文章目录
- [1. 核心概念](#1. 核心概念)
-
- [1.1 向量](#1.1 向量)
- [1.2 向量相似度](#1.2 向量相似度)
- [1.3 嵌入模型](#1.3 嵌入模型)
- [2. API 架构](#2. API 架构)
-
- [2.1 通用模型 API](#2.1 通用模型 API)
- [2.2 嵌入模型 API](#2.2 嵌入模型 API)
- [2.3 嵌入模型实现类](#2.3 嵌入模型实现类)
- [3. 核心组件](#3. 核心组件)
-
- [3.1 EmbeddingModel](#3.1 EmbeddingModel)
- [3.2 EmbeddingRequest](#3.2 EmbeddingRequest)
- [3.3 EmbeddingResponse](#3.3 EmbeddingResponse)
- [3.4 Embedding](#3.4 Embedding)
- [4. 接入智谱 AI 嵌入模型](#4. 接入智谱 AI 嵌入模型)
1. 核心概念
1.1 向量
在人工智能与大模型应用领域,向量 (Embedding Vector)是指通过嵌入模型(Embedding Model)对文本、图像、音频等非结构化数据进行语义编码后,生成的固定长度、高密度、低维连续数值数组。
向量以浮点数值数组形式承载原始数据的深层语义、上下文关联与特征分布,将不可计算的自然语言与多媒体信息,转化为机器可量化、可运算、可比对的结构化数值表达:
- 向量中每一位数值,代表抽象语义特征的权重分布;
- 向量长度称为向量维度,维度越高,特征表达能力越强;
- 语义内容越相近的文本 / 素材,其对应向量在高维空间中的几何距离越近(语义越相似)。
举个直观例子,文本 A:
text
春天花开,天气温暖向量 A:
text
[0.21, 0.66, -0.11, 0.90]文本 B(语义接近):
java
春日暖和,百花开放向量 B(A 和 B 数字几乎一样):
text
[0.23, 0.64, -0.09, 0.88]文本 C(A 和 C 数字完全不一样):
text
Java 并发编程实战向量的意义:
- 文字无法直接对比「语义相似度」,数字可以
- 可以存入向量数据库,毫秒级语义检索
- 大模型不能直接记忆海量文档,靠向量做外部知识库(
RAG) - 用于实现:问答、知识库、智能搜索、内容推荐
1.2 向量相似度
可通过多种数学公式判断两个向量的相似程度,其中余弦相似度 (Cosine Similarity)是衡量两个向量方向相似程度的经典算法,通过计算两个多维向量夹角的余弦值判定相似度大小。
余弦相似度公式 :
Similarity ( A ⃗ , B ⃗ ) = cos ( θ ) = A ⃗ ⋅ B ⃗ ∥ A ⃗ ∥ ⋅ ∥ B ⃗ ∥ \text{Similarity}(\vec{A}, \vec{B}) = \cos(\theta) = \frac{\vec{A} \cdot \vec{B}}{\|\vec{A}\| \cdot \|\vec{B}\|} Similarity(A ,B )=cos(θ)=∥A ∥⋅∥B ∥A ⋅B
1.3 嵌入模型
嵌入模型(Embedding Model)是一种专门用于将非结构化数据(文本、图像、音频等)转化为结构化数值向量的 AI 模型,将不可计算的自然语言、视觉信息,映射为固定长度、高密度的浮点数数组(向量),从而让机器能够量化、比对、计算数据的语义关联。
核心特性:
- 固定长度向量 :无论输入文本长短(一句话/一篇文档),输出向量长度固定(如
1536维、2048维),便于统一存储和计算; - 语义关联性 :语义相近的输入(如"春天花开"和"春日百花绽放"),输出向量距离极近;语义无关的输入(如"春天花开"和"
Java并发编程"),向量距离极远; - 低维高密度:将高维语义信息压缩到低维向量中,兼顾计算效率和语义表达能力,避免维度灾难;
- 多模态适配:主流嵌入模型支持文本、图像等多模态输入,统一转化为向量进行处理(如文生图检索、跨模态匹配)。
核心价值:
- RAG 检索增强生成:作为知识库的核心,将企业文档、私有数据转为向量,实现毫秒级语义检索,弥补大模型知识过时、无法访问私有数据的短板(如"武惠算"AI政策计算器平台,就通过嵌入模型实现惠企政策的智能推送);
- 文本语义匹配:如问答系统、智能搜索、人岗匹配(智谱为头部招聘网站提供的人岗匹配服务,核心就是通过嵌入模型计算简历与岗位的语义相似度);
- 文本聚类与分类:如用户评论情感分类、新闻主题聚类,通过向量相似度将相似内容归为一类;
- 多模态匹配:如图片检索、文本-图片关联(将图片和描述文本转为向量,通过相似度匹配找到对应内容);
- 知识图谱构建:通过嵌入模型将知识图谱中的实体、关系转为向量,提升知识表示和推理效率。
厂商 API 模型推荐:
- 智谱
AI Embedding系列(国产首选) OpenAI Embedding(国际主流)- 阿里千问
Embedding(国产备选)
开源嵌入模型推荐:
BAAI Embedding(国产开源标杆)Sentence-BERT(国际开源主流)Word2vec(传统开源模型)
2. API 架构
接口设计两大核心目标:
- 可移植性 :接口兼容所有类型的嵌入模型,开发者无需修改业务代码,即可无缝切换
OpenAI、智谱AI、Ollama等不同厂商的嵌入服务,完全遵循Spring模块化、可替换的设计理念。 - 简洁性 :屏蔽底层嵌入算法的复杂度,提供
embed(String text)等极简方法,AI新手也能快速将嵌入向量集成到项目中。
嵌入模型(Embedding Model) API 整体架构图:
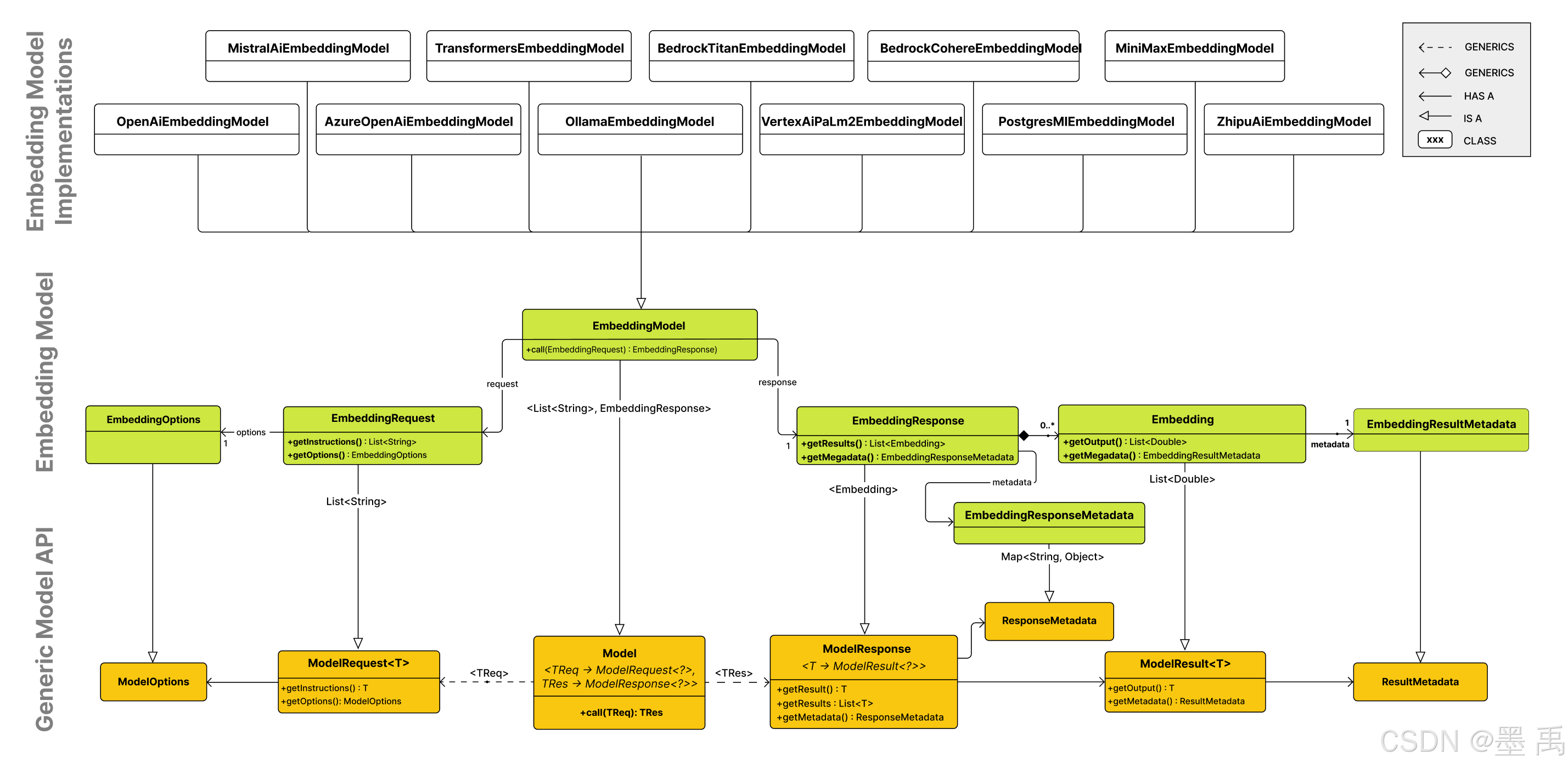
整个图从上到下分为三层:
Embedding Model Implementations:各种具体的嵌入模型实现类Embedding Model:嵌入模型领域的专用抽象Generic Model API:整个大模型体系通用的底层抽象
2.1 通用模型 API
整个框架的基础抽象层,定义了所有模型(不只是嵌入模型)都遵循的通用契约,实现了【请求 - 响应 - 结果】的标准化。
| 类名 | 核心职责 | 关键方法/关系 |
|---|---|---|
ModelOptions |
模型通用配置(如超时、重试、鉴权信息等) | 所有请求对象都包含此配置,提供基础运行参数 |
ModelRequest<T> |
通用请求模板,定义请求的统一结构 | getInstructions() 获取指令文本、getOptions() 获取配置 |
Model<TReq, TRes> |
所有模型的顶层接口,定义调用规范 | call(TReq): TRes 核心调用方法,接收请求返回响应 |
ModelResponse<T> |
通用响应模板,定义响应的统一结构 | getResult() 获取单个结果、getResults() 获取多个结果、getMetadata() 获取响应元数据 |
ModelResult<T> |
单个结果的模板,定义结果的统一结构 | getOutput() 获取结果数据、getMetadata() 获取结果元数据 |
ResponseMetadata |
通用响应元数据(如 Token 消耗、耗时、状态码等) | 存储调用过程中的附加信息 |
ResultMetadata |
通用结果元数据(如向量索引、相似度分数等) | 存储单个结果的附加信息 |
2.2 嵌入模型 API
基于通用 API,为嵌入模型量身定制的领域抽象层。
| 类名 | 核心职责 | 关键方法/关系 |
|---|---|---|
EmbeddingModel |
嵌入模型的顶层接口,继承自 Model |
call(EmbeddingRequest): EmbeddingResponse,将通用请求/响应特化为嵌入模型专用 |
EmbeddingOptions |
嵌入模型专用配置(如向量维度、模型名称等) | 继承自 ModelOptions,扩展嵌入相关的配置项 |
EmbeddingRequest |
嵌入请求对象,封装待处理的文本和配置 | getInstructions() 获取待嵌入的文本列表、getOptions() 获取嵌入配置 |
EmbeddingResponse |
嵌入响应对象,封装返回的向量结果 | getResults() 获取嵌入向量列表、getMetadata() 获取响应元数据 |
Embedding |
单个嵌入结果对象,封装向量数据 | getOutput() 获取向量数组、getMetadata() 获取结果元数据 |
EmbeddingResponseMetadata |
嵌入模型专用响应元数据 | 继承自 ResponseMetadata,补充嵌入模型相关信息 |
EmbeddingResultMetadata |
嵌入模型专用结果元数据 | 继承自 ResultMetadata,补充单个向量结果的附加信息 |
2.3 嵌入模型实现类
基于 EmbeddingModel 接口的不同厂商/模型实现。
| 实现类 | 对应模型/厂商 |
|---|---|
OpenAiEmbeddingModel |
OpenAI 嵌入模型 |
AzureOpenAiEmbeddingModel |
Azure OpenAI 嵌入模型 |
OllamaEmbeddingModel |
Ollama 本地部署嵌入模型 |
BedrockTitanEmbeddingModel |
AWS Bedrock Titan 嵌入模型 |
BedrockCohereEmbeddingModel |
AWS Bedrock Cohere 嵌入模型 |
VertexAiPaLm2EmbeddingModel |
Google Vertex AI PaLM2 嵌入模型 |
MistralAiEmbeddingModel |
Mistral AI 嵌入模型 |
TransformersEmbeddingModel |
HuggingFace Transformers 开源嵌入模型 |
PostgresMlEmbeddingModel |
Postgres ML 内置嵌入模型 |
MiniMaxEmbeddingModel |
MiniMax 嵌入模型 |
ZhipuAiEmbeddingModel |
智谱AI 嵌入模型 |
3. 核心组件
3.1 EmbeddingModel
EmbeddingModel 接口是 Spring AI 为嵌入模型集成 设计的核心接口,专注于将文本转换为数值向量(嵌入向量),是语义检索、文本分类、RAG 智能问答等场景的核心基础。
核心方法:
| 方法签名 | 功能说明 |
|---|---|
EmbeddingResponse call(EmbeddingRequest request) |
底层核心方法,执行嵌入向量请求 |
default float[] embed(String text) |
快捷方法,将单个文本字符串转换为向量 |
float[] embed(Document document) |
将 Spring AI 文档对象转换为向量 |
default List<float[]> embed(List<String> texts) |
批量将文本列表转换为向量列表 |
default List<float[]> embed(List<Document> documents, EmbeddingOptions options, BatchingStrategy batchingStrategy) |
批量将文档列表转换为向量,支持配置与分批策略 |
default EmbeddingResponse embedForResponse(List<String> texts) |
批量转换文本并返回完整的嵌入响应对象 |
default int dimensions() |
获取嵌入向量的维度(默认通过测试文本自动获取) |
关键特性:
- 支持 元数据模式(MetadataMode) :
OpenAI/智谱AI/Mistral等模型可将文档元数据一并嵌入; - 输出标准
float[]浮点数数组,直接适配所有向量数据库。
3.2 EmbeddingRequest
封装输入文本 + 模型配置(模型名称、向量维度等):
java
public class EmbeddingRequest {
private final List<String> inputs; // 待嵌入的文本列表
private final EmbeddingOptions options; // 可选配置项
}3.3 EmbeddingResponse
封装所有嵌入结果 + 响应元数据(模型信息、令牌消耗等):
java
public class EmbeddingResponse {
private List<Embedding> embeddings; // 嵌入结果集合
private EmbeddingResponseMetadata metadata; // 响应元数据
}3.4 Embedding
代表单段文本对应的嵌入向量:
java
public class Embedding {
private float[] embedding; // 最终的嵌入向量
private Integer index; // 文本序号
private EmbeddingResultMetadata metadata; // 结果元数据
}4. 接入智谱 AI 嵌入模型
Spring AI 官方支持智谱AI 的文本嵌入向量模型。
核心说明:
- 默认模型 :
embedding-2,新一代模型embedding-3(支持自定义维度) - 优先级规则 :嵌入模型专属配置(
embedding.base-url/api-key)优先级高于通用配置,支持多账号/多模型隔离使用 - 向量相关性 :向量距离越小,文本语义越相似,是
RAG检索的核心依据
目前最新的是第三代文本向量化模型:
| 模型名称 | 版本 | 上下文窗口 | 核心定位 | 典型应用场景 |
|---|---|---|---|---|
| Embedding-3 | V3 | 8K | 新一代通用向量模型,优化了长文本、多语言和复杂语义的理解能力 | 语义检索增强(RAG)、跨语言检索、复杂文档向量化、高精度分类 |
| Embedding-2 | V2 | 8K | 上一代稳定通用向量模型,成熟可靠,兼容性强 | 基础语义检索、聚类、主题建模、轻量级分类任务 |
4.1 引入依赖
Spring AI 为智谱 AI 嵌入模型提供 Spring Boot 自动配置,只需添加以下依赖:
xml
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-zhipuai</artifactId>
</dependency>4.2 获取 API Key
注册智谱账号并创建 API 密钥:
- 在智谱 AI 注册页面创建账号
- 在
API Keys页面生成访问令牌
4.3 配置属性说明
重试机制配置
前缀 spring.ai.retry 用于配置智谱 AI 嵌入模型的请求重试策略:
| 配置项 | 说明 | 默认值 |
|---|---|---|
| spring.ai.retry.max-attempts | 最大重试次数 | 10 |
| spring.ai.retry.backoff.initial-interval | 指数退避初始等待时间 | 2秒 |
| spring.ai.retry.backoff.multiplier | 退避时间乘数 | 5 |
| spring.ai.retry.backoff.max-interval | 最大退避时间 | 3分钟 |
| spring.ai.retry.on-client-errors | 4xx客户端错误是否重试 | false |
连接配置
前缀 spring.ai.zhipuai :
| 配置项 | 说明 | 默认值 |
|---|---|---|
| spring.ai.zhipuai.base-url | 智谱AI服务地址 | open.bigmodel.cn/api/paas |
| spring.ai.zhipuai.api-key | API密钥 | - |
核心配置
前缀 spring.ai.zhipuai.embedding :
| 配置项 | 说明 | 默认值 |
|---|---|---|
| spring.ai.zhipuai.embedding.base-url | 嵌入模型专属服务地址(覆盖通用配置) | - |
| spring.ai.zhipuai.embedding.api-key | 嵌入模型专属 API 密钥(覆盖通用配置) | - |
| spring.ai.zhipuai.embedding.options.model | 使用的模型名称 | embedding-2 |
| spring.ai.zhipuai.embedding.options.dimensions | 向量维度(embedding-3 默认2048) | - |
新版配置:通过
spring.ai.model.embedding启用/禁用嵌入模型
- 启用:
spring.ai.model.embedding=zhipuai(默认启用)- 禁用:
spring.ai.model.embedding=none
4.4 配置 API Key
直接配置:
yaml
spring:
ai:
zhipuai:
api-key: <你的智谱AI API密钥>通过变量配置:
yaml
spring:
ai:
zhipuai:
api-key: ${ZHIPUAI_API_KEY}在系统环境变量/.env文件中配置:
bash
export ZHIPUAI_API_KEY= AAAAAA也可以在 代码中手动配置:
java
String apiKey = System.getenv("ZHIPUAI_API_KEY");4.5 单元测试
注入 EmbeddingModel :
java
import org.junit.jupiter.api.Test;
import org.springframework.ai.document.Document;
import org.springframework.ai.embedding.*;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.util.List;
import static org.junit.jupiter.api.Assertions.*;
@SpringBootTest
public class EmbeddingModelOfficialTest {
@Autowired
@Qualifier("zhiPuAiEmbeddingModel")
private EmbeddingModel embeddingModel;
}底层核心方法 call 方法:
java
@Test
void testCall() {
// 给定测试文本
List<String> texts = List.of("Spring AI 官方接口测试", "向量模型调用");
// 构建请求
EmbeddingRequest request = new EmbeddingRequest(texts, EmbeddingOptions.builder().build());
// 执行调用
EmbeddingResponse response = embeddingModel.call(request);
// 断言
assertNotNull(response);
assertFalse(response.getResults().isEmpty());
System.out.println("call() => 结果数量:" + response.getResults().size());
}单个字符串转向量默认方法:
java
// default float[] embed(String text)
// -------------------------------------------------------------------------
@Test
void testEmbedString() {
String text = "这是一个测试文本";
float[] vector = embeddingModel.embed(text);
assertNotNull(vector);
assertTrue(vector.length > 0);
System.out.println("embed(String) => 向量维度:" + vector.length);
}Document 转向量:
java
@Test
void testEmbedDocument() {
Document document = new Document("这是用于向量化的文档内容");
float[] vector = embeddingModel.embed(document);
assertNotNull(vector);
assertTrue(vector.length > 0);
System.out.println("embed(Document) => 向量维度:" + vector.length);
}批量文本转向量默认方法:
java
// default List<float[]> embed(List<String> texts)
// -------------------------------------------------------------------------
@Test
void testEmbedListString() {
List<String> texts = List.of("文本1", "文本2", "文本3");
List<float[]> vectors = embeddingModel.embed(texts);
assertNotNull(vectors);
assertEquals(3, vectors.size());
System.out.println("embed(List<String>) => 批量向量数:" + vectors.size());
}批量文档转向量(带配置 + 分批策略)默认方法:
java
// default List<float[]> embed(List<Document> documents, EmbeddingOptions options, BatchingStrategy batchingStrategy)
@Test
void testEmbedDocumentsWithOptionsAndBatching() {
List<Document> documents = List.of(
new Document("文档1"),
new Document("文档2"),
new Document("文档3")
);
EmbeddingOptions options = EmbeddingOptions.builder().build();
BatchingStrategy batchingStrategy = new DefaultBatchingStrategy();
List<float[]> embeddings = embeddingModel.embed(documents, options, batchingStrategy);
assertNotNull(embeddings);
assertEquals(3, embeddings.size());
System.out.println("embed(documents, options, batch) => 向量数:" + embeddings.size());
}批量文本并返回完整响应默认方法:
java
// default EmbeddingResponse embedForResponse(List<String> texts)
// -------------------------------------------------------------------------
@Test
void testEmbedForResponse() {
List<String> texts = List.of("测试A", "测试B");
EmbeddingResponse response = embeddingModel.embedForResponse(texts);
assertNotNull(response);
assertEquals(2, response.getResults().size());
System.out.println("embedForResponse() => 结果数:" + response.getResults().size());
}自动获取向量维度默认方法:
java
// default int dimensions()
// -------------------------------------------------------------------------
@Test
void testDimensions() {
int dim = embeddingModel.dimensions();
assertTrue(dim > 0);
System.out.println("dimensions() => 向量维度:" + dim);
}
}4.6 进阶使用
4.6.1 自动配置
在 spring-ai-autoconfigure-model-zhipuai 配置包中提供了 ZhiPuAiEmbeddingProperties 属性配置类:
java
@ConfigurationProperties(ZhiPuAiEmbeddingProperties.CONFIG_PREFIX)
public class ZhiPuAiEmbeddingProperties extends ZhiPuAiParentProperties {
/**
* 配置前缀:spring.ai.zhipuai.embedding
* application.yml 中就是用这个前缀来配置
*/
public static final String CONFIG_PREFIX = "spring.ai.zhipuai.embedding";
/**
* 默认使用的向量模型:Embedding-2
* 对应你之前表格里的 Embedding-2
*/
public static final String DEFAULT_EMBEDDING_MODEL = ZhiPuAiApi.EmbeddingModel.Embedding_2.value;
/**
* 元数据模式:默认将文档元数据一起嵌入向量
* 用于控制是否把文档的标题、作者等元数据拼入主文本一起生成向量
*/
private MetadataMode metadataMode = MetadataMode.EMBED;
/**
* 向量模型的具体配置项:模型版本、维度等
* 默认构建器 → 默认模型 Embedding-2
*/
@NestedConfigurationProperty
private final ZhiPuAiEmbeddingOptions options = ZhiPuAiEmbeddingOptions.builder()
.model(DEFAULT_EMBEDDING_MODEL)
.build();
// ---------------- getter / setter ----------------
public ZhiPuAiEmbeddingOptions getOptions() {
return this.options;
}
public MetadataMode getMetadataMode() {
return this.metadataMode;
}
public void setMetadataMode(MetadataMode metadataMode) {
this.metadataMode = metadataMode;
}
}提供了 ZhiPuAiEmbeddingAutoConfiguration 自动配置类:
java
@AutoConfiguration(after = { RestClientAutoConfiguration.class, SpringAiRetryAutoConfiguration.class })
// 依赖加载顺序:在RestClient、SpringAI重试自动配置之后再加载
@ConditionalOnClass(ZhiPuAiApi.class)
// 类路径存在 ZhiPuAiApi 时,当前自动配置才生效
@ConditionalOnProperty(
name = SpringAIModelProperties.EMBEDDING_MODEL,
havingValue = SpringAIModels.ZHIPUAI,
matchIfMissing = true
)
// 配置项条件:
// spring.ai.embedding.model = zhipuai 时生效
// 缺失该配置项时,默认也生效
@EnableConfigurationProperties({ ZhiPuAiConnectionProperties.class, ZhiPuAiEmbeddingProperties.class })
// 绑定并注入智谱通用连接配置、向量模型专属配置
public class ZhiPuAiEmbeddingAutoConfiguration {
/**
* 注册 智谱AI向量模型 Bean
* 所有依赖自动注入:连接配置、向量配置、HTTP客户端构建器、重试、监控、异常处理器
*
* @param commonProperties 智谱全局连接配置(api-key、base-url 公共配置)
* @param embeddingProperties 智谱向量专属配置(model、metadataMode、embedding配置)
* @param restClientBuilderProvider 阻塞式 RestClient 构建器
* @param webClientBuilderProvider 响应式 WebClient 构建器
* @param retryTemplate SpringAI 重试模板
* @param responseErrorHandler 全局HTTP异常处理器
* @param observationRegistry 链路监控、观测注册器
* @param observationConvention 向量模型观测自定义规则
* @return 装配完成的 ZhiPuAiEmbeddingModel
*/
@Bean
@ConditionalOnMissingBean
// 容器中不存在自定义 ZhiPuAiEmbeddingModel 时,才创建内置实例
public ZhiPuAiEmbeddingModel zhiPuAiEmbeddingModel(
ZhiPuAiConnectionProperties commonProperties,
ZhiPuAiEmbeddingProperties embeddingProperties,
ObjectBuilder<RestClient.Builder> restClientBuilderProvider,
ObjectBuilder<WebClient.Builder> webClientBuilderProvider,
RetryTemplate retryTemplate,
ResponseErrorHandler responseErrorHandler,
ObjectProvider<ObservationRegistry> observationRegistry,
ObjectProvider<EmbeddingModelObservationConvention> observationConvention) {
// 1. 构建底层智谱API交互客户端
ZhiPuAiApi zhiPuAiApi = zhiPuAiApi(
embeddingProperties.getBaseUrl(),
commonProperties.getBaseUrl(),
embeddingProperties.getApiKey(),
commonProperties.getApiKey(),
restClientBuilderProvider.getIfAvailable(RestClient::builder),
webClientBuilderProvider.getIfAvailable(WebClient::builder),
responseErrorHandler
);
// 2. 初始化智谱向量模型实现类
ZhiPuAiEmbeddingModel embeddingModel = new ZhiPuAiEmbeddingModel(
zhiPuAiApi,
embeddingProperties.getMetadataMode(),
embeddingProperties.getOptions(),
retryTemplate,
observationRegistry.getIfUnique(() -> ObservationRegistry.NOOP)
);
// 3. 注入自定义观测规则(如果存在)
observationConvention.ifAvailable(embeddingModel::setObservationConvention);
return embeddingModel;
}
/**
* 构建 智谱AI 底层API客户端
* 配置优先级:子类专属配置 > 全局公共配置
* 1. baseUrl:embedding 独立地址 > 全局 zhipuai 地址
* 2. apiKey:embedding 独立密钥 > 全局 zhipuai 密钥
*
* @param baseUrl 向量模块独立baseUrl
* @param commonBaseUrl 全局公共baseUrl
* @param apiKey 向量模块独立apiKey
* @param commonApiKey 全局公共apiKey
* @param restClientBuilder 阻塞HTTP客户端构建器
* @param webClientBuilder 响应式HTTP客户端构建器
* @param responseErrorHandler 异常处理器
* @return 构建完成的 ZhiPuAiApi
*/
private ZhiPuAiApi zhiPuAiApi(
String baseUrl,
String commonBaseUrl,
String apiKey,
String commonApiKey,
RestClient.Builder restClientBuilder,
WebClient.Builder webClientBuilder,
ResponseErrorHandler responseErrorHandler) {
// 路由地址:优先取embedding独立配置,否则使用全局配置
String resolvedBaseUrl = StringUtils.hasText(baseUrl) ? baseUrl : commonBaseUrl;
// 密钥:优先取embedding独立密钥,否则使用全局密钥
String resolvedApiKey = StringUtils.hasText(apiKey) ? apiKey : commonApiKey;
// 强制校验:路由地址、密钥不能为空
Assert.hasText(resolvedBaseUrl, "ZhiPuAI base URL must be set");
Assert.hasText(resolvedApiKey, "ZhiPuAI API key must be set");
// 链式构建智谱API客户端
return ZhiPuAiApi.builder()
.baseUrl(resolvedBaseUrl)
.apiKey(new SimpleApiKey(resolvedApiKey))
.restClientBuilder(restClientBuilder)
.webClientBuilder(webClientBuilder)
.responseErrorHandler(responseErrorHandler)
.build();
}
}4.6.2 运行时配置选项
ZhiPuAiEmbeddingOptions 支持在请求时动态覆盖默认配置(如模型名称、维度)。
单请求指定模型示例:
java
EmbeddingResponse response = embeddingModel.call(
new EmbeddingRequest(
List.of("Hello World", "Spring AI"),
// 运行时指定模型
ZhiPuAiEmbeddingOptions.builder()
.model("embedding-3")
.dimensions(1536)
.build()
)
);4.6.3 多个嵌入模型
如果需要不同厂商模型共存,引入多个 Starter 包后,Spring AI 会自动配置多个具体类型的 EmbeddingModel ,可以使用 @Qualifier 指定:
java
@Autowired
@Qualifier("embeddingModel")
private EmbeddingModel embeddingModel;或者直接使用具体类型注入:
java
@Autowired
private ZhiPuAiEmbeddingModel zhiPuAiEmbeddingModel;