在使用大模型时,我们经常会遇到两个问题:
第一,模型默认返回的是自然语言。它可能写得很像人在聊天,但程序不好直接读取。
第二,模型生成长文本时,如果等它一次性返回完整结果,速度慢而且用户体验会比较差。网页端那种"一个字一个字往外泵"的效果,本质上就是流式输出。
这篇文章主要整理 LangChain 中两个常用能力:
- 结构化输出:让模型按固定格式返回结果。
- 流式传输:让模型边生成边返回。
结构化输出
什么是结构化输出?有什么用?
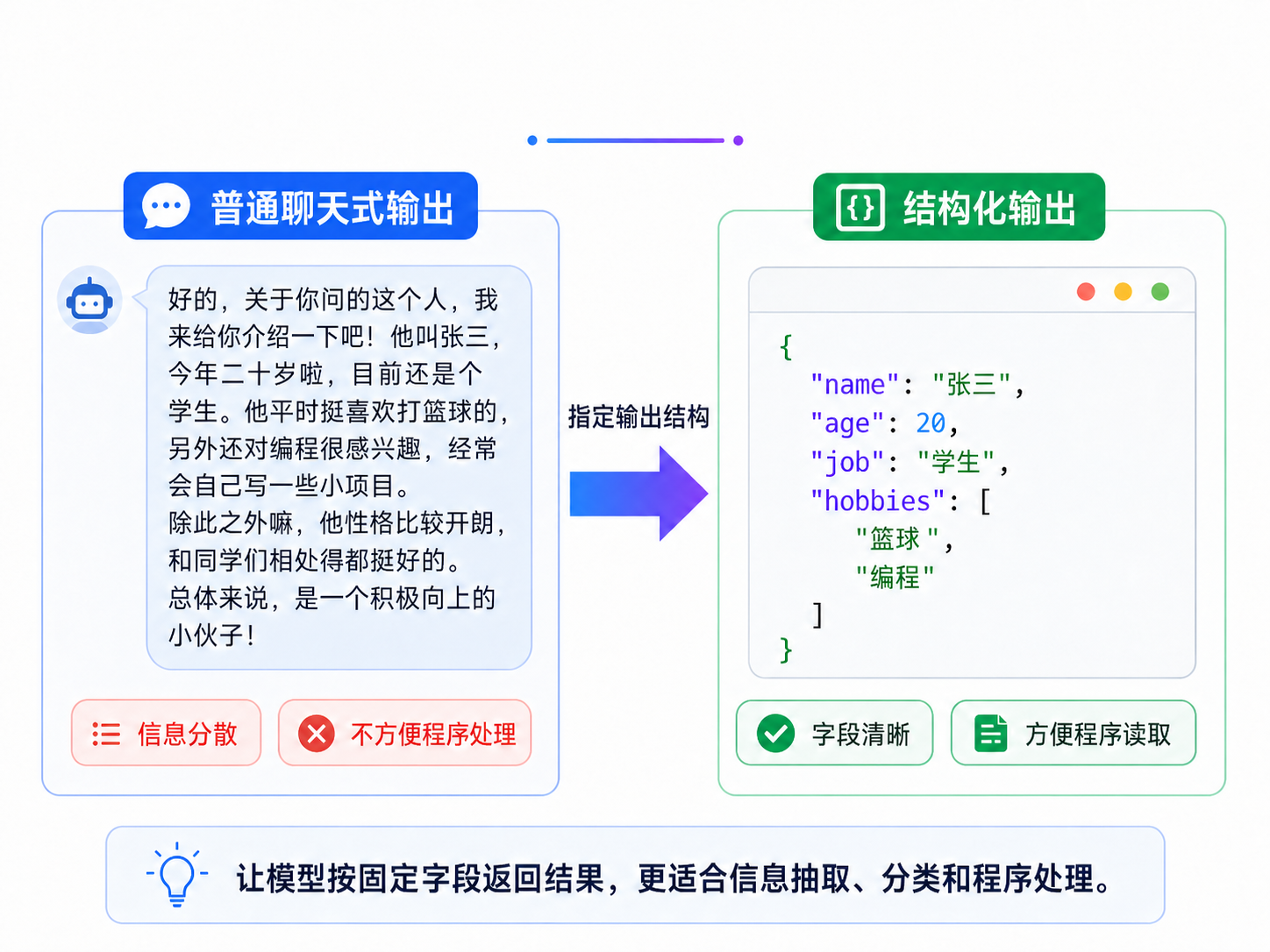
假设我们让大模型介绍一个人,它可能会返回一大段自然语言:
text
张三今年 20 岁,是一名学生,喜欢篮球和编程,目前在学习人工智能......这种输出适合人阅读,但不适合程序处理。比如我们想单独取出姓名、年龄、职业、兴趣,就需要再写一堆解析逻辑,而且很容易出错。
结构化输出就是让模型按照指定结构返回结果,例如:
json
{
"name": "张三",
"age": 20,
"job": "学生",
"hobbies": ["篮球", "编程"]
}这样程序就可以直接通过字段名读取数据。
在 LangChain 中,结构化输出通常可以用三种方式定义:
- Pydantic
- TypedDict
- JSON Schema
Pydantic
Pydantic 是 Python 中常用的数据建模和数据校验库。它不是 Python 语法,也不是关键字,而是一个第三方库。
在 LangChain 里,我们可以用 Pydantic 定义模型希望返回的结构。
python
from typing import Optional
import os
from langchain_openai import ChatOpenAI
from pydantic import BaseModel, Field
model = ChatOpenAI(
model="gpt-5.5",
api_key=os.getenv("CHAT_API_KEY"),
base_url=os.getenv("CHAT_BASE_URL"),
)
class Joke(BaseModel):
"""给用户讲一个笑话。"""
setup: str = Field(description="笑话的开头")
punchline: str = Field(description="笑话的妙语")
rating: Optional[int] = Field(default=None, description="1 到 10 分,给这个笑话评分")
structured_model = model.with_structured_output(Joke)
result = structured_model.invoke("讲一个笑话")
print(result)
print(result.setup)
print(result.punchline)
print(result.rating)可能输出:
text
setup='为什么数学书总是看起来很忧郁?' punchline='因为它有太多问题了。' rating=7这里要注意:
python
structured_model = model.with_structured_output(Joke)这一步返回的不是普通模型,而是一个新的 Runnable。后续调用:
python
structured_model.invoke("讲一个笑话")返回的也不是普通的 AIMessage,而是已经解析好的 Joke 对象。所以这里不能再写:
python
result.content因为 result 已经是 Pydantic 对象,不是聊天消息对象。
Pydantic、BaseModel、Field 分别是什么?
很多人刚开始会把 Pydantic、BaseModel、Field、类型注解混在一起。可以这样区分:
| 写法 | 本质 | 作用 |
|---|---|---|
Pydantic |
Python 第三方库 | 用来做数据建模和校验 |
BaseModel |
Pydantic 提供的基类 | 继承它来定义数据模型 |
Field() |
Pydantic 提供的函数 | 给字段增加默认值、描述、约束等信息 |
setup: str |
Python 类型注解 | 表示 setup 应该是字符串 |
Optional[int] |
Python 类型注解 | 表示可以是 int,也可以是 None |
class Joke(BaseModel) |
Python 类继承语法 | 表示 Joke 是一个 Pydantic 模型 |
简单说:
python
class Joke(BaseModel):
setup: str这不是"Pydantic 语法",而是普通 Python 类语法 + 类型注解。Pydantic 通过继承 BaseModel 接管了字段解析和校验能力。
TypedDict
除了 Pydantic,也可以用 TypedDict 定义结构化输出。
TypedDict 是 Python 类型系统里的一个工具,用来描述"这个字典应该有哪些 key,以及每个 key 的类型"。它更像是给字典加类型说明。
python
from typing import Annotated, Optional, TypedDict
import os
from langchain_openai import ChatOpenAI
model = ChatOpenAI(
model="gpt-5.5",
api_key=os.getenv("CHAT_API_KEY"),
base_url=os.getenv("CHAT_BASE_URL"),
)
class Joke(TypedDict):
"""给用户讲一个笑话。"""
setup: Annotated[str, ..., "笑话的开头"]
punchline: Annotated[str, ..., "笑话的妙语"]
rating: Annotated[Optional[int], ..., "1 到 10 分,给这个笑话评分"]
structured_model = model.with_structured_output(Joke)
result = structured_model.invoke("讲一个笑话")
print(result)
print(result["setup"])使用 TypedDict 时,返回结果通常是字典,而不是 Pydantic 对象。
也就是说:
python
result["setup"]而不是:
python
result.setup 这里还要注意一个细节:TypedDict 本身主要服务于类型检查器、IDE 和静态分析工具。普通 Python 运行时不会因为你把某个字段写错就自动报错。
也就是说,下面这类普通字典在 Python 运行时不会因为类型注解自动报错:
python
joke = {"setup": 123} 但在 LangChain 结构化输出里,TypedDict 会被用来生成输出 schema,让模型尽量按照这个结构返回数据。
include_raw=True 的作用
&emps; 默认情况下,结构化输出只返回解析后的结果。如果我们想同时查看模型原始返回、解析结果和解析错误,可以使用 include_raw=True。
python
structured_model = model.with_structured_output(Joke, include_raw=True)
result = structured_model.invoke("讲一个笑话")
print(result["raw"])
print(result["parsed"])
print(result["parsing_error"])返回结果通常包含三个字段:
python
{
"raw": ..., # 模型原始返回的 AIMessage
"parsed": ..., # 解析后的结果
"parsing_error": None, # 解析失败时的异常信息
}这在调试时非常有用。
例如,当你发现结构化输出失败时,可以先看 raw,确认模型到底返回了什么;再看 parsing_error,确认是 JSON 格式问题、字段缺失问题,还是类型不匹配问题。
JSON Schema
如果不想使用 Pydantic 或 TypedDict,也可以直接使用 JSON Schema。
JSON Schema 是一种用来描述 JSON 数据结构的规范。它本身也是一个 JSON 或 Python 字典。
定义一个json schema:
python
json_schema = {
"title": "joke",
"description": "给用户讲一个笑话。",
"type": "object",
"properties": {
"setup": {
"type": "string",
"description": "笑话的开头",
},
"punchline": {
"type": "string",
"description": "笑话的妙语",
},
"rating": {
"type": "integer",
"description": "从 1 到 10 分,给这个笑话评分",
},
},
"required": ["setup", "punchline"],
}
structured_model = model.with_structured_output(json_schema)
result = structured_model.invoke("讲一个笑话")
print(result)虽然我们用的是 JSON Schema 定义格式,但在 Python 里最终拿到的通常是字典:
python
{
"setup": "为什么程序员喜欢黑夜?",
"punchline": "因为白天 bug 太显眼了。",
"rating": 8,
}Pydantic、TypedDict、JSON Schema
可以按这个规则选择:
| 场景 | 推荐方式 |
|---|---|
| 需要字段校验、默认值、嵌套模型 | Pydantic |
| 只想轻量描述字典结构 | TypedDict |
| 要和接口协议、前端、OpenAPI 风格保持一致 | JSON Schema |
| 项目较大、希望代码更稳 | Pydantic |
| 临时脚本、简单字段提取 | TypedDict 或 JSON Schema |
如果是学习和真实项目,我更推荐先掌握 Pydantic。它表达能力更强,也更适合做复杂结构。
模型提供结构化能力,LangChain 提供结构化能力,到底有什么区别?
大模型厂商提供的是底层能力。比如某些模型 API 支持 JSON 模式、函数调用、工具调用、原生结构化输出等。
LangChain 提供的是统一封装。你不用每次都关心底层模型到底是通过 JSON 模式实现,还是通过 tool calling 实现。你只需要写:
python
model.with_structured_output(Joke)LangChain 会根据模型能力和你传入的 schema,帮你组织请求、约束输出、解析结果。
所以更准确地说:
- 模型提供生成结构化内容的底层能力。
- LangChain 提供统一的 Python 接口和解析封装。
- Pydantic、TypedDict、JSON Schema 提供结构定义。
这三层不要混在一起。
多种结构化返回
如果我们把模型固定成"讲笑话"的结构,然后用户问了一个普通问题,输出就可能很奇怪。
例如:
python
structured_model = model.with_structured_output(Joke)
structured_model.invoke("你是什么模型?")模型仍然会被迫返回 setup、punchline、rating 这些字段,这明显不合理。
这时可以定义多个输出结构,让模型根据问题选择合适的结构。
python
from typing import Optional, Union
from pydantic import BaseModel, Fiel
class Joke(BaseModel):
"""给用户讲一个笑话。"""
setup: str = Field(description="笑话的开头")
punchline: str = Field(description="笑话的妙语")
rating: Optional[int] = Field(default=None, description="1 到 10 分,给这个笑话评分")
class ChatResponse(BaseModel):
"""普通对话回复。"""
content: str = Field(description="对用户问题的自然语言回复")
class FinalResponse(BaseModel):
"""根据用户问题选择合适的输出结构。"""
final_output: Union[Joke, ChatResponse]
structured_model = model.with_structured_output(FinalResponse)
print(structured_model.invoke("讲一个关于唱歌的笑话"))
print(structured_model.invoke("你是什么模型?"))不过实战项目里,如果结构比较多,最好额外加一个类型字段,例如:
python
response_type: Literal["joke", "chat"]这样程序后续判断会更清楚。
结构化输出的实用场景
结构化输出最适合以下场景:
-
信息抽取:从一段文本里提取姓名、手机号、邮箱、公司、职位等字段。
-
分类任务
让模型返回固定类别,
例如:
text
positive / negative / neutral-
意图识别:判断用户是要查询订单、修改资料、投诉、退款,还是咨询商品。
-
工具调用前的参数整理
例如用户说:
text
帮我查一下明天下午三点北京到上海的高铁票模型可以结构化成:
json
{
"from": "北京",
"to": "上海",
"date": "明天",
"time": "15:00"
}然后程序再调用真正的查询接口。
- 少样本提示结果固定化:少样本提示可以让模型学会风格,结构化输出可以让模型稳定返回字段。两者结合,适合做可控的数据生成。
流式传输
什么是流式输出?
前面使用的 invoke() 都是非流式输出。
非流式输出的特点是:模型必须先生成完整结果,然后一次性返回。
python
result = model.invoke("写一篇关于夏天的作文,800 字左右")
print(result.content)如果内容很长,用户就要一直等。
流式输出则是边生成边返回。模型生成一点,客户端就接收一点,用户可以更快看到内容。
同步流式输出
python
from langchain_openai import ChatOpenAI
model = ChatOpenAI(model="gpt-5.5")
prompt = "写一篇关于夏天的作文,800 字左右"
for chunk in model.stream(prompt):
print(chunk.content, end="", flush=True)这里的 chunk 通常是 AIMessageChunk。
它不是完整的 AIMessage,而是消息片段。多个 chunk 可以逐步拼接成完整回复。
python
full_text = ""
for chunk in model.stream(prompt):
full_text += chunk.content
print(full_text)异步流式输出
如果项目本身使用异步框架,比如 FastAPI、异步爬虫、异步数据库连接,就可以使用 astream()。
python
import asyncio
from langchain_openai import ChatOpenAI
model = ChatOpenAI(model="gpt-5.5")
prompt = "写一首关于夏天的诗"
async def main():
async for chunk in model.astream(prompt):
print(chunk.content, end="", flush=True)
asyncio.run(main())它的核心思想是:当一个任务在等待网络、磁盘、数据库、模型返回时,不要让 CPU 干等,而是把执行权让出来,先处理其他任务。
比如:
python
await asyncio.sleep(5)这不是让线程傻等 5 秒,而是告诉事件循环:这个协程先暂停,5 秒后再继续,中间可以去执行其他协程。
invoke、stream、ainvoke、astream 的区别
| 方法 | 是否异步 | 是否流式 | 返回方式 |
|---|---|---|---|
invoke() |
否 | 否 | 一次性返回完整结果 |
stream() |
否 | 是 | 逐块返回结果 |
ainvoke() |
是 | 否 | 异步一次性返回完整结果 |
astream() |
是 | 是 | 异步逐块返回结果 |
简单记忆:
- 带
a:async,异步。 - 带
stream:流式。 ainvoke:异步,但不流式。astream:异步,并且流式。
自定义生成器:按句子输出
有时候我们不想一个 token 一个 token 输出,而是希望攒成一句话再输出。
可以自定义一个生成器:
python
from collections.abc import Iterator
from langchain_core.output_parsers import StrOutputParser
from langchain_openai import ChatOpenAI
model = ChatOpenAI(model="gpt-5.5")
parser = StrOutputParser()
def split_by_sentence(input_stream: Iterator[str]) -> Iterator[str]:
buffer = ""
for chunk in input_stream:
buffer += chunk
while "。" in buffer:
stop_index = buffer.index("。")
sentence = buffer[: stop_index + 1].strip()
buffer = buffer[stop_index + 1 :]
if sentence:
yield sentence
if buffer.strip():
yield buffer.strip()
chain = model | parser | split_by_sentence
for sentence in chain.stream("写一首关于夏天的诗"):
print(sentence)这里的关键点是 yield。
普通函数是一次性 return 结果;生成器函数可以多次 yield,每次产出一部分结果,并保留当前执行状态,下一次继续往下执行。
流式传输的底层原理
从客户端角度看,流式输出就是:客户端发出请求后,服务端不等完整结果生成完,而是生成一点就返回一点。
常见实现方式有两类:
- WebSocket
- SSE
WebSocket 是全双工通信。客户端和服务端可以在同一条长连接里互相发送消息。它适合实时聊天、游戏、协同编辑等强交互场景。
SSE,全称 Server-Sent Events,是基于 HTTP 的服务端推送技术。它主要是单向的:服务端持续向客户端发送消息。
大模型流式输出通常更适合 SSE,因为这个场景大多数时候是:
text
客户端发送 prompt -> 服务端持续返回 token客户端不需要在同一条连接里频繁反向推送消息,所以 SSE 已经够用。
SSE 响应一般会使用类似这样的响应头:
http
Content-Type: text/event-stream
Cache-Control: no-cache
Connection: keep-alive服务端发送的数据通常长这样:
text
data: {"content": "你"}
data: {"content": "好"}
data: [DONE] 不过在使用 LangChain 时,我们一般不用自己手写 SSE 解析逻辑。LangChain 的 stream() / astream() 会封装底层模型 API 的流式返回,然后把它转换成 Python 里可以迭代的 chunk。
所以这里也要分清楚三层:
- 模型服务商:提供 HTTP/SSE 等底层流式接口。
- LangChain:封装底层接口,提供
stream()/astream()。 - 你的程序:遍历 chunk,把内容打印到终端、网页或接口响应里。
总结
结构化输出解决的是"结果能不能被程序稳定读取"的问题。
流式传输解决的是"用户能不能更快看到结果"的问题。
它们分别对应两个方向:
| 能力 | 解决的问题 | 常用方法 |
|---|---|---|
| 结构化输出 | 输出格式不稳定,程序不好解析 | with_structured_output() |
| 流式传输 | 长文本等待时间长,体验差 | stream() / astream() |
学习 LangChain 时,不要只记 API 名字,而要理解它背后的分层:
结构化输出这一块:
text
Pydantic / TypedDict / JSON Schema 定义结构
LangChain 把结构传给模型并解析返回结果
模型按照结构生成内容流式传输这一块:
text
模型服务商提供底层流式接口
LangChain 封装为 stream / astream
应用层逐块消费并展示把这两块搞清楚后,就可以继续往工具调用、Agent、RAG、异步 Web 服务集成这些方向深入。
非常感谢您能耐心读完这篇文章。倘若您从中有所收获,还望多多支持呀!🎉