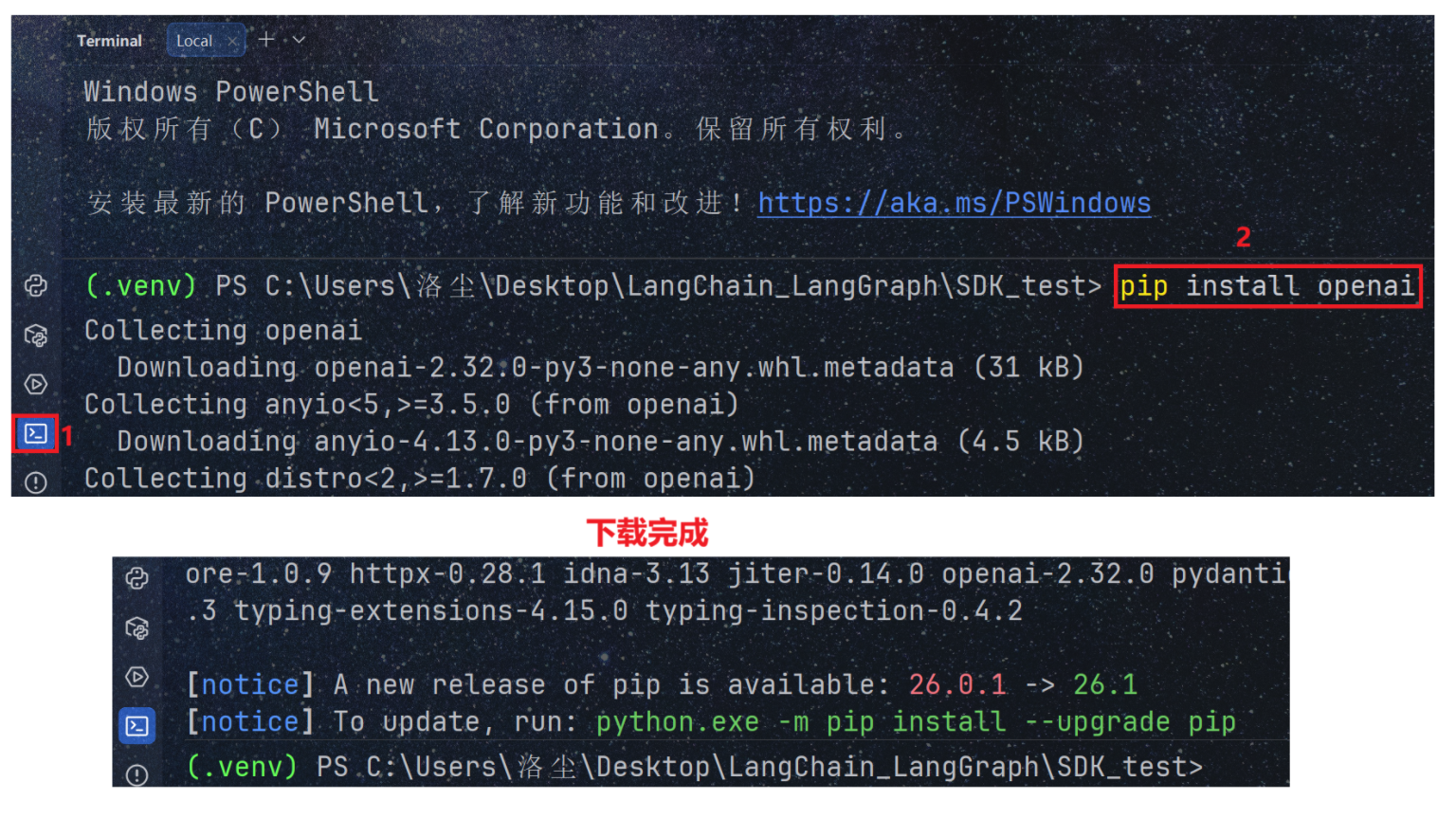
安装库:pip install openai
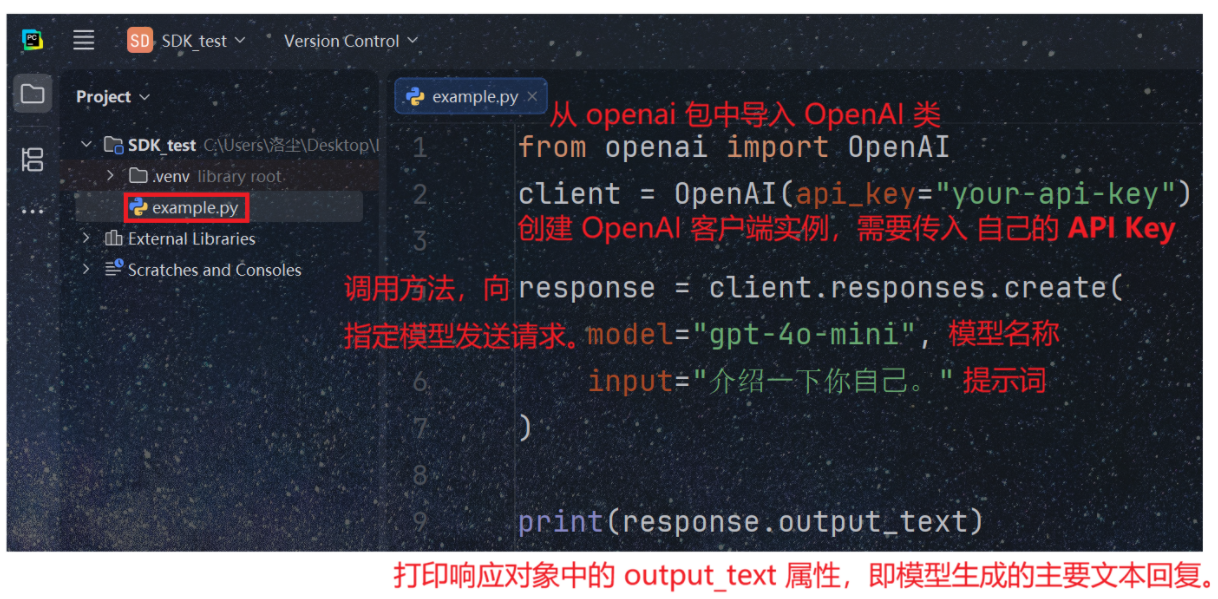
(2)**创建 一个名为example.py** 的文件 ,输入代码 ;输入 OpenAI 对应的秘钥,此处使用gpt-4o-mini模型。
python
from openai import OpenAI
client = OpenAI(api_key="your-api-key")
response = client.responses.create(
model="gpt-4o-mini",
input="介绍⼀下你⾃⼰。"
)
print(response.output_text)4.1暂未调用OpenAI,此处暂不演示。
3.4 总结
SDK 是必选的开发工具,它并不 与"API 远程调用 "和"本地部署 "并列 ,而是为两者提供统一的调用方式。
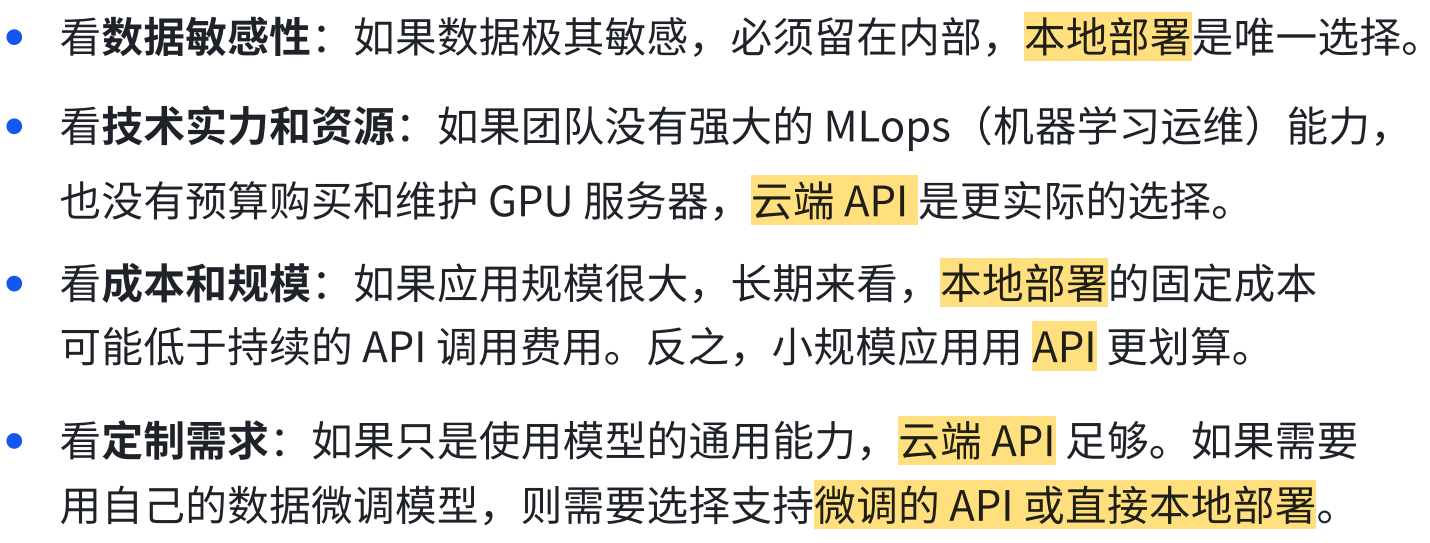

实际上,只要是原生LLM,无论怎么接入都有限制。

像LangChain这样的框架 ,正是为了系统性地解决这些问题而诞生的。

原生LLM更像一个"聪明的大脑 ",但缺少 "记忆、知识和规划能力",接入方式只 决定你如何连接这个大脑。
LangChain这类框架则是在为这个大脑装上工具、内存和外挂 ,让它能干真正复杂的活。
4.嵌入模型
4.1 概念
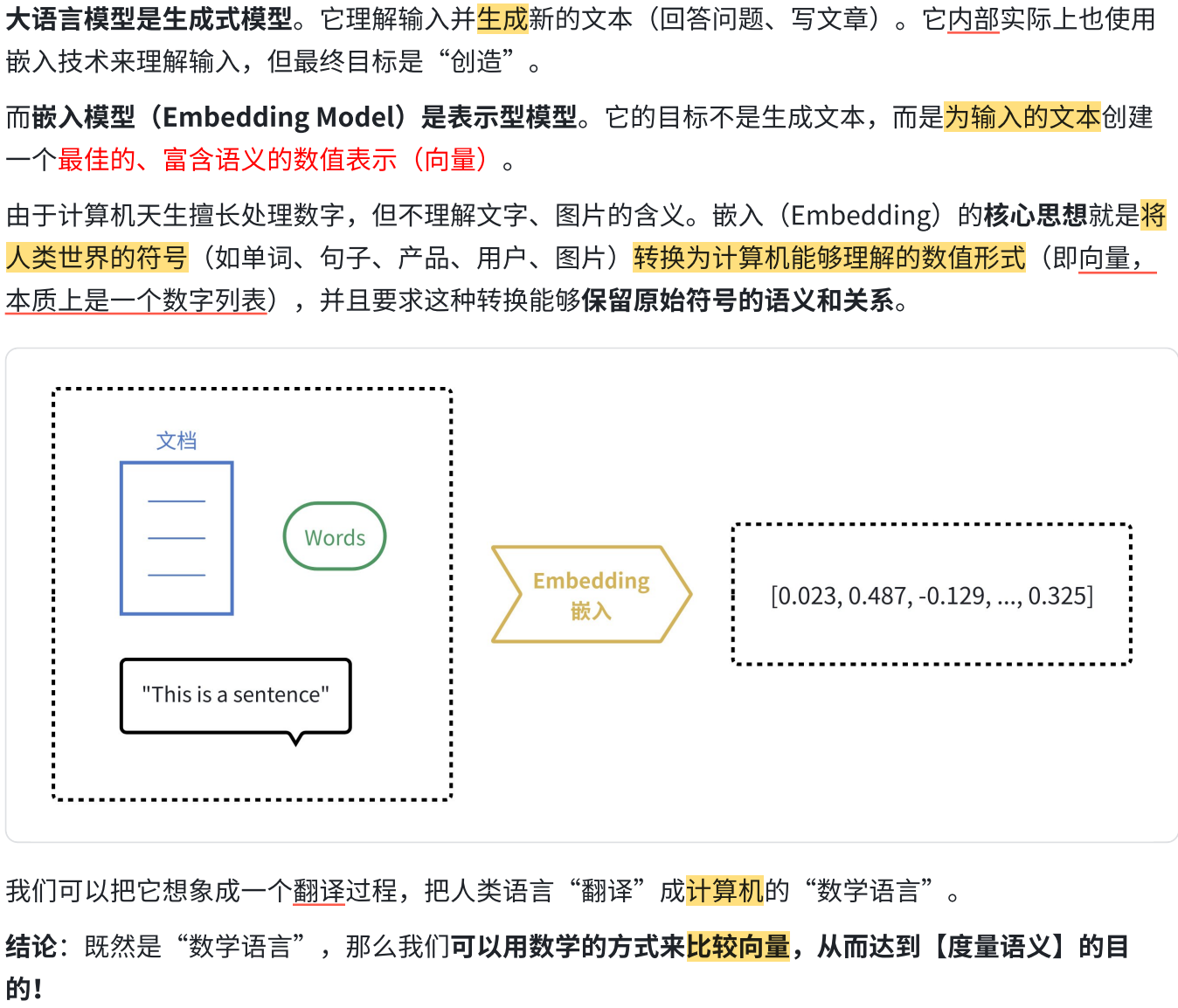
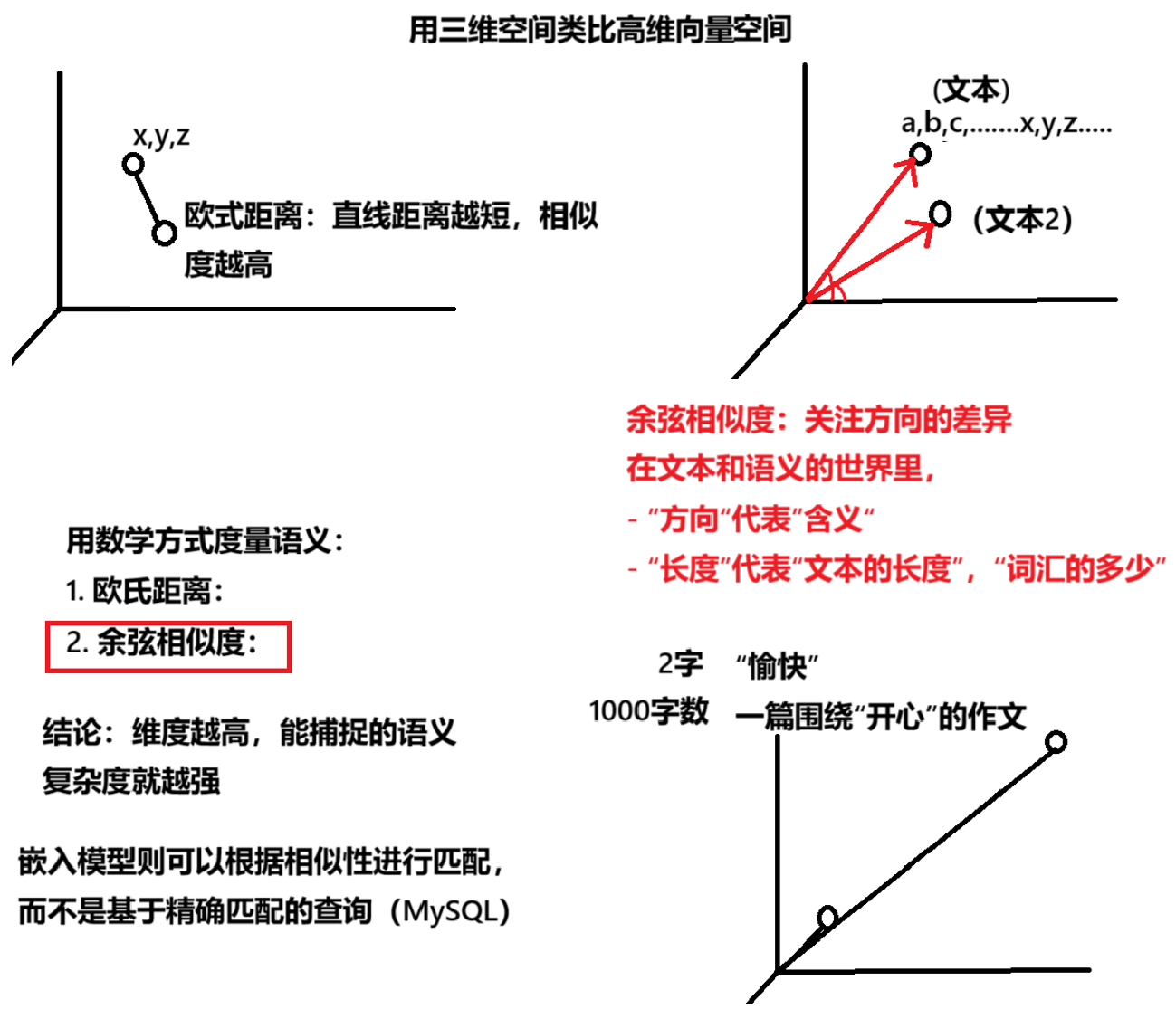
4.2 应用场景
(1)语义搜索
Semantic Search
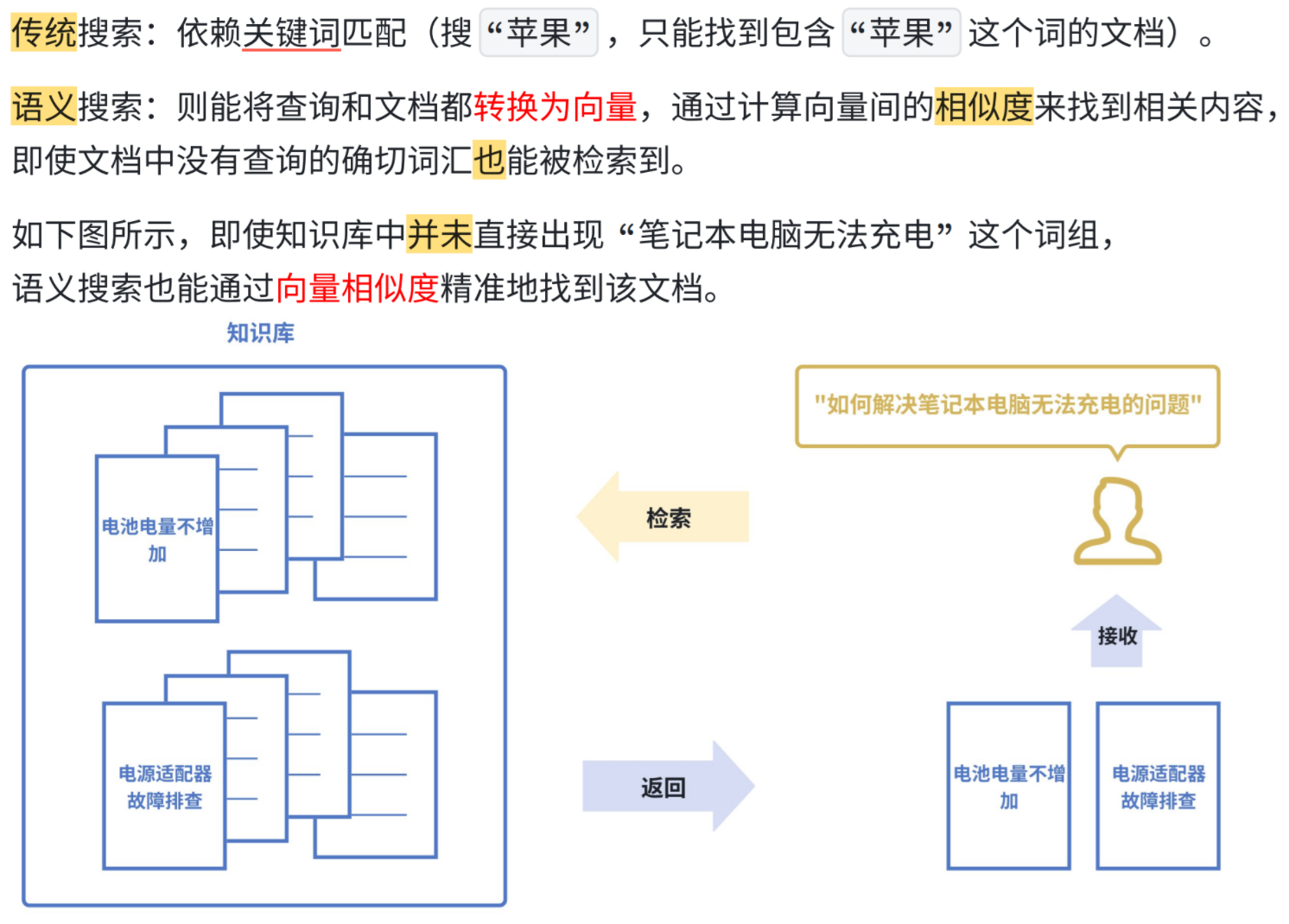
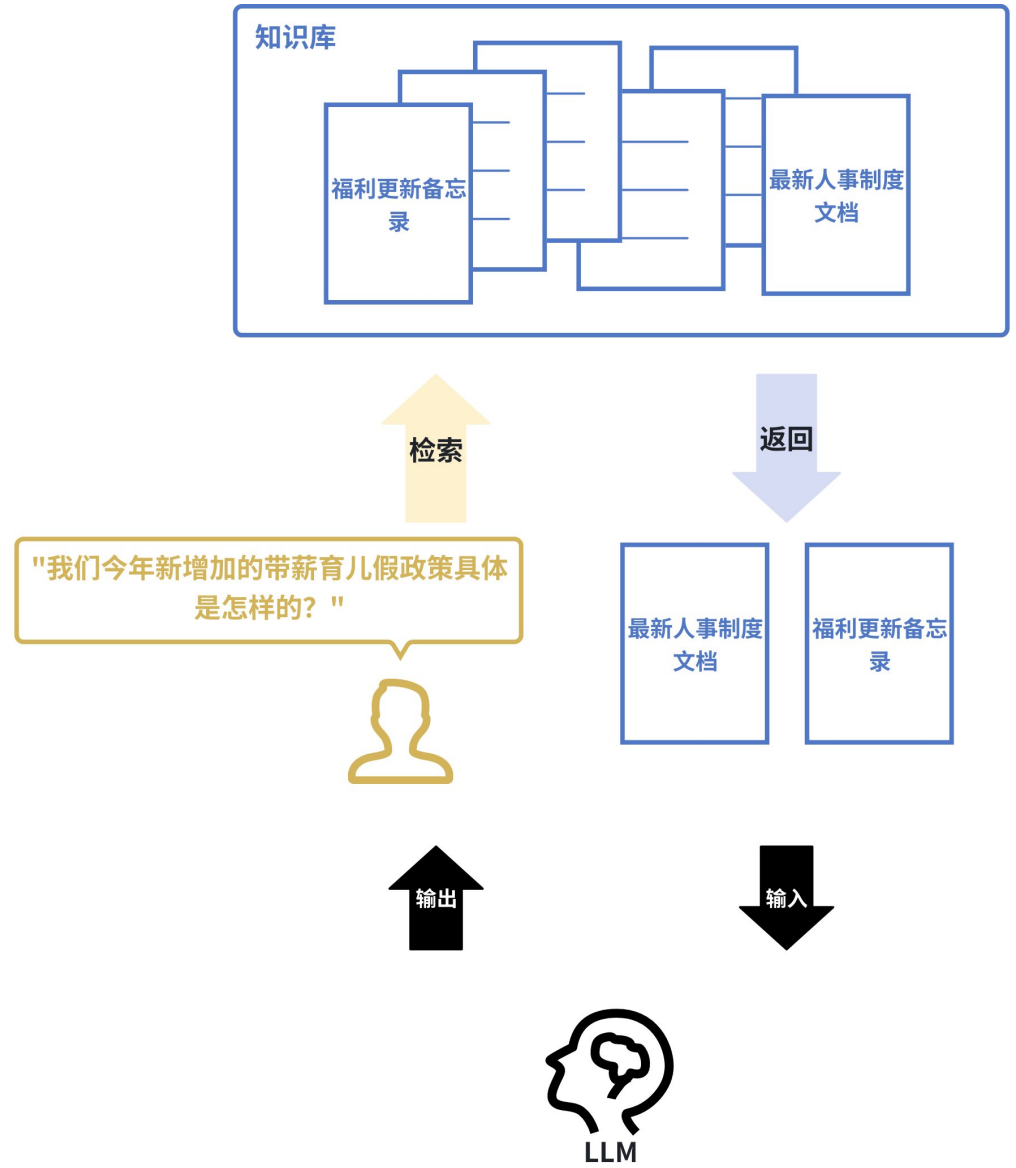
(2)检索增强生成-RAG
Retrieval-Augmented Generation


(3)推荐系统
Recommendation Systems

(4)异常检测
Anomaly Detection


4.3 主流的嵌入模型

https://huggingface.co/spaces/mteb/leaderboard
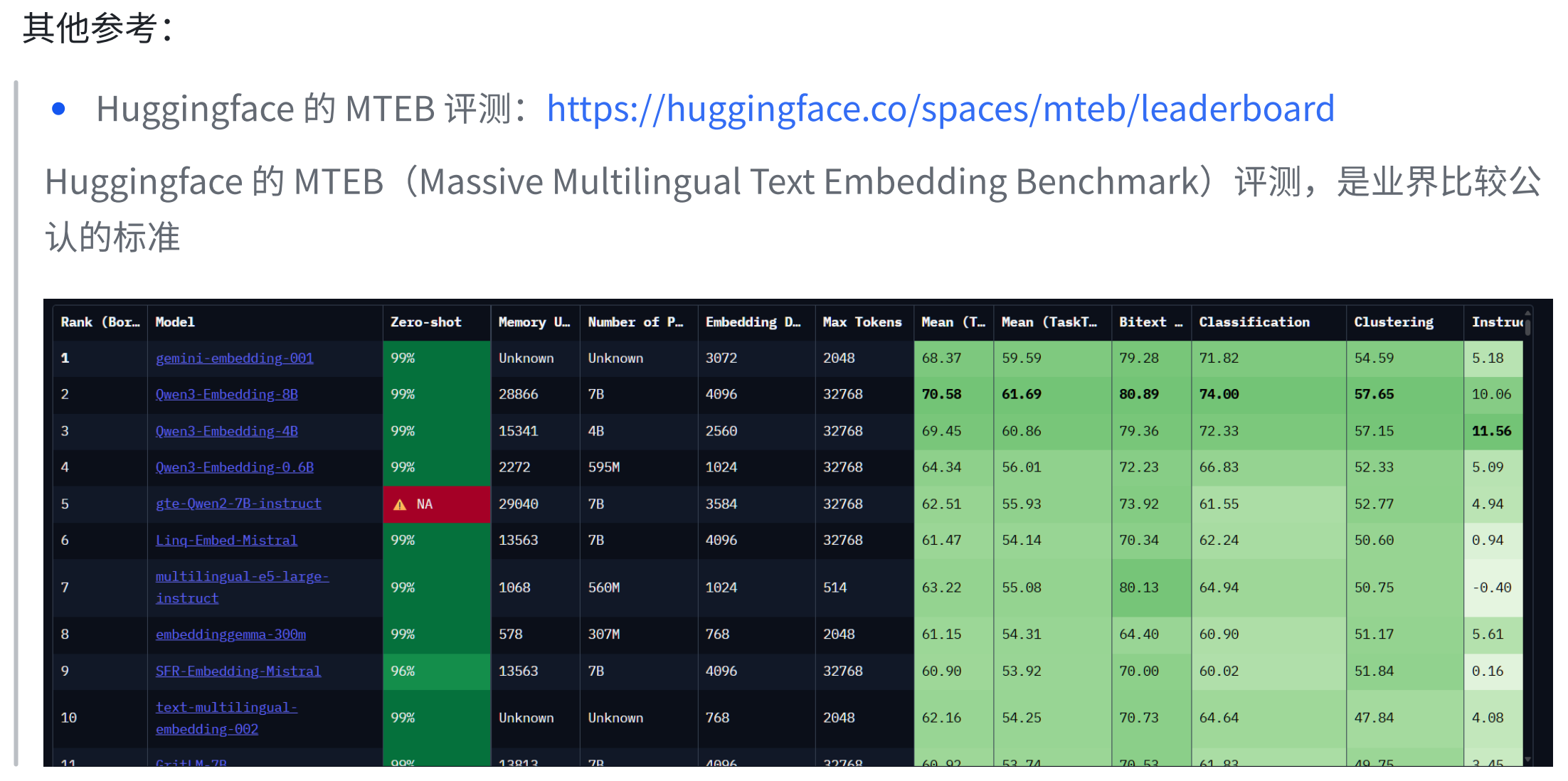
4.4 嵌入模型接入方式
接入和使用方式根据模型类型 (开源或闭源)有根本性的不同
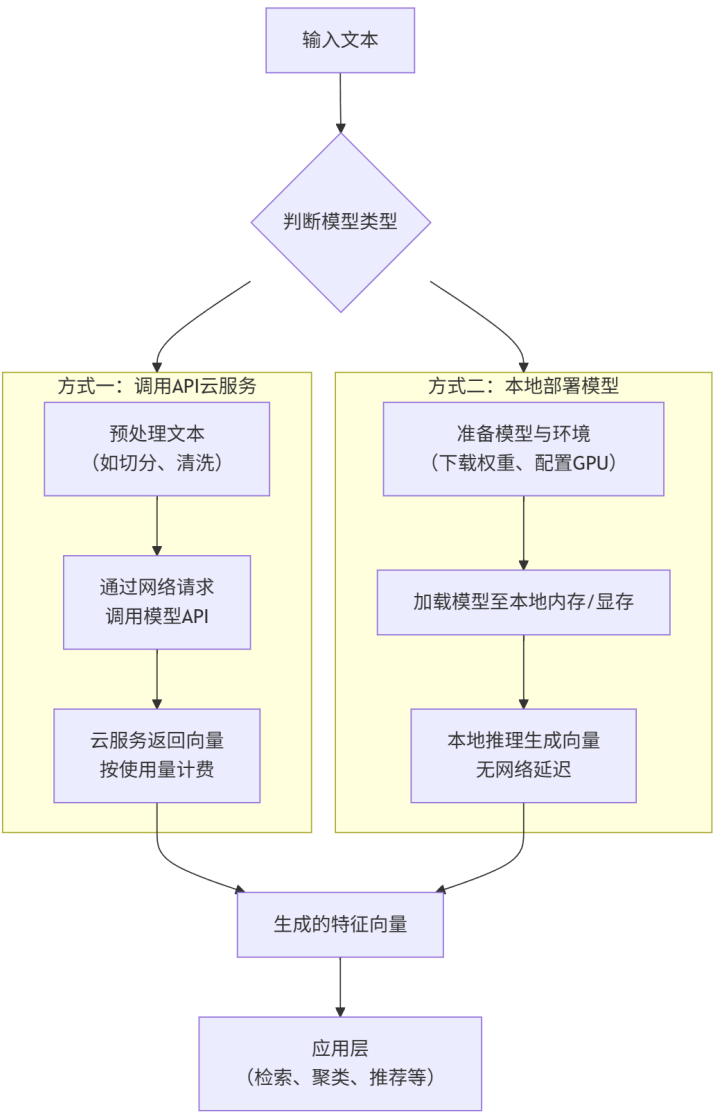
以text-embedding-3-large(OpenAI) 为例,4.1暂未调用OpenAI,此处暂不演示。
(1)API接入-闭源
向模型提供商 的服务端发送一个HTTP请求即可
①****注册账号并获取API Key :在对应的云服务平台上注册账号,获取 用于身份验证的API Key。
②****安装SDK或构造HTTP请求 :使用官方提供的SDK或直接构造HTTP请求。
③****调用API并处理响应 :发送文本,接收返回的JSON格式的向量数据。
①****类似4.1(1)
②-1****发起HTTP请求,在postman中,类似4.1(3)。

响应包含嵌入向量(浮点数列表)以及一些其他元数据

②**-2接入SDK,在python中,类似4.3。**
pip install openai
python
# 使⽤ OpenAI Python SDK
from openai import OpenAI
import os
# 1. 设置 API Key
client = OpenAI(api_key="your-api-key")
# 2. 准备输⼊⽂本
text = "这是⼀段需要转换为向量的⽂本。"
# 3. 调⽤ API
response = client.embeddings.create(
model="text-embedding-3-large", # 指定模型
input=text,
dimensions=1024 # 可选:指定输出维度,例如从3072降维到1024
)
# 4. 获取向量
embedding = response.data[0].embedding
print(f"向量维度:{len(embedding)}")
print(embedding)(2)本地部署-开源
4.5 总结

5.AI模型平台
5.1 Hugging Face(国外)

5.2 魔搭社区(国内)