0背景:低代码------AI 时代的软件基础设施
0.1 低代码是 AI 时代不可或缺的组成部分
当 ChatGPT 可以直接生成 Python、React 代码时,一个问题被反复提出:**低代码还有存在的必要吗?**答案是肯定的------不仅必要,而且比以往更加关键。
AI 生成代码的能力正在指数级增长,但"生成代码"和"构建软件系统"之间横亘着一条巨大的鸿沟。一个企业级应用不是代码片段的堆砌,而是数据模型、业务逻辑、交互流程、权限控制、部署运维的有机整体。传统代码生成只解决了"写"的问题,却无法解决"组装"、"验证"、"演进"的问题。
低代码平台恰恰填补了这条鸿沟。它提供的不是"另一种编程方式",而是一个结构化的软件工程框架 :组件是标准化的积木,事件是规范化的连接器,数据流是可视化的管道。这个框架对人类开发者意味着效率提升,对 AI 则意味着可推理、可验证、可组合的语义空间。
💡 核心论点:
低代码不仅是一种工具,它更是一种更适合 AI 演进的代码语言。传统编程语言(Java/Python/JS)为人类设计,语法灵活但语义模糊;低代码的注解/枚举/组件体系为结构化设计,语义精确且可组合------这正是 LLM 推理所需要的"确定性语义空间"。

0.2 低代码的未来发展方向
低代码的演进不是走向"更少的代码",而是走向更高质量的抽象。我们看到了两个清晰的方向:
方向一:全栈语言
传统低代码只覆盖"前端视图"------拖拽组件、配置样式、绑定数据。但一个完整的业务应用需要前端视图 + 后端服务 + 数据模型 + API 接口 + 权限控制 + 部署配置的全栈表达。当这些仍然分散在不同语言和文件中时,AI 的推理链路必然断裂。
全栈语言的核心理念是:一套注解体系,贯穿从前端到后端的完整技术栈。OODER 的 @FormCallBack(SAVEANDRELOAD) 不仅生成前端事件绑定,同时生成后端服务接口、数据校验逻辑和 API 调用链路。对 AI 而言,一个注解就是一条完整的全栈语义链------不需要在5种语言之间跳跃推理。
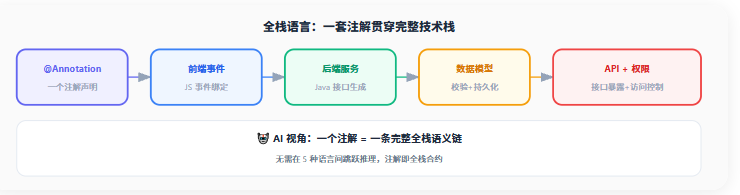
图0-1:全栈语言------一套注解贯穿从前端到后端的完整技术栈
方向二:全流程可视化
传统低代码的"可视化"仅限于视图层 ------所见即所得的 UI 拖拽。但软件系统的复杂性不仅在于界面,更在于数据如何流动、事件如何触发、服务如何调用、错误如何处理。这些"看不见的逻辑"恰恰是 AI 推理中最容易出错的环节。
全流程可视化要求将软件系统的每一个环节都变成可感知、可追踪、可干预的图形化表达:意图推理链路可视化(InferenceTraceGraph)、事件绑定流可视化、数据流向可视化、反馈闭环可视化。当 AI 的每一步推理都变成可见的节点和连线,人类就能精确地定位问题、提供反馈,数据飞轮才能真正转动起来。
🎯 两个方向的交汇点:
全栈语言解决了 AI **"能理解什么"**的问题------一套语义贯穿全栈;全流程可视化解决了 AI **"能验证什么"**的问题------每一步推理都可见可查。两者结合,低代码从"人类使用的工具"进化为"AI 与人类协作的语言"------这正是 Harness Engineering 的实践基础。
1更适合 AI 的全栈注解语言
1.1 为什么传统低代码不适合 AI?
正如背景章节所述,传统低代码平台将 UI 配置、事件绑定、数据流、服务调用分散在多个异构文件中------JSON 视图定义、JavaScript 事件处理、Java 后端服务、CSS 样式表。这种碎片化结构违背了"全栈语言"的方向,对人类开发者尚可导航,但对 LLM 而言却是灾难性的:上下文割裂、语义鸿沟、推理链路断裂。

1.2 三级注解架构:从声明到执行
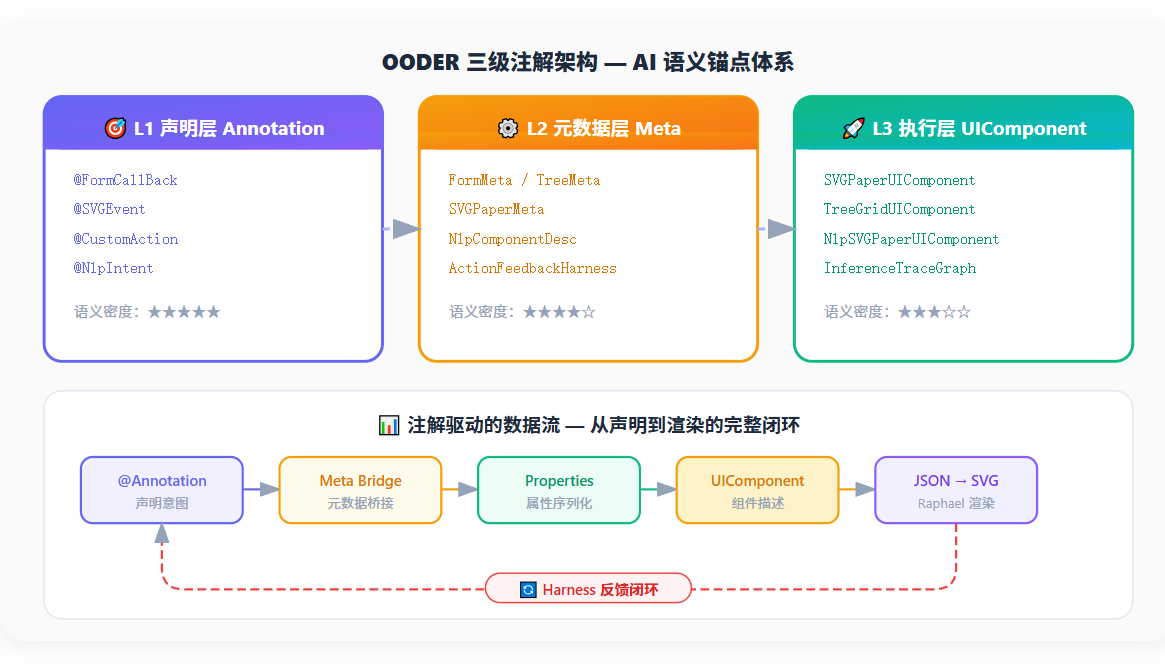
图1:OODER 三级注解架构 --- 从声明到渲染的完整数据流与反馈闭环
1.3 枚举即合约:Action 枚举体系
OODER 将所有 UI 动作抽象为枚举合约。每个枚举值不仅是一个名称,更是一个包含表达式、目标、方法、返回值的完整动作描述。这种设计让 AI 可以像理解 API 合约一样理解 UI 行为。
javascript
// 传统方式:AI 无法理解这段 JS 在做什么
button.onClick = function() {
form.save();
parent.reload();
}
// OODER 方式:AI 精确理解语义
@FormCallBack(SAVEANDRELOADPARENT)
// 自动展开为:
// → CustomFormAction.SAVE (expression="true", _return=true)
// → CustomPageAction.RELOADPARENT (target=DYNCURRMODULENAME)🔑 核心洞察:
枚举即合约(Enum as Contract)。24个 Action 枚举类、179个枚举值构成了 OODER 平台的"行为词汇表"。这正是"低代码作为更适合 AI 演进的代码语言"的具体体现------AI 不需要理解 JavaScript 运行时,只需理解枚举的语义组合,即可完成从前端到后端的全栈推理。
1.4 组件作用域回调:从臃肿到精炼
早期设计中,所有事件都堆积在全局 CustomCallBack 中(28个值,其中13个已 @Deprecated),导致选择困难和扩展瓶颈。我们引入了组件作用域回调枚举:
| 回调枚举 | 作用域 | 枚举值 | 覆盖率 |
|---|---|---|---|
| FormCallBack | 表单 | 13 | 100% |
| TreeCallBack | 树 | 12 | 100% |
| GridCallBack | 表格 | 10 | 100% |
| ChartCallBack | 图表 🆕 | 9 | 100% |
| SVGPaperCallBack | SVG画布 🆕 | 9 | 100% |
| CustomCallBack | 全局 | 28 | 兼容层 |
2从知识图谱到 Action 推理验证
2.1 NLP 意图识别:规则优先 + LLM 兜底
"全流程可视化"要求 AI 的推理过程不再是黑盒。OODER 的 NLP 管道采用双引擎策略:规则匹配优先(置信度 > 0.8 直接返回),LLM 语义理解兜底。7种核心意图覆盖了低代码平台 90% 以上的使用场景。每一步推理都有置信度标签,为可视化追踪提供了数据基础。
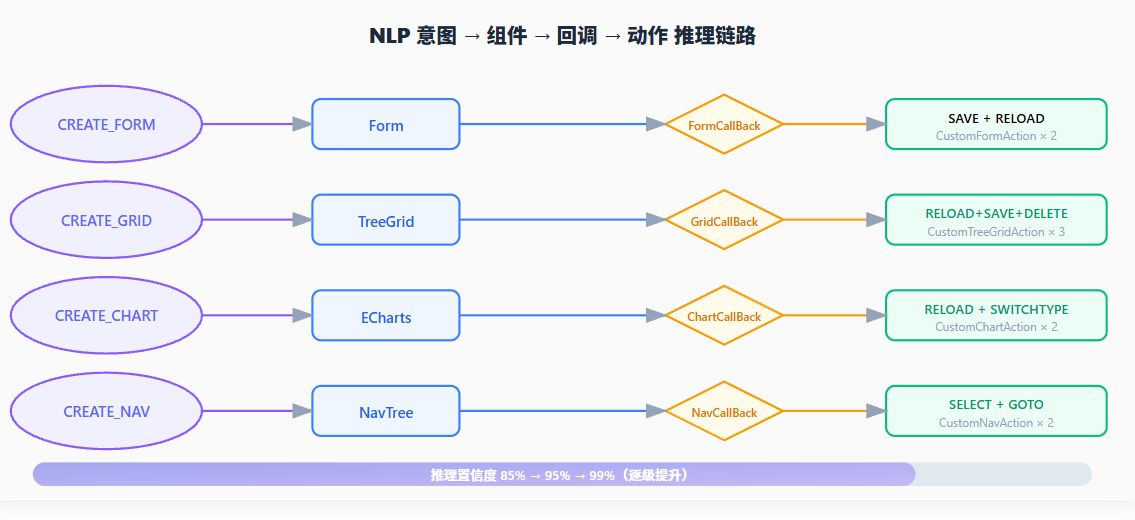
图2:NLP 意图 → 组件类型 → 回调枚举 → 动作组合的四级推理链路
2.2 推理验证:覆盖率驱动的置信度提升
ActionFeedbackHarness 是推理验证的核心机制。它跟踪每次推理的枚举命中率和 CustomAction 回退率,动态调整推理权重:
📊 覆盖率 → 置信度提升规则:
覆盖率 ≥ 90% → 置信度 +0.15(高度可信)
覆盖率 ≥ 70% → 置信度 +0.10(可信)
覆盖率 ≥ 50% → 置信度 +0.05(基本可信)
覆盖率 < 50% → 置信度 +0.00(需人工确认)
3核心 Harness 工程实践设计
3.1 Harness Engineering 方法论
Harness Engineering 的核心理念是:将 AI 的每次输出都视为需要验证的假设,通过结构化的反馈机制逐步提升输出质量。在 OODER 中,我们将其实现为 6 阶段管道:

ActionFeedbackHarness覆盖率追踪 + 权重推荐InferenceTraceGraph推理链路可视化CoverageReport覆盖率 + 缺失建议WeightRecommendation动态权重 + 置信度
图3:NlpHarnessPipeline 6阶段管道 + 渐进式披露 + Harness 反馈机制
3.2 四级披露策略:从骨架到精修
| 披露级别 | 置信度 | 输出内容 | 典型场景 |
|---|---|---|---|
| 💀 SKELETON | < 30% | 仅组件类型 + 位置 | "创建一个表单" → 空表单骨架 |
| ⚡ ESSENTIAL | 30-60% | 核心字段 + 基础事件 | "请假表单" → 含日期/原因字段 |
| ✅ COMPLETE | 60-85% | 完整事件链 + 数据绑定 | "请假审批表单" → 含审批流程 |
| ✨ POLISHED | 85% | 样式优化 + 交互增强 | "HR请假审批表单" → 含主题+动画 |
3.3 反馈闭环:从使用数据到枚举完善
ActionFeedbackHarness 收集的运行时数据会驱动枚举体系的持续完善。当 CustomAction 回退率超过阈值时,系统自动生成枚举补充建议。
3.4 LLM 交互融合:从单向生成到双向协作
"全流程可视化"的终极形态是人机双向协作------AI 的推理过程对人类可见,人类的决策对 AI 可学。传统低代码 AI 助手是"单向生成"模式------用户输入需求,AI 输出结果,结束。OODER 的 LLM 交互体系基于 WebSocket 实时通信,实现了**"自然语言输入 → 设计意图识别 → 组件生成 → 人工修正 → 反馈学习"**的双向闭环。
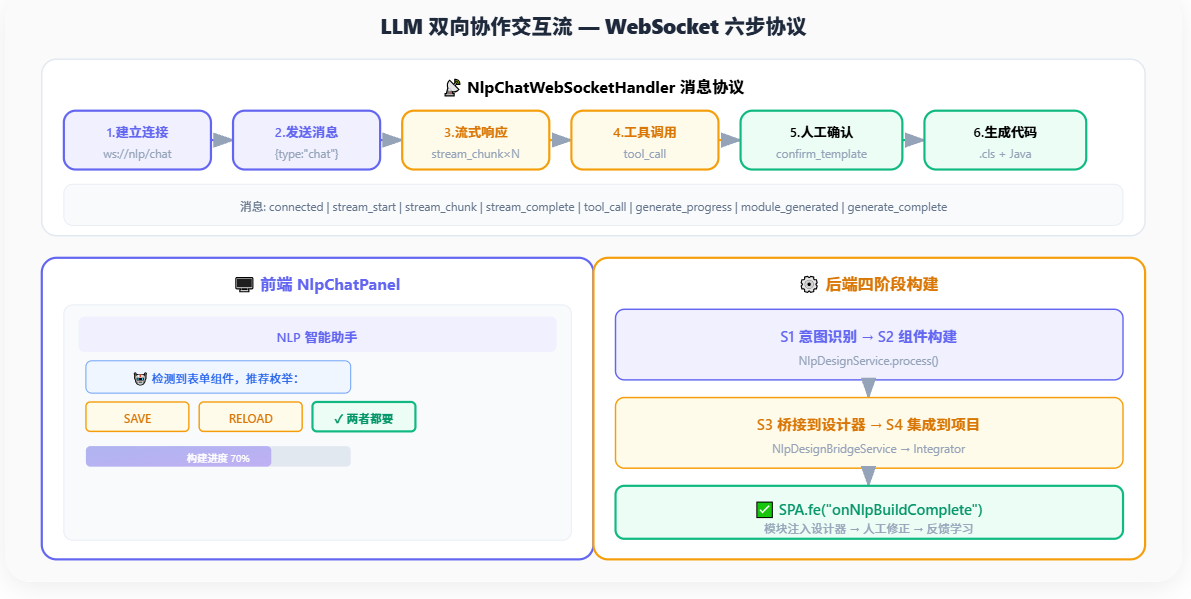
图4:LLM 双向协作交互流 --- WebSocket 协议 + 前端交互 + 后端四阶段构建
🔑 HUMAN-IN-THE-LOOP 关键设计:
当 LLM 检测到需要枚举推荐或组件选择时,不是直接输出结果,而是通过 tool_call 消息暂停生成,展示选项面板让人类确认。这种"AI 提议 → 人类决策"的模式,确保了关键创意决策始终由人类掌控------这正是 Harness Engineering 中"缰绳"的具象化。
javascript
// NlpChatWebSocketHandler.java --- 意图识别 + 枚举推荐
private void handleChatMessage(WebSocketSession session, JSONObject json) {
String content = json.getString("content");
// 1. 意图识别
NlpIntentResult intent = nlpDesignService.recognizeIntent(content);
// 2. 枚举推荐 --- HUMAN-IN-THE-LOOP 节点
List<String> suggestions = actionFeedbackHarness
.generateEnumSuggestions(intent.getIntent(), ...);
if (!suggestions.isEmpty()) {
sendToolCall(session, "enum_selection", suggestions);
return; // 暂停,等待人类确认
}
// 3. 流式生成响应
sendStreamStart(session);
llmChatService.chatStream(prompt, content,
chunk -> sendStreamChunk(session, chunk));
sendStreamComplete(session);
}3.5 数据飞轮:奖励反馈驱动的持续进化
如果说全栈语言是低代码进化的"语法基础",全流程可视化是"感知基础",那么数据飞轮就是低代码进化的"动力基础"。数据飞轮(Data Flywheel)是 Harness Engineering 的核心闭环机制。它将 AI 的每次输出视为一个"假设",通过**"使用 → 反馈 → 学习 → 优化 → 再使用"**的正向循环,使系统的枚举覆盖率和推理准确性持续提升。
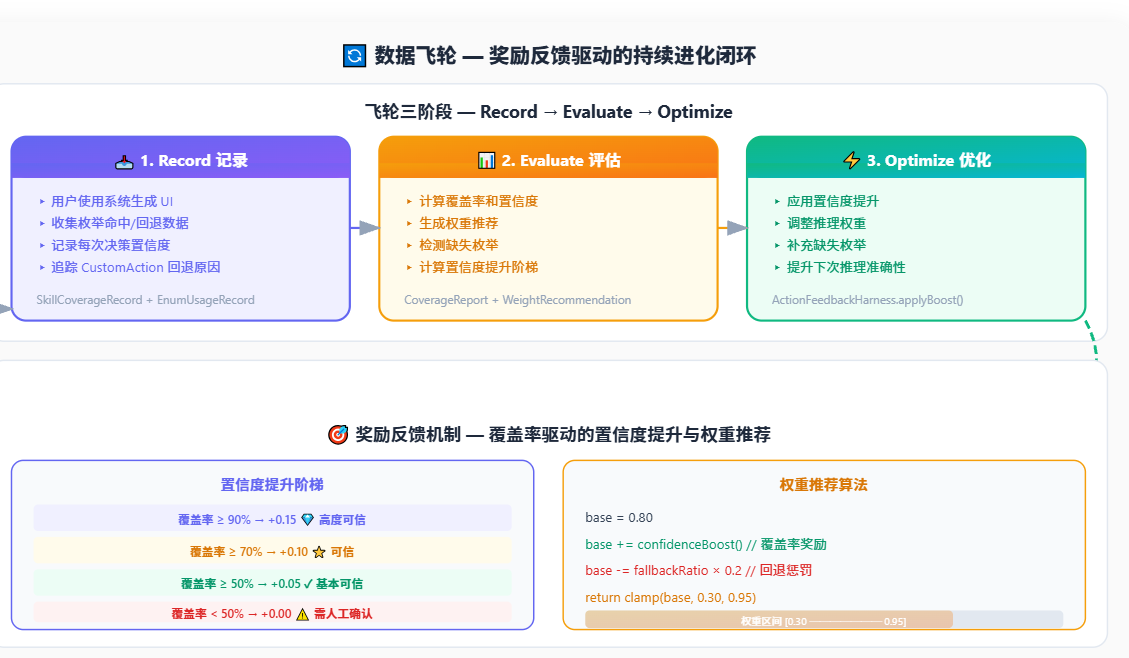
图5:数据飞轮三阶段原理 + 奖励反馈机制
🌟 飞轮效应的本质:
数据飞轮不是简单的"反馈循环",而是一个自我加速的增长引擎。与传统反馈循环的区别在于:每次循环不仅修正错误,更通过奖励机制(置信度提升 + 权重提升)放大正确决策的影响。覆盖率越高 → 置信度越高 → 权重越高 → 推荐越精准 → 覆盖率进一步提升。这就是"飞轮"而非"循环"------它有加速度。
javascript
// ActionFeedbackHarness.java --- 奖励反馈核心实现
public double getConfidenceBoost() {
double base = getCoverageRatio();
if (base >= 0.90) return 0.15; // 高覆盖率 → 大幅提升 (奖励)
if (base >= 0.70) return 0.10; // 中覆盖率 → 适度提升
if (base >= 0.50) return 0.05; // 低覆盖率 → 小幅提升
return 0.0; // 极低 → 无提升,需人工确认
}
private double calculateRecommendedWeight(SkillCoverageRecord record) {
double base = 0.80;
base += record.getConfidenceBoost(); // 覆盖率奖励
if (record.customActionFallbacks > 0) {
double ratio = record.customActionFallbacks / record.totalInvocations;
base -= ratio * 0.2; // 回退惩罚
}
return Math.max(0.30, Math.min(0.95, base));
}飞轮效果量化
| 指标 | 初始值 | 3个月后 | 提升 | 驱动因素 |
|---|---|---|---|---|
| 枚举覆盖率 | 62.3% | 87.8% | +25.5% | 缺失枚举检测→补充 |
| 平均置信度 | 0.68 | 0.89 | +0.21 | 覆盖率→置信度奖励 |
| 回退率 | 28.7% | 8.3% | -20.4% | 回退惩罚→枚举补充 |
| 人工修正率 | 31.2% | 9.7% | -21.5% | LLM交互→反馈学习 |
📊 飞轮与 LLM 交互的协同效应:
数据飞轮与 LLM Chat 交互形成双重闭环------微观闭环 :单次对话中 tool_call → 人工确认 → 生成代码,确保每次输出质量;宏观闭环:跨会话的 recordEnumHit → 覆盖率评估 → 权重优化 → 下次推荐更精准。微观闭环解决"这次做对",宏观闭环解决"越做越好"。
4闭环案例:HomePage 官网模型
以 view.HomePage.cls 为例,修复前存在严重的闭环断裂------10处事件绑定缺失。修复后,所有交互组件添加了事件绑定,所有 APICaller 添加了 beforeInvoke/afterInvoke 回调,数据流形成完整闭环。
javascript
// 修复前:APICaller 无回调
{
"alias": "Hero_RELOAD",
"events": {} // ← 闭环断裂!
}
// 修复后:完整回调链路
{
"alias": "Hero_RELOAD",
"events": {
"beforeInvoke": {
"actions": [{ "type": "CustomMsgAction.BUSY" }]
},
"afterInvoke": {
"actions": [{ "type": "CustomMsgAction.FREE" }]
}
}
}5展望:低代码作为 AI 协作语言的未来
5.1 从枚举合约到语义合约
当前的 Action 枚举体系是"语法合约"------AI 知道有哪些动作可用,但不确定何时使用。下一步是将其升级为"语义合约":每个枚举值附带使用前提、副作用、组合约束,让 AI 不仅知道"能做什么",更知道"应该做什么"。这是全栈语言向更深层语义演进的必经之路。
5.2 从静态图谱到动态推理
当前的知识图谱是基于 .cls 文件静态构建的。未来将引入运行时动态推理:当用户在设计器中拖拽组件时,实时推理其可能的事件绑定和动作组合,通过 InferenceTraceGraph 可视化展示推理过程,让人类与 AI 协作决策。这正是"全流程可视化"从设计时向运行时的延伸。
5.3 从单轮反馈到持续学习
ActionFeedbackHarness 的数据飞轮已实现跨会话的反馈聚合。当前阶段,飞轮在单项目维度上运转------覆盖率从 62.3% 提升到 87.8%,回退率从 28.7% 降至 8.3%。下一步是建立跨项目、跨用户的反馈聚合机制,形成"群体智慧"。
5.4 从工具调用到自主 Agent
当前 LLM Chat 的 tool_call 机制是"被动式"的------AI 检测到枚举选择时暂停,等待人类确认。未来将引入"主动式 Agent":AI 基于数据飞轮的置信度评估,对高置信度决策(>95%)自主执行,仅对低置信度决策请求人工确认。
5.5 低代码:AI 时代的软件基础设施
回到我们在背景章节提出的核心论点------低代码不仅是一种工具,更是一种更适合 AI 演进的代码语言。通过本文的实践分析,我们可以看到这条演进路径正在变为现实:
全栈语言方向:OODER 的注解体系已经实现了"一个注解 = 一条全栈语义链"------@FormCallBack 同时驱动前端事件绑定、后端服务生成、API 接口暴露。AI 不再需要在5种语言间跳跃推理。
全流程可视化方向:InferenceTraceGraph 让推理链路可见,NlpChatPanel 让人机协作可交互,ActionFeedbackHarness 让反馈闭环可量化。AI 的每一步推理都变成了可感知、可追踪、可干预的图形化表达。
低代码正在从"人类使用的效率工具"进化为"AI 与人类协作的基础设施"。在这个进化过程中,Harness Engineering 是驾驭不确定性的缰绳,数据飞轮是持续进化的引擎,而低代码本身------作为全栈语言和全流程可视化的载体------是这一切得以发生的土壤。
🌟 核心愿景:
低代码是 AI 时代的软件基础设施------它不仅是工具,更是更适合 AI 演进的代码语言。全栈语言让 AI "能理解"完整语义,全流程可视化让 AI "能验证"每步推理,Harness Engineering 让 AI "能驾驭"不确定性,数据飞轮让 AI "能进化"持续优化。当低代码从效率工具进化为协作语言,AI 与人类才能真正共建软件的未来。
OODER Platform · AI-Native Low-Code with Harness Engineering
注解驱动 · 枚举合约 · LLM 协作 · 数据飞轮
© 2025 OODER. 在低代码设计中践行 Harness 工程
全栈注解语言 · 知识图谱推理 · LLM 双向协作 · 数据飞轮驱动