本章目标:深入理解基础 RAG 的三大核心缺陷,掌握 Multi-Query(多查询扩展)、Contextual Compression(上下文压缩)、HyDE(假设文档嵌入)三种高级检索策略,并能根据场景选择合适方案。
前期回顾
一、基础 RAG 的三大痛点
学完第6章的基础 RAG 后,你可能已经在实际项目中遇到了这些问题:
痛点一:语义漂移(召回率低)
用户问:"Python 程序跑得太慢了,怎么优化?"
知识库文档里写的是:"使用 cProfile 分析 性能瓶颈 ......""NumPy 向量化操作 替代 Python 循环......"
用户说"跑得慢",文档说"性能瓶颈"和"向量化"------语义相关,但向量相似度可能不够高,好文章被漏掉了。
痛点二:文档噪声(精确率低)
检索到了一篇 3000 字的 Python 优化指南,但你只问了 GIL 锁的问题。LLM 收到的上下文里 90% 都是无关内容,干扰了 LLM 的判断,还白白消耗 Token。
痛点三:专业表述差距(专业域问题)
普通用户问:"那个让大模型回答风格像人一样的技术是什么?"
技术文档里写的是:"RLHF(基于人类反馈的强化学习)......"
问题和答案所用的词汇完全不同,向量相似度极低,找不到对应文档。
二、三种高级 RAG 策略全景
| 策略 | 解决的痛点 | 额外 LLM 调用 | 适合场景 |
|---|---|---|---|
| Multi-Query | 召回率低(语义漂移) | +1次(改写查询) | 通用知识库,用户问题表述多样 |
| Contextual Compression | 精确率低(文档噪声) | +N次(每个文档压缩一次) | 文档块大,信息密度低 |
| HyDE | 专业域表述差距 | +1次(生成假设答案) | 技术/医疗/法律等专业领域 |
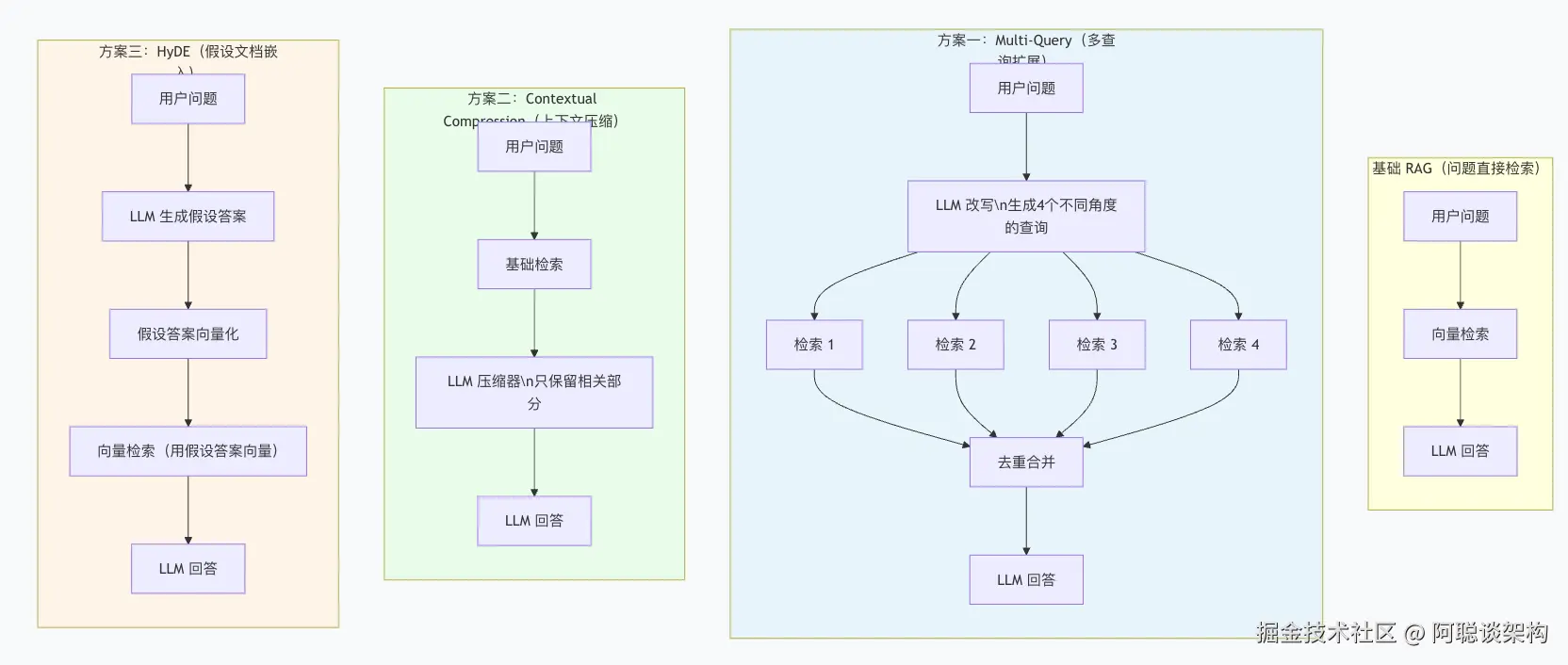
三、方案一:Multi-Query RAG
代码文件:12_advanced_rag/01_multi_query_rag.py
3.1 核心思路
Multi-Query(多查询检索):让 LLM 把用户问题改写成多个不同角度的查询,分别检索,合并去重后送给 LLM 回答。
arduino
用户问:"Python 程序跑得太慢了,有什么方法可以提速?"
LLM 改写为:
1. "Python 代码运行慢的解决方法" ← 从"解决方法"角度
2. "Python 性能瓶颈分析工具" ← 从"分析工具"角度
3. "Python 并发与并行处理提升速度" ← 从"并发优化"角度
4. "CPython 解释器性能优化技巧" ← 从"底层原理"角度
4路检索 → 去重合并 → 覆盖更多相关文档3.2 完整实现
python
import os # 读取环境变量
import re # 正则表达式,用于解析查询列表
from langchain_core.documents import Document # 文档数据结构
from langchain_core.output_parsers import BaseOutputParser, StrOutputParser
from langchain_core.prompts import PromptTemplate, ChatPromptTemplate
from langchain_openai import ChatOpenAI # LLM
from langchain_milvus import Milvus # 向量数据库(Milvus Lite)
from langchain_openai import OpenAIEmbeddings # 嵌入模型
from dotenv import load_dotenv
# ★ 已移除未使用的 `from typing import Union`
load_dotenv()
# ── 初始化 LLM 和 Embeddings ──────────────────────────────────
llm = ChatOpenAI(
model="qwen-plus",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key=os.getenv("DASHSCOPE_API_KEY"),
temperature=0.3, # 查询改写允许少量创意性
)
embeddings = OpenAIEmbeddings(
model="text-embedding-v3", # 百炼的文本嵌入模型
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key=os.getenv("DASHSCOPE_API_KEY"),
)
# ── 构建知识库 ─────────────────────────────────────────────────
documents = [
Document(
page_content="使用 cProfile 和 line_profiler 分析 Python 性能瓶颈。"
"常见性能问题:不必要的循环、字符串拼接、频繁 I/O 操作。",
metadata={"section": "性能分析工具"}, # 元数据,可用于过滤
),
Document(
page_content="Python GIL 限制多线程并行。CPU 密集型任务用 multiprocessing,"
"I/O 密集型任务用 asyncio 协程。",
metadata={"section": "并发优化"},
),
Document(
page_content="NumPy 向量化操作将 Python 循环转为底层 C 实现,速度提升 10-100 倍。"
"避免 Python 层面 for 循环,优先使用 NumPy ufunc。",
metadata={"section": "数值计算"},
),
Document(
page_content="内存优化:__slots__ 减少实例内存,生成器替代列表推导处理大数据集,"
"lru_cache 缓存函数结果。",
metadata={"section": "内存优化"},
),
Document(
page_content="连接池是数据库性能优化关键,避免频繁创建连接。"
"asyncpg、aiomysql 配合 asyncio 大幅提升 I/O 吞吐量。",
metadata={"section": "数据库优化"},
),
]
# Milvus.from_documents:从文档列表创建向量数据库(Milvus Lite 本地文件模式)
# connection_args={"uri": "..."} 指定本地 .db 文件路径,无需启动独立 Milvus 服务
# drop_old=True 保证每次运行从空集合开始,避免重复写入
vectorstore = Milvus.from_documents(
documents=documents,
embedding=embeddings,
connection_args={"uri": "./milvus_ch12_01.db"},
drop_old=True,
)
# ── 自定义输出解析器:将多行文本解析为字符串列表 ──────────────
class LineListOutputParser(BaseOutputParser[list[str]]):
"""把 LLM 改写的多行查询解析为列表。
LLM 输出格式:
1. Python 代码运行慢的解决方法
2. Python 性能瓶颈分析工具
...
解析后:["Python 代码运行慢的解决方法", "Python 性能瓶颈分析工具", ...]
"""
def parse(self, text: str) -> list[str]:
lines = text.strip().split("\n") # 按换行拆分
result = []
for line in lines:
line = line.strip() # 去除首尾空格
if not line:
continue # 跳过空行
# 去除 "1. " "2. " "- " "• " 等前缀
line = re.sub(r"^[\d]+[\.\)]\s*", "", line)
line = re.sub(r"^[-•]\s*", "", line)
if line: # 确保去前缀后不为空
result.append(line)
return result
# ── Multi-Query 检索核心函数 ──────────────────────────────────
def multi_query_retrieve(
vectorstore: Milvus,
llm: ChatOpenAI,
original_question: str,
n_queries: int = 4, # 改写查询的数量
) -> list[Document]:
"""执行 Multi-Query 检索。
Args:
vectorstore: 向量数据库实例(Milvus)
llm: 用于改写查询的语言模型
original_question: 用户原始问题
n_queries: 改写查询数量(建议 3-5 个)
Returns:
去重合并后的相关文档列表
"""
# ── 第一步:改写查询 ──────────────────────────────────────
rewrite_prompt = PromptTemplate.from_template(
"你是 AI 问题改写专家。将用户问题改写成 {n} 个不同角度的版本,"
"以提升向量检索的召回率。\n\n"
"原始问题:{question}\n\n"
"生成 {n} 个改写版本,每行一个,直接输出查询内容,不要编号:"
)
# 构建改写链:提示词 → LLM → 解析为列表
rewrite_chain = rewrite_prompt | llm | LineListOutputParser()
generated_queries = rewrite_chain.invoke({
"n": n_queries,
"question": original_question,
})
# 改写查询 + 原始查询 = 全部查询
all_queries = [original_question] + generated_queries
print(f"📝 原始查询:{original_question}")
print(f"🔄 改写查询({len(generated_queries)} 个):")
for q in generated_queries:
print(f" • {q}")
# ── 第二步:多路并行检索 ──────────────────────────────────
retriever = vectorstore.as_retriever(search_kwargs={"k": 2}) # 每次取2个
all_docs: list[Document] = []
seen_contents: set[int] = set() # 用集合存内容哈希,实现去重
for query in all_queries:
docs = retriever.invoke(query) # 向量检索
for doc in docs:
content_hash = hash(doc.page_content) # 用内容哈希判断重复
if content_hash not in seen_contents:
seen_contents.add(content_hash)
all_docs.append(doc)
print(f"\n📦 多路检索后去重,共 {len(all_docs)} 个不重复文档块")
return all_docs
# ── 完整 Multi-Query RAG 流程 ─────────────────────────────────
def multi_query_rag(question: str) -> str:
"""完整的 Multi-Query RAG 问答。"""
# 第一步:多查询检索
docs = multi_query_retrieve(vectorstore, llm, question, n_queries=3)
# 第二步:拼接上下文
context = "\n\n---\n".join([doc.page_content for doc in docs])
# 第三步:LLM 生成最终答案
qa_prompt = ChatPromptTemplate.from_messages([
("system",
"你是 Python 技术专家。请根据以下知识库内容,为用户提供全面专业的解答。\n\n"
"相关知识库内容:\n{context}"),
("human", "{question}"),
])
qa_chain = qa_prompt | llm | StrOutputParser()
return qa_chain.invoke({"context": context, "question": question})
# ── 执行示例 ───────────────────────────────────────────────────
question = "Python 程序跑得太慢了,有什么方法可以提速?"
answer = multi_query_rag(question)
print(f"\n💡 最终回答:\n{answer}")3.3 效果对比验证
python
# ── 基础检索 vs Multi-Query 对比 ─────────────────────────────
question = "Python 程序跑得太慢了,有什么方法可以提速?"
# 基础检索:只用原始问题
basic_retriever = vectorstore.as_retriever(search_kwargs={"k": 2})
basic_docs = basic_retriever.invoke(question)
print(f"基础检索:{len(basic_docs)} 个文档")
for doc in basic_docs:
print(f" • {doc.metadata.get('section')}: {doc.page_content[:60]}...")
# Multi-Query 检索
multi_docs = multi_query_retrieve(vectorstore, llm, question)
print(f"\nMulti-Query:{len(multi_docs)} 个文档(覆盖更多主题)")
for doc in multi_docs:
print(f" • {doc.metadata.get('section')}: {doc.page_content[:60]}...")
# 预期结果:Multi-Query 能覆盖"性能分析"、"并发优化"、"内存优化"等多个主题
# 基础检索可能只返回与"跑得慢"最相近的2个文档块四、方案二:Contextual Compression(上下文压缩)
代码文件:lessons/12_advanced_rag/02_contextual_compression.py
4.1 核心思路
Contextual Compression(上下文压缩):在向量检索之后,用 LLM 对检索结果进行二次过滤/压缩,只保留真正与查询相关的部分。
markdown
原始检索返回:
文档1(2000字):Python 完整优化指南
- GIL 介绍(200字,与问题相关)
- 数据结构选择(300字,无关)
- 异步编程(500字,部分相关)
- 内存管理(400字,无关)
- ...
压缩后:
文档1(200字):仅保留 GIL 相关内容4.2 两种压缩策略
LLMChainExtractor(抽取式):从文档中抽取相关段落,去掉无关部分。优点是保留原文措辞,缺点是 LLM 调用成本较高。
LLMChainFilter(过滤式):对每个文档做 Yes/No 判断,过滤掉整体不相关的文档。优点是快速低成本,缺点是粒度粗(保留或删除整个文档)。
python
import os
from langchain_core.documents import Document
from langchain_openai import ChatOpenAI
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import LLMChainExtractor, LLMChainFilter
from langchain_milvus import Milvus
from langchain_openai import OpenAIEmbeddings
from dotenv import load_dotenv
load_dotenv()
llm = ChatOpenAI(
model="qwen-plus",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key=os.getenv("DASHSCOPE_API_KEY"),
temperature=0, # 压缩/过滤任务要确定性
)
embeddings = OpenAIEmbeddings(
model="text-embedding-v3",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key=os.getenv("DASHSCOPE_API_KEY"),
)
# ── 构建包含"噪声"的文档(模拟真实知识库的文档块) ─────────────
# 注意:每个文档故意包含多个主题,模拟真实的"大而全"文档块
noisy_documents = [
Document(
page_content=(
"Python 性能优化综合指南。"
"一、GIL(全局解释器锁):GIL 是 CPython 的互斥锁,同一时刻只允许一个线程执行 Python 字节码。"
"对 CPU 密集型任务影响大,推荐使用 multiprocessing 模块绕过 GIL。"
"二、代码规范:遵循 PEP 8 风格指南,使用 flake8 进行代码检查,保持代码可读性。"
"三、虚拟环境:使用 venv 或 conda 管理项目依赖,避免包版本冲突。"
"四、异步 I/O:对于网络请求等 I/O 密集型任务,asyncio 协程可大幅提升并发性能。"
),
metadata={"source": "python_guide", "topic": "综合指南"},
),
Document(
page_content=(
"Python 数据科学生态介绍。"
"NumPy:高性能数值计算库,向量化操作比纯 Python 循环快 100 倍。"
"Pandas:数据处理和分析,支持 DataFrame 操作。"
"Matplotlib:数据可视化,支持静态图表绘制。"
"Scikit-learn:机器学习算法库,包含分类、回归、聚类等算法。"
"注意:NumPy 和 Pandas 的底层计算均已优化,大量计算任务应优先使用它们而非纯 Python。"
),
metadata={"source": "data_science", "topic": "数据科学"},
),
]
# Milvus Lite:本地文件存储,drop_old=True 每次从空集合开始
base_vectorstore = Milvus.from_documents(
documents=noisy_documents,
embedding=embeddings,
connection_args={"uri": "./milvus_ch12_02.db"},
drop_old=True,
)
base_retriever = base_vectorstore.as_retriever(search_kwargs={"k": 2})
# ── 方案 A:LLMChainExtractor(抽取式压缩) ───────────────────
# 从检索到的文档中,提取与查询相关的文本片段
# 完整流程:查询 → 向量检索(粗筛) → LLM 抽取相关段落(精筛)
extractor = LLMChainExtractor.from_llm(llm) # 用 LLM 做抽取
extractor_retriever = ContextualCompressionRetriever(
base_compressor=extractor, # 压缩器:LLMChainExtractor
base_retriever=base_retriever, # 基础检索器:向量检索
)
question = "Python 的 GIL 是什么,如何解决?"
compressed_docs = extractor_retriever.invoke(question)
print("【LLMChainExtractor 结果】")
for i, doc in enumerate(compressed_docs, 1):
print(f"文档 {i}(压缩后 {len(doc.page_content)} 字):")
print(f" {doc.page_content}") # 只剩下 GIL 相关内容
# 对比:原始文档有约 500 字,压缩后只剩 GIL 相关的 ~100 字
# ── 方案 B:LLMChainFilter(过滤式) ─────────────────────────
# 对每个文档进行相关性判断,过滤掉整体不相关的文档
# 适合:快速过滤明显不相关的文档块
doc_filter = LLMChainFilter.from_llm(llm) # 用 LLM 做过滤
filter_retriever = ContextualCompressionRetriever(
base_compressor=doc_filter, # 压缩器:LLMChainFilter
base_retriever=base_retriever,
)
filtered_docs = filter_retriever.invoke(question)
print(f"\n【LLMChainFilter 结果】({len(filtered_docs)} 个文档通过过滤)")
for doc in filtered_docs:
print(f" 来源:{doc.metadata.get('source')} 内容:{doc.page_content[:80]}...")4.3 压缩检索的成本权衡
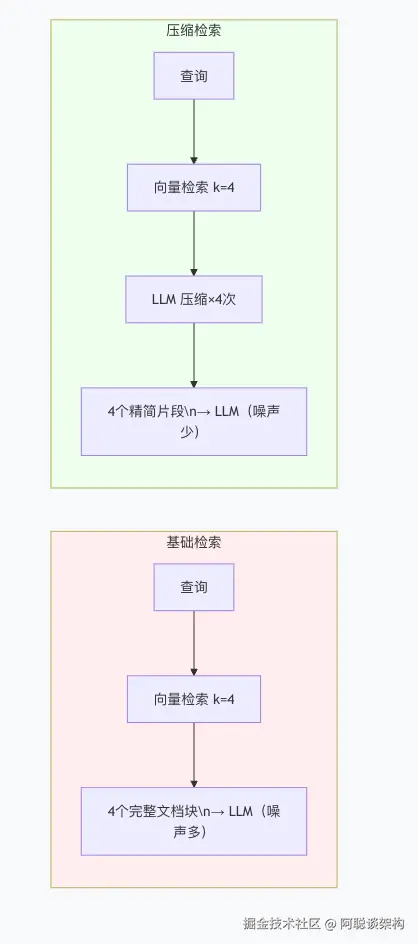
| 指标 | 基础检索 | 压缩检索 |
|---|---|---|
| LLM 调用次数 | 1次(最终回答) | 1 + k次(k = 检索文档数) |
| 上下文质量 | 包含噪声 | 高度相关 |
| Token 消耗 | 文档块全文 | 仅相关片段 |
| 延迟 | 低 | 较高(多次 LLM 调用串行) |
| 建议 k 值 | k=4-8 | k=2-4(压缩器会增加成本) |
五、方案三:HyDE(假设文档嵌入)
代码文件:lessons/12_advanced_rag/03_hyde_rag.py
5.1 核心思路
HyDE(Hypothetical Document Embeddings,假设文档嵌入):不直接用问题的向量去检索,而是先让 LLM 生成一段"假设性答案",再用假设答案的向量去检索知识库。
为什么这样有效?
yaml
问题: "那个让大模型跟人说话风格一样的技术是什么原理?"
问题向量: [0.12, -0.34, 0.89, ...](口语化,偏向"说话风格")
知识库文档:"RLHF(基于人类反馈的强化学习)通过人工评分来对齐模型输出......"
文档向量: [0.45, -0.21, 0.76, ...](技术性,偏向"RLHF")
→ 直接检索:问题向量与文档向量相似度低,找不到!
---
HyDE 假设答案:"基于人类反馈的强化学习(RLHF)是实现对话风格对齐的关键技术,
通过收集人类对不同回答的偏好评分,训练奖励模型......"
假设答案向量: [0.44, -0.20, 0.77, ...](接近文档向量)
→ HyDE 检索:假设答案向量与文档向量高度相似,成功找到!5.2 完整 HyDE 实现
python
import os
from langchain_core.documents import Document
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_milvus import Milvus
from dotenv import load_dotenv
load_dotenv()
llm = ChatOpenAI(
model="qwen-plus",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key=os.getenv("DASHSCOPE_API_KEY"),
temperature=0.3,
)
embeddings = OpenAIEmbeddings(
model="text-embedding-v3",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key=os.getenv("DASHSCOPE_API_KEY"),
)
# ── 构建专业技术知识库 ─────────────────────────────────────────
tech_documents = [
Document(
page_content=(
"RLHF(基于人类反馈的强化学习)是对齐大语言模型的核心技术。"
"流程:先进行监督微调(SFT),再训练奖励模型(RM),"
"最后使用 PPO 算法对 LLM 进行强化学习,使其输出更符合人类偏好。"
"ChatGPT、Claude 等产品均使用了 RLHF 技术。"
),
metadata={"source": "rlhf_paper"},
),
Document(
page_content=(
"LoRA(Low-Rank Adaptation)是参数高效微调(PEFT)技术。"
"核心思想:预训练权重的更新矩阵可以用低秩矩阵分解近似。"
"LoRA 冻结原始权重,只训练低秩矩阵,参数量减少 99%+,"
"可在消费级 GPU 上微调大型模型(如 Qwen、LLaMA)。"
),
metadata={"source": "lora_paper"},
),
Document(
page_content=(
"Flash Attention 是内存高效的注意力计算算法,"
"通过 IO 感知的块状计算减少 HBM 访问次数。"
"标准 Attention 内存占用 O(N²),Flash Attention 显著降低内存峰值。"
"长上下文模型(128k+ tokens)几乎都依赖 Flash Attention 技术。"
),
metadata={"source": "flash_attention"},
),
Document(
page_content=(
"RAG(检索增强生成)弥补 LLM 知识截止日期的局限。"
"流程:Query → 向量检索 → 相关文档 → LLM + 上下文 → 答案。"
"高级 RAG:Multi-Query、HyDE、Contextual Compression、Re-ranking。"
),
metadata={"source": "rag_overview"},
),
]
# Milvus Lite:本地文件存储,drop_old=True 每次从空集合开始
vectorstore = Milvus.from_documents(
documents=tech_documents,
embedding=embeddings,
connection_args={"uri": "./milvus_ch12_03.db"},
drop_old=True,
)
# ── 第一步:生成假设性答案文档 ────────────────────────────────
def generate_hypothetical_document(question: str) -> str:
"""让 LLM 针对问题生成一段"假设性答案"(不需要完全正确)。
关键点:假设答案不用真实准确,只需要在向量空间中
与真实知识库文档足够接近即可。LLM 可能有幻觉,
但这里只用它的向量,不用它的文字内容。
"""
hyde_prompt = ChatPromptTemplate.from_messages([
("system",
"请针对问题,生成一段详细的技术解释(约100字),作为该问题的理想答案。"
"用陈述句,语气专业,直接陈述核心内容,不要以'答案是'开头。"),
("human", "{question}"),
])
chain = hyde_prompt | llm | StrOutputParser()
return chain.invoke({"question": question})
# ── 第二步:用假设答案的向量检索 ─────────────────────────────
def hyde_retrieve(question: str, k: int = 2) -> tuple[str, list[Document]]:
"""HyDE 检索:生成假设答案 → 向量化 → 检索知识库。
Returns:
(假设性答案文本, 检索到的相关文档列表)
"""
# Step 1: 生成假设答案
hypothetical_doc = generate_hypothetical_document(question)
print(f"📝 假设性答案(节选):{hypothetical_doc[:100]}...")
# Step 2: 将假设答案转为向量(而不是将问题转为向量)
# embed_query() 返回 list[float],即一个向量
hyp_vector = embeddings.embed_query(hypothetical_doc)
# Step 3: 用假设答案的向量在知识库中检索
# similarity_search_by_vector:直接用向量检索,不再二次嵌入
docs = vectorstore.similarity_search_by_vector(hyp_vector, k=k)
return hypothetical_doc, docs
# ★ hyde_rag 在对比测试循环之前定义,确保代码从上到下可读
# ── 完整 HyDE RAG 问答 ─────────────────────────────────────────
def hyde_rag(question: str) -> str:
"""完整的 HyDE RAG 问答流程。"""
_, docs = hyde_retrieve(question, k=3) # HyDE 检索
context = "\n\n".join([d.page_content for d in docs]) # 拼接上下文
qa_prompt = ChatPromptTemplate.from_messages([
("system", "你是 AI 技术专家。基于知识库内容为用户提供准确专业的解答。\n\n"
"参考资料:\n{context}"),
("human", "{question}"),
])
chain = qa_prompt | llm | StrOutputParser()
return chain.invoke({"context": context, "question": question})
# ── 对比测试:基础检索 vs HyDE 检索 ──────────────────────────
test_questions = [
"那个让大模型可以做到跟人类对话风格一样的技术是什么原理?", # 应找到 RLHF
"微调大模型但是 GPU 显存不够怎么办?", # 应找到 LoRA
]
for question in test_questions:
print(f"\n{'─' * 50}")
print(f"查询:{question}")
# 基础检索(直接用问题向量)
basic_retriever = vectorstore.as_retriever(search_kwargs={"k": 2})
basic_docs = basic_retriever.invoke(question)
print(f"\n【基础检索】:")
for doc in basic_docs:
# ★ 使用 .get() 避免 metadata 中缺少 'source' 键时抛出 KeyError
print(f" 来源:{doc.metadata.get('source', '未知')} {doc.page_content[:60]}...")
# HyDE 检索
print(f"\n【HyDE 检索】:")
_, hyde_docs = hyde_retrieve(question)
for doc in hyde_docs:
print(f" 来源:{doc.metadata.get('source', '未知')} {doc.page_content[:60]}...")
answer = hyde_rag("那个让大模型可以做到跟人类对话风格一样的技术是什么原理?")
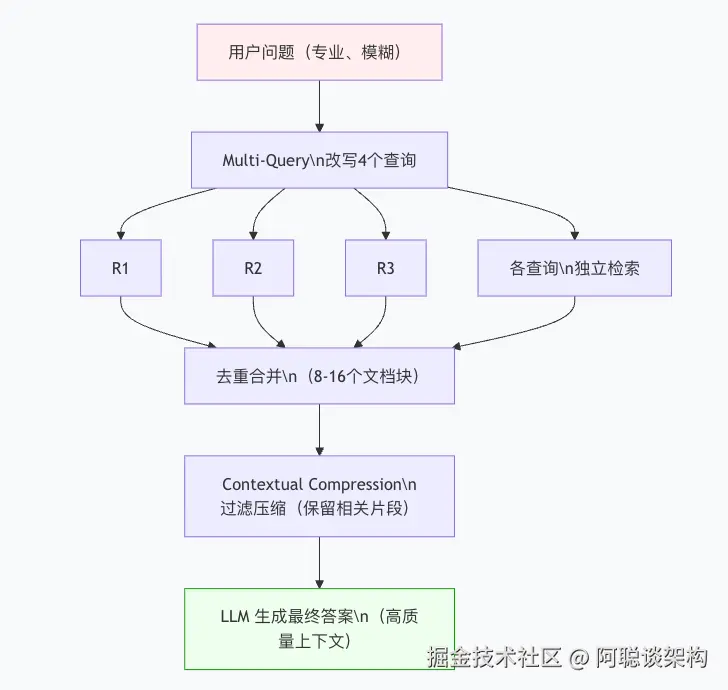
print(f"\n💡 HyDE RAG 最终回答:\n{answer}")六、三种方案组合使用
高级技巧:三种方案可以叠加使用,应对最复杂的场景:
python
def advanced_rag(question: str) -> str:
"""组合方案:Multi-Query + Contextual Compression。"""
# 第一步:Multi-Query 扩展(提升召回率)
all_docs = multi_query_retrieve(vectorstore, llm, question, n_queries=3)
# 第二步:手动实现文档压缩(过滤不相关内容)
# 简化版:用 LLM 评分每个文档的相关性
compress_prompt = ChatPromptTemplate.from_messages([
("system", "判断以下文档是否与查询相关。只回答 '是' 或 '否'。"),
("human", "查询:{query}\n\n文档:{document}"),
])
compress_chain = compress_prompt | llm | StrOutputParser()
relevant_docs = []
for doc in all_docs:
relevance = compress_chain.invoke({
"query": question,
"document": doc.page_content,
})
# ★ Bug fix: "不是" 中也含有 "是",必须先排除否定答复,再判断肯定答复
# LLM 可能回答 "是"、"是的"、"是,相关" 或 "否"、"不是"、"否,不相关"
relevance_stripped = relevance.strip()
is_relevant = (
relevance_stripped.startswith("是")
and not relevance_stripped.startswith("是否") # 排除"是否..."反问句
) or relevance_stripped == "Yes"
if is_relevant: # 只保留相关文档
relevant_docs.append(doc)
# ★ Bug fix: 若所有文档都被过滤掉,回退到全部文档,避免以空上下文调用 LLM
if not relevant_docs:
relevant_docs = all_docs
# 第三步:生成回答
context = "\n\n---\n".join([d.page_content for d in relevant_docs])
qa_prompt = ChatPromptTemplate.from_messages([
("system", "基于知识库内容回答问题。\n\n内容:\n{context}"),
("human", "{question}"),
])
chain = qa_prompt | llm | StrOutputParser()
return chain.invoke({"context": context, "question": question})七、场景选型指南
| 你的问题 | 推荐方案 | 理由 |
|---|---|---|
| 用户提问方式多样(同一问题10种说法) | Multi-Query | 覆盖更多语义变体 |
| 文档块太大,包含大量无关内容 | Contextual Compression | 精准提取相关片段 |
| 专业领域,用户用口语问技术问题 | HyDE | 桥接日常用语与专业术语 |
| 知识库小(<100文档)、问题简单 | 基础 RAG | 额外复杂度不值得 |
| 响应速度要求极高(<2秒) | 基础 RAG 或 Multi-Query | CC 和 HyDE 增加延迟 |
| 预算有限,控制 API 成本 | Multi-Query | 额外 1 次 LLM 调用,性价比高 |
八、常见错误与排查
| 错误信息 | 原因 | 解决方法 |
|---|---|---|
ImportError: langchain_milvus |
未安装 Milvus 依赖 | uv sync --extra milvus 或 pip install langchain-milvus milvus-lite |
| Multi-Query 改写的查询意思完全偏离 | 改写提示词不够清晰 | 在提示词中加入"改写应保持原始问题的核心意图" |
压缩后文档为空([]) |
LLMChainFilter 过滤太严 | 改用 LLMChainExtractor,或降低 k 值 |
| HyDE 假设答案包含严重错误信息 | LLM 幻觉(正常现象) | HyDE 设计上允许幻觉,只用向量不用文字,无需担心 |
| 向量检索返回结果全部不相关 | Embedding 模型与文档语言不匹配 | 使用多语言 Embedding 模型(如 text-embedding-v3) |
grpc.RpcError 或空错误信息 |
pymilvus 版本与 milvus-lite 不兼容 | 确保使用 pymilvus<2.6.0 + milvus-lite>=2.4.10,与 langchain-milvus<0.3.0 配套 |
ModuleNotFoundError: pkg_resources |
milvus-lite 依赖 setuptools | pip install setuptools>=78.1.1 |
下一章预告
掌握了高级 RAG 策略,下一章我们进入生产部署的核心话题。
第13章 将覆盖:
- 异步编程:同时处理 100 个 LLM 请求,不阻塞服务器
- FastAPI 集成:把 LangChain 封装成 REST API,支持流式 SSE
- LLM 缓存:相同问题第二次请求 0 延迟,大幅降低 API 成本
高级 RAG 解决了"找到正确信息"的问题,生产部署解决了"高效稳定地服务用户"的问题。两章合力,构建真正可用的 AI 产品。
AI入门开发系列文章合集
作者:阿聪谈架构公众号:阿聪谈架构 (分享后端架构 / AI / Java 技术文章)
相关代码关注公众号:【阿聪谈架构】 回复:AI专栏代码