在生成式AI的发展轨迹中,大型语言模型(LLM)主要作为纯粹的文本或代码生成引擎。然而,传统LLM在应用中本质上是被动的无状态计算节点(Stateless Compute Nodes),缺乏跨越会话的记忆,且无法直接干预外部系统。为了跨越从"信息生成"到"自主行动"的鸿沟,AI智能体(AI Agents)架构应运而生。
从技术工程的角度定义,Agent是一种以大模型为核心控制器(Core Controller),通过整合状态管理(Memory/State)、逻辑推理与规划(Planning)、以及工具调用(Tools/Action),实现复杂目标驱动的分布式软件系统。简而言之,如果LLM是CPU的运算单元,那么Agent架构就是为这个运算单元外挂了总线、内存、硬盘和各种外部I/O接口,使其成为一台完整的"计算机"。
现代Agent的核心架构与组件拓扑
一个生产级的Agent架构必须将LLM的认知智能与持久化记忆系统、动态工具调用以及高级规划算法相融合。其核心通常包含以下模块:
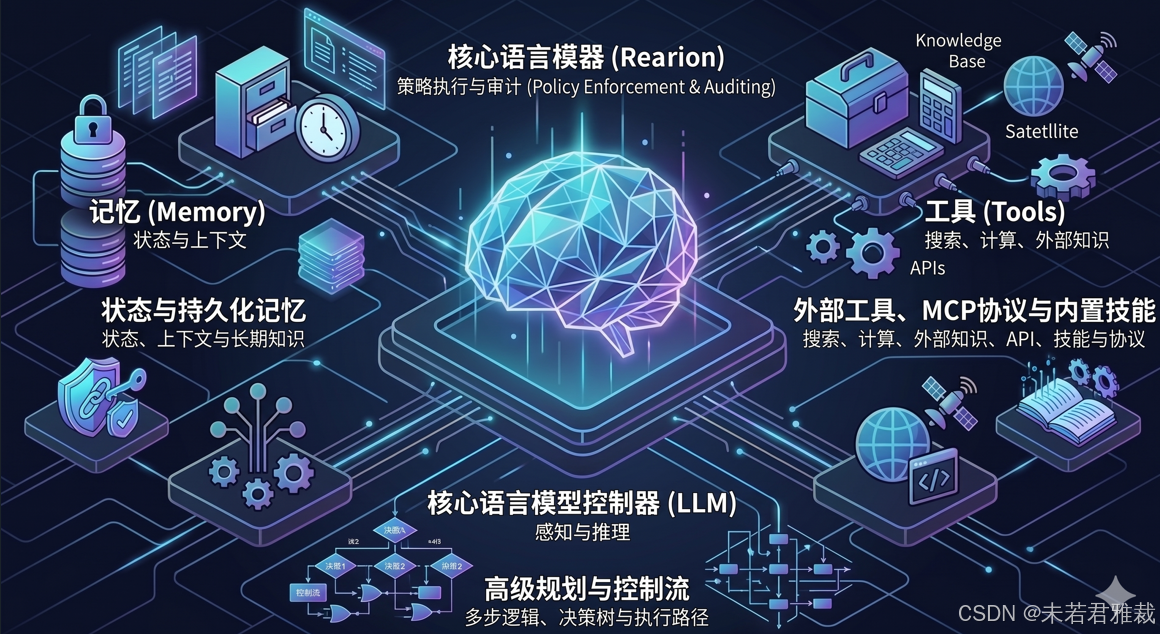
1. 状态与记忆管理 (State & Memory)
在Agent系统中,状态(State)指的是智能体维护的持久或瞬时数据,用于在长时间交互中保持上下文。
- 短期记忆与状态共享: 通常通过系统内存维护(如LangGraph中的
TypedDict或Pydantic实例)。在图网络架构中,每个节点的输出都会更新全局状态,从而实现多步骤推理中的数据流转。 - 长期记忆与向量检索: 依赖于外部向量数据库(Vector DBs)或图数据库,实现经验的持久化。
- 结构化笔记 (Structured Note-taking / Agentic Memory): 对于超出模型上下文窗口(Context Window)的长周期任务,直接堆砌对话历史会导致效率低下。一种典型的工程模式是让Agent定期将核心进度和依赖关系写入外部的
NOTES.md文件或专用的记忆载体中。这种脱离上下文窗口的持久化方式,能以极低的Token开销维持跨周期的任务连贯性。
2. 外部工具、协议栈与内置技能 (Tools, MCP & Skills)
LLM的权重是冻结的,工具调用(Function Calling)赋予了Agent与真实物理和数字世界交互的接口。当前,Agent的执行层正在经历从单一的"API"向"协议栈"加"认知技能"的全面升级:
- 传统API的局限: 传统API是为人类开发者设计的固定端点。对于Agent而言,面对一个包含上百个端点的企业API集合时,极易陷入"选择悖论(Paradox of Choice)"------模型难以在众多相似接口中做出正确选择,导致性能骤降、幻觉增加或陷入死循环。
- MCP协议的破局: MCP是一个开源的双向通信标准,专为AI应用设计。与传统API不同,MCP强调"能力协商(Capability Negotiation)"和动态发现机制。它将不同的数据源和工具(如本地文件、数据库、企业内部系统)标准化为Agent可以原生理解的格式,允许Agent根据上下文动态发掘和调用工具,大大降低了复杂系统集成的代码耦合度。
- Skill(技能)与 Tool(工具)的本质解耦: 在最前沿的架构设计中,Tool和Skill被严格区分。Tool(如MCP或外部API)解决的是"执行力(Do-this)"问题,它在模型外部运行,提供确定性的输入输出接口。而Skill解决的则是"专业认知与SOP(Know-how)"问题,它封装了特定领域的业务逻辑、多步推理流程和决策规则。简而言之,Tool提供了连接外部系统的渠道,而Skill则在内部指导Agent在面对特定任务时该如何思考,以及在何时应该调用哪些Tool。
- 渐进式加载(Progressive Disclosure)应对上下文溢出: 如果将企业所有的业务SOP(Skill)全部写入系统提示词中,会瞬间耗尽上下文窗口并导致模型注意力涣散。为此,现代Skill架构(如基于
SKILL.md的文件系统实现)采用了渐进式机制。在初始化阶段,系统仅向Agent加载极轻量的Skill元数据(Metadata,通常仅约100 Tokens),让Agent知道有哪些技能可用。只有当Agent根据当前任务触发特定Skill时,系统才会动态注入数千Tokens的详细执行规范和逻辑资源。这种设计使得Agent能够以极小的内存印记挂载海量的专业技能。
3. 高级规划与控制流 (Planning & Control Flow)
面对复杂任务,Agent必须具备将大目标拆解为子目标(Subgoal Decomposition)并动态修正的控制流。
- ReAct (Reasoning and Acting): 经典的"思考-行动-观察"交替循环。通过强制LLM生成"思维链(CoT)",降低模型幻觉概率并根据观察结果调整策略。缺点是状态冗长,容易在工具失效时陷入死循环。
- ReWOO (Reasoning Without Observation): 将"逻辑推理"与"外部观察"解耦。Planner节点前置生成完整执行蓝图,Worker节点并行调用工具收集数据,最后由Solver综合。这种模式可降低近80%的Token消耗,且在单节点失败时具有更强的鲁棒性。
- LATS (Language Agent Tree Search): 结合蒙特卡洛树搜索(MCTS)与LLM评估。Agent在多个可能的行动分支中进行并行探索和评分,遇到死胡同时可自主回溯,代表了极难任务下的推理极限。
生产级开发模式:多智能体编排与HITL
在工程实践中,开发者已从早期的线性链式调用(Chains)转向基于图(Graph)或状态机(State Machine)的复杂编排。
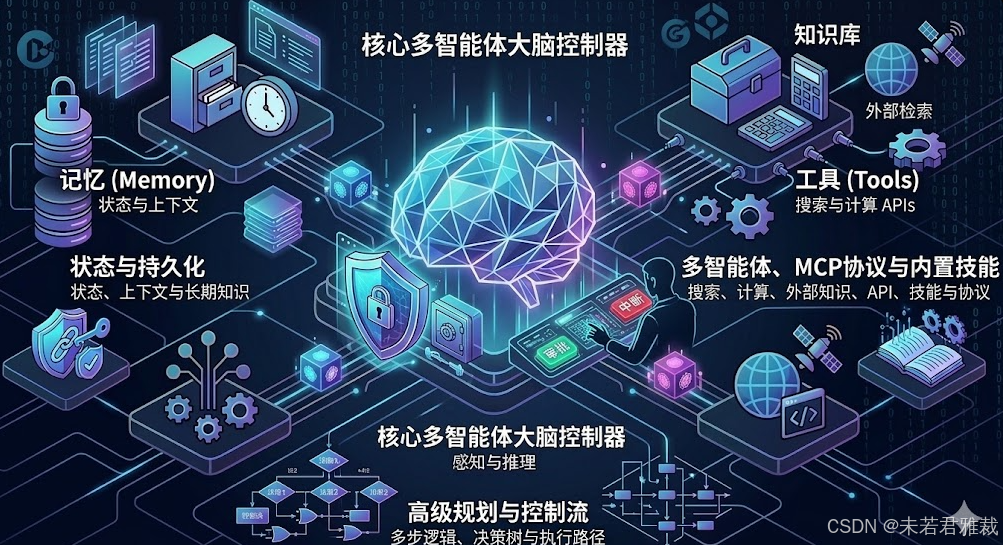
多智能体状态机编排
以LangGraph为代表的框架,通过定义节点(Nodes)处理模型调用、边(Edges)决定条件分支,构建出具有严格确定性的执行流。在复杂系统中,单智能体虽然架构简单,但在处理多个异构任务时容易顾此失彼;**多智能体(Multi-agent)**通过为不同节点分配具备特定系统提示词(System Prompts)和专属工具的专家Agent,在并行任务处理中能够显著提升成功率,但这同时也增加了状态同步的复杂性。
Human-in-the-loop (HITL) 与中断机制
在执行高风险操作(如数据库写入、支付接口调用、邮件发送)时,完全的自主性是不可接受的。生产级Agent必须实现HITL模式。
例如,LangGraph 提供了原生的 interrupt() 函数机制。当执行到关键节点时,Agent会触发中断,通过持久化层(Checkpointer)将当前的完整图状态保存下来,并无限期挂起执行。外部应用接收到中断Payload后,等待人类用户输入(如"批准"、"修改"或"拒绝"),随后系统通过传入带有特定 thread_id 的恢复指令(Command),唤醒Agent并继续后续执行轨迹。
底层演进:Reasoning Models 对架构的影响
2024年底至2025年,以DeepSeek-R1和OpenAI o1/o3系列为代表的新一代推理模型(Reasoning Models)的出现,正在重塑Agent的架构范式。
这些模型引入了"测试时计算扩展(Test-Time Compute Scaling)",在输出前通过内置的RL强化学习隐式或显式地生成复杂的"思维轨迹(Reasoning Traces)"。
架构重构: 在传统范式中,开发者需要编写复杂的外部Agent框架(如专门的Planner、Reviewer节点)来强制普通LLM进行反思。然而,当底层模型原生具备极强的自我纠错能力时,臃肿的外部提示链反而会干扰其内置逻辑。因此,现代Agent架构正向**混合编排(Hybrid Architectures)**收敛:让高延迟、深思熟虑的推理模型(如o1或R1)专门负责宏观工作流拆解与工具分配(Planner);而在叶子节点,部署极低延迟的普通模型(如GPT-4o、Claude 3.5 Haiku)作为一线执行者(Worker),以最优的系统延迟和成本实现闭环。
评估与测试:如何衡量Agent的性能?
与传统的LLM仅需评估静态的输入输出(如MMLU基准)不同,Agent系统与动态环境交互,具有极高的非确定性。现代Agent评估体系通常采用以下思路:
- 指标拆分(Trajectory vs. Outcome):
评估Agent不仅要看最终的"结果指标(Outcome metrics)"(是否成功删除了记录),更要严格审查"轨迹指标(Trajectory metrics)"------即评估Agent的推理过程是否合理、工具调用顺序是否优化、以及面对错误时是否进行了有效的自我纠错。 - 核心测试基准 (Benchmarks):
- SWE-bench: 专门用于评估软件工程Agent(如代码编写与修复)的能力。它要求Agent在沙盒中独立阅读整个代码库、定位issue并提交PR,是目前开发者最关注的硬核基准之一。
- GAIA: 区别于传统的数学或常识问答,GAIA提出的是"概念简单但需要多步工具协作解决的实际问题"。它极好地测试了Agent在复杂环境中的泛化规划能力。
- AgentBench: 这是一个多维度的评估框架,涵盖了操作系统操作、数据库查询、知识图谱及网页浏览等8个不同的任务环境,旨在全方位评估系统在不同API边界下的适应性。
总结与市面常见AI智能体盘点
AI智能体正在将大型语言模型从单纯的"信息生成器"升级为能够自主规划、调用工具、管理状态并自我纠错的"数字执行者"。随着MCP协议打破系统孤岛,以及底层推理模型大幅提升了逻辑规划能力,开发者得以真正将繁复的软件工程和业务流水线交由AI去闭环完成。
在当前的开发生态中,命令行界面(CLI)和集成开发环境(IDE)成为了AI智能体落地的最前沿阵地。以下是目前技术人员最常使用的几款标杆级Agent工具:
- Claude Code: 由Anthropic推出的终端原生(Terminal-native)编程智能体。它直接在开发者的命令行环境中运行,能够在执行编辑前进行深度推理规划(Plan mode)。Claude Code极大地依赖其特有的Agent Skills架构和MCP协议,允许开发者挂载从代码审查、UI设计到Slack集成的各种定制化能力。它擅长并行处理多文件重构,被视为目前生产力极强的代码级自主Agent。
- Gemini CLI: Google推出的开源终端AI智能体,专为习惯命令行的开发者设计。它原生接入了拥有100万级超大上下文窗口的Gemini 3模型,并内置了Google搜索增强(Grounding)、文件操作和Shell命令执行能力。Gemini CLI也是Google Cloud开发平台的核心编排骨干,通过统一的指令即可将复杂的云端资源与MCP工具无缝连接,非常适合多模型协同工作流。
- OpenAI Codex (CLI Agent): 作为大模型编程领域的先驱,Codex在演进中也推出了强大的CLI Agent形态(如
@openai/codex)。现代Codex不仅在代码补全上表现卓越,更在智能体形态下集成了执行沙盒和MCP架构。它突破了封闭代码库的限制,能够根据实时的企业结构化数据进行逻辑推理和UI构建,甚至可以将安全威胁建模等前置流程固化为其执行环境的底层基础设施。 - 其他典型代表: 除了上述纯CLI形态的智能体,市面上还包括深度集成GUI且支持多文件Agent模式的AI编辑器(如 Cursor )、专注于Git工作流的开源终端结对编程工具(如 Aider ),以及能够在隔离沙盒中完全自主阅读代码库、定位Issue并提交PR的全自动软件工程师系统(如 OpenHands)。