opencode SQLite 数据库结构与查询手册
数据库文件位置
opencode 使用 XDG Base Directory 标准存储数据:
| 系统 | 默认路径 |
|---|---|
| macOS(XDG 环境) | ~/.local/share/opencode/opencode.db |
| macOS(无 XDG) | ~/Library/Application Support/opencode/opencode.db |
| Linux | ~/.local/share/opencode/opencode.db |
脚本会自动检测两个路径,取第一个存在的。
自定义路径: 设置环境变量 OPENCODE_DB 可覆盖默认路径(绝对路径或 :memory:)。
安装渠道隔离: 非 latest/beta/prod 渠道的安装版本,数据库文件名为 opencode-{channel}.db。
数据库配置(PRAGMA)
ini
PRAGMA journal_mode = WAL; -- 预写式日志,提升并发
PRAGMA synchronous = NORMAL; -- 性能与安全的平衡
PRAGMA busy_timeout = 5000; -- 5 秒锁等待超时
PRAGMA cache_size = -64000; -- 64MB 内存缓存
PRAGMA foreign_keys = ON; -- 启用外键约束表结构总览
csharp
project(项目)
├── permission(权限规则)
├── workspace(工作空间)
└── session(会话)
├── message(消息)
│ └── part(消息片段:文本/工具调用/工具结果/压缩...)
├── todo(待办项)
├── session_share(会话分享)
└── session_entry(会话条目/事件)
account(账户)
└── account_state(账户状态)
event_sequence(事件序列)
└── event(事件)表详细说明
project --- 项目
| 字段 | 类型 | 说明 |
|---|---|---|
id |
TEXT PK | 项目唯一 ID |
worktree |
TEXT | Git worktree 路径 |
vcs |
TEXT | 版本控制系统类型 |
name |
TEXT | 项目名称 |
icon_url |
TEXT | 项目图标 URL |
icon_url_override |
TEXT | 覆盖图标 URL |
icon_color |
TEXT | 图标颜色 |
sandboxes |
TEXT(JSON) | 沙箱配置列表 |
commands |
TEXT(JSON) | 项目命令({start?: string}) |
time_created |
INTEGER | 创建时间戳(毫秒) |
time_updated |
INTEGER | 更新时间戳(毫秒) |
time_initialized |
INTEGER | 初始化时间戳 |
session --- 会话
| 字段 | 类型 | 说明 |
|---|---|---|
id |
TEXT PK | 会话唯一 ID |
project_id |
TEXT FK→project | 所属项目 |
workspace_id |
TEXT FK→workspace | 所属工作空间(可选) |
parent_id |
TEXT FK→session | 父会话 ID(子 agent 场景) |
slug |
TEXT | URL 友好别名 |
directory |
TEXT | 工作目录 |
path |
TEXT | 文件路径(可选) |
title |
TEXT | 会话标题 |
version |
TEXT | 会话版本号 |
share_url |
TEXT | 分享链接 |
summary_additions |
INTEGER | 代码增加行数 |
summary_deletions |
INTEGER | 代码删除行数 |
summary_files |
INTEGER | 修改文件数 |
summary_diffs |
TEXT(JSON) | 文件差异快照 |
revert |
TEXT(JSON) | 回滚信息 {messageID, partID?, snapshot?, diff?} |
permission |
TEXT(JSON) | 权限规则集 |
time_created |
INTEGER | 创建时间戳(毫秒) |
time_updated |
INTEGER | 更新时间戳(毫秒) |
time_compacting |
INTEGER | 正在压缩的时间戳 |
time_archived |
INTEGER | 归档时间戳 |
message --- 消息
| 字段 | 类型 | 说明 |
|---|---|---|
id |
TEXT PK | 消息唯一 ID |
session_id |
TEXT FK→session | 所属会话 |
time_created |
INTEGER | 创建时间戳(毫秒) |
time_updated |
INTEGER | 更新时间戳(毫秒) |
data |
TEXT(JSON) | 消息信息(见下方 JSON 结构) |
data 字段 JSON 结构(MessageV2.Info):
json
// role = "user"
{
"id": "msg_xxx",
"role": "user",
"sessionID": "ses_xxx",
"model": { "providerID": "anthropic", "modelID": "claude-sonnet-4-6" }
}
// role = "assistant"
{
"id": "msg_xxx",
"role": "assistant",
"sessionID": "ses_xxx",
"parentID": "msg_yyy", // 对应的 user 消息 ID
"model": { "providerID": "...", "modelID": "..." },
"agent": "general", // 使用的 agent 名称
"summary": true, // 是否为压缩摘要(compaction 产出)
"finish": "stop", // 结束原因:stop / tool-calls / length / error
"tokens": {
"input": 1234,
"output": 567,
"cache": { "read": 0, "write": 0 }
},
"error": { ... } // 若出错,包含错误信息
}part --- 消息片段
每条消息由一个或多个 part 组成,每个 part 是消息的一个组成单元。
| 字段 | 类型 | 说明 |
|---|---|---|
id |
TEXT PK | Part 唯一 ID |
message_id |
TEXT FK→message | 所属消息 |
session_id |
TEXT | 所属会话(冗余存储,加速查询) |
time_created |
INTEGER | 创建时间戳(毫秒) |
time_updated |
INTEGER | 更新时间戳(毫秒) |
data |
TEXT(JSON) | Part 数据(见下方 JSON 结构) |
data 字段的 type 取值:
json
// type = "text"(普通文本回复)
{
"type": "text",
"id": "part_xxx",
"messageID": "msg_xxx",
"sessionID": "ses_xxx",
"text": "这是 LLM 的回复文本"
}
// type = "tool"(工具调用请求)
{
"type": "tool",
"id": "part_xxx",
"tool": "read", // 工具名称
"toolCallID": "call_xxx",
"input": { "file_path": "/path/to/file" },
"state": {
"status": "completed", // pending / running / completed / error
"output": "文件内容...",
"metadata": { ... },
"time": {
"start": 1700000000000,
"end": 1700000001000,
"compacted": null // 若被 prune 裁剪则有时间戳
}
}
}
// type = "compaction"(压缩请求标记)
{
"type": "compaction",
"id": "part_xxx",
"auto": true, // 是否自动触发
"overflow": false, // 是否因 API overflow 触发
"tail_start_id": "msg_yyy" // tail 开始消息 ID
}
// type = "step-start"(agent 步骤开始标记)
{
"type": "step-start",
"id": "part_xxx"
}
// type = "error"
{
"type": "error",
"error": { "name": "...", "message": "..." }
}todo --- 待办项
| 字段 | 类型 | 说明 |
|---|---|---|
session_id |
TEXT FK→session | 所属会话 |
content |
TEXT | 待办内容 |
status |
TEXT | 状态(pending/completed 等) |
priority |
TEXT | 优先级 |
position |
INTEGER | 排序位置 |
time_created |
INTEGER | 创建时间戳 |
time_updated |
INTEGER | 更新时间戳 |
主键: (session_id, position)
session_entry --- 会话条目
记录会话过程中的结构化事件(如权限请求、文件变更等)。
| 字段 | 类型 | 说明 |
|---|---|---|
id |
TEXT PK | 条目唯一 ID |
session_id |
TEXT FK→session | 所属会话 |
type |
TEXT | 条目类型 |
data |
TEXT(JSON) | 条目数据 |
time_created |
INTEGER | 创建时间戳 |
time_updated |
INTEGER | 更新时间戳 |
session_share --- 会话分享
| 字段 | 类型 | 说明 |
|---|---|---|
session_id |
TEXT PK FK→session | 所属会话 |
id |
TEXT | 分享 ID |
secret |
TEXT | 分享密钥 |
url |
TEXT | 分享链接 |
time_created |
INTEGER | 创建时间戳 |
time_updated |
INTEGER | 更新时间戳 |
workspace --- 工作空间
| 字段 | 类型 | 说明 |
|---|---|---|
id |
TEXT PK | 工作空间 ID |
project_id |
TEXT FK→project | 所属项目 |
type |
TEXT | 类型 |
name |
TEXT | 名称 |
branch |
TEXT | Git 分支 |
directory |
TEXT | 工作目录 |
extra |
TEXT(JSON) | 额外配置 |
account / account_state --- 账户
| 字段(account) | 类型 | 说明 |
|---|---|---|
id |
TEXT PK | 账户 ID |
email |
TEXT | 邮箱 |
url |
TEXT | 服务端 URL |
access_token |
TEXT | OAuth access token |
refresh_token |
TEXT | OAuth refresh token |
token_expiry |
INTEGER | token 过期时间戳 |
| 字段(account_state) | 类型 | 说明 |
|---|---|---|
id |
INTEGER PK | 单例记录 ID |
active_account_id |
TEXT FK→account | 当前激活账户 |
active_org_id |
TEXT | 当前激活组织 ID |
event / event_sequence --- 事件溯源
| 字段(event) | 类型 | 说明 |
|---|---|---|
id |
TEXT PK | 事件 ID |
aggregate_id |
TEXT FK→event_sequence | 聚合根 ID |
seq |
INTEGER | 序列号 |
type |
TEXT | 事件类型 |
data |
TEXT(JSON) | 事件数据 |
常用 SQL 查询
连接数据库(命令行):
javascriptsqlite3 ~/Library/Application\ Support/opencode/opencode.db
查询所有 Session 列表
sql
SELECT
s.id,
s.title,
s.directory,
datetime(s.time_created / 1000, 'unixepoch', 'localtime') AS created_at,
datetime(s.time_updated / 1000, 'unixepoch', 'localtime') AS updated_at,
s.summary_files,
s.summary_additions,
s.summary_deletions
FROM session s
ORDER BY s.time_created DESC;查询某个 Session 的完整对话(消息 + 文本内容)
scss
-- 替换 'your-session-id' 为实际 session ID
SELECT
m.id AS message_id,
datetime(m.time_created / 1000, 'unixepoch', 'localtime') AS time,
json_extract(m.data, '$.role') AS role,
json_extract(m.data, '$.agent') AS agent,
json_extract(m.data, '$.finish') AS finish,
json_extract(m.data, '$.tokens.input') AS tokens_in,
json_extract(m.data, '$.tokens.output') AS tokens_out,
p.id AS part_id,
json_extract(p.data, '$.type') AS part_type,
json_extract(p.data, '$.text') AS text_content
FROM message m
LEFT JOIN part p ON p.message_id = m.id
WHERE m.session_id = 'your-session-id'
AND json_extract(p.data, '$.type') = 'text'
ORDER BY m.time_created, p.time_created;查询所有工具调用记录
sql
SELECT
p.session_id,
m.id AS message_id,
datetime(p.time_created / 1000, 'unixepoch', 'localtime') AS time,
json_extract(p.data, '$.tool') AS tool_name,
json_extract(p.data, '$.input') AS input_json,
json_extract(p.data, '$.state.status') AS status,
json_extract(p.data, '$.state.time.start') AS start_ms,
json_extract(p.data, '$.state.time.end') AS end_ms,
(json_extract(p.data, '$.state.time.end') -
json_extract(p.data, '$.state.time.start')) AS duration_ms,
CASE WHEN json_extract(p.data, '$.state.time.compacted') IS NOT NULL
THEN 'pruned' ELSE 'intact' END AS prune_status
FROM part p
JOIN message m ON m.id = p.message_id
WHERE json_extract(p.data, '$.type') = 'tool'
ORDER BY p.time_created DESC
LIMIT 200;按工具名称统计调用次数和平均耗时
sql
SELECT
json_extract(p.data, '$.tool') AS tool_name,
COUNT(*) AS call_count,
COUNT(CASE WHEN json_extract(p.data, '$.state.status') = 'error' THEN 1 END) AS error_count,
AVG(json_extract(p.data, '$.state.time.end') -
json_extract(p.data, '$.state.time.start')) AS avg_duration_ms,
MAX(json_extract(p.data, '$.state.time.end') -
json_extract(p.data, '$.state.time.start')) AS max_duration_ms
FROM part p
WHERE json_extract(p.data, '$.type') = 'tool'
AND json_extract(p.data, '$.state.status') = 'completed'
GROUP BY tool_name
ORDER BY call_count DESC;查询 Token 消耗统计(按 Session)
sql
SELECT
s.title,
s.id AS session_id,
datetime(s.time_created / 1000, 'unixepoch', 'localtime') AS created_at,
SUM(json_extract(m.data, '$.tokens.input')) AS total_input_tokens,
SUM(json_extract(m.data, '$.tokens.output')) AS total_output_tokens,
SUM(json_extract(m.data, '$.tokens.input') +
json_extract(m.data, '$.tokens.output')) AS total_tokens,
COUNT(DISTINCT m.id) AS message_count
FROM session s
JOIN message m ON m.session_id = s.id
WHERE json_extract(m.data, '$.role') = 'assistant'
AND json_extract(m.data, '$.tokens.input') IS NOT NULL
GROUP BY s.id
ORDER BY total_tokens DESC;查询压缩(Compaction)记录
sql
SELECT
p.session_id,
m.id AS compact_req_msg,
datetime(m.time_created / 1000, 'unixepoch', 'localtime') AS time,
json_extract(p.data, '$.auto') AS auto_triggered,
json_extract(p.data, '$.overflow') AS was_overflow,
json_extract(p.data, '$.tail_start_id') AS tail_start_id
FROM part p
JOIN message m ON m.id = p.message_id
WHERE json_extract(p.data, '$.type') = 'compaction'
ORDER BY m.time_created DESC;查询压缩摘要内容
sql
SELECT
m.session_id,
m.id AS summary_msg_id,
datetime(m.time_created / 1000, 'unixepoch', 'localtime') AS time,
p.id AS part_id,
json_extract(p.data, '$.text') AS summary_text
FROM message m
JOIN part p ON p.message_id = m.id
WHERE json_extract(m.data, '$.summary') = 1
AND json_extract(p.data, '$.type') = 'text'
ORDER BY m.time_created DESC;查询被 Prune 裁剪的工具输出
sql
SELECT
p.session_id,
json_extract(p.data, '$.tool') AS tool_name,
datetime(json_extract(p.data, '$.state.time.compacted') / 1000,
'unixepoch', 'localtime') AS pruned_at
FROM part p
WHERE json_extract(p.data, '$.type') = 'tool'
AND json_extract(p.data, '$.state.time.compacted') IS NOT NULL
ORDER BY json_extract(p.data, '$.state.time.compacted') DESC;查询 Todo 列表
vbnet
SELECT
t.session_id,
s.title AS session_title,
t.position,
t.content,
t.status,
t.priority,
datetime(t.time_created / 1000, 'unixepoch', 'localtime') AS created_at
FROM todo t
JOIN session s ON s.id = t.session_id
ORDER BY t.session_id, t.position;导出数据到 Excel
方式一:按 Session ID 导出完整数据(推荐)
同时生成 Excel(4 sheets)和 JSON,输出到脚本同级的 excels/ 目录。
安装依赖:
pip install pandas openpyxl运行:
bash
# 修改脚本顶部的 SESSION_ID,然后运行
python docs/export_session.py输出文件:
| 文件 | 说明 |
|---|---|
docs/excels/session_<id8>.xlsx |
Excel,含 4 个 sheet |
docs/excels/session_<id8>_messages.json |
JSON,与插件 save-messages.js 格式一致 |
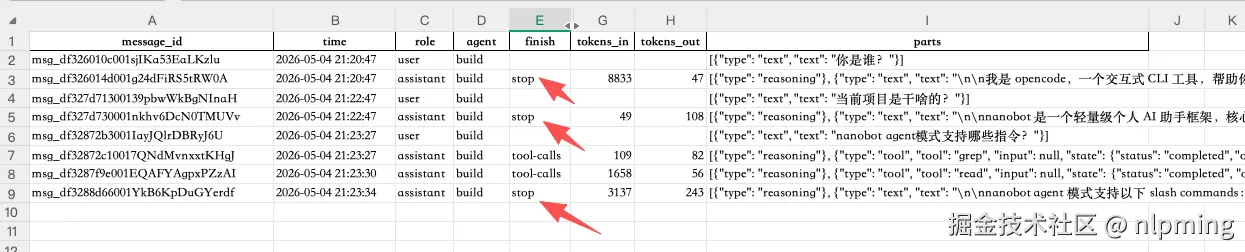
Excel Sheet 结构:
| Sheet | 内容 |
|---|---|
Messages |
每行一条消息:role、agent、finish、token、parts(JSON 字符串) |
Session |
session 基本信息、项目名、代码变更统计 |
ToolStats |
按工具名汇总(调用次数、成功/失败/pruned、平均/最大耗时) |
TokenUsage |
每轮 assistant token 消耗时序(input/output/cache) |
脚本完整代码:
python
import sqlite3
import pandas as pd
import os
import sys
import json
from datetime import datetime
from collections import defaultdict
from urllib.request import pathname2url
# ── 配置 ──────────────────────────────────────────────────
SESSION_ID = "ses_29276303affePFCDRVSqdzdE2B" # ← 替换为目标 session ID
_candidates = [
os.path.expanduser("~/.local/share/opencode/opencode.db"),
os.path.expanduser("~/Library/Application Support/opencode/opencode.db"),
]
DB_PATH = next((p for p in _candidates if os.path.exists(p)), None)
if DB_PATH is None:
print("找不到 opencode 数据库,请手动设置 DB_PATH")
sys.exit(1)
print(f"使用数据库: {DB_PATH}")
_output_dir = os.path.join(os.path.dirname(os.path.abspath(__file__)), "excels")
os.makedirs(_output_dir, exist_ok=True)
OUTPUT_PATH = os.path.join(_output_dir, f"session_{SESSION_ID[:8]}.xlsx")
OUTPUT_JSON_PATH = os.path.join(_output_dir, f"session_{SESSION_ID[:8]}_messages.json")
conn = sqlite3.connect(f"file:{pathname2url(DB_PATH)}?mode=ro", uri=True)
conn.row_factory = sqlite3.Row
def ts(ms):
"""毫秒时间戳 → 可读字符串"""
if ms is None:
return ""
return datetime.fromtimestamp(ms / 1000).strftime("%Y-%m-%d %H:%M:%S")
messages_raw = conn.execute("""
SELECT
m.id, m.time_created,
json_extract(m.data, '$.role') AS role,
json_extract(m.data, '$.agent') AS agent,
json_extract(m.data, '$.finish') AS finish,
json_extract(m.data, '$.summary') AS is_summary,
json_extract(m.data, '$.tokens.input') AS tokens_in,
json_extract(m.data, '$.tokens.output') AS tokens_out
FROM message m
WHERE m.session_id = ?
ORDER BY m.time_created, m.id
""", (SESSION_ID,)).fetchall()
parts_raw = conn.execute("""
SELECT
p.id, p.message_id, p.time_created,
json_extract(p.data, '$.type') AS type,
json_extract(p.data, '$.text') AS text,
json_extract(p.data, '$.tool') AS tool,
json_extract(p.data, '$.input') AS input_json,
json_extract(p.data, '$.state.status') AS status,
json_extract(p.data, '$.state.output') AS output,
json_extract(p.data, '$.state.time.start') AS tool_start,
json_extract(p.data, '$.state.time.end') AS tool_end,
json_extract(p.data, '$.state.time.compacted') AS compacted,
json_extract(p.data, '$.auto') AS compact_auto,
json_extract(p.data, '$.overflow') AS compact_overflow
FROM part p
WHERE p.session_id = ?
ORDER BY p.time_created, p.id
""", (SESSION_ID,)).fetchall()
# 按 message_id 分组 parts
parts_by_msg = defaultdict(list)
for p in parts_raw:
parts_by_msg[p["message_id"]].append(p)
def build_part(p):
"""将 sqlite Row 转为与插件格式对齐的 part dict"""
t = p["type"]
if t == "text":
return {"type": "text", "text": p["text"] or ""}
elif t == "tool":
try:
inp = json.loads(p["input_json"]) if p["input_json"] else None
except Exception:
inp = p["input_json"]
return {
"type": "tool",
"tool": p["tool"],
"input": inp,
"state": {
"status": p["status"],
"output": "[compacted]" if p["compacted"] else (p["output"] or ""),
"time": {
"start": p["tool_start"],
"end": p["tool_end"],
},
},
}
elif t == "compaction":
return {
"type": "compaction",
"auto": p["compact_auto"],
"overflow": p["compact_overflow"],
}
elif t == "error":
return {"type": "error", "text": p["text"] or ""}
else:
return {"type": t}
# ── 构建 messages 结构(每条消息 → { info, parts })────────
messages_list = []
for msg in messages_raw:
info = {
"role": msg["role"],
"sessionID": SESSION_ID,
"messageID": msg["id"],
"agent": msg["agent"],
"finish": msg["finish"],
"is_summary": bool(msg["is_summary"]),
"time": ts(msg["time_created"]),
"time_created": msg["time_created"],
"tokens": {
"input": msg["tokens_in"],
"output": msg["tokens_out"],
},
}
parts_for_msg = [
build_part(p)
for p in parts_by_msg.get(msg["id"], [])
if p["type"] != "step-start"
]
messages_list.append({"info": info, "parts": parts_for_msg})
# Messages sheet:每行一条消息,parts 序列化为 JSON 字符串
df_messages = pd.DataFrame([
{
"message_id": m["info"]["messageID"],
"time": m["info"]["time"],
"role": m["info"]["role"],
"agent": m["info"]["agent"] or "",
"finish": m["info"]["finish"] or "",
"is_summary": m["info"]["is_summary"],
"tokens_in": m["info"]["tokens"]["input"] or "",
"tokens_out": m["info"]["tokens"]["output"] or "",
"parts": json.dumps(m["parts"], ensure_ascii=False),
}
for m in messages_list
])
df_session = pd.read_sql_query("""
SELECT
s.id, s.title, s.directory, s.version,
datetime(s.time_created/1000, 'unixepoch', 'localtime') AS created_at,
datetime(s.time_updated/1000, 'unixepoch', 'localtime') AS updated_at,
s.summary_files, s.summary_additions, s.summary_deletions,
p.worktree, p.name AS project_name
FROM session s
LEFT JOIN project p ON p.id = s.project_id
WHERE s.id = ?
""", conn, params=(SESSION_ID,))
df_tool_stats = pd.read_sql_query("""
SELECT
json_extract(p.data, '$.tool') AS tool_name,
COUNT(*) AS call_count,
SUM(CASE WHEN json_extract(p.data,'$.state.status')='completed' THEN 1 ELSE 0 END) AS success,
SUM(CASE WHEN json_extract(p.data,'$.state.status')='error' THEN 1 ELSE 0 END) AS errors,
SUM(CASE WHEN json_extract(p.data,'$.state.time.compacted') IS NOT NULL THEN 1 ELSE 0 END) AS pruned,
ROUND(AVG(
json_extract(p.data,'$.state.time.end') -
json_extract(p.data,'$.state.time.start')), 0) AS avg_duration_ms,
MAX(
json_extract(p.data,'$.state.time.end') -
json_extract(p.data,'$.state.time.start')) AS max_duration_ms
FROM part p
WHERE p.session_id = ?
AND json_extract(p.data,'$.type') = 'tool'
GROUP BY tool_name
ORDER BY call_count DESC
""", conn, params=(SESSION_ID,))
df_tokens = pd.read_sql_query("""
SELECT
m.id AS message_id,
datetime(m.time_created/1000, 'unixepoch', 'localtime') AS time,
json_extract(m.data, '$.agent') AS agent,
json_extract(m.data, '$.tokens.input') AS tokens_in,
json_extract(m.data, '$.tokens.output') AS tokens_out,
json_extract(m.data, '$.tokens.cache.read') AS cache_read,
json_extract(m.data, '$.tokens.cache.write') AS cache_write,
(
COALESCE(json_extract(m.data,'$.tokens.input'), 0) +
COALESCE(json_extract(m.data,'$.tokens.output'), 0) +
COALESCE(json_extract(m.data,'$.tokens.cache.read'), 0) +
COALESCE(json_extract(m.data,'$.tokens.cache.write'), 0)
) AS total_tokens
FROM message m
WHERE m.session_id = ?
AND json_extract(m.data, '$.role') = 'assistant'
AND json_extract(m.data, '$.tokens.input') IS NOT NULL
ORDER BY m.time_created
""", conn, params=(SESSION_ID,))
conn.close()
if df_session.empty:
print(f"Session not found: {SESSION_ID}")
sys.exit(1)
# ── 写入 Excel ────────────────────────────────────────────
with pd.ExcelWriter(OUTPUT_PATH, engine="openpyxl") as writer:
df_messages.to_excel( writer, sheet_name="Messages", index=False)
df_session.to_excel( writer, sheet_name="Session", index=False)
df_tool_stats.to_excel(writer, sheet_name="ToolStats", index=False)
df_tokens.to_excel( writer, sheet_name="TokenUsage", index=False)
# ── 写入 JSON(与插件 save-messages.js 格式一致)────────────
json_payload = {
"sessionId": SESSION_ID,
"title": df_session["title"].iloc[0],
"messages": messages_list,
}
with open(OUTPUT_JSON_PATH, "w", encoding="utf-8") as f:
json.dump(json_payload, f, ensure_ascii=False, indent=2)
print(f"\n导出完成")
print(f" Excel → {OUTPUT_PATH}")
print(f" JSON → {OUTPUT_JSON_PATH}")
print(f" Session : {df_session['title'].iloc[0]}")
print(f" 消息数 : {len(messages_list)}")方式二:导出所有 Session 汇总
ini
import sqlite3
import pandas as pd
import os
from urllib.request import pathname2url
_candidates = [
os.path.expanduser("~/.local/share/opencode/opencode.db"),
os.path.expanduser("~/Library/Application Support/opencode/opencode.db"),
]
DB_PATH = next((p for p in _candidates if os.path.exists(p)), None)
OUTPUT_PATH = os.path.expanduser("~/Desktop/opencode_all.xlsx")
conn = sqlite3.connect(f"file:{pathname2url(DB_PATH)}?mode=ro", uri=True)
def q(sql):
return pd.read_sql_query(sql, conn)
sessions = q("""
SELECT
s.id, s.title, s.directory,
datetime(s.time_created/1000, 'unixepoch', 'localtime') AS created_at,
datetime(s.time_updated/1000, 'unixepoch', 'localtime') AS updated_at,
s.summary_files, s.summary_additions, s.summary_deletions,
p.name AS project_name
FROM session s
LEFT JOIN project p ON p.id = s.project_id
ORDER BY s.time_created DESC
""")
tool_stats = q("""
SELECT
p.session_id,
json_extract(p.data, '$.tool') AS tool_name,
COUNT(*) AS call_count,
ROUND(AVG(
json_extract(p.data, '$.state.time.end') -
json_extract(p.data, '$.state.time.start')
), 0) AS avg_duration_ms
FROM part p
WHERE json_extract(p.data, '$.type') = 'tool'
GROUP BY p.session_id, tool_name
ORDER BY p.session_id, call_count DESC
""")
token_summary = q("""
SELECT
m.session_id,
SUM(json_extract(m.data,'$.tokens.input')) AS total_input,
SUM(json_extract(m.data,'$.tokens.output')) AS total_output,
COUNT(*) AS assistant_msgs
FROM message m
WHERE json_extract(m.data,'$.role') = 'assistant'
AND json_extract(m.data,'$.tokens.input') IS NOT NULL
GROUP BY m.session_id
""")
conn.close()
with pd.ExcelWriter(OUTPUT_PATH, engine="openpyxl") as writer:
sessions.to_excel( writer, sheet_name="Sessions", index=False)
tool_stats.to_excel( writer, sheet_name="ToolStats", index=False)
token_summary.to_excel(writer, sheet_name="TokenSummary",index=False)
print(f"导出完成 → {OUTPUT_PATH},共 {len(sessions)} 个 Session")方式三:sqlite3 CLI 导出 CSV
bash
# 进入 sqlite3
sqlite3 ~/Library/Application\ Support/opencode/opencode.db
# 设置 CSV 模式
.mode csv
.headers on
# 导出 Session 列表
.output /tmp/sessions.csv
SELECT id, title, directory,
datetime(time_created/1000,'unixepoch','localtime') AS created_at
FROM session ORDER BY time_created DESC;
# 导出工具调用
.output /tmp/tool_calls.csv
SELECT p.session_id,
json_extract(p.data,'$.tool') AS tool,
json_extract(p.data,'$.state.status') AS status,
datetime(p.time_created/1000,'unixepoch','localtime') AS time
FROM part p
WHERE json_extract(p.data,'$.type') = 'tool';
.quit之后用 Excel 直接打开 CSV 文件(文件→导入)。
方式四:GUI 工具(推荐日常使用)
| 工具 | 平台 | 说明 |
|---|---|---|
| DB Browser for SQLite | macOS/Win/Linux | 免费,支持直接执行 SQL 并导出 CSV/Excel |
| TablePlus | macOS/Win | 商业软件,界面美观 |
| DBeaver | 全平台 | 免费,支持 JSON 字段可视化 |
打开数据库文件路径:~/Library/Application Support/opencode/opencode.db
注意事项
- JSON 字段 :
message.data、part.data等字段存储 JSON 文本,SQLite 通过json_extract()函数查询内部字段。 - 时间戳 :所有时间字段均为毫秒级 Unix 时间戳,转可读时间用
datetime(field/1000, 'unixepoch', 'localtime')。 - 只读建议:直接查询数据库时建议以只读模式连接,避免意外修改运行中的数据。
- WAL 模式 :若 opencode 正在运行,WAL 日志文件(
.db-wal、.db-shm)可能存在,Python 的sqlite3可以安全读取,不影响正常运行。 - part 与 message 关系 :一条 message 对应多个 parts,通过
message_id关联。文本内容在type='text'的 part 里;工具调用在type='tool'的 part 里。