前置知识:
计算机中,位(bit)是存储数据的最小基本单位,只有0或1两种状态。
但在硬件上,位(bit)不是**最小的可寻址存储单元,**最小的可寻址、可读写的存储单元是一个字节(Byte),也就是8位。
一、整数
无符号整数(unsigned-integer,uint),所有位都用来表示数值。如uint8,其表示范围从0-255,即00000000~11111111,其中255等于2^7+2^6+...+2^0=128+64+...+1=255。同理,uint16,其表示范围从0-65535。
有符号整数 (signed-integer,int),最高位作为符号位(0代表正,1代表负)。如int8,表示范围从-128~127。int16,表示范围从-32768~32767.
对于无符号8位二进制数,
1 1 1 1 1 1 1 1
128 64 32 16 8 4 2 1
可以看到任意一个位置所代表具体数值,等于所有比它低的位所代表的数值之和再加1.
比如128=64+32+16+8+4+2+1**+1**
64 = 32+16+8+4+2+1**+1,** 8=4+2+1**+1**
而对于有符号8位二进制数,最高位代表正(0)负(1).
0 1 1 1 1 1 1 1
0 64 32 16 8 4 2 1
最高位为0,自然可表示的范围是0~127
那么负数怎么表示呢?如果和正数的表示一样,那理论上应该是0~ -127,而非-1~-128。
这就出问题了,0到底是正的还是负的呢?所以要搞懂负数在计算机中是怎么计算的。
1 1 1 1 1 1 1 1
128 64 32 16 8 4 2 1
对于一个负数-42,首先先得到其正数42(32+8+2)的二进制00101010,称为原码
然后对正数42的二进制进行按位取反 得到反码11010101(不考虑最高位,85=64+16+4+1) ,实际上原码和反码 加在一起就是8位全1的二级制11111111。换句话说,按位取反其实就是求差值,在不考虑最高位的情况下,反码与原码的和为127,127-42=85.
而前面我们说过,任意一个位置所代表具体数值,等于所有比它低的位所代表的数值之和再加1,这里的1就是我们说的补码。
即原码+反码+补码=128(这个128表示的低7位之和再加1,即01111111+00000001)
而当正数42取反后,最高位由0变成1,规定10000000为-128,
那么-128+反码+补码不就等于原码的值取负吗?事实也正是如此。
也就是说,得到42的原码00101010后,按位取反得到的反码11010101,反码的含义其实就是
-128+64+16+4+1=-43,然后再加一个补码00000001,得到-42。
所以-42的二进制表示是11010101+00000001=11010110,即-128+64+16+4+2=-42.
下面举几个例子:
-1,原码00000001,反码11111110,补码00000001,所以-1二进制为11111111,即-128+64+32+16+8+4+2+1= -1。这也恰好证明了我们说的任意一个位置所代表具体数值,等于所有比它低的位所代表的数值之和再加1。
-2,原码00000010,反码11111101,补码00000001,所以-2的二进制为11111110。
-3,原码00000011,反码11111100,补码00000001,所以-3的二进制位11111101.
-128,原码10000000,反码01111111,补码00000001,所以-128的二进制为10000000。
可以发现对于正数,数值增大二进制趋于全1;而对于负数,也符合数值增大趋于全1.
二、定点数和浮点数
整数讨论完了,那么小数呢?
对于一个8位二进制,如果小数点的位置定得靠前10.110011,那么表示的范围很小,但是精度很高。而如果小数点的位置定的靠后,101100.11,那么可表示的范围很大,但是精度很低。这种小数点固定的方式,称之为定点数。
其实不论小数点定在哪里,在当今计算动辄巨大的时代,定点数所表示的范围和精度,是远远不够的。就算小数点定在最后,最大范围也才到万级别,就算小数点定在最前,最大精度也只能保留小数点后8位。
于是,浮点数出来了,其本质是应用了科学计数法的思想。
对于10进制科学计数法,如1.325×10^(3),通过改变幂次数,实现了小数点的移动,故称为浮点数。这样可以表示的范围可就大多了,比如10^9就表示一亿;可表示的精度,也可以更高,比如10^(-9)。
在10进制中,小数点后一位表示0.1,即1/10;小数点后两位,表示0.01,即1/100;后三位,0.001,1/1000。也就是从万-千-十-个-十分之一-百分之一-千分之一,都在缩小10倍。
同样的,在二进制中,从16-8-4-2-1-1/2-1/4-1/8,换句话说,二进制的科学计数法,小数点后一位表示0.5,小数点后两位表示0.25,小数点后三位表示0.125。可以发现二进制的细粒程度比10进制要低。
二进制的科学计数法可以写成:1.125×2^(3),其编码可以是:
0 0 0 1 1 0 0 1
其中,最高位为符号位,接着后4位为指数(exponent)位(2+1=3),再接着后三位为小数位也称尾数(mantissa)(1/8=0.125)。
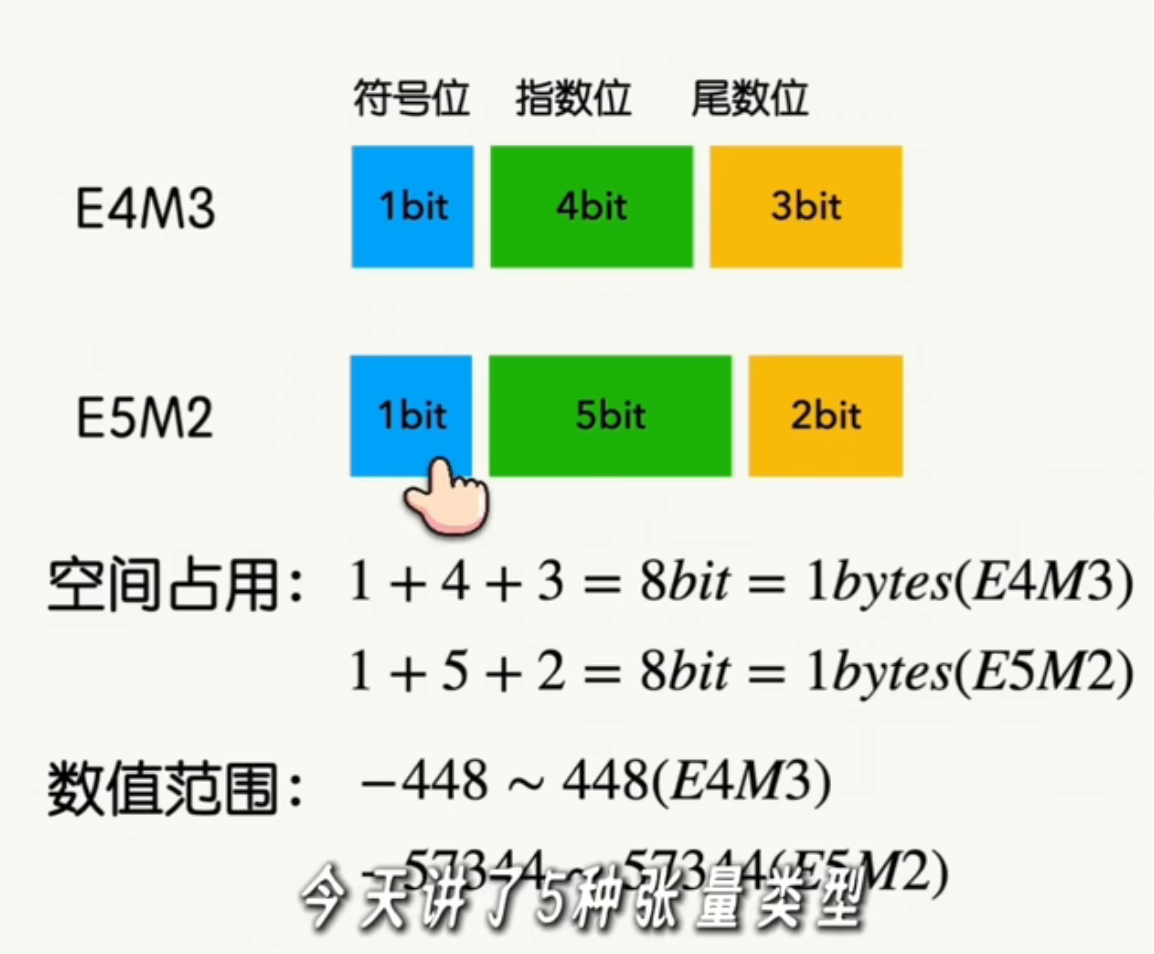
这就是8位浮点数 Float point ,简称FP8。而这种4位指数3位尾数,简称为E4M3 FP8,在范围和精度之间得到了很好的权衡。
如果想扩大范围,可以使用E5M2,即牺牲一点精度换取大范围。E4M3和E5M2都是英伟达GPU所支持的FP8格式,并在硬件上专门做了优化。
如果更极端一点,完全舍弃尾数,同时舍弃符号位,那么将得到无符号的8位浮点数,
即UE8M0 FP8
这种完全舍弃尾数,只保留指数部分,2^(x)的做法,相当于是对8位二进制数进行位移操作。
比如2^51是00110011,要变成2^25,只需向右平移1位变成00011001。
但在计算机中,最常用的还是FP32和FP64分别称为单精度和双精度浮点数。
FP32采用了1位符号8位指数和23位尾数;而FP64采用了1位符号11位指数52位尾数。
随深度学习的发展,又出现了FP16和BF16,分别是1+5+10和1+8+7。再进一步压缩就是FP8及其诞生的E4M3,E5M3和UE8M0。
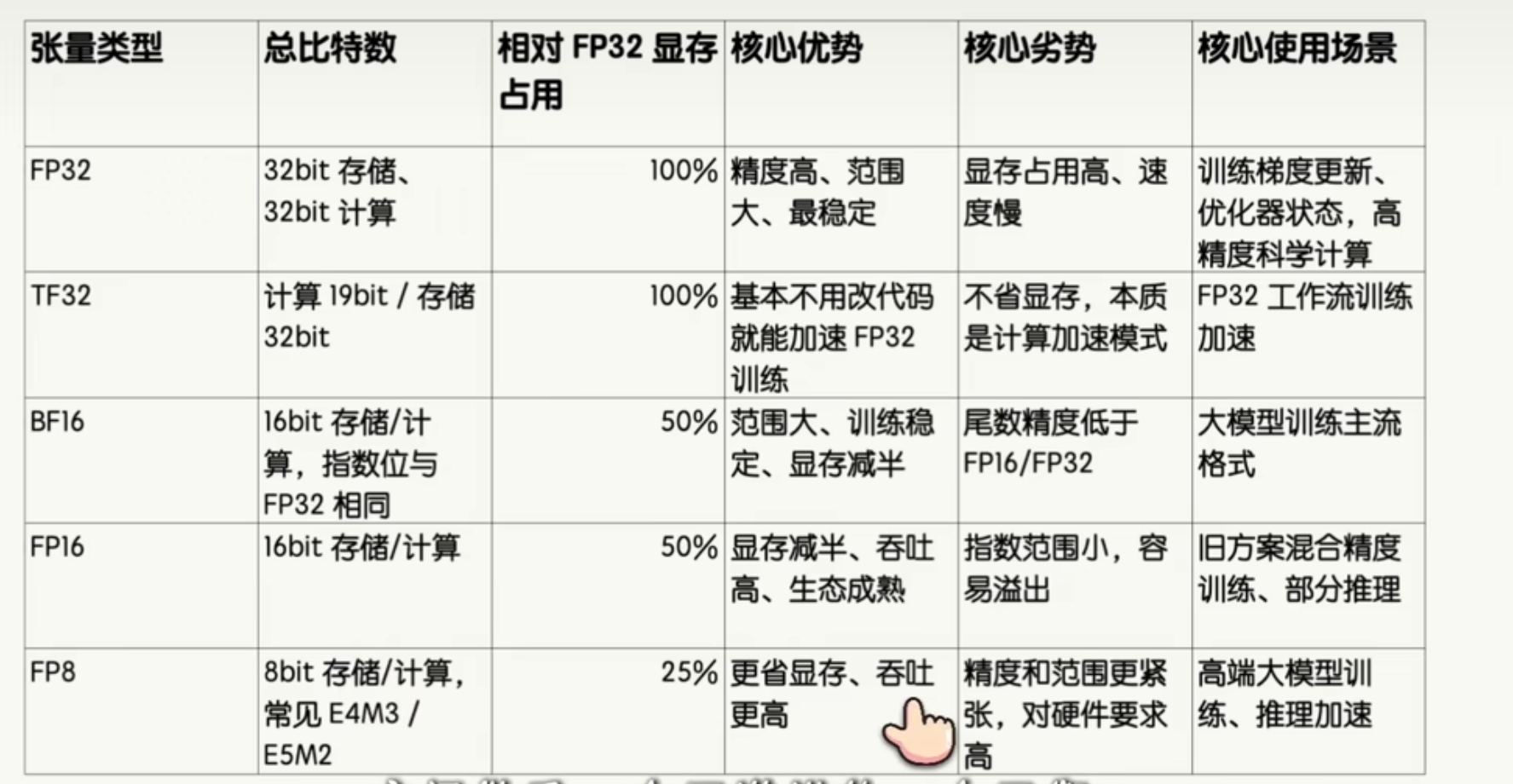
三、浮点数的显存占用对比
FP32

上图可以看到,对于7B(70亿)参数量的大模型,或者说模型权重参数有7B,仅加载就需要26GB的显存,个人笔记本GPU或者家用主机的GPU基本扛不住。
FP16

对于上图的FP16,很明显可以看到显存占用直接减少一半。但其指数位过少,表示的范围太小,大模型的梯度更新容易超出此范围,所以很少用了。
BF16

对于BF16,其指数位和FP32一样,可以取到较大范围,虽牺牲了尾数精度,但大模型对尾数精度不是很敏感,所以常常用来作为混合精度中的低精度代表。
(插一嘴,什么叫混合精度训练,就是大模型的某些参数对精度敏感,需要使用高精度格式来训练如FP32,而有些参数对精度不敏感,可以使用低精度训练,如BF16,这样可以加速训练)
在以上基础上,英伟达退出了TF32
TF32

注意TF32只有19位,在BF16的尾数上多加了3位,这是针对大模型专门定制的范围和精度的极致优化。
最后是FP8
总结