从零搭建 AI 日记助手:用 Milvus 向量数据库实现语义搜索
前言:当 AI 拥有了记忆
近两年 Agentic AI(智能体 AI)的爆发,让应用不再只是被动地回答问题,而是能够主动规划、调用工具、甚至拥有长期记忆。而支撑这种"记忆"的关键基础设施,就是向量数据库。今天我们就借助开源向量数据库 Milvus,从零实现一个会"读懂"日记内容的语义搜索引擎------你说"想看看关于户外活动的日记",它就能精准找到爬山、散步等相关的记录。
一、为什么我们需要向量数据库?
传统关系型数据库(如 MySQL、PostgreSQL)擅长精确匹配和结构化查询:
sql
SELECT * FROM diaries WHERE tags LIKE '%户外%';但自然语言是模糊的------"户外活动"可能对应"爬山""公园散步""骑自行车"等各种说法,光靠关键词匹配远远不够。而向量数据库将文本转化为高维空间中的向量,通过计算向量之间的余弦相似度,可以找到语义最相近的内容,完全不需要死板的关键词。
Milvus 就是这样一款为 AI 场景设计的开源向量数据库,支持百亿级向量检索,已经被大量 AI Agent 产品使用。结合大模型的 Embedding 接口,我们可以轻松赋予应用真正的语义理解能力。
二、项目结构概览
我们将使用 Node.js 环境,结合两个核心库:
@zilliz/milvus2-sdk-node:Milvus 官方 Node SDK@langchain/openai:调用 OpenAI 兼容的 Embedding 模型
最终实现的功能:
- 设计日记的存储结构(id、向量、内容、日期、心情、标签)
- 将日记文本转为向量写入 Milvus
- 输入查询语句,返回语义最匹配的日记条目
三、环境准备与嵌入模型配置
首先安装依赖:
bash
npm install @zilliz/milvus2-sdk-node @langchain/openai dotenv在 .env 文件中配置连接信息和 API Key:
env
MILVUS_ADDRESS=your_milvus_host:port
MILVUS_TOKEN=your_milvus_token
OPENAI_API_KEY=your_openai_api_key
OPENAI_BASE_URL=https://api.openai.com/v1 # 或任何兼容的地址
EMBEDDING_MODEL_NAME=text-embedding-3-small我们使用 @langchain/openai 提供的 OpenAIEmbeddings 封装,方便切换模型,并可以通过 dimensions 参数指定输出向量维度(示例中使用 1024,可根据你的模型调整):
javascript
import { OpenAIEmbeddings } from '@langchain/openai'
const embeddings = new OpenAIEmbeddings({
apiKey: process.env.OPENAI_API_KEY,
model: process.env.EMBEDDING_MODEL_NAME,
configuration: {
baseURL: process.env.OPENAI_BASE_URL,
},
dimensions: VECTOR_DIM, // 1024
})封装一个简单的 embedding 函数,用于后续将文本转换为向量:
javascript
async function getEmbeddings(text) {
const result = await embeddings.embedQuery(text);
return result;
}四、连接 Milvus 实例
创建客户端并检查健康状态,这是所有操作的前提:
javascript
import { MilvusClient } from '@zilliz/milvus2-sdk-node'
const client = new MilvusClient({
address: process.env.MILVUS_ADDRESS,
token: process.env.MILVUS_TOKEN,
})
const health = await client.checkHealth();
if (!health.isHealthy) {
console.error('连接失败,请检查地址和 Token');
return;
}
console.log('Milvus 连接成功!');五、设计 Collection 的 Schema
与传统数据库中的"表"类似,Milvus 使用 Collection 组织数据。我们需要定义字段(Field)结构:
id:主键,字符串类型,便于区分日记vector:浮点型向量字段,维度与嵌入模型输出一致content:日记正文date:日期mood:心情标签tags:数组类型的标签,可存放多个关键词
javascript
await client.createCollection({
collection_name: 'ai_diary',
fields: [
{ name: 'id', data_type: DataType.VarChar, max_length: 50, is_primary_key: true },
{ name: 'vector', data_type: DataType.FloatVector, dim: VECTOR_DIM },
{ name: 'content', data_type: DataType.VarChar, max_length: 5000 },
{ name: 'date', data_type: DataType.VarChar, max_length: 50 },
{ name: 'mood', data_type: DataType.VarChar, max_length: 50 },
{ name: 'tags', data_type: DataType.Array, element_type: DataType.VarChar, max_capacity: 10, max_length: 50 },
]
})接着创建索引,这是实现高效向量检索的关键。我们选择 IVF_FLAT 索引,配合余弦相似度度量:
javascript
await client.createIndex({
collection_name: 'ai_diary',
field_name: 'vector',
index_type: IndexType.IVF_FLAT,
metric_type: MetricType.COSINE,
params: { nlist: VECTOR_DIM }
})小贴士:
nlist是聚类单元数,一般设为向量维度的数值可以快速上手,实际场景需根据数据量调优。
六、写入日记:嵌入与插入
准备好一组示例日记,利用之前封装的 getEmbeddings 将每条 content 转化为向量,然后批量插入:
javascript
const diaryContents = [
{ id: 'diary_001', content: '今天天气很好,去公园散步了...', date: '2026-01-10', mood: 'happy', tags: ['生活', '散步'] },
{ id: 'diary_002', content: '今天工作很忙,完成了一个重要的项目里程碑...', date: '2026-01-11', mood: 'excited', tags: ['工作', '成就'] },
{ id: 'diary_003', content: '周末和朋友去爬山,天气很好...', date: '2026-01-12', mood: 'relaxed', tags: ['户外', '朋友'] },
{ id: 'diary_004', content: '今天学习了 Milvus 向量数据库...', date: '2026-01-12', mood: 'curious', tags: ['学习', '技术'] },
{ id: 'diary_005', content: '晚上做了一顿丰盛的晚餐,尝试了新菜谱...', date: '2026-01-13', mood: 'proud', tags: ['美食', '家庭'] },
];
const diaryData = await Promise.all(
diaryContents.map(async (diary) => ({
...diary,
vector: await getEmbeddings(diary.content),
}))
);
const insertRes = await client.insert({
collection_name: 'ai_diary',
data: diaryData,
});
console.log(`成功插入 ${insertRes.insert_cnt} 条数据`);Milvus 的 insert 支持一次写入多条,非常便捷。
七、语义搜索:让机器"读懂"你想找什么
这是我们最期待的部分。用户输入查询语句 我想看看关于户外活动的日记,我们先将其向量化,然后调用 Milvus 的 search 接口,指定度量方式为余弦相似度,并返回最接近的 3 条记录。
注意在搜索前需要将 Collection 加载到内存 中(如果是已存在的 Collection):
javascript
await client.loadCollection({ collection_name: 'ai_diary' });
const query = '我想看看关于户外活动的日记';
const queryVector = await getEmbeddings(query);
const searchResult = await client.search({
collection_name: 'ai_diary',
vector: queryVector,
output_fields: ['id', 'content', 'date', 'mood', 'tags'],
limit: 3,
metric_type: MetricType.COSINE,
});最后遍历结果并打印:
javascript
searchResult.results.forEach((result) => {
console.log('ID:', result.id);
console.log('内容:', result.content);
console.log('日期:', result.date);
console.log('心情:', result.mood);
console.log('标签:', result.tags);
console.log('---');
});如图
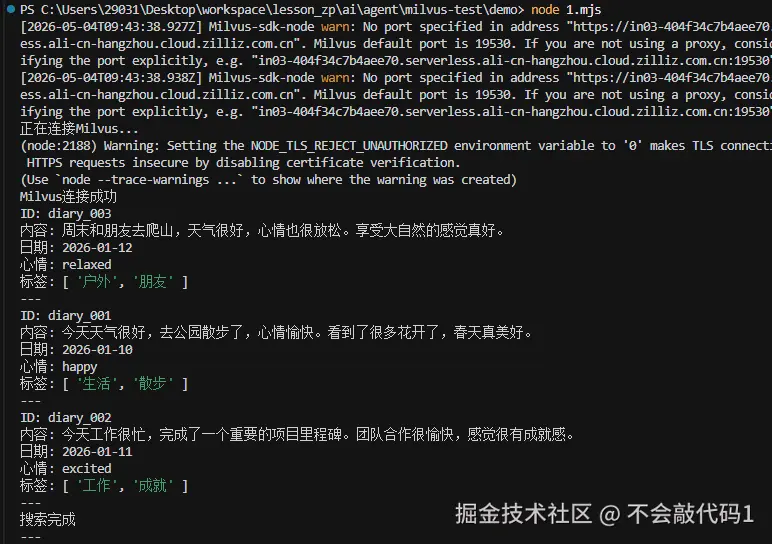 不出意外,你会看到"周末和朋友去爬山"这条日记排在前面,而纯工作或做饭的内容不会被匹配。这就是向量搜索的魅力------它理解的是语义,而非字符。
不出意外,你会看到"周末和朋友去爬山"这条日记排在前面,而纯工作或做饭的内容不会被匹配。这就是向量搜索的魅力------它理解的是语义,而非字符。
八、传统关系型 vs 向量数据库在前端眼中的分工
让我们回到开篇的对比:
- 传统数据库(MySQL):承载文章列表、详情页、基于确定条件(如日期区间、标签筛选)的查询。后端主要做 CRUD。
- 向量数据库(Milvus) :承载 ChatBot 的语义理解、智能搜索页面、推荐系统。后端除了增删改,核心增加了 embedding 生成 和 retriever 检索。
对于前端同学来说,虽然看不见向量数据库,但你使用的"智能搜索"或者"AI 对话记录查找"功能,背后几乎都有类似 Milvus 的组件在默默工作。
九、总结与展望
通过这个小小的 AI 日记项目,我们完成了:
- Milvus 实例的连接与 Collection 创建
- 使用 OpenAI Embeddings 将文本转化为向量
- 向量数据写入与索引构建
- 自然语言语义搜索的完整流程
这一切都不到 100 行核心代码。由此可以衍生出更多玩法:比如结合大语言模型实现"对话式日记检索",或者根据用户当前心情自动推荐过往的相似日记。
向量数据库已经不再是实验室里的概念,而是每一个准备拥抱 AI 的开发者工具箱中必备的武器。Milvus 作为开源领域的佼佼者,以高性能和丰富的生态,绝对值得你深入探索。
附录
完整代码
javascript
import {
MilvusClient,
DataType,
MetricType,
IndexType,
}from '@zilliz/milvus2-sdk-node'
import 'dotenv/config'
import {
OpenAIEmbeddings
} from '@langchain/openai'
const VECTOR_DIM=1024;
const COLLECTION_NAME='ai_diary';
const TOKEN=process.env.MILVUS_TOKEN;
const ADDRESS=process.env.MILVUS_ADDRESS;
const embeddings=new OpenAIEmbeddings({
apiKey:process.env.OPENAI_API_KEY,
model:process.env.EMBEDDING_MODEL_NAME,
configuration:{
baseURL:process.env.OPENAI_BASE_URL,
},
dimensions:VECTOR_DIM,
})
const client=new MilvusClient({
address:ADDRESS,
token:TOKEN,
})
//嵌入,将文本转为向量的函数封装
async function getEmbeddings(text){
const result=await embeddings.embedQuery(text);
return result;
}
async function main(){
console.log('正在连接Milvus...');
const checkHealth=await client.checkHealth();
if(!checkHealth.isHealthy){
console.log('Milvus连接失败:',checkHealth);
return;
}
console.log('Milvus连接成功');
await client.loadCollection({
collection_name:COLLECTION_NAME,
})
const query='我想看看关于户外活动的日记';
const queryVector=await getEmbeddings(query);
const searchResult=await client.search({
collection_name:COLLECTION_NAME,
vector:queryVector,
output_fields:['id','content','date','mood','tags'],
limit:3,
metric_type:MetricType.COSINE,
})
searchResult.results.forEach((result)=>{
console.log('ID:',result.id);
console.log('内容:',result.content);
console.log('日期:',result.date);
console.log('心情:',result.mood);
console.log('标签:',result.tags);
console.log('---');
})
console.log('搜索完成');
console.log('---')
/*
await client.createCollection({
collection_name:COLLECTION_NAME,
fields:[
{name:'id',data_type:DataType.VarChar,max_length:50,is_primary_key:true},
{name:'vector',data_type:DataType.FloatVector,dim:VECTOR_DIM},
{name:'content',data_type:DataType.VarChar,max_length:5000},
{name:'date',data_type:DataType.VarChar,max_length:50},
{name:'mood',data_type:DataType.VarChar,max_length:50},
{name:'tags',data_type:DataType.Array,element_type:DataType.VarChar,max_capacity:10,max_length:50}
]
})
await client.createIndex({
collection_name:COLLECTION_NAME,
field_name:'vector',//常用的查询字段
index_type:IndexType.IVF_FLAT,
metric_type:MetricType.COSINE,
params:{
nlist:VECTOR_DIM,
}
})
*/
/*
console.log('\nInserting diary entries...');
const diaryContents = [
{
id: 'diary_001',
content: '今天天气很好,去公园散步了,心情愉快。看到了很多花开了,春天真美好。',
date: '2026-01-10',
mood: 'happy',
tags: ['生活', '散步']
},
{
id: 'diary_002',
content: '今天工作很忙,完成了一个重要的项目里程碑。团队合作很愉快,感觉很有成就感。',
date: '2026-01-11',
mood: 'excited',
tags: ['工作', '成就']
},
{
id: 'diary_003',
content: '周末和朋友去爬山,天气很好,心情也很放松。享受大自然的感觉真好。',
date: '2026-01-12',
mood: 'relaxed',
tags: ['户外', '朋友']
},
{
id: 'diary_004',
content: '今天学习了 Milvus 向量数据库,感觉很有意思。向量搜索技术真的很强大。',
date: '2026-01-12',
mood: 'curious',
tags: ['学习', '技术']
},
{
id: 'diary_005',
content: '晚上做了一顿丰盛的晚餐,尝试了新菜谱。家人都说很好吃,很有成就感。',
date: '2026-01-13',
mood: 'proud',
tags: ['美食', '家庭']
}
];
console.log('Generating embeddings...');
const diaryData=await Promise.all(
diaryContents.map(async (diary)=>({
...diary,
vector:await getEmbeddings(diary.content),
}))
);
const inserRes=await client.insert({
collection_name:COLLECTION_NAME,
data:diaryData,
})
console.log(`插入成功:${inserRes.insert_cnt}条数据`)
*/
}
main();如果你也在学习向量数据库或构建 AI 应用,欢迎在评论区交流你的实践与困惑!