多组件invoke嵌套的缺点
我们使用多个组件的 invoke 进行嵌套来创建 LLM 应用,示例代码如下:
python
prompt = chatPromptTemplate.from_template("{query}")
llm = ChatOpenAI(model="gpt-3.5-turbo-16k")
parser = StrOutputParser()
# 获取输出内容
content = parser.invoke(
llm.invoke(
prompt.invoke(
{"query": req.query.data}
)
)
)这种写法虽然能实现对应的功能,但是存在很多缺陷:
- 嵌套式写法让程序的维护性与可读性大大降低,当需要修改某个组件时,变得异常困难。
- 没法得知每一步的具体结果与执行进度,出错时难以排查。
- 嵌套式写法没法集成大量的组件,组件越来越多时,代码会变成 "一次性" 代码。
类比:前端代码中的嵌套 / 回调地狱问题
能否将嵌套的写法改成平级的调用,这样就可以屏蔽嵌套带来的大量缺陷
手写一个Chain优化代码
观察发现,虽然 Prompt、Model、OutputParser 分别有自己独立的调用方式,例如:
- Prompt 组件 :
format、invoke、to_string、to_messages - Model 组件 :
generate、invoke、batch - OutputParser 组件 :
parse、invoke
但是它们有一个共同的调用方法:invoke,并且每一个组件的输出都是下一个组件的输入。
基于这个共性,我们可以思考:
是否可以将所有组件组装成一个列表,然后循环依次调用 invoke 执行每一个组件,再将当前组件的输出作为下一个组件的输入?
源码实现:
python
from typing import Any
import dotenv
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_openai import ChatOpenAI
dotenv.load_dotenv()
# 1. 构建组件
prompt = ChatPromptTemplate.from_template("{query}")
llm = ChatOpenAI(model="gpt-3.5-turbo-16k")
parser = StrOutputParser()
# 2. 定义一个链
class Chain:
steps: list = []
def __init__(self, steps: list):
self.steps = steps
def invoke(self, input: Any) -> Any:
for step in self.steps:
input = step.invoke(input)
print("步骤:", step)
print("输出:", input)
print("============")
return input
# 3. 编排链
chain = Chain([prompt, llm, parser])
# 4 执行链并获取结果
print(chain.invoke({"query":"你好,你是?"}))通过自定义"Chain"的方法虽然简化了过程,也支持观察,不过功能过于简陋
Runnable简介与LECL表达式
为了尽可能简化创建自定义链,LangChain 官方实现了一个 Runnable 协议,这个协议适用于 LangChain 中的绝大部分组件,并实现了大量的标准接口,涵盖:
- stream:将组件的响应块流式返回,如果组件不支持流式则会直接输出。
- invoke:调用组件并得到对应的结果。
- batch:批量调用组件并得到对应的结果。
- astream :
stream的异步版本。 - ainvoke :
invoke的异步版本。 - abatch :
batch的异步版本。 - astream_log:除了流式返回最终响应块之外,还会流式返回中间步骤。
除此之外,在 Runnable 中还重写了 __or__ 和 __ror__ 方法(对应 Python 中 | 运算符的计算逻辑),所有的 Runnable 组件,均可以通过 | 或者 pipe() 的方式将多个组件拼接起来形成一条链。
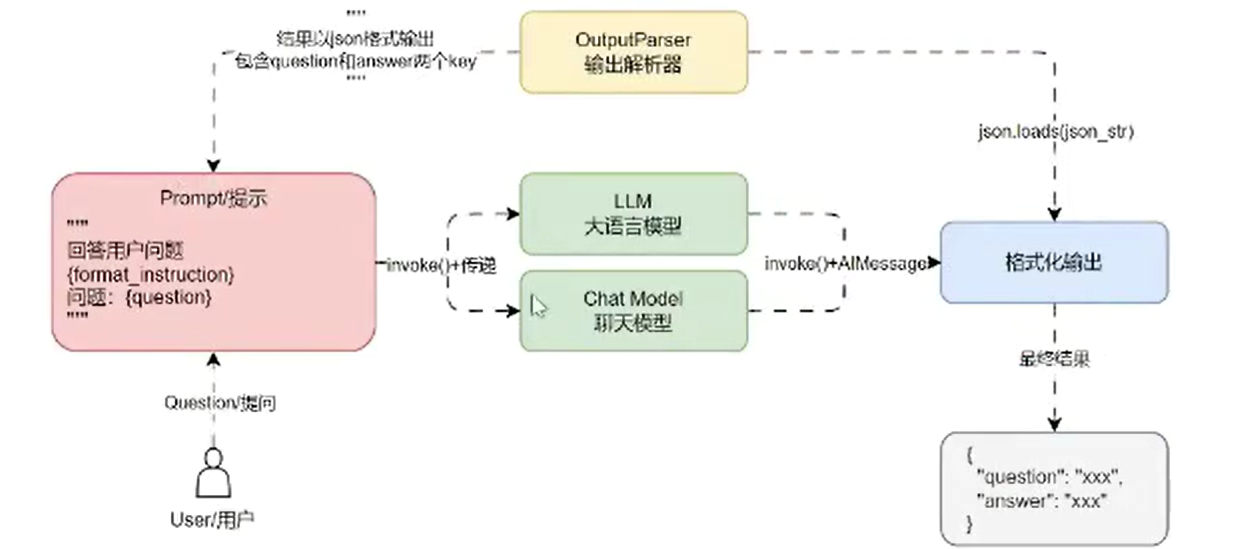
LangChain Runnable 组件的输入/输出类型
其中 Runnable 组件的输入类型和输出类型因组件而异:
| 组件 | 输入类型 | 输出类型 |
|---|---|---|
| Prompt 提示 | Dict 字典 | PromptValue 提示值 |
| ChatModel 聊天模型 | 字符串、聊天消息列表、PromptValue 提示值 | ChatMessage 聊天消息 |
| LLM 大语言模型 | 字符串、聊天消息列表、PromptValue 提示值 | String 字符串 |
| OutputParser 输出解析器 | LLM 或聊天模型的输出 | 取决于解析器 |
| Retriever 检索器 | 单个字符串 | List of Document 文档列表 |
| Tool 工具 | 字符串、字典或取决于工具 | 取决于工具 |
例如上面自定义 "Chain" 的写法等同于如下的代码:
python
import dotenv
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_openai import ChatOpenAI
dotenv.load_dotenv()
# 1. 构建组件
prompt = ChatPromptTemplate.from_template("{query}")
llm = ChatOpenAI(model="gpt-3.5-turbo-16k")
parser = StrOutputParser()
# 2. 创建链
chain = prompt | llm | parser
# 等价以下写法
composed_chain_with_pip = (
RunnableParallel({"query": RunnablePassthrough()})
.pipe(prompt)
.pipe(llm)
.pipe(parser)
)
# 3.调用链得到结果
print(chain.invoke({"query": "请讲一个程序员的冷笑话"}))Runnable底层的运行逻辑本质上也是将每一个组件添加到列表中,然后按照顺序执行并返回最终结果,核心源码:
python
def invoke(self, input: Input, config: Optional[RunnableConfig] = None) -> Output:
from langchain_core.beta.runnables.context import config_with_context
# setup callbacks and context
config = config_with_context(ensure_config(config), self.steps)
callback_manager = get_callback_manager_for_config(config)
# start the root run
run_manager = callback_manager.on_chain_start(
dumpd(self),
input,
name=config.get("run_name") or self.get_name(),
run_id=config.pop("run_id", None),
)
# 调用所有步骤并逐个执行得到对应的输出,然后作为下一个的输入
try:
for i, step in enumerate(self.steps):
input = step.invoke(
input,
# mark each step as a child run
patch_config(
config, callbacks=run_manager.get_child(f"seq:step:{i+1}")
),
)
# finish the root run
except BaseException as e:
run_manager.on_chain_error(e)
raise
else:
run_manager.on_chain_end(input)
return cast(Output, input)两个Runnable核心类的讲解与使用
RunnableParallel并行运行
RunnableParallel 是 LangChain 中封装的支持运行多个 Runnable 的类,一般用于操作 Runnable 的输出,以匹配序列中下一个 Runnable 的输入,起到并行运Runnable 并格式化输出结构的作用。
例如 RunnableParallel 可以让我们同时执行多条 Chain,然后以字典的形式返回各个 Chain 的结果,对比每一条链单独执行,效率会高很多。
python
import dotenv
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnableParallel
from langchain_openai import ChatOpenAI
dotenv.load_dotenv()
# 1. 编排2个提示模板
joke_prompt = ChatPromptTemplate.from_template("请讲一个关于{subject}的冷笑话,尽可能短")
poem_prompt = ChatPromptTemplate.from_template("请写一篇关于{subject}的诗,尽可能短")
# 2. 创建大语言模型
llm = ChatOpenAI(model="gpt-3.5-turbo-16k")
# 3. 创建输出解析器
parser = StrOutputParser()
# 4.编排链
joke_chain = joke_prompt | llm | parser
poem_chain = poem_prompt | llm | parser
# 5.并行链
map_chain = RunnableParallel(joke=joke_chain, poem=poem_chain)
# map_chain = RunnableParallel({
# "joke": joke_chain,
# "poem": poem_chain,
# })
res = map_chain.invoke({"subject": "程序员"})
print(res)除了并执行,RunnableParallel还可以用于操作Runnable的输出,用于产生符合下一个Runnable组件的数据。
列如:用户传递数据,并行执行检索策略得到上下文随后传递给Prompt组件,如下
python
from operator import itemgetter
import dotenv
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnableParallel
dotenv.load_dotenv()
def retrieval(query: str) -> str:
"""一个模拟的检索器函数"""
print("正在检索:", query)
return "我是莫小课"
# 1. 编排prompt
prompt = ChatPromptTemplate.from_template("""请根据用户的问题回答,可以参考对应的上下文进行生成。
<context>
{context}
</context>
用户的提问是:{query}""")
# 2.构建大语言模型
llm = ChatOpenAI(model="gpt-3.5-turbo-16k")
# 3.输出解析器
parser = StrOutputParser()
# 4.构建链
chain = RunnableParallel(
context=retrieval,
query=RunnablePassthrough(),
) | prompt | llm | parser
# 5.调用链
content = chain.invoke({ "query": "你好,我是谁?"})
print(content)在创建RunnableParallel的时候,支持传递字典、函数、映射、键值对数据等多种方式。RunnableParallerl底层会执行检测并将数据统一转换Runnable,核心源码如下:
python
# `langchain-core/runnables/base.py` 代码片段
```python
# langchain-core/runnables/base.py
def __init__(
self,
steps__: Optional[
Mapping[
str,
Union[
Runnable[Input, Any],
Callable[[Input], Any],
Mapping[str, Union[Runnable[Input, Any], Callable[[Input], Any]]],
],
]
] = None,
**kwargs: Union[
Runnable[Input, Any],
Callable[[Input], Any],
Mapping[str, Union[Runnable[Input, Any], Callable[[Input], Any]]],
],
) -> None:
# 1. 检测是否传递字典,如果传递,则提取字段内的所有键值对
merged = {**steps__} if steps__ is not None else {}
# 2. 传递了键值对,则将键值对更新到merged进行合并
merged.update(kwargs)
super().__init__( # type: ignore[call-arg]
# 3. 循环遍历merged的所有键值对,并将每一个元素转换成Runnable
steps__={key: coerce_to_runnable(r) for key, r in merged.items()}
)除此之外,在Chains中使用时,可以简写成字典的方式,__or__和__ror__会自动将字典转换成RunnableParallerl,核心源码:
python
# langchain_core/runnables/base.py
def coerce_to_runnable(thing: RunnableLike) -> Runnable[Input, Output]:
"""Coerce a runnable-like object into a Runnable.
Args:
thing: A runnable-like object.
Returns:
A Runnable.
"""
if isinstance(thing, Runnable):
return thing
elif is_async_generator(thing) or inspect.isgeneratorfunction(thing):
return RunnableGenerator(thing)
elif callable(thing):
return RunnableLambda(cast(Callable[[Input], Output], thing))
elif isinstance(thing, dict):
# 如果类型为字典,使用字典创建RunnableParallel并转换成Runnable格式
return cast(Runnable[Input, Output], RunnableParallel(thing))
else:
raise TypeError(
f"Expected a Runnable, callable or dict."
f"Instead got an unsupported type: {type(thing)}"
)RunnablePassthrough传递数据
除了 RunnableParallel,在 LangChain 中,另外一个高频使用的 Runnable 类是 RunnablePassthrough,这个类透传上游参数输入,简单来说,就是可以获取上游的数据,并保持不变或者新增额外的键。
通常与 RunnableParallel 一起使用,将数据分配给映射中的新键。
例如:使用 RunnablePassthrough 来简化 invoke 的调用流程。
python
import dotenv
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import ChatOpenAI
dotenv.load_dotenv()
# 1. 编排prompt
prompt = ChatPromptTemplate.from_template("{query}")
# 2. 构建大语言模型
llm = ChatOpenAI(model="gpt-3.5-turbo-16k")
# 3. 创建链
chain = {"query": RunnablePassthrough()} | prompt | llm | StrOutputParser()
# 4. 调用链并获取结果
content = chain.invoke("你好,你是")
print(content)RunnablePassthrough() 获取的是整个输入的内容(字符串或者字典),如果想获取字典内的某个部分,可以使用 itemgetter 函数,并传入对应的字段名即可,如下:
python
from operator import itemgetter
chain = {"query": itemgetter("query")} | prompt | llm | StrOutputParser()
content = chain.invoke({"query": "你好,你是?"})除此之外,如果想在传递的数据中添加数据,还可以使用RunnablePassthrough.assign() 方法来实现快速添加。
例如:
python
from operator import itemgetter
import dotenv
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnableParallel
dotenv.load_dotenv()
def retrieval(query: str) -> str:
"""一个模拟的检索器函数"""
print("正在检索:", query)
return "我是莫小课"
# 1. 编排prompt
prompt = ChatPromptTemplate.from_template("""请根据用户的问题回答,可以参考对应的上下文进行生成。
<context>
{context}
</context>
用户的提问是:{query}""")
# 2.构建大语言模型
llm = ChatOpenAI(model="gpt-3.5-turbo-16k")
# 3.输出解析器
parser = StrOutputParser()
# 4.编排链:RunnablePassthrough.assign写法
chain = RunnablePassthrough.assign(context=lambda x: retrieval(x["query"])) | prompt | llm | parser
# 5.调用链
content = chain.invoke({ "query": "你好,我是谁?"})
print(content)利用回调功能调试链应用-让过程更透明
Callback功能介绍
LangChain Callback 回调机制
Callback 是 LangChain 提供的回调机制,允许我们在 LLM 应用程序的各个阶段使用 hook(钩子)。钩子的含义也非常简单,我们把应用程序看成一个一个的处理逻辑,从开始到结束,钩子就是在事件传送到终点前截获并监控事件的传输。
Callback 对于记录日志、监控、流式传输等任务非常有用,简单理解,callback 就是记录整个流程的运行情况的一个组件,在每个关键的节点记录响应的信息以便跟踪整个应用的运行情况。
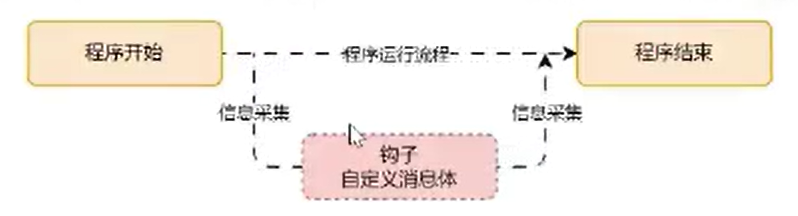
例如:
- 在 Agent 模块中调用了几次 tool,每次的返回值是什么?
- 在 LLM 模块的执行输出是什么样的,是否有报错?
- 在 OutputParser 模块的输出解析是什么样的,重试了几次?
Callback 收集到的信息可以直接输出到控制台,也可以输出到文件,更可以输入到第三方应用,相当于独立的日志管理系统,通过这些日志就可以分析应用的运行情况,统计异常率,运行的瓶颈模块以便优化。
在 LangChain 中,callback 模块中具体实现包括两大功能,对应 CallbackHandler 和 CallbackManager:
- CallbackHandler:对每个应用场景比如 Agent 或 Chain 或 Tool 的记录。
- CallbackManager:对所有 CallbackHandler 的封装和管理,包括了单个场景的 Handle,也包括运行时整条链路的 Handle。
不过在 LangChain 的底层,这些任务的执行逻辑由回调处理器(callbackHandler)定义。
CallbackHandler 里的各个钩子函数的触发时间如下:
CallbackHandler 钩子函数触发时机
| 事件 | 事件触发 | 相关方法 |
|---|---|---|
| Chat Model start | 当聊天模型启动时 | on_chat_model_start |
| LLM start | 当大语言模型启动时 | on_llm_start |
| LLM new token | 当聊天模型或大语言模型生成新 token 时 | on_llm_new_token |
| LLM end | 当聊天模型或大语言模型结束时 | on_llm_end |
| LLM error | 当聊天模型或大语言模型发生错误时 | on_llm_error |
| Chain start | 当链开始运行时 | on_chain_start |
| Chain end | 当链结束时 | on_chain_end |
| Chain error | 当链发生错误时 | on_chain_error |
| Tool start | 当工具开始运行时 | on_tool_start |
| Tool end | 当工具结束时 | on_tool_end |
| Tool error | 当工具发生错误时 | on_tool_error |
| Agent action | 当智能体执行动作时 | on_agent_action |
| Agent finish | 当智能体结束时 | on_agent_finish |
| Retriever start | 当检索工具开始运行时 | on_retriever_start |
| Retriever end | 当检索工具结束时 | on_retriever_end |
| Retriever error | 当检索工具发生错误时 | on_retriever_error |
| Text | 运行任意文本时,该接口可以在自定的 Chain、Agent、Tool 上调用该接口。使用该接口增加了灵活性和可扩展性 | on_text |
| Retry | 当重试事件时 | on_retry |
在 LangChain 中使用回调,使用 CallbackHandler 有以下几种方式:
- 在运行
invoke时传递对应的config信息配置callbacks(推荐)。 - 在
Chain上调用with_config函数,传递对应的config并配置callbacks(推荐)。 - 在构建大语言模型时,传递
callbacks参数(不推荐)。
在 LangChain 中提供了两个最基础的 CallbackHandler,分别是:StdoutCallbackHandler 和 FileCallbackHandler。
使用实例如下:
python
from typing import Dict, Any, List, Optional, Union
from uuid import UUID
import dotenv
from langchain_core.messages import BaseMessage
from langchain_core.output_parsers import StrOutputParser
from langchain_core.outputs import GenerationChunk, ChatGenerationChunk
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import ChatOpenAI
from langchain_core.callbacks import StdOutCallbackHandler, BaseCallbackHandler
dotenv.load_dotenv()
# 1. 编排prompt
prompt = ChatPromptTemplate.from_template("{query}")
# 2. 创建大语言模型
llm = ChatOpenAI(model="gpt-3.5-turbo-16k")
# 3. 构建链
chain = { "query": RunnablePassthrough() } | prompt | llm | StrOutputParser()
# 4.调用链并执行
resp = chain.stream(
"你好,你是?",
config ={"callbacks": [StdOutCallbackHandler()]}
)
for chunk in resp:
pass自定义回调
在LangChain中,箱创建自定义回调处理器,只需继承BaseCallbackHandler并实现内部的部分接口即可,列如:
python
from langchain_core.callbacks import StdoutCallbackHandler, BaseCallbackHandler
from typing import Dict, Any, List, Optional, Union
from uuid import UUID
from langchain_core.messages import GenerationChunk, ChatGenerationChunk
class LLMOpsCallbackHandler(BaseCallbackHandler):
"""自定义LLMOps回调处理器"""
def on_llm_start(
self,
serialized: Dict[str, Any],
prompts: List[str],
*,
run_id: UUID,
parent_run_id: Optional[UUID] = None,
tags: Optional[List[str]] = None,
metadata: Optional[Dict[str, Any]] = None,
**kwargs: Any,
) -> Any:
print("on_llm_start serialized:", serialized)
print("on_llm_start prompts:", prompts)
def on_llm_new_token(
self,
token: str,
*,
chunk: Optional[Union[GenerationChunk, ChatGenerationChunk]] = None,
run_id: UUID,
parent_run_id: Optional[UUID] = None,
**kwargs: Any,
) -> Any:
print("on_llm_new_token:", token)