作为一名高级开发,定时任务是分布式系统中不可或缺的组件,而 XXL-JOB 作为轻量级、易集成、高可用的分布式任务调度框架,是企业级开发的首选方案。本篇基于官方文档 + 实战测试,带你本地跑通 XXL-JOB,并深度拆解核心原理、架构设计与高级特性,一站式掌握框架使用与底层逻辑。
一、本地快速部署
1. 环境准备
基础环境:JDK 17+、MySQL5.7+、Maven3.6+,拉取 XXL-JOB 官方源码即可开始部署。
git clone https://github.com/xuxueli/xxl-job.git
2. 初始化调度数据库
执行源码中/doc/db/tables_xxl_job.sql脚本,一键创建 8 张核心数据表,为调度中心提供数据支撑。
3. 配置调度中心
修改xxl-job-admin模块的application.properties,配置 MySQL 连接信息:
spring.datasource.url=jdbc:mysql://127.0.0.1:3306/xxl_job?useUnicode=true&characterEncoding=UTF-8
spring.datasource.username=root
spring.datasource.password=1234564. 启动调度中心
运行XxlJobAdminApplication主类,访问地址:http://localhost:8080/xxl-job-admin默认账号密码:admin/123456,登录后即可看到可视化管理平台。
二、核心概念:调度中心 vs 执行器
这是 XXL-JOB 最核心的设计,也是理解框架的关键:
- 调度中心(xxl-job-admin) :分布式调度的「大脑」,只做决策不执行业务,负责配置任务、触发调度、监控结果、负载均衡。
- 执行器 :承载业务任务的 SpringBoot 应用,只负责执行具体代码,接收调度中心的指令并运行 JobHandler。
三、实战:自定义任务开发
基于官方示例xxl-job-executor-sample-springboot,快速开发自定义任务:
1. 编写任务 Handler
通过@XxlJob注解定义任务,支持初始化和销毁方法:
java
package com.xxl.job.executor.jobhandler;
import com.xxl.job.core.handler.annotation.XxlJob;
import org.springframework.stereotype.Component;
@Component
public class TestJob {
// 定义任务名称,对应管理平台配置
@XxlJob(value = "test1Job", init = "init", destroy = "destroy")
public void test1Job() {
// 获取任务入参(管理平台配置)
String command = XxlJobHelper.getJobParam();
System.out.println("test1Job execute,参数:" + command);
}
// 任务初始化
public void init() {
System.out.println("test1Job init");
}
// 任务销毁
public void destroy() {
System.out.println("test1Job destroy");
}
}在页面上进行注册
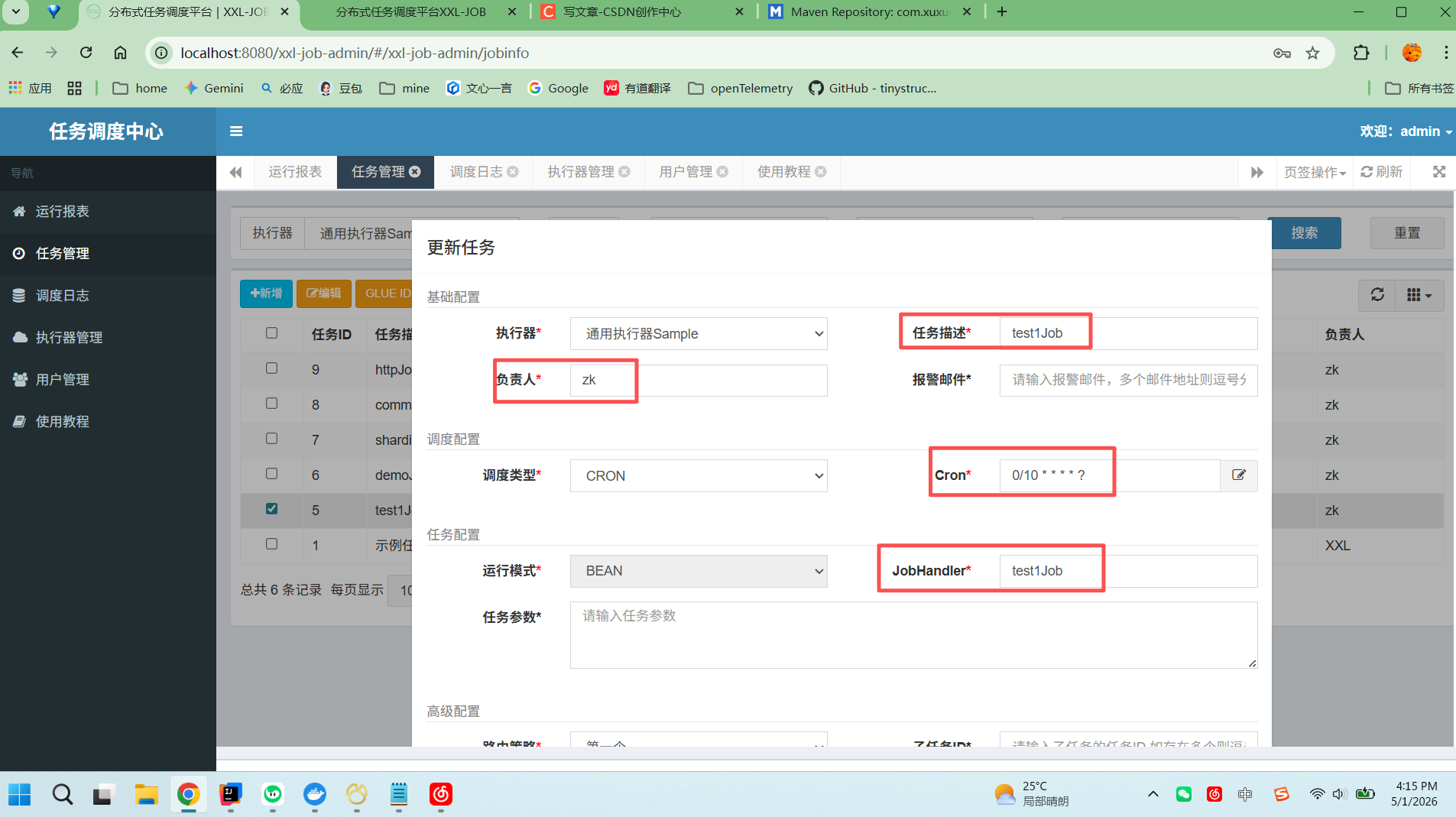
这里主要注意 Cron 表达式的时间配置以及 JobHandler 的值需要与自定义任务方法的注解上的 value 属性值一致即可。
高级配置:
路由策略:当执行器集群部署时,提供丰富的路由策略,包括:FIRST(第一个):固定选择第一个机器;LAST(最后一个):固定选择最后一个机器;ROUND(轮询):;RANDOM(随机):随机选择在线的机器;CONSISTENT_HASH(一致性HASH):每个任务按照Hash算法固定选择某一台机器,且所有任务均匀散列在不同机器上。LEAST_FREQUENTLY_USED(最不经常使用):使用频率最低的机器优先被选举;LEAST_RECENTLY_USED(最近最久未使用):最久未使用的机器优先被选举;FAILOVER(故障转移):按照顺序依次进行心跳检测,第一个心跳检测成功的机器选定为目标执行器并发起调度BUSYOVER(忙碌转移):按照顺序依次进行空闲检测,第一个空闲检测成功的机器选定为目标执行器并发起调度SHARDING_BROADCAST(分片广播):广播触发对应集群中所有机器执行一次任务,同时系统自动传递分片参数,可根据分片参数开发分片任务;
- 子任务:每个任务都拥有一个唯一的任务ID(任务ID可以从任务列表获取),当本任务执行结束并且执行成功时,将会触发子任务ID所对应的任务的一次主动调度。
- 调度过期策略:
- 忽略:调度过期后,忽略过期的任务,从当前时间开始重新计算下次触发时间;
- 立即执行一次:调度过期后,立即执行一次,并从当前时间开始重新计算下次触发时间;
- 阻塞处理策略:调度过于密集执行器来不及处理时的处理策略;
- 单机串行(默认):调度请求进入单机执行器后,调度请求进入
FIFO队列并以串行方式运行; - 丢弃后续调度:调度请求进入单机执行器后,发现执行器存在运行的调度任务,本次请求将会被丢弃并标记为失败;
- 覆盖之前调度:调度请求进入单机执行器后,发现执行器存在运行的调度任务,将会终止运行中的调度任务并清空队列,然后运行本地调度任务;
- 单机串行(默认):调度请求进入单机执行器后,调度请求进入
- 任务超时时间:支持自定义任务超时时间,任务运行超时将会主动中断任务;
- 失败重试次数:支持自定义任务失败重试次数,当任务失败时将会按照预设的失败重试次数主动进行重试;
2. 管理平台配置任务
登录调度中心,新增任务:绑定执行器、填写 JobHandler 名称(test1Job)、配置 Cron 表达式,保存后即可启动 / 执行一次任务。
一次完整的任务调度 + 执行 + 回调全流程
这是 XXL-JOB 最核心的通讯与执行链路,完全遵循官方文档逻辑:
完整流程(调度中心 → 执行器 → 调度中心回调)
-
**任务触发(调度中心)**调度中心根据 Cron 表达式 / 手动触发,判定任务需要执行,从数据库加载任务信息,并根据路由策略(如故障转移、轮询)选择一台在线执行器。
-
调度中心发送 RPC 调度请求 调度中心通过HTTP 调用目标执行器的9999 端口(执行器内置 Netty 服务器),发送任务执行请求(包含任务 Handler、参数、日志 ID 等信息)。
-
执行器接收并处理请求执行器 9999 端口监听到调度请求后:
- 匹配对应的
JobHandler(如test1Job); - 异步执行任务业务代码,立即返回调度中心 "接收成功",不阻塞调度中心。
- 匹配对应的
-
执行器执行业务逻辑 执行器运行
@XxlJob标注的方法,打印日志、处理业务、获取参数。 -
执行器回调调度中心(上报执行结果) 任务执行完成(成功 / 失败)后,执行器主动调用调度中心的 API 接口:
- 接口地址:
JobApiController.callback - 回调内容:执行状态、日志、耗时、错误信息;
- 调度中心接收回调,更新
xxl_job_log表中的任务状态。
- 接口地址:
-
调度中心完成最终状态更新调度中心将任务标记为「执行成功 / 失败」,在管理平台展示日志与结果,完成一次完整调度。
官方核心说明:调度中心提供日志回调 API 服务,执行器必须在任务结束后回调结果,否则调度中心会将任务标记为运行中,超时后自动判定失败。
四、核心机制:自动注册与心跳
执行器与调度中心的绑定,依靠自动注册 + 心跳机制实现:
- 执行器启动后,会周期性向调度中心上报机器地址(默认 30s 心跳);
- 调度中心通过
xxl_job_registry表维护在线执行器列表,实现动态发现; - 类比:调度中心 = 项目经理,只派发任务给执行器分组;执行器 = 开发组,内部自行负载均衡执行任务。
五、端口分工详解
XXL-JOB 涉及三个关键端口,功能完全隔离:
| 服务模块 | 端口 | 核心用途 |
|---|---|---|
| 调度中心(admin) | 8080 | Web 管理界面,任务配置与监控 |
| 执行器 SpringBoot 服务 | 8081 | 执行器自身业务端口,与 XXL-JOB 调度无关 |
| 执行器 Netty 通信端口 | 9999 | 核心 RPC 端口,接收调度中心的调度指令 |
重点:9999 是执行器与调度中心通讯的核心端口,不可占用。
六、8 张核心数据表作用
XXL-JOB 基于 MySQL 实现调度与集群,8 张表各司其职:
xxl_job_lock:任务调度锁,保证集群不重复执行;xxl_job_group:执行器信息表,管理执行器分组;xxl_job_info:任务核心信息表,存储任务配置、参数、报警规则;xxl_job_log:调度日志表,记录任务调度 / 执行结果;xxl_job_log_report:日志报表,平台报表功能使用;xxl_job_logglue:GLUE 任务日志,支持版本回溯;xxl_job_registry:执行器注册表,维护在线机器;xxl_job_user:系统用户表,管理平台登录账号。
七、架构设计深度解析
1. 核心设计思想
调度与任务完全解耦:
- 调度中心:只负责发起调度请求,无业务逻辑;
- 执行器:只负责执行业务任务,接收调度指令;
- 优势:提升系统稳定性、扩展性,调度中心性能不受业务任务影响。
2. 系统组成
- 调度模块:可视化管理任务、集群调度、监控日志、故障转移;
- 执行模块:接收指令、执行任务、回调结果、处理分片。
3. 高可用核心特性
(1)调度中心 HA(集群)
基于数据库锁实现集群,同一任务同一时间仅一个调度节点执行,避免重复调度。
(2)并行调度
- 不同任务:并行调度、并行执行;
- 单个任务:多执行器并行,单执行器串行;
- 线程池设计:避免单线程阻塞导致任务延迟。
(3)过期任务处理
任务错过触发时间:
- 过期 > 5s:忽略本次,从当前时间重新计算;
- 过期≤5s:立即触发一次,保证任务不丢失。
(4)全异步化 + 轻量级
- 异步调度:调度请求入队,异步推送给执行器;
- 异步执行:执行器接收请求后立即响应,异步执行业务;
- 单机支撑 5000 + 任务稳定运行,单个任务耗时仅 10ms 左右。
- 系统架构图
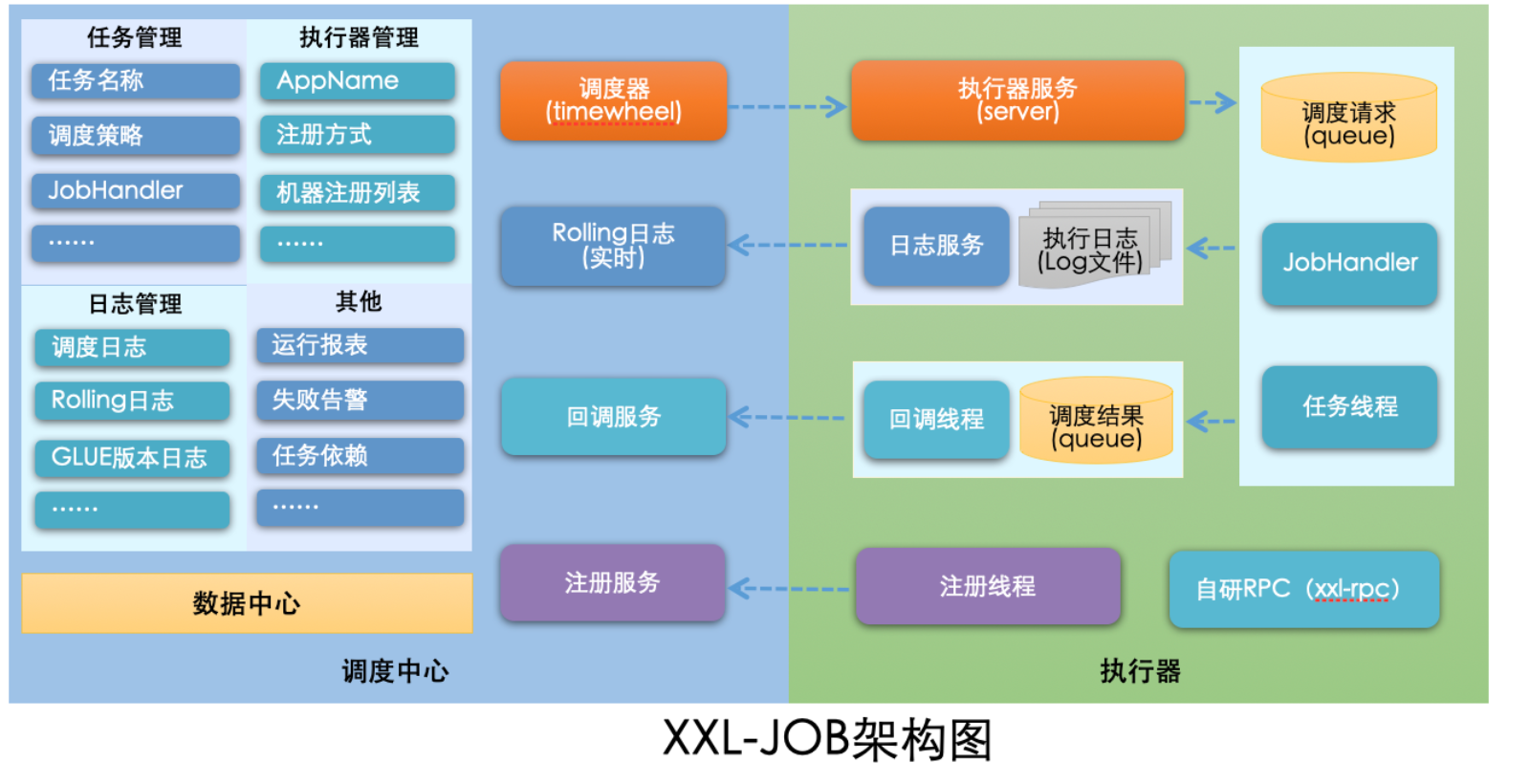
八、高级特性
1. 通讯流程
一次完整调度三步曲:
- 调度中心 → 执行器(9999 端口):发送 RPC 调度请求;
- 执行器:执行任务逻辑;
- 执行器 → 调度中心:回调执行结果。
2. 分片广播 & 动态分片
企业级大数据量任务核心方案:
- 执行器集群部署,选择「分片广播」路由策略;
- 调度中心触发所有执行器同时执行,自动传递分片序号 / 总数;
- 场景:10 台执行器处理 10w 数据,每台仅处理 1w,性能提升 10 倍。
获取分片参数:
java
int shardIndex = XxlJobHelper.getShardIndex(); // 当前分片序号
int shardTotal = XxlJobHelper.getShardTotal(); // 总分片数-
场景 :处理可并行的批量任务,如清理全库用户日志、同步所有店铺数据。
-
原理 :一次触发,所有实例同时 执行同一个任务。XXL-JOB会为每个实例传入分片参数(当前实例索引、实例总数),让每个实例知道自己该处理哪部分数据。例如,2个实例处理100条数据,实例0处理ID为偶数的数据,实例1处理ID为奇数的数据。
假如项目需要对上传到分布式文件系统 minio 中的视频文件进行统一格式的视频转码操作,由于视频转码操作会带了很大的时间消耗以及 CPU 的开销,所以考虑集群服务下使用 xxl-job 的方式以任务调度的方式定时处理视频转码操作.
这样可以带来两个好处:
- 任务调度的方式,可以使得视频转码操作不会阻塞主线程,避免影响主要业务的吞吐量;
- 以集群服务分片接收任务的方式,可以将任务均分给每个机器使得任务调度可以并行执行,提高总任务处理时间以及降低单台机器 CPU 的开销;
执行流程图
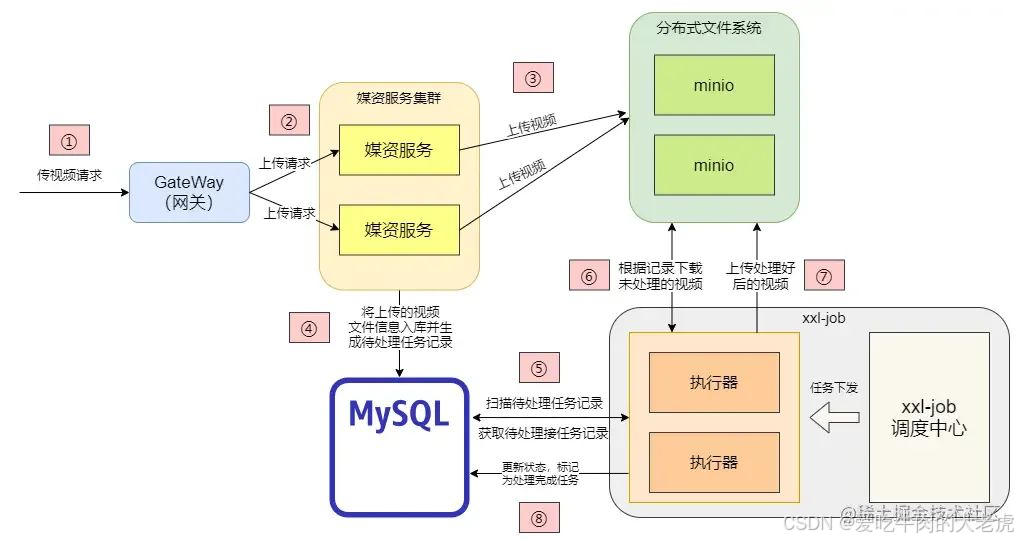
怎么将任务均分给每台服务器
由于任务执行时间过长,需要搭建集群服务来做到并行任务调度,从而减小 CPU 的开销,那么怎么均分任务呢?
利用 xxl-job 在集群部署时,配置路由策略中选择 分片广播 的方式,可以使一次任务调度会广播触发集群中所有的执行器执行一次任务,并且可以向系统传递分片参数。
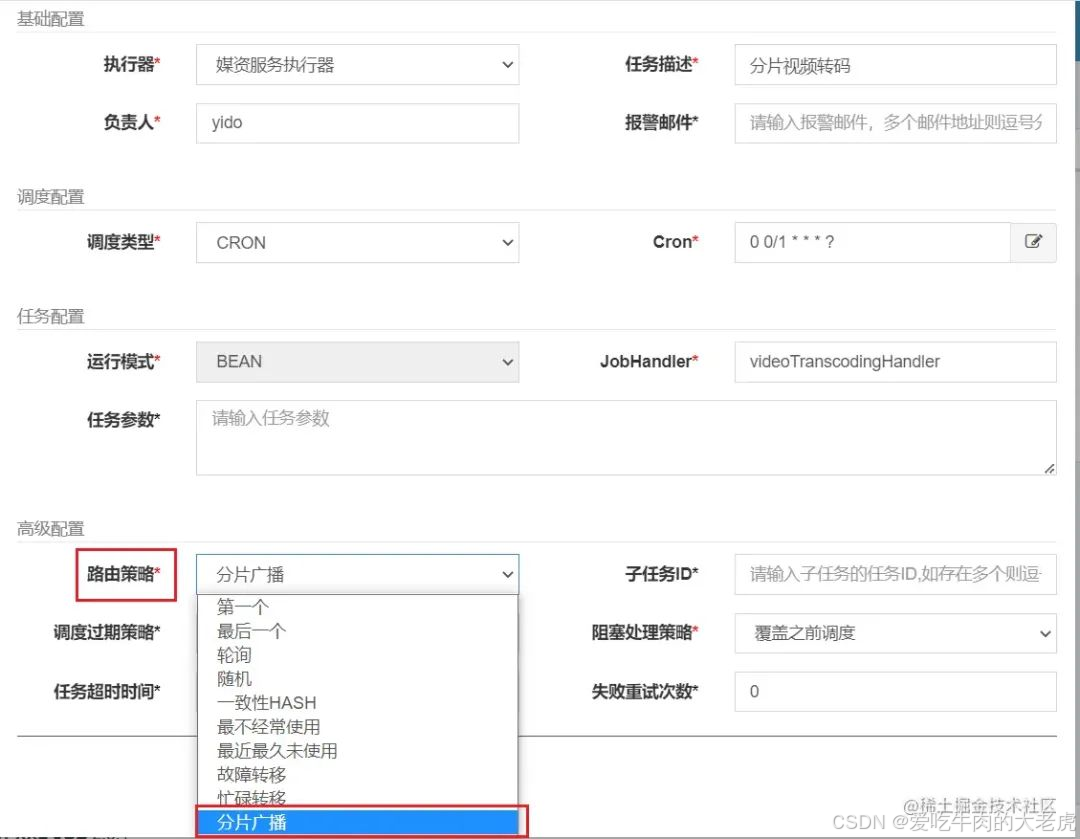
利用这一特性可以根据 当前执行器的分片序号和分片总数 来获取对应的任务记录。
先来看看 Bean 模式下怎么获取分片序号和分片总数:
// 分片序号(当前执行器序号)
int shardIndex = XxlJobHelper.getShardIndex();
// 分片总数(执行器总数)
int shardTotal = XxlJobHelper.getShardTotal();有了这两个属性,当执行器扫描数据库获取记录时,可以根据 取模 的方式获取属于当前执行器的任务,可以这样编写 sql 获取任务记录:
select * from media_process m
where m.id % #{shareTotal} = #{shareIndex}
and (m.status = '1' or m.status = '3')
and m.fail_count < 3
limit #{count}扫描任务表,根据任务 id 对分片总数 取模 来实现对所有分片的均分任务,通过判断是否是当前分片序号,并且当前任务状态为 1(未处理)或 3(处理失败)并且当前任务失败次数小于3次时可以取得当前任务。每次扫描只取出 count 个任务数(批量处理)。
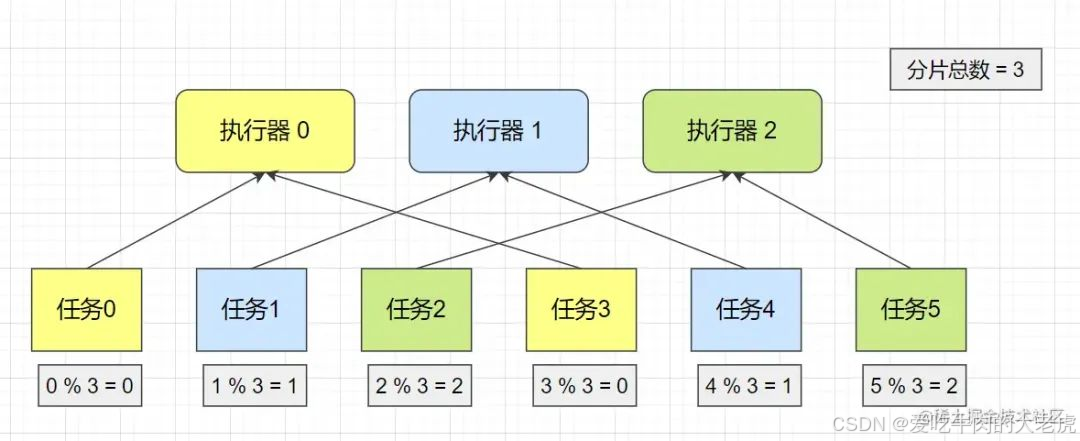
因此通过 xxl-job 的分片广播 + 取模 的方式即可实现对集群服务均分任务的操作。
怎么确保任务不会被重复消费
由于视频转码本身处理时间就会比较长,所以更不允许服务重复执行,虽然上面通过分片广播+取模的方式提高了任务不会被重复执行的机率,但是依旧存在如下情况:
如下图,有三台集群机器和六个任务,刚开始分配好了每台机器两个任务,执行器0正准备执行任务3时,刚好执行器2宕机了,此时执行器1刚好执行一次任务,因为分片总数减小,导致执行器1重新分配到需要执行的任务正好也是任务3,那么此时就会出现执行器0和执行器1都在执行任务3的情况。
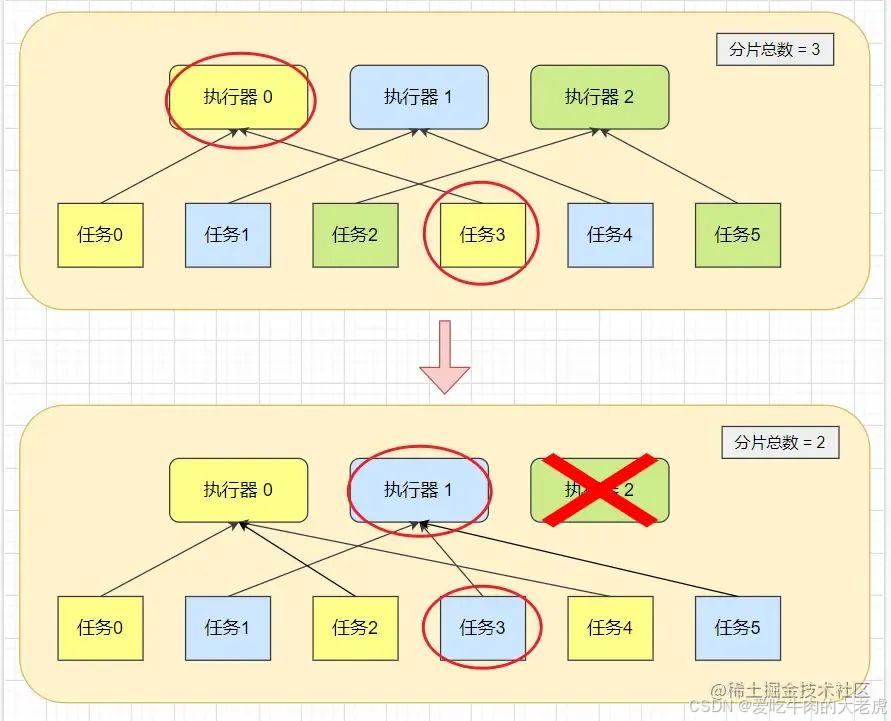
那么这种情况就需要实现幂等性了,幂等性有很多种实现方法
这里使用乐观锁的方式实现幂等性,具体 sql 如下:
update media_process m
set m.status = '2'
where (m.status = '1' or m.status = '3')
and m.fail_count < 3
and m.id = #{id}这里只需要依靠任务的状态即可实现(未处理1;处理中2;处理失败3;处理成功4),可以看到这里类似于 CAS 的方式通过比较和设置的方式只有在状态为未处理或处理失败时才能设置为处理中。这样在并发场景下,即使多个执行器同时处理该任务,也只有一个任务可以设置成功进入处理任务阶段。
为了真正达到幂等性,还需要设置一下 xxl-job 的调度过期策略和阻塞处理策略来保证真正的幂等性。分别设置为 忽略(调度过期后,忽略过期的任务,从当前时间开始重新计算下次触发时间) 和 丢弃后续调度(调度请求进入单机执行器后,发现执行器存在运行的调度任务,本次请求将会被丢弃并标记为失败)。
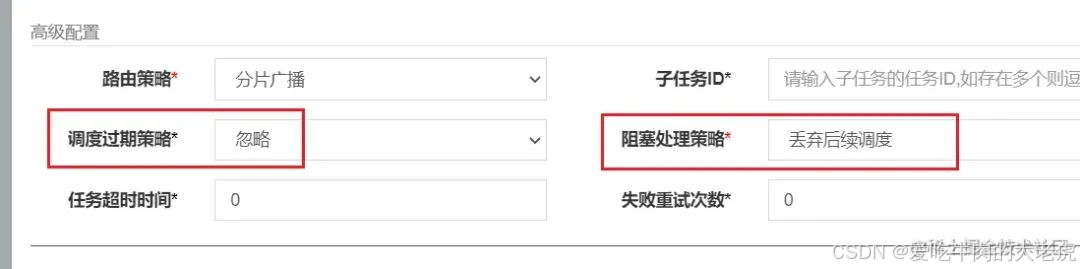
分片视频转码处理
/**
* 视频转码处理任务
*/
@XxlJob("videoTranscodingHandler")
public void videoTranscodingHandler() throws InterruptedException {
int shardTotal = XxlJobHelper.getShardTotal();//总分片数
int shardIndex = XxlJobHelper.getShardIndex();//当前分片数
// 1. 分片获取当前执行器需要执行的所有任务
List<MediaProcess> mediaProcessList = mediaProcessService.getMediaProcessList(shardIndex, shardTotal, count);
// 通过JUC工具类阻塞直到所有任务执行完
CountDownLatch countDownLatch = new CountDownLatch(mediaProcessList.size());
// 遍历所有任务
mediaProcessList.forEach(mediaProcess -> {
// 以多线程的方式执行所有任务
executor.execute(() -> {
try {
// 2. 尝试抢占任务(通过乐观锁实现)
boolean res = mediaProcessService.startTask(id);
if (!res) {
XxlJobHelper.log("任务抢占失败,任务id{}", id);
return;
}
// 3. 从minio中下载视频到本地
File file = mediaFileService.downloadFileFromMinIO(bucket, objectName);
// 下载失败
if (file == null) {
XxlJobHelper.log("下载视频出错,任务id:{},bucket:{},objectName:{}", id, bucket, objectName);
// 出现异常重置任务状态为处理失败等待下一次处理
mediaProcessService.saveProcessFinishStatus(id, Constants.MediaProcessCode.FAIL.getValue(), fileId, null, "下载视频到本地失败");
return;
}
// 4. 视频转码
String result = videoUtil.generateMp4();
if (!result.equals("success")) {
XxlJobHelper.log("视频转码失败,原因:{},bucket:{},objectName:{},", result, bucket, objectName);
// 出现异常重置任务状态为处理失败等待下一次处理
mediaProcessService.saveProcessFinishStatus(id, Constants.MediaProcessCode.FAIL.getValue(), fileId, null, "视频转码失败");
return;
}
// 5. 上传转码后的文件
boolean b1 = mediaFileService.addMediaFilesToMinIO(new_File.getAbsolutePath(), "video/mp4", bucket, objectNameMp4);
if (!b1) {
XxlJobHelper.log("上传 mp4 到 minio 失败,任务id:{}", id);
// 出现异常重置任务状态为处理失败等待下一次处理
mediaProcessService.saveProcessFinishStatus(id, Constants.MediaProcessCode.FAIL.getValue(), fileId, null, "上传 mp4 文件到 minio 失败");
return;
}
// 6. 更新任务状态为成功
mediaProcessService.saveProcessFinishStatus(id, Constants.MediaProcessCode.SUCCESS.getValue(), fileId, url, "创建临时文件异常");
} finally {
countDownLatch.countDown();
}
});
});
// 阻塞直到所有方法执行完成(30min后不再等待)
countDownLatch.await(30, TimeUnit.MINUTES);
}核心任务 - 分片获取任务后执行视频转码任务,步骤如下:
- 通过
分片广播拿到的参数以取模的方式 获取当前执行器所属的任务记录集合 - 遍历集合,以
多线程的方式并发地执行任务 - 每次执行任务前需要先通过
数据库乐观锁的方式抢占当前任务,抢占到才能执行 - 执行任务过程分为 分布式文件系统下载需要转码的视频文件 -> 视频转码 -> 上传转码后的视频 -> 更新任务状态(处理成功)
- 使用JUC工具类
CountDownLatch实现所有任务执行完后才退出方法 - 中间使用 xxl-job 的日志记录错误信息和执行结果
视频补偿机制
由于使用乐观锁会将任务状态更新为处理中,如果此时执行任务的执行器(服务)宕机了,会导致该任务记录一直存在,因为乐观锁的原因别的执行器也无法获取,这个时候同样需要使用任务调度的方式,定期扫描任务表,判断任务是否处于处理中状态并且任务创建时间远大于30分钟,则说明任务超时了,则是使用任务调度的方式重新更新任务的状态为未处理,等待下一次视频转码任务的调度处理。此外视频补偿机制任务调度还需要检查是否存在任务最大次数已经大于3次的,如果存在则交付给人工处理。
主要实现两个功能:① 处理任务超时情况下的任务,做出补偿;② 处理失败次数大于3次的任务,做出补偿;
这部分内容来自博客.
3. 安全校验:AccessToken
调度中心与执行器配置相同的accessToken,校验通过才允许通讯,提升系统安全性。
4. 故障转移 + 失败重试
- 故障转移:调度阶段检测执行器存活,自动跳过故障节点;
- 失败重试:支持自定义重试次数,调度 / 执行阶段失败自动重试。
5. 执行器灰度上线
避免重启执行器中断任务:
- 手动注册执行器,下线一半机器(A 组);
- 上线 A 组,切换调度至 A 组;
- 上线剩余机器(B 组),恢复全量集群。
6. 其他实用特性
- 任务超时控制:超时自动中断任务;
- 失败告警:默认支持邮件,可扩展钉钉 / 短信;
- 日志自动清理:支持配置日志保留天数,避免磁盘爆满;
- 命令行任务:原生支持执行 Shell/Python 等命令行任务。
XXL-JOB 全程全异步化,这是支撑高并发的核心:
- 异步调度:调度中心只负责将请求推入异步队列,不等待执行结果,耗时仅 10ms 左右;
- 异步执行:执行器接收请求后立即响应调度中心,任务在本地异步线程运行,不占用调度中心资源;
- 这种设计让调度中心单机可支撑 5000 + 任务稳定并发,完全实现 "轻量级调度中心"。
任务成功 / 失败由以下标准严格判断:
- Bean/GLUE (Java) 任务 :返回
ReturnT.code == 200表示成功,否则失败; - Shell/Python 等脚本任务 :退出码
0表示成功,非 0表示失败; - 执行器会将结果通过回调接口同步给调度中心,作为平台展示的最终状态。
通讯数据加密
调度中心 ↔ 执行器之间的所有通讯数据:
- 使用
RequestModel、ResponseModel封装; - 底层进行对象序列化;
- 传输前做数据协议校验 + 时间戳校验;
- 防止数据篡改、非法请求,提升通讯安全性。
任务链(父子依赖)
-
实现 :在调度中心配置任务时,有一个 **"子任务ID"** 的选项。你可以在那里填写另一个任务的ID。当父任务执行成功后,会自动触发指定的子任务。
排查"运行中"卡死
-
步骤1 :首先在调度中心查看 "调度日志",找到该次执行的日志详情,看是否有超时错误。
-
步骤2 :登录到对应的执行器服务器,查看应用日志,看任务线程是否在正常运行或卡在某个地方。
-
步骤3 :检查系统资源(CPU、内存、磁盘),并考虑在代码中添加更详细的日志 或设置合理的超时时间。
任务触发不执行
-
检查点1 :网络与端口 。确保调度中心能连通 执行器注册的
IP:端口(如192.168.1.16:9999)。这是最常见的问题。 -
检查点2 :JobHandler名称 。检查执行器代码中
@XxlJob("value")的 "value" 是否与调度中心任务配置的 **"JobHandler"** 完全一致(区分大小写)。 -
检查点3 :执行器状态 。在调度中心"执行器管理"中,确认该执行器在线(绿色),并且注册的地址正确。
附带常用配置:
### 调度中心部署根地址 [选填]:如调度中心集群部署存在多个地址则用逗号分隔。执行器将会使用该地址进行"执行器心跳注册"和"任务结果回调";为空则关闭自动注册;
xxl.job.admin.addresses=http://127.0.0.1:8080/xxl-job-admin
### 调度中心通讯TOKEN [选填]:非空时启用;
xxl.job.admin.accessToken=default_token
### 调度中心通讯超时时间[选填],单位秒;默认3s;
xxl.job.admin.timeout=3
### 执行器启用开关 [选填]:默认开启,关闭时不进行执行器初始化;
xxl.job.executor.enabled=true
### 执行器AppName [选填]:执行器心跳注册分组依据;为空则关闭自动注册
xxl.job.executor.appname=xxl-job-executor-sample
### 执行器注册 [选填]:优先使用该配置作为注册地址,为空时使用内嵌服务 "IP:PORT" 作为注册地址。从而更灵活的支持容器类型执行器动态IP和动态映射端口问题。
xxl.job.executor.address=
### 执行器IP [选填]:默认为空表示自动获取IP,多网卡时可手动设置指定IP,该IP不会绑定Host仅作为通讯使用;地址信息用于 "执行器注册" 和 "调度中心请求并触发任务";
xxl.job.executor.ip=
### 执行器端口号 [选填]:小于等于0则自动获取;默认端口为9999,单机部署多个执行器时,注意要配置不同执行器端口;
xxl.job.executor.port=9999
### 执行器运行日志文件存储磁盘路径 [选填] :需要对该路径拥有读写权限;为空则使用默认路径;
xxl.job.executor.logpath=/data/applogs/xxl-job/jobhandler
### 执行器日志文件保存天数 [选填] : 过期日志自动清理, 限制值大于等于3时生效; 否则, 如-1, 关闭自动清理功能;
xxl.job.executor.logretentiondays=30
### 任务扫描排除路径 [选填] :任务扫描时忽略指定包路径下的Bean;支持配置包路径前缀,多个逗号分隔;
xxl.job.executor.excludedpackage=org.springframework,spring七、总结
XXL-JOB 凭借轻量级、易集成、高可用、可视化的特性,成为分布式定时任务的工业级方案。
- 新手可 2-3 小时本地跑通全流程,快速落地业务;
- 高级开发可基于集群、分片、故障转移等特性,支撑大规模分布式任务调度;
- 核心设计「调度与执行解耦」,完美适配微服务架构,是 Java 开发者必须掌握的中间件技能。
本篇从实战到原理全覆盖,无论是学习还是生产环境落地,都可以直接参考使用!