参数是什么?------从原理到实战,一篇讲透
作者 :Weisian
发布时间:2026年4月

直击痛点:
"面试官:'7B、70B 里的参数到底是什么意思?'你:'就是模型里的数字......'面试官:'那为什么参数量越大模型越聪明?70B 一定比 7B 好吗?'你:'呃......不一定吧......'"------这是大模型面试中的经典"翻车现场":听说过"参数"这个词,但说不清参数是什么、为什么重要、怎么调优。
在大模型时代,参数是最核心却又最容易被混淆的概念之一:
- 初学者:把参数和算力画等号,以为参数越多越好;
- 算法工程师:不清楚不同参数的作用,微调时无从下手;
- 产品经理:不理解参数对模型性能、部署成本的影响,选型踩坑;
- 面试者:背了"参数是权重"的定义,却讲不清原理和实际价值,错失高薪机会。
解决方案 :本文将从生活类比出发,深入浅出地讲解参数的本质、三大类型、规模与能力的关系、推理参数的调优技巧,并提供基于本地 Ollama + Qwen2.5 的完整可运行代码。
📌 核心一句话:大模型的参数,本质是模型从海量数据中"学来的经验",是存储语义规则、逻辑关联的"记忆单元",相当于模型的"大脑神经元连接"------参数越多,模型能记住的"经验"越细致,理解和生成能力越强(但不是绝对)。
📌 面试金句先记牢(全文精华速览):
- 参数定义:训练中学习到的可调整权重和偏置,是模型理解和推理的核心依据。
- 参数 vs 神经元:神经元是容器,参数是容器里的内容。
- 三大参数类型:模型参数(权重/偏置)、超参数(训练配置)、推理参数(生成配置)。
- 规模跃迁:B=Billion(十亿),1B以下像小学生,7B-13B像大学生,70B+像研究生。
- 参数越多越好? 不是,需匹配数据量与算力,否则过拟合且成本飙升。
- Scaling Law:性能随参数量、数据量、计算量幂律增长,但边际效应递减。
- 推理参数:温度(随机性)、Top-p(多样性)、Top-k(候选集)、重复惩罚(流畅性)。
- 微调与参数:微调是调整部分参数(如LoRA),让模型适配特定任务。
- 本地部署与参数:参数规模决定显存,7B模型需10-15GB,13B需20-30GB(量化后可减半)。
- 优化技巧:量化(INT4/INT8)、剪枝,降低部署成本。
- 参数量≠智能:数据质量和训练方法同样关键,70B不一定比7B更适合你的任务。
一、参数的本质:从"数字大脑"到"生活类比"
1.1 一句话定义
大模型的参数,是模型在训练过程中从海量文本数据中学习到的"经验值",本质是神经网络中神经元之间的连接权重(Weight)和偏置(Bias),是模型"理解"语言、完成推理的核心依据。

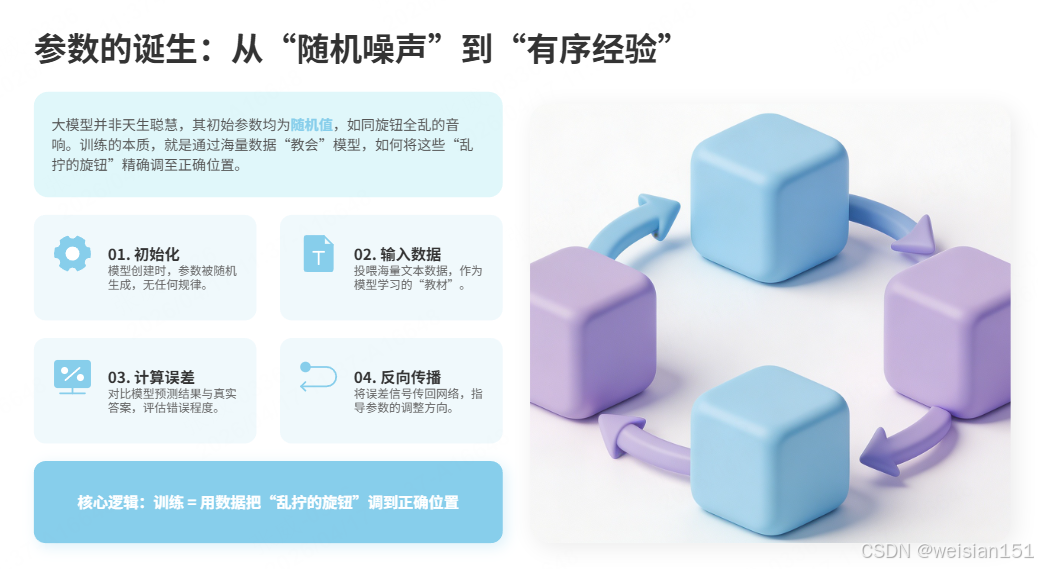
1.2 参数的诞生:从"随机噪声"到"有序经验"(训练过程)
大模型不是天生聪明的。它的参数一开始是随机值,就像一台所有旋钮都乱拧的音响。训练的过程,就是通过海量数据"教会"模型如何拧对每一个旋钮。
参数产生的五步循环:
- 初始化:模型创建时,参数随机生成,此时模型什么都不会。
- 输入数据:给模型输入海量文本,让模型尝试预测"下一个词"。
- 计算误差:将模型预测的结果和真实结果对比,计算"误差"(损失函数)。
- 反向传播:将误差从输出层往回传,告诉每个参数"你该往哪边拧"以减少误差。
- 更新参数:所有参数根据指令微调一点点。重复步骤2-5,直到误差足够小。
流程图解:
初始状态:所有参数随机(乱拧的音响)
│
▼
喂数据:"猫"这个字的向量应该是什么?
│
▼
模型预测:猜一个答案
│
▼
计算误差:猜错了多少?(损失函数)
│
▼
反向传播:误差往回传,告诉每个参数"你该往哪边拧"
│
▼
更新参数:所有参数微调一点点
│
▼
重复......直到误差足够小简单说:训练 = 用数据把"乱拧的旋钮"调到正确位置。
生活类比:模型就像一个刚出生的孩子,参数就是它通过"读书(学习数据)"记住的"知识点"和"逻辑规则"------比如"太阳从东方升起""下雨需要带伞",这些规则被转化为数字(参数),存储在模型的"大脑"(神经网络)中。
1.3 核心误区:参数存储的是"规则",不是"数据"
很多人误以为大模型的参数直接存储了训练数据,这是完全错误的。
核心真相 :参数不存储任何原始数据,只存储"数据中的逻辑规则和语义关联"。
例如,模型看过数百万句包含"你好"的对话,它不会记住这些句子,而是通过参数学习到"你好"是一种问候语,通常用于对话开头------这些"规则"被转化为数字(参数)存储。

1.4 7B、70B 里的"B"是什么?参数如何组成?
B = Billion(十亿)。
- 7B = 70 亿个参数
- 70B = 700 亿个参数
- 175B = 1750 亿个参数(GPT-3 的规模)
这些数字描述的是:模型里一共有多少个可学习权重。

二、参数的分类:业界最合理的"三层体系"
为了彻底理清概念,我们将参数分为三层 :模型参数(核心) 、超参数(训练配置) 、推理参数(生成配置)。面试中90%的混淆都源于没分清这三层。
2.1 第一层:模型参数(核心:可学习参数)------权重(Weight)和偏置(Bias)
这是常说的"7B、13B"所指的参数,占比99%以上,是模型真正"学到"的知识。训练后固定,决定模型能力上限。
| 类型 | 本质 | 作用 | 生活类比 |
|---|---|---|---|
| 权重 | 神经元间的连接强度,数字越大,两个神经元关联越强 | 决定一个输入对输出的影响有多大 | 你和家人的熟悉程度(权重)很高,和陌生人很低 |
| 偏置 | 神经元的激活阈值,决定神经元是否被激活 | 让神经元即使输入较弱也能"激活" | 闹钟的叫醒时间,到点就响(激活),不到不响。 |

深度解析:Embedding(嵌入参数)------一切的开端
在模型内部,每个词(Token)都被表示为一个长长的数字列表,这就是Embedding。例如,在 Qwen2.5 中,每个词的 Embedding 是一个 4,096 维的向量。
"国王" 的 Embedding ≈ [0.12, -0.34, 0.56, ..., 0.78] (共4096个数字)
"王后" 的 Embedding ≈ [0.11, -0.33, 0.55, ..., 0.79] (非常接近!)
"苹果" 的 Embedding ≈ [0.89, 0.12, -0.45, ..., 0.01] (完全不同!)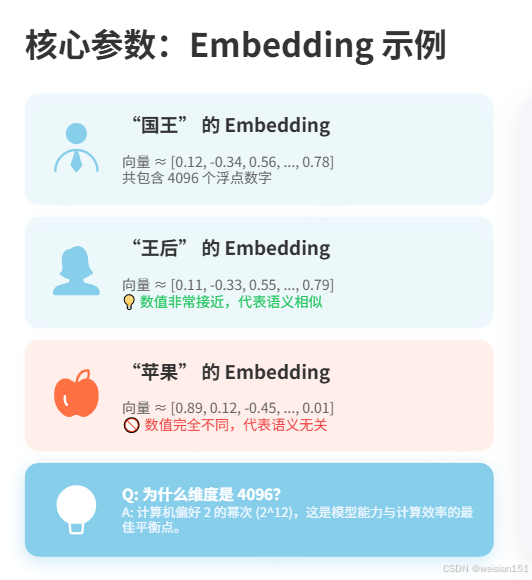
权重 vs 偏置:一个形象的比喻:
想象你在嘈杂的房间里听人说话。权重 就像音量旋钮------把说话声音大的调得更高,声音小的压得更低。偏置则像一个"助听器增益"按钮------即使某人说话声音小,你也可以整体抬高音量,让他的声音能被听见。两者配合,才能把信息从噪声中提取出来。
特点:
- 数量庞大,训练时自动调整,决定模型能力上限。
- 训练完成后固定,不可手动修改。
为什么 Embedding 维度是 4096?
因为计算机喜欢 2 的幂次(2、4、8、16、32......),而 4096 是 2^12。研究发现,这个维度恰好是能力与效率的平衡点:维度太少,无法捕捉语义的细微差别;维度太多,计算成本爆炸。
2.2 第二层:超参数(训练配置)------人工预设的"学习规则"
超参数是训练前人工设定的规则,不参与反向传播更新,但决定训练效率和泛化能力。
| 超参数 | 作用 | 生活类比 |
|---|---|---|
| 学习率(Learning Rate) | 每次参数调整的步长,太大不稳定,太小收敛慢 | 走路步长 |
| 批次大小(Batch Size) | 每次输入模型的样本数量 | 一次吃多少饭 |
| 迭代次数 (Epochs) | 整个数据集被完整训练的次数 | 复习遍数 |
| Dropout率 | 训练时随机关闭部分神经元,防止过拟合 | 考试时不允许查资料 |
训练超参数 = 学习方法与节奏,决定学得快不快、稳不稳。

2.3 第三层:推理参数(生成配置)------控制"怎么说话"的旋钮
这是调用模型时调节的参数,不改变模型的知识 ,只控制输出风格。面试中出现频率最高。
| 推理参数 | 作用 | 生活类比 | Ollama 参数名 |
|---|---|---|---|
| 温度 | 控制输出随机性,越低越确定 | 骰子的权重 | temperature |
| Top-p | 动态选择累积概率达p的词集 | 从最有可能的前几个答案里选 | top_p |
| Top-k | 只考虑概率最高的k个词 | 只考虑前三名候选人 | top_k |
| 重复惩罚 | 降低已出现词的重复概率 | 防止一个人一直说话 | repeat_penalty |
| 最大输出Token | 限制输出长度 | 说话字数限制 | num_predict |
这部分是工程调优、产品效果、面试问答的重中之重。

三、参数规模与智能水平:越大就一定越聪明吗?
3.1 规模跃迁:从"小学生"到"研究生"
核心答案:参数规模与模型能力不是线性关系,而是存在**"跃迁点"**。每跨过一个规模门槛,模型会"顿悟"出新的能力。
| 参数规模 | 能力表现 | 类比 | 代表模型 |
|---|---|---|---|
| 100M - 1B | 基础理解、简单语义 | 小学生 | BERT-base (110M) |
| 1B - 7B | 开始有推理能力、能总结 | 高中生 | GPT-2 1.5B |
| 7B - 13B | 逻辑推理、创作、代码生成 | 大学生 | LLaMA-7B、Qwen-7B |
| 30B - 70B | 系统性思考、跨领域推断 | 研究生 | LLaMA-65B、Qwen-72B |
| 100B+ | "世界模型"、抽象推理 | 专家 | GPT-3 175B |
生活类比 :就像学数学。加减乘除(小模型)谁都会,但到了微积分(大模型),只有经过系统训练的人才能理解。不是"多学一点点"就能从算术跳到微积分,而是需要质的飞跃。

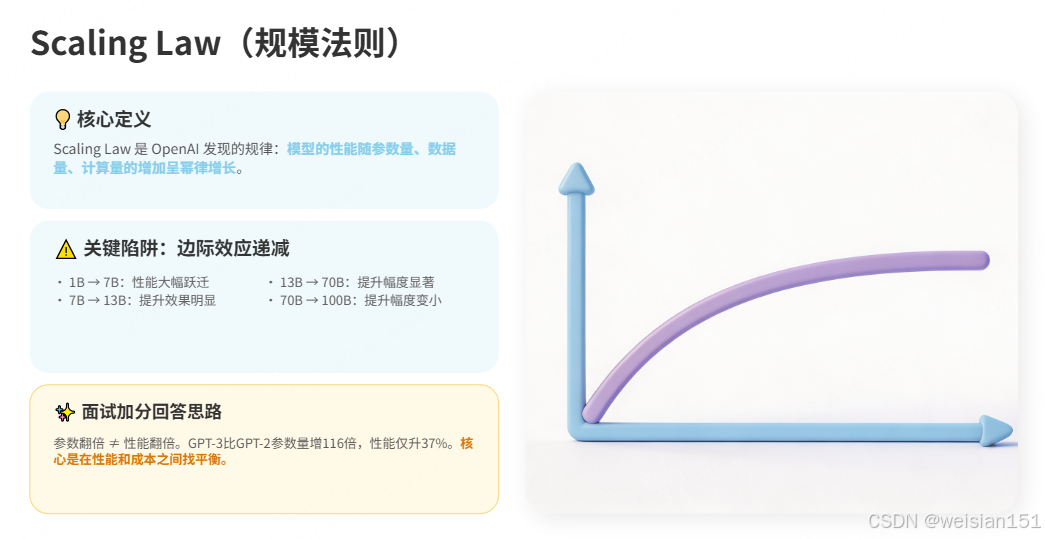
3.2 Scaling Law(规模法则):规模越大,性能越强?
Scaling Law 是 OpenAI 在 2020 年发现的规律:模型的性能随着参数量、数据量、计算量的增加而幂律增长。
关键陷阱 :性能提升是幂律,不是线性的,边际效应递减。
- 从 1B → 7B:性能大幅提升(跃迁)
- 从 7B → 13B:性能提升明显
- 从 13B → 70B:性能提升显著
- 从 70B → 100B:提升幅度变小
面试加分回答:
"Scaling Law 告诉我们,参数量翻倍并不会让性能翻倍。GPT-3(175B)相比 GPT-2(1.5B)参数增加了 116 倍,但性能只提升了约 37%。所以不是参数越大越好,而是要在性能和成本之间找平衡。"
3.3 为什么参数量大会变聪明?------"世界模型"的涌现
当参数足够多时,模型会自发学会一种叫 "世界模型" 的能力。它不是死记硬背,而是理解世界如何运作。
小模型(1B)的思维方式:
问:"为什么天空是蓝色的?"
想:"蓝色"和"天空"经常一起出现 → "因为天空是蓝色的"
答:"因为天空是蓝色的。"(循环论证)大模型(70B)的思维方式:
问:"为什么天空是蓝色的?"
想:光 → 散射 → 波长 → 瑞利散射 → 蓝光波长短 → 被散射得更强
答:"蓝光的波长更短,会在大气分子中发生瑞利散射,因此蓝色被各方向扩散,所以人眼看到的是蓝色。"为什么大模型能学会这些?
参数足够多,意味着模型有足够的"存储空间"来存放:
- 因果关系链:A 导致 B,B 导致 C
- 抽象概念映射:"快乐"≈"高兴"≈"愉悦"
- 推理模式:如果-那么、因为-所以
3.4 三个必须知道的"坑":参数不是万能的
| 问题 | 说明 | 示例 |
|---|---|---|
| 训练成本爆炸 | 参数量增加,训练成本指数级增长 | GPT-3 训练成本约 1200 万美元 |
| 推理成本飙升 | 70B 模型需要多块 A100,7B 单卡就能跑 | 推理延迟差 10 倍以上 |
| 数据和训练方法更关键 | 参数只是"容器",喂什么数据更重要 | LLaMA-13B 在很多任务上超越了 GPT-3 175B,因为用了更高质量的数据 |
面试金句:
"参数量决定模型'能不能学会',数据决定模型'学到的是什么东西',训练策略决定模型'能不能真正理解'。"
四、参数的实际影响:性能、成本、速度

4.1 性能:参数决定能力上限
参数越多:
- 理解越深刻(长文本、隐晦语义);
- 推理越强(数学、代码、多步逻辑);
- 生成越稳定、结构化越好。
4.2 部署成本:参数越多越贵
参数越大,显存占用越高,成本越高。
- 7B:个人显卡可跑
- 13B:中高端显卡
- 70B:专业卡/A100/多卡
4.3 推理速度:参数越大越慢
同算力下,参数翻倍,速度下降约50%~70%。
实时交互(客服、对话)优先用7B。
五、参数与工程落地:显存、速度与优化

参数与显存的换算公式(面试高频)
面试高频题:"7B 模型需要多大显存?"
计算公式:
显存 ≈ 参数量 × 每个参数占用的字节数 × 1.2(额外开销系数)不同精度下的显存占用(以7B模型为例):
| 精度 | 每参数占用 | 7B 模型理论显存 | 实际推理显存(含开销) |
|---|---|---|---|
| FP32 | 4 字节 | ~28 GB | ~34 GB |
| FP16 | 2 字节 | ~14 GB | ~17 GB |
| INT8 | 1 字节 | ~7 GB | ~8.5 GB |
| INT4 | 0.5 字节 | ~3.5 GB | ~4.2 GB |
推理时的额外开销:
- KV Cache:约 1-2 GB(取决于序列长度)
- 激活值:约 0.5-1 GB
- 实际需要 ≈ 参数量显存 × 1.2
快速估算:
7B 模型 INT8 量化 → 约 8-10 GB 显存(RTX 3080/4070 可以)
7B 模型 FP16 → 约 14-16 GB 显存(RTX 4090 可以)
70B 模型 INT4 量化 → 约 40-45 GB 显存(需要 A100 或双卡)快速选型建议
- 8G 显存:7B INT4
- 12G 显存:7B INT8
- 24G 显存:13B INT8 / 7B FP16
- 40G+ 显存:70B INT4
六、参数优化:在性能与成本间找平衡
6.1 量化(最常用)
把高精度参数(FP16)压缩为低精度(INT8/INT4),牺牲少量性能,大幅降低显存。
| 精度 | 压缩比 | 性能损失 | 适用 |
|---|---|---|---|
| FP16 | 1:1 | 0% | 极致性能 |
| INT8 | 1:2 | 5% | 均衡 |
| INT4 | 1:4 | 10~15% | 成本优先 |
说明:如将FP16转为INT8,显存减半,性能仅降低5%左右,性价比非常高。
Ollama量化模型:
bash
ollama pull qwen2_5-7b:q4_0
ollama pull qwen2_5-7b:q8_0
6.2 剪枝
删掉权重极小、几乎无用的参数,减小模型体积。
类比:整理房间,扔掉没用的东西。
6.3 LoRA(微调必用)
只训练少量额外参数 (适配器),不动主模型,节省显存+训练快。
全量微调 :更新全部参数,效果好但成本极高。
LoRA (Low-Rank Adaptation):仅训练少量额外的低秩矩阵(<1%参数),省显存、速度快,是当前主流方案。
七、微调与参数:如何"定制"模型?
7.1 预训练 vs 微调:知识 vs 行为
面试常考:"预训练和微调有什么区别?"
核心答案:
- 预训练 :在海量数据上学习"世界知识",注入的是知识
- 微调 :在特定数据上学习"行为模式",注入的是行为
生活类比:
预训练就像一个人读了 12 年书(积累知识),微调就像入职培训(学会怎么干活)。一个人知识再多,不培训也不会按公司规范做事;反之,培训不能替代知识积累。

7.2 全参数微调 vs 参数高效微调(PEFT)
| 方式 | 原理 | 更新参数比例 | 显存需求 | 适用场景 |
|---|---|---|---|---|
| 全参数微调 | 更新所有参数 | 100% | 极大(3倍模型显存) | 大公司、领域大改 |
| LoRA | 插入低秩矩阵 | <1% | 较小(+5-10%) | 大多数场景 |
| QLoRA | LoRA + 量化 | <1% | 小(4-bit 量化) | 消费级显卡 |
| Adapter | 插入适配层 | 约3-5% | 较小 | 特定任务适配 |

为什么 LoRA 省显存?
- 全量微调:更新全部参数,效果好但成本极高。
- LoRA (Low-Rank Adaptation):仅训练少量额外的低秩矩阵(<1%参数),省显存、速度快,是当前主流方案。
LoRA 的核心思想:不直接更新大的权重矩阵 W,而是学习两个小矩阵 A 和 B,使得 W + B×A 近似等于更新后的权重。
原始权重 W: 4096 × 4096 ≈ 1600 万参数
LoRA 矩阵 A: 4096 × 8 ≈ 3.2 万参数
LoRA 矩阵 B: 8 × 4096 ≈ 3.2 万参数
总共约 6.4 万参数,只有原始权重的 0.4%!
7.3 实战:用 Ollama 进行 LoRA 微调
python
"""
使用 Ollama 进行 LoRA 微调的示例
注意:这需要准备训练数据,实际运行时间较长
"""
# 1. 准备训练数据(JSONL 格式)
# 示例数据:questions.jsonl
"""
{"instruction": "什么是机器学习?", "output": "机器学习是人工智能的一个分支,让计算机从数据中学习规律而不需要显式编程。"}
{"instruction": "解释什么是神经网络", "output": "神经网络是受生物神经元启发的计算模型,由多层节点组成,通过权重连接来学习数据模式。"}
"""
# 2. 创建 Modelfile
modelfile_content = """
FROM qwen2_5-7b-q6
# 设置推理参数
PARAMETER temperature 0.7
PARAMETER top_p 0.9
# 设置系统提示
SYSTEM 你是一个专业的技术助手,用中文回答问题。
# 微调数据路径(需要先准备数据)
TEMPLATE """{{ .System }}
用户:{{ .Prompt }}
助手:"""
"""
# 3. 使用 Ollama 命令行创建微调模型
# ollama create my-finetuned-model -f ./Modelfile
# 4. 使用微调后的模型
# ollama run my-finetuned-model "什么是机器学习?"
print("""
📚 LoRA 微调步骤概要:
1. 准备训练数据(JSONL 格式,每行一个问答对)
2. 创建 Modelfile 指定基础模型和参数
3. 运行: ollama create my-model -f ./Modelfile
4. 测试: ollama run my-model "你的问题"
⚠️ 注意:完整的 LoRA 微调需要使用 transformers + peft 库,
Ollama 主要支持模型导入和推理,训练建议使用:
- unsloth (高效微调)
- transformers + peft (标准方案)
- Axolotl (配置化微调)
""")八、推理参数:控制模型"怎么说话"的旋钮
除了模型内部的"可训练参数",我们在调用模型时还可以调节 "推理参数" (也叫超参数 Hyperparameters)。这些参数不改变模型的知识,但能控制模型的输出风格 。

8.1 温度(Temperature):创造力的调节器
温度参数 控制模型输出的随机性。它是面试中出现频率最高的推理参数。
数学原理:
原始分数 (logits): [2.0, 1.0, 0.0]
│
▼ 除以温度 T
T=0.5: [4.0, 2.0, 0.0] → softmax → [0.87, 0.12, 0.01] (非常确定)
T=1.0: [2.0, 1.0, 0.0] → softmax → [0.67, 0.24, 0.09] (正常)
T=2.0: [1.0, 0.5, 0.0] → softmax → [0.51, 0.31, 0.18] (更均匀)通俗解释:
- 低温度(0.1-0.4):模型"保守",总是选最可能的词 → 回答稳定、可预测
- 中温度(0.5-0.8):平衡创造性和确定性 → 适合大多数场景
- 高温度(0.9-1.5):模型"放飞自我",会选一些意想不到的词 → 适合创意写作
生活类比:
温度就像汽车的"驾驶模式"。低温 = 经济模式(省油、稳定);高温 = 运动模式(有劲、但费油)。

代码实战:
python
from langchain_ollama import ChatOllama
def demonstrate_temperature():
"""演示温度参数的效果"""
prompts = [
"未来的城市交通将会",
"给这个产品起一个创意名称:一款可以自动浇花的智能花盆",
]
temperatures = [0.2, 0.7, 1.2]
for prompt in prompts:
print(f"\n📝 提示词: {prompt}")
print("-" * 50)
for temp in temperatures:
llm = ChatOllama(
model="qwen2_5-7b-q6",
temperature=temp,
num_predict=100
)
response = llm.invoke(prompt)
print(f"\n🌡️ 温度 = {temp}:")
print(f" {response.content[:150]}...")
# demonstrate_temperature()预期效果:
🌡️ 温度 = 0.2:
未来的城市交通将会更加智能化、自动化和电动化。
🌡️ 温度 = 0.7:
未来的城市交通将会出现飞行汽车、地下真空管道和智能交通调度系统。
🌡️ 温度 = 1.2:
未来的城市交通将会由反重力悬浮车和量子传送网络主导,人们可以在城市间瞬间移动...8.2 Top-p(核采样):概率分布的智能裁剪
Top-p(也叫 Nucleus Sampling)通过设定一个概率累积阈值 p,只从累积概率达到 p 的最小 Token 集合中采样。
工作原理:
假设下一个词的候选及其概率:
"猫" 0.4 → 累积 0.4
"狗" 0.3 → 累积 0.7
"鸟" 0.2 → 累积 0.9
"鱼" 0.1 → 累积 1.0
设置 p=0.8 → 只保留"猫""狗""鸟"(累积到0.9,超过0.8)生活类比:
就像你只考虑"最有可能的前几名候选人"。p=0.9 意味着你考虑了累计占 90% 可能性的所有选项。
Top-p vs Top-k:
| 参数 | 原理 | 优点 | 缺点 |
|---|---|---|---|
| Top-k | 只考虑概率最高的 k 个 | 简单可控 | 固定数量可能不灵活 |
| Top-p | 考虑累积概率到 p 的所有 | 自适应 | 计算稍复杂 |

代码实战:
python
def demonstrate_top_p():
"""演示 Top-p 参数的效果"""
prompt = "写一个关于人工智能的短故事开头"
top_p_values = [0.3, 0.7, 0.95]
print(f"📝 提示词: {prompt}\n")
for top_p in top_p_values:
llm = ChatOllama(
model="qwen2_5-7b-q6",
temperature=0.8,
top_p=top_p,
num_predict=120
)
response = llm.invoke(prompt)
print(f"🎲 Top-p = {top_p}:")
print(f" {response.content[:100]}...\n")8.3 重复惩罚(Repetition Penalty):防止"复读机"
重复惩罚通过降低已出现 Token 的概率,防止模型陷入重复循环。
数学原理:
惩罚后的概率 = 原始概率 / (惩罚因子 ^ 出现次数)
出现1次 → 除以 1.1
出现2次 → 除以 1.21
出现3次 → 除以 1.33生活类比:
就像开会时,一个人发言次数越多,他下次发言的"权重"就越低------给其他人发言的机会。

代码对比:
python
def demonstrate_repetition_penalty():
"""演示重复惩罚的效果"""
prompt = "列举5个编程语言的名称"
print(f"📝 提示词: {prompt}\n")
# 无重复惩罚(默认)
llm_default = ChatOllama(
model="qwen2_5-7b-q6",
temperature=0.7,
repeat_penalty=1.0 # 无惩罚
)
# 高重复惩罚
llm_penalized = ChatOllama(
model="qwen2_5-7b-q6",
temperature=0.7,
repeat_penalty=1.2 # 适度惩罚
)
print("❌ 无重复惩罚 (penalty=1.0):")
print(f" {llm_default.invoke(prompt).content[:200]}\n")
print("✅ 有重复惩罚 (penalty=1.2):")
print(f" {llm_penalized.invoke(prompt).content[:200]}")8.4 推理参数速查表
| 参数 | 作用 | 低值效果 | 高值效果 | 推荐起始值 |
|---|---|---|---|---|
| temperature | 控制随机性 | 稳定、保守 | 创意、随机 | 0.7 |
| top_p | 控制候选集大小 | 保守、聚焦 | 多样、发散 | 0.9 |
| top_k | 限制候选数量 | 稳定但可能重复 | 多样但可能跑题 | 40-60 |
| repeat_penalty | 防止重复 | 可能复读 | 避免重复但可能怪异 | 1.1 |
| max_tokens | 限制输出长度 | 回答短 | 回答长 | 512-2048 |
场景推荐配置:
| 应用场景 | temperature | top_p | repeat_penalty |
|---|---|---|---|
| 事实问答 | 0.1-0.3 | 0.5-0.7 | 1.05 |
| 代码生成 | 0.2-0.4 | 0.8-0.9 | 1.1 |
| 客服对话 | 0.5-0.7 | 0.7-0.9 | 1.1 |
| 创意写作 | 0.8-1.2 | 0.9-0.95 | 1.15 |
| 头脑风暴 | 1.0-1.5 | 0.95-1.0 | 1.2 |

九、面试高频题详解(附参考答案)
Q1:什么是大模型的参数?7B 里的 B 是什么意思?
参考答案:参数是模型内部的可调节数值(权重和偏置),是模型存储知识和做出决策的基本单元。7B 里的 B 代表 Billion(十亿),所以 7B 就是 70 亿个参数。

Q2:参数量越大模型就越聪明吗?为什么?
参考答案:大体上是,但不是绝对的。根据 Scaling Law,参数量增加会带来性能幂律增长,但存在边际效应递减。更重要的是,参数量只是"容量",真正决定模型能力的是训练数据质量和训练策略。经典例子:LLaMA-13B 在很多任务上超越了参数量大 10 倍的 GPT-3 175B。

Q3:温度参数(Temperature)是什么?怎么用?
参考答案 :温度参数控制模型输出的随机性。原理是调整 softmax 函数的分布:低温度(<1)使概率分布更尖锐,输出稳定;高温度(>1)使分布更平滑,输出更有创造性。使用建议:事实问答用 0.1-0.3,代码生成用 0.2-0.4,创意写作用 0.8-1.2。

Q4:Top-p 和 Top-k 有什么区别?
参考答案 :两者都用于控制生成时的候选词范围。Top-k 固定选择概率最高的 k 个词,简单但不够灵活。Top-p (核采样)动态选择累积概率达到 p 的最小词集,能自适应分布情况。推荐:大多数场景用 Top-p,p 设为 0.9-0.95。

Q5:7B 模型需要多大显存?怎么估算?
参考答案 :公式:显存 ≈ 参数量 × 每参数字节数 × 1.2。7B 模型:FP16 约需 17GB,INT8 约需 8.5GB,INT4 约需 4.2GB。实际建议:消费级显卡(8-12GB)用 INT8 量化的 7B 模型;高端显卡(24GB)可跑 FP16 的 7B。

Q6:预训练和微调的区别是什么?
参考答案 :预训练 在大规模无标注数据上学习语言规律和世界知识,注入的是"知识";微调 在特定任务的标注数据上调整模型行为,注入的是"行为"。生活类比:预训练像大学教育(积累知识),微调像岗前培训(学习工作规范)。

Q7:LoRA 和全量微调有什么区别?
参考答案 :LoRA 只训练少量额外参数(低秩矩阵),显存占用小(+5-10%)、速度快、不会破坏原模型,是大多数场景的首选。全量微调更新所有参数,效果可能更好,但显存需求极大(约3倍模型显存),成本高昂。

总结
核心知识点速记口诀
参数是模型的小旋钮,权重偏置各有用。
7B 就是七十亿,规模越大越聪明。
但参数多不是万能,数据质量更关键。
推理参数调风格,温度高低控随机。
Top-p 裁剪候选词,重复惩罚防复读。
显存需求算清楚,量化压缩能省钱。
预训练学知识库,微调定制行为模。
面试把原理讲透,Offer 拿到手不慌。
选型决策树(实用建议)
- 个人学习/本地部署:7B + INT4 量化
- 企业客服/简单RAG:13B + INT8 量化
- 复杂推理/Agent:70B + 量化 + 多卡
- 成本极度敏感:7B + INT4 + 优质数据微调

写在最后
参数,是大模型的"记忆细胞"和"计算开关"。理解参数,你就理解了大模型为什么能"记住"那么多知识,为什么"越大越聪明",也知道了如何在成本和效果之间做权衡。
面试官问参数,不是在考"定义",而是在考察你的基础扎实程度 、对模型本质的理解 和工程化思维。
记住:能讲清楚参数的人,模型选型、成本估算、效果调优都不会差。
如果觉得有帮助,欢迎点赞、收藏、转发!有问题欢迎在评论区留言交流。