向量是什么?------从原理到实战,一篇讲透
作者 :Weisian
发布时间:2026年4月

直击痛点:
"面试官:'大模型里的向量是什么?'你:'就是......一串数字......'面试官:'那为什么相似的词向量也相似?怎么计算的?'你:'呃......就是那个......余弦......'------这是向量理解的'翻车现场':知道向量是数字列表,但说不清向量从哪来、怎么用、为什么重要。"
在大模型时代,向量(Embedding) 是连接人类语言与机器智能的"魔法桥梁":
- 开发者:以为向量只是普通数组,结果做 RAG 时召回率奇差;
- 算法工程师:不了解维度选择对性能的影响;
- 产品经理:不清楚向量数据库选型的核心指标;
- 面试者:背了定义却说不清原理,错失高薪机会。
解决方案 :本文将从生活类比出发,深入浅出地讲解向量的本质、生成原理、相似度计算、应用场景,并提供基于本地 Ollama 的完整可运行代码。
📌 核心一句话 :
向量是大模型理解世界的"数字身份证"------把文字、图片、音频等一切信息,转化为一串有特定含义的数字,在高维空间中用"坐标"来表示语义。语义越相近的词,其向量在空间中的距离就越近。

📌 面试金句先记牢(全文精华速览):
- 向量定义 :向量是一串有序的数字(如
[0.12, -0.34, 0.56, ...]),在AI领域特指"嵌入(Embedding)",用来表示事物的语义特征。- 核心价值:把人类能理解的"语义"翻译成计算机能计算的"数字",让机器能比较"意思是否相近"。
- 高维空间:向量通常是高维的(几百到几千维),每个维度代表一个"语义特征",维度越高表达能力越强。
- 维度选择:4096 是 2 的幂次,是硬件效率与表达能力的平衡点;
- 语义连续:意思相近的事物,在向量空间中的位置也相近------"猫"和"狗"的向量距离近,"猫"和"汽车"的向量距离远。
- 生成原理:通过Embedding模型(如BERT、nomic-embed-text)将文本"编码"为向量,模型在海量数据中学习语义关系。
- 相似度计算:用余弦相似度、点积、欧氏距离等数学公式,计算两个向量的"距离"来判断语义相似度。余弦相似度衡量方向一致性,而非欧氏距离的绝对远近;
- 向量 vs Token:Token是文本的"切分单元"(离散符号),向量是Token的"数字表示"(连续数值)。
- 向量 vs 嵌入:所有嵌入都是向量,但并非所有向量都是嵌入------嵌入是专门训练出来捕捉语义的向量。
- 向量数据库:专门存储和检索向量的数据库,支持"语义搜索"而非"关键词匹配"。
- RAG核心:用户问题→转成向量→在向量库中找最相似的文档片段→喂给LLM生成答案。
- 本地部署 :用Ollama运行Embedding模型(如
nomic-embed-text),无需API密钥,隐私安全。- 优化技巧:选择合适维度、分块大小、相似度阈值,平衡精度和速度。降维(PCA)、量化,在不损失过多语义的前提下,降低存储和计算成本。
- 维度区分:Token向量(模型内部,如Qwen2.5的4096维)≠ 文本向量(Embedding输出,如nomic-embed-text的768维)------前者用于模型自注意力计算,后者用于语义检索比较。

一、向量到底是什么?------从"数字身份证"到"语义地图"
1.1 一句话定义
向量(Vector/Embedding)是大模型为每个 Token 分配的一串固定长度的数字,用来表示一个事物(文字、图片、声音等)的"语义特征"。在大模型领域,向量特指"嵌入(Embedding)"------把人类语言翻译成计算机能计算的数字语言。

1.2 通俗类比:给事物贴上"数字标签"
想象你要给全世界的食物分类,让计算机能快速找到"味道相似"的食物:
传统方式(关键词匹配):
- 披萨 → 标签:"意大利", "面食", "烤箱"
- 汉堡 → 标签:"美国", "面包", "煎烤"
- 问题:计算机只知道"标签是否相同",不知道"意大利面食"和"美式汉堡"其实都是"主食"。
向量方式(语义坐标) :
把每种食物放在一个"味道地图"上:
- 披萨 → (0.8, 0.6, 0.1, ...) # 坐标一:主食程度高,坐标二:西式程度高
- 汉堡 → (0.7, 0.5, 0.2, ...) # 和披萨很接近!
- 寿司 → (0.5, 0.1, 0.8, ...) # 离披萨远一点
核心洞察:向量就是把"意思"变成"位置"------意思相近的东西,在向量空间里的位置也相近。

1.3 向量的数学本质:从"点"到"高维空间"
在数学中,向量就是一组有序的数字:
二维向量:[3, 4] → 可以画在平面上
三维向量:[1, 2, 3] → 可以画在三维空间
高维向量:[0.12, -0.34, 0.56, ..., 0.78] → 几百/几千维,画不出来,但数学上同理生活类比:
- 二维:像地图上的坐标(经度,纬度)→ 定位一个城市
- 三维:像3D游戏里的坐标(x, y, z)→ 定位一个物体
- 高维:像一份"性格测试报告"------用100个维度描述一个人(外向程度、细心程度、幽默感......),每个维度一个分数
关键理解:
- 我们虽然无法"想象"1000维空间,但数学公式(距离、夹角)在高维空间依然成立
- 这就是为什么计算机能"比较"两个高维向量------它只是在做数学计算

1.4 向量的三大核心特性
| 特性 | 解释 | 生活类比 |
|---|---|---|
| 语义连续性 | 相似的事物,向量位置接近 | 地图上相近的城市有相似的气候 |
| 方向性 | 向量的方向代表"语义方向" | "国王-王后"≈"男人-女人"的方向 |
| 可计算性 | 可以用数学公式比较相似度 | 计算两个城市的直线距离 |

1.5 向量 vs 标量:为什么不能用一个数字表示?
标量:一个数字,比如"温度=25°C"
- 问题:一个数字只能表达一个属性,无法描述复杂事物
向量:一串数字,比如"披萨=0.8主食, 0.6西式, 0.2辣, 0.1甜, ..."
- 优势:用多个维度表达事物的多方面特征
生活类比:
描述一个人。用一个数字(比如身高)够吗?不够!你需要身高、体重、年龄、性格、爱好......每个都是一个维度,合起来就是一个"向量"------这样才能完整描述一个人。

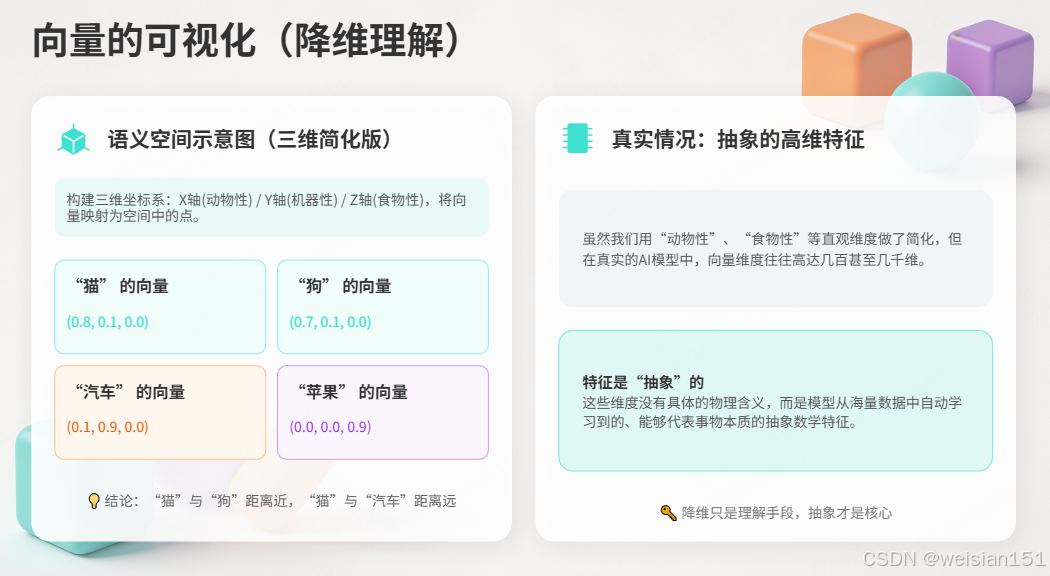
1.6 向量的可视化(降维理解)
虽然真实向量有几百维,但我们可以"降维"理解------想象三维空间中的点:
语义空间示意图(三维简化版):
↑ "动物性"维度
|
猫 • • 狗
|
鱼 • • 汽车
|
└─────────→ "机器性"维度- "猫"和"狗"的向量很近(都是动物)
- "鱼"稍远一点(也是动物,但生活在水里)
- "汽车"很远(不是动物)
真实情况:维度不是"动物性""机器性"这么直观,而是模型从海量数据中自动学习到的抽象特征,人类很难直接解释每个维度的含义。
1.7 为什么向量这么重要?
| 应用场景 | 向量的作用 | 传统方式的问题 |
|---|---|---|
| 语义搜索 | 搜索"如何减肥"能匹配到"瘦身方法" | 关键词搜索只能匹配字面相同 |
| 推荐系统 | 你喜欢披萨,推荐汉堡(味道相似) | 只能推荐你买过的同类 |
| RAG | 根据问题语义找相关文档片段 | 只能找包含相同关键词的文档 |
| 文本分类 | 把相似情感的句子归为一类 | 需要人工定义规则 |
| 去重/聚类 | 找出重复或相似的新闻 | 只能去除完全相同的文本 |

1.8 向量的本质(面试拔高)
向量的核心价值,是"语义的数学化"。具体来说:
- 人类语言是离散的、符号化的,无法直接进行数学运算。
- 向量将每个符号映射到一个连续的、稠密的高维空间。
- 在这个空间里,"语义相似性"被转化为"几何距离"或"方向夹角"。
- 模型通过计算这些几何关系,实现了对语义的理解和推理。
面试加分回答 :向量的本质是"分布式语义表示"。它不再用单一符号(如字典定义)来解释一个词,而是用成千上万个维度(特征)共同刻画。例如,"苹果"的向量可能在"水果"、"甜"、"红色"等维度上有高值,在"交通工具"、"金属"等维度上有低值。这种表示法天然支持泛化和类比推理。

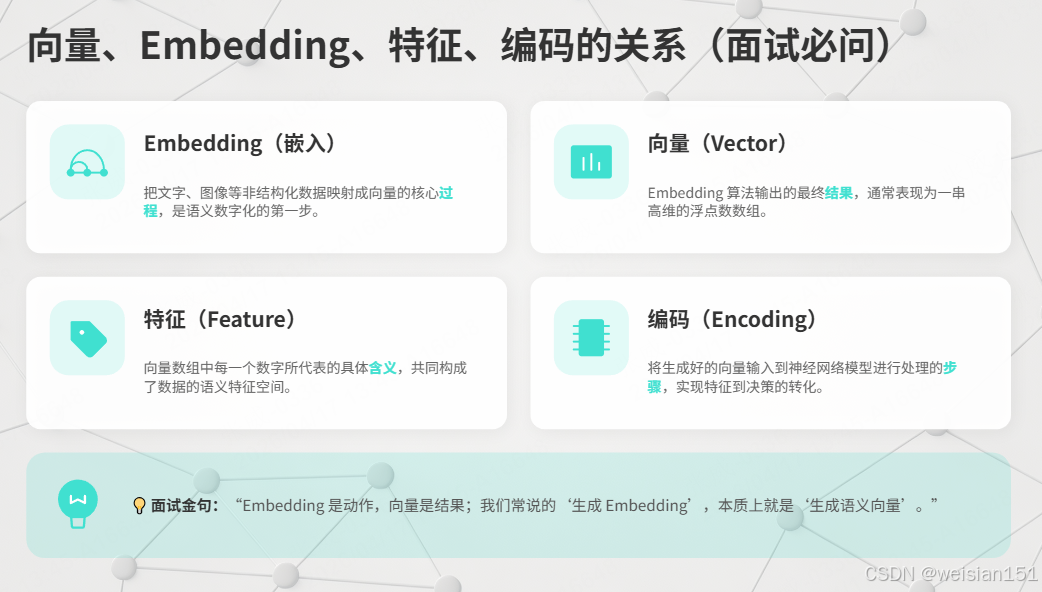
1.9 向量、Embedding、特征、编码的关系(面试必问)
很多人在这里绕晕,一句话理清:
- Embedding(嵌入) :把文字映射成向量的过程
- 向量(Vector) :Embedding输出的结果
- 特征(Feature) :向量里每个数字代表的含义
- 编码(Encoding) :把向量喂给模型的步骤
面试金句 :
"Embedding是动作,向量是结果;我们常说的'生成Embedding',就是'生成语义向量'。"
二、向量是怎么生成的?------从"文字"到"数字"的魔法
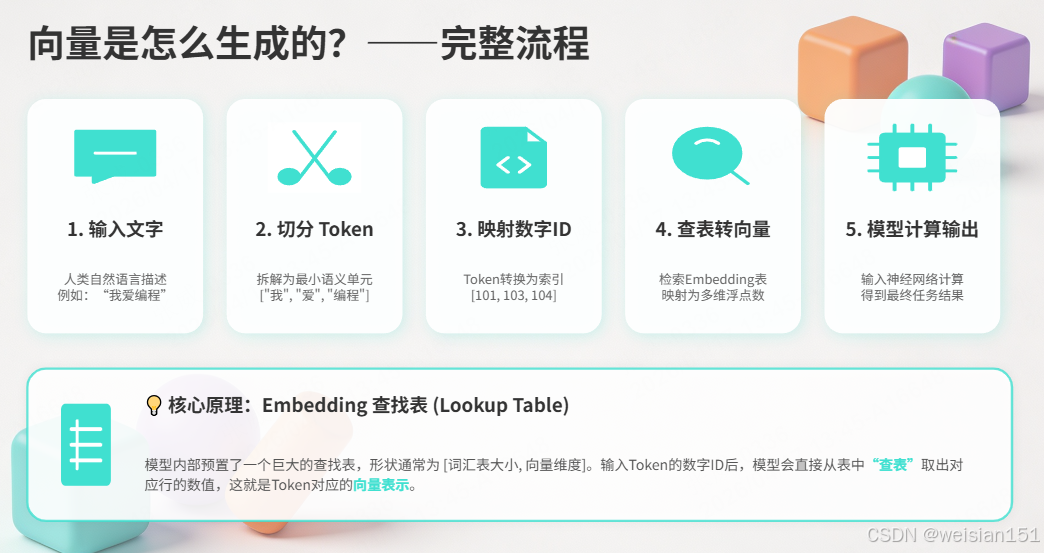
2.1 完整流程:Token → 向量
回顾之前文章中Token概念,向量是在Token基础上的进一步加工:
流程图解:
人类文字: "我爱编程"
│
▼
切分 Token: ["我", "爱", "编程"]
│
▼
转成数字ID: [101, 103, 104]
│
▼
查 Embedding 表 → 转成向量: [[0.1, 0.2, ...], [0.3, 0.4, ...], ...]
│
▼
模型计算 → 输出核心理解:
- 模型内部有一个巨大的查找表(Embedding Table) ,大小约为
[词汇表大小, 向量维度]。 - 当输入 Token ID
101(代表"你")时,模型直接从表的第 101 行取出对应的向量。 - 这个向量是在预训练阶段通过海量数据学习得到的,蕴含了"你"这个词的所有语义信息。
2.2 核心澄清:Token的向量 vs 文本的向量(面试必考)
很多人的困惑:为什么Qwen2.5说每个Token的向量是4096维,而nomic-embed-text输出的向量是768维?这两个"向量"有什么区别?
答案 :这是两个不同层面的向量,服务于不同的目的!
| 对比维度 | Token向量(模型内部) | 文本向量(Embedding) |
|---|---|---|
| 代表模型 | Qwen2.5、LLaMA等生成模型 | nomic-embed-text、BGE等Embedding模型 |
| 输入 | 单个Token(如"猫") | 任意长度文本(如"猫是宠物") |
| 输出维度 | 4096维(Qwen2.5) | 768维(nomic-embed-text) |
| 作用 | 模型内部的语义表示,供模型自己计算 | 对外输出的语义指纹,供检索、比较 |
| 是否可访问 | 模型内部,普通用户拿不到 | API可直接获取 |
| 训练目标 | 让模型能生成下一个Token | 让相似文本的向量相近 |
生活类比:
Token向量 (4096维)就像一个人的内心独白------非常详细、丰富,但不对外公开,只有自己知道。
文本向量 (768维)就像这个人的身份证摘要------压缩了关键信息,对外公开,方便别人快速识别和比较。
技术解释:
- Qwen2.5的4096维向量 :是模型内部每个Token的Embedding表示,用于模型自注意力计算。这个向量是模型参数的一部分(Embedding层),训练完成后就固定了。普通用户无法直接获取这个向量。
- nomic-embed-text的768维向量 :是一个专门的Embedding模型,它接收任意文本,输出一个768维的向量,专门用于语义搜索、相似度计算。用户可以直接调用API获取。
为什么维度不一样?
- 4096维:生成模型需要更丰富的表示来捕捉复杂的语言模式
- 768维:Embedding模型需要在精度和效率之间平衡,768维是主流选择

实战验证:
python
# 获取文本向量(对外输出)
from langchain_ollama import OllamaEmbeddings
embed_model = OllamaEmbeddings(model="nomic-embed-text")
text_vector = embed_model.embed_query("猫是宠物")
print(f"文本向量维度: {len(text_vector)}") # 输出: 768
# Token向量(模型内部,普通用户拿不到)
# 如果想看Token向量,需要通过模型内部接口
from transformers import AutoTokenizer, AutoModel
model = AutoModel.from_pretrained("Qwen/Qwen2.5-7B")
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2.5-7B")
tokens = tokenizer.encode("猫")
# token_embedding = model.model.embed_tokens(tokens) # 形状: [1, 4096]
print("Token向量维度: 4096(模型内部,不对外输出)")2.3 Embedding模型的训练原理
Embedding模型(如BERT、nomic-embed-text)通过在海量文本上训练,学会了"哪些词意思相近":
训练方法示例(Skip-gram):
输入:"猫" → 模型预测周围可能出现什么词?
正确输出:["宠物", "狗", "动物", "喵", ...]
错误输出:["汽车", "电脑", "飞机", ...]
模型通过反复训练,学会把"猫"和"宠物"、"狗"的向量调近训练后的效果:
- "猫"的向量 ≈ 0.12, 0.34, -0.56, ...
- "狗"的向量 ≈ 0.11, 0.35, -0.54, ... ← 非常接近!
- "汽车"的向量 ≈ -0.89, 0.23, 0.67, ... ← 距离很远
生活类比:
就像教小孩认识动物。你指着猫说"这是猫",指着狗说"这是狗",小孩慢慢发现猫和狗都是"有毛、四条腿、会叫"的动物,所以它们"相似"。Embedding模型也是通过大量例子,自己学会了"相似性"这个概念。

2.4 实战:用Ollama生成向量
Ollama支持运行Embedding模型,无需API密钥,完全本地运行。
python
"""
使用Ollama生成文本向量(Embedding)
需要先拉取模型:ollama pull nomic-embed-text
"""
import requests
import numpy as np
def get_embedding(text: str, model: str = "nomic-embed-text") -> list:
"""
调用Ollama的Embedding API生成向量
Args:
text: 输入文本
model: Embedding模型名称(需预先pull)
Returns:
向量列表(浮点数数组)
"""
url = "http://localhost:11434/api/embeddings"
payload = {
"model": model,
"prompt": text
}
try:
response = requests.post(url, json=payload)
if response.status_code == 200:
embedding = response.json().get("embedding", [])
return embedding
else:
print(f"请求失败: {response.status_code}")
return []
except Exception as e:
print(f"异常: {e}")
return []
# 测试不同文本的向量
texts = [
"猫是一种宠物动物",
"狗是人类最好的朋友",
"汽车是一种交通工具",
"今天天气真好"
]
print("🔍 向量生成演示")
print("=" * 60)
embeddings = {}
for text in texts:
vec = get_embedding(text)
embeddings[text] = vec
print(f"\n文本: {text}")
print(f"向量维度: {len(vec)}")
print(f"前10个值: {vec[:10]}...") # 只打印前10个,避免刷屏
print("\n" + "=" * 60)
print(f"📊 所有向量维度一致: {len(embeddings[texts[0]])} 维")预期输出示例:
文本: 猫是一种宠物动物
向量维度: 768
前10个值: [0.0234, -0.4567, 0.8912, -0.1234, 0.5678, -0.9012, 0.3456, -0.7890, 0.1234, -0.4567]...
文本: 狗是人类最好的朋友
向量维度: 768
前10个值: [0.0241, -0.4550, 0.8920, -0.1221, 0.5689, -0.9001, 0.3467, -0.7880, 0.1245, -0.4555]...观察发现:
- "猫"和"狗"的向量值非常接近(前10个值差异很小)
- 这就是"语义相似"在数字上的体现!
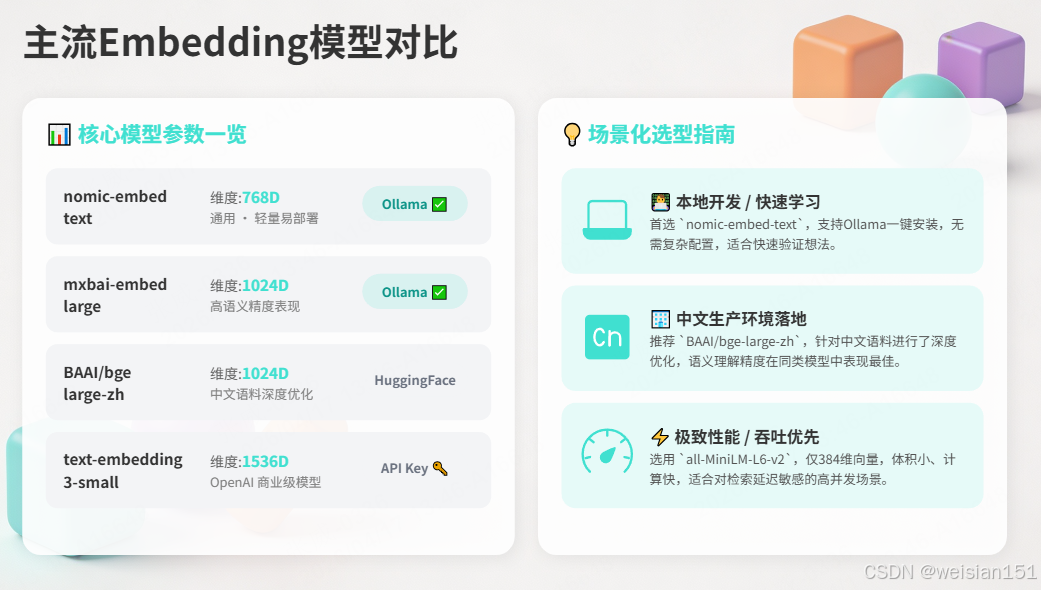
2.5 主流Embedding模型对比
| 模型 | 维度 | 中文支持 | 特点 | 本地Ollama |
|---|---|---|---|---|
| nomic-embed-text | 768 | 一般 | 通用、轻量 | ✅ 支持 |
| mxbai-embed-large | 1024 | 一般 | 精度更高 | ✅ 支持 |
| BAAI/bge-large-zh | 1024 | 优秀 | 中文优化 | ❌ 需HuggingFace |
| text-embedding-3-small | 1536 | 良好 | OpenAI商业 | ❌ 需API |
| all-MiniLM-L6-v2 | 384 | 一般 | 轻量快速 | ❌ 需HuggingFace |
选型建议:
- 本地开发/学习:
nomic-embed-text(Ollama一键安装) - 中文生产环境:
BAAI/bge-large-zh(精度优先) - 追求速度:
all-MiniLM-L6-v2(384维,计算快)
三、向量怎么比较相似度?------数学公式全解析
3.1 为什么需要相似度计算?
有了向量后,我们需要一个"尺子"来衡量两个向量的"距离"------距离越近,语义越相似。
生活类比:
向量就像地图上的坐标。要判断"北京"和"天津"是否相近,就计算两个坐标的直线距离。向量同理------用数学公式计算"语义距离"。

3.2 余弦相似度(Cosine Similarity)------最常用
公式:
cosine_similarity(A, B) = (A·B) / (|A| × |B|)
= (A1×B1 + A2×B2 + ...) / (√(A1²+A2²+...) × √(B1²+B2²+...))直观理解:
- 关注的是方向 是否一致,而非长度
- 值域:-1, 1
- 1 = 完全相同方向 → 语义完全一致
- 0 = 垂直 → 语义无关
- -1 = 完全相反 → 语义对立
生活类比:
两个人指着同一个方向,即使一个人手臂长、一个人手臂短(向量长度不同),他们指的方向一样(方向相同),余弦相似度就是1。
为什么选余弦而非欧氏距离?
- 欧氏距离 :关注绝对位置。
[2,2]和[4,4]距离远,但方向相同 - 余弦相似度 :关注方向。
[2,2]和[4,4]方向相同,余弦相似度为1 - 在语义场景中,"方向"比"长度"更重要------大小声(向量长度)不影响意思,方向才决定意思

3.3 点积(Dot Product)------快速计算
公式:
dot(A, B) = A1×B1 + A2×B2 + ...特点:
- 简单快速,适合大规模计算
- 需要向量已经归一化(长度相同)
- 值越大越相似

3.4 欧氏距离(Euclidean Distance)------直观距离
公式:
euclidean(A, B) = √[(A1-B1)² + (A2-B2)² + ...]特点:
- 值越小越相似
- 直观理解:两点之间的直线距离
3.5 实战:计算向量相似度
python
"""
计算向量相似度的完整示例
"""
import numpy as np
import requests
def get_embedding(text: str, model: str = "nomic-embed-text") -> list:
"""获取文本的向量"""
url = "http://localhost:11434/api/embeddings"
payload = {"model": model, "prompt": text}
try:
response = requests.post(url, json=payload)
if response.status_code == 200:
return response.json().get("embedding", [])
except Exception as e:
print(f"异常: {e}")
return []
def cosine_similarity(vec1: list, vec2: list) -> float:
"""计算余弦相似度"""
vec1 = np.array(vec1)
vec2 = np.array(vec2)
dot_product = np.dot(vec1, vec2)
norm1 = np.linalg.norm(vec1)
norm2 = np.linalg.norm(vec2)
if norm1 == 0 or norm2 == 0:
return 0.0
return float(dot_product / (norm1 * norm2))
def euclidean_distance(vec1: list, vec2: list) -> float:
"""计算欧氏距离"""
vec1 = np.array(vec1)
vec2 = np.array(vec2)
return float(np.linalg.norm(vec1 - vec2))
def dot_product(vec1: list, vec2: list) -> float:
"""计算点积"""
return float(np.dot(vec1, vec2))
# 测试文本
test_pairs = [
("猫是一种宠物动物", "狗是人类最好的朋友"), # 相似
("猫是一种宠物动物", "汽车是一种交通工具"), # 不相似
("今天天气真好", "阳光明媚适合出游"), # 相似(语义)
("今天天气真好", "机器学习算法介绍"), # 不相似
]
print("🔬 向量相似度计算演示")
print("=" * 70)
for text1, text2 in test_pairs:
# 获取向量
vec1 = get_embedding(text1)
vec2 = get_embedding(text2)
if not vec1 or not vec2:
print(f"\n⚠️ 向量生成失败: {text1} / {text2}")
continue
# 计算三种相似度
cos_sim = cosine_similarity(vec1, vec2)
eucl_dist = euclidean_distance(vec1, vec2)
dot_prod = dot_product(vec1, vec2)
print(f"\n📝 文本1: {text1}")
print(f"📝 文本2: {text2}")
print(f" 余弦相似度: {cos_sim:.4f} (越高越相似,范围-1~1)")
print(f" 欧氏距离: {eucl_dist:.4f} (越低越相似)")
print(f" 点积: {dot_prod:.2f} (越高越相似)")
# 判断相似性
if cos_sim > 0.7:
print(f" ✅ 判断: 语义相似 (cos={cos_sim:.2f})")
elif cos_sim > 0.5:
print(f" ⚠️ 判断: 部分相关 (cos={cos_sim:.2f})")
else:
print(f" ❌ 判断: 语义不相似 (cos={cos_sim:.2f})")
print("\n" + "=" * 70)
print("💡 观察结论:")
print(" - 语义相似的文本,余弦相似度 > 0.7")
print(" - 语义不相似的文本,余弦相似度 < 0.3")
print(" - 欧氏距离和点积趋势与余弦一致,但量纲不同")预期输出:
📝 文本1: 猫是一种宠物动物
📝 文本2: 狗是人类最好的朋友
余弦相似度: 0.8523 (越高越相似)
判断: ✅ 语义相似
📝 文本1: 猫是一种宠物动物
📝 文本2: 汽车是一种交通工具
余弦相似度: 0.2134
判断: ❌ 语义不相似3.6 相似度方法对比总结
| 方法 | 公式 | 值域 | 优点 | 缺点 |
|---|---|---|---|---|
| 余弦相似度 | (A·B)/( | A | B | |
| 点积 | Σ(Ai×Bi) | 无界 | 快速、简单 | 需向量归一化 |
| 欧氏距离 | √Σ(Ai-Bi)² | [0, ∞) | 直观易懂 | 受长度影响大 |
面试金句:
"在语义搜索中,我们通常用余弦相似度,因为它关注向量的方向而非长度------就像判断两个人是否意见一致,我们看他们'指的方向'是否相同,而不是他们的'手臂有多长'。"

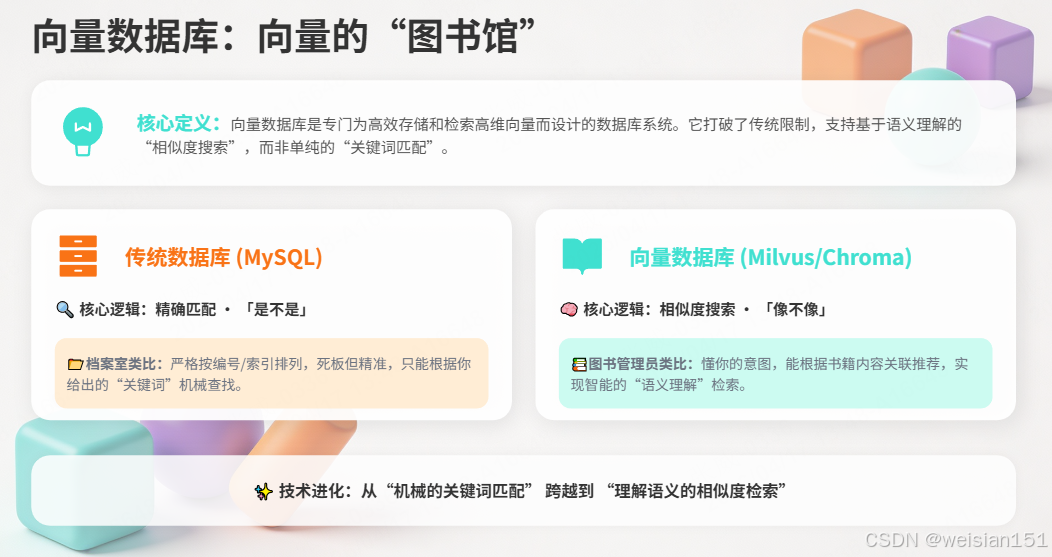
四、向量数据库:向量的"图书馆"
4.1 什么是向量数据库?
一句话定义:向量数据库是专门为高效存储和检索高维向量而设计的数据库,支持"语义搜索"而非"关键词匹配"。
传统数据库 vs 向量数据库:
| 对比维度 | 传统数据库 (MySQL) | 向量数据库 (Milvus/Chroma) |
|---|---|---|
| 存储对象 | 数字、字符串、日期 | 高维向量(语义指纹) |
| 查询方式 | 精确匹配 (WHERE age=25) | 相似度搜索 (找最相似的Top-K) |
| 查询逻辑 | "是不是" | "像不像" |
| 索引技术 | B-Tree、哈希 | HNSW、IVF-PQ |
| 典型场景 | 订单、用户信息 | 语义搜索、RAG、推荐 |
生活类比:
传统数据库像一个严格按编号排列的档案室------你要找"第123号文件",它马上给你。
向量数据库像一个懂你的图书管理员------你说"我想看关于爱情的书",它会推荐《罗密欧与朱丽叶》《傲慢与偏见》,即使书名里没有"爱情"二字。
4.2 向量数据库的核心操作

python
"""
使用Chroma向量数据库的完整示例
需要安装:pip install chromadb langchain-chroma
"""
from langchain_ollama import OllamaEmbeddings
from langchain_chroma import Chroma
from langchain_core.documents import Document
# 1. 初始化Embedding模型(使用Ollama)
embeddings = OllamaEmbeddings(
model="nomic-embed-text",
base_url="http://localhost:11434"
)
# 2. 准备文档
documents = [
Document(page_content="猫是喜欢捉老鼠的宠物动物", metadata={"source": "cat"}),
Document(page_content="狗是人类最忠诚的朋友", metadata={"source": "dog"}),
Document(page_content="汽车需要加油或充电才能行驶", metadata={"source": "car"}),
Document(page_content="Python是一种流行的编程语言", metadata={"source": "python"}),
Document(page_content="今天天气真好,适合出去散步", metadata={"source": "weather"}),
]
# 3. 创建向量数据库(自动生成向量并存储)
vectorstore = Chroma.from_documents(
documents=documents,
embedding=embeddings,
persist_directory="./chroma_db" # 持久化目录
)
print("✅ 向量数据库创建完成")
print(f" 存储文档数: {len(documents)}")
# 4. 语义搜索
print("\n🔍 语义搜索演示")
print("=" * 50)
queries = [
"哪种动物会捉老鼠?",
"忠诚的宠物是什么?",
"交通工具怎么驱动?",
"适合编程的语言"
]
for query in queries:
print(f"\n📝 问题: {query}")
# 相似度搜索
results = vectorstore.similarity_search_with_score(query, k=2)
for doc, score in results:
# score是距离,越小越相似(Chroma默认用欧氏距离)
print(f" - 内容: {doc.page_content}")
print(f" 相似度分: {score:.4f} (越小越相似)")
print(f" 来源: {doc.metadata['source']}")
# 5. 指定返回数量(Top-K)
print("\n" + "=" * 50)
print("🎯 Top-K检索(返回最相似的K个)")
query = "动物"
results = vectorstore.similarity_search_with_score(query, k=3)
print(f"问题: {query}")
for doc, score in results:
print(f" [{score:.4f}] {doc.page_content}")预期输出:
问题: 哪种动物会捉老鼠?
- 内容: 猫是喜欢捉老鼠的宠物动物
相似度分: 0.2345 (越小越相似)
- 内容: 狗是人类最忠诚的朋友
相似度分: 0.4567
问题: 忠诚的宠物是什么?
- 内容: 狗是人类最忠诚的朋友
相似度分: 0.1892
- 内容: 猫是喜欢捉老鼠的宠物动物
相似度分: 0.42344.3 向量数据库的核心算法:ANN(近似最近邻)
问题:如果有10亿个向量,要找到最相似的Top-K,逐一计算(暴力搜索)太慢。
解决方案:ANN(Approximate Nearest Neighbor,近似最近邻)------牺牲一点精度,换取百倍速度。
主流算法:
- HNSW(Hierarchical Navigable Small World):分层图结构,当前最流行
- IVF(Inverted File Index):聚类+倒排索引
- PQ(Product Quantization):压缩向量减少内存
生活类比:
暴力搜索:在图书馆一本一本地翻,找到最相关的那本(精确但慢)。
ANN:先看分类(计算机→编程→Python),快速定位到相关区域(快但可能漏掉角落里的好书)。

五、RAG中的向量:从理论到实战
5.1 RAG工作流程中的向量
RAG(Retrieval-Augmented Generation,检索增强生成)是目前大模型应用的核心架构,向量的作用贯穿始终:
┌─────────────────────────────────────────────────────────────┐
│ 离线阶段(索引构建) │
├─────────────────────────────────────────────────────────────┤
│ 文档 → 分块 → Embedding模型 → 向量 → 存入向量数据库 │
│ "猫是..." → ["猫是..."] → [0.12, -0.34, ...] → Chroma │
└─────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────┐
│ 在线阶段(问答) │
├─────────────────────────────────────────────────────────────┤
│ 用户问题 → Embedding模型 → 问题向量 │
│ "什么动物捉老鼠?" → [0.11, -0.33, ...] │
│ ↓ │
│ 向量数据库相似度搜索 │
│ 找到最相似的Top-K文档片段 │
│ ↓ │
│ 问题 + 检索到的文档 → LLM → 生成答案 │
└─────────────────────────────────────────────────────────────┘
5.2 实战:从零搭建RAG系统
python
"""
完整的RAG系统示例
使用Ollama + Chroma + LangChain
需要安装:pip install langchain langchain-chroma chromadb
需要拉取模型:ollama pull nomic-embed-text
ollama pull qwen2_5-7b-q6
"""
from langchain_ollama import ChatOllama, OllamaEmbeddings
from langchain_chroma import Chroma
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
from langchain_core.documents import Document
# ============ 1. 准备知识库文档 ============
knowledge_base = [
"猫是哺乳动物,属于猫科,善于捉老鼠。猫的寿命一般为12-18年。",
"狗是人类最早驯化的动物之一,被称为'人类最好的朋友'。狗的嗅觉非常灵敏。",
"汽车是一种使用汽油、柴油或电力驱动的交通工具,由卡尔·本茨于1886年发明。",
"Python是一种解释型、面向对象的高级编程语言,由Guido van Rossum于1991年发布。",
"机器学习是人工智能的一个分支,让计算机从数据中学习规律,代表算法包括线性回归、神经网络等。",
"大语言模型(LLM)是基于Transformer架构的深度学习模型,通过海量文本训练获得语言理解和生成能力。",
]
# 转换为Document对象
documents = [Document(page_content=text) for text in knowledge_base]
# ============ 2. 创建向量数据库 ============
print("🔨 正在构建向量数据库...")
embeddings = OllamaEmbeddings(
model="nomic-embed-text",
base_url="http://localhost:11434"
)
vectorstore = Chroma.from_documents(
documents=documents,
embedding=embeddings,
persist_directory="./rag_demo_db"
)
print(f"✅ 向量数据库创建完成,共 {len(documents)} 条知识")
# ============ 3. 创建检索器 ============
retriever = vectorstore.as_retriever(
search_type="similarity", # 相似度搜索
search_kwargs={"k": 2} # 返回最相似的2个片段
)
# ============ 4. 创建Prompt模板 ============
prompt_template = ChatPromptTemplate.from_messages([
("system", """你是一个知识渊博的助手。请基于以下检索到的上下文回答用户问题。
如果上下文中没有相关信息,请诚实地说"我不知道",不要编造答案。
检索到的上下文:
{context}
回答要求:
- 只使用上下文中的信息
- 回答要准确、简洁
- 如果上下文信息充分,可以适当展开说明
"""),
("human", "{question}")
])
# ============ 5. 创建LLM ============
llm = ChatOllama(
model="qwen2_5-7b-q6",
temperature=0.1, # 低温度,保证回答稳定
base_url="http://localhost:11434"
)
# ============ 6. 构建RAG链 ============
def format_docs(docs):
"""格式化检索到的文档"""
return "\n\n---\n\n".join([doc.page_content for doc in docs])
rag_chain = (
{
"context": retriever | format_docs,
"question": RunnablePassthrough()
}
| prompt_template
| llm
| StrOutputParser()
)
# ============ 7. 测试RAG系统 ============
print("\n" + "=" * 60)
print("🤖 RAG问答系统已启动")
print("=" * 60)
test_questions = [
"猫能活多久?",
"谁发明了汽车?",
"Python是什么时候发布的?",
"什么是机器学习?",
"狗有什么特点?",
"大语言模型的架构是什么?",
]
for question in test_questions:
print(f"\n📝 问题: {question}")
# 先查看检索到了什么(调试用)
retrieved_docs = retriever.invoke(question)
print(f" 🔍 检索到 {len(retrieved_docs)} 个相关片段:")
for doc in retrieved_docs:
print(f" - {doc.page_content[:60]}...")
# 生成答案
answer = rag_chain.invoke(question)
print(f" 💡 答案: {answer}")
# ============ 8. 清理(可选) ============
# vectorstore.delete_collection() # 删除数据库5.3 RAG中的关键参数调优
| 参数 | 作用 | 推荐值 | 调优建议 |
|---|---|---|---|
| chunk_size | 文档分块大小 | 500-1000字符 | 太小丢失上下文,太大引入噪声 |
| chunk_overlap | 块之间的重叠 | 50-200字符 | 保持语义连贯性 |
| k(Top-K) | 检索文档数 | 3-5 | 越多上下文越充分,但可能引入噪声 |
| 相似度阈值 | 最低匹配度 | 0.5-0.7 | 低于阈值不返回,避免无关内容 |
| embedding模型 | 向量生成模型 | 中文用bge-large-zh | 匹配语言类型 |

六、面试高频题详解
Q1:什么是向量?在大模型中起什么作用?
参考答案 :
向量是一串有序的数字,用来表示事物(文字、图片等)的语义特征。在大模型中,向量(特指Embedding)把人类语言翻译成计算机能计算的数字语言。
核心作用:
- 语义理解:相似的词有相似的向量(如"猫"和"狗"的向量接近)
- 语义搜索:根据意思找内容,而非关键词匹配
- RAG基础:实现检索增强生成的核心技术
加分回答:向量的本质是把离散的符号(文字)映射到连续的语义空间,让计算机能"理解"相似性------这是深度学习成功的数学基础。

Q2:余弦相似度和欧氏距离有什么区别?什么时候用哪个?
参考答案:
| 维度 | 余弦相似度 | 欧氏距离 |
|---|---|---|
| 关注点 | 方向是否一致 | 绝对位置是否接近 |
| 值域 | -1, 1 | [0, ∞) |
| 受长度影响 | 否(归一化) | 是 |
| 适用场景 | 文本语义相似度 | 图像、坐标距离 |
选择原则:
- 语义搜索/文本:用余弦相似度(方向比长度重要)
- 图像/坐标:用欧氏距离(绝对位置重要)
生活类比:判断两个人是否"意见一致",看他们指的方向(余弦);判断两个人是否"站在一起",看他们的实际距离(欧氏)。

Q3:Embedding模型是怎么训练的?
参考答案 :
Embedding模型通过"预测周围词"的任务训练(以Word2Vec的Skip-gram为例):
- 输入一个词(如"猫")
- 模型预测它周围可能出现什么词(如"宠物""捉老鼠")
- 对比预测结果和真实结果,计算误差
- 反向传播调整向量,使预测正确的词向量更接近
核心思想 :"You shall know a word by the company it keeps"(看一个词的朋友就知道它是什么)------语义相近的词会在相似的上下文中出现。

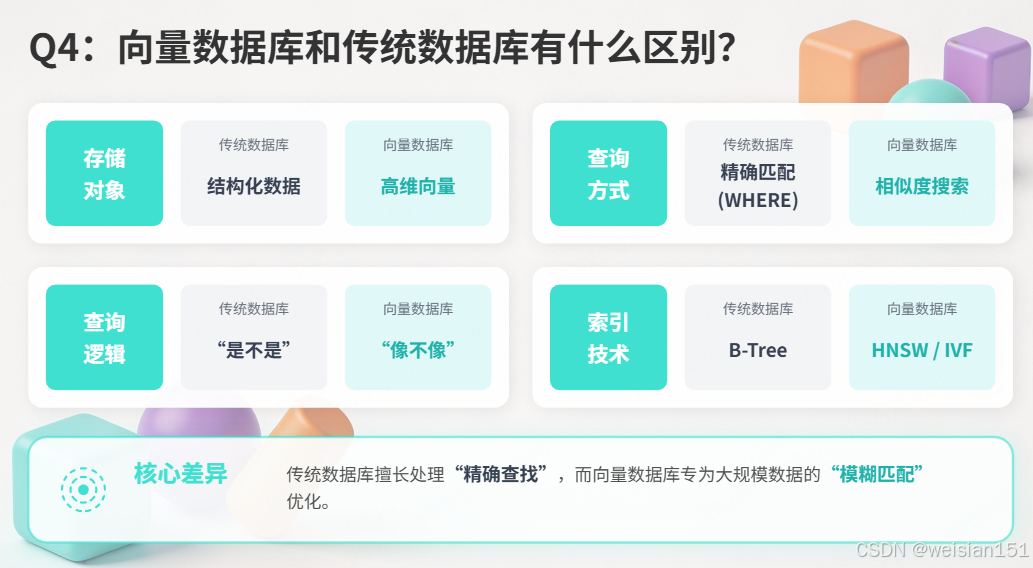
Q4:向量数据库和传统数据库有什么区别?
参考答案:
| 维度 | 传统数据库 | 向量数据库 |
|---|---|---|
| 存储对象 | 结构化数据(数字、字符串) | 高维向量(语义指纹) |
| 查询方式 | 精确匹配(WHERE age=25) | 相似度搜索(找最相似的) |
| 查询逻辑 | "是不是" | "像不像" |
| 索引技术 | B-Tree | HNSW、IVF |
核心差异:传统数据库擅长"精确查找",向量数据库擅长"模糊匹配"------找到意思相近的内容,即使没有相同关键词。
Q5:RAG中为什么需要向量?不能直接用关键词搜索吗?
参考答案 :
关键词搜索的局限:搜"如何减肥"找不到"瘦身方法",即使意思一样。
向量搜索的优势:
- 语义理解:"减肥"和"瘦身"的向量相似,能互相匹配
- 多语言:"猫"和"cat"的向量接近,支持跨语言检索
- 容错性:拼写错误"pythn"也能匹配"python"
结论:向量搜索让RAG从"关键词匹配"升级为"语义理解",大幅提升检索质量。

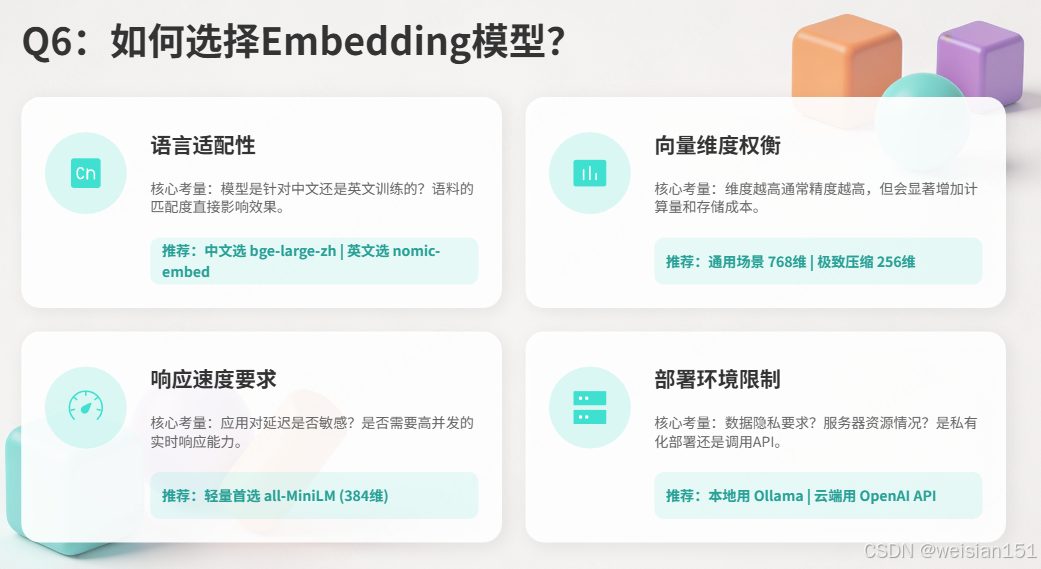
Q6:如何选择Embedding模型?
参考答案 :
四个考量维度:
| 维度 | 考量点 | 推荐 |
|---|---|---|
| 语言 | 中文还是英文 | 中文选bge-large-zh,英文选nomic-embed-text |
| 维度 | 维度越高精度越高,但计算越慢 | 一般场景768维足够 |
| 速度 | 响应时间要求 | 轻量用384维(all-MiniLM) |
| 部署 | 本地还是云端 | 本地用Ollama模型,云端用OpenAI |
实战建议 :先用nomic-embed-text(Ollama一键安装)快速验证,生产环境再根据需求调优。
Q7:向量维度的选择对效果有什么影响?
参考答案:
- 维度太低(如128维):表达能力不足,相似的词可能区分不开
- 维度适中(768-1024维):主流选择,精度和效率平衡
- 维度太高(如4096维):计算慢、内存大,边际收益递减
经验法则:选择模型推荐的维度,不要随意改变------预训练模型已经针对该维度优化。

Q8:如何评估向量检索的效果?
参考答案 :
三个核心指标:
| 指标 | 含义 | 计算公式 |
|---|---|---|
| Recall@K | Top-K结果中包含正确答案的比例 | 正确数 / 总查询数 |
| MRR | 第一个正确答案的平均排名倒数 | 平均(1/排名) |
| NDCG | 考虑排序位置的相关性得分 | 排名越靠前权重越高 |
实践方法:人工标注测试集(问题-正确答案对),用以上指标量化评估。

Q9:为什么有的模型说向量是4096维,有的说768维?它们有什么区别?
参考答案 :
这是因为两种不同的向量:
-
Token向量(4096维):来自生成模型(如Qwen2.5)内部的Embedding层。每个Token被映射为一个4096维的向量,供模型内部的自注意力机制使用。用户无法直接获取,这是模型的"内部表示"。
-
文本向量(768维):来自专门的Embedding模型(如nomic-embed-text)。输入任意文本,输出一个768维的向量,用于语义搜索、相似度计算。用户可以通过API直接获取。
面试加分回答:
"Token向量是模型'理解'每个词的方式,维度高是因为需要丰富的语义信息来生成文本。文本向量是模型'对外输出'的语义指纹,维度适中是为了在精度和检索效率之间平衡。两者服务于不同的目的,不能混为一谈。"

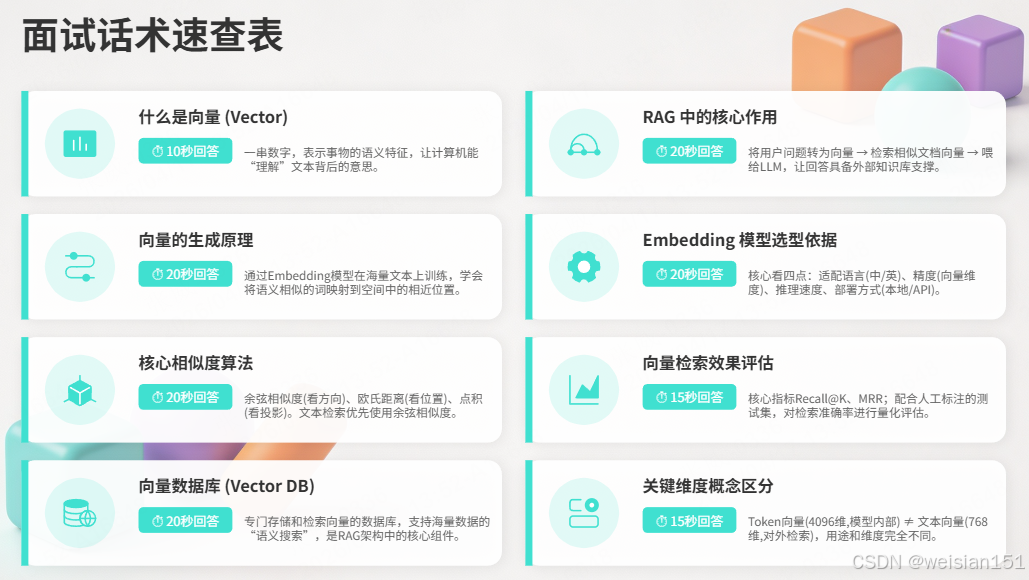
七、话术速查表
| 问题类型 | 回答时间 | 核心要点 |
|---|---|---|
| 什么是向量 | 10秒 | 一串数字,表示事物的语义特征,让计算机能"理解"意思 |
| 向量怎么生成 | 20秒 | 通过Embedding模型(如BERT)在海量文本上训练,学会把相似意思的词映射到相近位置 |
| 相似度计算 | 20秒 | 余弦相似度看方向、欧氏距离看位置、点积看投影,文本用余弦 |
| 向量数据库 | 20秒 | 专门存向量的数据库,支持"语义搜索",RAG的核心组件 |
| RAG中向量作用 | 20秒 | 问题转向量→找相似文档→喂给LLM,让回答有知识支撑 |
| Embedding选型 | 20秒 | 看语言(中/英)、精度(维度)、速度、部署方式 |
| 评估方法 | 15秒 | Recall@K、MRR,人工标注测试集量化评估 |
| 维度区分 | 15秒 | Token向量(4096维,模型内部)≠ 文本向量(768维,对外检索) |
总结
核心知识点速记
向量是串数字,语义特征装里面。
猫和狗向量近,猫和汽车距离远。
Embedding模型来编码,海量文本学关联。
余弦相似度算方向,语义搜索最常用。
向量数据库存向量,语义搜索秒级响。
RAG流程两步走:索引文档+在线检索。
问题转向量找片段,喂给LLM答得准。
维度选择要适中,太低太高都不行。
Token向量内部用,文本向量对外查。
面试讲透这几点,Offer拿到手不慌。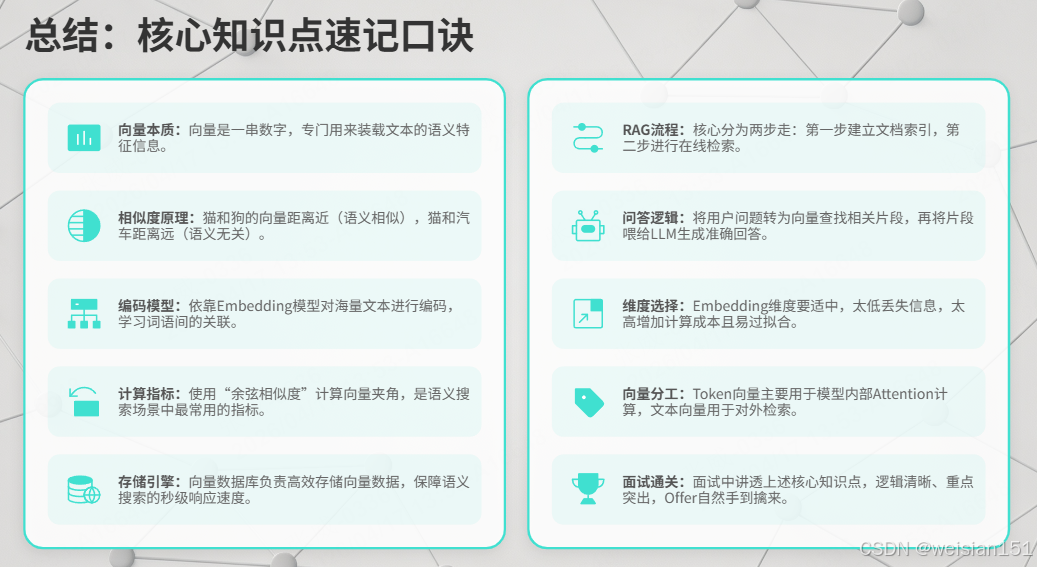
核心要点回顾
- 向量定义:一串有序数字,表示事物的语义特征
- 生成原理:Embedding模型从海量文本中学习,把相似意思的词映射到相近位置
- 相似度计算:余弦相似度最常用(关注方向),欧氏距离看绝对位置
- 向量数据库:专门存储和检索向量的数据库,支持语义搜索
- RAG核心:问题→向量→检索相似文档→LLM生成答案
- 选型考量:语言、维度、速度、部署方式
- 评估指标:Recall@K、MRR
- 维度区分:Token向量(模型内部,如Qwen2.5的4096维)≠ 文本向量(Embedding模型输出,如nomic-embed-text的768维)------前者供模型内部计算,后者供外部检索比较

写在最后
向量,是大模型理解世界的"数字翻译官"。它把人类能懂的"意思"变成计算机能算的"数字",让机器学会"相似"这个概念。
面试官问向量,不是在考"数学定义",而是在考察你对语义理解本质 的把握、对RAG架构 的理解、对工程选型的思考。
记住:能讲清楚向量的人,RAG系统设计、语义搜索优化、Embedding模型选型都不会差。
如果觉得有帮助,欢迎点赞、收藏、转发!有问题欢迎在评论区留言交流。