前言
前段时间业务有个性能优化需求:需对2000 万条物料数据 做整体排序。起初采用单线程实现,执行效率极低,排查后发现CPU 多核利用率严重偏低。
这时我开始思考:如何才能真正压榨多核 CPU 的并行算力?
深入研究后,我选用 ForkJoinPool 结合归并排序 来落地优化。归并排序核心思想是:将大数组不断拆分为两个等长子数组,对子数组各自排序后,再合并成完整有序数组。
由于天然适合递归拆分、分而治之的特性,和 ForkJoin 框架完美适配。
一、实现原理
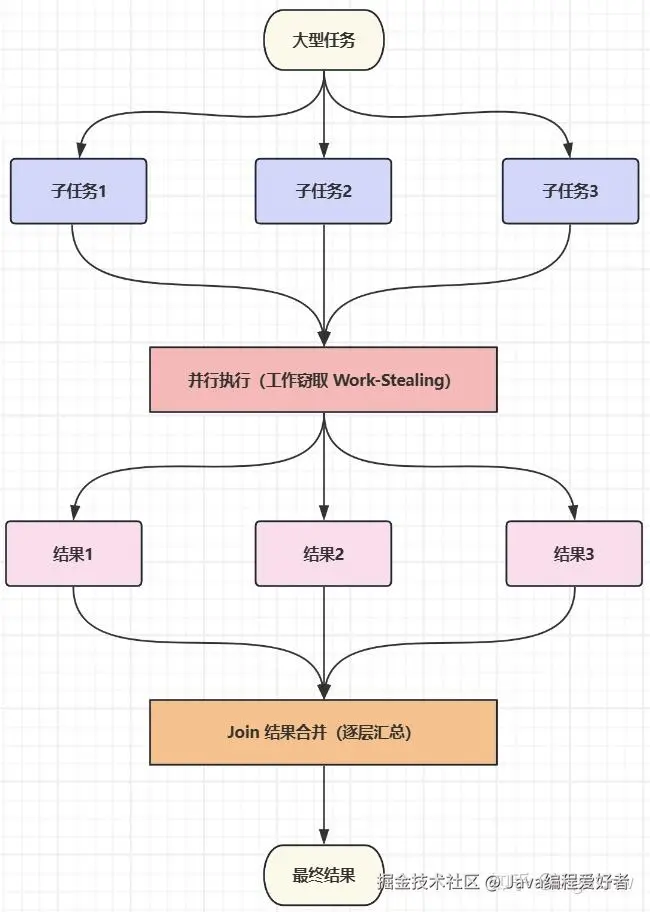
Fork/Join 是一款面向并行计算的框架,专为支撑分治任务模型而设计。在该框架中,Fork 对应分治模型里的任务拆分 ,Join 则负责结果汇总。
其核心设计思想为:将一个体量庞大的复杂任务,拆解为若干轻量化子任务并并行执行,待所有子任务运算完成后,再统一整合输出最终结果。
该框架适配各类可通过分治策略处理的计算密集型场景,典型应用包括大规模数组排序、图形渲染、复杂算法运算等。
二,🌰🌰举个例子
1、🌰RecursiveAction:排序
用于递归执行但不需要返回结果的任务。
1.1、代码例子
java
package com.nl.forkjoin;
import java.util.Arrays;
import java.util.Random;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.RecursiveAction;
public class ForkJoinDemo {
public static void main(String[] args) {
// 创建数组
int size = 10000000;
int[] array = new Random().ints(size, 0, 100000000).toArray();
// 普通方式
int[] arr1 = Arrays.copyOf(array, size);
long start1 = System.currentTimeMillis();
Arrays.sort(arr1);
System.out.println("普通排序: " + (System.currentTimeMillis() - start1) + "ms");
// ForkJoin方式
int[] arr2 = Arrays.copyOf(array, size);
ForkJoinPool pool = new ForkJoinPool();
long start2 = System.currentTimeMillis();
pool.invoke(new SortTask(arr2, 0, arr2.length));
System.out.println("ForkJoin: " + (System.currentTimeMillis() - start2) + "ms");
pool.shutdown();
}
/**
* ForkJoinPool排序任务
*/
static class SortTask extends RecursiveAction {
private int[] arr;
private int l, r;
SortTask(int[] arr, int l, int r) {
this.arr = arr;
this.l = l;
this.r = r;
}
/**
* 排序
*/
@Override
protected void compute() {
// 必须保留终止条件,任务过小不拆分,阈值会影响计算消耗时间
// 避免没有设置阈值导致无限递归拆分,最终栈溢出或资源耗尽
if (r - l <= 10000) {
Arrays.sort(arr, l, r);
return;
}
int m = (l + r) / 2;
invokeAll(new SortTask(arr, l, m), new SortTask(arr, m, r));
}
}
}⚠️注意
✔️必须保留终止阈值条件,避免没有设置阈值导致无限递归拆分,最终栈溢出或资源耗尽
✔️阈值会影响计算消耗时间,如:r - l <=10000
1.2、输出结果
makefile
普通排序: 663ms
ForkJoin: 33ms⚠️注意
✔️阈值会影响计算消耗时间
2、🌰RecursiveTask:计算
用于递归执行需要返回结果的任务。
2.1、执行
java
public class LongSumMain {
public static void main(String[] args) throws Exception {
//准备数组
int[] array = Utils.buildRandomIntArray(100000000);
LongSumDemo longSumDemo = new LongSumDemo(array, 0, array.length);
// 构建ForkJoinPool
ForkJoinPool forkJoinPool = new ForkJoinPool();
//ForkJoin计算数组总和
ForkJoinTask<Long> result = forkJoinPool.submit(longSumDemo);
System.out.println("forkJoinPool sum=" + result.get());
forkJoinPool.shutdown();
}
}2.2、计算任务
ini
package com.nl.forkjoin
import java.util.concurrent.RecursiveTask;
public class LongSumDemo extends RecursiveTask<Long> {
static final int THRESHOLD = 1000;
int[] arr;
int lo, hi;
LongSumDemo(int[] arr, int lo, int hi) {
this.arr = arr;
this.lo = lo;
this.hi = hi;
}
/**
* 执行拆分任务,拆分的任务都存在:ForkJoinTask<?>[] array
* 比如:left.fork(),会创建一个ForkJoinTask对象,并添加到ForkJoinTask[] array中
* @return
*/
@Override
protected Long compute() {
// 任务执行逻辑,如果任务拆分到小于等于阀值(THRESHOLD),则开始求和
if (hi - lo <= THRESHOLD) {
long sum = 0;
for (int i = lo; i < hi; i++) {
sum += arr[i];
}
return sum;
}
int mid = (lo + hi) / 2;
LongSumDemo left = new LongSumDemo(arr, lo, mid);
LongSumDemo right = new LongSumDemo(arr, mid, hi);
// invokeAll(left, right);
// 等价于
// left.fork();、right.fork();
invokeAll(left, right);
return left.join() + right.join();
}
}⚠️注意
✔️汇总输出结果,也需要设置阈值是为了平衡并行开销和计算效率:hi - lo <=THRESHOLD
2.2、输出
ini
forkJoinPool sum=5000239626626864三、源码分析
1、构造函数
scss
public ForkJoinPool(int parallelism,
ForkJoinWorkerThreadFactory factory,
UncaughtExceptionHandler handler,
boolean asyncMode) {
this(checkParallelism(parallelism),
checkFactory(factory),
handler,
asyncMode ? FIFO_QUEUE : LIFO_QUEUE,
"ForkJoinPool-" + nextPoolId() + "-worker-");
checkPermission();
}
public ForkJoinPool() {
this(Math.min(MAX_CAP, Runtime.getRuntime().availableProcessors()),
defaultForkJoinWorkerThreadFactory, null, false);
}- int parallelism :指定并行级别(parallelism level),
ForkJoinPool会根据该值确定工作线程的数量。若未显式设置,将默认使用Runtime.getRuntime().availableProcessors()获取 CPU 核心数作为并行级别。 - ForkJoinWorkerThreadFactory factory :用于创建
ForkJoinPool工作线程的工厂类。注意必须实现ForkJoinWorkerThreadFactory接口,而非普通的ThreadFactory。若未指定,将使用框架默认的DefaultForkJoinWorkerThreadFactory创建线程。 - UncaughtExceptionHandler handler:设置未捕获异常处理器,用于处理任务执行过程中抛出的未捕获异常。
- boolean asyncMode :配置内部任务队列的工作模式。当值为
true时采用 先进先出(FIFO)队列;为false时采用后进先出(LIFO) 队列。
⚠️注意
✔️Runtime.getRuntime().availableProcessors() : 获取 CPU 逻辑核心数(如 8 核、16 线程)
✔️Math.min(MAX_CAP, ...) : 限制最大值不超过 MAX_CA
⚠️为什么要这样写?
✔️防止 CPU 核心数过多时创建太多线程,导致资源浪费
2、 fork()和 join()
ForkJoinTask 的核心为 fork() 与 join() 两大方法,二者承担核心的任务调度协作职责,分别用于异步提交子任务 与阻塞获取任务结果。
2.1、fork ():提交拆分任务
fork() 方法用于将子任务提交至线程池执行。若当前线程为 ForkJoinWorkerThread 工作线程,任务会优先加入当前线程的私有任务队列;否则,统一提交至 Common 公共线程池队列。
⚠️注意
✔️left.fork(); right.fork(); 效果等价于 invokeAll(left, right)。
✔️Common 公共线程池: 内部
workQueues数组里的一类特殊WorkQueue,所有者线程owner=null队列
2.2、join():获取任务执行结果
join() 方法用于等待并获取任务最终执行结果,调用该方法会阻塞当前线程,直至目标任务执行完毕,再返回计算结果。
3、execute、invoke和submit:提交执行
ForkJoinPool 中最常用的任务提交方式,核心区别就是是否阻塞主线程 和谁来负责任务拆分
| 方法名 | 谁负责第一层拆分 | 主线程是否阻塞 | 返回值 | 核心特点 | 适用场景 |
|---|---|---|---|---|---|
| invoke() | 主线程 | 是,阻塞等待完成 | 直接返回任务结果 | 同步执行,任务完成才继续执行后续代码 | 需要立即获取计算结果(大数据排序、聚合计算) |
| execute() | 线程池核心线程 | 否,非阻塞 | 无返回值(void) | 纯异步执行,不关注结果、不处理异常 | 后台无返回值任务(日志写入、文件清理、异步通知) |
| submit() | 线程池核心线程 | 否,非阻塞 | 返回 Future | 异步执行,可主动获取结果、处理异常、取消任务 | 需要异步获取结果,且支持灵活控制任务 |
⚠️主线程调用invoke
✔️主线程调用 task.fork():任务被放入共享队列workQueues(owner == null)
✔️主线程调用 task.compute():主线程直接在当前栈帧里递归执行。
✔️主线程调用 task.join():如果子任务还没做完,主线程甚至会尝试去偷别人的任务来干。
✔️无论使用 invoke 还是 submit 方式提交任务,只要是由 ForkJoinPool 外部线程(例如主线程、Tomcat 业务线程等)发起提交,该任务绑定的 WorkQueue 其 owner 属性始终为 null
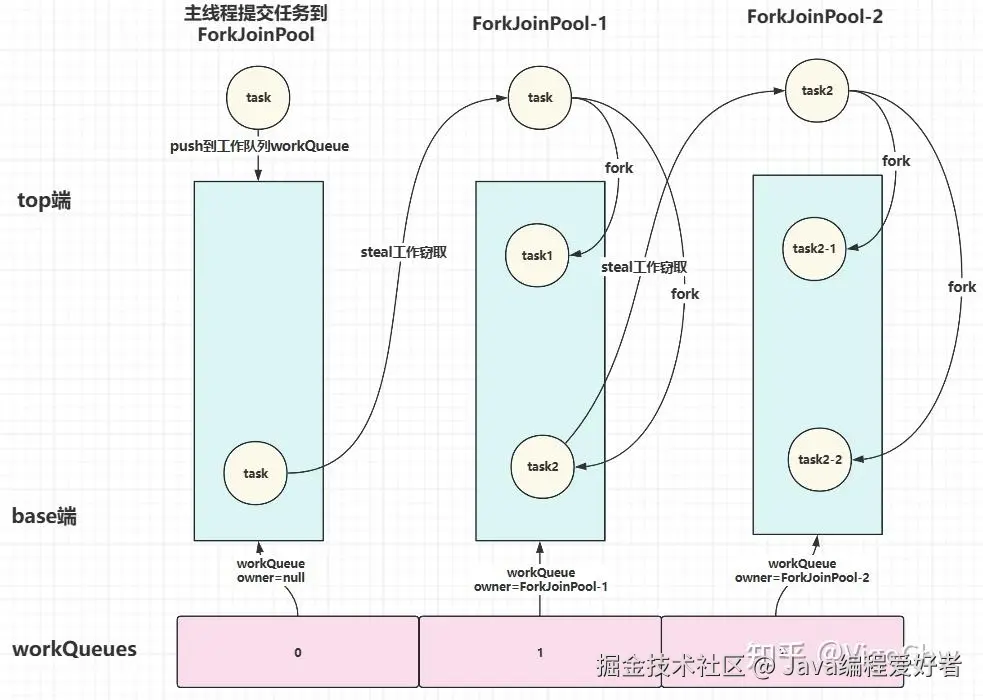
4、工作窃取
工作窃取机制:允许空闲线程从繁忙线程的双端队列中抢夺任务执行。
- 默认规则下,工作线程优先从自身双端队列(WorkQueue)的头部获取任务;
- 当本地队列无任务可处理 时,便会从其他繁忙线程的队列(WorkQueue)尾部窃取任务。
该设计能够有效降低多线程之间的任务竞争,充分利用线程资源,大幅提升整体并行执行效率。
⚠️注意
✔️ForkJoinPool 与 ThreadPoolExecutor 的核心差异,在于ForkJoinPool 引入了工作窃取机制,这也是 Fork/Join 高性能的关键设计。
4.1、WorkQueue
WorkQueue 是 ForkJoinPool 内部的双端队列 ,用来存放工作线程的专属任务。每个工作线程都维护独立的本地 WorkQueue,优先执行自身队列任务;当本地任务处理完毕,便会从其他繁忙线程的 WorkQueue 中窃取任务。
php
static final class WorkQueue {
......
volatile int base; // index of next slot for poll
int top; // index of next slot for push
ForkJoinTask<?>[] array; // the elements (initially unallocated)
......
}⚠️注意
✔️线程owner=自己 fork 任务 → top 指针 +1
✔️线程owner=自己 取任务 → top 指针 -1✔️其他线程 窃取任务 → base 指针 +1
4.2、总结
| 步骤 | 动作 | 关键指针 / 字段 | 形象比喻 |
|---|---|---|---|
| 提交 | 外部线程扔任务 | workQueues 数组 | 快递员把包裹放进公共柜 |
| 拆分 | 大任务变小任务 | top 指针 +1 | 把大石头敲成小石子,堆在托盘顶 |
| 窃取 | 闲线程偷忙线程的活 | base 指针 +1 | 隔壁工人从你托盘底抽走一块大石头 |
| 合并 | 小结果汇成大结果 | join() | 把碎纸片拼成完整的画 |
⚠️ 补充说明
✔️流程:提交→拆分→ 窃取→ 合并
✔️
top指针:所有者线程入队 / 出队的一端,fork()提交任务时top指针上移,任务下沉到队列底部。✔️
base指针:窃取线程取任务的一端,窃取时base指针上移,从队列底部取任务,避免和所有者竞争。
四,面试题
1、当工作线程自身的任务队列变为空时,是否就会闲置?
不闲置。
ForkJoinPool 具备任务窃取(Work-Stealing) 机制:一旦工作线程空闲,它就可以主动 "窃取" 其他工作线程队列中尚未执行的任务。通过这种机制,所有工作线程都能尽可能保持忙碌,大幅提升线程利用率与整体并行效率。
2、递归任务是否可以不设置阈值?
不可以。
- 面对递归深度较高的任务场景,使用 Fork/Join 框架容易出现任务调度过载、内存占用过高等问题,极易触发 StackOverflowError 栈溢出错误。
- 递归层级过深时,会批量生成大量子任务,大量子任务分散调度至不同线程执行。频繁的线程创建、销毁与任务调度会产生高额开销,持续挤占系统资源,最终造成整体性能下降。
设置阈值代码:
bash
if (r - l <= 10000) {
Arrays.sort(arr, l, r);
return;
}如果是r - l <=100时,就会导致错误:
php
Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
at java.util.Arrays.copyOf(Arrays.java:3284)
at com.forkjoin.recursiveaction.ForkJoinDemo.main(ForkJoinDemo.java:16)因此,在使用 Fork/Join 框架处理递归任务时,需结合实际场景合理评估递归深度 与任务粒度,以此规避任务调度过载、内存消耗过高及栈溢出等潜在问题。
五、总结
ForkJoinPool 工作窃取机制核心:让空闲线程偷取繁忙线程任务,最大化利用CPU。其workQueues含私有队列和公共队列,工作线程从自身队列头部取任务,空闲时从其他队列尾部窃取,fork改top指针、窃取改base指针,join等待返回结果。