1.存储相关概念
1.概述
在现代计算机系统和网络中,数据存储是至关重要的。随着数据量的爆炸式增长,如何高效、可靠地存储和管理数据成为了一个重要的挑战。文件存储、块存储和对象存储是三种主要的数据存储方式,它们各自具有独特的特性和适用场景。本文将详细探讨这三种存储方式的定义、架构、原理和应用场景,帮助读者更好地理解和选择合适的数据存储解决方案。
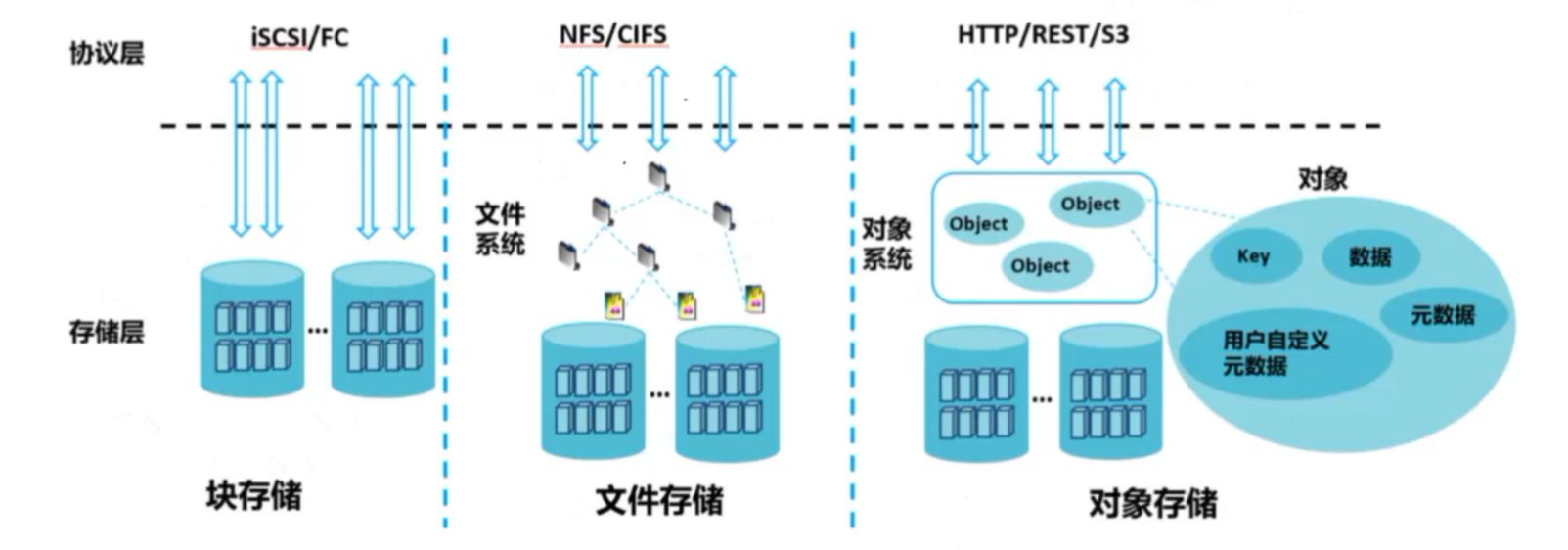
2.块存储
1.定义
块存储(Block storage)是一种将数据分割成固定大小的块进行存储的方法。每个块都有一个唯一的地址,应用程序通过块地址来读取和写入数据,而不关心文件系统的具体实现。这种存储方式类似于我们日常使用的图书馆,每本书可以被分割成多个章节,每个章节都有一个唯一的编号。
典型设备:磁盘整列、硬盘
2.原理
块存储的基本原理是将数据分割成多个固定大小的块,并为每个块分配一个唯一的地址。操作系统通过块设备驱动程序直接访问这些块从而实现对数据的读写操作。
块存储系统通常不关心数据的具体内容和结构,只提供简单的读写接口。应用程序或文件系统负责管理数据的逻辑结构,如文件的组织和目录结构。
块存储的一个重要特点是支持随机访问,即可以快速定位并读取任意块的数据。这使得块存储非常适合需要高性能和低延迟的数据访问场景
3.应用场景
数据库存储 :数据库系统通常需要高性能的随机访问,块存储能够满足这一需求,提供快速的数据读写能力。
虚拟机存储:虚拟机镜像文件需要高效的存储和管理,块存储提供了灵活和高效的解决方案,支持虚拟机的快速启动和迁移。高性能计算 :高性能计算(HPC)需要快速读写大规模数据集,块存储可以提供高吞吐量和低延迟的数据访问,支持科学计算、数据分析等应用。
容灾和备份:块存储支持数据的快速复制和备份,提高系统的容灾能力,确保数据的安全性和可靠性。
3.对象存储
1.定义
对象存储(Object storage)是一种将数据作为对象进行存储的方法。每个对象包含数据、元数据和一个唯一的标识符,用户通过标识符访问对象,而不需要关心对象的物理存储位置。这种存储方式类似于我们日常使用的邮政系统,每个邮件包裏都有一个唯一的追踪号,可以通过追踪号查找包裹的状态和位置
2.原理
对象存储的基本原理是将数据作为独立的对象进行存储,每个对象包含数据本身、元数据和唯一标识符。对象存储系统通过分布式存储节点来存储和管理这些对象,并提供统一的接口供用户访问。
对象存储系统通常采用水平扩展的架构,可以通过增加存储节点来扩展存储容量和性能。对象存储系统还支持数据的冗余和分布,以提高数据的可靠性和可用性
对象存储系统通过元数据来管理对象的属性和访问权限,支持快速检索和复杂查询。对象存储系统还支持大规模并发访问,适合处理海量数据和高访问负载的应用场景。
3.应用场景
云存储服务:云存储服务提供大规模、高可用的存储空间,支持数据的冗余和分布,如亚马逊S3、阿里云OSS等
媒体存储和分发:对象存储适合存储和分发图片、视频、音频等多媒体内容,支持大规模并发访问和快速检索。
备份和归档:对象存储系统可以用于备份和归档数据,提供高效的数据保护和恢复,支持海量数据的存储和管理
大数据和分析:对象存储适合存储和管理大规模的数据集,支持大数据分析和处理,如日志分析、数据挖掘等。
4.文件存储
1.定义
文件存储(File storage)是一种将数据以文件的形式存储在存储介质上的方法。每个文件都有一个文件名,并存储在一个目录结构中用户可以通过文件路径来访问和管理文件。这种存储方式类似于我们日常使用的文件柜,每个文件柜有多个文件夹,文件夹中有多个文件。
2.原理
文件存储的基本原理是将数据分割成文件,并通过文件系统进行管理。文件系统提供了一个抽象层,使用户可以通过简单的路径和文件名来访问数据,而不需要关心数据在物理存储介质上的具体位置。
文件系统通常采用树状目录结构来组织文件,根目录下可以有多个子目录,每个子目录下可以包含多个文件或其他子目录。文件系统通过索引和目录结构来快速定位文件,提高数据访问的效率。
文件存储系统支持多种操作,包括文件的创建、删除、读取、写入、复制、移动等。文件系统负责管理文件的存储空间分配和回收,保证数据的一致性和完整性。
3.应用场景
**个人计算机:**用户可以在个人计算机上存储文档、图片、音乐、视频等文件,通过文件系统进行管理和访问。
**企业文件服务器:**企业内部可以使用文件服务器进行文件共享和协作,支持多用户访问和权限管理,提高工作效率。
**网络文件共享:**通过网络文件系统协议(如NFS、SMB等),用户可以在不同设备之间共享文件,实现跨平台的数据访问。
**备份和归档:**文件存储系统可以用于备份和归档数据,提供数据的余和保护,确保数据的安全性和可靠性。
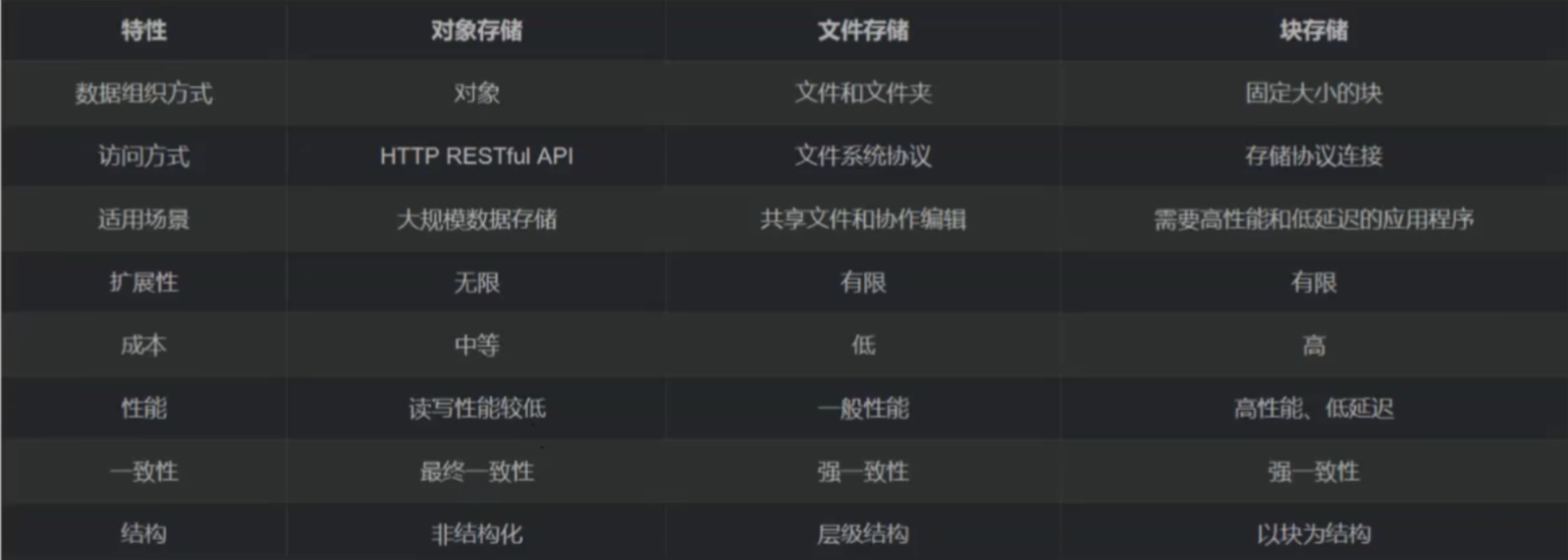
5.不同存储的区别
2.ceph概述
1.概述
Ceph是一个统一的分布式存储系统,最早起源于Sage就读博士期间的工作(最早的成果于2004年发表),随后贡献给开源社区。其设计初衷是提供较好的性能、可靠性和可扩展性。在经过多年的发展之后,目前已得到众多云计算厂商的支持并被广泛应用。RedHat及Openstack都可与ceph整合以支持虚拟机镜像的后端存储。
Ceph是一个能提供文件存储、块存储和对象存储的分布式存储系统。它提供了一个可无限伸缩的ceph存储集群。
高性能:
摒弃了传统的集中式存储元数据寻址的方案,采用CRUSH算法,数据分布均衡,并行度。
考虑了容灾域的隔离,能够实现各类负载的副本放置规则,例如跨机房、机架感知等
能够支持上千个存储节点的规模。支持TB到PB级的数据
高可用:副本数可以灵活控制
支持故障域分隔,数据强一致性
多种故障场景自动进行修复自愈
没有单点故障,自动管理
高扩展性去中心化
扩展灵活
随着节点增加,性能线性增长
2.ceph架构
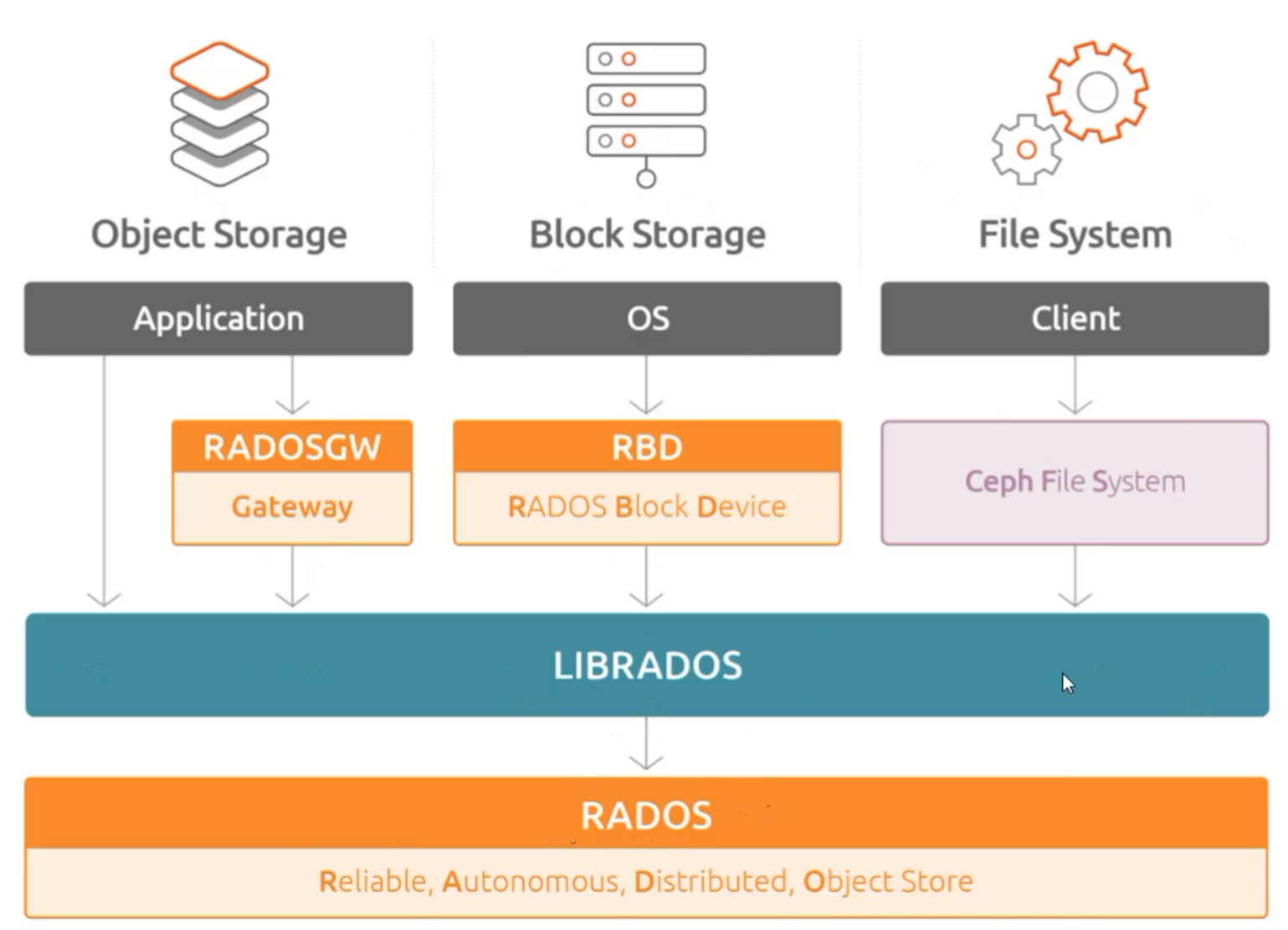
1. 最底层:RADOS(Ceph 的心脏)
全称是 Reliable, Autonomous, Distributed, Object Store,翻译为「可靠、自治、分布式对象存储引擎」。
- 核心作用:把集群里无数台服务器的硬盘,整合成一个无限扩容、数据多副本、自动容错、自动数据均衡的统一存储池,Ceph 里所有数据最终都以「对象」的形式存放在这里。
- 通俗理解:这就是 Ceph 的超级大仓库,所有货物(数据)最终都存在这里,仓库自己管货物的备份、摆放、损坏补货,不用上层操心。
2. 中间层:LIBRADOS(Ceph 的统一 API 桥梁)
这是 RADOS 的原生访问库,是上层服务和底层 RADOS 集群之间的唯一官方桥梁。
- 核心作用:把 RADOS 底层复杂的分布式逻辑,封装成支持多语言(C/C++、Python、Java 等)的库函数 / API。上层的 RBD、RADOSGW、CephFS,全部都是基于 LIBRADOS 来调用底层能力,不用自己处理分布式集群的复杂逻辑。
- 通俗理解:这是仓库的统一管理处,所有要进仓库存取货物的请求,都必须通过这里对接,不用自己去仓库里找货、搬货。
3. 上层:3 种对外存储服务(Ceph 的三大业务入口)
这就是图里的三个竖列,对应 Ceph 支持的 3 种主流存储形态,也是业务方真正会直接使用的能力,也就是上述的三个存储
3.ceph核心组件
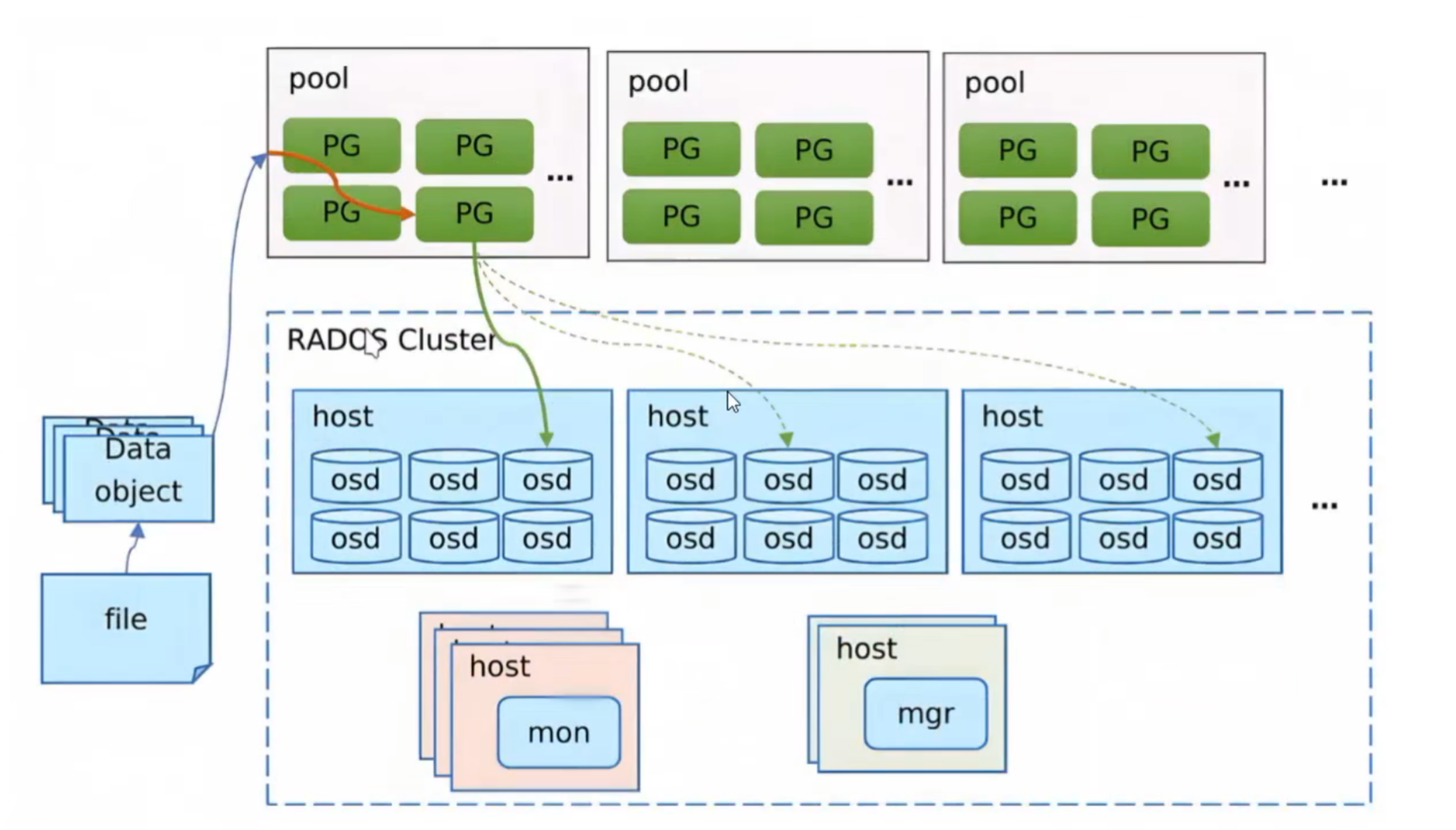
**RADOS:**RADOS全称Reliable Autǎnomic Distributed Object store,是Ceph集群的精华,用户实现数据分配、Failover等集群操作
Monitor: 一个ceph集群需要多个Moniter组成的小集群,它们通过paxos同步数据,用来保存OSD的元数据(mon及mgr组成的Monitor:monitor)
**OSD:**OSD全称Object storage Device,也就是负责响应客户端请求返回具体数据的进程。一个Ceph集群一般都有很多个OSDpool: 资源池,管理了PG
**PG:**PG全称Placement Grougps,是一个逻辑的概念,一个PG包含多个OSD。引入PG这一层其实是为了更好的分配数据和定位数据**Object:**Ceph最底层的存储单元是Obiect对象,每个Object包含元数据和原始数据
3.ceph集群部署
1.集群概述
Ceph集群包括Ceph OSD、Ceph Monitor 两种守护进程:
Ceph OSD (Obiect storage Device):功能是存储数据,处理数据的复制、恢复、回填、再均衡,并通过检査其他OSD守护进程的心跳来向Ceph Monitor提供一些监控信息
Ceph Monitor:是一个监视器,监视ceph集群状态和维护集群中的各种关系
2.环境说明初始化
准备四台主机

同样的每台主机先配置防火墙设置主机名,配置yum源
echo 192.168.22.137 node1 >> /etc/hosts
echo 192.168.22.147 node2 >> /etc/hosts
echo 192.168.22.148 node3 >> /etc/hosts
echo 192.168.22.149 client >> /etc/hosts安装必要组件
yum install vim -y
yum install net-tools -y
yum install wget -y
yum install yum-utils -y
yum install ntp -y
# 设置时间同步
systemctl enable ntpd --now
reboot3.配置免密登录
以node1为部署配置节点,在node1上配置ssh等效性(要求ssh node1、node2、node3、client都要免密码)说明:此步骤不是必要的,做此步骤的目的:
如果使用ceph-deploy来安装集群,密钥会方便安装
如果不使用ceph-deploy安装,也可以方便后面操作:比如同步配置文件在node1上进行以下操作:
# 这里是默认将.ssh下的id_rsa.pub传入各服务器的,如果名字写错需要指定路径
ssh-keygen -P '' -f /root/.ssh/id_rsa
ssh-copy-id -i root@node2
ssh-copy-id -i root@node3
ssh-copy-id -i root@client2.在node1上安装部署工具ceph-deploy
yum install createrepo -y
cd /root/ceph_soft
createrepo
yum -y install ceph-deploy3.在node1上部署集群
#创建一个集群配置目录,后续的大部分操作都会在此目录
mkdir /etc/ceph && cd /etc/ceph
# 创建集群
ceph-deploy new node1
ls
##############################################
ceph.conf ceph-deploy-ceph.log ceph.mon.keyring
#说明:
# ceph.conf 集群配置文件
# ceph-deploy-ceph.log 使用ceph-deploy部署的日志记录
# ceph.mon.keyring mon的验证key文件
# 若执行ceph-deploy命令报错,需要安装一个模块
yum install python-setuptools4.ceph集群节点安装ceph(node1,node2,node3)
前面准备环境安装好了yum源,这里所有集群节点(不包括client)都安装一下软件
yum -y install ceph ceph-radosgw
ceph -v
5.客户端安装ceph-common
yum -y install ceph-common6.创建监控
# 在node1上增加public网络用于监控,在[global]配置段里添加下面一句(直接放到最后一行)
vim /etc/ceph/ceph.conf
public network = 192.168.22.0/24
# 监控节点初始化,并同步配置到所有节点(node1、node2、node3、不包括client)
ceph-deploy mon create-initial
ceph health
########################################
HEALTH_OK # 状态health(健康)
# 将配置文件信息同步到所有节点
ceph-deploy admin node2 node3
ceph -s这里这个有个安全漏洞需要关闭一个不安全配置,最好是换个ceph版本
# 永久关闭不安全的global_id回收机制
ceph config set mon auth_allow_insecure_global_id_reclaim false
最后配置完成后
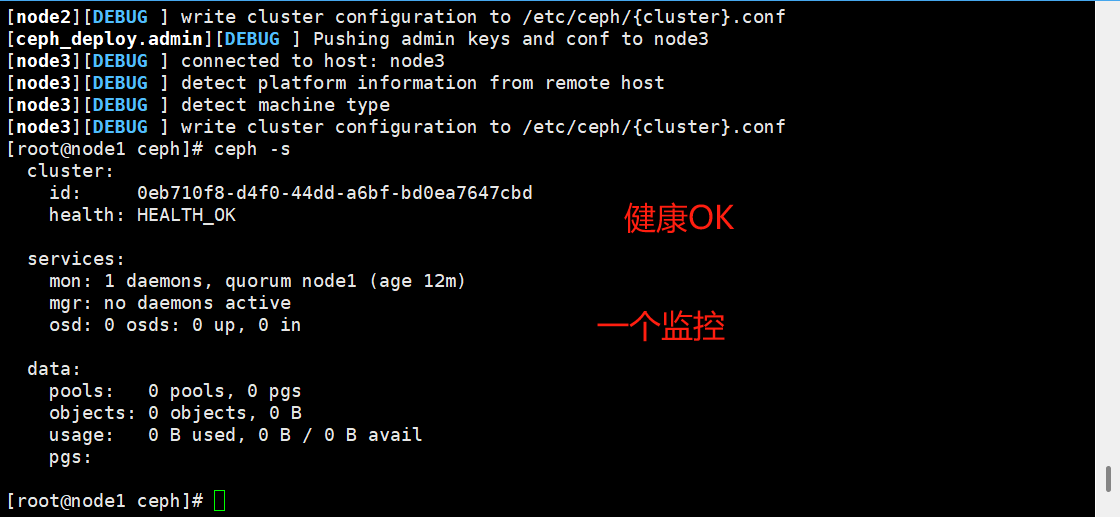
防止单点故障添加多个节点
ceph-deploy mon add node2
ceph-deploy mon add node3
ceph -s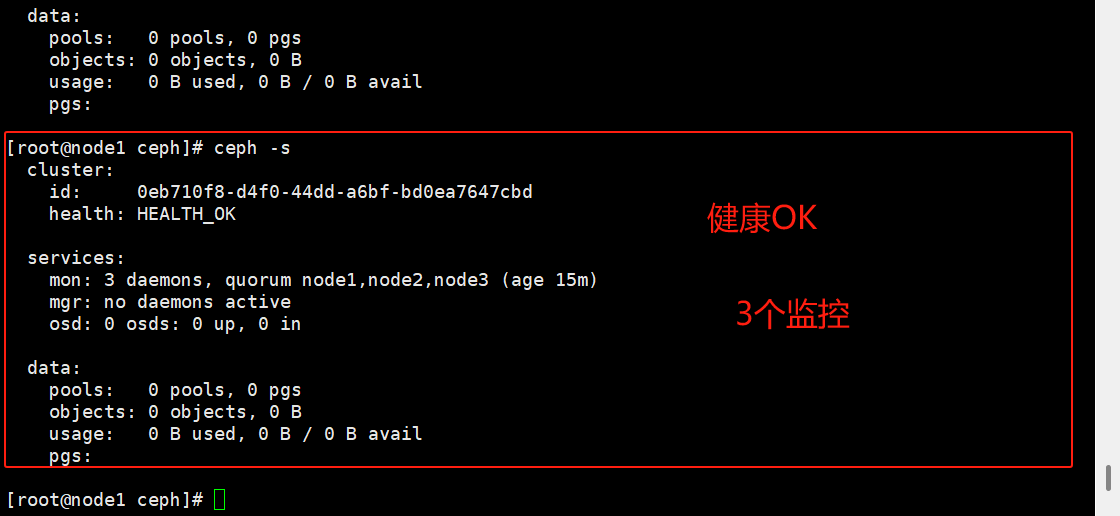
监控最好为单数,如果出现问题
# 报错 ceph -s
HEALTH_WARN clock skew detected on mon.node2, mon.node3或者修改时间同步服务将ntpd修改为chrony
调宽 Ceph 的容忍度
如果你确认只是测试环境,且 NTP 怎么搞都无法维持在 0.05 秒以内,你可以修改 Ceph 的配置,让它"宽容"一点。(生产环境禁用)
# 编辑ceph.conf
[global]
# 在 global 下面添加这一行,把容忍度放大到 2 秒(默认是 0.05)
mon_clock_drift_allowed = 2
# 把修改后的配置文件推送到所有节点
ceph-deploy --overwrite-conf config push node1 node2 node3
# 在所有节点上重启 Monitor 服务让配置生效
systemctl restart ceph-mon.target7.创建mgr(管理)
ceph luminous版本中新增加了一个组件:Ceph Manager Daemon,简称ceph-mgr。
该组件的主要作用是分担和扩展monitor的部分功能,减轻monitor的负担,让更好地管理ceph存储系统
# 在node1创建一个mgr
ceph-deploy mgr create node1
ceph -s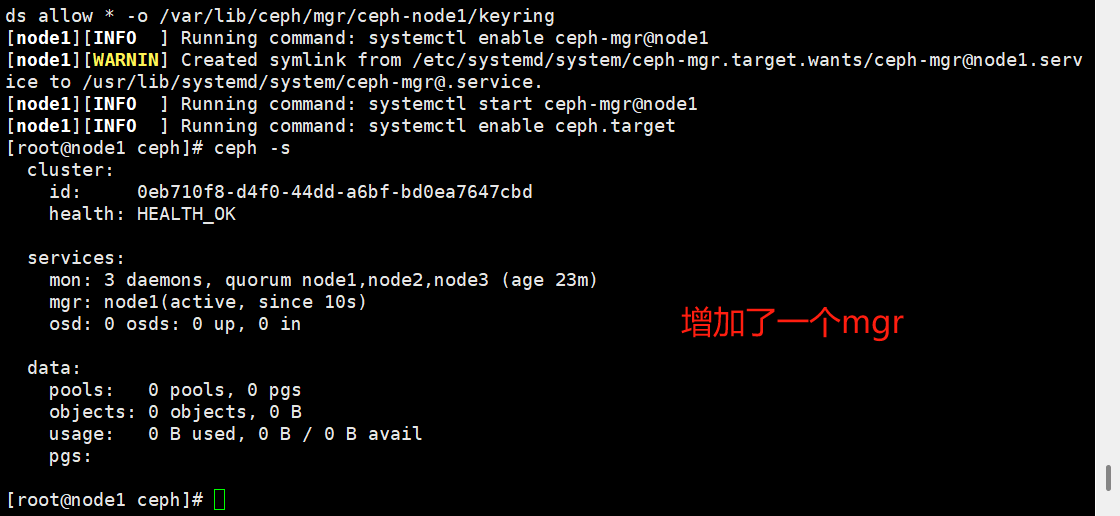
同样也能创建多个管理节点
ceph-deploy mgr create node2 node38.创建osd存储盘
列表所有节点的磁盘,都有sda和sdb两个盘,sdb为我们要加入分布式存储的盘
#列表查看节点上的磁盘
ceph-deploy disk list node1
ceph-deploy disk list node2
ceph-deploy disk list node3
# zap表示干掉磁盘上的数据,相当于格式化
ceph-deploy disk zap node1 /dev/sdb
ceph-deploy disk zap node2 /dev/sdb
ceph-deploy disk zap node3 /dev/sdb
# 将磁盘创建为osd
ceph-deploy osd create --data /dev/sdb node1
ceph-deploy osd create --data /dev/sdb node2
ceph-deploy osd create --data /dev/sdb node3
ceph -s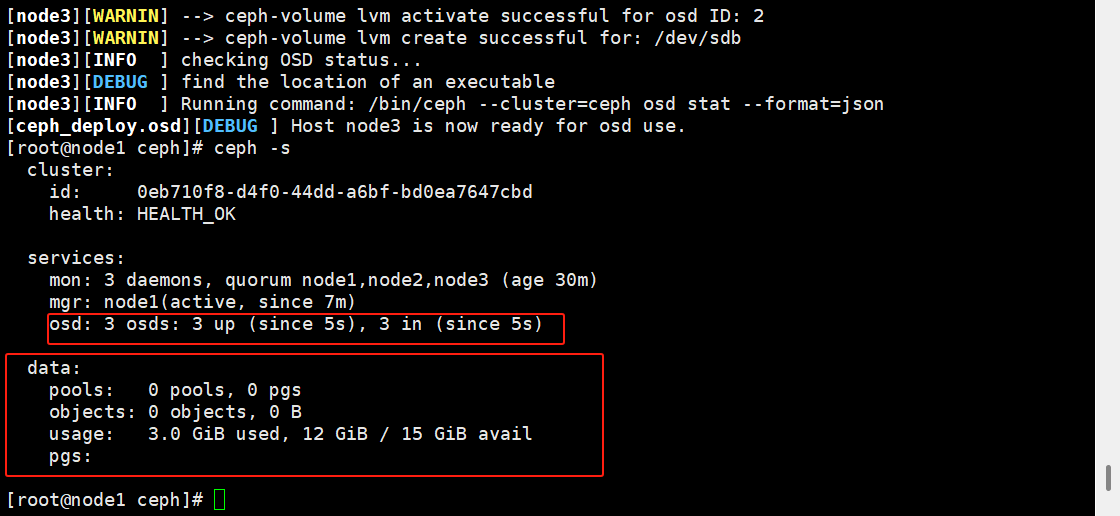
4.RADOS原生数据管理
1.概述
上面提到了RADOS也可以进行数据的存取操作,一般不直接使用它,但我们可以先用RADOS的方式来深入了解下ceph的数据存取原理
2.原理
实现数据存储需要创建一个pool要先分配PG
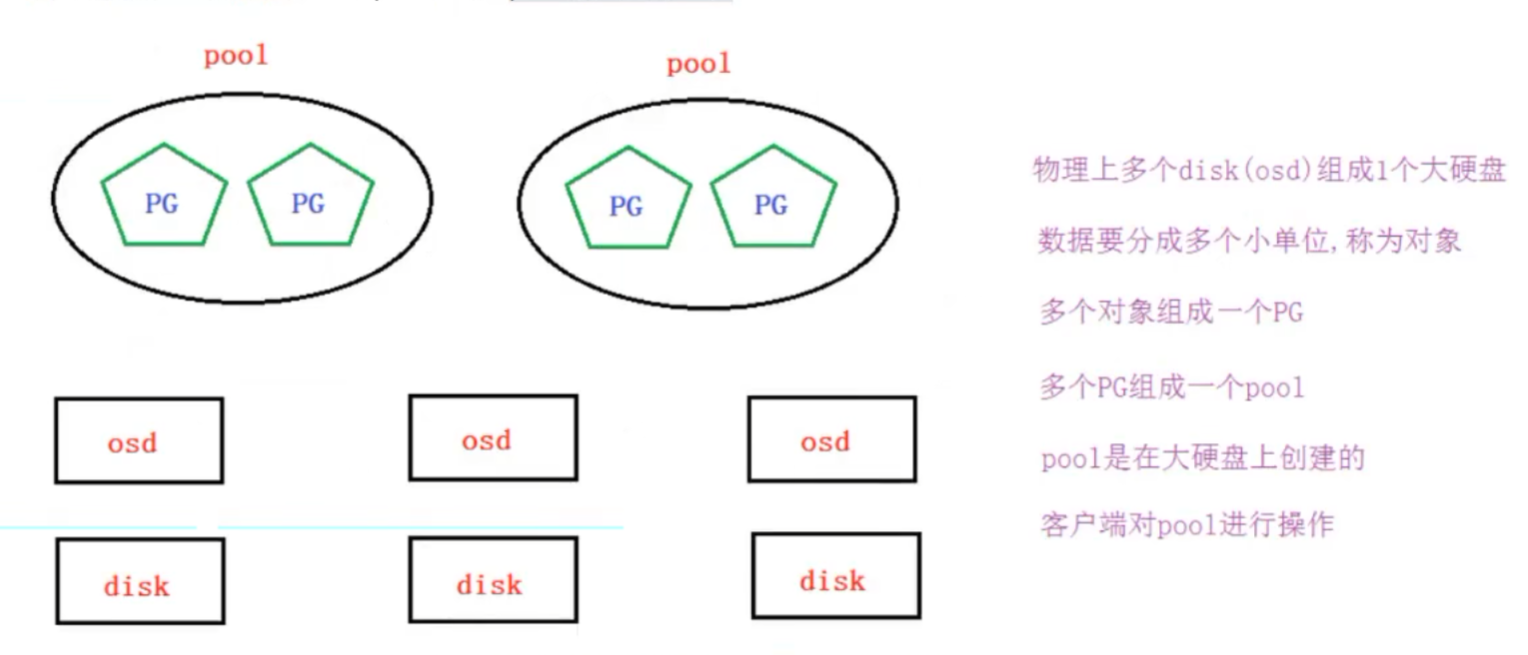
如果客户端对一个pool写了一个文件,那么这个问阿金是如何分配到多节点的磁盘上呢?
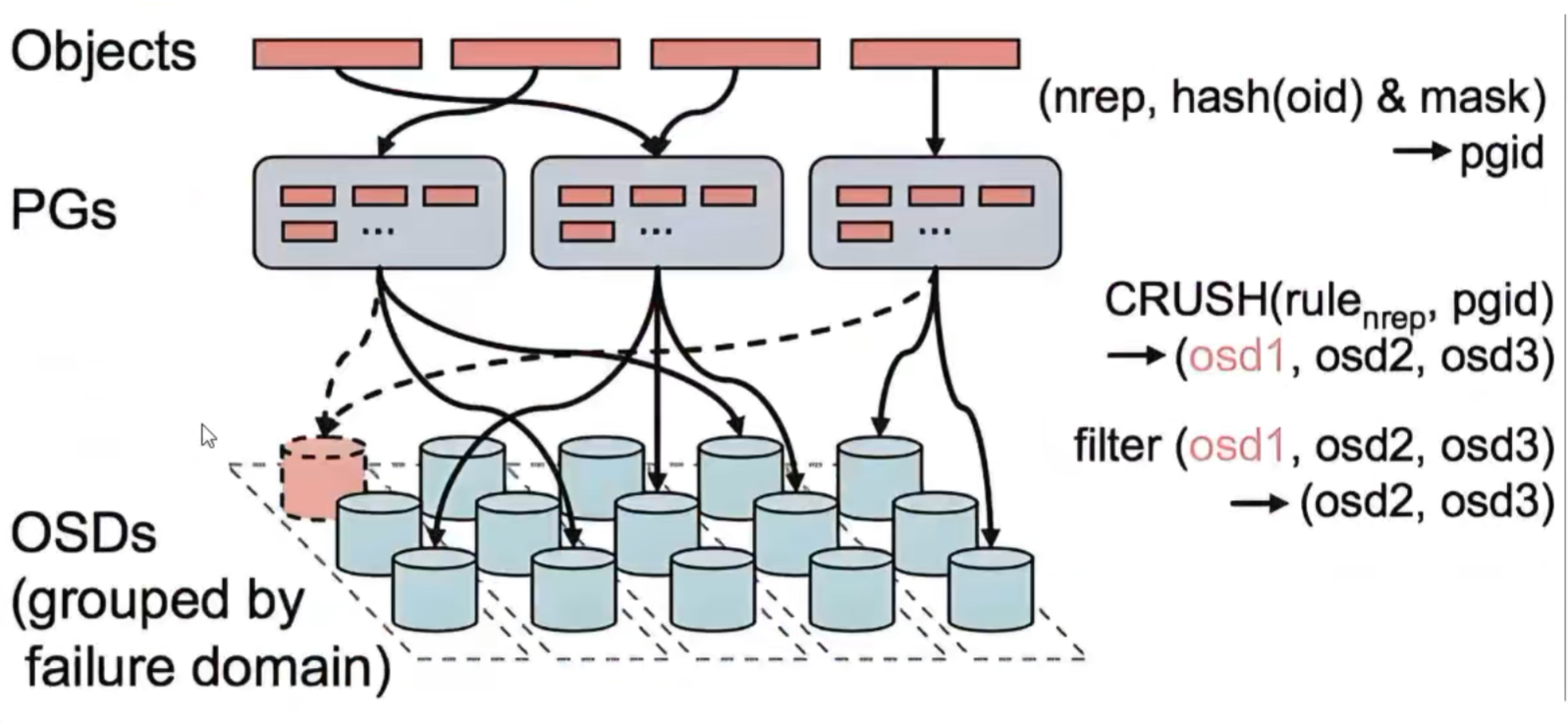
他是通过crush算法
3.创建pool(存储池)
创建test_pool,指定pg数为128
ceph osd pool create test_pool 128查看pg数量,可以使用ceph gsd poolset test_pool pg_num 64这样的命令来尝试调整
ceph osd pool get test_pool pg_num说明:pg数与ods数量有关系
pg数为2的倍数,一般5个以下gsd,分128个PG或以下即可(分多了PG会报错的,可按报错适当调低)
可以使用ceph osd pool set test_pool pg_num 64这样的命令来尝试调整
4.存储数据
先创建一个文件,里面的内容为0字节一共100M
dd if=/dev/zero of=/root/test.txt bs=1M count=100
创建好之后将文件放入存储池
# 将root目录下的test.txt以test01.txt的名字存入存储池中
rados put test01.txt /root/test.txt --pool=test_pool查看数据
# 数据列表
rados -p test_pool ls
# 从pool中获取对象内容(下载)
# 语法:rados -p pool名 get 获取的对象名字 获取的内容保存的文件名
rados -p test_pool get test01.txt test.txt删除数据
rados rm test01.txt --pool=test_pool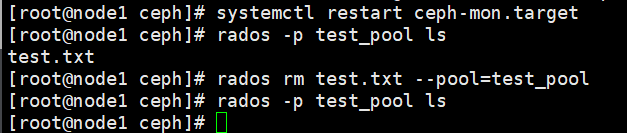
5.删除存储池
# 在部署节点node1上增加参数允许ceph删除pool
vi /etc/ceph/ceph.conf
################################
#文件内容最后一行添加下面的配置
mon_allow_pool_delete = true
# 修改了配置,要同步到其它集群节点
ceph-deploy --overwrite-conf admin node2 node3
#重启监控服务
systemctl restart ceph-mon.target
# 删除时pool名输两次,后再接`--yes-i-rea1ly-rea11y-mean-it`参数就可以删除了
ceph osd pool delete test_pool test_pool --yes-i-really-really-mean-it5.文件存储
1.概述
要运行Ceph文件系统,你必须先创建至少带一个mds的ceph存储集群。Ceph MDs:ceph文件存储类型存放与管理元数据metadata的服务
2.创建文件存储
#在node1部署节点上同步配置文件,并创建mds服务(也可以做多个mds实现HA)(注意该命令的执行位置需要在/etc/ceph目录下)
ceph-deploy mds create node1 node2 node3
#一个ceph文件系统需要至少两个RADOS存储池,一个用于数据,一个用于元数据。所以我们创建它们
ceph osd pool create cephfs_pool 128
ceph osd pool create cephfs_metadata 64
# 列出包含cephfs名字的存储池
ceph osd pool ls | grep cephfs
# 创建ceph文件系统,并确认客户端访问的节点,cephfs为文件系统的名称
ceph fs new cephfs cephfs_metadata cephfs_pool
ceph fs ls
# 可以看到节点状态
ceph mds stat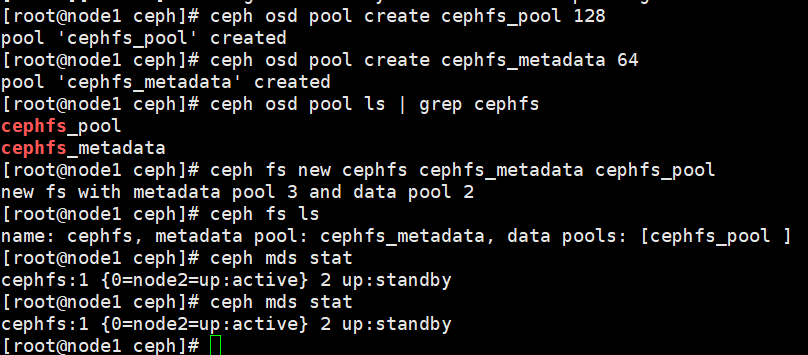
客户端操作也就是client服务器上
# 先在node1上拿到验证key文件
cat /etc/ceph/ceph.client.admin.keyring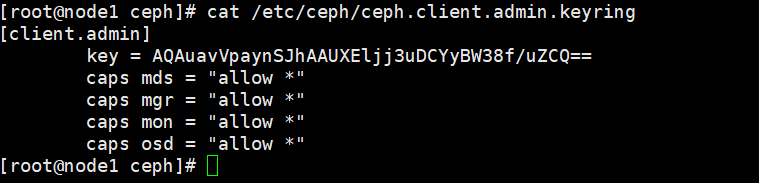
# 在客户端上任意目录创建一个文件记录密钥字符串(client上进行操作)
vi /root/admin.key # 将上述的密钥写入文件当中
# 客户端挂载(挂载ceph集群中跑了mon监控的节点,mon监控为6789端口)(在c1ient中进行操作)
mount -t ceph node1:6789:/ /mnt -o name=admin,secretfile=/root/admin.key
# 验证
df -h | tail -l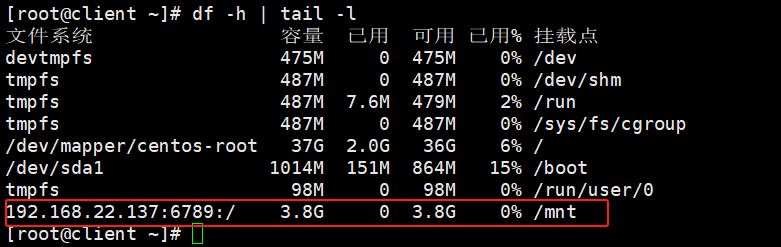
# 高可用性,挂载到三个节点上,若一个出现问题,还可以用其他两个
mount -t ceph node1,node2,node3:6789:/ /mnt -o name=admin,secretfile=/root/admin.key这里的客户端也是成功通过/mnt目录连接到了ceph分布式存储管理,此时将文件放入其中就会实现分布式存储,在三个服务器上node1,node2,node3上,实现高可用
3.删除文件存储
#在客户端上删除数据,并umount所有挂载
rm -rf /mnt/*
umount /mnt/
# 停掉所有节点的mds(只有停掉mds才能删除文件存储)
# node1
systemctl stop ceph-mds.target
# node2
systemctl stop ceph-mds.target
# node3
systemctl stop ceph-mds.target
# 回到集群任意一个节点上(node1、node2、node3其中之一)删除
# 删除文件系统
ceph fs rm cephfs --yes-i-really-mean-it
#删除池
ceph osd pool delete cephfs_metadata cephfs_metadata --yes-i-really-really-mean-it
ceph osd pool delete cephfs_pool cephfs_pool --yes-i-really-really-mean-it
#再次mds服务再次启动
# node1
systemctl start ceph-mds.target
# node2
systemctl start ceph-mds.target
# node3
systemctl start ceph-mds.target